?網絡優化是指尋找一個神經網絡模型來使得經驗(或結構)風險最小化的過程,包括模型選擇以及參數學習等。
關于經驗風險最小化和結構風險最小化,請參考博文:
認識機器學習中的經驗風險最小化準則_樣本均值近似與經驗風險最小化的關系-CSDN博客
認識機器學習中的結構風險最小化準則_結構風險機器學習-CSDN博客
深度神經網絡是一個高度非線性的模型,其風險函數是一個非凸函數,因此風險最小化是一個非凸優化問題。此外,深度神經網絡還存在梯度消失問題。因此,深度神經網絡的優化是一個具有挑戰性的問題。
神經網絡的種類非常多,比如卷積網絡、循環網絡、圖網絡等。不同網絡的結構也非常不同,有些比較深,有些比較寬,不同參數在網絡中的作用也有很大的差異,比如連接權重和偏置的不同,以及循環網絡中循環連接上的權重和其他權重的不同。
由于網絡結構的多樣性,我們很難找到一種通用的優化方法。不同優化方法在不同網絡結構上的表現也有比較大的差異。
此外,網絡的超參數一般比較多,這也給優化帶來很大的挑戰.
作為鋪墊,前一博文我們介紹了低維空間的非凸優化問題:低維空間的非凸優化問題-CSDN博客
本文我們來正式學習高維變量(空間)的非凸優化。
低維空間的非凸優化問題主要是存在一些局部最優點。基于梯度下降的優化方法會陷入局部最優點,因此在低維空間中非凸優化的主要難點是如何選擇初始化參數和逃離局部最優點。深度神經網絡的參數非常多,其參數學習是在非常高維空間中的非凸優化問題,其挑戰和在低維空間中的非凸優化問題有所不同。
一、這里解釋一下:低維空間中非凸優化的“逃離局部最優點”
概念理解
-
局部最優點(Local Optimum)
在非凸優化中,局部最優點指的是在某個小范圍內,目標函數的值比附近所有點都小(或大),但它并不一定是全局范圍的最小(或最大)值。換言之,它是“這個山谷的最低點”,卻可能高于另一座更深的山谷底部。 -
“逃離局部最優點”的含義
-
“逃離”意味著算法在某一次迭代中發現自己處于一個次優的谷底(局部最優),如果繼續按常規梯度方向下降,則只會在這個谷底中震蕩,無法到達更深的、全局最優的山谷。
-
要“逃離”,就需要引入額外機制,讓搜索過程能夠“跳出”當前的谷底,去探索其他區域,以期找到全局最優解或更優的局部解。
-
為什么會陷入局部最優
-
梯度為零:在局部最優點,目標函數梯度(或一階導數)為零,普通的梯度下降算法無法再更新參數。
-
鞍點與平坦區域:還可能出現既非極大也非極小的鞍點,算法在此也會停滯。
-
目標地形復雜:非凸函數常有多個起伏不平的“山谷”和“山峰”,算法只要初始點落在某個山谷附近,就可能陷入該谷。
常見“逃離”策略
-
多次隨機初始化(Random Restarts)
-
從不同的初始點多次運行優化算法,記錄各次結果,取最優者。這樣可增加至少一次落到全局最優區域的概率。
-
-
模擬退火(Simulated Annealing)
-
引入溫度參數,允許算法以一定概率接受“上坡”(目標值變差)的步驟;隨著溫度逐漸降低,這種隨機越過山脊的機會減少,從而有機會跳出局部谷底。
-
-
添加噪聲(Noise Injection)
-
在每次梯度更新時加入小隨機擾動,擾動有助于擺脫梯度為零的陷阱,將參數推離局部極值點。
-
-
動量方法(Momentum)
-
利用過去梯度的累積方向,幫助克服鞍點或淺谷的拖拽效應,使得優化路徑能繼續往前越過局部障礙。
-
-
演化或群體算法(Genetic Algorithms, Particle Swarm)
-
使用多種候選解同時搜索,通過選擇、交叉、變異等操作,群體解可跳出局部最優,逐代逼近全局最優。
-
“逃離局部最優點”就是讓優化算法不被眼前的小山谷困住,而有能力去嘗試更遠處的區域,以期尋找到全局最優或更優的局部解。常見做法包括多次隨機啟動、模擬退火、噪聲注入、動量方法和群體智能等,它們從不同角度幫助“跳出”或“越過”局部最優的障礙。
二、從鞍點角度分析高維變量(空間)的非凸優化
在高維空間中,非凸優化的難點并不在于如何逃離局部最優點,而是如何逃離鞍點(Saddle Point)。鞍點的梯度是 0,但是在一些維 度上是最高點,在另一些維度上是最低點,如下圖:
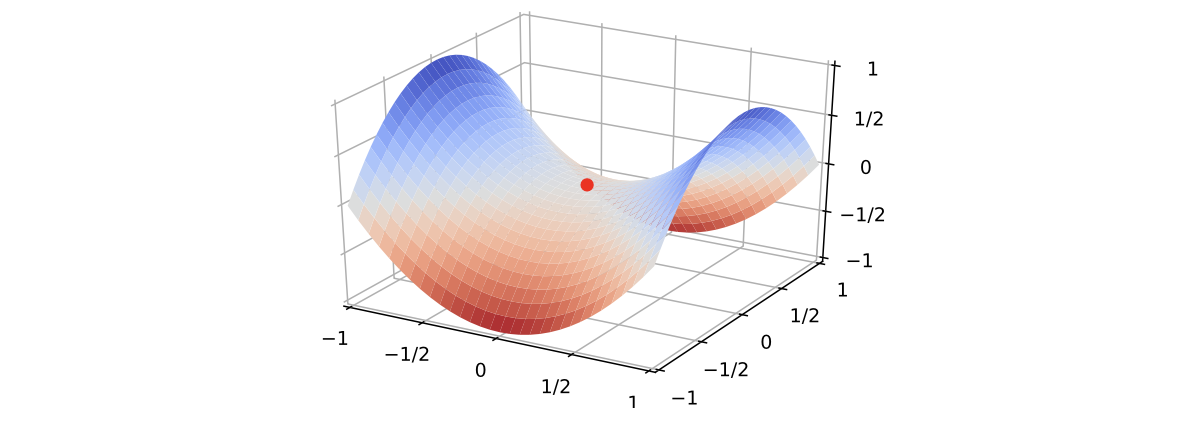
鞍點的叫法是因為其形狀像馬鞍。鞍點的特征是一階梯度為0,但是二階梯度的 Hessian 矩陣不是半正定矩陣。
在高維空間中,局部最小值(Local Minima)要求在每一維度上都是最低點,這種概率非常低。假設網絡有10,000維參數,梯度為0的點(即駐點(Sta-tionary Point))在某一維上是局部最小值的概率為 𝑝,那么在整個參數空間中,駐點是局部最優點的概率為 𝑝10,000,這種可能性非常小。也就是說,在高維空間 中大部分駐點都是鞍點。
基于梯度下降的優化方法會在鞍點附近接近于停滯,很難從這些鞍點中逃 離。因此,隨機梯度下降對于高維空間中的非凸優化問題十分重要,通過在梯度方向上引入隨機性,可以有效地逃離鞍點。后面的博文中會詳細介紹。
Hessian 矩陣是什么?

這個矩陣在優化中非常重要,可以用來判斷駐點(梯度為零的點)是極小點、極大點還是鞍點:
-
若 Hessian 正定(所有特征值都大于零),則該駐點是局部極小。
-
若 Hessian 負定(所有特征值都小于零),則該駐點是局部極大。
-
若 Hessian 不定(既有正特征值也有負特征值),則該駐點是鞍點。
半正定矩陣是什么?

在優化中:
-
如果 Hessian 是半正定的,那么函數在該點附近是“向上開口”的(或平坦),可能是局部極小或鞍點,但不會是局部極大。
-
半正定性質保證二次近似不會在任何方向上出現向下的“山形”,常用于證明凸函數的二次泰勒展開是下界。
這些數學定義的理解,需要額外去翻閱資料去了解,大家感興趣可以自行深入了解一下,這里只總結性的列一下,輔助理解高維空間中,逃離鞍點的復雜性。
三、從平坦最小值分析高維變量(空間)的非凸優化
深度神經網絡的參數非常多,并且有一定的冗余性,這使得每單個 參數對最終損失的影響都比較小,因此會導致損失函數在局部最小解附近通常 是一個平坦的區域,稱為平坦最小值。
下圖給出了平坦最小值和尖銳最小值(Sharp Minima)的示例:
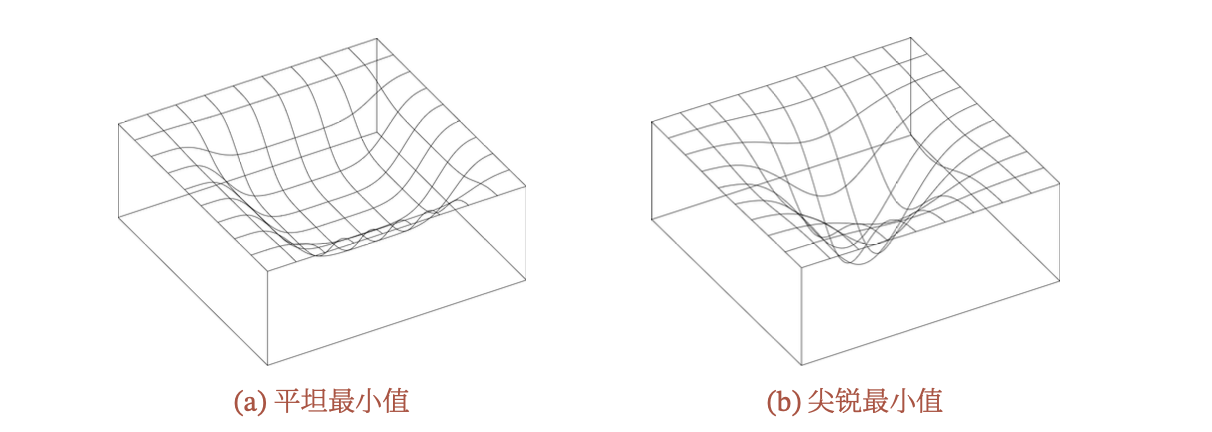
在一個平坦最小值的鄰域內,所有點對應的訓練損失都比較接近,表明我們這里的很多描述都是在訓練神經網絡時,不需要精確地找到一個局部最小解,只要在一個局部最小解 的鄰域內就足夠了。平坦最小值通常被認為和模型泛化能力有一定的關系。一般而言,當一個模型收斂到一個平坦的局部最小值時,其魯棒性會更好,即微小的參數變動不會劇烈影響模型能力(魯棒性的定義);而當一個模型收斂到一個尖銳的局部最小值 時,其魯棒性也會比較差。具備良好泛化能力的模型通常應該是魯棒的,因此理想的局部最小值應該是平坦的。
(這里的很多描述都是經驗性的,并沒有很好的理論證明)
四、從局部最小解的等價性分析高維變量(空間)的非凸優化
在非常大的神經網絡中,大部分的局部最小解是等價的, 它們在測試集上性能都比較相似。此外,局部最小解對應的訓練損失都可能非常接近于全局最小解對應的訓練損失 。雖然神經網絡 有一定概率收斂于比較差的局部最小值,但隨著網絡規模增加,網絡陷入比較差的局部最小值的概率會大大降低。在訓練神經網絡時,我們通常沒有必要找全局 最小值,這反而可能導致過擬合。
在高維非凸優化中,神經網絡的局部最小解通常表現出“等價性”(equivalence),即絕大多數局部最小點在目標值(損失)和泛化能力上差異極小。
(一)概要
-
高維效應:隨著參數維度增加,損失函數的隨機成分平均化,絕大多數局部極小點集中在一個狹窄的“能量帶”中,損失值相近。
-
自旋玻璃理論:借鑒物理中自旋玻璃模型,高維隨機場的局部極小多且值近。
-
參數對稱性:神經網絡層內部的置換對稱使得同一個模型函數對應多個參數解,進一步增多“等價”局部極小。
(二)幾何與自旋玻璃視角
-
能量地形多峰結構
-
在數千甚至數百萬維參數空間中,目標函數類似“多峰山脈”。
-
隨機矩陣理論顯示,絕大多數局部極小值點對應的 Hessian 特征值分布都集中在相似區間,這意味著它們的“深度”(損失值)近似一致。
-
-
自旋玻璃模型對比
-
Choromanska 等人在 AISTATS 2015 中將深度網絡損失與自旋玻璃能量函數做類比,證明局部極小值的損失值幾乎等價。
-
這表明在高度非凸的高維場景下,真正的全局最優與普通局部最優在數值上區別微小,不至顯著影響模型性能。
-
(三)參數對稱性與模式連通
-
置換對稱
-
同一隱藏層中神經元的任意置換不會改變網絡函數輸出,使得參數空間存在巨大的等價類。
-
這意味著若一個解是局部極小,那么對其神經元重命名后仍是一個等價解,增大了局部極小的數量且使其等價。
-
-
模式連通性(Mode Connectivity)
-
Garipov 等人(ICML 2018)和 Draxler 等人(ICLR 2018)觀察到,不同訓練得到的局部極小點之間可以通過低損失的“拱橋”相連,說明它們位于同一個連通“谷底”區域。
-
這種結構進一步支持所有局部極小的等價性:它們并非孤立,而是在同一平坦區域的不同“點”。
-
(四)實證與理論支持
-
Kawaguchi 的全局極小無“壞”局部論
-
Kawaguchi(NIPS 2016)證明,對于線性或某些簡化非線性網絡,所有局部極小都是全局極小,強化了等價性的理論基礎。
-
-
Dauphin 的鞍點主導論
-
Dauphin 等(NIPS 2014)指出,高維非凸場景下,梯度下降更易被大量高索引鞍點而非局部極小所阻,于是能到達平坦的局部極小區域,這些區域損失相近且泛化好。
-
(五)小結
-
在高維非凸優化中,參數維度越高,局部極小點的“深度”分布越集中,幾乎等價。
-
這種等價性來源于統計平均效應、自旋玻璃類比和網絡自身的對稱結構。
-
理論與實驗均表明,只要算法能避開鞍點并到達平坦區域,不同初始化往往收斂到等價的低損失解,從而保證泛化性能穩定。
注:關于這部分,個人建議,我們更多的認識到,有“局部最小解的等價性”這個理論存在,然后理解其在高維變量(空間)的非凸優化中的應用及其合理性即可。當然若想進一步理解其原理和理論依據,可以去深究一下上面提到的各種理論和研究。



)















——不僅僅是簡單的基礎設施遷移)