目錄
前言:
set
基本命令
交集并集差集
內部編碼和應用場景
zset
基本命令
交集并集差集
內部編碼和應用場景
應用場景(AI生成)
排行榜系統
應用背景
設計思路
熱榜系統
應用背景
設計思路
熱度計算方式
總結對比表
前言:
在前幾篇Redis的基本數據類型中,我們已經了解了string list hash,并且了解了對應的內部編碼和實際的應用場景,也是對于基本的命令操作花了比較多的文字描述的去介紹。那么在本文呢,既然有了前幾個類型多個基礎,我們學習set和zset也是會比較輕松的了。
廢話不多說,我們直接進入主題吧。
set
基本命令
首先,set它是代表集合的意思,那么對于它來說,存在的幾個特點有:無序的,不可重復的,那么因為無序,它也就不存在索引的特點。
既然是集合,我們曾經在高中階段,或者是大學階段均接觸過集合的概念,對于集合來說有的基本操作有交集并集差集,在Redis中也存在這幾個操作,所以這里的set雖然說和C++中的set差別比較大,但是和數學中的集合還是挺有相同點的。
sadd:給集合中添加元素,返回值為添加成功了幾個元素
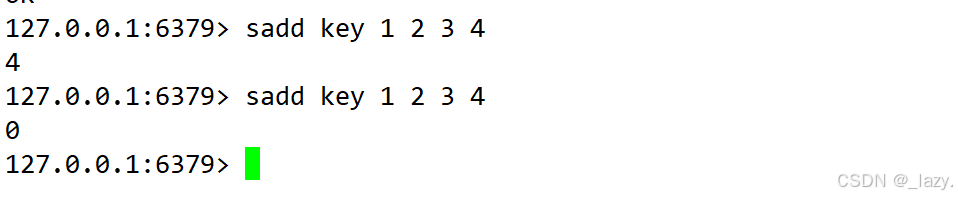
因為集合是去重的,所以我們重復添加元素的話,是會添加失敗的。
smembers:查看集合中的元素?
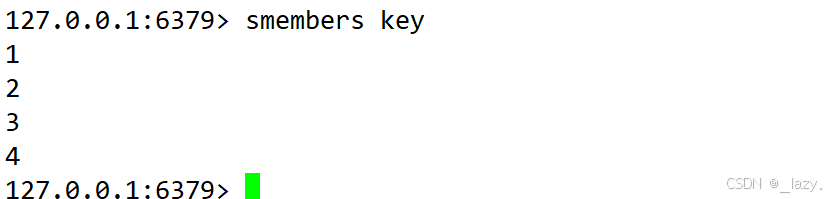
sismember: 判斷元素是否在集合內部

不過sismember只能判斷一個元素,其實對于這種命令來說我們甚至可以通過翻譯的方式判斷它是什么意思,比如sismember,s代表set is的意思代表是 member代表成員,那么sismember的意思就是是否是set的成員。所以我們也沒有必要專門記命令。
scard:查詢set中有多少個元素

spop:隨機刪除一個元素
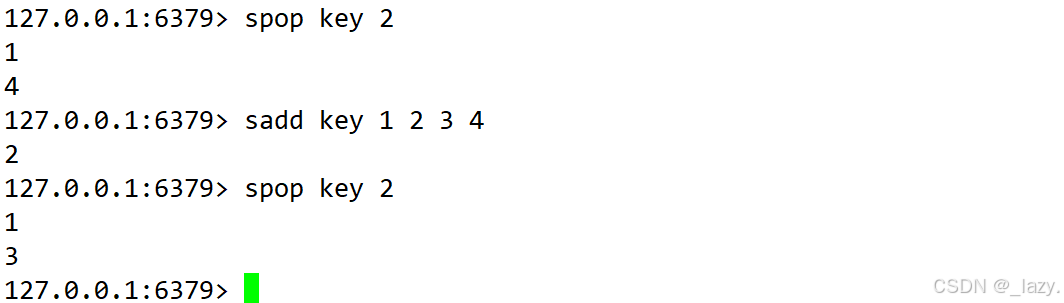
注意,這里的隨機是真的隨機,我們也可以通過驗證的方式判斷是否是隨機的,第一次是1 4,第二次是1 3,不存在任何的順序。這其實就有點意思了,隨機刪除。
至于為什么是隨機的呢,可能也和set本身是無序的有關系吧,而且官方文檔也明確說了spop是隨機的,并且在源碼中也是使用的生成隨機數的方式的:


既然我們現在提到了無序,我們可以簡單引出一個話題,即什么是有序的?
其實對于有序來說,分為有順序和排名有序的,比如我們拿set來說,有1 2 3 4和4 1 3 2的兩種情況的set都是一樣的,拿list來說,1 2 3 4和 1 2 4 3的兩種不是一樣的,因為list是有序的,但是以上我們兩種說的有序的都是指的是有順序的。對于有順序的話,比如排名一類的,就是有序的,但是這個有序的是指按照某種權重進行排序的,而非順序上的有序。
以上是對有序這個詞的討論。
smove:將某個元素從source移動到destination

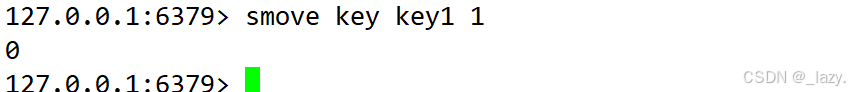
不過要是沒有這個元素,也就返回0了。
srem:將某個元素從key中刪除。

這里的rem代表的意思是remove,即移除的意思,它的返回值的意思是刪除成功的元素的個數。
交集并集差集
對于集合之間的運算涉及到的命令是:sinter,sunion,sdiff,sinterstore,sunionstore,sdiffstore。
sinter:求多個集合的交集
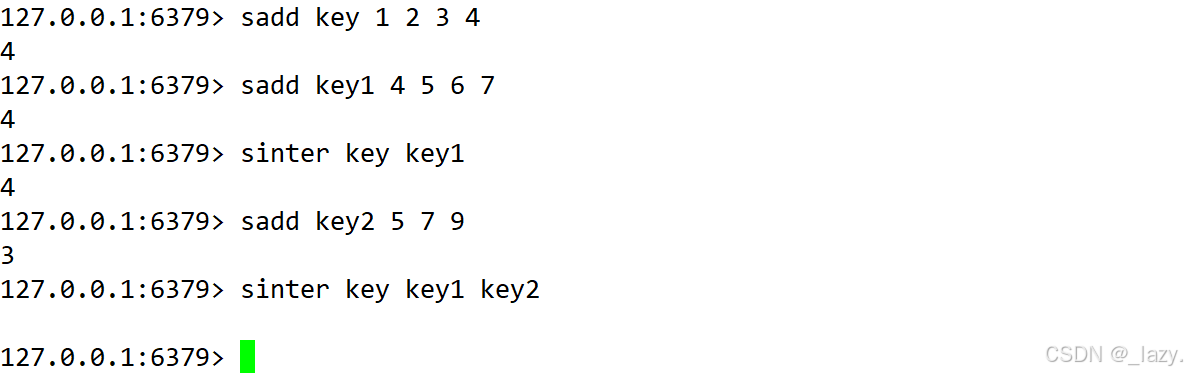
比如sinter key key1就是求兩個key之間的交集,我們也可以求多個,不過我們設置的多個集合之間并沒有交集,所以什么也沒有返回。
sinterstore:求多個集合之間的交集并存在一個集合中

我們倒是發現了一個有意思的點是,key2原本的數據被清空了,只剩下了求完交集之后的元素。以上兩個命令的時間復雜度是O(N*M),N和M分別代表的是最小的集合元素個數和最大的集合元素個數。
sunion,sunionstore:求并集元素(并把并集的元素放在另一個集合中)。

同樣,還是具備清空的效果,那么對于以上兩個命令的時間復雜度是O(N),這個N是總的元素個數。
有意思的是,不管我們如何更換求交集或者并集的set的次序,結果都是不會改變的,而差集不一樣,差集存在一定的次序問題,比如sdiff key1 key2 和sdiff key2 key1之間的結果是不同的,因為差集的定義是key1中有的而key2中沒有的,反過來肯定就不一樣了:

就像這樣。
同理,它的時間復雜度還是O(N),因為要遍歷所有的元素,但是具體怎么實現的,就是Redis內部源碼的實現了,我們后面更新。
以上就是Redis中set的基本命令了。
內部編碼和應用場景
對于set來說,它內部的編碼方式分為了兩種,一種是intset一種是hashtable,如果set內部的元素是整數并且數據個數不多的就是使用的intset,如果是字符串一類的,那么就是hashtable了:

而且我們也能發現,內部編碼方式一旦確定了,也是不太好輕易發生修改的。
它的應用場景的話也是非常顯然的,比如使用QQ的時候,我們經常會收到某某某和你有多少個共同好友,是否加他為好友?這其實就是set求交集的結果,set也可以用來保存用戶的標簽,而用戶的標簽是多樣化的,因為千人千面嘛,所以對于用戶數據來說很多都是公司是共享的,比如A軟件的用戶數據有青年,18歲,喜歡看美女,B軟件的用戶數據有青年,18歲,喜歡跑車,那么就有一種業務是讓兩個公司對接一下用戶數據。
這樣用戶的互聯網畫像也就是越來越完整了。
還有一個非常經典的應用場景是:用Set統計PV和UV數據。同學可自行下來探索~
zset
基本命令
對于zset和set來說,zset的特點是有序的,這里的有序代表的就是用權重來進行排序了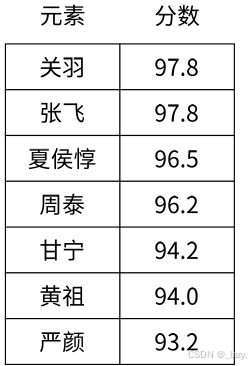
就像這張表一樣,不同的三國猛將用武將值來進行排序,這樣就構成了一個zset,不過因為引入了分數的概念,那么對于zset來說,它的命令操作自然就要復雜的多了。
不過我們首先引入一個問題,因為zset中元素是不允許重復的,分數是可以重復的,如果分數重復了,如何進行排序呢?實際上就按照元素的字典序來進行排序。
既然引入了分數的概念,我們需要認識到一個點是zset存儲的是元素,對于分數來說,它只是一個輔助工具而已。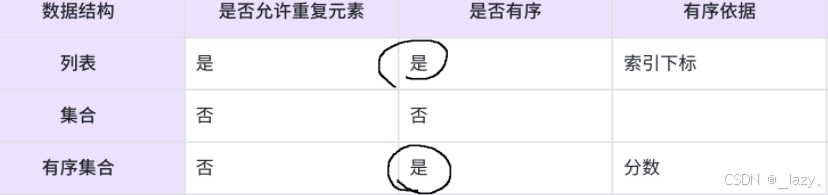
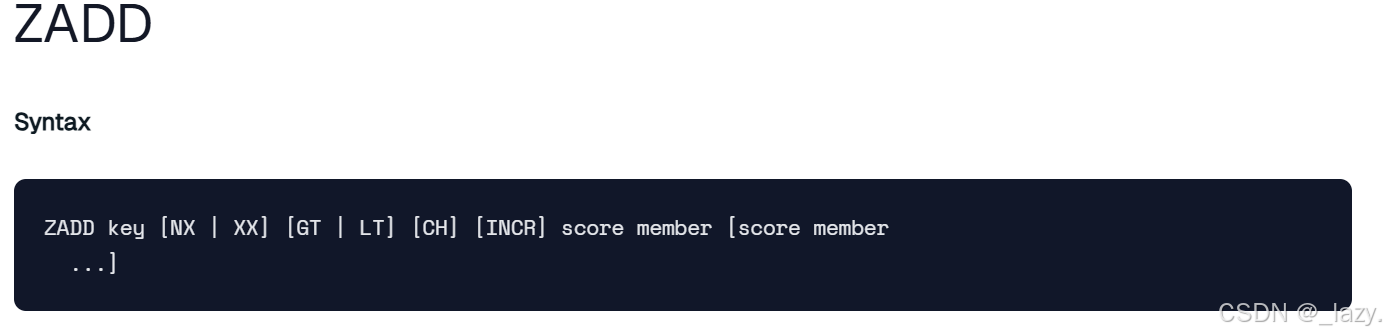
zadd:向集合添加元素,不過這里涉及到了一些選項,比如NX|XX GT|LT INCR等 。
我們一個一個來,先是最普通的應用:
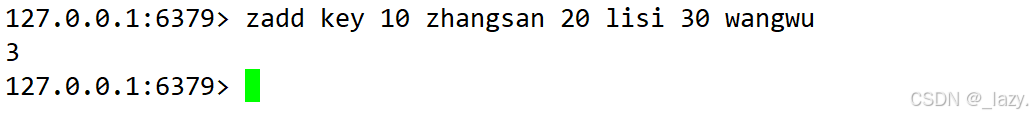

我們插入了之后,可以通過zrange查看,其中如果要帶有分數的查看,就加上withscores就行了,這里默認的是升序,咱們雖然說zset是有序的,有序無非是升序和降序,對于zset來說默認的就是升序了。
對于選項,NX和XX 與之前我們學習string的時候有點差別
string是對key存在性的判斷,zset是對成員存在性的判斷。
因為兩個成員都存在,所以自然就添加失敗,對于XX來說,就更像是一種更新了:
而對于zadd來說它的返回值是新增了的元素個數(并不包括更新的元素)

對于LT和GT官方的描述是這樣的,如果要更新元素,那么LT代表是less than,GT代表的是greater than,如果分數小于原來的就更新或者分數如果大于原來的就更新。

不過不幸的是,GT和LT是6.2之后才有的,我們的版本沒到那里,所以我們先了解一下。
接著是CH,它的作用就是更改返回值,因為zadd的返回值是只返回新增加的元素,對于更新的元素是不管的,那么CH就是加上了更新的元素

最后是incr,它其實就是用來單個增加分數的,和之前的incr hincr沒啥區別:?

它類似的有這個命令
但是zadd已經可以完成了。
這個命令的時間復雜度是logN:
它不像之前的hash list set一樣的時間復雜度為O(1),它因為是有序的,并且要找到對應的位置,所以在它內部實現的時候,使用跳表利用有序的特點找到對應的位置。
zcard:查看集合中的所有元素

返回值是有幾個元素。
但是因為引入了分數的概念,所以我們也可以使用zcount指定區間查看對應的元素個數:
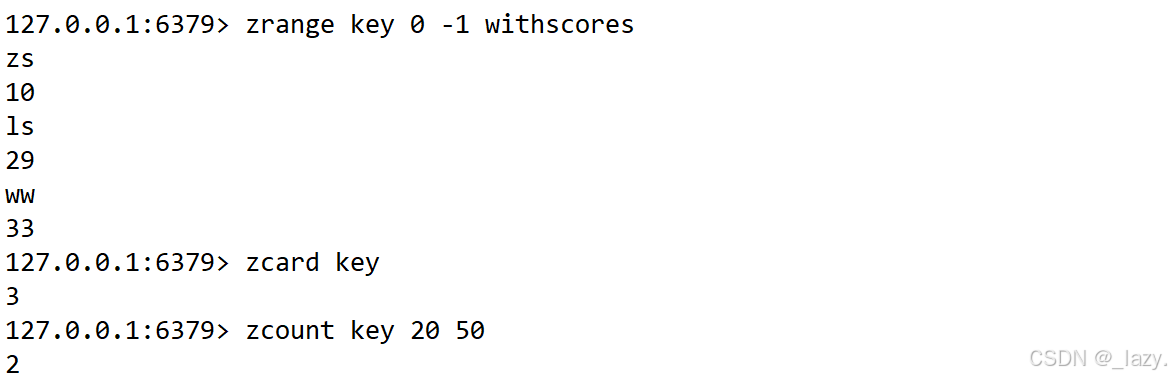
那么我們想用zcount實現成zcard的效果,我們就可以: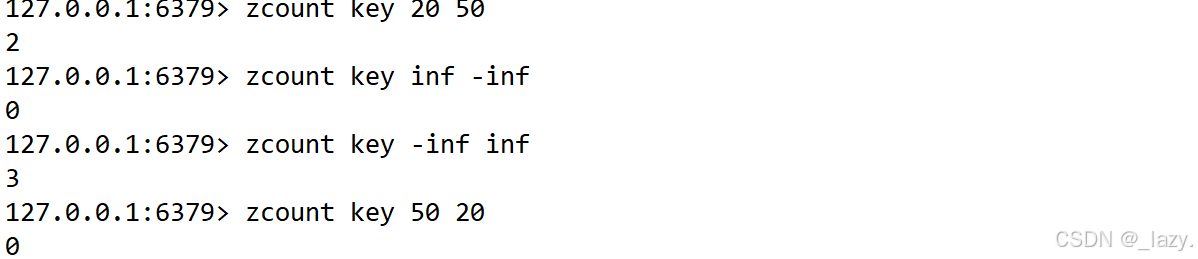
使用inf,inf代表的是無窮大,那么我們指定閉區間為負無窮大到無窮大,就可以完成所有元素的遍歷。
它的時間復雜度是O(logN)其中主要是為了找到Min和max對應的位置,然后因為zset內部會記錄每個元素當前的次序,找到了之后做個減法,就可以得到對應的結果了。
不過這里有一個比較反人類的設定,如果我們想要設置為開區間,就在想要設置為開區間的元素前面加一個(即可:
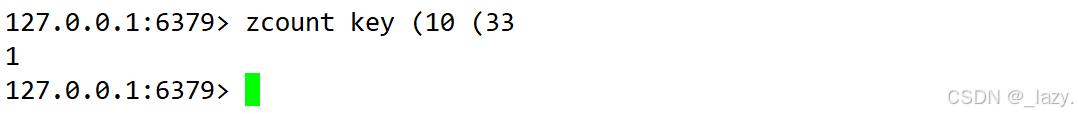
zrevrange:逆序遍歷,這個是對上面zrange的補充。

但是對應的索引是不變的。
既然我們可以通過索引來查看元素,我們是否也可以通過分數來查看呢?
使用命令zrangebyscore即可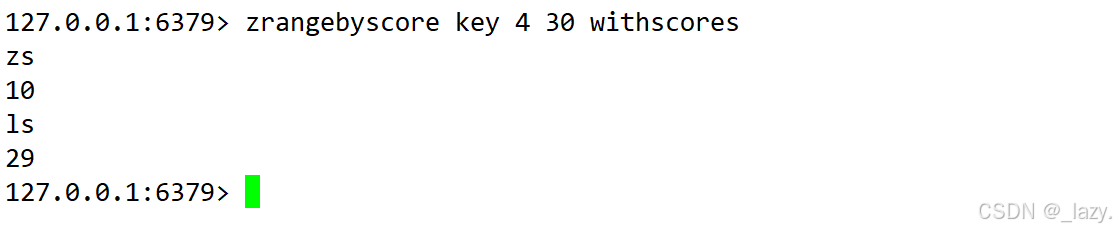
zpopmax:刪除最高分數的count個元素
首先我們先記住,它的時間復雜度是O(M * logN),其中N是key中的總元素,M是count的,我們有基礎的話,很難不去想對于刪除一個有序的特殊位置,比如尾部,它的時間復雜度是logN而不是O(1),這就讓人有點疑惑了,因為按照Redis的技術是完全可以的,但是咱也不知道為啥沒有優化,可能是技術人員認為優化這里完全沒有必要,因為LogN已經很快了,所以在zpopmax的內部還是調用的通用的刪除函數:
Bzpopmax:按照阻塞的方式刪除最高分數的count個元素

和前面學習的blpop一摸一樣的,它也是能夠一次性檢測多個key。它的時間復雜度是O(M * logN),這個M不是監測了幾個key的M,而是在key上刪除了元素的key個數。
zpopmin和bzpopmin:(按照阻塞的方式)刪除最低分數的count個元素,因為用法幾乎是一樣的,所以咱在這里啊 也就不演示了。
zrank和zrevrank:從前往后(從后往前)計算對應的排名,對應的時間復雜度是O(logN)
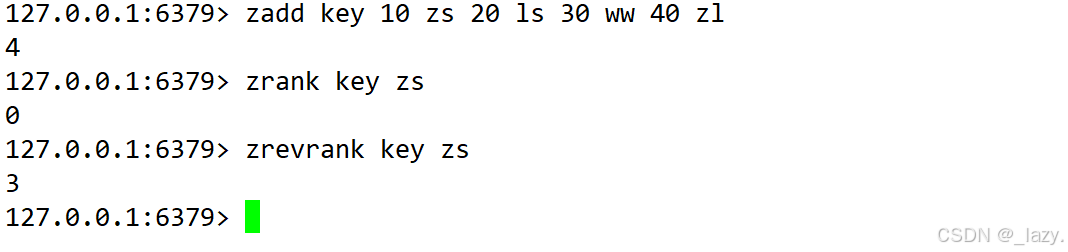
zscore:返回對應member的分數,時間復雜度是O(1),這里的話就是Redis針對進行特殊的優化的,是采取了空間換時間的做法

zrem和zremrangebyrank:(根據排名)刪除元素


有趣的是,根據排名的時候是可以使用負數的,-1代表的就是最后一名,不過用法還是從前往后的,時間復雜度是logN + M,其中N是成員總數,M是區間個數。
zincrby:調整某個元素的分數

但是改變了分數之后,整體還是會保持升序的。
交集并集差集
這里涉及到的命令有:zunion,zinter,zdiff,不過這三個命令都是6.2版本才開始支持,我們這里就暫時不討論,我們這里討論兩個命令,一個是zinterstore,一個是zunionstore。

destination代表的存儲到這個key里面,numbers代表的是有幾個集合參與運算,weights代表的是權重,雖然說是不同的key進行運算,但是根據實際情況不同的key自己的份量不同,所以運算的時候分數會乘上我們給定的權重,然后就是合并的時候,是總和呢還是最小的還是最大的,就是最后一個參數了,默認是按照總和。
這里使用到了numkeys來指定集合數,就非常像我們之前學習http的時候,報頭里面有一個字段是正文部分的長度,如果這里出現了問題,就會導致粘包問題。


就像這樣。
主要涉及到的還是score的計算,那你說,zunionstore的使用是不是一樣的?完全一樣嘛,所以這里就不演示了。
內部編碼和應用場景
它的內部編碼方式有ziplist和skiplist,如果元素較少,單個元素體積小,就使用ziplist,反之就使用skiplist,不過對于這里的ziplist還是使用的空間換取時間的做法,自然就不敢元素多了還用ziplist了。
明白啦,下面是為博客撰寫的純文字版內容,格式整潔、內容完整,可直接復制粘貼上傳到博客平臺(如 CSDN、掘金、個人博客等):
應用場景(AI生成)
排行榜系統
應用背景
排行榜常用于游戲、競賽、學習平臺等系統中,主要用來展示用戶在某項指標上的相對排名,例如積分榜、活躍度榜、勝率榜等。系統要求能夠快速地更新用戶得分、獲取前幾名用戶,以及查詢某個用戶的實時排名。
設計思路
在排行榜中,每個用戶對應一個唯一標識(如用戶 ID),而其得分則用于排序依據。Redis 的有序集合能夠很好地完成這項任務。它會根據用戶得分自動維持從低到高的順序,同時支持查詢、更新、分頁等操作。
為了方便擴展,不同類型的排行榜可以用不同的 key 名進行管理,比如設置日榜、周榜、總榜等。
熱榜系統
應用背景
在內容平臺或社區系統中,文章、帖子或視頻的“熱度”是衡量內容受歡迎程度的重要指標。平臺通常會根據內容的瀏覽量、點贊數、評論量等因素,計算一個熱度得分,并據此展示熱門內容排行榜。
與普通排行榜不同,文章熱度往往涉及多維因素,還可能加入時間衰減,以保持榜單的新鮮感,避免長期霸榜。
設計思路
在 Redis 中,可以將每篇文章的唯一標識作為 ZSet 成員,將計算后的熱度值作為排序依據。每當文章發生交互行為時(例如點贊、被瀏覽、被評論等),系統即可對其熱度進行更新。
為了支持多分類內容推薦,也可以為不同的內容類別創建獨立的熱度榜,例如科技類、娛樂類、教育類等,每個分類對應一個有序集合。
熱度計算方式
熱度得分通常不是單一數據,而是由多個指標加權計算而來。例如,可以設定一個公式,綜合點擊量、點贊量、評論量等數據;還可以為舊文章引入時間衰減機制,防止內容因早期流量過大而長期占據榜單。
最終熱度值由業務邏輯層計算完成,再寫入 Redis 中的有序集合。
總結對比表
| 功能需求 | 排行榜系統 | 文章熱度榜 |
|---|---|---|
| 目標成員 | 用戶 ID | 文章 ID |
| 分數含義 | 積分、活躍度 | 熱度(閱讀、點贊等加權計算) |
| 更新頻率 | 實時(如游戲加分) | 實時或周期更新(如點贊、點擊) |
| 查詢方式 | Top N、用戶排名、分頁 | 熱榜分頁、熱度值查詢 |
| 清理策略 | 刪除低排名用戶,節省空間 | 刪除冷文章,保持熱榜實時性 |
感謝閱讀!

)











)



)
:定義、發展、構建與應用)
