提升自己,掌握數據分析的能力,最快的方式就是實踐!
下面是對本項目的一些功能展示、介紹以及部分核心代碼的展示,附項目系統展示的視頻,制作不易如需完整代碼后臺私信我有償獲取!
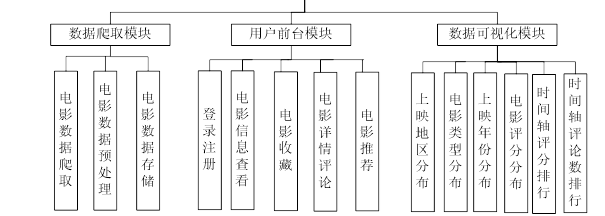
一 、系統分析及功能介紹
1.系統分析
系統采用Python作為開發語言,擁有豐富的庫和強大的生態系統。Flask框架輕量級且靈活,易于構建Web應用,處理用戶請求和業務邏輯。協同過濾推薦算法有成熟理論,借助Python相關庫能高效實現個性化推薦。ECharts可實現數據可視化,其豐富的圖表類型和良好的交互性,能滿足多種數據展示需求。
2.功能介紹
(1)用戶功能
登錄/注冊:用戶需通過注冊賬號并登錄系統才能訪問個性化功能。系統應提供簡便的注冊和登錄流程,并確保用戶信息的安全性。
電影信息查看:用戶能夠瀏覽系統中各類電影的信息,包括電影海報、基本介紹和評分等。提供簡單易用的搜索和篩選功能,以幫助用戶快速找到感興趣的電影。
電影收藏:用戶可以將喜歡的電影添加到個人收藏列表中,以便于日后查看和管理。系統需支持對收藏列表的增刪改查操作。
電影詳情評論:用戶可以查看每部電影的詳細信息和其他用戶的評論,系統還應提供發表評論的功能,提升互動性和用戶參與感。
電影推薦:系統將基于用戶的歷史觀看記錄和偏好,提供個性化的電影推薦,幫助用戶發現新電影,提升用戶的觀影體驗。
(2)數據可視化功能
上映地區分布:系統可以通過地圖或圖表形式顯示電影在不同地區的上映情況,幫助用戶了解電影的地域分布。
電影類型分布:展示不同類型電影的數量和比例,讓用戶能夠更好地了解市場趨勢及觀眾偏好。
上映年份分布:通過時間軸或柱狀圖展示不同年份上映電影的數量,分析電影行業的變化和發展趨勢。
電影評分分布:系統應展示電影評分的分布情況,幫助用戶了解不同評分段電影的數量,提供更全面的參考。
時間軸評分排行:對電影進行時間軸評分排行,便于用戶快速獲取評分變化的趨勢,了解新舊電影的受歡迎程度。
時間軸評論數排行:展示各電影在不同時間段的評論數變化,幫助分析用戶互動的活躍度和受歡迎程度,為后續的市場分析提供數據支持。
(3)管理員功能
?登錄:管理員通過專屬的登錄頁面進行登錄,輸入正確的用戶名和密碼后成功登錄進入后臺管理頁面。
用戶管理:管理員能夠查看用戶信息,并且能夠對用戶進行添加以及刪除操作。
電影管理:管理員能夠查看所有的電影數據以及對電影數據進行添加以及刪除操作。
留言管理:管理員能夠查看用戶的留言記錄,并且能夠對留言記錄進行添加以及刪除操作。
二、 系統功能詳細設計
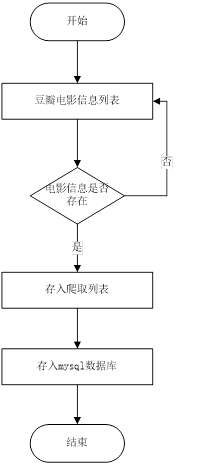
1.數據爬取
利用Python的Requests庫編寫網絡爬蟲代碼,對豆瓣電影數據展開爬取。向豆瓣電影返回數據的接口發起請求,請求時帶上請求頭信息和隨機IP。把返回的結果加載成json格式,再用with open語句將結果寫入文件。
此數據爬取功能可采集豆瓣電影網站的電影數據,涵蓋主演信息、上映日期、電影id、電影url地址、海報圖片、上映地區、評分、電影簡介、電影名稱、電影類型等字段。管理員在后臺運行特定腳本文件來觸發數據采集操作。系統運用Python語言,結合網絡爬蟲框架進行數據抓取與存儲,同時記錄相關日志信息,以此保障數據的準確性和完整性,為后續的電影個性化推薦系統提供數據支撐。
2.系統流程設計
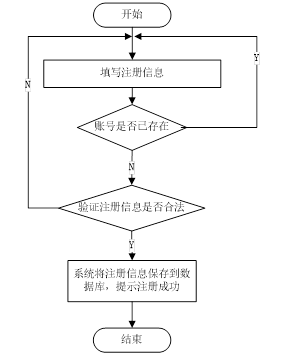
用戶注冊過程在系統里是極為關鍵且不可或缺的步驟。用戶通過注冊,能夠獲取登錄系統所必需的賬號與密碼,并且填寫一些必要的個人信息,這樣系統就能更精準地為用戶提供個性化服務。要是用戶還沒有注冊賬號,系統就會提醒用戶去進行注冊。
注冊流程具體包含填寫賬號、密碼以及其他必要信息。一旦用戶填寫的用戶名已經存在于系統中,系統會馬上提示用戶該用戶名已被占用,同時要求用戶重新填寫。當用戶完成注冊流程中的所有步驟后,就能夠成功注冊。
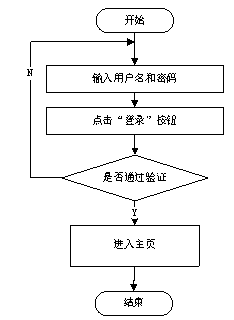
對于已經注冊的用戶,他們可以直接依照既定流程進行登錄操作。
用戶登錄是系統中必不可少的環節,通過登錄驗證用戶身份,同時也為系統管理員提供了登錄用戶相關信息的來源,為系統數據分析提供了基礎數據。用戶在登錄過程中需在相應窗口輸入賬號、密碼以及正確的驗證碼,系統將驗證用戶輸入信息的正確性,若驗證通過,則用戶可以成功登錄系統。
3.推薦模塊設計
本模塊主要功能是根據用戶歷史行為數據分析結果,結合協同過濾算法進行個性化、精準化的電影推薦。
系統讀取用戶收藏信息,并將其轉化為相應的文件格式,再將其存儲到相應的數據庫表,生成推薦模型,推薦模型根據用戶評分以及收來對每部電影進行排序,然后優先將符合用戶喜好的電影加入推薦表中,進行可視化展示。
在實現電影推薦的過程中,重點在于評估系統里不同用戶之間的關聯相似度。本研究把用戶的收藏行為當作衡量標準,要是兩個用戶的收藏行為相近,那就表明他們對某些電影有著相似的興趣。
就拿用戶1001和用戶1002來說,這里設定N(1001)代表用戶1001曾經收藏過的電影集合,N(1002)代表用戶1002曾經收藏過的電影集合。運用Jaccard相似度公式來計算用戶1001和用戶1002之間的興趣相似度。通過計算Jaccard相似度,就可以得出用戶1001和用戶1002之間的相似度數值。相似度值越高,意味著這兩個用戶對電影的興趣越相似,則給用戶1001推薦用戶1002喜歡的電影,反過來也是同樣的道理。

三、項目功能圖片展示
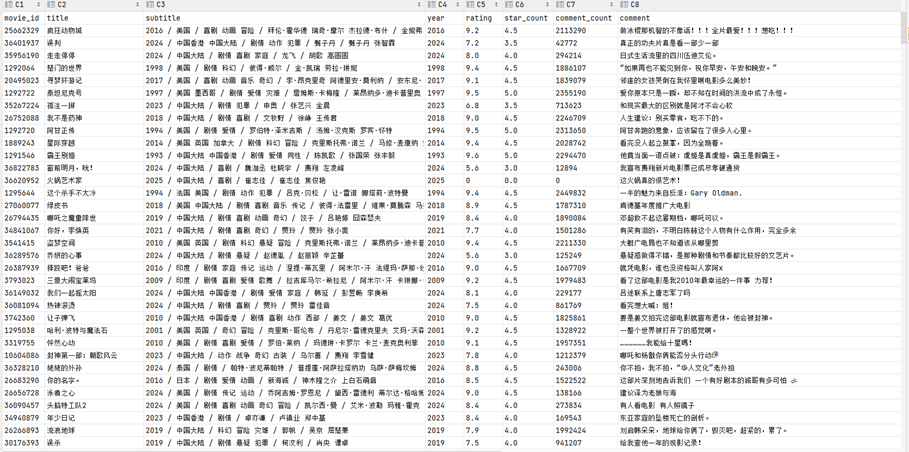
數據爬取結果展示 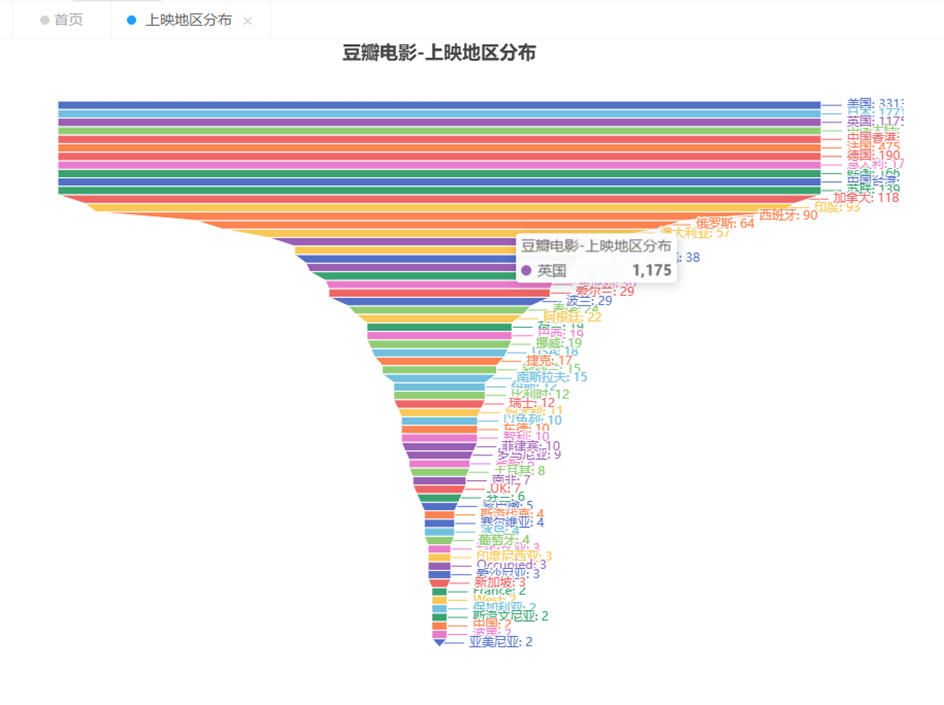
可視化部分展示
四、部分核心代碼展示
1.數據爬取模塊
import csv
import json
import os
import random
import timeimport requestsheaders = {"accept": "application/json, text/plain, */*","accept-language": "zh-CN,zh;q=0.9","origin": "https://movie.douban.com","priority": "u=1, i","referer": "https://movie.douban.com/explore","sec-ch-ua": "\"Not A(Brand\";v=\"8\", \"Chromium\";v=\"132\", \"Google Chrome\";v=\"132\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","sec-fetch-dest": "empty","sec-fetch-mode": "cors","sec-fetch-site": "same-site","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36"
}
cookies = {"bid": "aSEkw2BmMy0","ll": "\"118163\"","douban-fav-remind": "1","_ga_RXNMP372GL": "GS1.1.1726020007.1.1.1726020014.53.0.0","_vwo_uuid_v2": "D198CDC8B0A44076199DA8D05449AF077|3e376f7533096e5b359997a603c09ab0","_ga": "GA1.2.1806896010.1723441748","_ga_PRH9EWN86K": "GS1.2.1734079184.1.0.1734079184.0.0.0","viewed": "\"33474750_37093283_25888061_36999799\"","dbcl2": "\"279168322:XDbIgnxunIQ\"","push_noty_num": "0","push_doumail_num": "0","__utmv": "30149280.27916","ck": "_Dv9","ap_v": "0,6.0","__utma": "30149280.1806896010.1723441748.1736760449.1737437299.5","__utmb": "30149280.0.10.1737437299","__utmc": "30149280","__utmz": "30149280.1737437299.5.5.utmcsr=baidu|utmccn=(organic)|utmcmd=organic","frodotk_db": "\"ba3b2147d5f487f62eb163d781dd97e2\""
}def spider(tags, p):# 定義請求的urlurl = "https://m.douban.com/rexxar/api/v2/movie/recommend"# 使用 format 方法填充 tagsselected_categories = '{{"類型":"{}"}}'.format(tags)# 定義請求參數params = {"refresh": "0","start": f"{p}","count": "20","selected_categories": selected_categories,"uncollect": "false","sort": "S","tags": f"{tags}","ck": "_Dv9"}#發送 HTTP GET 請求response = requests.get(url, headers=headers, cookies=cookies, params=params)print(response.text)# 解析JSON數據data = json.loads(response.text)# 提取電影信息列表feeds = data['items']# CSV文件路徑csv_file_path = 'movies.csv'# 檢查文件是否存在file_exists = os.path.exists(csv_file_path)# 打開文件以追加模式寫入數據with open(csv_file_path, mode='a', encoding='utf-8', newline='') as csvfile:# 定義CSV列名# fieldnames = ['電影ID', '標題', '副標題', '年份', '評分', '星級人數', '評論數', '評論', '海報', '用戶頭像', '用戶名', '排名']fieldnames = ['movie_id', 'title', 'subtitle', 'year', 'rating', 'star_count', 'comment_count', 'comment','poster', 'user_avatar', 'user_name', 'rank']# 創建CSV寫入對象writer = csv.DictWriter(csvfile, fieldnames=fieldnames)# 如果文件不存在,寫入表頭if not file_exists:writer.writeheader()# 寫入每個電影的詳細信息for feed in feeds:try:movie_data = {'movie_id': feed['id'],'title': feed['title'],'subtitle': feed['card_subtitle'],'year': feed['year'],'rating': feed['rating']['value'],'star_count': feed['rating']['star_count'],'comment_count': feed['rating']['count'],'comment': feed['comment']['comment'],'poster': feed['pic']['large'],'user_avatar': feed['comment']['user']['avatar'],'user_name': feed['comment']['user']['name'],'rank': feed['honor_infos'][0]['rank'] if feed['honor_infos'] else None # 確保有榮譽信息}print(movie_data)writer.writerow(movie_data) # 寫入行except:continue# 定義電影類型列表并循環爬取
tags_list = ['動作', '科幻', '動畫', '懸疑', '犯罪', '驚悚', '冒險', '音樂', '歷史', '奇幻', '恐怖', '戰爭', '傳記', '歌舞', '武俠', '情色', '災難', '西部','紀錄片', '短片']
for tags in tags_list:for p in range(1, 30):print(f'第{p}頁爬取中')# 計算請求的起始位置p = p * 20# 調用 spider 函數進行爬取spider(tags, p)# 隨機暫停 1 - 5 秒time.sleep(random.randint(1, 5))
2.數據清洗模塊
import pandas as pd# 讀取CSV文件
df = pd.read_csv('movies.csv',names=['電影ID', '標題', '副標題', '年份', '評分', '星級人數', '評論數', '評論', '海報', '用戶頭像', '用戶名', '排名'], skiprows=1)# 拆分副標題為多個列
subtitle_split = df['副標題'].str.split(' / ', expand=True)# 檢查拆分后的列數量
n_columns = subtitle_split.shape[1]if n_columns == 5:# 如果有5列,將第四列和第五列合并成一個列subtitle_split[3] = subtitle_split[3] + ' / ' + subtitle_split[4] # 合并第四和第五列subtitle_split = subtitle_split.drop(columns=[4]) # 刪除原來的第五列
elif n_columns > 5:# 如果大于5列,將第四列和第五列以后的所有列合并為一個列subtitle_split[3] = subtitle_split.iloc[:, 4:].apply(lambda row: ' / '.join(row.dropna()), axis=1) # 合并第四列及以后的列subtitle_split = subtitle_split.iloc[:, :4] # 只保留前4列# 重命名列
subtitle_split.columns = ['發布年份', '發布地區', '電影類型', '主演'] # 這里定義 "主演" 列# 將拆分后的列加入到原DataFrame
df = pd.concat([df, subtitle_split], axis=1)# 刪除原副標題列
df.drop(columns=['副標題'], inplace=True)
df['主演'] = df['主演'].replace('/', '', regex=True)
df['發布地區'] = df['發布地區'].str.split(' ').str[0]
df['電影類型'] = df['電影類型'].str.split(' ').str[0]
df['排名'] = df['排名'].fillna('0')
# 保存處理后的DataFrame
df.to_csv('clean.csv', index=False, encoding='utf-8-sig')
?3.數據分析模塊
from collections import Counterimport jieba
import pandas as pd
import pymysqlconn = pymysql.connect(host='localhost',user='root',password='123456',db='hot_movie_analysis',charset='utf8mb4'
)
cursor = conn.cursor()df = pd.read_csv('clean.csv')
df = df.drop_duplicates(subset=['標題'])def part1():# 首先去除空值df['主演'] = df['主演'].replace('', None) # 將空字符串替換為 None# 提取每個演員并統計出現次數actor_counts = df['主演'].dropna().str.split(' ').explode().value_counts() # 使用 dropna() 去掉空值# 將結果轉換為 DataFrameactor_counts_df = actor_counts.reset_index()actor_counts_df.columns = ['演員', '出現次數'] # 重命名列# 移除演員列為空的行actor_counts_df = actor_counts_df[actor_counts_df['演員'].str.strip() != '']print(actor_counts_df)truncate_sql = 'truncate table part1'cursor.execute(truncate_sql)conn.commit()sql = 'insert into part1(name,value) values(%s,%s)'for index, row in actor_counts_df.iterrows():cursor.execute(sql, (row['演員'], row['出現次數']))conn.commit()def part2():# 首先去除空值df['主演'] = df['主演'].replace('', None) # 將空字符串替換為 None# 創建一個列表用于存儲演員和相關評論數actor_comments_list = []# 確保評論數是數值類型df['評論數'] = pd.to_numeric(df['評論數'], errors='coerce') # 將評論數轉換為數值類型,無法轉換的將變為 NaN# 提取每個演員和對應的評論數for index, row in df.iterrows():# 檢查主演是否為 NaNif pd.notna(row['主演']):actors = row['主演'].split(' ')comments_count = row['評論數']for actor in actors:if actor.strip(): # 確保演員名稱不是空的actor_comments_list.append({'演員': actor.strip(), '評論數': comments_count})# 將列表轉換為 DataFrameactor_comments = pd.DataFrame(actor_comments_list)# 計算每個演員的平均評論數average_comments = actor_comments.groupby('演員')['評論數'].mean().reset_index().sort_values(by='評論數',ascending=False).head(10)average_comments.columns = ['演員', '平均評論數'] # 重命名列# 輸出結果print(average_comments)truncate_sql = 'truncate table part2'cursor.execute(truncate_sql)conn.commit()sql = 'insert into part2(name,value) values(%s,%s)'for index, row in average_comments.iterrows():cursor.execute(sql, (row['演員'], row['平均評論數']))conn.commit()def part3():# 確保年份列是數值類型df['年份'] = pd.to_numeric(df['年份'], errors='coerce')# 確保評論數是數值類型df['評論數'] = pd.to_numeric(df['評論數'], errors='coerce')# 計算不同年份的平均評論數average_comments_by_year = df.groupby('年份')['評論數'].mean().reset_index()# 重命名列average_comments_by_year.columns = ['年份', '平均評論數']# 輸出結果print(average_comments_by_year)truncate_sql = 'truncate table part3'cursor.execute(truncate_sql)conn.commit()sql = 'insert into part3(name,value) values(%s,%s)'for index, row in average_comments_by_year.iterrows():cursor.execute(sql, (row['年份'], row['平均評論數']))conn.commit()def part4():global df# 確保評論數是數值類型df['評論數'] = pd.to_numeric(df['評論數'], errors='coerce') # 將評論數轉換為數值類型,無法轉換的將變為 NaN# 按評論數排序,選擇前20個top_20_movies = df.sort_values(by='評論數', ascending=False).head(30)# 選擇需要的列進行展示top_20_movies_summary = top_20_movies[['標題', '年份', '評分', '評論數', '主演']]# 輸出結果print(top_20_movies_summary)truncate_sql = 'truncate table part4'cursor.execute(truncate_sql)conn.commit()sql = 'insert into part4(name,value) values(%s,%s)'for index, row in top_20_movies_summary.iterrows():cursor.execute(sql, (row['標題'], row['評論數']))conn.commit()def load_stopwords(file_path):"""加載停用詞文件,確保使用 UTF-8 編碼"""with open(file_path, 'r', encoding='utf-8') as f:stopwords = set(f.read().strip().splitlines())return stopwordsdef part5():# 加載停用詞stopwords = load_stopwords('stopwords.txt')comments = df['評論'].tolist()# 分詞并過濾停用詞word_list = []for comment in comments:words = (word for word in jieba.cut(comment) if word not in stopwords and word.strip())word_list.extend(words)# 統計詞頻word_counts = Counter(word_list)# 轉換為 DataFrame 以便更好地查看結果word_freq_df = pd.DataFrame(word_counts.items(), columns=['詞語', '出現次數'])# 按出現次數排序word_freq_df = word_freq_df.sort_values(by='出現次數', ascending=False)# 輸出結果print(word_freq_df)truncate_sql = 'truncate table part5'cursor.execute(truncate_sql)conn.commit()sql = 'insert into part5(name,value) values(%s,%s)'for index, row in word_freq_df.iterrows():cursor.execute(sql, (row['詞語'], row['出現次數']))conn.commit()if __name__ == "__main__":# part1()# part2()# part3()# part4()part5()
4.電影推薦模塊
# coding = utf-8# 推薦算法實現
import csv
import pymysql
import math
from operator import itemgetterclass UserBasedCF():# 初始化相關參數def __init__(self):# 找到與目標用戶興趣相似的3個用戶,為其推薦5部電影self.n_sim_user = 5self.n_rec_movie = 6self.dataSet = {}# 用戶相似度矩陣self.user_sim_matrix = {}self.movie_count = 0print('Similar user number = %d' % self.n_sim_user)print('Recommneded movie number = %d' % self.n_rec_movie)# 讀文件得到“用戶-電影”數據def get_dataset(self, filename, pivot=0.75):dataSet_len = 0for line in self.load_file(filename):movie, user, rating = line.split(',')# print(type(movie), type(user), type(rating))# if random.random() < pivot:self.dataSet.setdefault(int(user), {})self.dataSet[int(user)][int(movie)] = ratingprint(self.dataSet)dataSet_len += 1# else:# self.testSet.setdefault(user, {})# self.testSet[user][movie] = rating# testSet_len += 1print('Split trainingSet and testSet success!')print('dataSet = %s' % dataSet_len)# 讀文件,返回文件的每一行def load_file(self, filename):with open(filename, 'r') as f:for i, line in enumerate(f):if i == 0: # 去掉文件第一行的titlecontinueyield line.strip('\r\n')print('Load %s success!' % filename)# 計算用戶之間的相似度def calc_user_sim(self):# 構建“電影-用戶”倒排索引# key = movieID, value = list of userIDs who have seen this movieprint('Building movie-user table ...')movie_user = {}for user, movies in self.dataSet.items():for movie in movies:if movie not in movie_user:movie_user[movie] = set()movie_user[movie].add(user)print('Build movie-user table success!')self.movie_count = len(movie_user)print('Total movie number = %d' % self.movie_count)print('Build user co-rated movies matrix ...')for movie, users in movie_user.items():for u in users:for v in users:# if u == v:# continueself.user_sim_matrix.setdefault(u, {})self.user_sim_matrix[u].setdefault(v, 0)self.user_sim_matrix[u][v] += 1# print(self.user_sim_matrix)print('Build user co-rated movies matrix success!')# 計算相似性print('Calculating user similarity matrix ...')for u, related_users in self.user_sim_matrix.items():for v, count in related_users.items():self.user_sim_matrix[u][v] = count / math.sqrt(len(self.dataSet[u]) * len(self.dataSet[v]))print('Calculate user similarity matrix success!')# 針對目標用戶U,找到其最相似的K個用戶,產生N個推薦def recommend(self, user):K = self.n_sim_userN = self.n_rec_movierank = {}# print(user)watched_movies = self.dataSet[user]# print('user',type(user))# print('111',self.user_sim_matrix)# v=similar user, wuv=similar factorfor v, wuv in sorted(self.user_sim_matrix[user].items(), key=itemgetter(1), reverse=True)[0:K]:for movie in self.dataSet[v]:if movie in watched_movies:continuerank.setdefault(movie, 0)rank[movie] += wuvreturn sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]# 產生推薦并通過準確率、召回率和覆蓋率進行評估def evaluate(self):print("Evaluation start ...")N = self.n_rec_movie# 準確率和召回率hit = 0rec_count = 0test_count = 0# 覆蓋率all_rec_movies = set()# 打開數據庫連接db = pymysql.connect(host='localhost', user='root', password='123456', database='hot_movie_analysis',charset='utf8')cursor = db.cursor()# 使用 execute() 方法執行 SQL 查詢sql1 = "truncate table rec;"cursor.execute(sql1)db.commit()sql = "insert into rec (user_id,movie_id,rating ) values (%s,%s,%s)"print(self.dataSet)for i, user, in enumerate(self.dataSet):print(user, i)rec_movies = self.recommend(int(user))print(user, rec_movies)for item in rec_movies:data = (user, item[0], item[1])cursor.execute(sql, data)db.commit()# rec_movies 是推薦后的數據# 把user-rec-rating 存到數據庫cursor.close()db.close()if __name__ == '__main__':db = pymysql.connect(host='localhost', user='root', password='123456', database='hot_movie_analysis',charset='utf8')cursor = db.cursor()# 使用 execute() 方法執行 SQL 查詢sql = "select * from user_movie"cursor.execute(sql)data = cursor.fetchall()cursor.close()db.close()with open('rating.csv', 'w', encoding='utf-8', newline='') as f:writer = csv.writer(f)writer.writerow(['movie_id', 'user_id', 'rating'])for item in data:writer.writerow([item[2], item[1], 1])rating_file = 'rating.csv'userCF = UserBasedCF()userCF.get_dataset(rating_file)userCF.calc_user_sim()userCF.evaluate()
到這里這個電影推薦數據分析可視化系統的介紹就結束了,本文章附帶了項目系統展示視頻,可以自行查看,本項目可以當做技術訓練進階以及畢業設計項目進行學習和使用,有需要完整代碼的可以后臺私信我有償獲取(#^.^#)!
????????


(詳細示例))
)
- 使用vscode遠程連接泰山派進行開發)






區別和globalPos區別)

)

)

)

