一 數據庫操作
Hive數據庫操作,與MySql有很多都是一致的
創建數據庫
create database if not exists myhive;
use myhive;
查看數據庫詳細信息
desc database myhive;

數據庫本質上就是在HDFS之上的文件夾,是一個以.db結尾的目錄,默認存儲在:/user/hive/warehouse內,可以通過LOCATION關鍵字在創建的時候指定存儲目錄。
創建數據庫并指定hdfs存儲位置
create database myhive2 location '/myhive2';
使用location關鍵字,可以指定數據庫在HDFS的存儲路徑。
刪除一個空數據庫,如果數據庫下面有數據表,那么就會報錯
drop database myhive;
強制刪除數據庫,包含數據庫下面的表一起刪除
drop database myhive2 cascade;
二 表操作
2.1 基本語法
創建數據庫表語法
創建表的語法還是比較復雜的
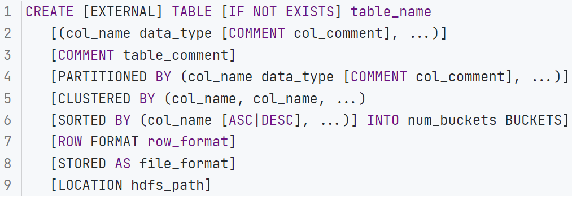
- EXTERNAL,創建外部表
- PARTITIONED BY, 分區表
- CLUSTERED BY,分桶表
- STORED AS,存儲格式
- LOCATION,存儲位置
數據類型
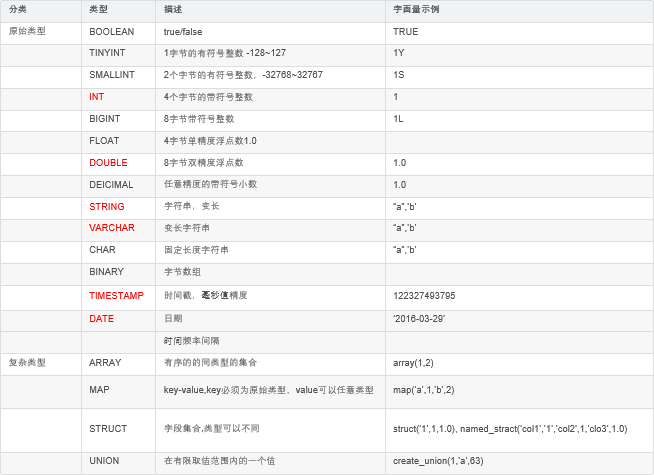
Hive中支持的數據類型還是比較多的,其中紅色的是使用比較多的類型。
基礎創建表示意
盡管建表語法比較復雜,目前我們暫時未接觸到分區、分桶等概念。所以,創建一個簡單的數據庫表可以有如下SQL:
CREATE TABLE test(id INT,name STRING,gender STRING
);
刪除表
如果要刪除表可以使用:
DROP TABLE table_name;
2.2 表分類
Hive中可以創建的表有好幾種類型, 分別是:
- 內部表
- 外部表
- 分區表
- 分桶表
不同類型的表有各自的用途。我們首先學習內部表和外部表的區別。
內部表和外部表
內部表(CREATE TABLE table_name …)
未被external關鍵字修飾的表就是內部表, 即普通表。 內部表又稱管理表,內部表數據存儲的位置由hive.metastore.warehouse.dir參數決定(默認:/user/hive/warehouse),刪除內部表會直接刪除元數據(metadata)及存儲數據,因此內部表不適合和其他工具共享數據。
外部表(CREATE EXTERNAL TABLE table_name …LOCATION…)
被external關鍵字修飾的就是外部表, 即關聯表。外部表是指表數據可以在任何位置,通過LOCATION關鍵字指定。 數據存儲的不同也代表了這個表在理念上并不是Hive內部管理的,而是可以隨意臨時鏈接到外部數據上的。
所以,在刪除外部表的時候, 僅僅是刪除元數據(表的信息),不會刪除數據本身。
快速對比一下內部表和外部表

2.2.1 內部表
創建內部表
內部表的創建語法就是標準的:CREATE TABLE table_name......
創建一個基礎的表:
create database if not exists myhive;
use myhive;
create table if not exists stu(id int,name string);
insert into stu values (1,"zhangsan"), (2, "wangwu");
select * from stu;
查看表的數據存儲
在HDFS上,查看表的數據存儲文件

可以看到,數據在HDFS上也是以明文文件存在的。奇怪的是, 列ID和列NAME,好像沒有分隔符,而是擠在一起的。這是因為,默認的數據分隔符是:”\001”是一種特殊字符,是ASCII值,鍵盤是打不出來的,在某些文本編輯器中是顯示為SOH的。
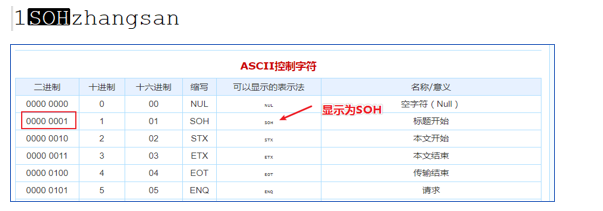
當然,分隔符我們是可以自行指定的。在創建表的時候可以自己決定:
create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t';
- row format delimited fields terminated by ‘\t’:表示以\t分隔

其它創建內部表的形式
除了標準的CREATE TABLE table_name的形式創建內部表外,我們還可以通過:
- CREATE TABLE table_name as,基于查詢結果建表
create table stu3 as select * from stu2;
- CREATE TABLE table_name like,基于已存在的表結構建表
create table stu4 like stu2;
- 也可以使用DESC FORMATTED table_name,查看表類型和詳情
DESC FORMATTED stu2;
刪除內部表
我們是內部表,刪除后,數據本身也不會保留,讓我們試一試吧。
DROP TABLE table_name,刪除表
drop table stu2;

可以看到,stu2文件夾已經不存在了,數據被刪除了。
2.2.2 外部表
外部表的創建

外部表,創建表被EXTERNAL關鍵字修飾,從概念是被認為并非Hive擁有的表,只是臨時關聯數據去使用。
創建外部表也很簡單,基于外部表的特性,可以總結出: 外部表 和 數據 是相互獨立的, 即:
- 可以先有表,然后把數據移動到表指定的LOCATION中
- 也可以先有數據,然后創建表通過LOCATION指向數據
-
在Linux上創建新文件,test_external.txt,并填入如下內容:

數據列用’\t’分隔 -
演示先創建外部表,然后移動數據到LOCATION目錄
- 首先檢查:
hadoop fs -ls /tmp,確認不存在/tmp/test_ext1目錄 - 創建外部表:
create external table test_ext1(id int, name string) row format delimited fields terminated by ‘\t’ location ‘/tmp/test_ext1’;(注意:必須使用row format delimited fields terminated by指定列分隔符,必須使用LOCATION指定數據路徑) - 可以看到,目錄/tmp/test_ext1被創建
select * from test_ext1,空結果,無數據- 上傳數據:
hadoop fs -put test_external.txt /tmp/test_ext1/ select * from test_ext1,即可看到數據結果
- 首先檢查:
-
演示先存在數據,后創建外部表
- hadoop fs -mkdir /tmp/test_ext2
- hadoop fs -put test_external.txt /tmp/test_ext2/
- create external table test_ext2(id int, name string) row format delimited fields terminated by ‘\t’ location ‘/tmp/test_ext2’;
- select * from test_ext2;
刪除外部表
drop table test_ext1;
drop table test_ext2;
可以發現,在Hive中通過show table,表不存在了。但是在HDFS中,數據文件依舊保留
2.2.3 內外部表轉換
Hive可以很簡單的通過SQL語句轉換內外部表。查看表類型:desc formatted stu;
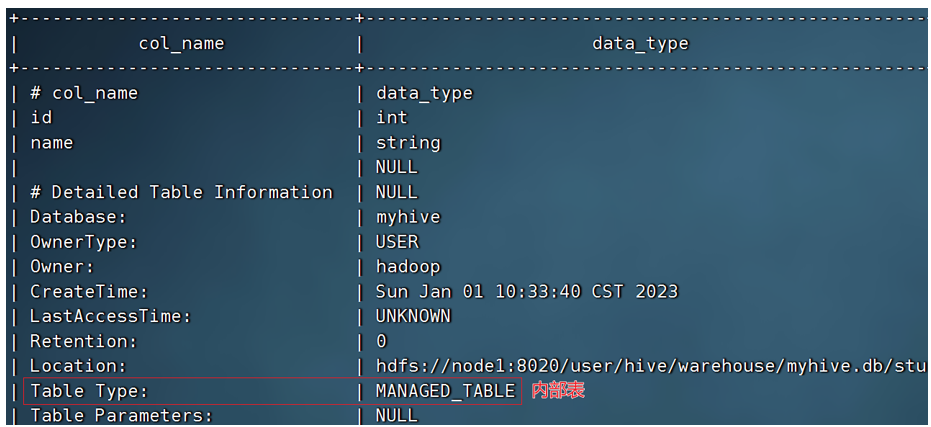
內部表轉外部表
alter table stu set tblproperties('EXTERNAL'='TRUE');

外部表轉內部表
alter table stu set tblproperties('EXTERNAL'='FALSE');

通過stu set tblproperties來修改屬性,要注意:('EXTERNAL'='FALSE') 或 ('EXTERNAL'='TRUE')為固定寫法,區分大小寫!!!
三 表數據
3.1 數據加載(數據導入)
方式一 LOAD語法
我們使用 LOAD 語法,把外部將數據加載到Hive內,語法如下:
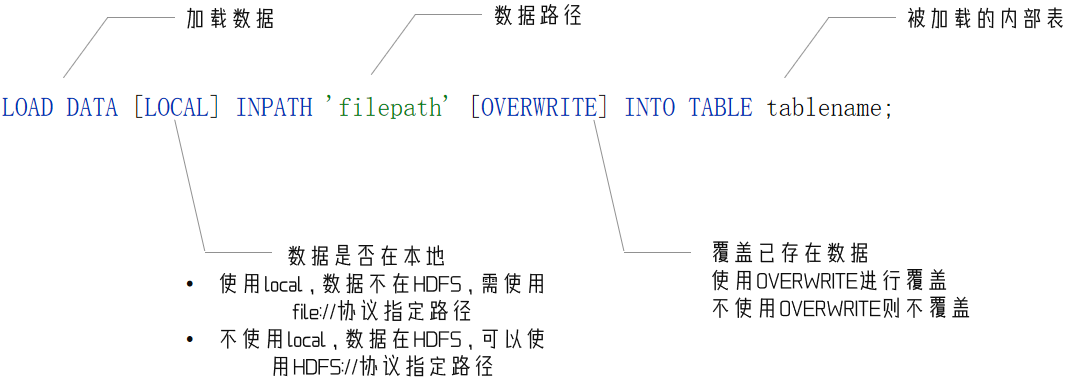
案例
建表如下:
CREATE TABLE myhive.test_load(dt string comment '時間(時分秒)', user_id string comment '用戶ID', word string comment '搜索詞',url string comment '用戶訪問網址'
) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
數據如下:
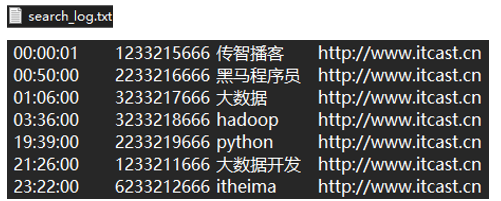
數據加載
load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load;
# 不使用location 說明數據在hdfs
load data inpath '/tmp/search_log.txt' overwrite into table myhive.test_load;
注意,基于HDFS進行load加載數據,源數據文件會消失(本質是被移動到表所在的目錄中)
方式二 INSERT SELECT 語法
除了load加載外部數據外,我們也可以通過SQL語句,從其它表中加載數據。
語法:
INSERT [OVERWRITE | INTO] TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
將SELECT查詢語句的結果插入到其它表中,被SELECT查詢的表可以是內部表或外部表。
示例:
INSERT INTO TABLE tbl1 SELECT * FROM tbl2;
INSERT OVERWRITE TABLE tbl1 SELECT * FROM tbl2;
對于數據加載,我們學習了:LOAD和INSERT SELECT的方式,那么如何選擇它們使用呢?
- 數據在本地:推薦 load data local加載
- 數據在HDFS:如果不保留原始文件,推薦使用LOAD方式直接加載。如果保留原始文件,推薦使用外部表先關聯數據,然后通過INSERT SELECT 外部表的形式加載數據
- 數據已經在表中:只可以INSERT SELECT
推薦選擇加載數據到內部表內
- 部表就像企業的外聘顧問一樣,并非正式成員,在設計上只是臨時工,一般用于中轉數據或臨時使用。
- 外部表存儲位置不固定,權限管控不統一,容易出現數據丟失問題。
所以,我們需要學習數據加載,完成將外部數據導入到Hive內部表中
3.2 數據導出
方式一 insert overwrite
將hive表中的數據導出到其他任意目錄,例如linux本地磁盤,例如hdfs,例如mysql等等
insert overwrite [local] directory ‘path’ select_statement1 FROM from_statement;
將查詢的結果導出到本地 - 使用默認列分隔符
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;
將查詢的結果導出到本地 - 指定列分隔符
insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * from test_load;
將查詢的結果導出到HDFS上(不帶local關鍵字)
insert overwrite directory '/tmp/export' row format delimited fields terminated by '\t' select * from test_load;
方式二 hive shell
基本語法:(hive -f/-e 執行語句或者腳本 > file)
bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txtbin/hive -f export.sql > /home/hadoop/export4/export4.txt
四 Hive復雜類型的基本使用
Hive支持的數據類型很多,除了基本的:int、string、varchar、timestamp等,還有一些復雜的數據類型:
array:數組類型
map:映射類型
struct:結構類型
4.1 array類型
如下是 data_for_array_type.txt 數據文件,有2個列,locations列包含多個城市:
說明:name與locations之間制表符分隔,locations中元素之間逗號分隔

可以使用array數組類型,存儲locations的數據,建表語句:
create table myhive.test_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
COLLECTION ITEMS TERMINATED BY ',';
其中:
row format delimited fields terminated by ‘\t’ 表示列分隔符是\t
COLLECTION ITEMS TERMINATED BY ‘,’ 表示集合(array)元素的分隔符是逗號
導入數據
load data local inpath '/home/hadoop/data_for_array_type.txt' overwrite into table myhive.test_array;
常用array類型查詢:
-- 查詢所有數據
select * from myhive.test_array;
-- 查詢loction數組中第一個元素
select name, work_locations[0] location from myhive.test_array;
-- 查詢location數組中元素的個數
select name, size(work_locations) location from myhive.test_array;
-- 查詢location數組中包含tianjin的信息
select * from myhive.test_array where array_contains(work_locations,'tianjin');
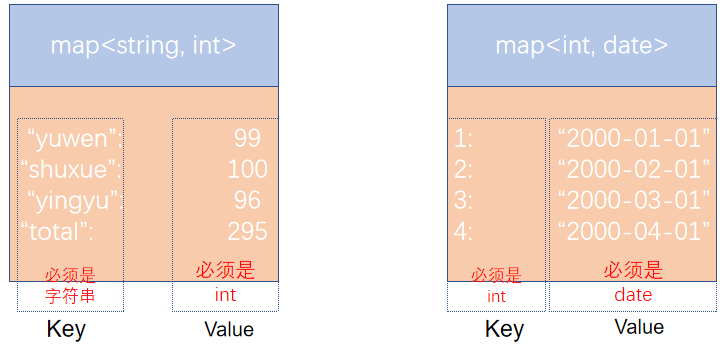
4.2 map類型
map類型其實就是簡單的指代:Key-Value型數據格式。 有如下數據文件,其中
- members字段是key-value型數據
- 字段與字段分隔符: “,”
- 需要map字段之間的分隔符:“#”
- map內部k-v分隔符:“:”
id,name,members,age
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
建表語句:
create table myhive.test_map(
id int, name string, members map<string,string>, age int
)
row format delimited
fields terminated by ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';
其中:
MAP KEYS TERMINATED BY ‘:’ 表示key-value之間用:分隔
導入數據
load data local inpath '/home/hadoop/data_for_map_type.txt' overwrite into table myhive.test_map;
常用查詢
# 查詢全部
select * from myhive.test_map;
# 查詢father、mother這兩個map的key
select id, name, members['father'] father, members['mother'] mother, age from myhive.test_map;
# 查詢全部map的key,使用map_keys函數,結果是array類型
select id, name, map_keys(members) as relation from myhive.test_map;
# 查詢全部map的value,使用map_values函數,結果是array類型
select id, name, map_values(members) as relation from myhive.test_map;
# 查詢map類型的KV對數量
select id,name,size(members) num from myhive.test_map;
# 查詢map的key中有brother的數據
select * from myhive.test_map where array_contains(map_keys(members), 'brother');
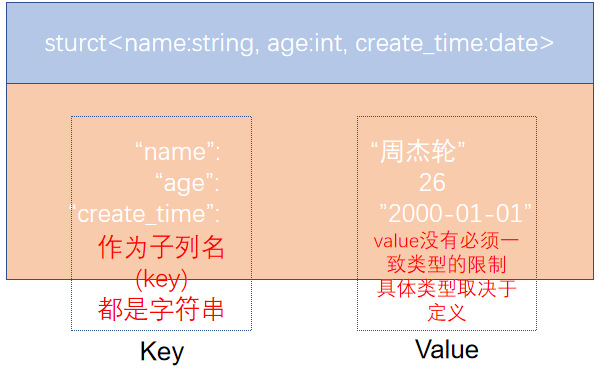
4.3 struct類型
struct類型是一個復合類型,可以在一個列中存入多個子列,每個子列允許設置類型和名稱
有如下數據文件,說明:字段之間#分割,struct之間冒號分割
1#周杰輪:11
2#林均杰:16
3#劉德滑:21
4#張學油:26
5#蔡依臨:23
建表語句
create table myhive.test_struct(id string, info struct<name:string, age:int>
)
row format delimited
fields terminated by '#'
COLLECTION ITEMS TERMINATED BY ':';
導入數據
load data local inpath '/home/hadoop/data_for_struct_type.txt' into table myhive.test_struct;
常用查詢
select * from hive_struct;
# 直接使用列名.子列名 即可從struct中取出子列查詢
select ip, info.name from hive_struct;
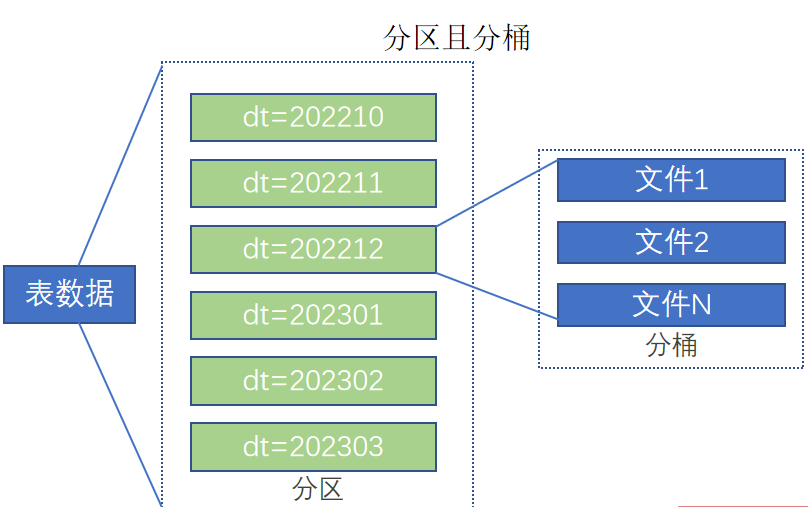
五 分區表
在大數據中,最常用的一種思想就是分治,我們可以把大的文件切割劃分成一個個的小的文件,這樣每次操作一個小的文件就會很容易了。
同樣的道理,在hive當中也是支持這種思想的,就是我們可以把大的數據,按照每天,或者每小時進行切分成一個個的小的文件,這樣去操作小的文件就會容易得多了。
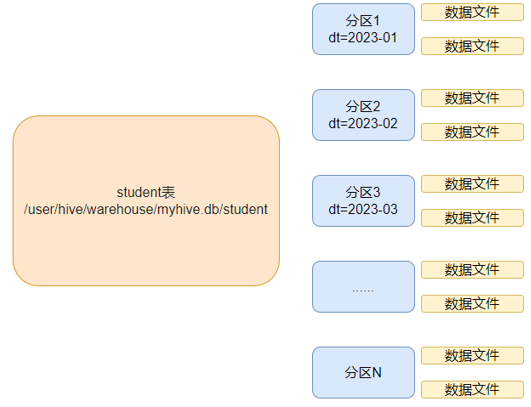
如圖,一個典型的按月份分區的表。每一個分區,是一個文件夾。
同時Hive也支持多個字段作為分區,多分區帶有層級關系,如下圖,多分區表(三級分區)
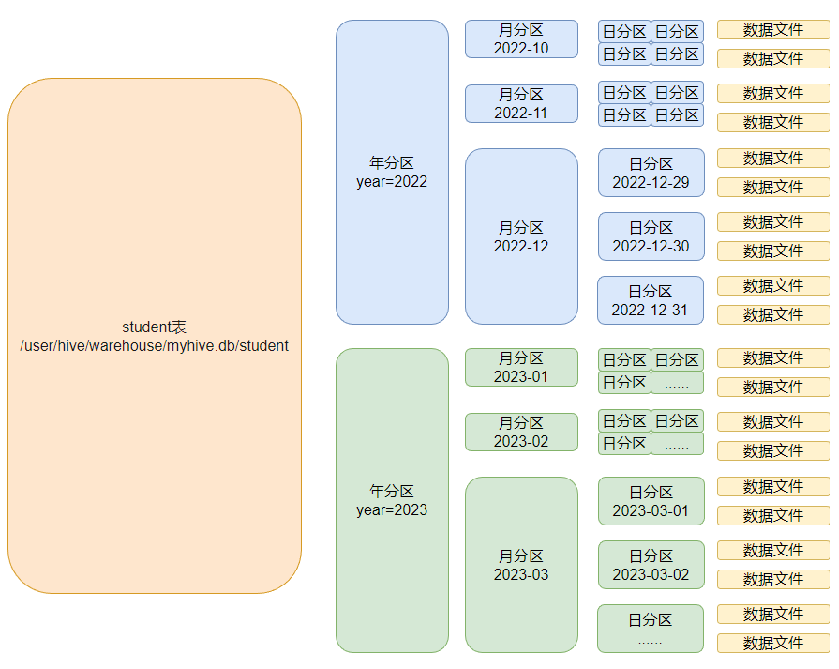
分區其實就是HDFS上的不同文件夾。分區表可以極大的提高特定場景下Hive的操作性能。
分區表的使用
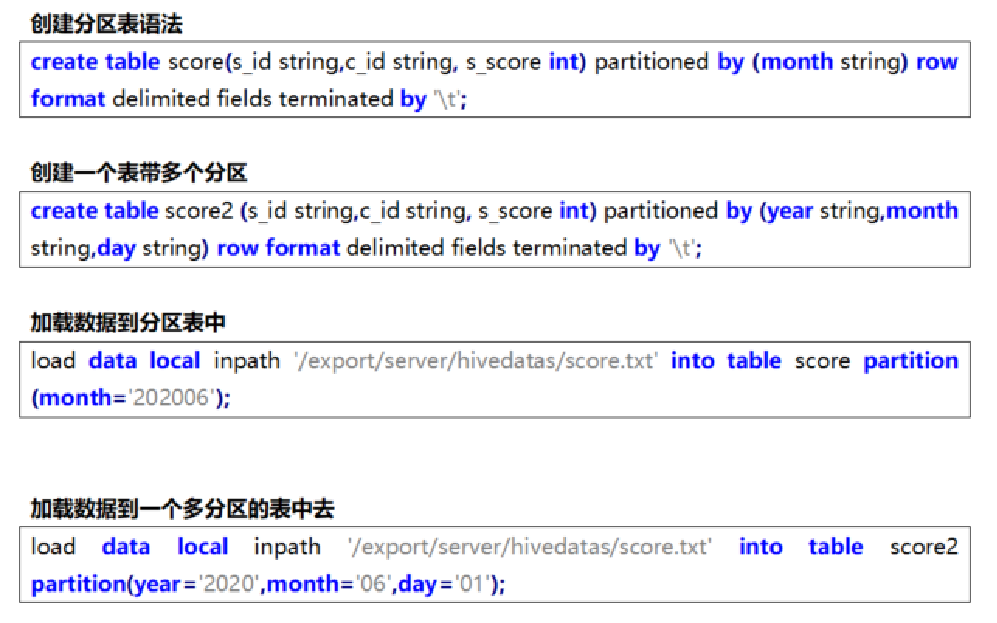
基本語法:
create table tablename(...) partitioned by (分區列 列類型, ......)
row format delimited fields terminated by '';
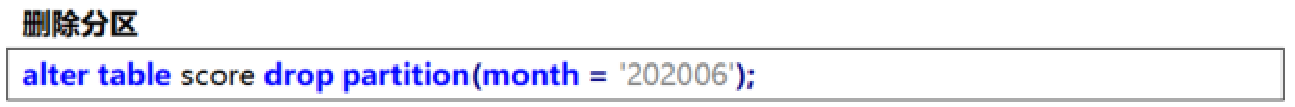
六 分桶表
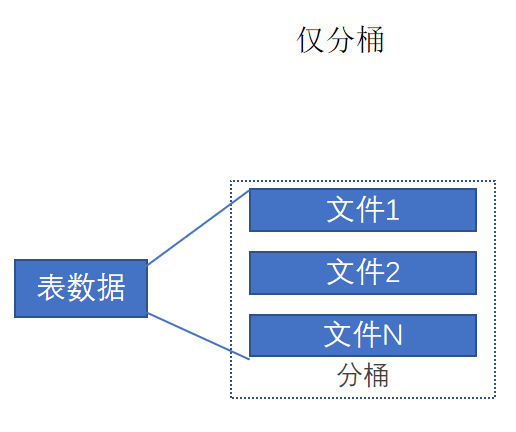
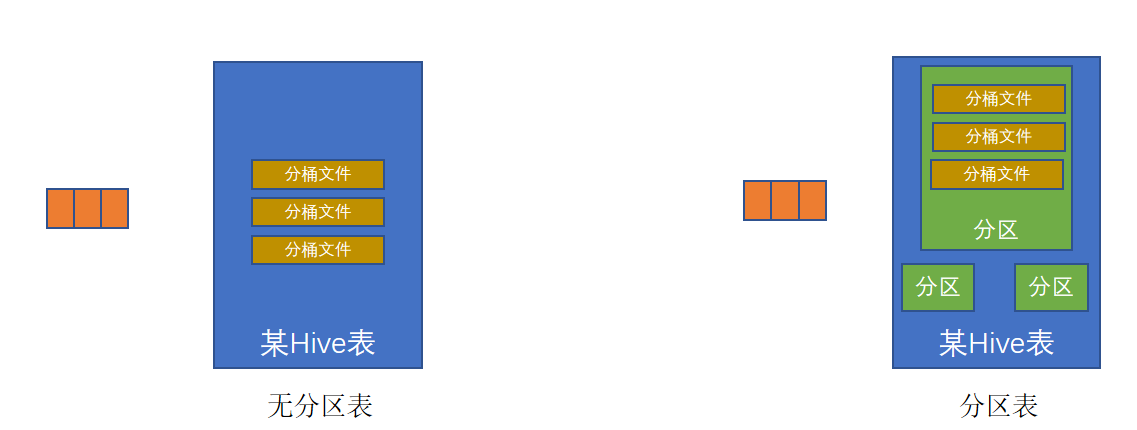
分桶和分區一樣,也是一種通過改變表的存儲模式,從而完成對表優化的一種調優方式。
但和分區不同,分區是將表拆分到不同的子文件夾中進行存儲,而分桶是將表拆分到固定數量的不同文件中進行存儲。
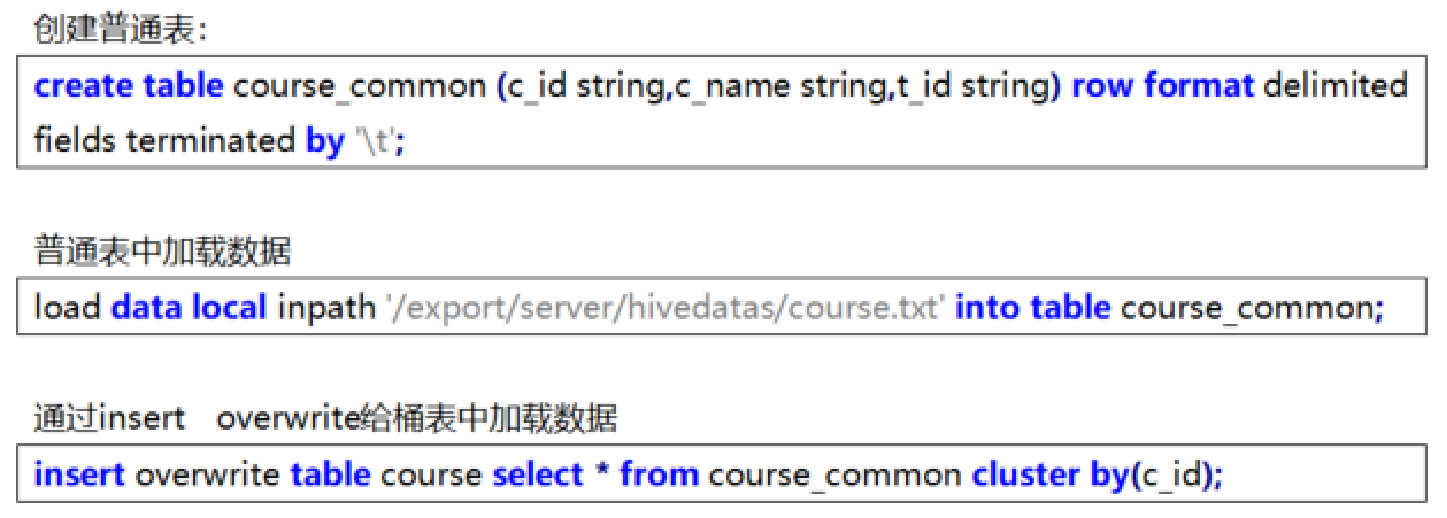
分桶表創建
開啟分桶的自動優化(自動匹配reduce task數量和桶數量一致)
set hive.enforce.bucketing=true;
創建分桶表
# clustered by指定分桶字段
# into num buckets指定分桶數量
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
分桶表數據加載
桶表的數據加載,由于桶表的數據加載通過load data無法執行,只能通過insert select,所以,比較好的方式是
- 創建一個臨時表(外部表或內部表均可),通過
load data加載數據進入表 - 然后通過
insert select從臨時表向桶表插入數據
為什么不可以用load data,必須用insert select插入數據?
需要insert select觸發MapReduce進行hash取模計算,來基于分桶列的值,確定哪一條數據進入到哪一個桶文件中
如果沒有分桶設置,插入(加載)數據只是簡單的將數據放入到:
- 表的數據存儲文件夾中(沒有分區)
- 表指定分區的文件夾中(帶有分區)


一旦有了分桶設置,比如分桶數量為3,那么,表內文件或分區內數據文件的數量就限定為3,當數據插入的時候,需要一分為3,進入三個桶文件內。

問題就在于:如何將數據分成三份,劃分的規則是什么?
數據的三份劃分基于分桶列的值進行hash取模來決定
由于load data不會觸發MapReduce,也就是沒有計算過程(無法執行Hash算法),只是簡單的移動數據而已,所以無法用于分桶表數據插入。
Hash取模
Hash算法是一種數據加密算法,其原理我們不去詳細討論,我們只需要知道其主要特征:
- 同樣的值被Hash加密后的結果是一致的
比如字符串“hadoop”被Hash后的結果是12345(僅作為示意),那么無論計算多少次,字符串“hadoop”的結果都會是12345。
比如字符串“bigdata”被Hash后的結果是56789(僅作為示意),那么無論計算多少次,字符串“bigdata”的結果都會是56789。
基于如上特征,再輔以有3個分桶文件的基礎上,將Hash的結果基于3取模(除以3 取余數),那么,可以得到如下結果:
- 無論什么數據,得到的取模結果均是:0、1、2 其中一個
- 同樣的數據得到的結果一致,如hadoop hash取模結果是1,無論計算多少次,字符串hadoop的取模結果都是1
所以,必須使用insert select的語法,因為會觸發MapReduce,進行hash取模計算。
Hash取模確定數據歸屬哪個分桶文件
基于Hash取模,數據中的每一個分桶列的值,都被hash取模得到0、1、2其中一個數,基于結果,存入對應序號的桶文件中。
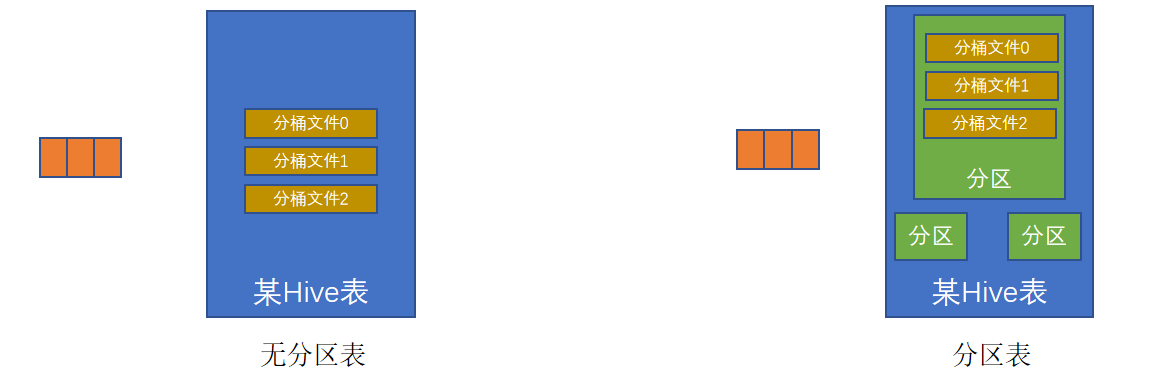

分桶表的性能提升
如果說分區表的性能提升是:在指定分區列的前提下,減少被操作的數據量,從而提升性能。
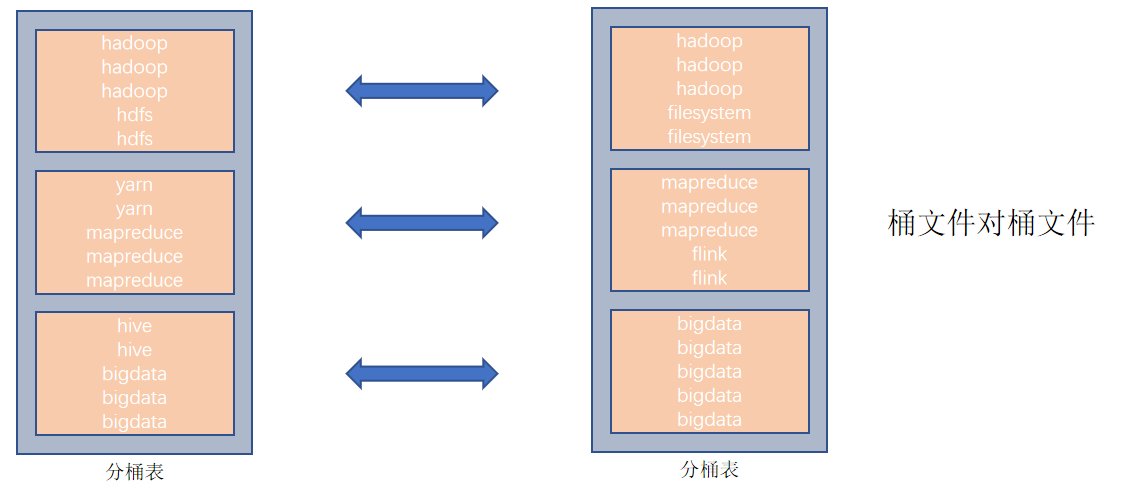
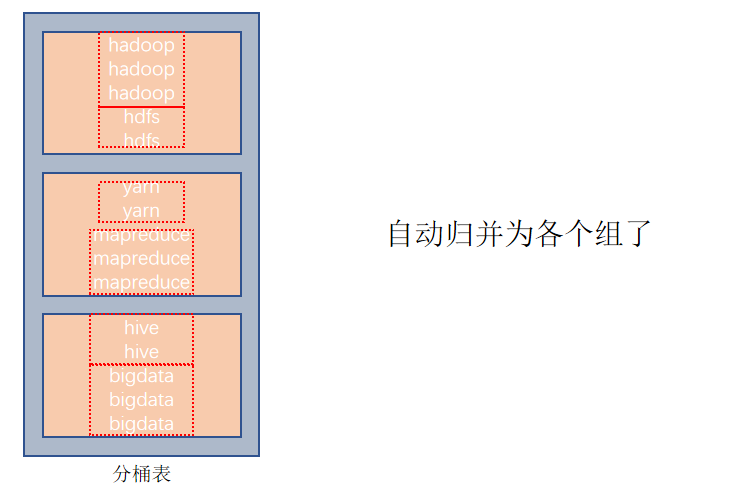
分桶表的性能提升就是:基于分桶列的特定操作,如:過濾、JOIN、分組,均可帶來性能提升。
基于分桶列,過濾單個值
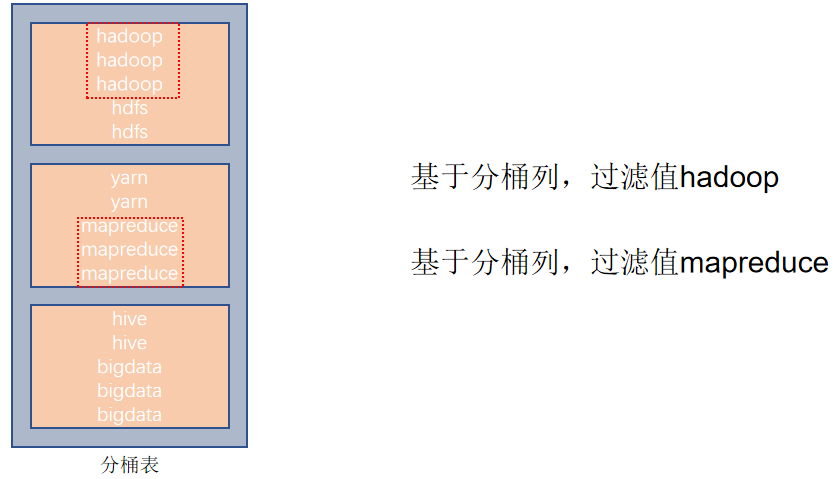
基于分桶列,進行雙表JOIN
基于分桶列,group by 分組
七 修改表
表重命名
alter table old_table_name rename to new_table_name;
如:alter table score4 rename to score5;
修改表屬性值
ALTER TABLE table_name SET TBLPROPERTIES table_properties;
table_properties:: (property_name = property_value, property_name = property_value, ... )
如:ALTER TABLE table_name SET TBLPROPERTIES("EXTERNAL"="TRUE"); 修改內外部表屬性
如:ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comment); 修改表注釋
其余屬性可參見:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-listTableProperties
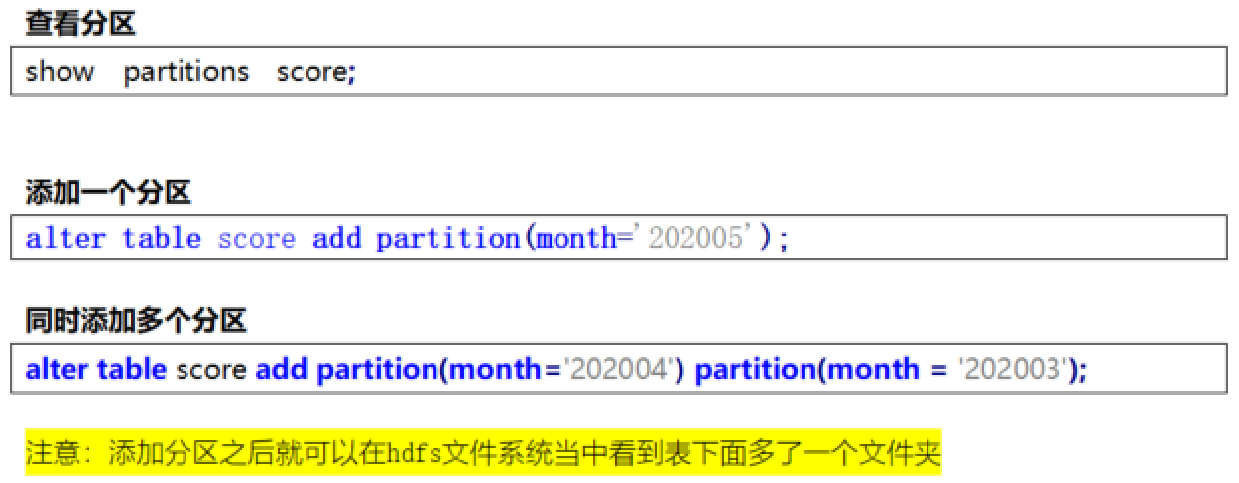
添加分區
ALTER TABLE tablename ADD PARTITION (month='201101');
新分區是空的沒數據,需要手動添加或上傳數據文件
修改分區值
ALTER TABLE tablename PARTITION (month='202005') RENAME TO PARTITION (month='201105');
刪除分區
ALTER TABLE tablename DROP PARTITION (month='201105');
添加列
ALTER TABLE table_name ADD COLUMNS (v1 int, v2 string);
修改列名
ALTER TABLE test_change CHANGE v1 v1new INT;
刪除表
DROP TABLE tablename;
清空表
TRUNCATE TABLE tablename;
ps:只可以清空內部表
八 復雜類型操作
Hive支持的數據類型很多,除了基本的:int、string、varchar、timestamp等,還有一些復雜的數據類型:
- array
數組類型 - map
映射類型 - struct
結構類型
8.1 array類型
如下數據文件,有2個列,locations列包含多個城市:
說明:name與locations之間制表符分隔,locations中元素之間逗號分隔

可以使用array數組類型,存儲locations的數據,建表語句:
create table myhive.test_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
COLLECTION ITEMS TERMINATED BY ',';
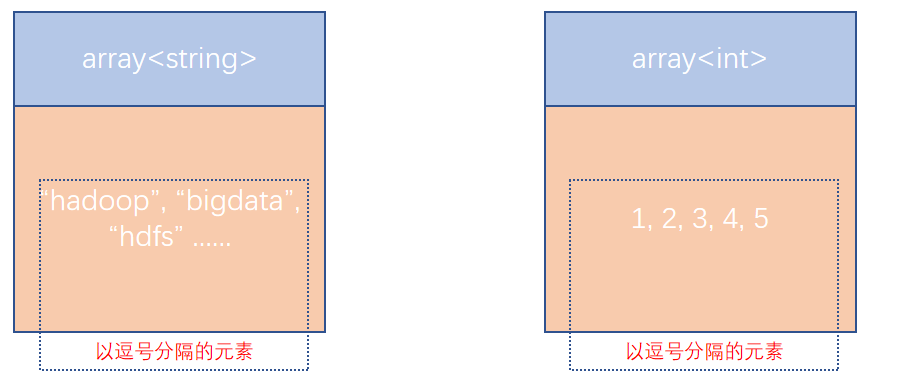
row format delimited fields terminated by '\t' 表示列分隔符是\t
COLLECTION ITEMS TERMINATED BY ',' 表示集合(array)元素的分隔符是逗號
基于COLLECTION ITEMS TERMINATED BY ',' 設定的array類型的一條數據示意
導入數據
load data local inpath '/home/hadoop/data_for_array_type.txt' overwrite into table myhive.test_array;
常用array類型查詢:
-- 查詢所有數據
select * from myhive.test_array;
-- 查詢loction數組中第一個元素
select name, work_locations[0] location from myhive.test_array;
-- 查詢location數組中元素的個數
select name, size(work_locations) location from myhive.test_array;
-- 查詢location數組中包含tianjin的信息
select * from myhive.test_array where array_contains(work_locations,'tianjin');
8.2 map類型
map類型其實就是簡單的指代:Key-Value型數據格式。 有如下數據文件,其中members字段是key-value型數據,字段與字段分隔符: “,”;需要map字段之間的分隔符:“#”;map內部k-v分隔符:“:”
id,name,members,age
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
建表語句
create table myhive.test_map(id int, name string, members map<string,string>, age int
)
row format delimited
fields terminated by ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';
MAP KEYS TERMINATED BY ‘:’ 表示key-value之間用:分隔;
不同鍵值對之間:COLLECTION ITEMS TERMINATED BY ‘分隔符’ 分隔
基于map定義的結構一條數據示例
導入數據
load data local inpath '/home/hadoop/data_for_map_type.txt' overwrite into table myhive.test_map;
常用查詢
# 查詢全部
select * from myhive.test_map;
# 查詢father、mother這兩個map的key
select id, name, members['father'] father, members['mother'] mother, age from myhive.test_map;
# 查詢全部map的key,使用map_keys函數,結果是array類型
select id, name, map_keys(members) as relation from myhive.test_map;
# 查詢全部map的value,使用map_values函數,結果是array類型
select id, name, map_values(members) as relation from myhive.test_map;
# 查詢map類型的KV對數量
select id,name,size(members) num from myhive.test_map;
# 查詢map的key中有brother的數據
select * from myhive.test_map where array_contains(map_keys(members), 'brother');
- map[key]來獲取指定key的值
- map_keys(map)取到全部的key作為array返回,map_values(map)取到全部values
- size(map)可以統計K-V對的個數
- array_contains(map_values(map), 數據) 可以統計map是否包含指定數據
8.3 struct類型
struct類型是一個復合類型,可以在一個列中存入多個子列,每個子列允許設置類型和名稱
有如下數據文件,說明:字段之間#分割,struct之間冒號分割
1#周杰輪:11
2#林均杰:16
3#劉德滑:21
4#張學油:26
5#蔡依臨:23
建表語句
create table myhive.test_struct(
id string, info struct<name:string, age:int>
)
row format delimited
fields terminated by '#'
COLLECTION ITEMS TERMINATED BY ':';
導入數據
load data local inpath '/home/hadoop/data_for_struct_type.txt' into table myhive.test_struct;
常用查詢
select * from hive_struct;
# 直接使用列名.子列名 即可從struct中取出子列查詢
select ip, info.name from hive_struct;
struct的分隔符只需要:COLLECTION ITEMS TERMINATED BY '分隔符' 只需要分隔數據即可(數據中不記錄key,key是建表定義的固定的)
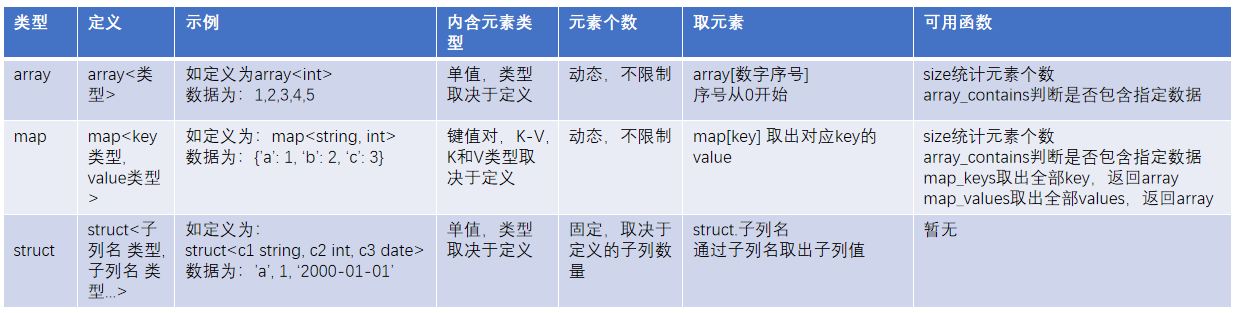
8.4 array、map、struct總結
九 數據查詢
9.1 基本查詢
查詢語句的基本語法
SELECT [ALL | DISTINCT]select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BYcol_list]
[HAVING where_condition]
[ORDER BYcol_list]
[CLUSTER BYcol_list| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
整體上和普通SQL差不多,部分有區別,如:CLUSTER BY、DISTRIBUTE BY、SORT BY等,這些我們會放入到后邊高階原理章節進行講解。
準備數據:訂單表
CREATE DATABASE itheima;USE itheima;CREATE TABLE itheima.orders (orderId bigint COMMENT '訂單id',orderNo string COMMENT '訂單編號',shopId bigint COMMENT '門店id',userId bigint COMMENT '用戶id',orderStatus tinyint COMMENT '訂單狀態 -3:用戶拒收 -2:未付款的訂單 -1:用戶取消 0:待發貨 1:配送中 2:用戶確認收貨',goodsMoney double COMMENT '商品金額',deliverMoney double COMMENT '運費',totalMoney double COMMENT '訂單金額(包括運費)',realTotalMoney double COMMENT '實際訂單金額(折扣后金額)',payType tinyint COMMENT '支付方式,0:未知;1:支付寶,2:微信;3、現金;4、其他',isPay tinyint COMMENT '是否支付 0:未支付 1:已支付',userName string COMMENT '收件人姓名',userAddress string COMMENT '收件人地址',userPhone string COMMENT '收件人電話',createTime timestamp COMMENT '下單時間',payTime timestamp COMMENT '支付時間',totalPayFee int COMMENT '總支付金額'
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';LOAD DATA LOCAL INPATH '/home/hadoop/itheima_orders.txt' INTO TABLE itheima.orders;
這是一張訂單銷售表,我們基于此表,做一下簡單的Hive基本查詢
準備數據:用戶表
CREATE TABLE itheima.users (userId int,loginName string,loginSecret int,loginPwd string,userSex tinyint,userName string,trueName string,brithday date,userPhoto string,userQQ string,userPhone string,userScore int,userTotalScore int,userFrom tinyint,userMoney double,lockMoney double,createTime timestamp,payPwd string,rechargeMoney double
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
加載數據
LOAD DATA LOCAL INPATH '/home/hadoop/itheima_users.txt' INTO TABLE itheima.users;
單表查詢
查詢所有
SELECT * FROM itheima.orders;
查詢單列
SELECT orderid, totalmoney, username, useraddress, paytime FROM itheima.orders;
查詢數據量
SELECT COUNT(*) FROM itheima.orders;
過濾廣東省訂單
SELECT * FROM itheima.orders WHERE useraddress LIKE '%廣東%';
找出廣東省單筆營業額最大的訂單
SELECT * FROM itheima.orders WHERE useraddress like '%廣東%' ORDER BY totalmoney DESC LIMIT 1;
分組、聚合
統計未支付、已支付各自的人數
SELECT ispay, COUNT(*) AS cnt FROM itheima.orders GROUP BY ispay;
在已付款訂單中,統計每個用戶最高的一筆消費金額
SELECT userid, MAX(totalmoney) AS max_money FROM itheima.orders WHERE ispay = 1 GROUP BY userid;
統計每個用戶的平均訂單消費額
SELECT userid, AVG(totalmoney) FROM itheima.orders GROUP BY userid;
統計每個用戶的平均訂單消費額,過濾大于10000的數據
SELECT userid, AVG(totalmoney) AS avg_money FROM itheima.orders GROUP BY userid HAVING avg_money > 10000;
JOIN
JOIN訂單表和用戶表,找出用戶名
SELECT o.orderid, o.userid, u.username, o.totalmoney, o.useraddress, o.paytime FROM itheima.orders o JOIN itheima.users u ON o.userid = u.userid;
左外關聯,訂單表和用戶表,找出用戶名
SELECT o.orderid, o.userid, u.username, o.totalmoney, o.useraddress, o.paytime FROM itheima.orders o LEFT JOIN itheima.users u ON o.userid = u.userid;
可以發現,Hive中使用基本查詢SELECT、WHERE、GROUP BY、聚合函數、HAVING、JOIN和普通的SQL語句沒有區別
9.2 RLIKE關鍵字進行正則匹配
正則表達式
正則表達式是一種規則集合,通過特定的規則字符描述,來判斷字符串是否符合規則。
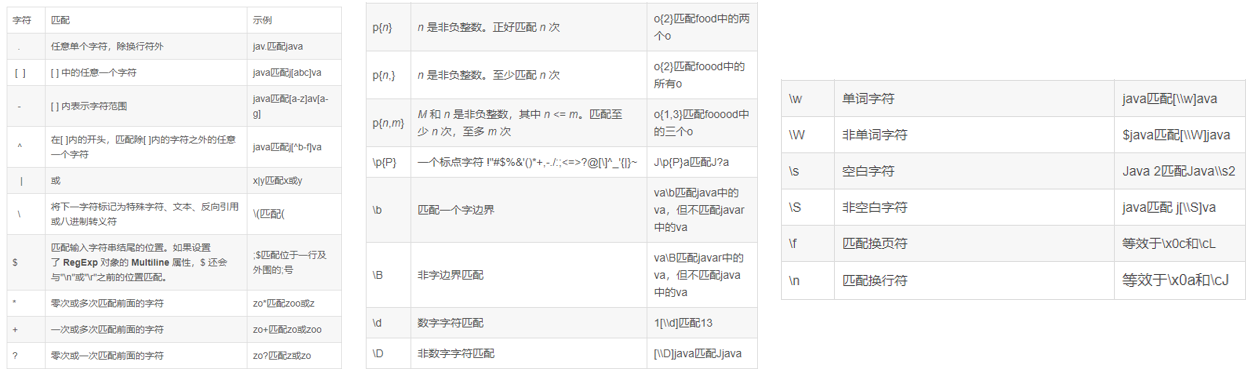
RLIKE
Hive中提供RLIKE關鍵字,可以供用戶使用正則和數據進行匹配。我們以上一節中使用的訂單表為例,來簡單使用一下RLIKE正則匹配。
# 查找廣東省的數據
SELECT * FROM itheima.orders WHERE useraddress RLIKE '.*廣東.*';
# 查找用戶地址是:xx省 xx市 xx區的數據
SELECT * FROM itheima.orders WHERE useraddress RLIKE '..省 ..市 ..區';
# 查找用戶姓為張、王、鄧
SELECT * FROM itheima.orders WHERE username RLIKE '[張王鄧]\\S+';
# 查找手機號符合:188****0*** 規則
SELECT * FROM itheima.orders WHERE userphone RLIKEE '188\\S{4}0\\S{3}';
9.3 UNION關鍵字進行查詢
UNION 用于將多個 SELECT 語句的結果組合成單個結果集。每個 select 語句返回的列的數量和名稱必須相同。否則,將引發架構錯誤。
基礎語法:
SELECT ...UNION [ALL]
SELECT ...
準備數據進行測試
CREATE TABLE itheima.course(c_id string, c_name string, t_id string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';LOAD DATA LOCAL INPATH '/home/hadoop/course.txt' INTO TABLE itheima.course;
聯合兩個查詢結果集
SELECT * FROM course WHERE t_id = '周杰輪'UNION
SELECT * FROM course WHERE t_id = '王力鴻'
UNION聯合 - 去重
UNION默認有去重功能:
直接聯合兩個同樣的查詢結果
SELECT * FROM course
UNION
SELECT * FROM course
如果不需要去重效果
SELECT * FROM courseUNION ALL
SELECT * FROM course
UNION寫在FROM中
SELECT t_id, COUNT(*) FROM
(SELECT t_id FROM itheima.course WHERE t_id = '周杰輪'UNION ALLSELECT t_id FROM itheima.course WHERE t_id = '王力鴻'
) AS u GROUP BY t_id;
用于INSERT SELECT中
CREATE TABLE itheima.course2 LIKE itheima.course;INSERT OVERWRITE TABLE itheima.course2SELECT * FROM itheima.courseUNION ALLSELECT * FROM itheima.course;
9.4 Sampling采樣
為什么需要抽樣表數據?
對表進行隨機抽樣是非常有必要的。大數據體系下,在真正的企業環境中,很容易出現很大的表,比如體積達到TB級別。對這種表一個簡單的SELECT * 都會非常的慢,哪怕LIMIT 10想要看10條數據,也會走MapReduce流程,這個時間等待是不合適的。
Hive提供的快速抽樣的語法,可以快速從大表中隨機抽取一些數據供用戶查看。
TABLESAMPLE函數
進行隨機抽樣,本質上就是用TABLESAMPLE函數
語法1,基于隨機分桶抽樣:
SELECT ... FROM tbl TABLESAMPLE(BUCKET x OUT OF y ON(colname | rand()))
- y表示將表數據隨機劃分成y份(y個桶)
- x表示從y里面隨機抽取x份數據作為取樣
- colname表示隨機的依據基于某個列的值
- rand()表示隨機的依據基于整行
示例:
SELECT username, orderId, totalmoney FROM itheima.orders TABLESAMPLE(BUCKET 1 OUT OF 10 ON username);
SELECT * FROM itheima.orders TABLESAMPLE(BUCKET 1 OUT OF 10 ON rand());
注意:
- 使用colname作為隨機依據,則其它條件不變下,每次抽樣結果一致
- 使用rand()作為隨機依據,每次抽樣結果都不同
語法2,基于數據塊抽樣
SELECT ... FROM tbl TABLESAMPLE(num ROWS | num PERCENT | num(K|M|G));
- num ROWS 表示抽樣num條數據
- num PERCENT 表示抽樣num百分百比例的數據
- num(K|M|G) 表示抽取num大小的數據,單位可以是K、M、G表示KB、MB、GB
注意:使用這種語法抽樣,條件不變的話,每一次抽樣的結果都一致。 即無法做到隨機,只是按照數據順序從前向后取。
9.5 Virtual Columns 虛擬列
虛擬列是Hive內置的可以在查詢語句中使用的特殊標記,可以查詢數據本身的詳細參數。
Hive目前可用3個虛擬列:
- INPUT__FILE__NAME,顯示數據行所在的具體文件
- BLOCK__OFFSET__INSIDE__FILE,顯示數據行所在文件的偏移量
- ROW__OFFSET__INSIDE__BLOCK,顯示數據所在HDFS塊的偏移量
- 此虛擬列需要設置:SET hive.exec.rowoffset=true 才可使用
示例:
SELECT *, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM itheima.course;

虛擬列的作用
使用虛擬列,可以讓我們更精準的查看到具體每一條數據在存儲上的詳細參數細節
虛擬列不僅僅可以用于SELECT,在WHERE、GROUP BY等均可使用,如:
SELECT *, BLOCK__OFFSET__INSIDE__FILE FROM course WHERE BLOCK__OFFSET__INSIDE__FILE > 50;
SELECT INPUT__FILE__NAME, COUNT(*) FROM itheima.orders_bucket GROUP BY INPUT__FILE__NAME;
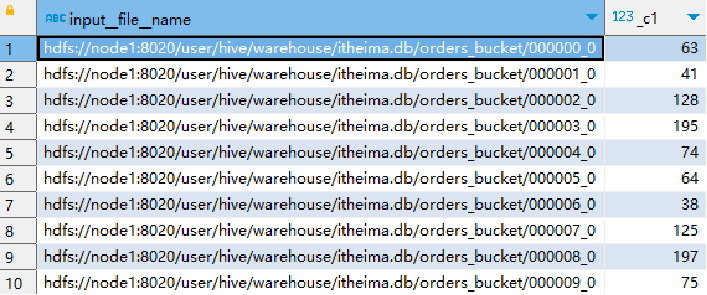
如上SQL,統計分桶表每個桶的數據行數。
除此以外,在某些錯誤排查場景上,虛擬列可以提供相關幫助。
十 函數
分類標準
Hive的函數分為兩大類:內置函數(Built-in Functions)、用戶定義函數UDF(User-Defined Functions):

Hive的函數共計有上百種,這里無法一一講解,會挑選一些常用的進行講解。
詳細的函數使用可以參閱:官方文檔
常用函數如下
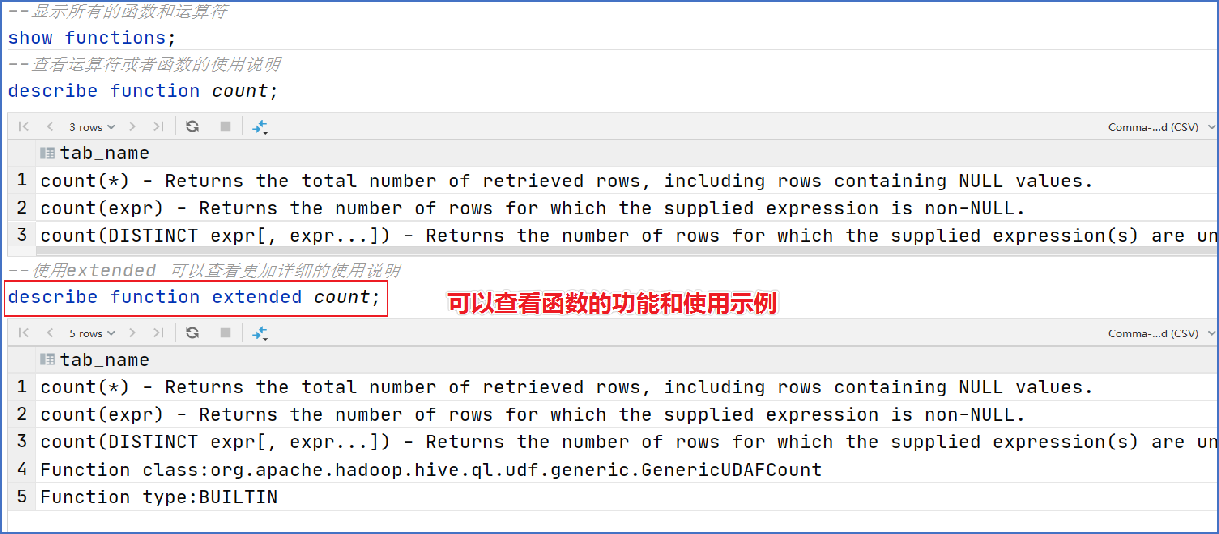
-- 查看所有可用函數
show functions;
-- 查看函數使用方式
describe function extended count;
-- 數值函數
-- round 取整,設置小數精度
select round(3.1415926); -- 取整(四舍五入)
select round(3.1415926, 4); -- 設置小數精度4位(四舍五入)
-- 隨機數
select rand(); -- 完全隨機
select rand(3); -- 設置隨機數種子,設置種子后每次運行結果一致的
-- 絕對值
select abs(-3);
-- 求PI
select pi();-- 集合函數
-- 求元素個數
select size(work_locations) from test_array;
select size(members) from test_map;
-- 取出map的全部key
select map_keys(members) from test_map;
-- 取出map的全部value
select map_values(members) from test_map;
-- 查詢array內是否包含指定元素,是就返回True
select * from test_array where ARRAY_CONTAINS(work_locations, 'tianjin');
-- 排序
select *, sort_array(work_locations) from test_array;-- 類型轉換函數
-- 轉二進制
select binary('hadoop');
-- 自由轉換,類型轉換失敗報錯或返回NULL
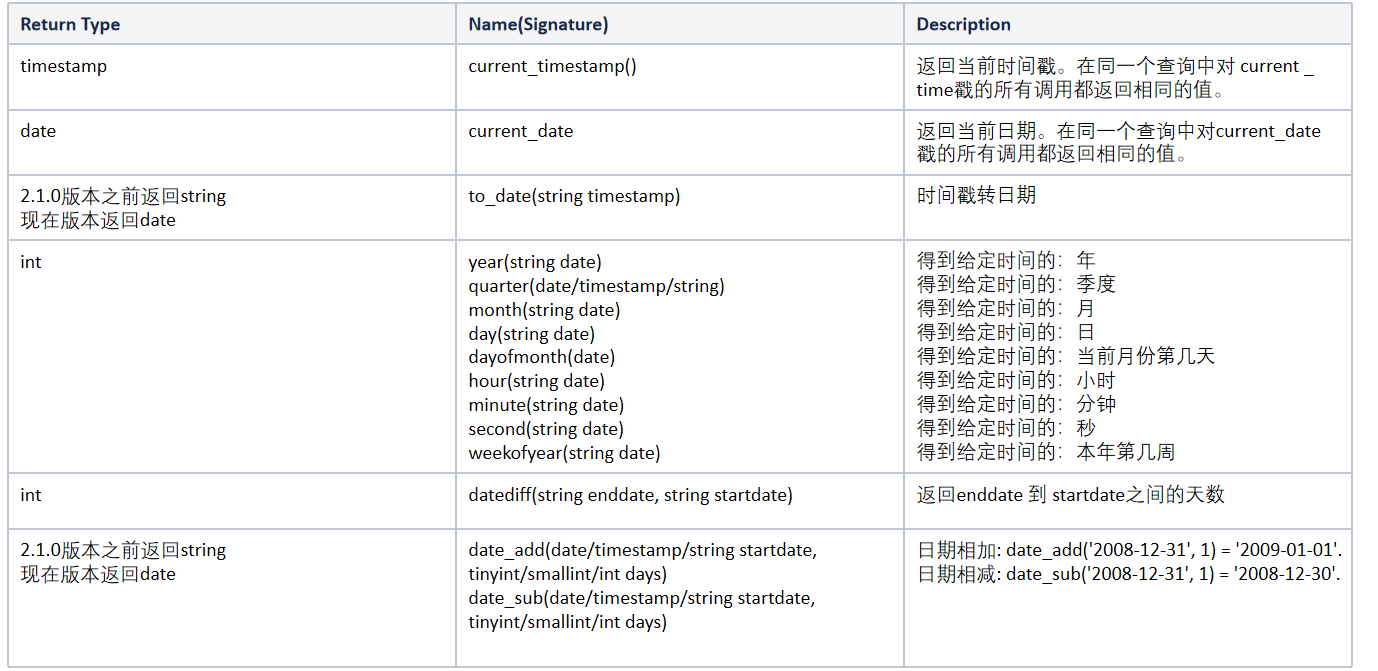
select cast('1' as bigint);-- 日期函數
-- 當前時間戳
select current_timestamp();
-- 當前日期
select current_date();
-- 時間戳轉日期
select to_date(current_timestamp());
-- 年月日季度等
select year('2020-01-11');
select month('2020-01-11');
select day('2020-01-11');
select quarter('2020-05-11');
select dayofmonth('2020-05-11');
select hour('2020-05-11 10:36:59');
select minute('2020-05-11 10:36:59');
select second('2020-05-11 10:36:59');
select weekofyear('2020-05-11 10:36:59');
-- 日期之間的天數
select datediff('2022-12-31', '2019-12-31');
-- 日期相加、相減
select date_add('2022-12-31', 5);
select date_sub('2022-12-31', 5);
Hive內建了不少函數
- 使用
show functions查看當下可用的所有函數; - 通過
describe function extended funcname來查看函數的使用方式。
Mathematical Functions 數學函數 - 部分
----Mathematical Functions 數學函數-------------
--取整函數: round 返回double類型的整數值部分 (遵循四舍五入)
select round(3.1415926);
--指定精度取整函數: round(double a, int d) 返回指定精度d的double類型
select round(3.1415926,4);
--取隨機數函數: rand 每次執行都不一樣 返回一個0到1范圍內的隨機數
select rand();
--指定種子取隨機數函數: rand(int seed) 得到一個穩定的隨機數序列
select rand(3);
--求數字的絕對值
select abs(-3);
--得到pi值(小數點后15位精度)
select pi();
Collection Functions集合函數 - 全部

Type Conversion Functions類型轉換函數 - 全部

Date Functions日期函數 - 部分
Conditional Functions條件函數 - 全部

String Functions字符串函數 - 部分
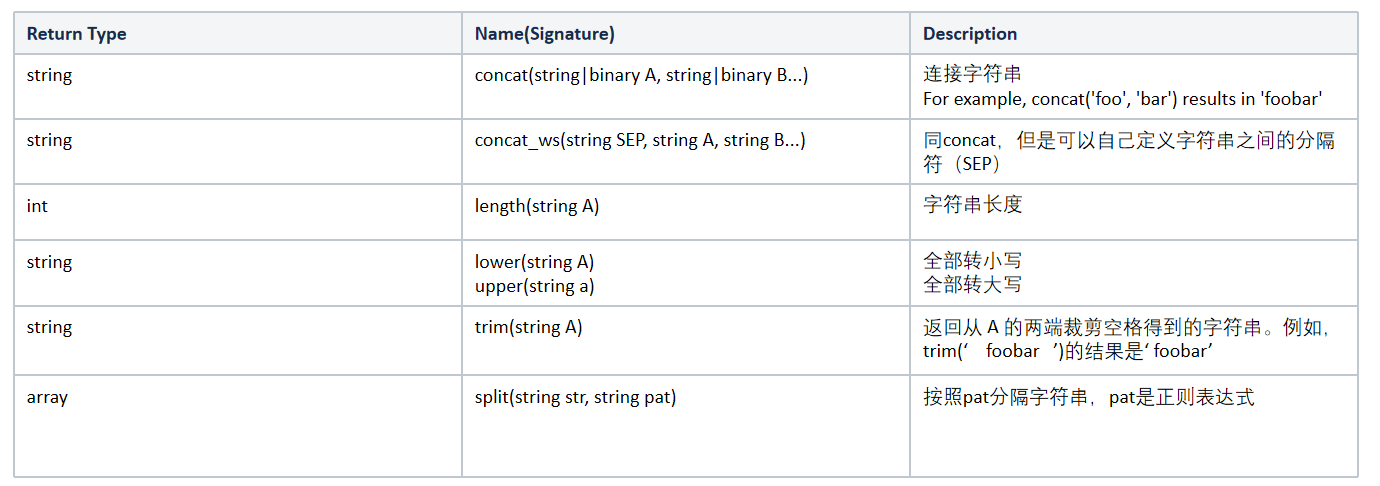
Data Masking Functions數據脫敏函數 - 部分

Misc. Functions其它函數 - 部分

十一 案例
11.1 需求分析
背景介紹
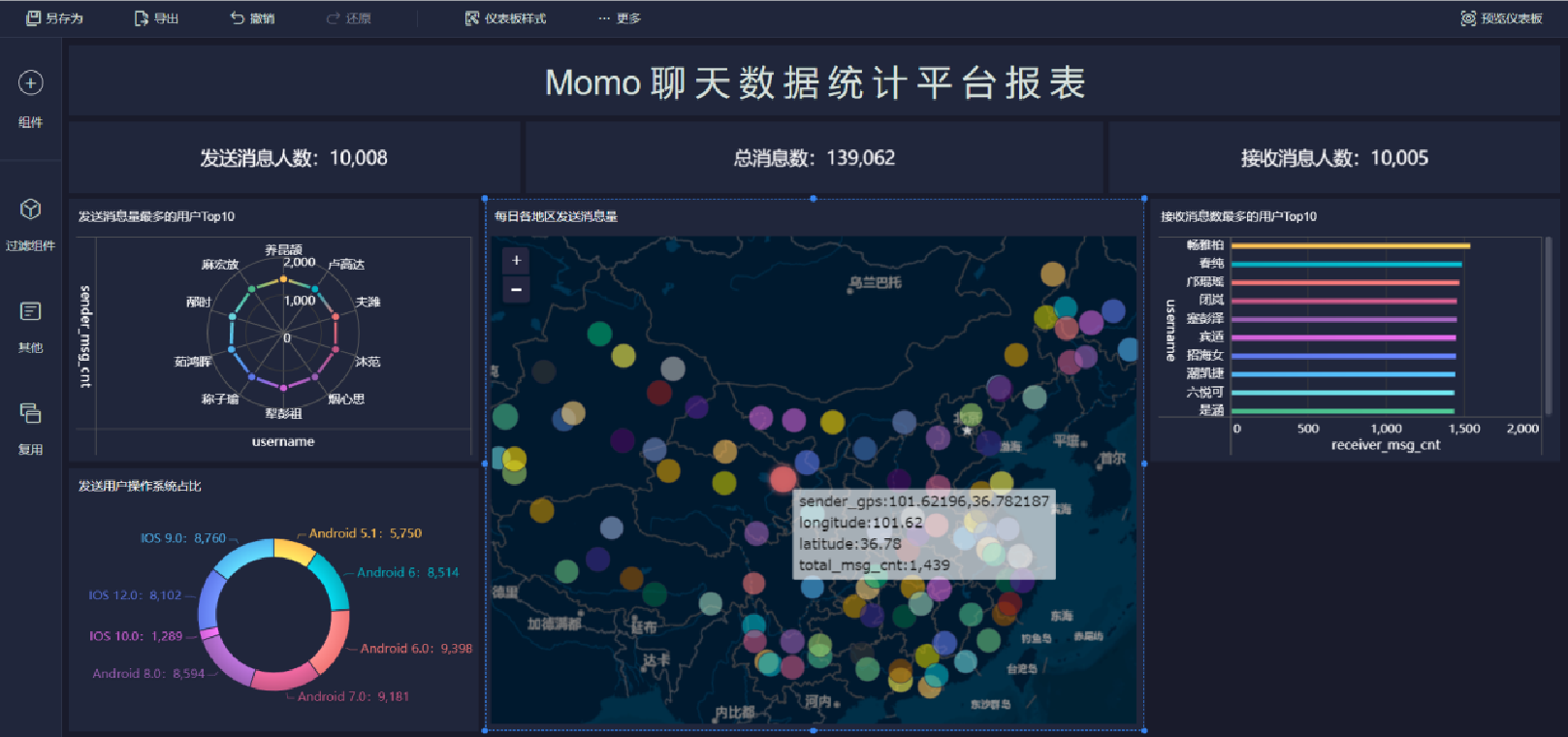
聊天平臺每天都會有大量的用戶在線,會出現大量的聊天數據,通過對聊天數據的統計分析,可以更好的對用戶構建精準的用戶畫像,為用戶提供更好的服務以及實現高ROI的平臺運營推廣,給公司的發展決策提供精確的數據支撐。
我們將基于一個社交平臺App的用戶數據,完成相關指標的統計分析并結合BI工具對指標進行可視化展現。
目標
基于Hadoop和Hive實現聊天數據統計分析,構建聊天數據分析報表
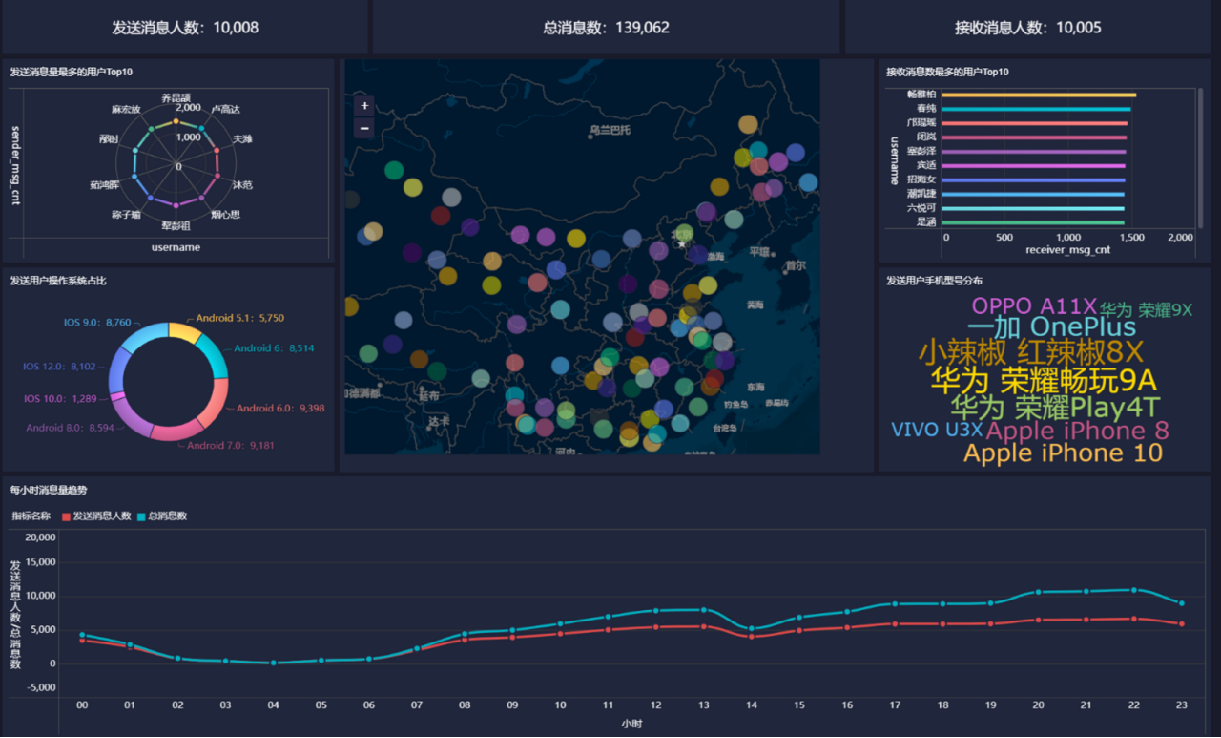
需求
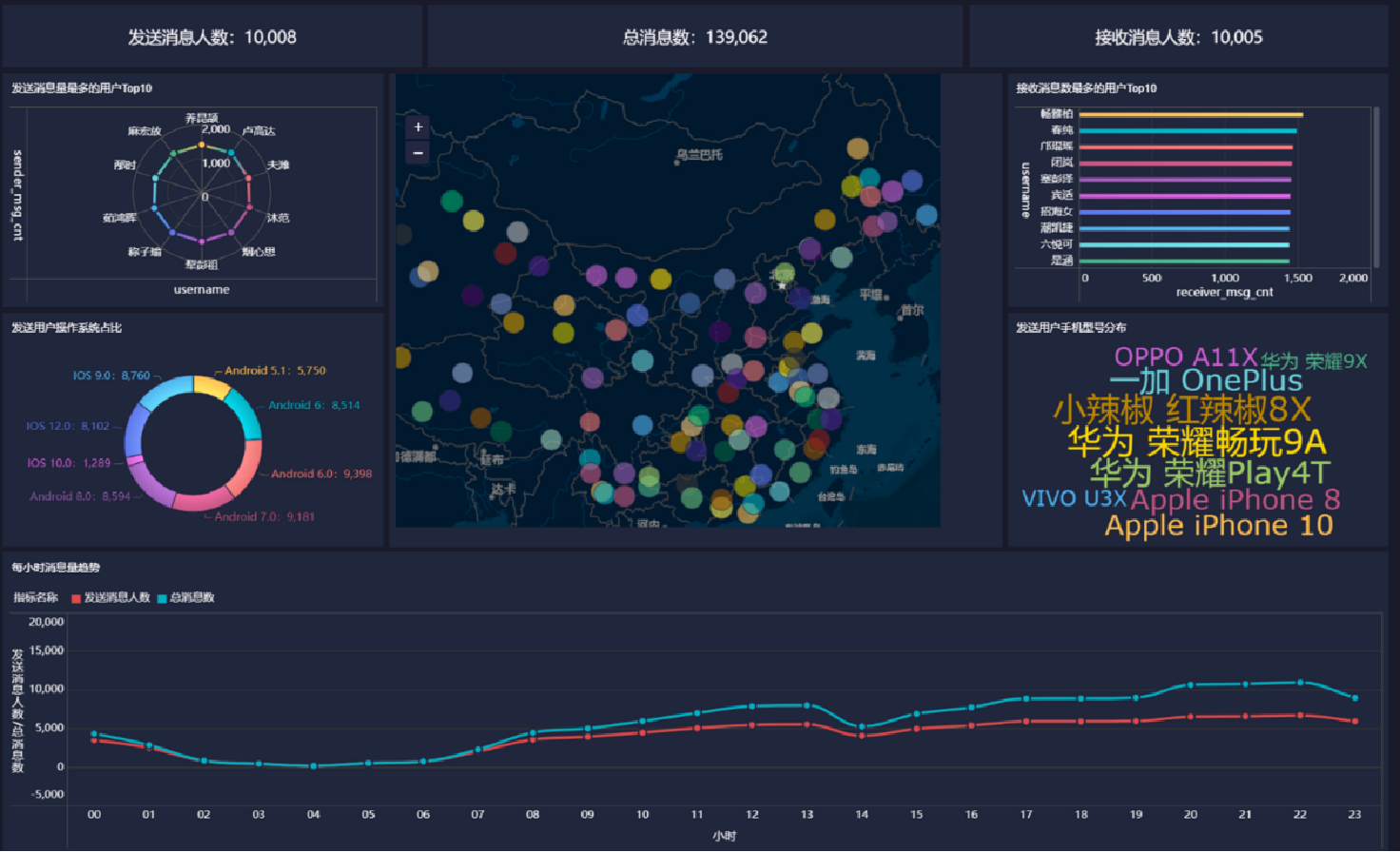
- 統計今日總消息量
- 統計今日每小時消息量、發送和接收用戶數
- 統計今日各地區發送消息數據量
- 統計今日發送消息和接收消息的用戶數
- 統計今日發送消息最多的Top10用戶
- 統計今日接收消息最多的Top10用戶
- 統計發送人的手機型號分布情況
- 統計發送人的設備操作系統分布情況
數據內容
- 數據大小:30萬條數據
- 列分隔符:Hive默認分隔符’\001’
- 數據字典及樣例數據

建庫建表
建庫
--如果數據庫已存在就刪除
drop database if exists db_msg cascade ;
--創建數據庫
create database db_msg ;
--切換數據庫
use db_msg ;
--列舉數據庫
show databases ;
建表
--如果表已存在就刪除
drop table if exists db_msg.tb_msg_source ;
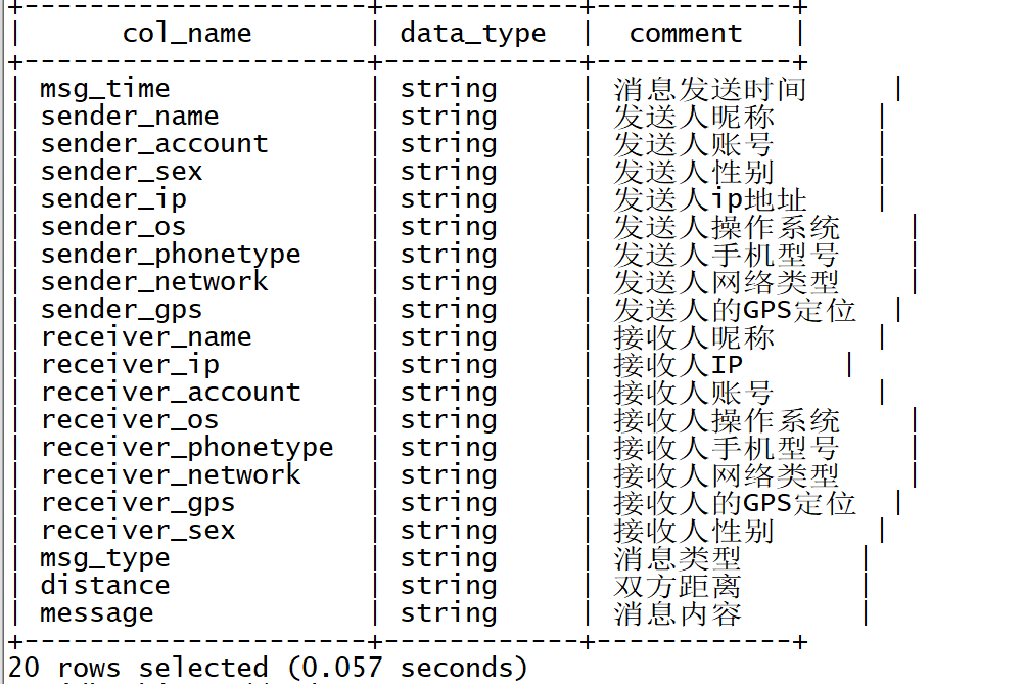
--建表
create table db_msg.tb_msg_source(msg_time string comment "消息發送時間",sender_name string comment "發送人昵稱",sender_account string comment "發送人賬號",sender_sex string comment "發送人性別",sender_ip string comment "發送人ip地址",sender_os string comment "發送人操作系統",sender_phonetype string comment "發送人手機型號",sender_network string comment "發送人網絡類型",sender_gps string comment "發送人的GPS定位",receiver_name string comment "接收人昵稱",receiver_ip string comment "接收人IP",receiver_account string comment "接收人賬號",receiver_os string comment "接收人操作系統",receiver_phonetype string comment "接收人手機型號",receiver_network string comment "接收人網絡類型",receiver_gps string comment "接收人的GPS定位",receiver_sex string comment "接收人性別",msg_type string comment "消息類型",distance string comment "雙方距離",message string comment "消息內容"
);
上傳文件到Linux系統,load數據到表
load data local inpath '/home/hadoop/chat_data-30W.csv' overwrite into table tb_msg_source;
驗證結果
select msg_time, sender_name, sender_ip, sender_phonetype, receiver_name, receiver_network from tb_msg_source limit 10;

11.2 ETL數據清洗
11.2.1 數據問題
- 問題1:當前數據中,有一些數據的字段為空,不是合法數據
select msg_time, sender_name, sender_gps from db_msg.tb_msg_source where length(sender_gps) = 0 limit 10;

- 問題2:需求中,需要統計每天、每個小時的消息量,但是數據中沒有天和小時字段,只有整體時間字段,不好處理
select msg_time from db_msg.tb_msg_source limit 10;
- 問題3:需求中,需要對經度和維度構建地區的可視化地圖,但是數據中GPS經緯度為一個字段,不好處理
select sender_gps from db_msg.tb_msg_source limit 10;
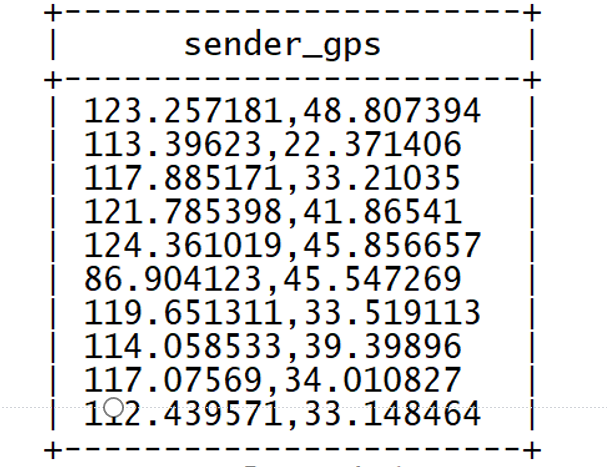
數據清洗的需求
- 需求1:對字段為空的不合法數據進行過濾 - where過濾
- 需求2:通過時間字段構建天和小時字段 - date hour函數
- 需求3:從GPS的經緯度中提取經度和維度 - split函數
- 需求4:將ETL以后的結果保存到一張新的Hive表中
create table db_msg.tb_msg_etl(msg_time string comment "消息發送時間",sender_name string comment "發送人昵稱",sender_account string comment "發送人賬號",sender_sex string comment "發送人性別",sender_ip string comment "發送人ip地址",sender_os string comment "發送人操作系統",sender_phonetype string comment "發送人手機型號",sender_network string comment "發送人網絡類型",sender_gps string comment "發送人的GPS定位",receiver_name string comment "接收人昵稱",receiver_ip string comment "接收人IP",receiver_account string comment "接收人賬號",receiver_os string comment "接收人操作系統",receiver_phonetype string comment "接收人手機型號",receiver_network string comment "接收人網絡類型",receiver_gps string comment "接收人的GPS定位",receiver_sex string comment "接收人性別",msg_type string comment "消息類型",distance string comment "雙方距離",message string comment "消息內容",msg_day string comment "消息日",msg_hour string comment "消息小時",sender_lng double comment "經度",sender_lat double comment "緯度"
);
11.2.2 實現
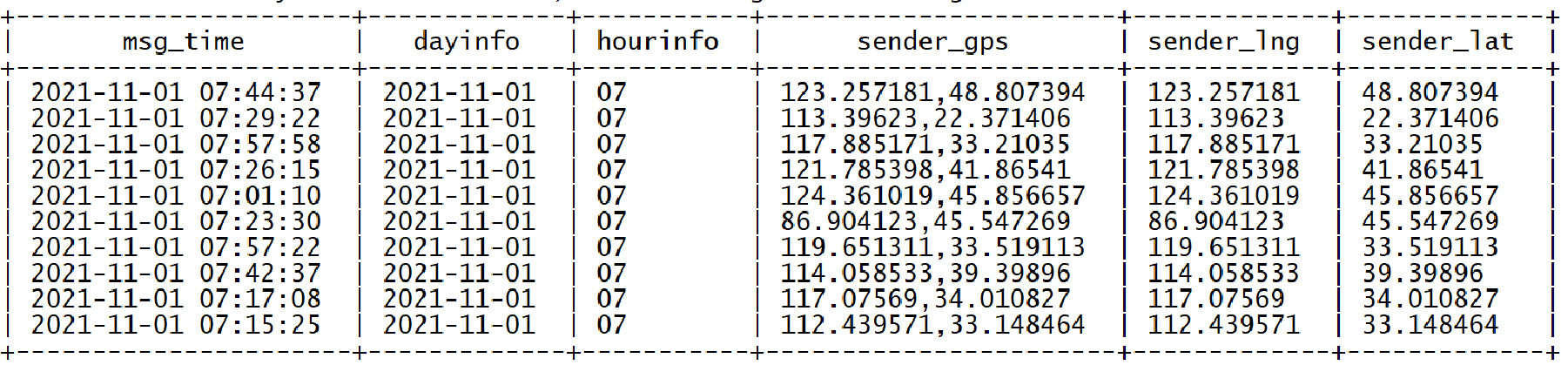
INSERT OVERWRITE TABLE db_msg.tb_msg_etl
SELECT *, day(msg_time) as msg_day, HOUR(msg_time) as msg_hour, split(sender_gps, ',')[0] AS sender_lng,split(sender_gps, ',')[1] AS sender_lat
FROM tb_msg_source WHERE LENGTH(sender_gps) > 0;
查看結果
select msg_time, msy_day, msg_hour, sender_gps, sender_lng, sender_lat from db_msg.tb_msg_etl limit 10;
11.2.3 擴展概念:ETL
其實我們剛剛完成了從表tb_msg_source 查詢數據進行數據過濾和轉換,并將結果寫入到:tb_msg_etl表中的操作,這種操作,本質上是一種簡單的ETL行為。
ETL:
E,Extract,抽取
T,Transform,轉換
L,Load,加載
從A抽取數據(E),進行數據轉換過濾(T),將結果加載到B(L),就是ETL啦。ETL在大數據系統中是非常常見的,后續我們還會繼續接觸到它,目前簡單了解一下即可。
11.3 指標計算
基于Hive完成需求的各個指標計算
需求
- 統計今日總消息量
- 統計今日每小時消息量、發送和接收用戶數
- 統計今日各地區發送消息數據量
- 統計今日發送消息和接收消息的用戶數
- 統計今日發送消息最多的Top10用戶
- 統計今日接收消息最多的Top10用戶
- 統計發送人的手機型號分布情況
- 統計發送人的設備操作系統分布情況
指標1:統計今日消息總量
--保存結果表
CREATE TABLE IF NOT EXISTS tb_rs_total_msg_cnt
COMMENT "每日消息總量" AS
SELECT msg_day, COUNT(*) AS total_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day;

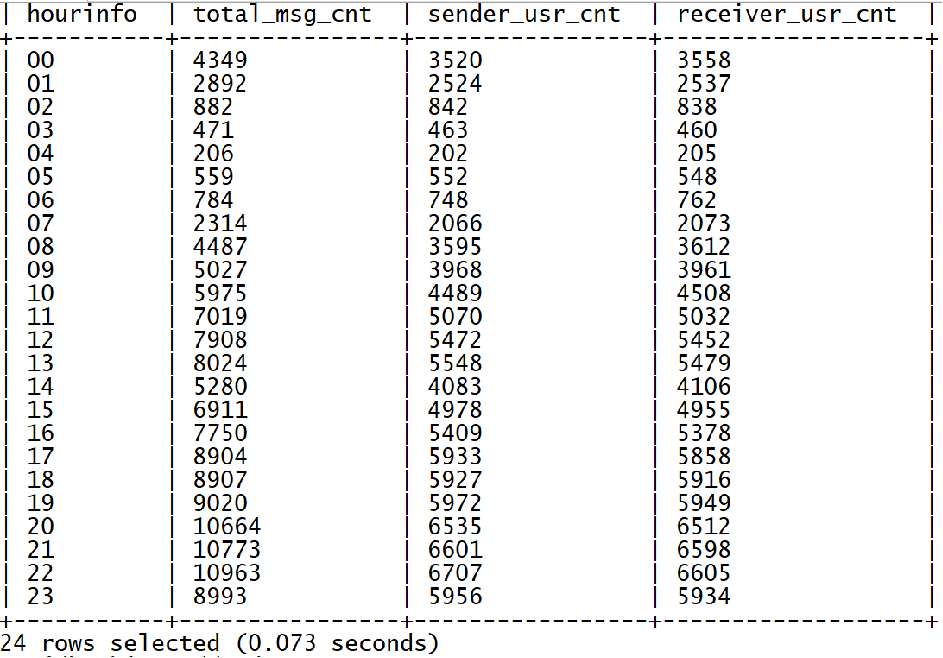
指標2:統計每小時消息量、發送和接收用戶數
--保存結果表
CREATE TABLE IF NOT EXISTS tb_rs_hour_msg_cnt
COMMENT "每小時消息量趨勢" AS
SELECT msg_hour, COUNT(*) AS total_msg_cnt, COUNT(DISTINCT sender_account) AS sender_usr_cnt, COUNT(DISTINCT receiver_account) AS receiver_usr_cnt
FROM db_msg.tb_msg_etl GROUP BY msg_hour;
指標3:統計今日各地區發送消息總量
CREATE TABLE IF NOT EXISTS tb_rs_loc_cnt
COMMENT '今日各地區發送消息總量' AS
SELECT msg_day, sender_lng, sender_lat, COUNT(*) AS total_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day, sender_lng, sender_lat;
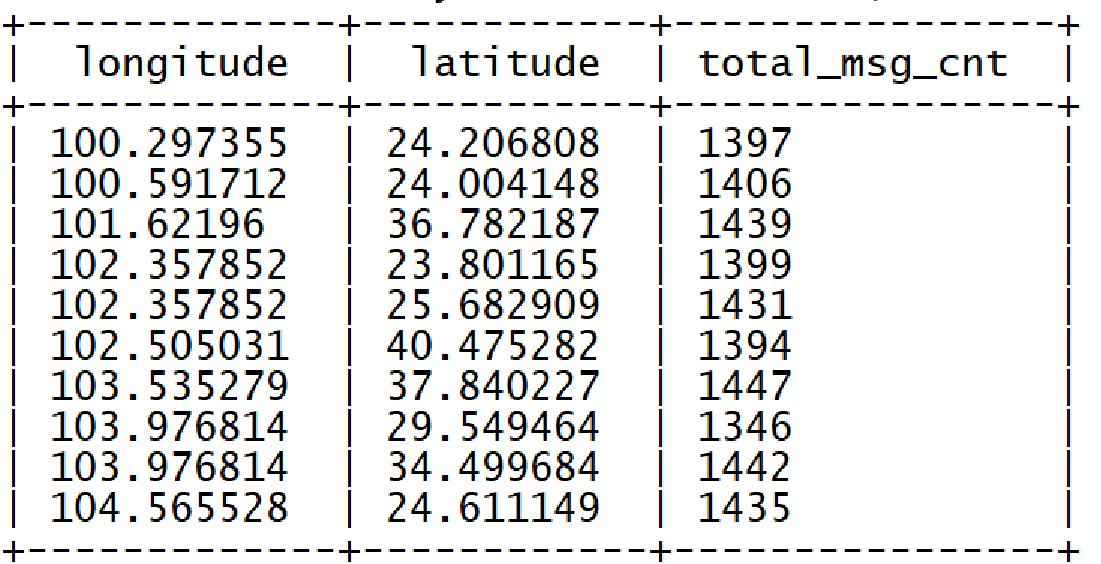
指標4:統計今日發送和接收用戶人數
--保存結果表
CREATE TABLE IF NOT EXISTS tb_rs_usr_cnt
COMMENT "今日發送消息人數、接受消息人數" AS
SELECT
msg_day,
COUNT(DISTINCT sender_account) AS sender_usr_cnt,
COUNT(DISTINCT receiver_account) AS receiver_usr_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day;

指標5:統計發送消息條數最多的Top10用戶
--保存結果表
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_s_user_top10
COMMENT "發送消息條數最多的Top10用戶" AS
SELECT sender_name AS username, COUNT(*) AS sender_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_name
ORDER BY sender_msg_cnt DESC
LIMIT 10;

指標6:統計接收消息條數最多的Top10用戶
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_r_user_top10
COMMENT "接收消息條數最多的Top10用戶" AS
SELECT
receiver_name AS username,
COUNT(*) AS receiver_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY receiver_name
ORDER BY receiver_msg_cnt DESC
LIMIT 10;

指標7:統計發送人的手機型號分布情況
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_sender_phone
COMMENT "發送人的手機型號分布" AS
SELECT sender_phonetype, COUNT(sender_account) AS cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_phonetype;

指標8:統計發送人的手機操作系統分布
--保存結果表
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_sender_os
COMMENT "發送人的OS分布" AS
SELECTsender_os, COUNT(sender_account) AS cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_os

十二 可視化展現
12.1 BI工具
BI:Business Intelligence,商業智能。
指用現代數據倉庫技術、線上分析處理技術、數據挖掘和數據展現技術進行數據分析以實現商業價值。
簡單來說,就是借助BI工具,可以完成復雜的數據分析、數據統計等需求,為公司決策帶來巨大的價值。
所以,一般提到BI,我們指代的就是工具軟件。常見的BI軟件很多,比如:
- FineBI
- SuperSet
- PowerBI
- TableAu
- 等
12.2 FineBI的介紹及安裝
FineBI的介紹:https://www.finebi.com/
FineBI 是帆軟軟件有限公司推出的一款商業智能(Business Intelligence)產品。FineBI 是定位于自助大數據分析的 BI 工具,能夠幫助企業的業務人員和數據分析師,開展以問題導向的探索式分析。
FineBI的特點
- 通過多人協作來實現最終的可視化構建
- 不需要通過復雜代碼來實現開發,通過可視化操作實現開發
- 適合于各種數據可視化的應用場景
- 支持各種常見的分析圖表和各種數據源
- 支持處理大數據

啟動登陸
目錄、首頁大屏及幫助文檔
儀表盤:用于構建所有可視化報表
數據準備:用于配置各種報表的數據來源
管理系統:用于管理整個FineBI的使用:用戶管理、數據源管理、插件管理、權限管理等
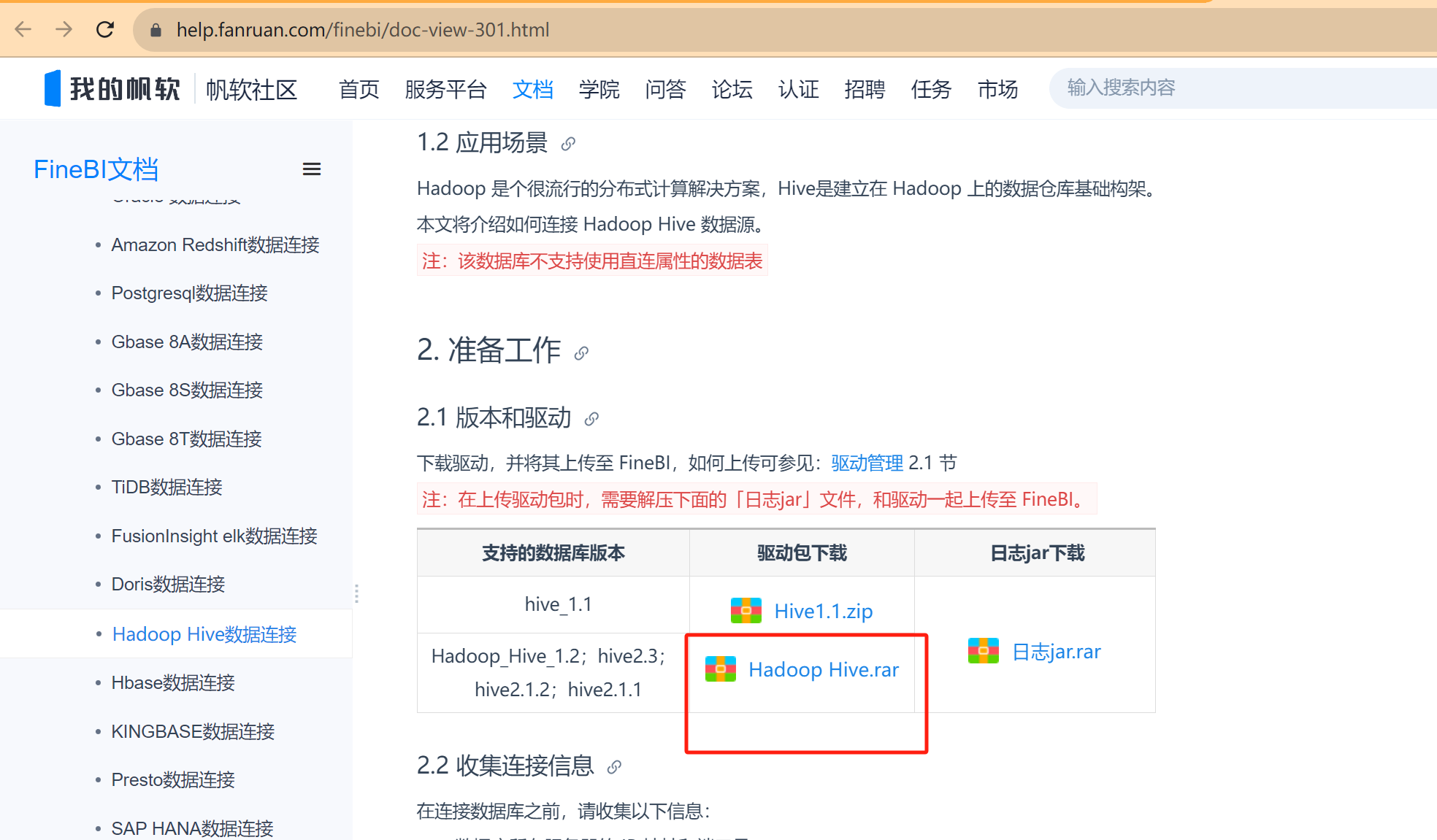
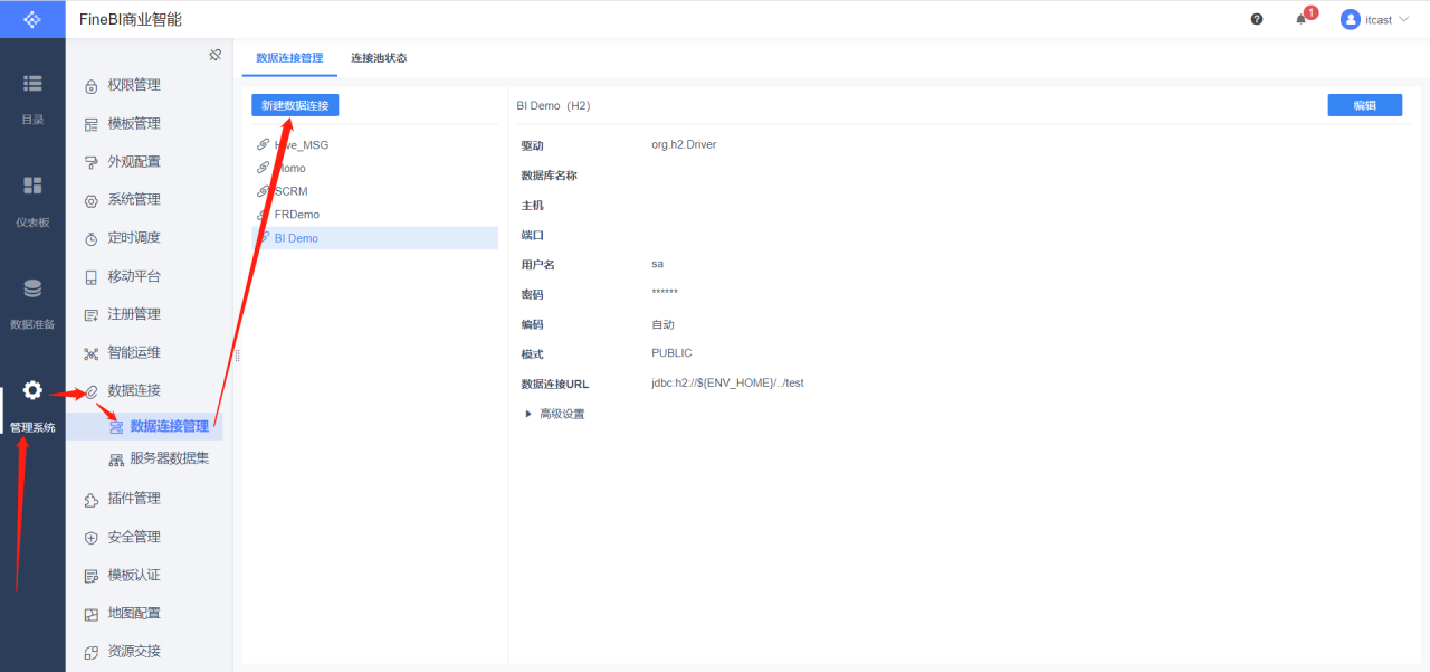
FineBI與Hive集成的官方文檔:https://help.fanruan.com/finebi/doc-view-301.html
驅動配置
- 問題:如果使用FineBI連接Hive,讀取Hive的數據表,需要在FineBI中添加Hive的驅動jar包
- 解決:將Hive的驅動jar包放入FineBI的lib目錄下(webapps\webroot\WEB-INF\lib)
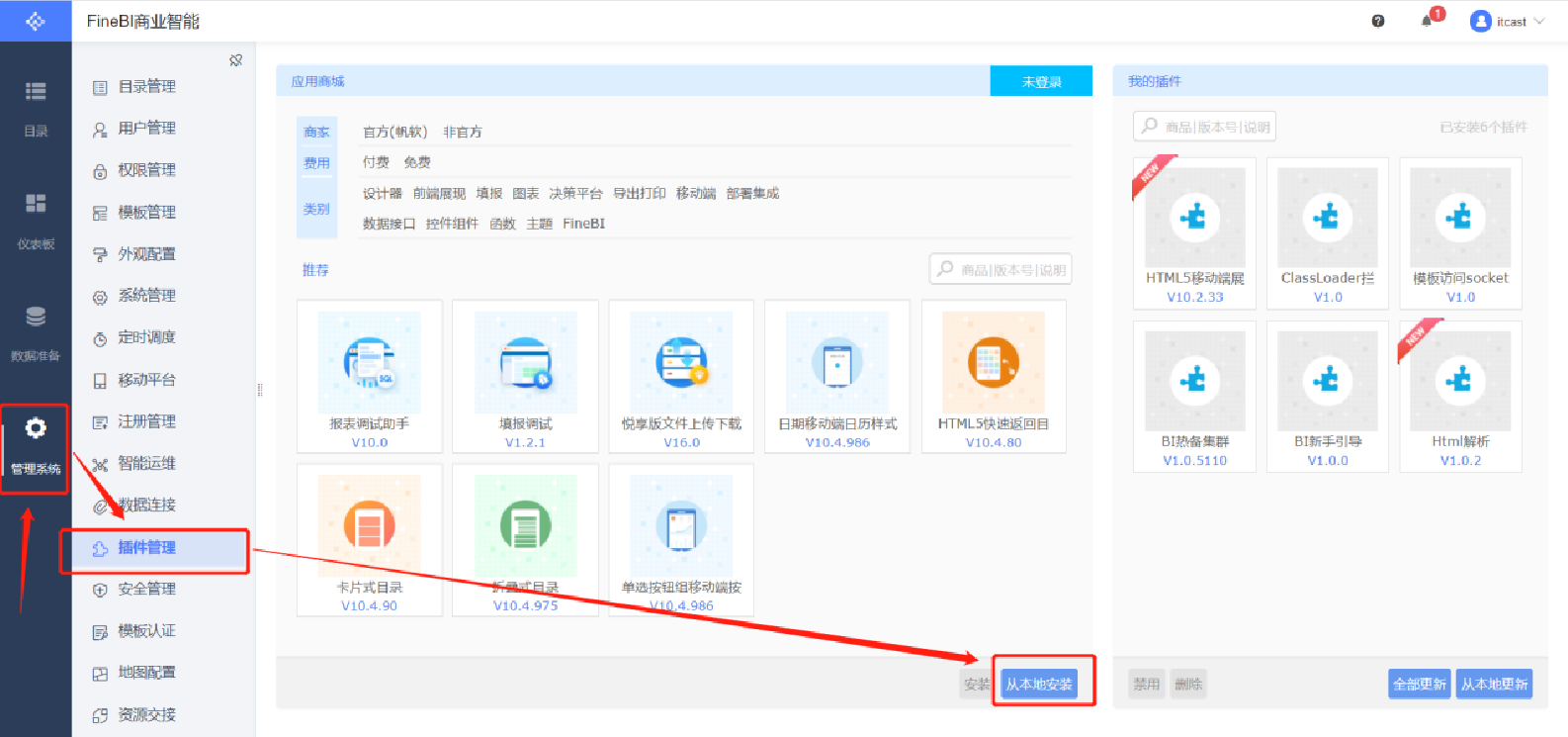
插件安裝
- 問題:我們自己放的Hive驅動包會與FineBI自帶的驅動包產生沖突,導致FineBI無法識別我們自己的驅動包
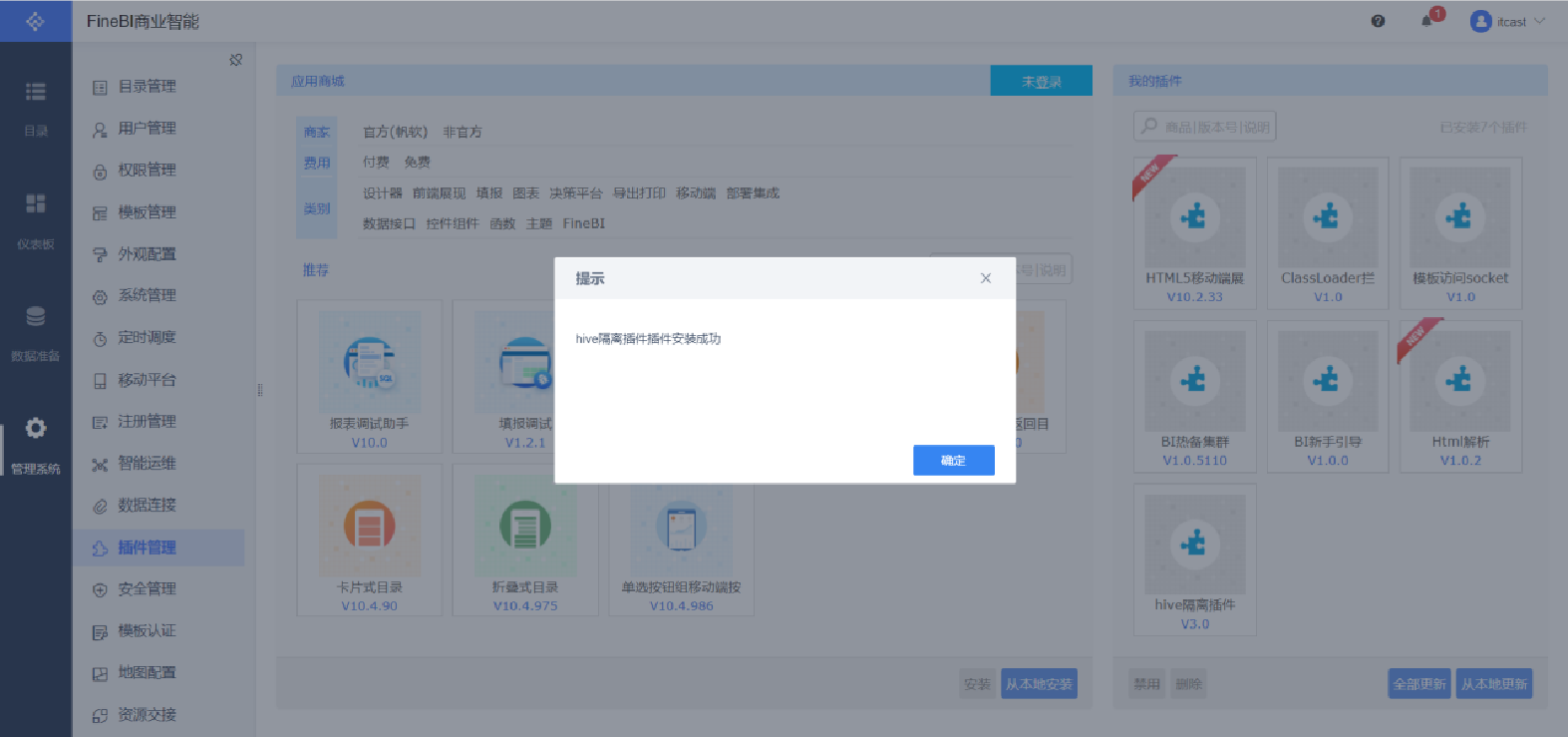
- 解決:安裝FineBI官方提供的驅動包隔離插件:隔離插件下載
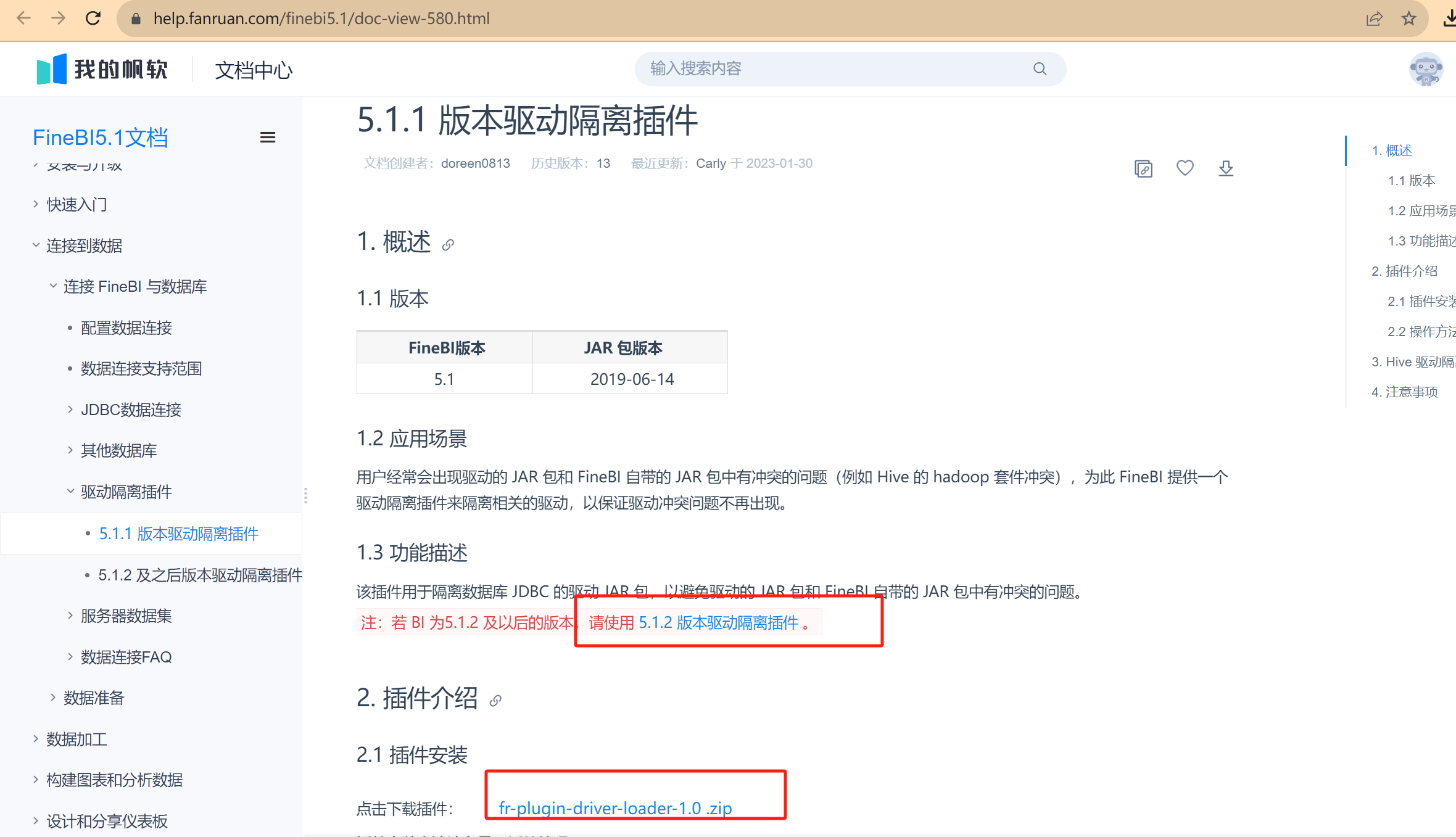
安裝插件
構建連接

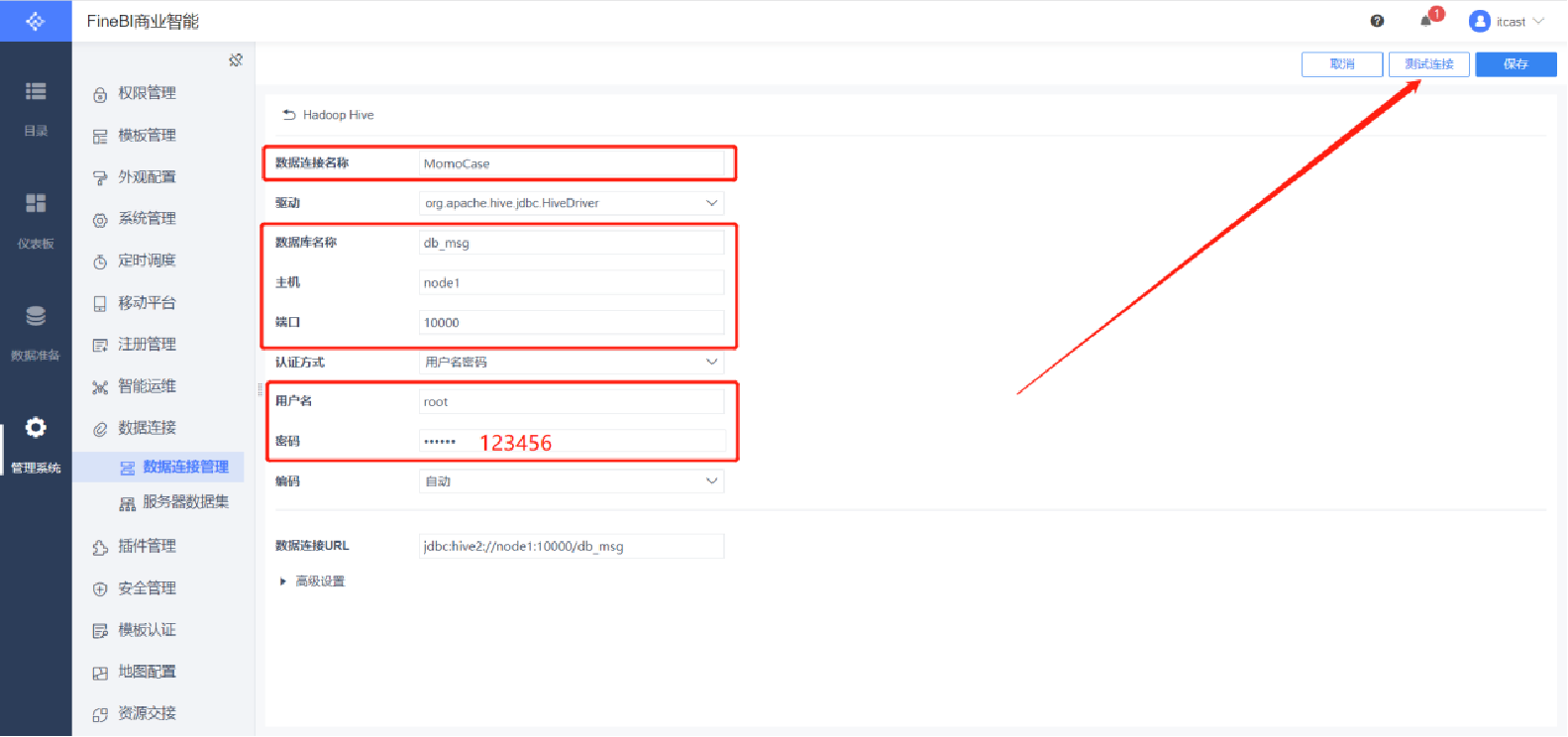
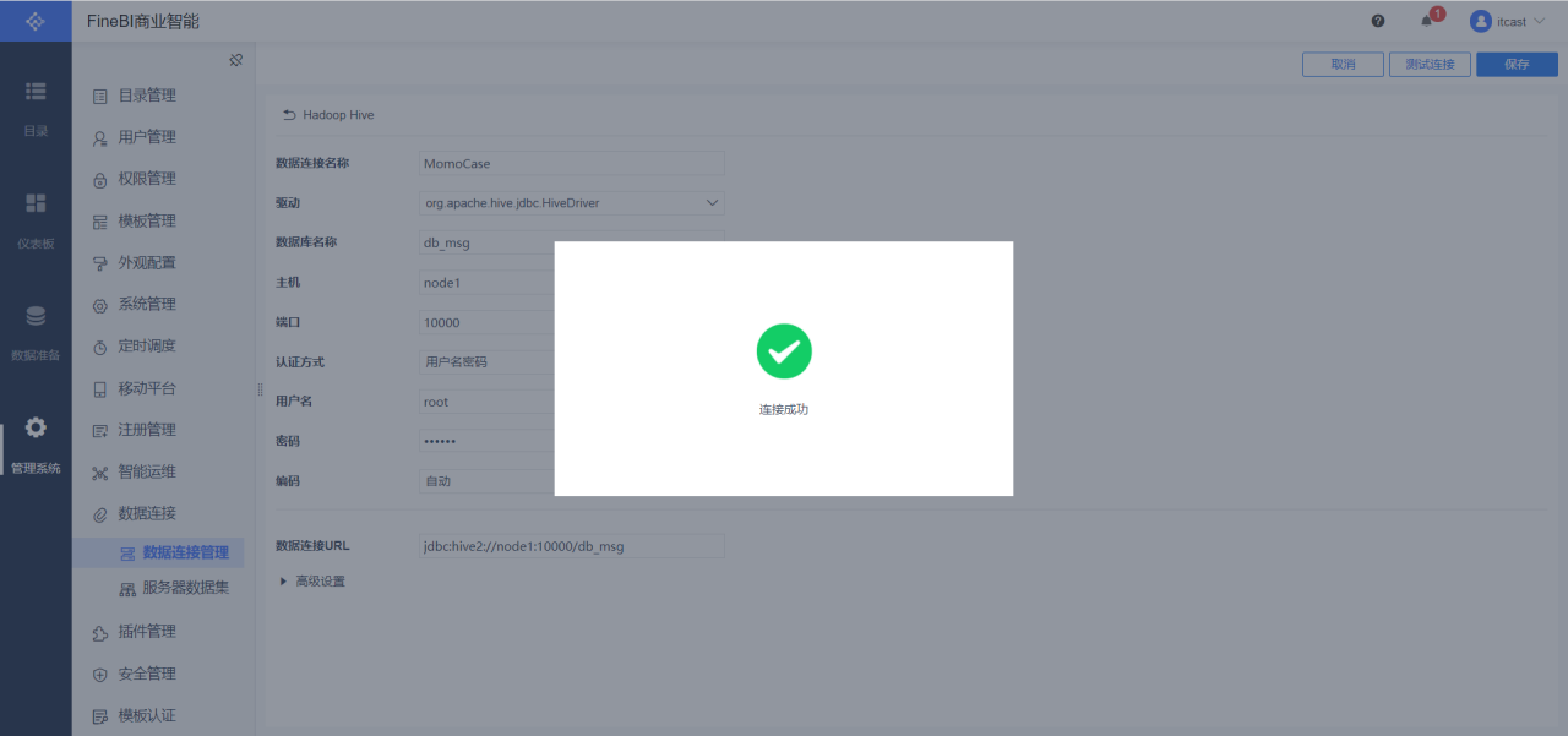
保存連接
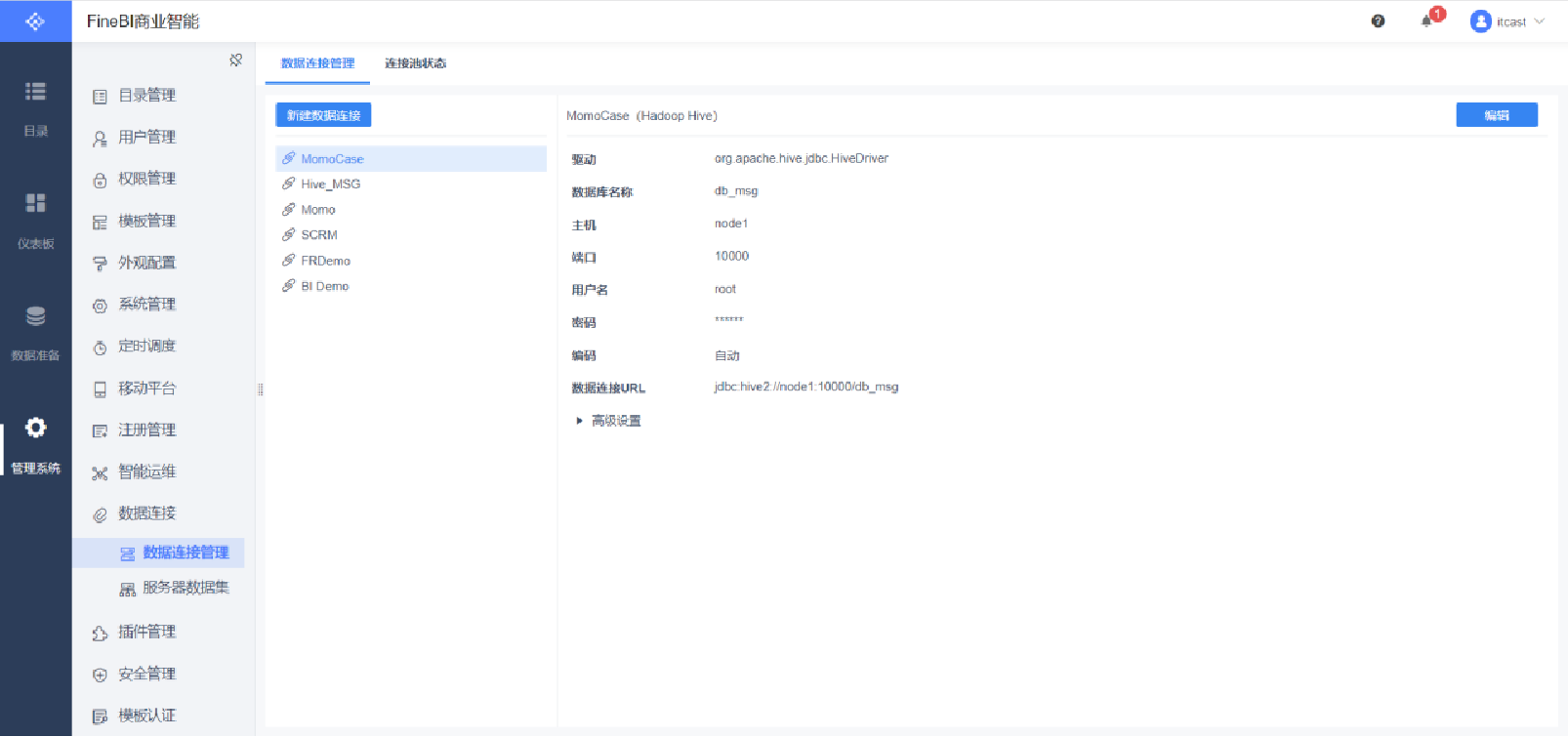
數據準備
新建分組
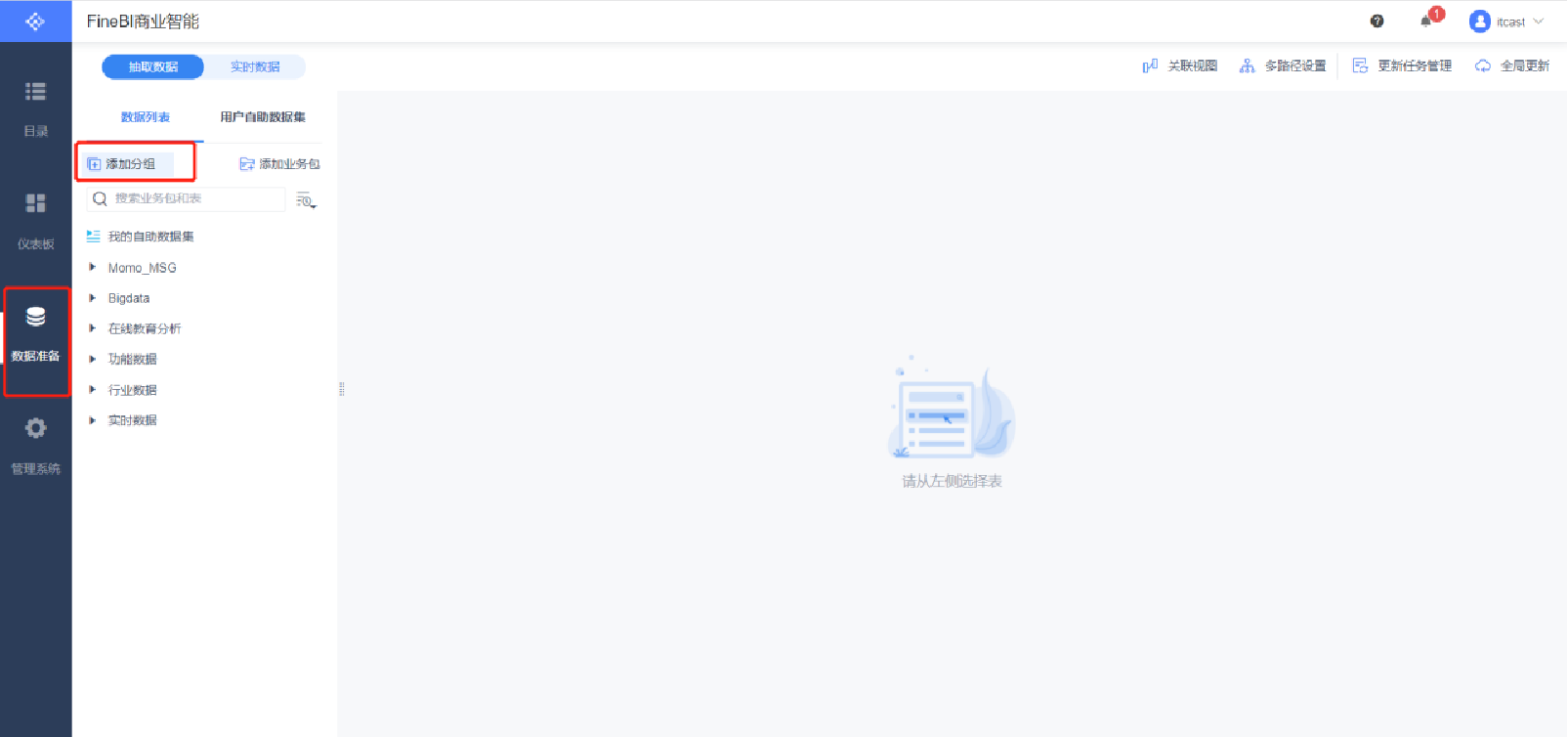
添加業務包
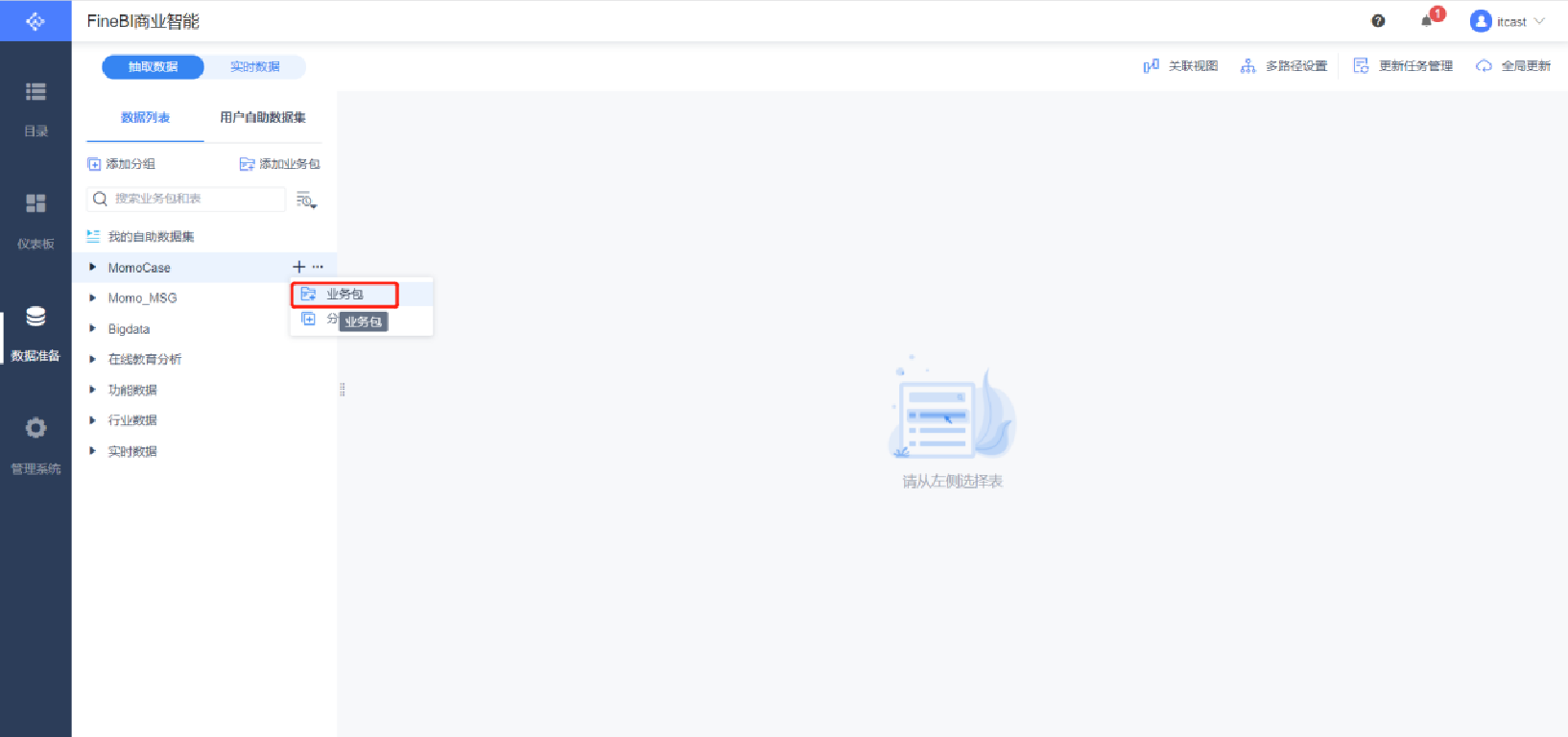
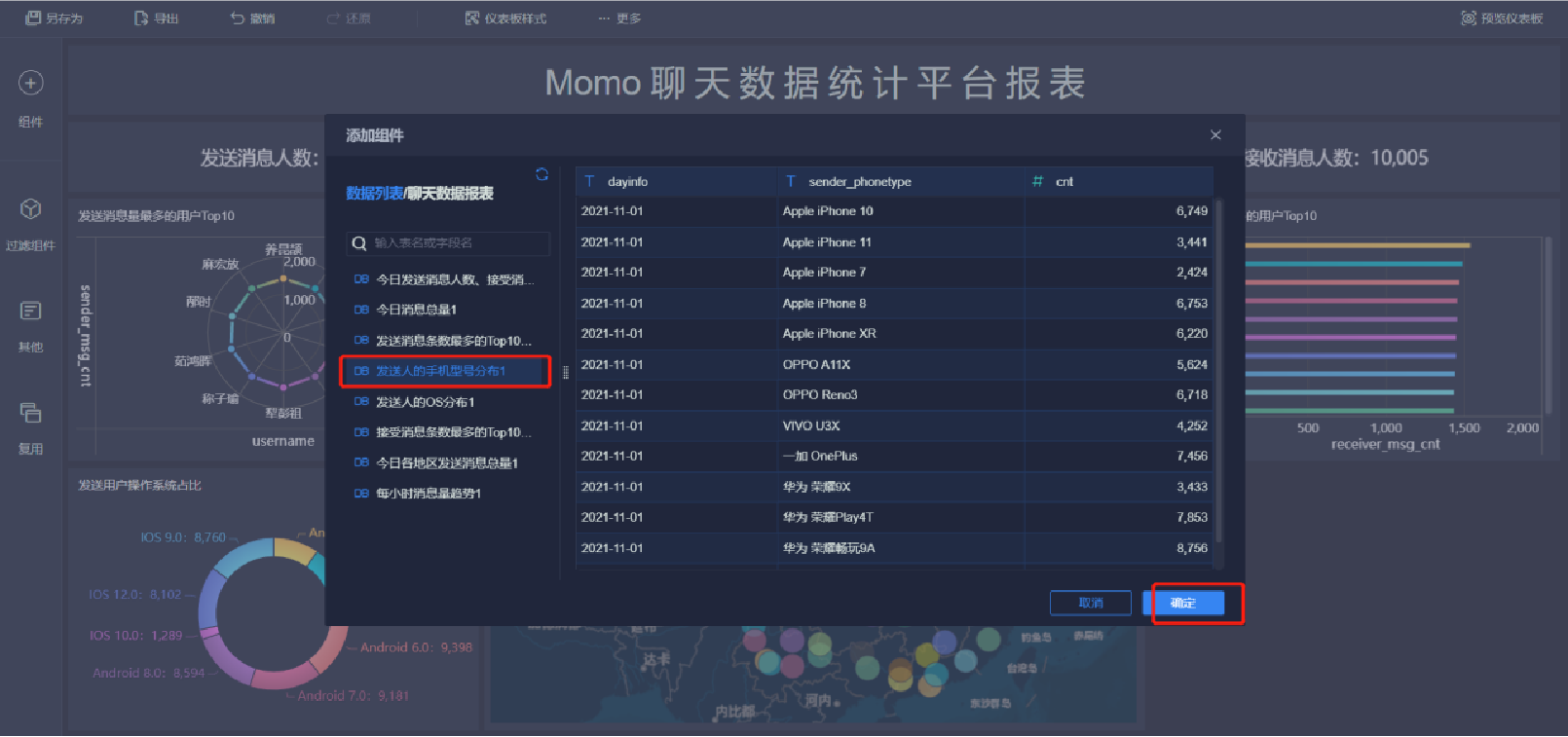
添加表
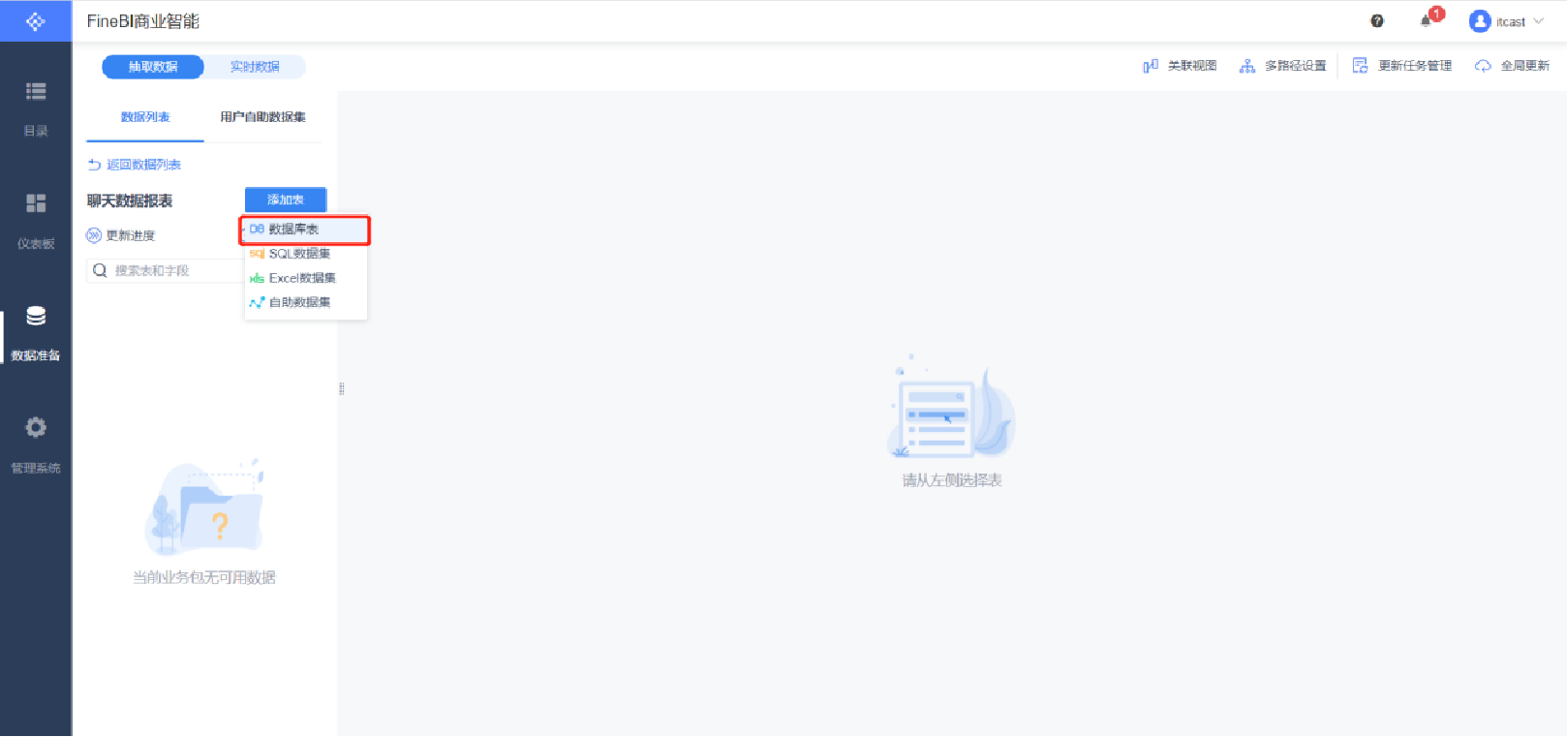
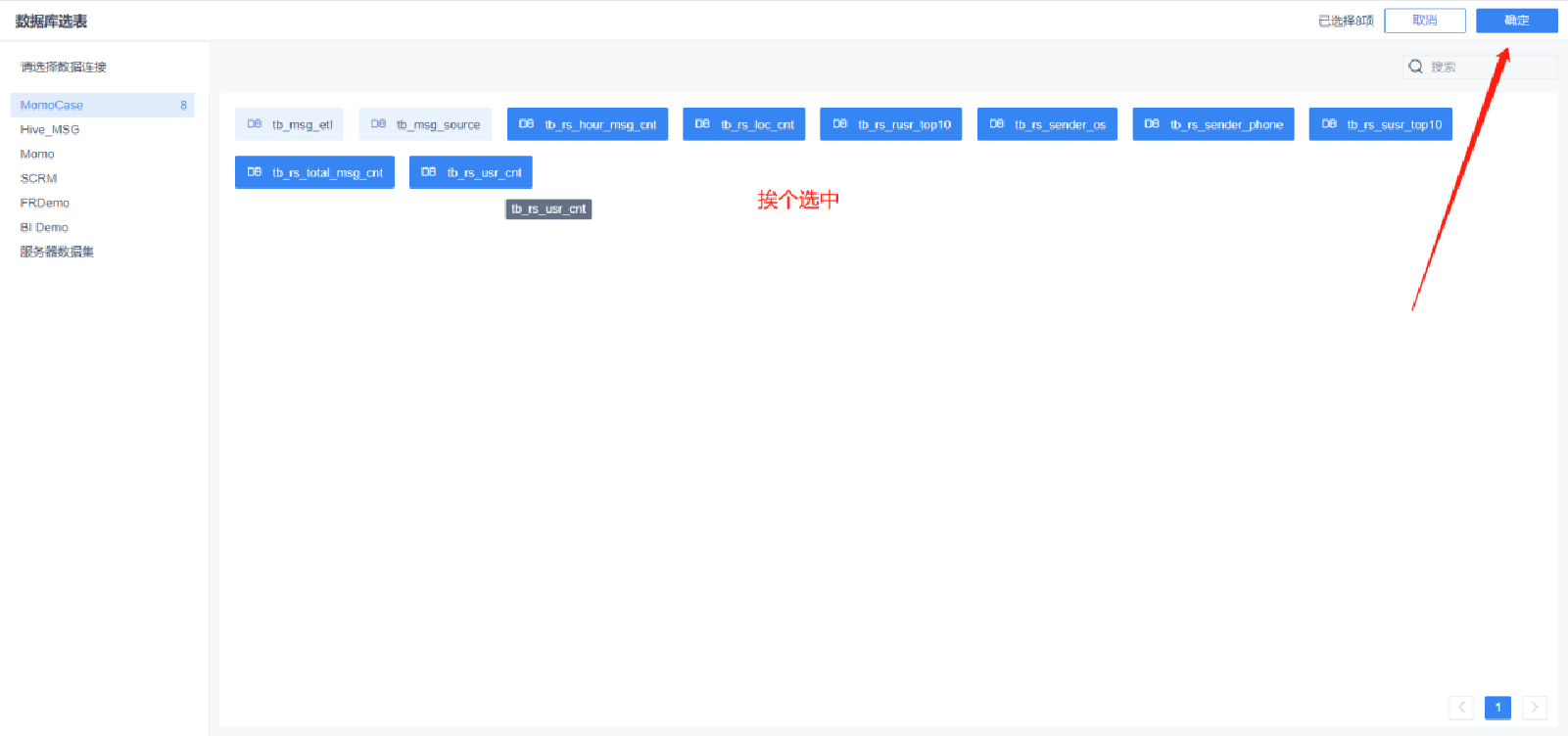
更新業務包
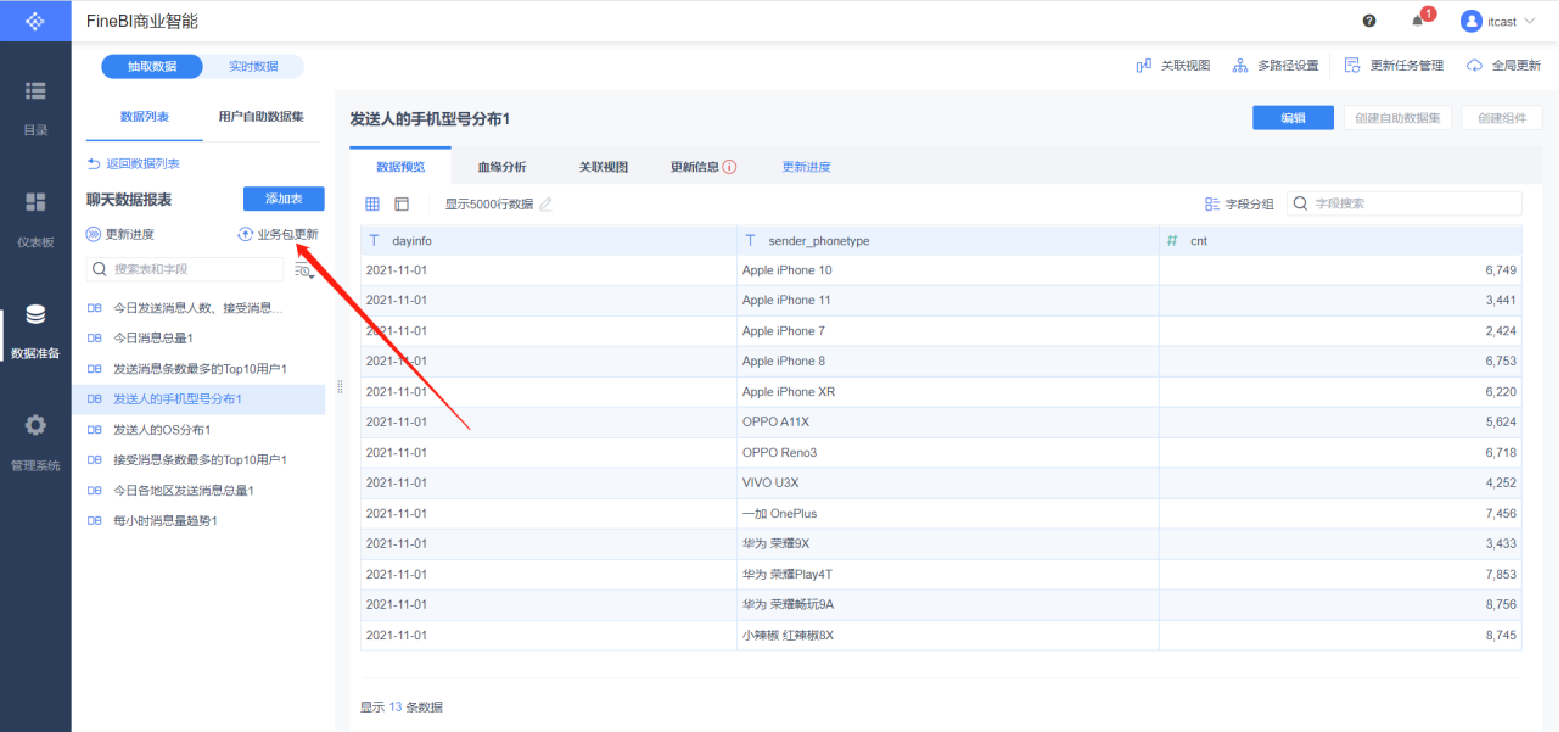
12.3可視化展現
基于FineBI完成指標的可視化展現
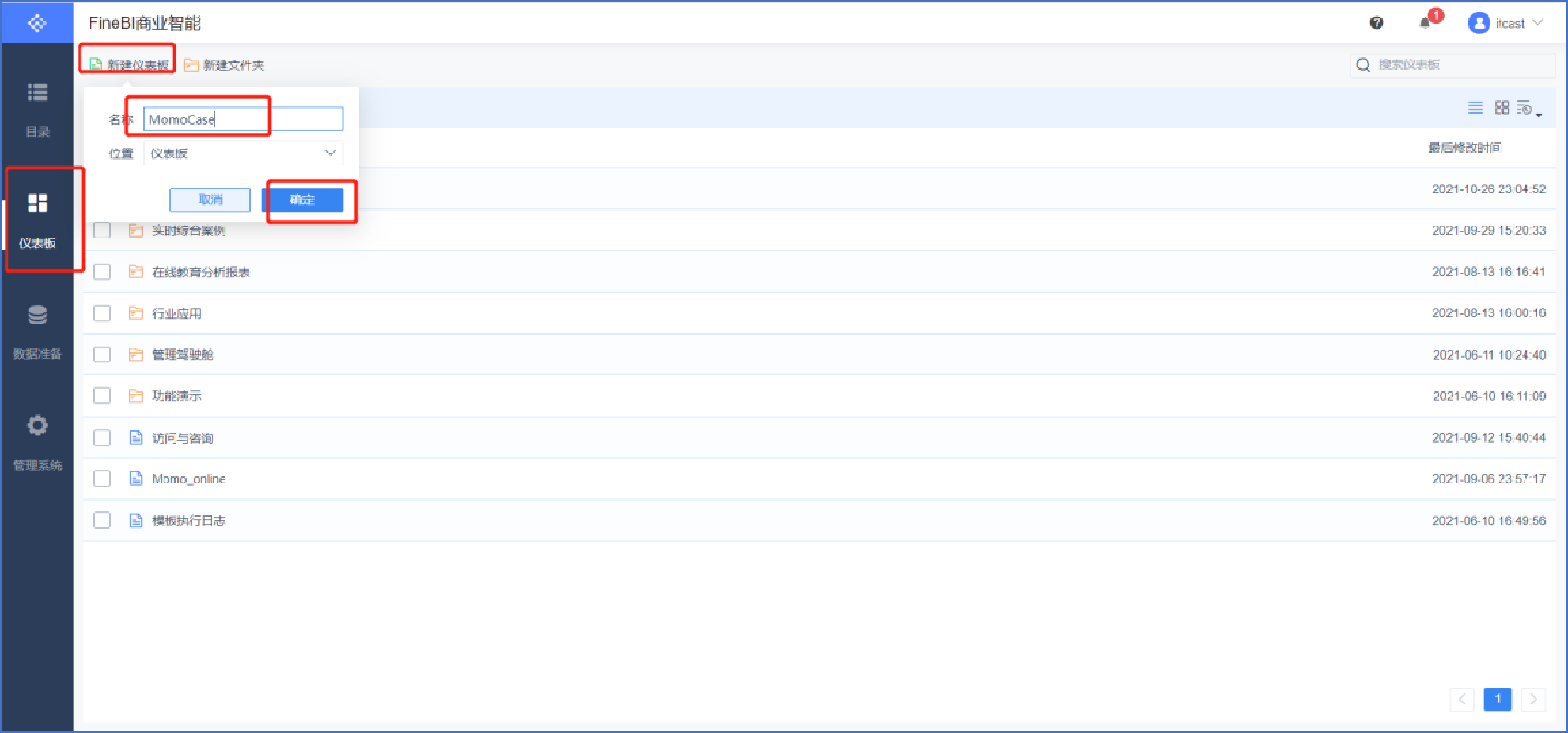
創建報表
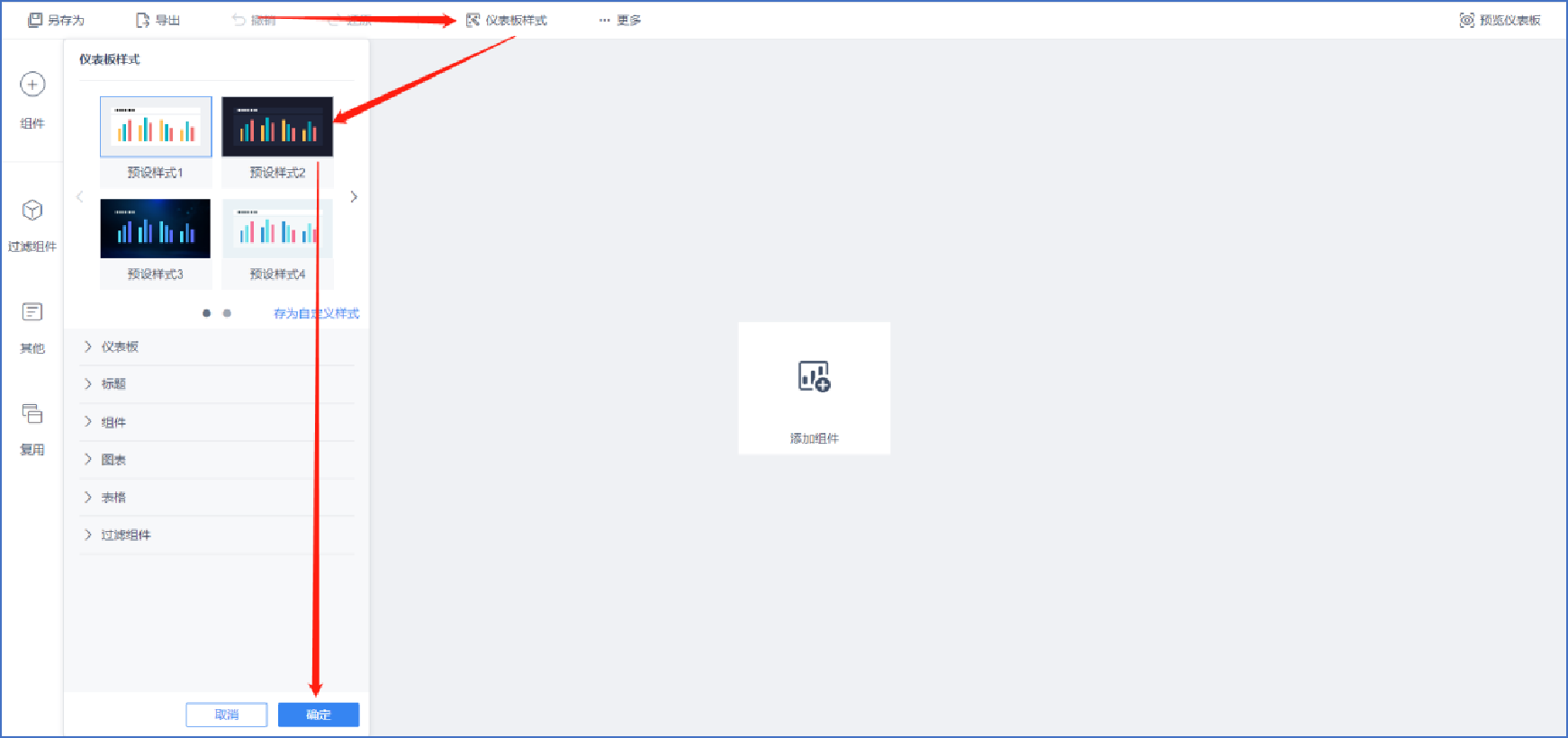
選擇儀表板樣式
添加標題
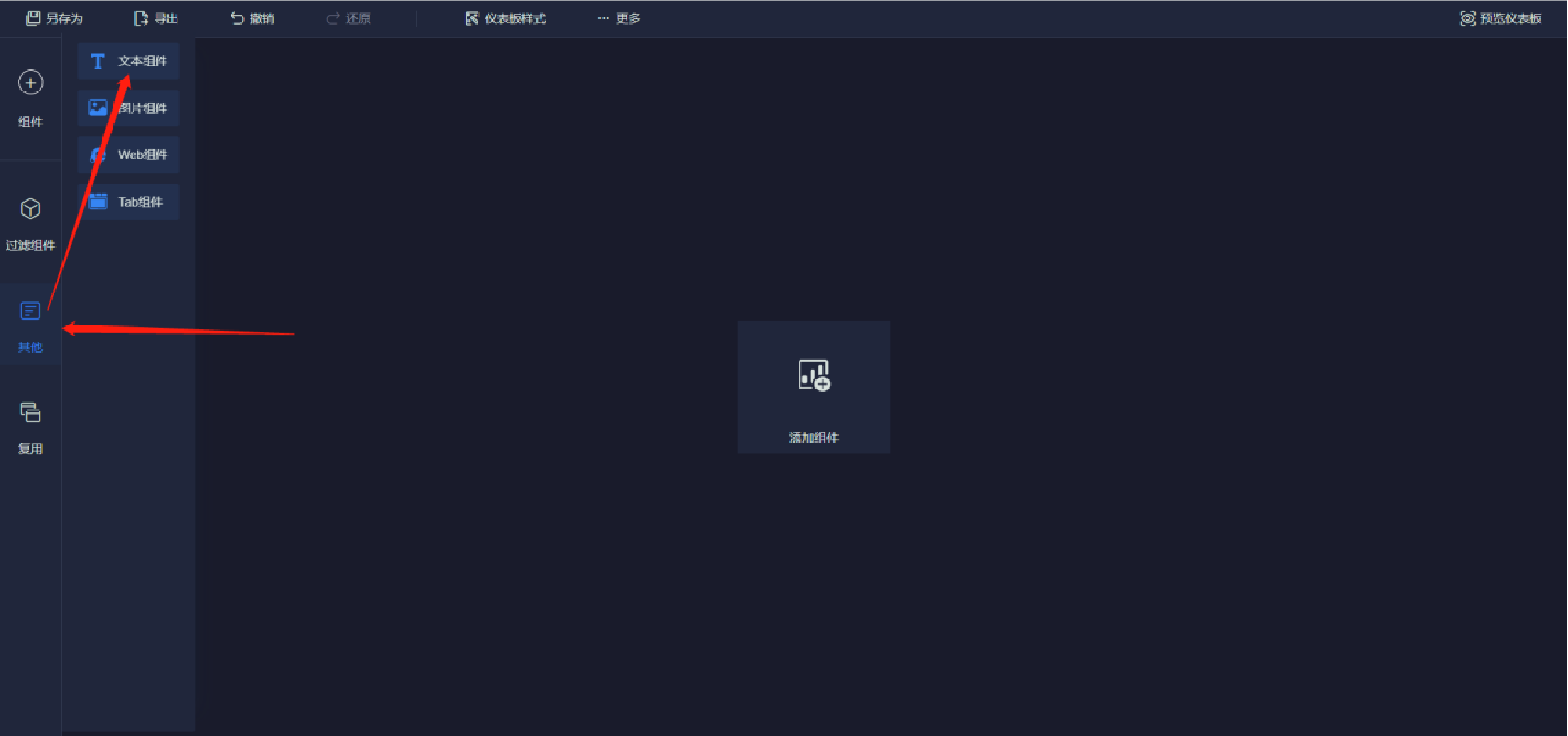
編輯標題文本框(注意字體大小、居中、文本框位置可調整)
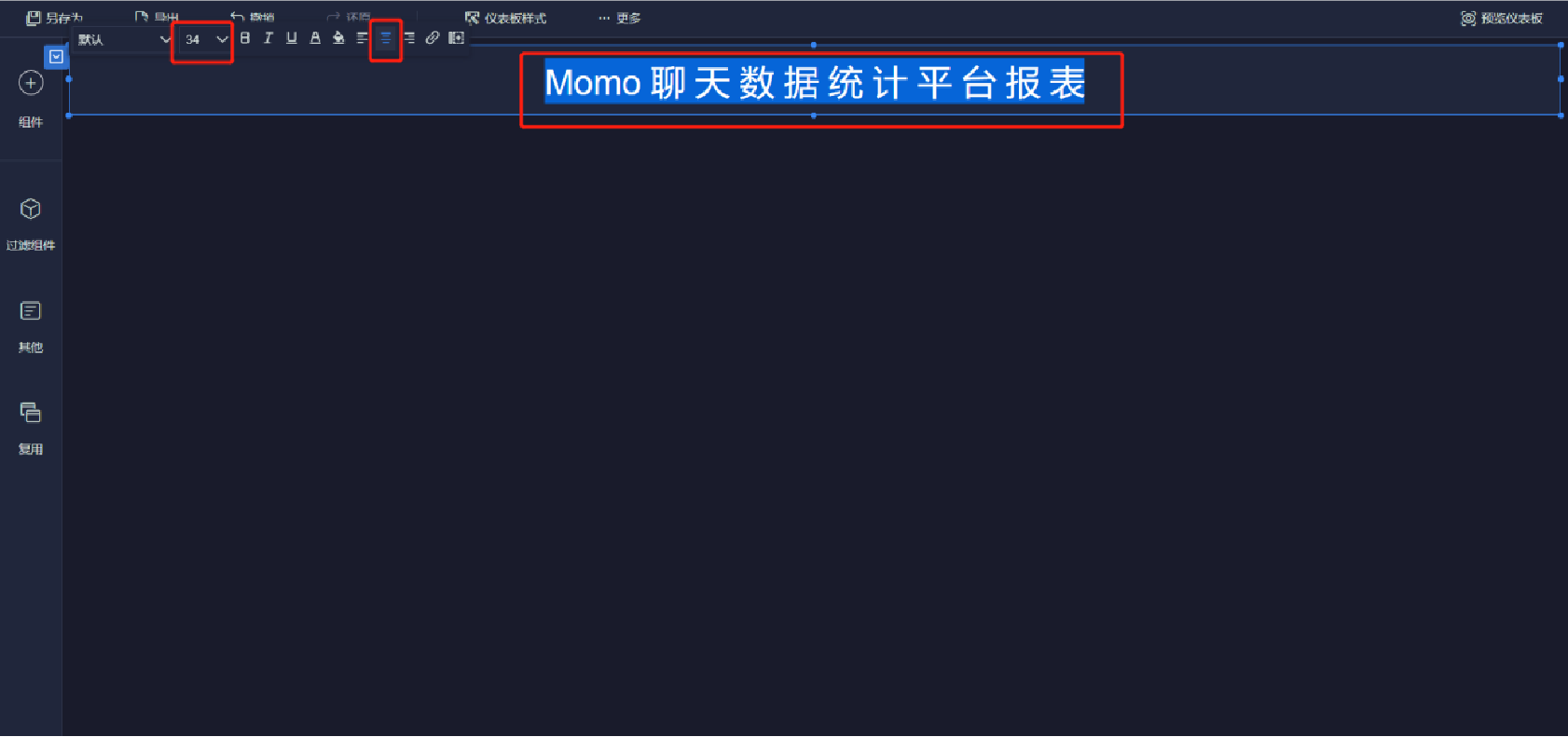
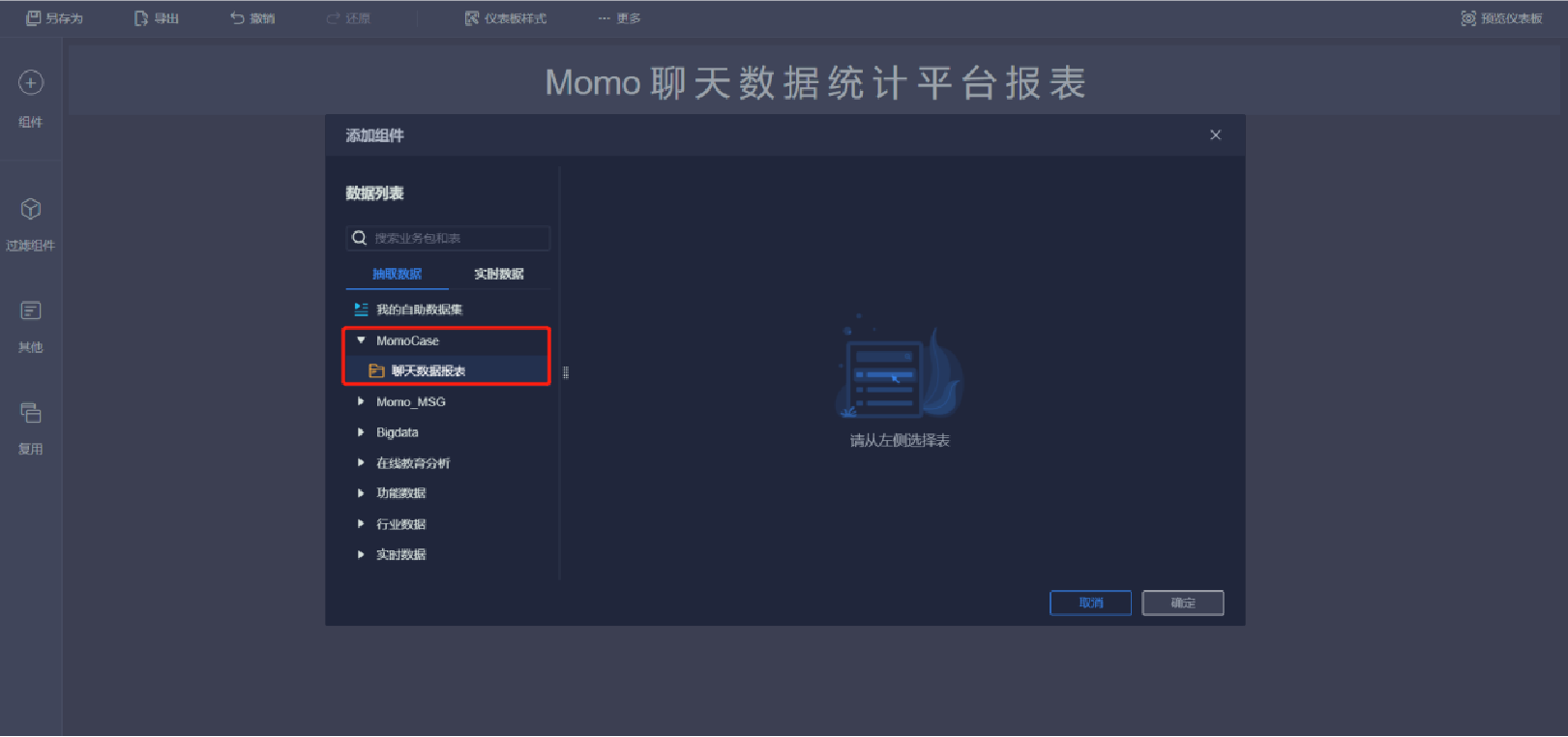
添加文本內容(1/10)
添加文本內容(2/10)
添加文本內容(3/10)
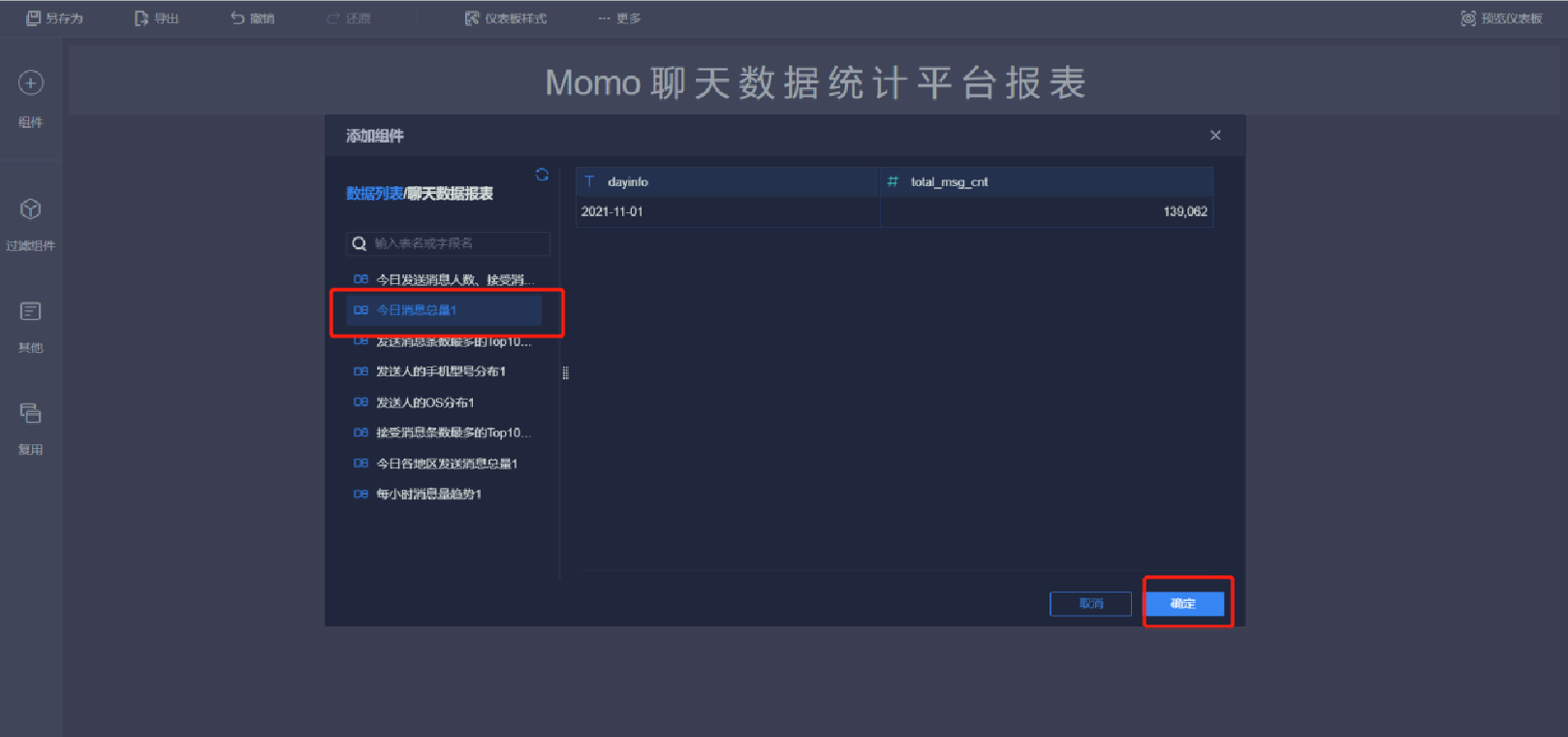
添加文本內容(4/10)
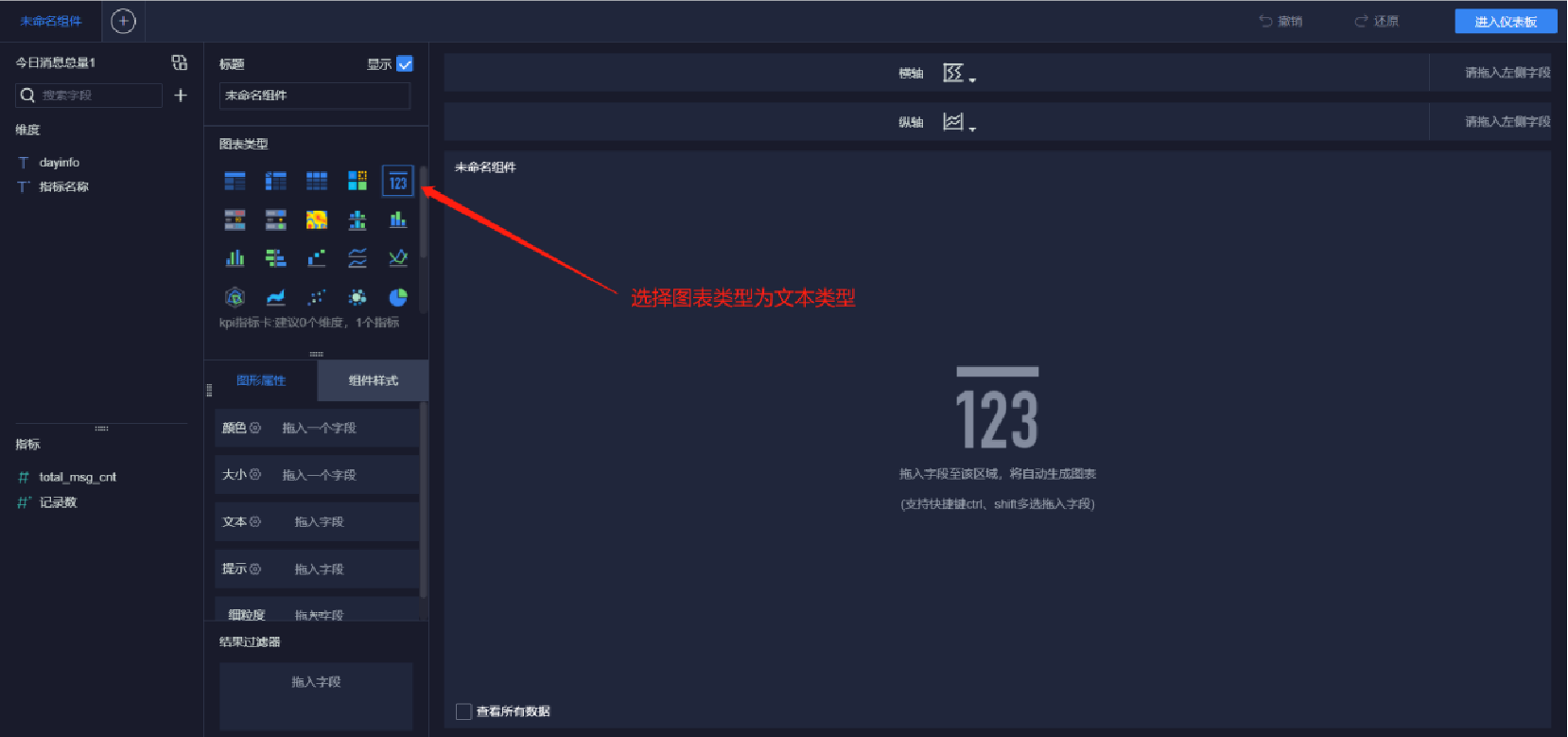
添加文本內容(5/10)
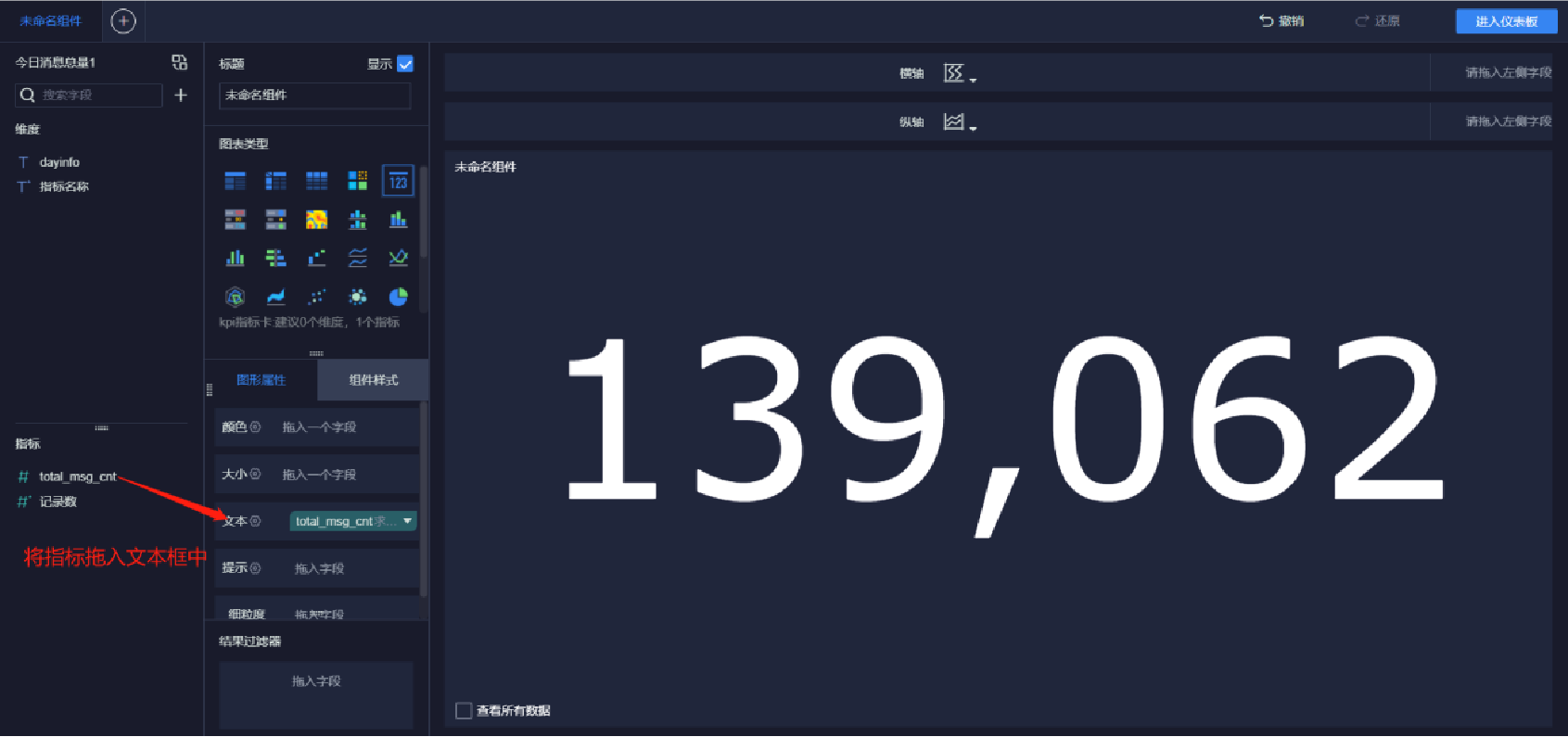
添加文本內容(6/10)
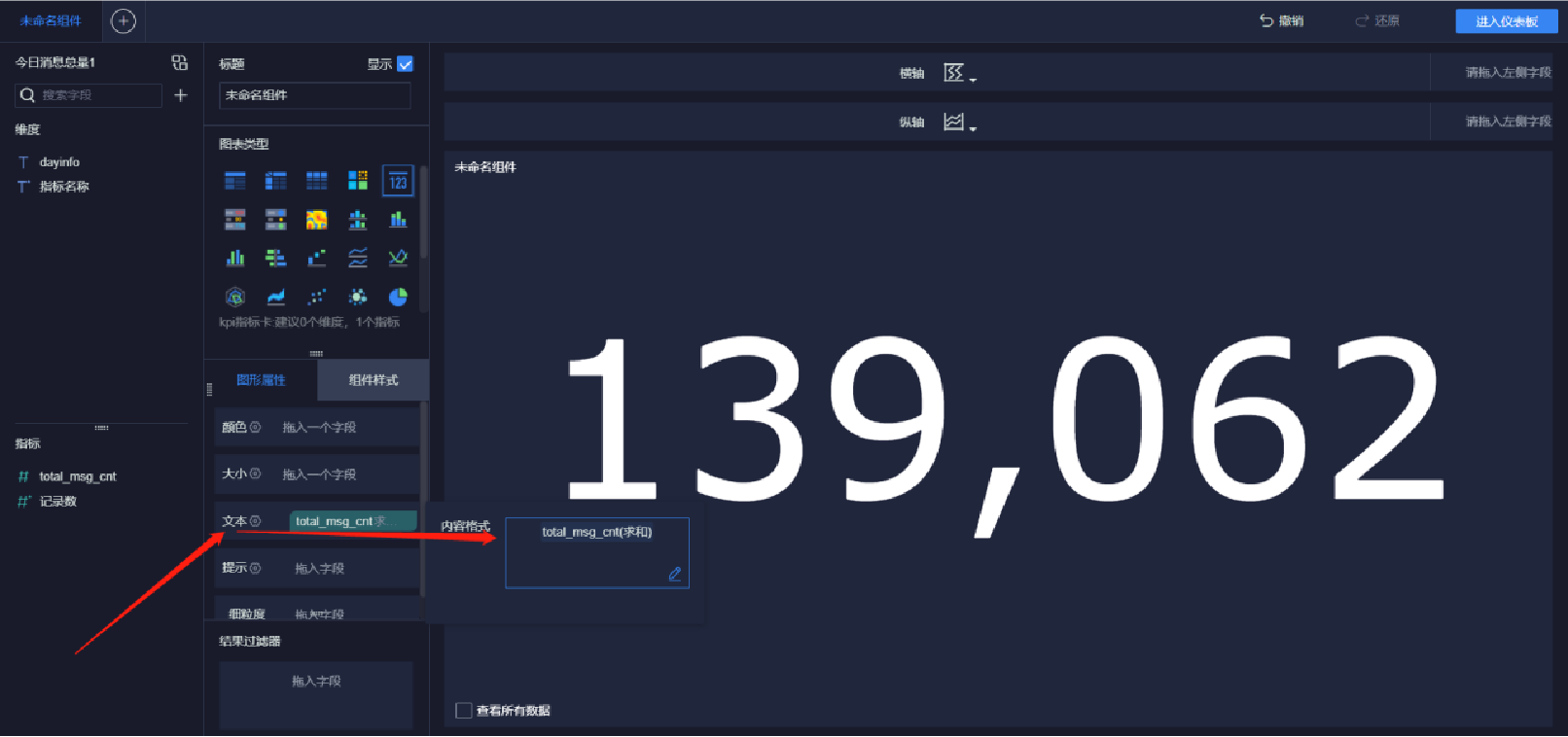
添加文本內容(7/10)
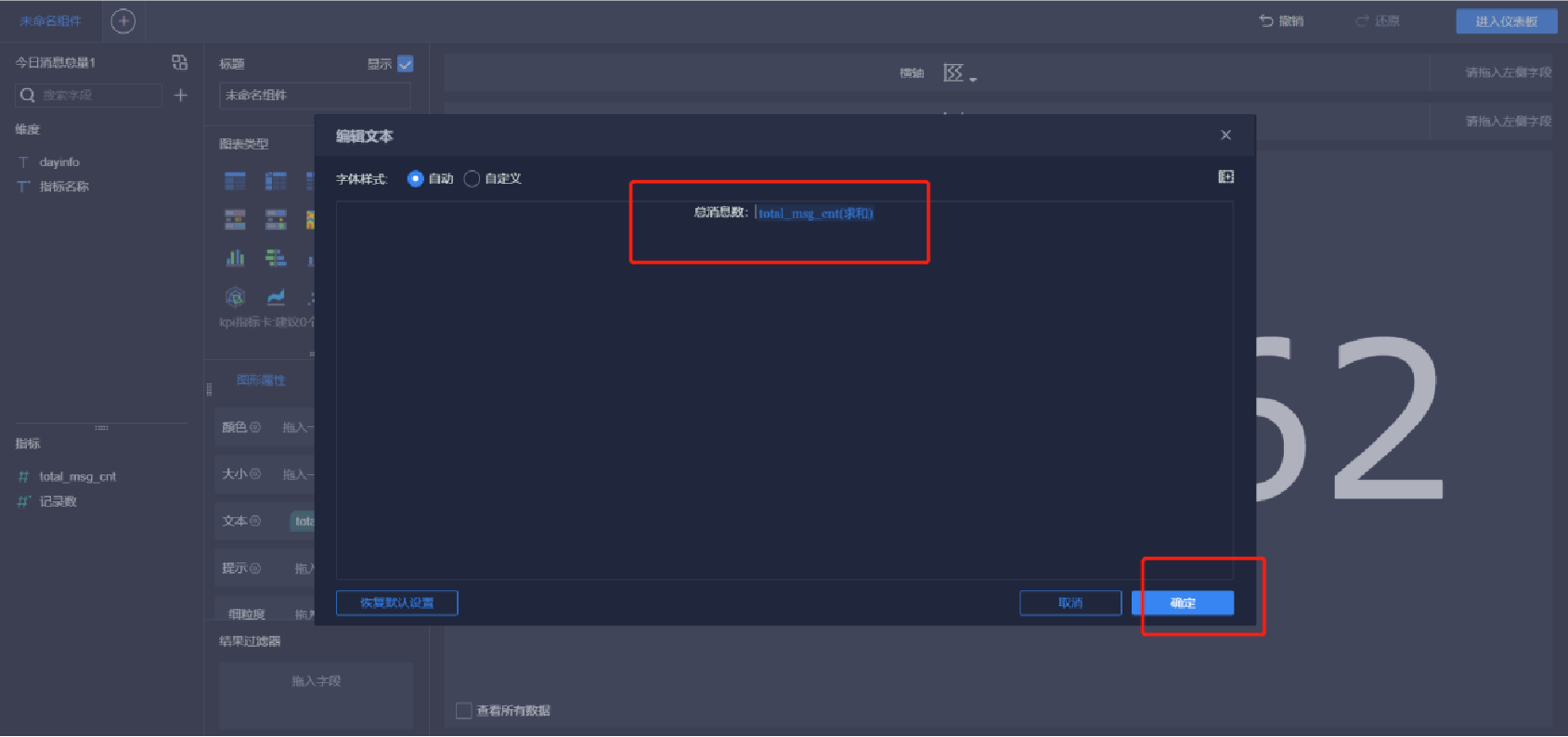
添加文本內容(8/10)
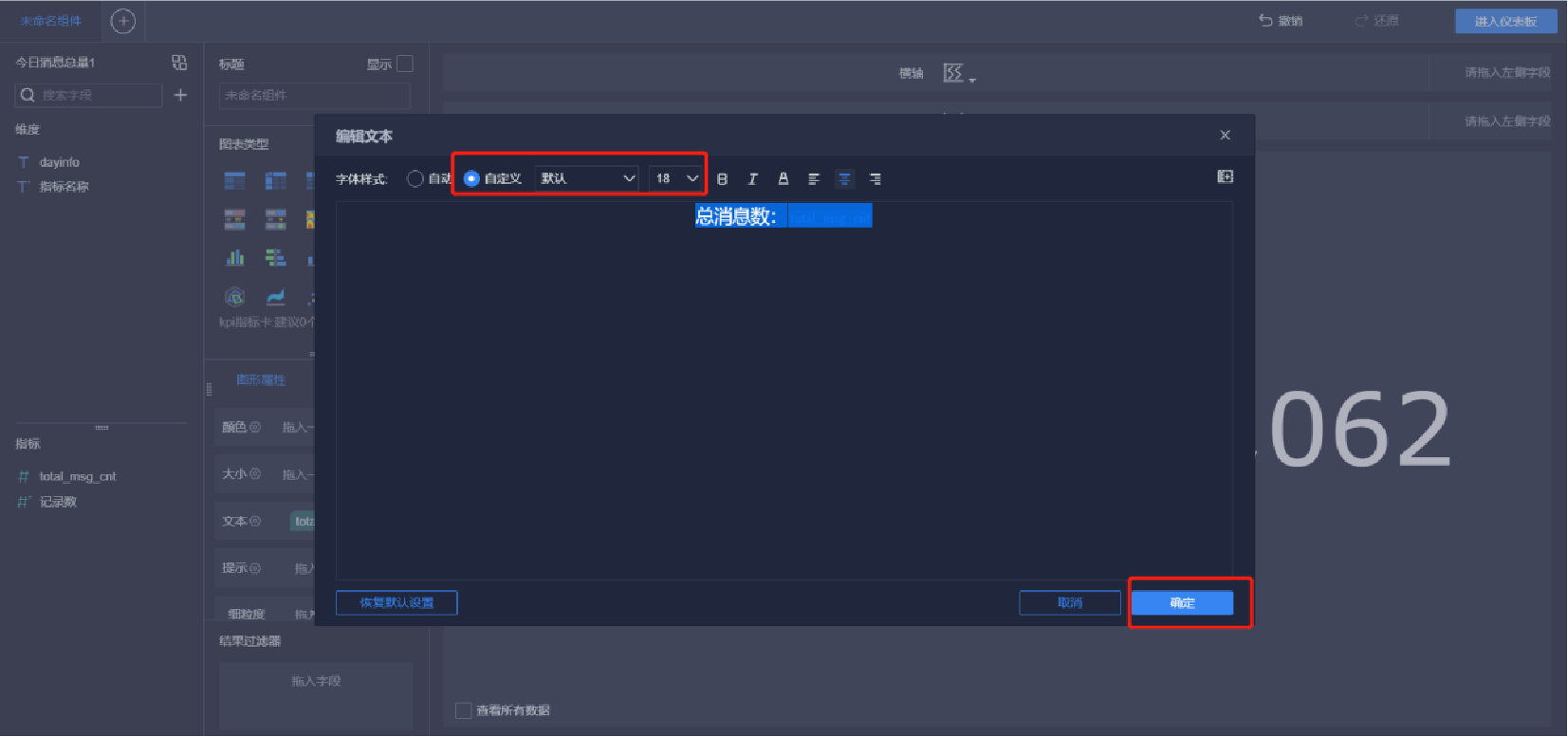
添加文本內容(9/10)
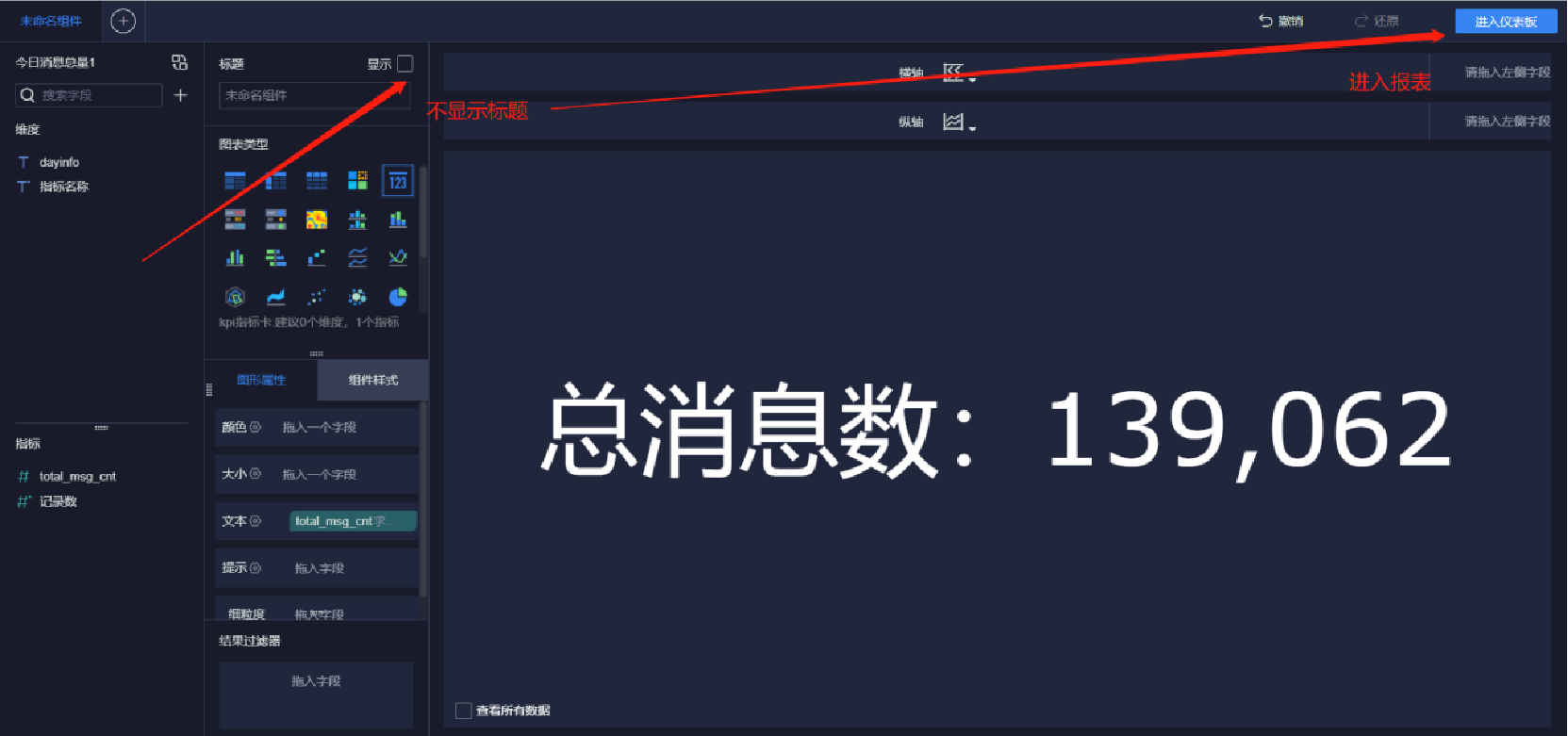
添加文本內容(10/10),同理添加總發送消息人數和總接收消息人數
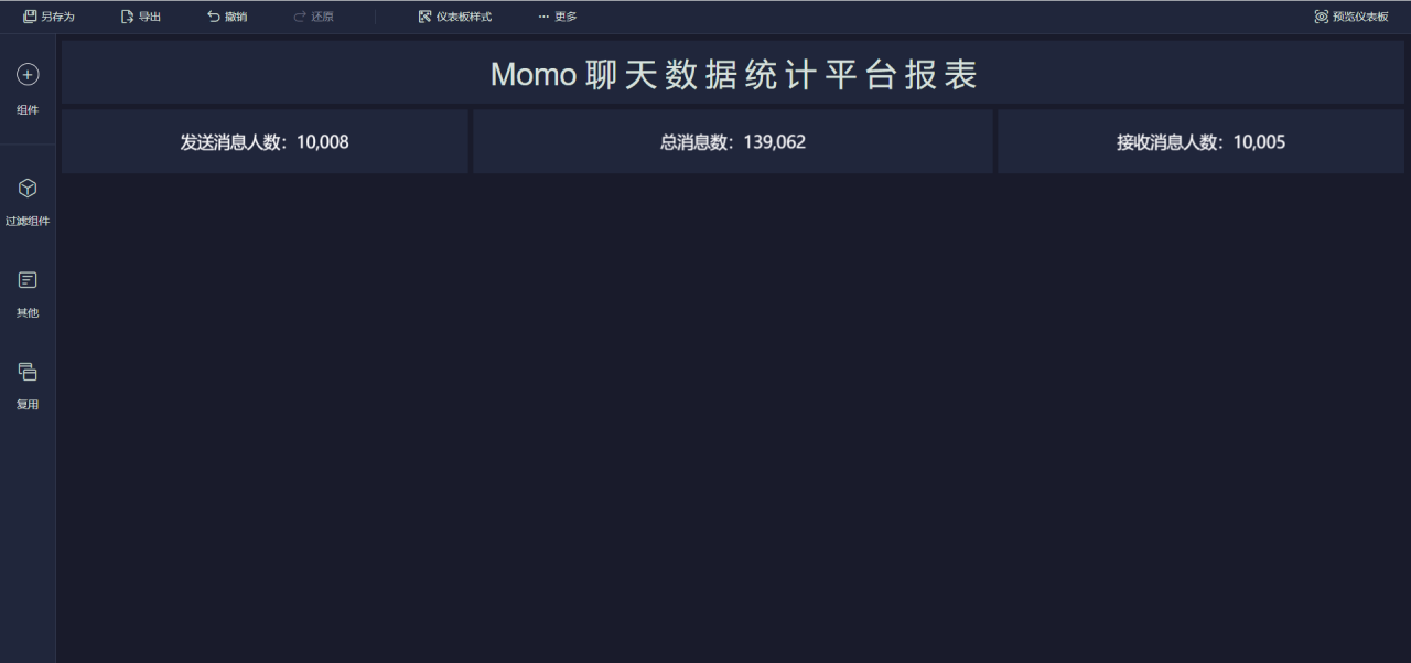
添加地圖(1/9)
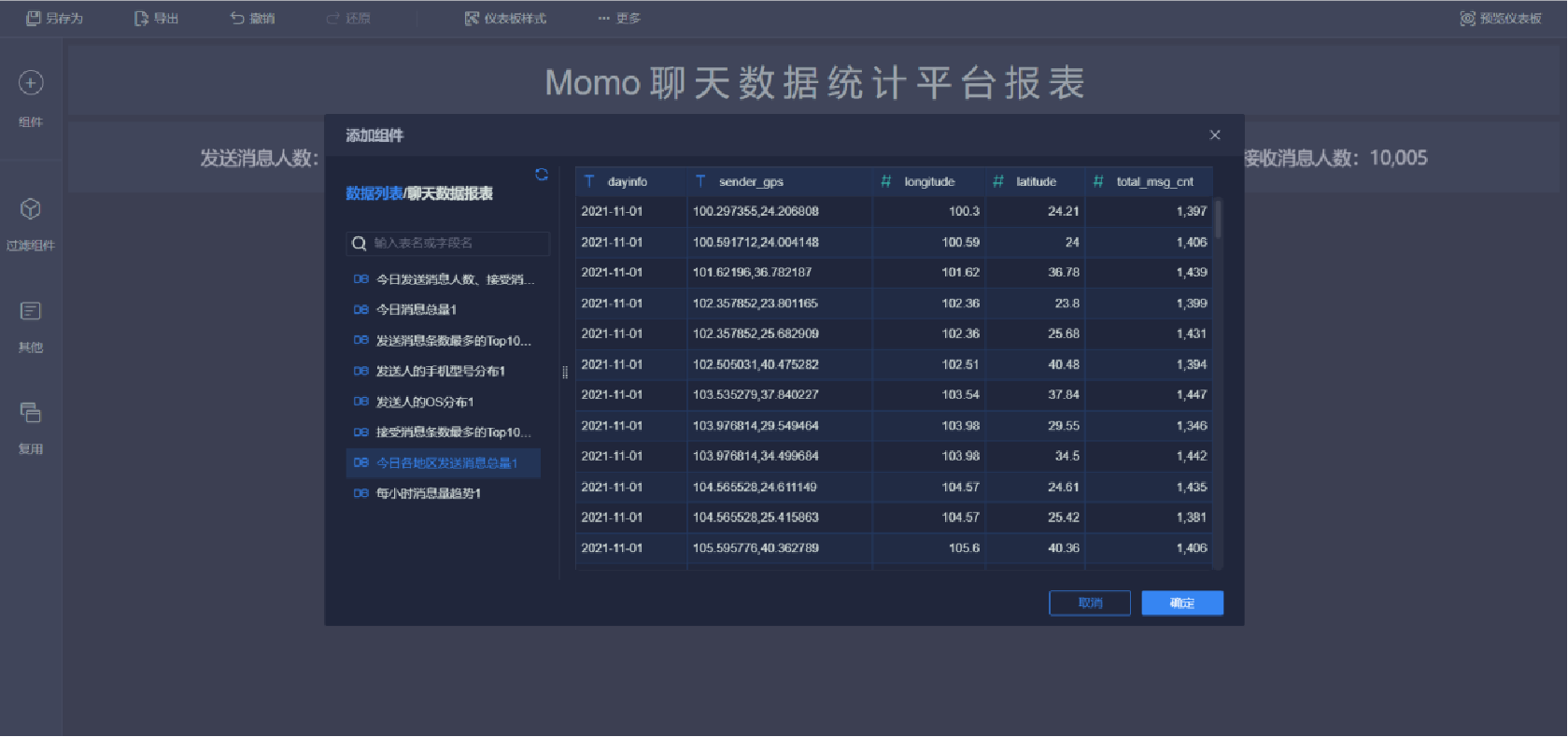
添加地圖(2/9)
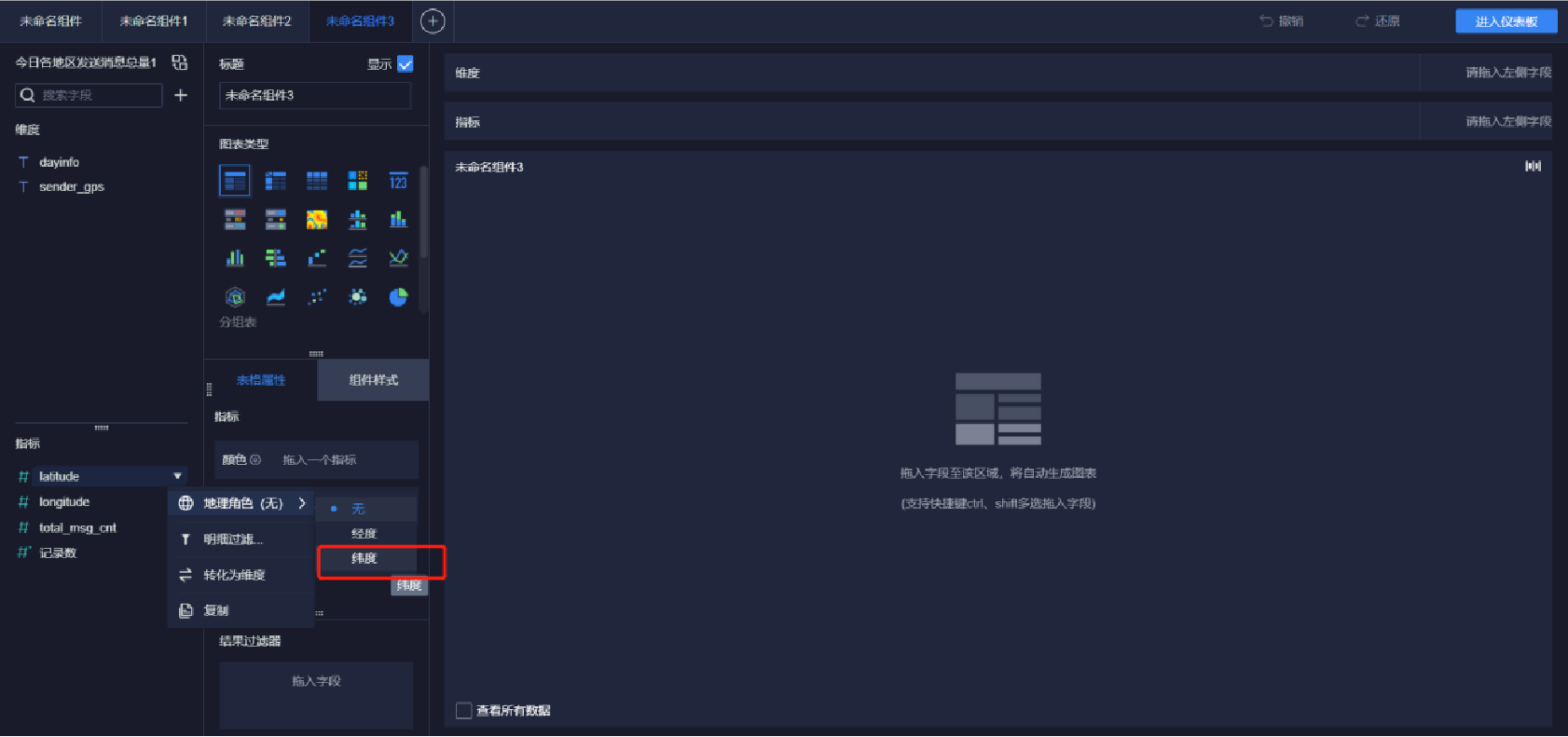
添加地圖(3/9)
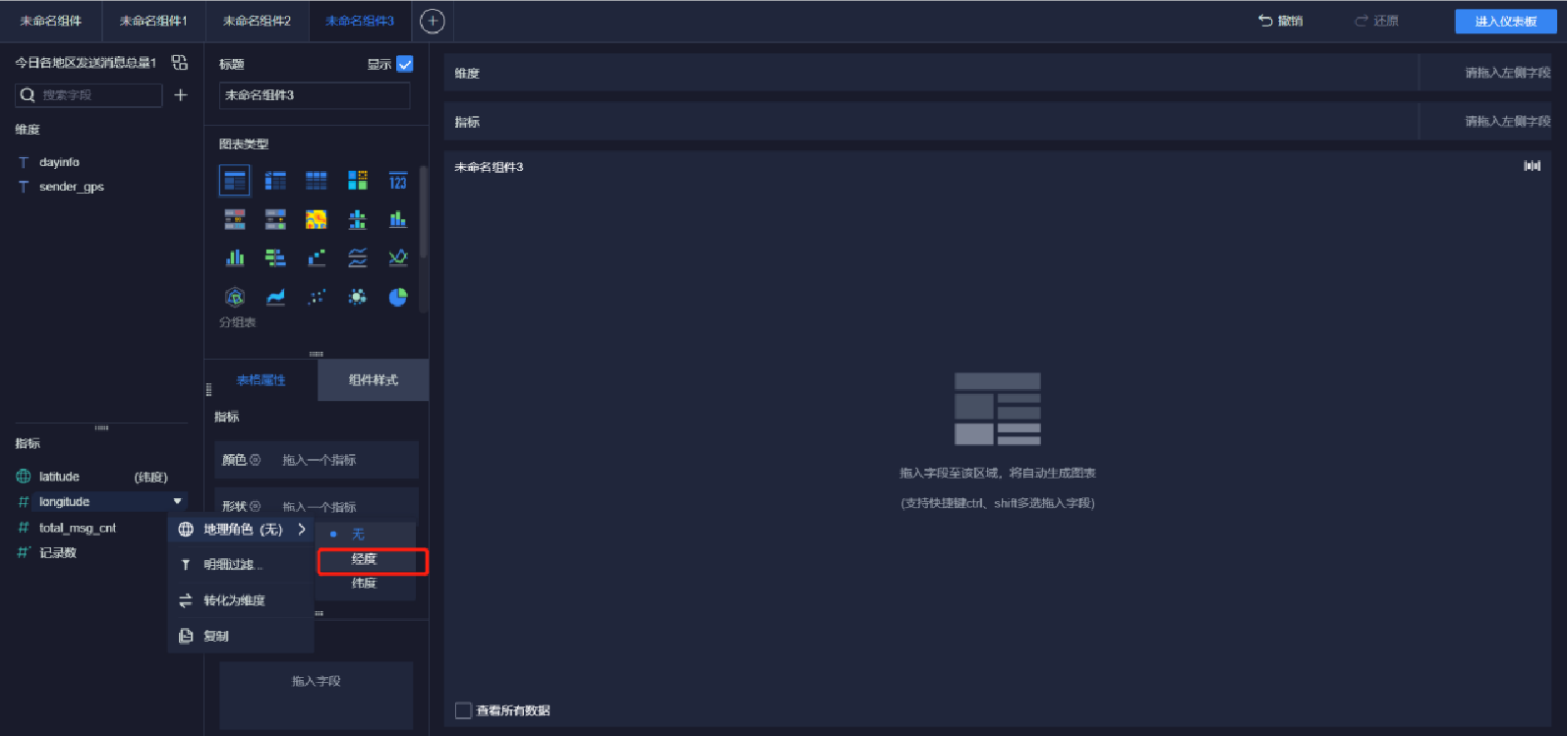
添加地圖(4/9)
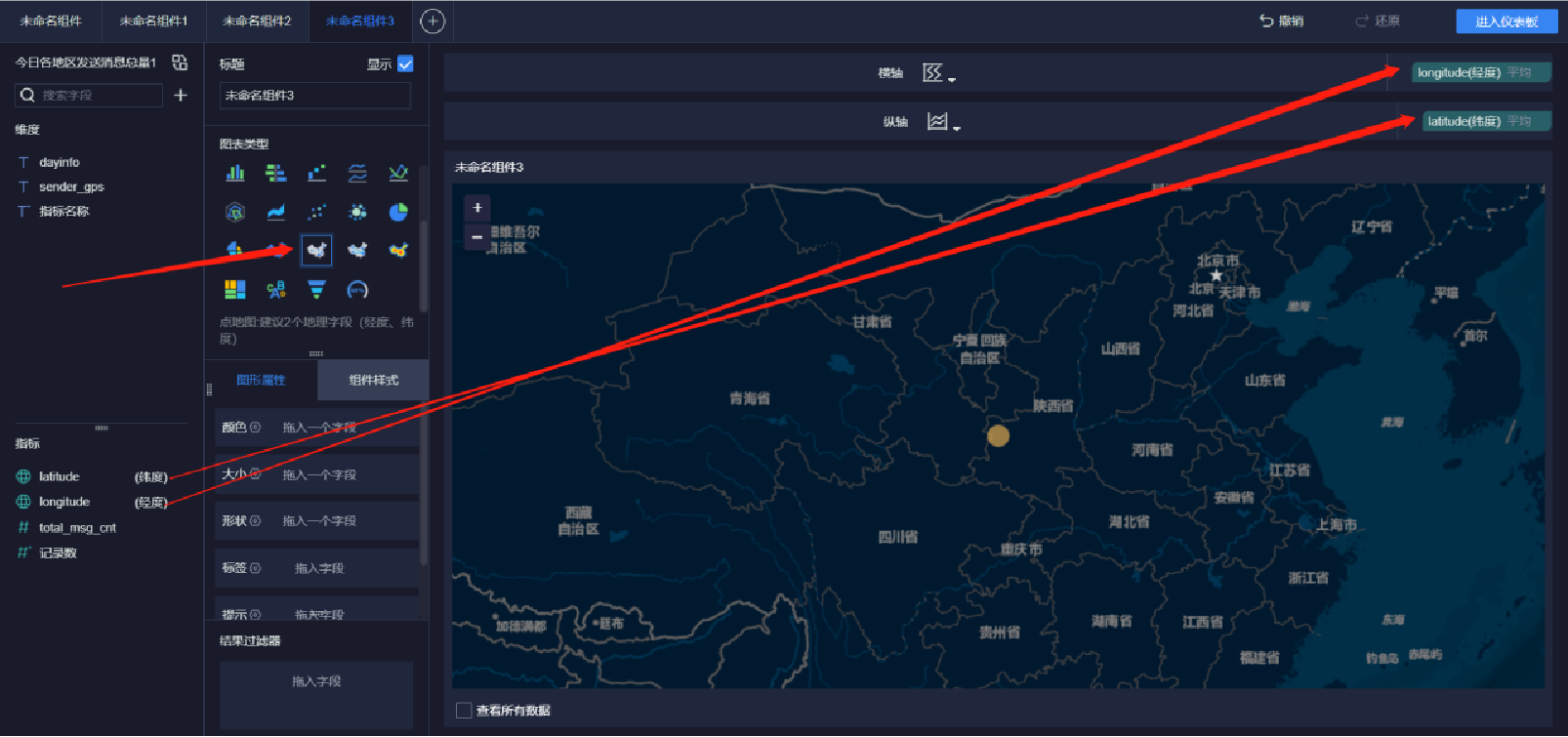
添加地圖(5/9)
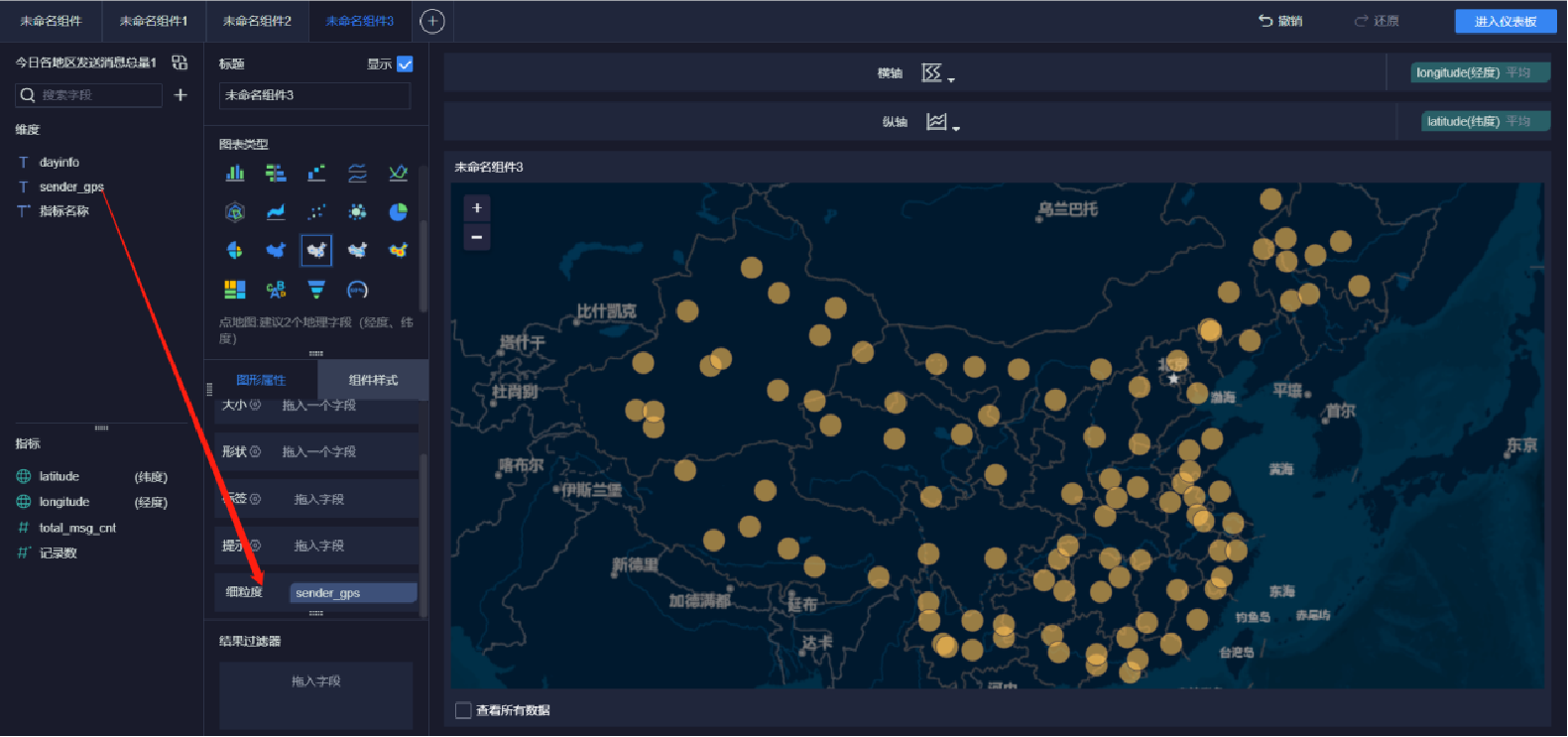
添加地圖(6/9)
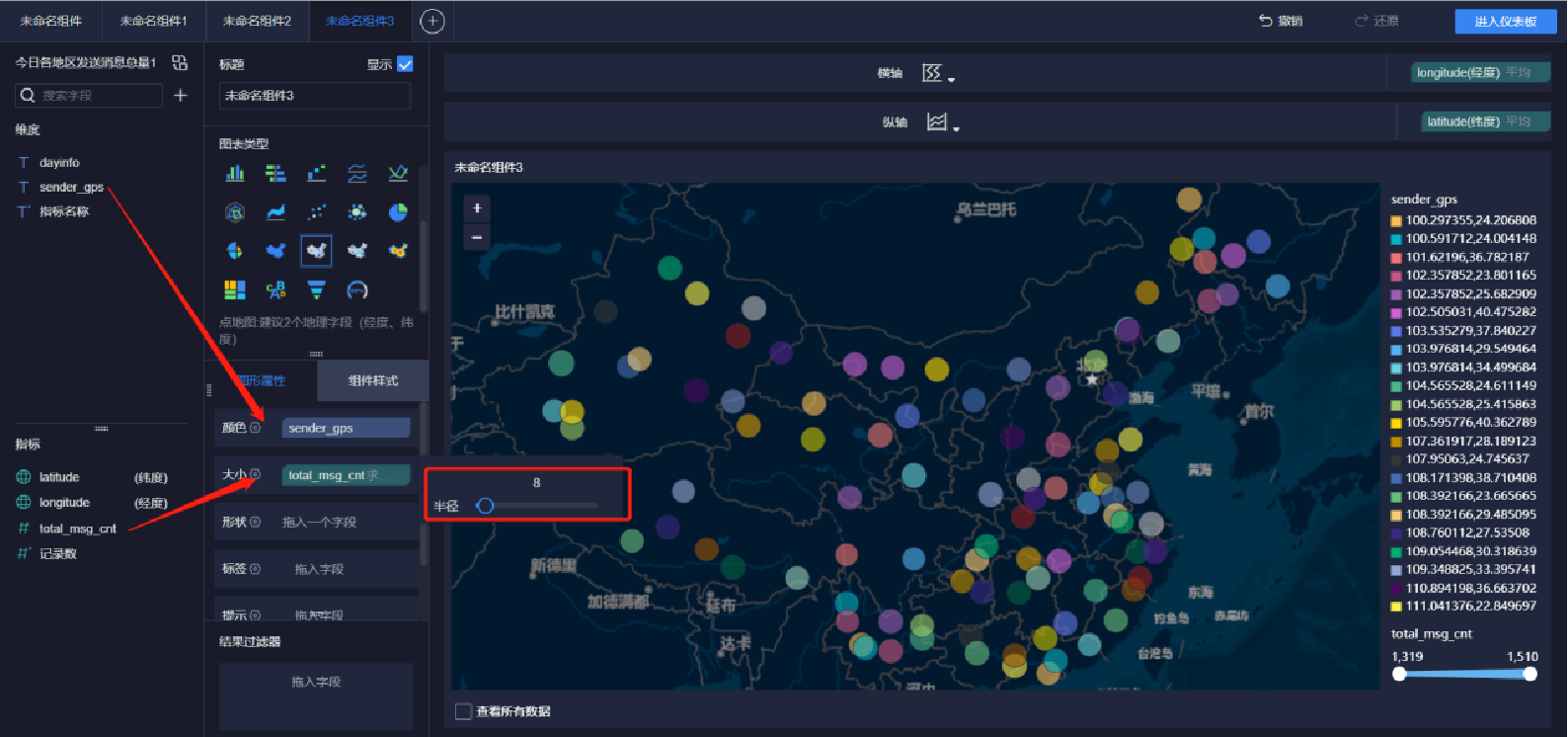
添加地圖(7/9)
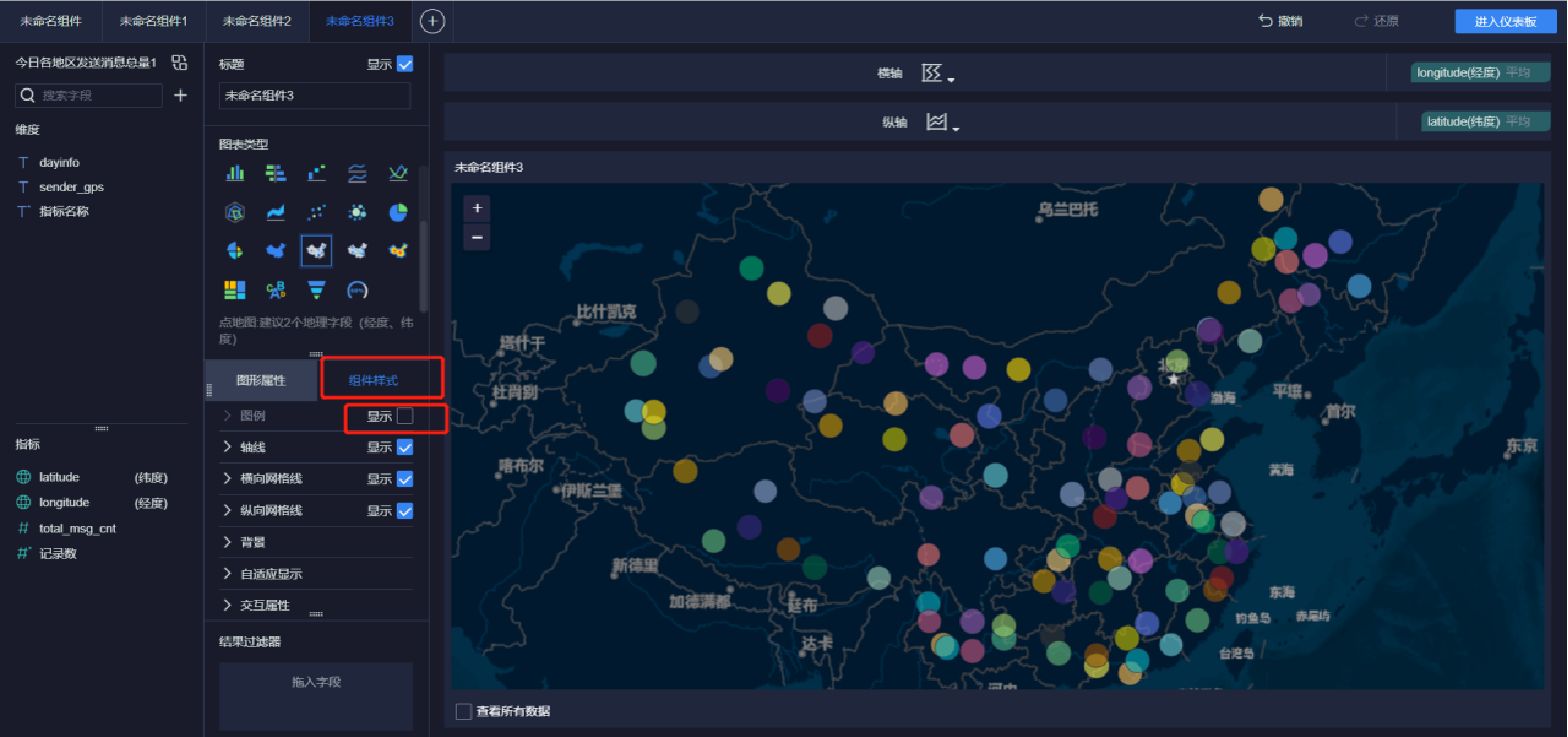
添加地圖(8/9)
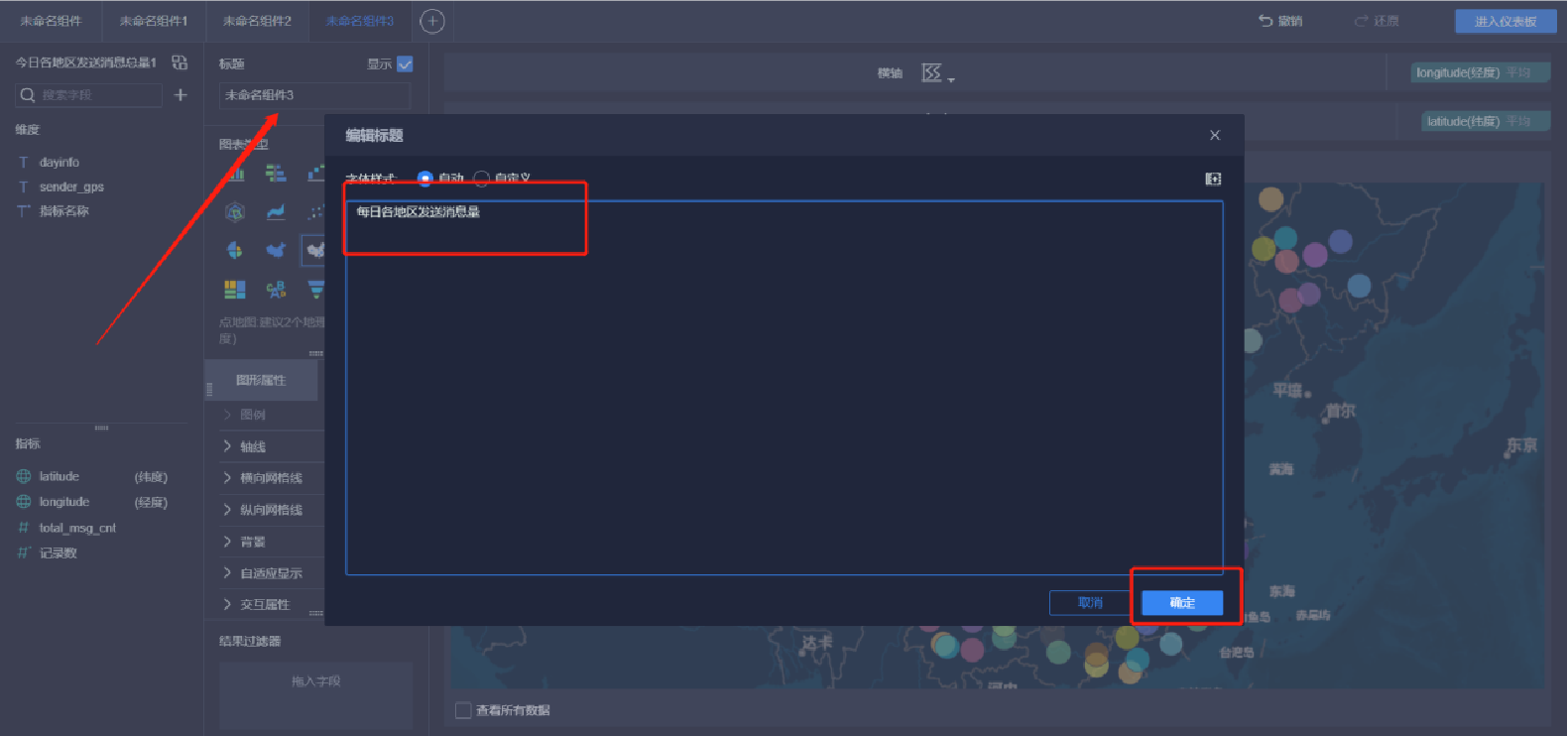
添加地圖(9/9)
添加雷達圖(1/5)
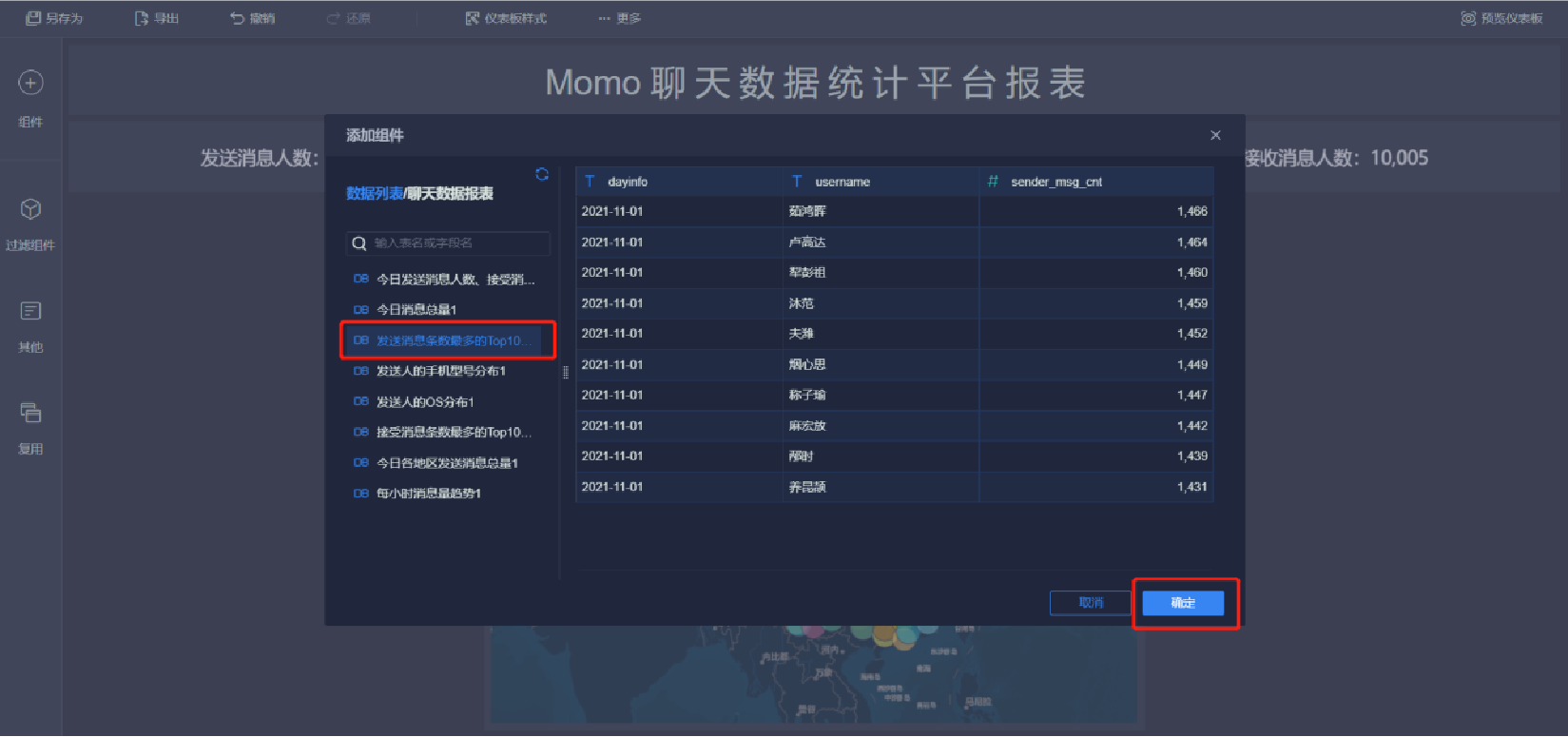
添加雷達圖(2/5)
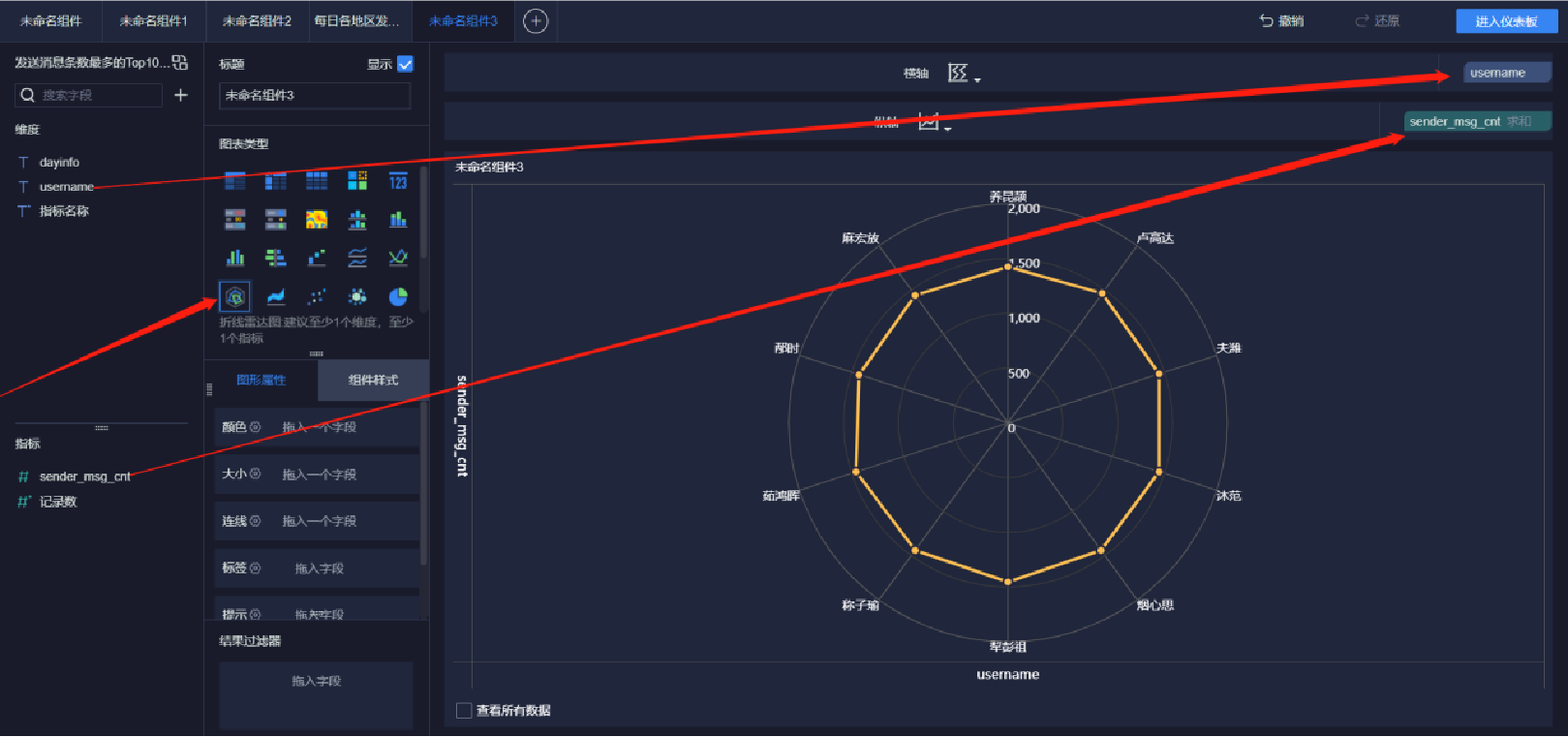
添加雷達圖(3/5)
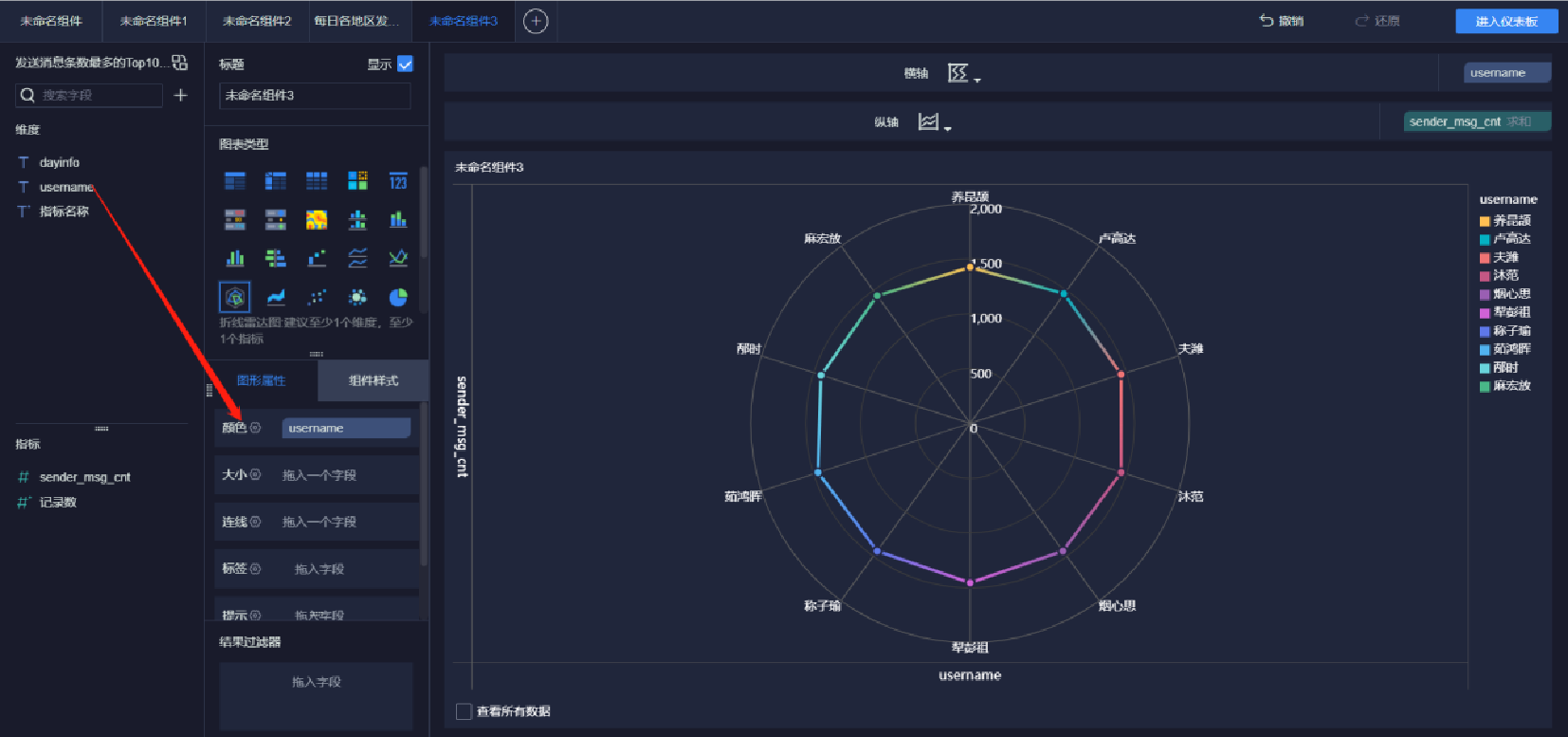
添加雷達圖(4/5)
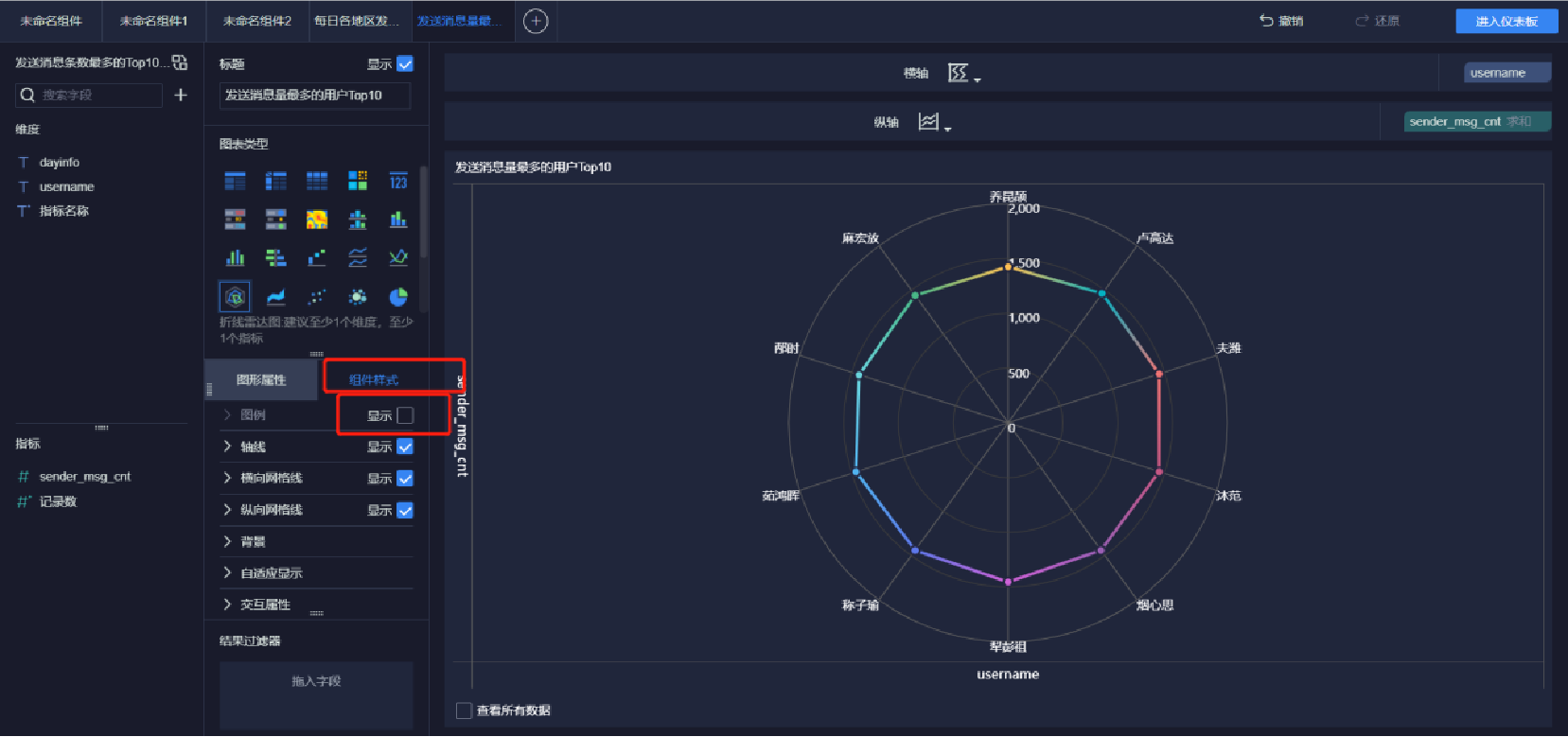
添加雷達圖(5/5)
添加柱狀圖(1/5)

添加柱狀圖(2/5)
添加柱狀圖(3/5)
添加柱狀圖(4/5)
添加柱狀圖(5/5)
添加環餅狀圖(1/6)
添加環餅狀圖(2/6)
添加環餅狀圖(3/6)
添加環餅狀圖(4/6)
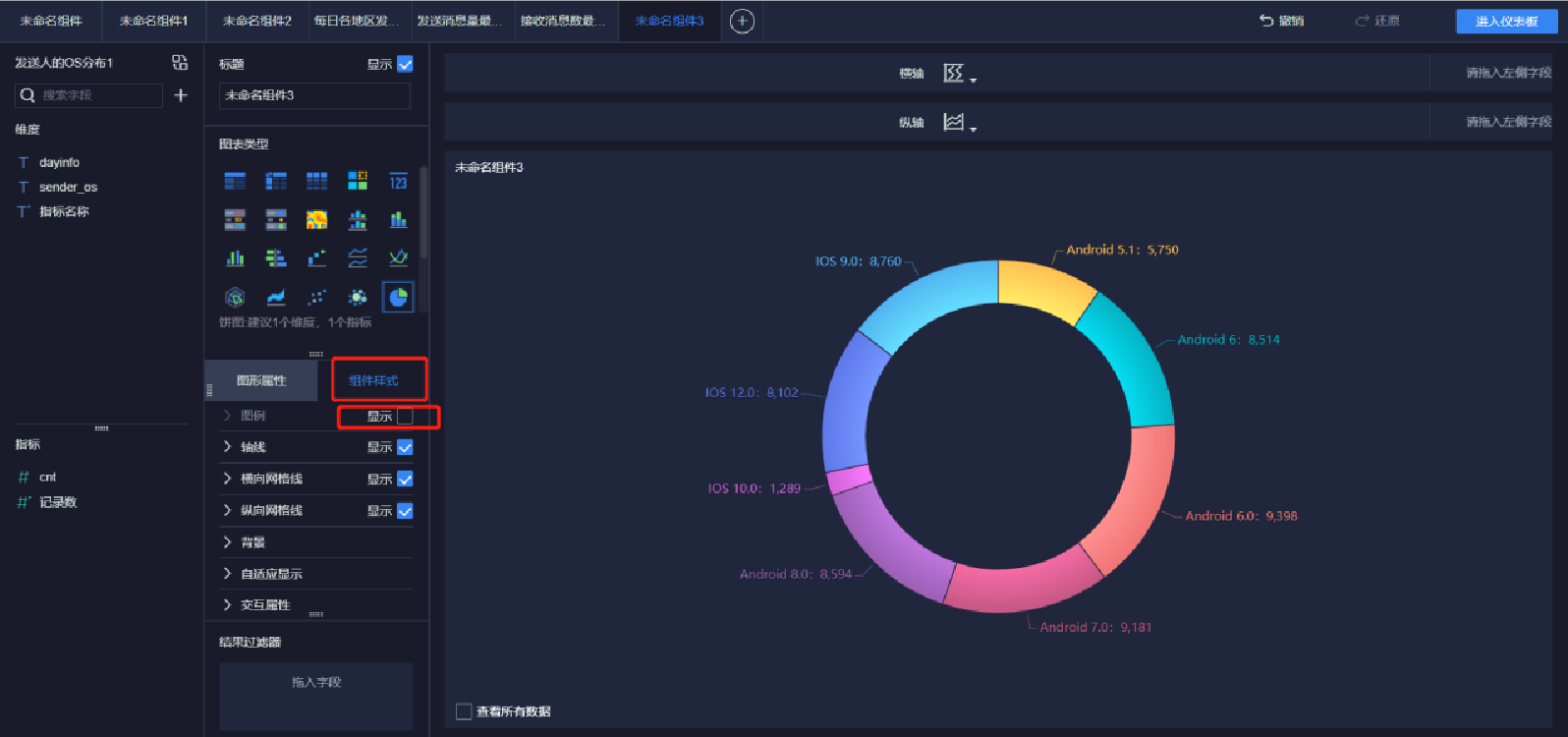
添加環餅狀圖(5/6)
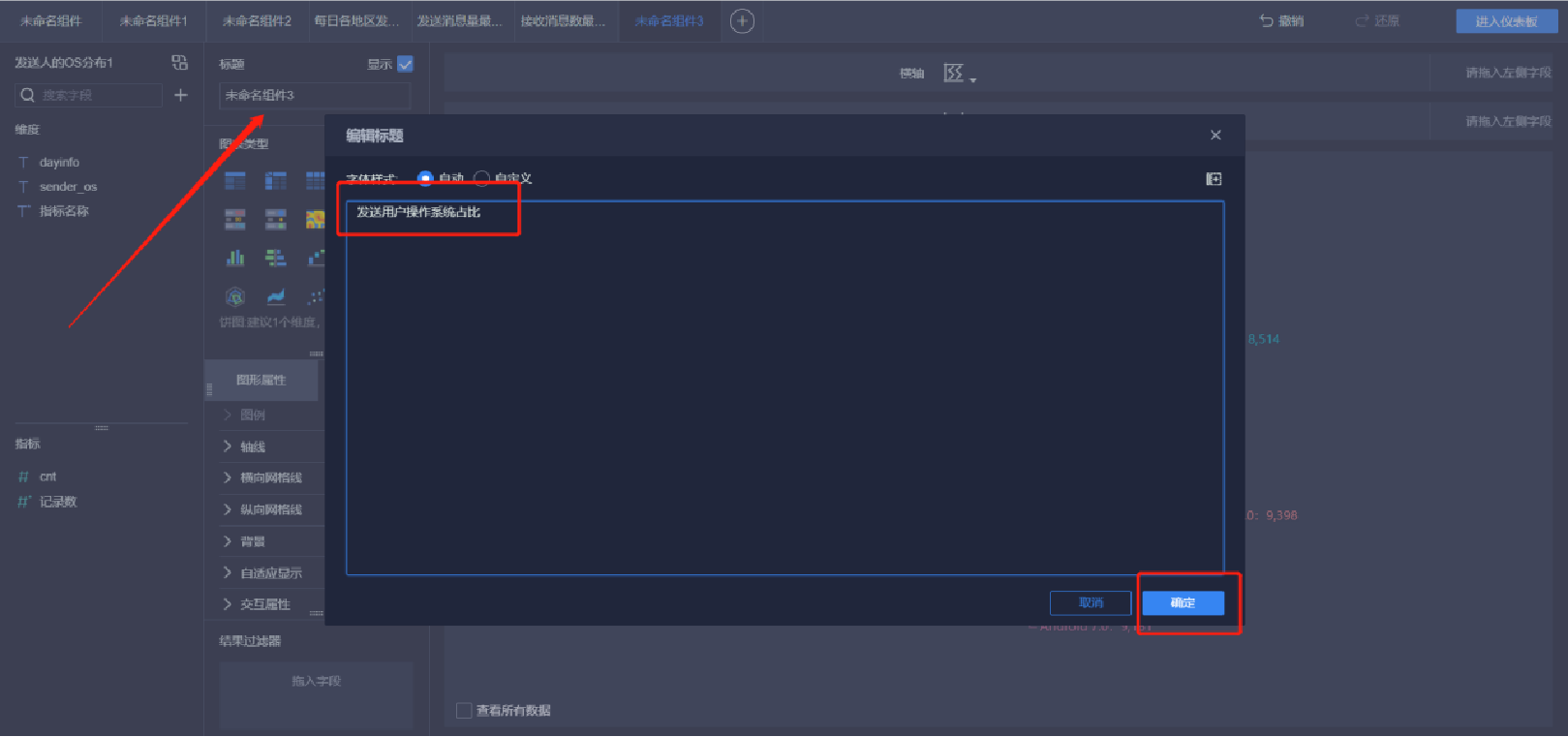
添加環餅狀圖(6/6)
添加詞匯云圖(1/5)
添加詞匯云圖(2/5)
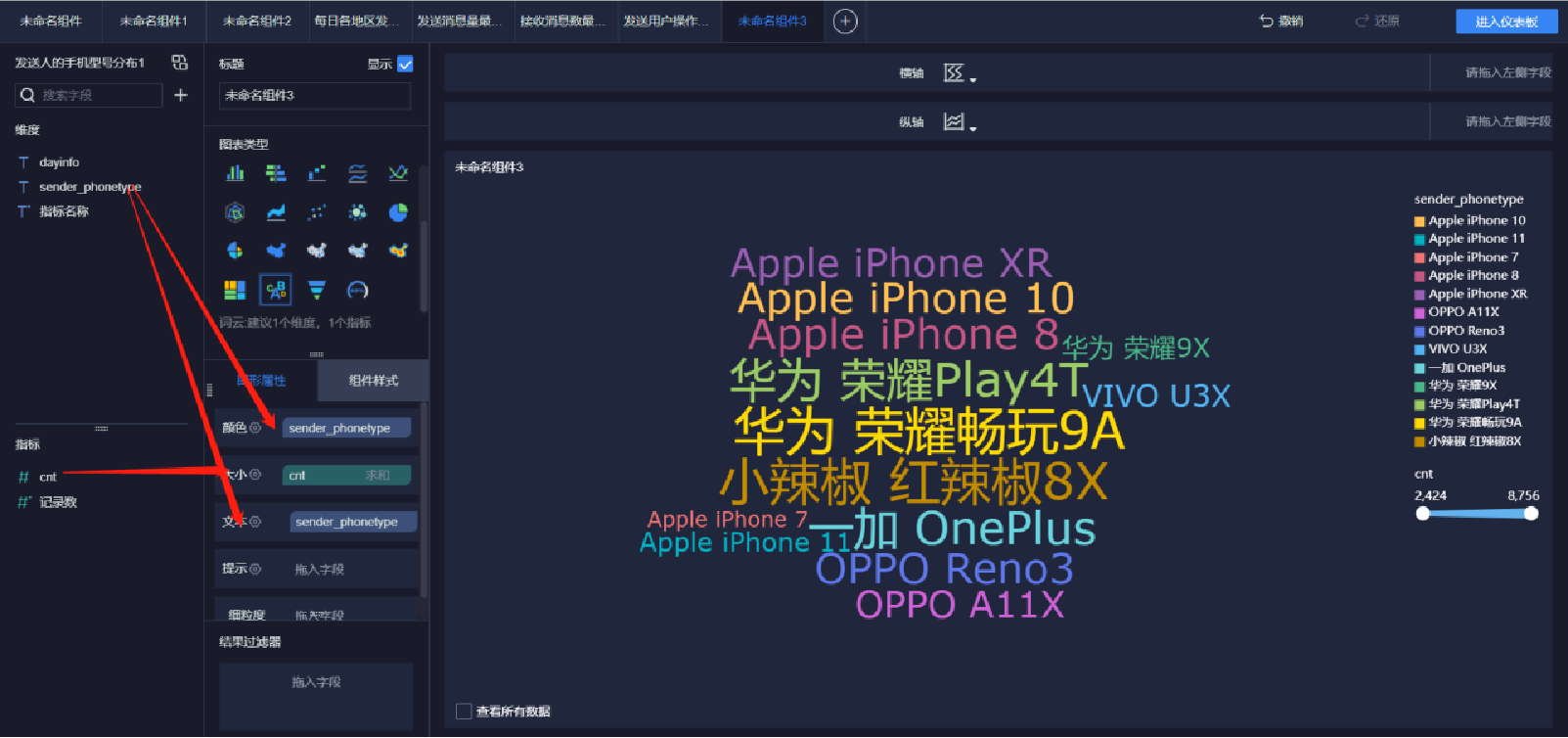
添加詞匯云圖(3/5)
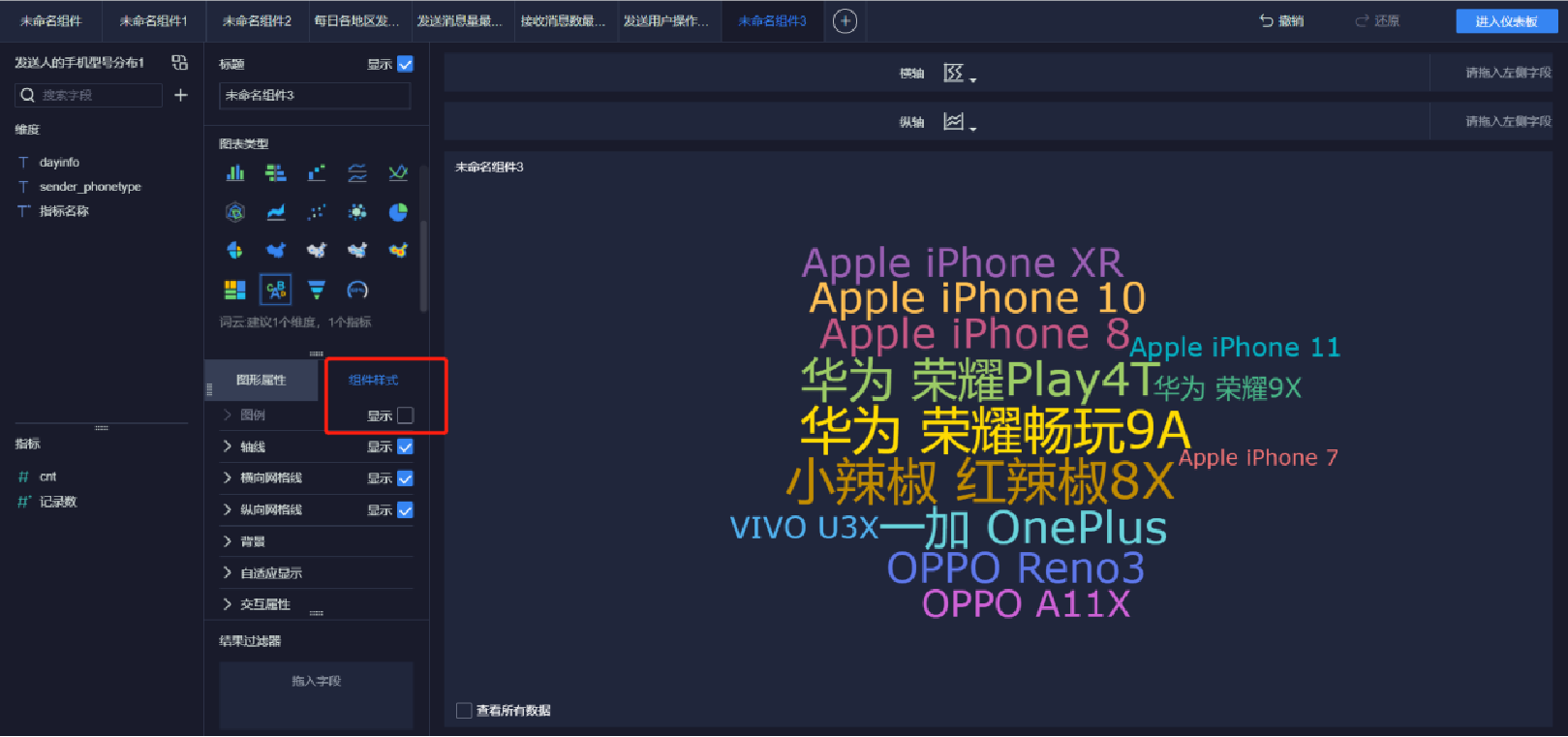
添加詞匯云圖(4/5)
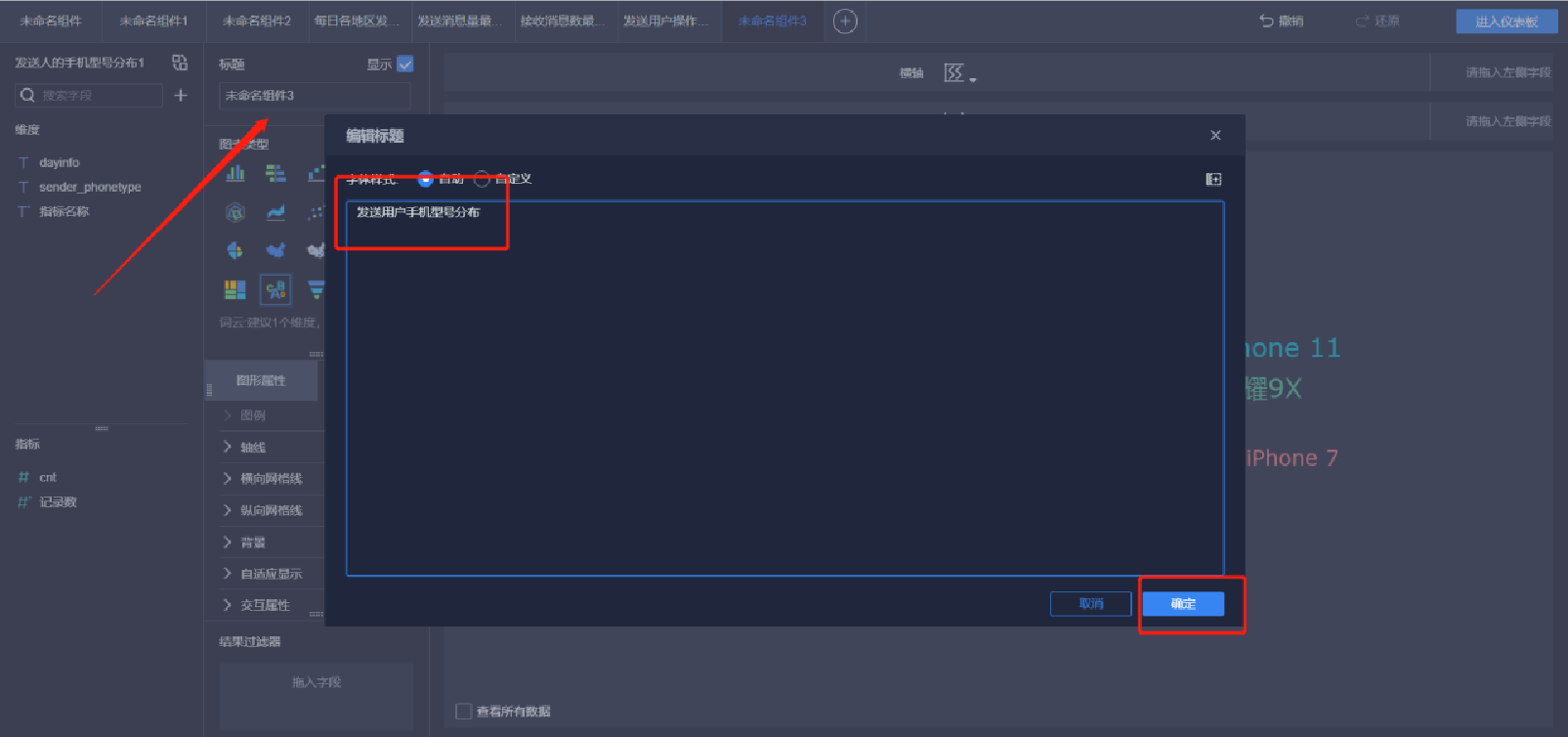
添加詞匯云圖(5/5)
添加趨勢曲線圖(1/5)
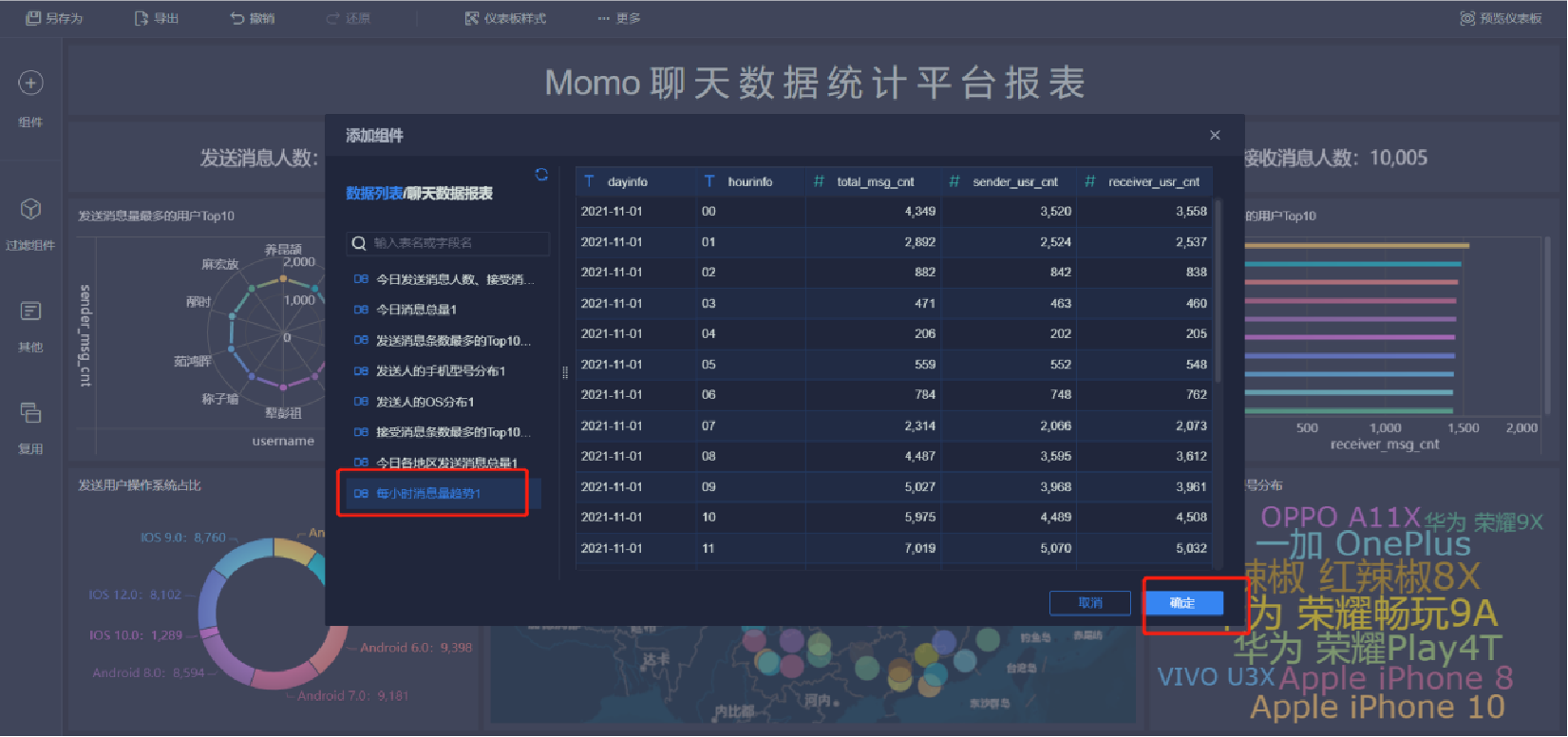
添加趨勢曲線圖(2/5)
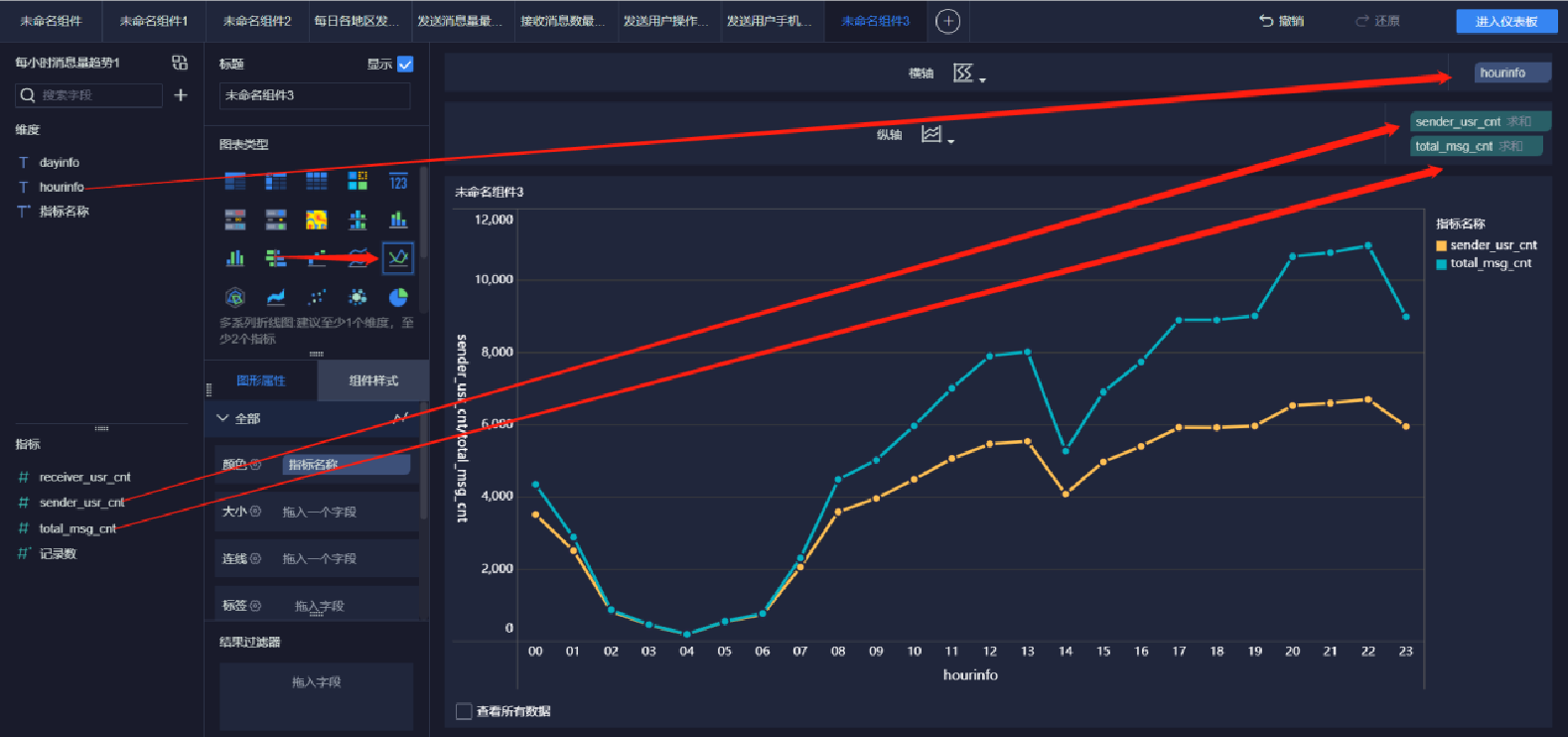
添加趨勢曲線圖(3/5)
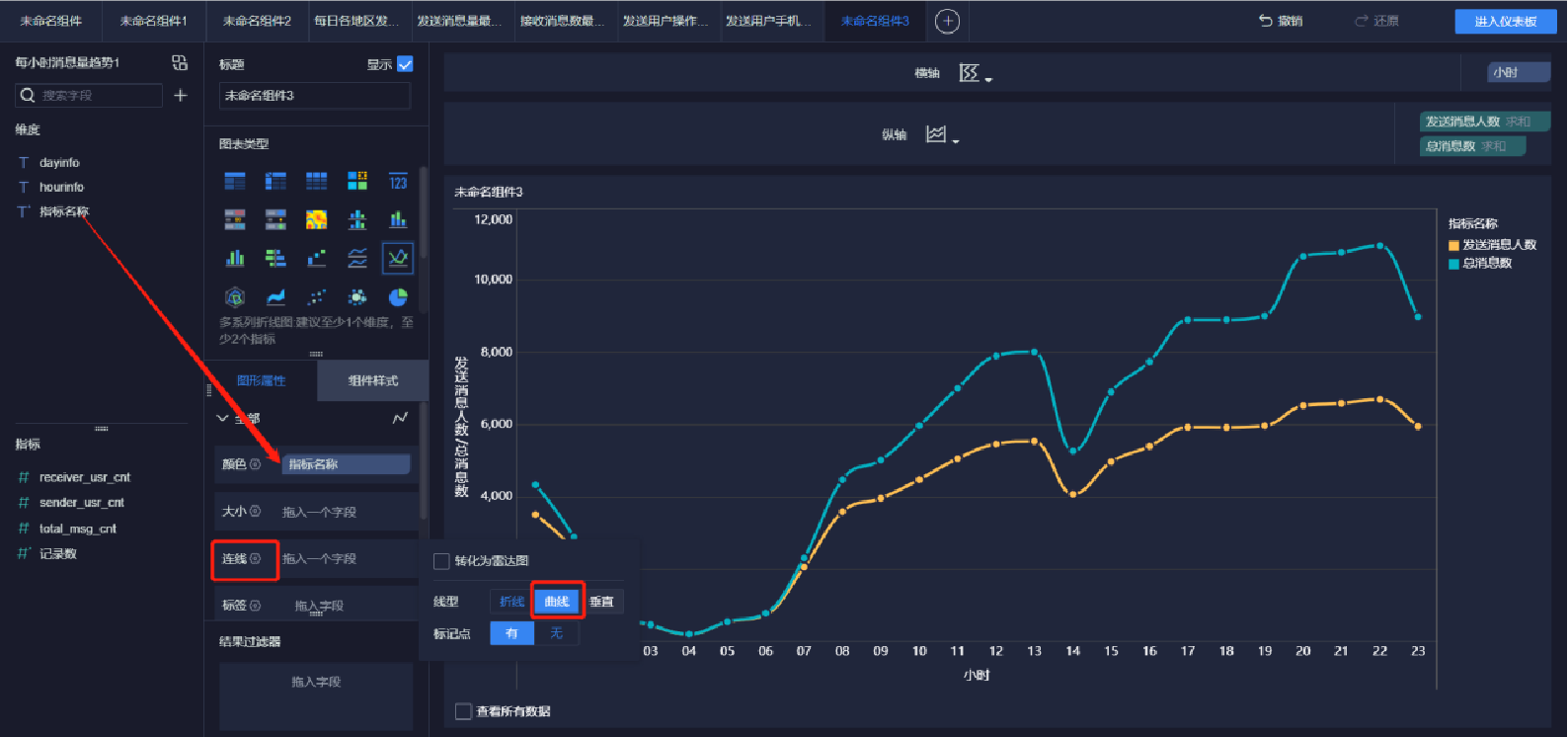
添加趨勢曲線圖(4/5)
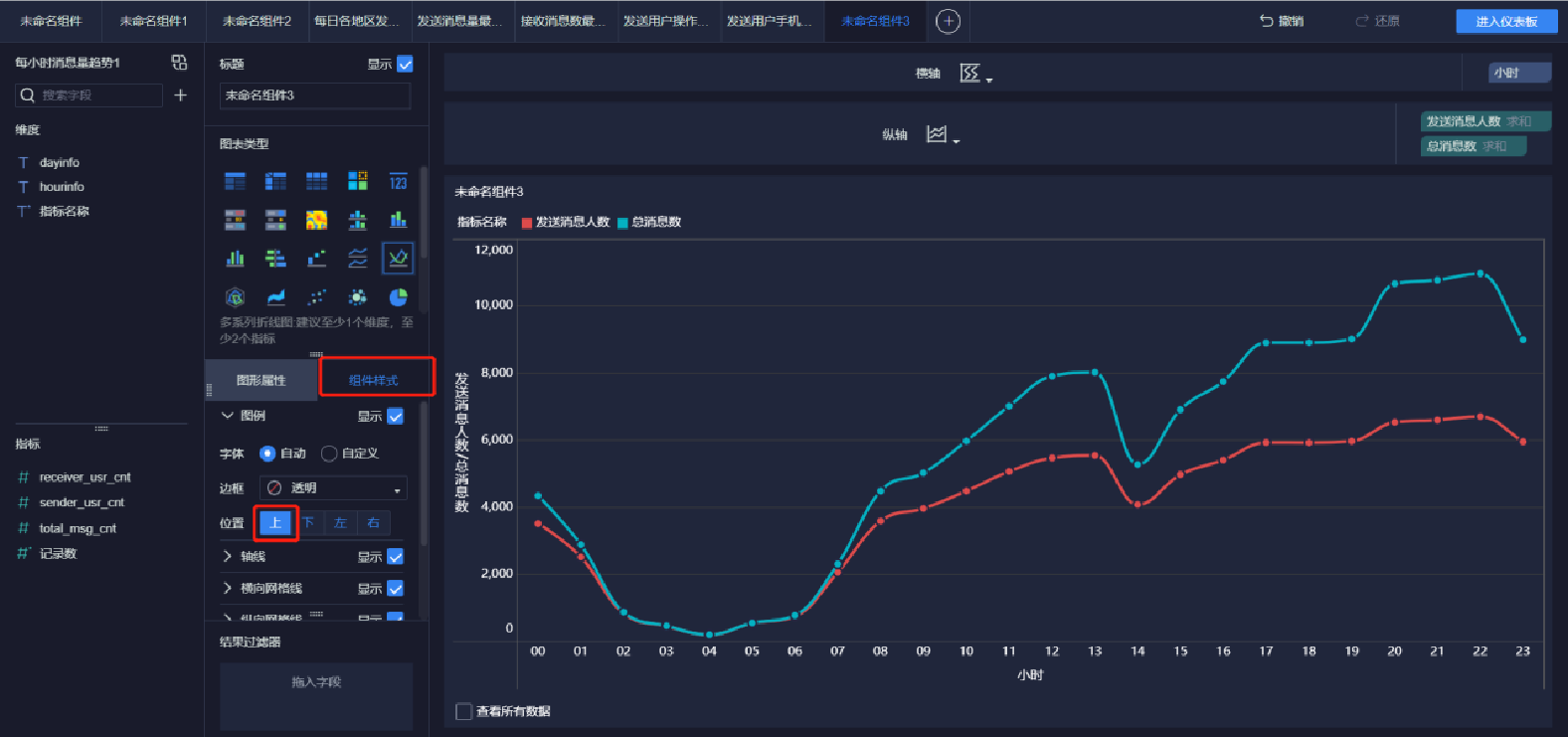
添加趨勢曲線圖(5/5)
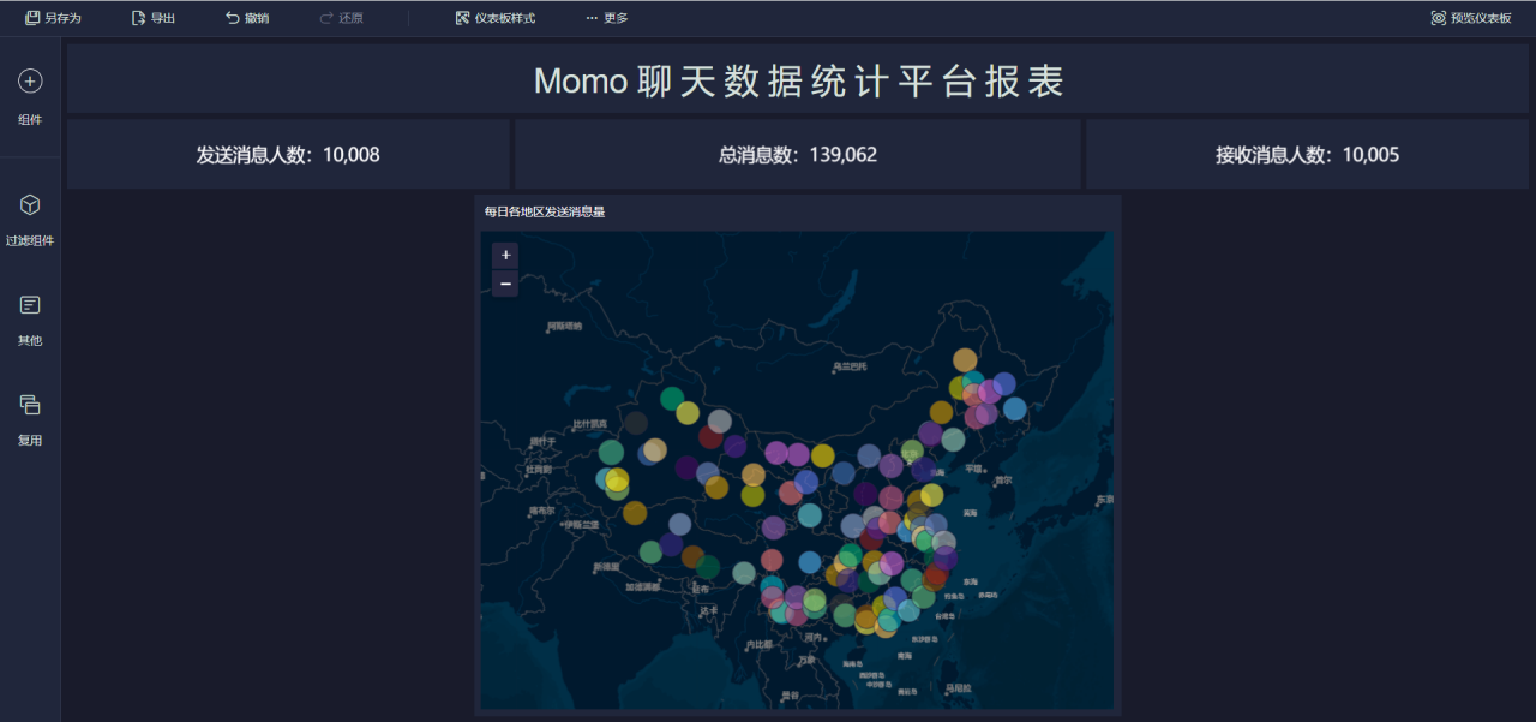
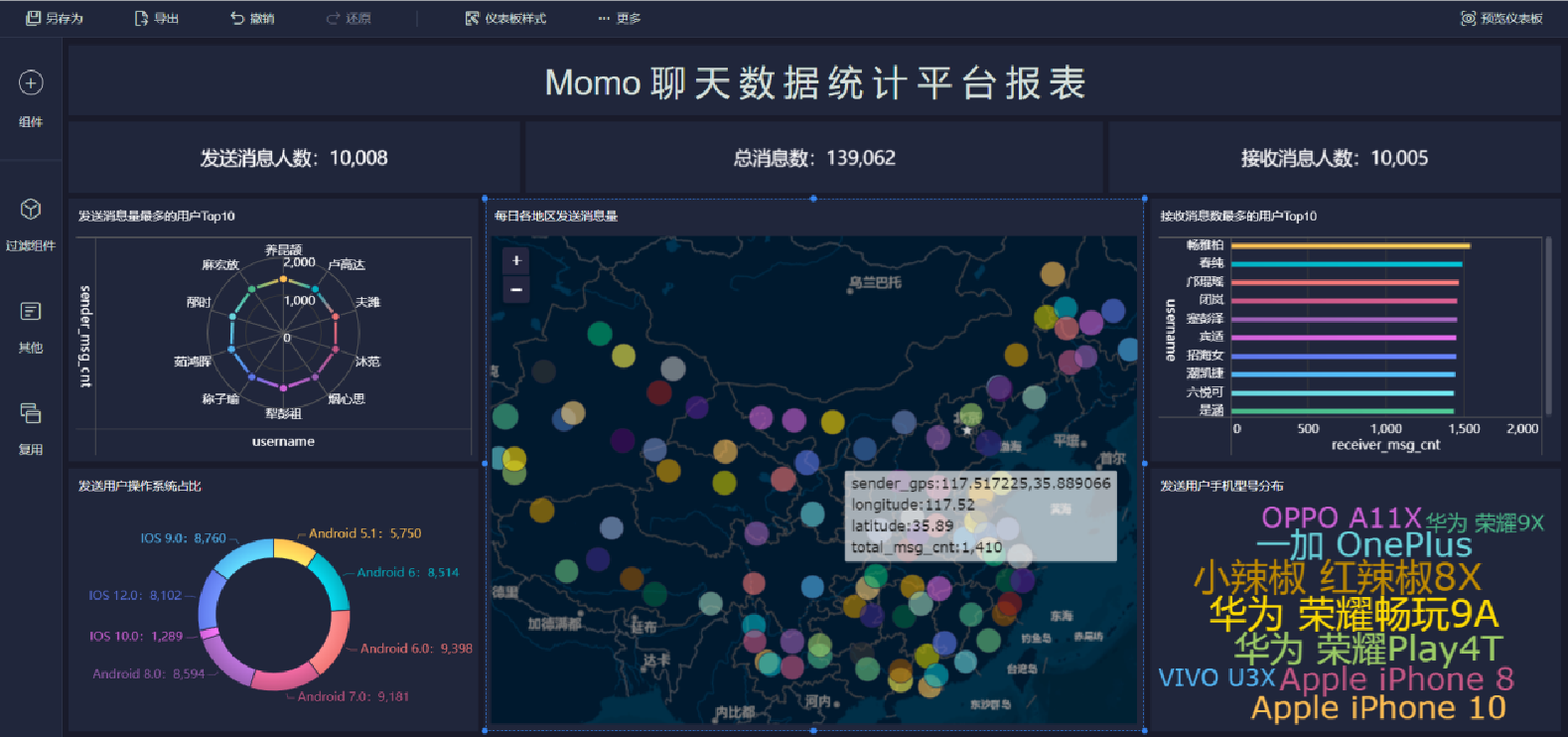
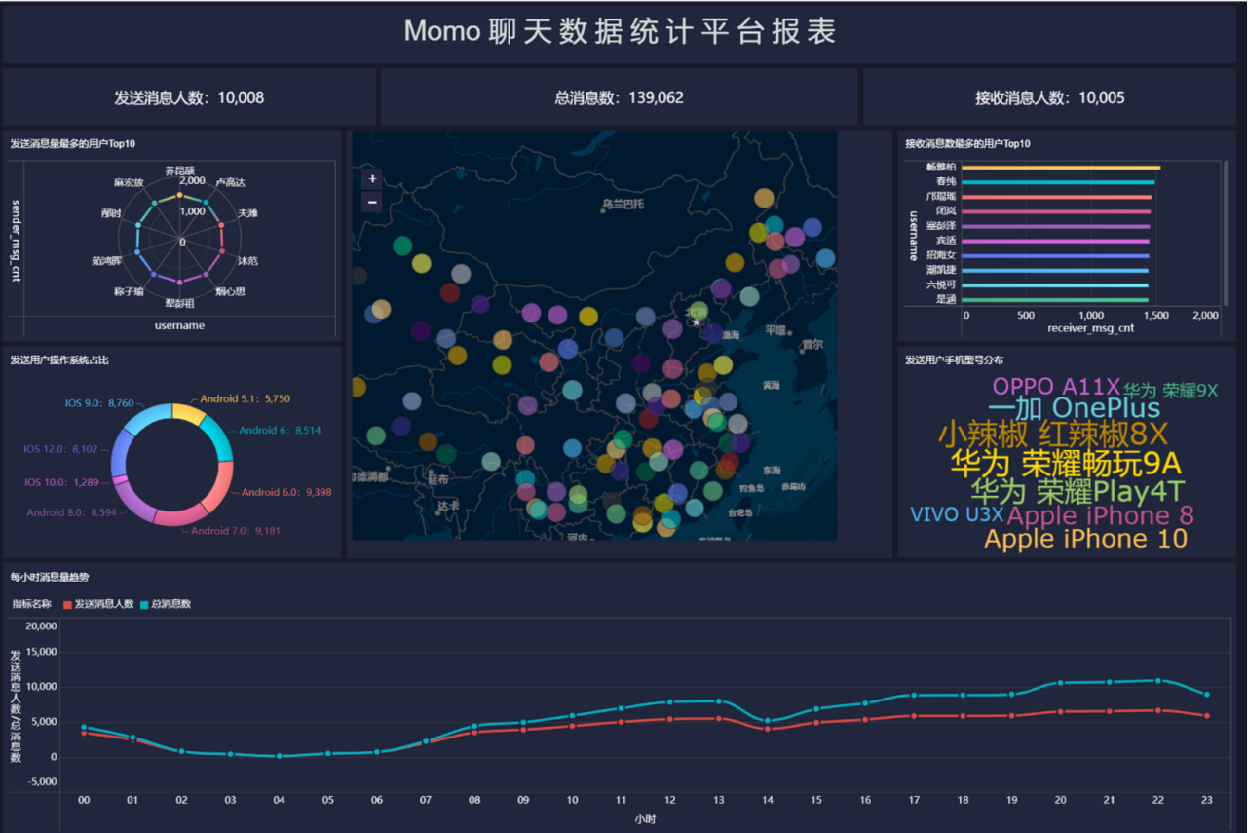
報表預覽
)

)

)







)



(SpringBoot2.x整合Mybatis實現CURD操作和分頁查詢詳細項目文檔))


)