一、常見的查找方式?
順序查找 O(N)
二分查找 O(logN)(要求有序和隨機訪問)
二叉搜索樹 O(N)
平衡二叉搜索樹(AVL樹和紅黑樹) O(logN)
哈希 O(1)
考慮效率和要求而言,正常選用 平衡二叉搜索樹 和 哈希 作為查找方式。但這兩種結構適合用于數據量相對不是很大,能夠一次性存放在內存中,進行數據查找的場景。如果數據量很大,比如有100G數據,無法一次放進內存中,那就只能放在磁盤上了。
如果放在磁盤上,有需要搜索某些數據,那么如果處理呢?
可以考慮將?存放關鍵字及其映射的數據的地址放到一個內存中的搜索樹的節點?中。需要訪問數據時,先取這個地址去磁盤訪問數據。
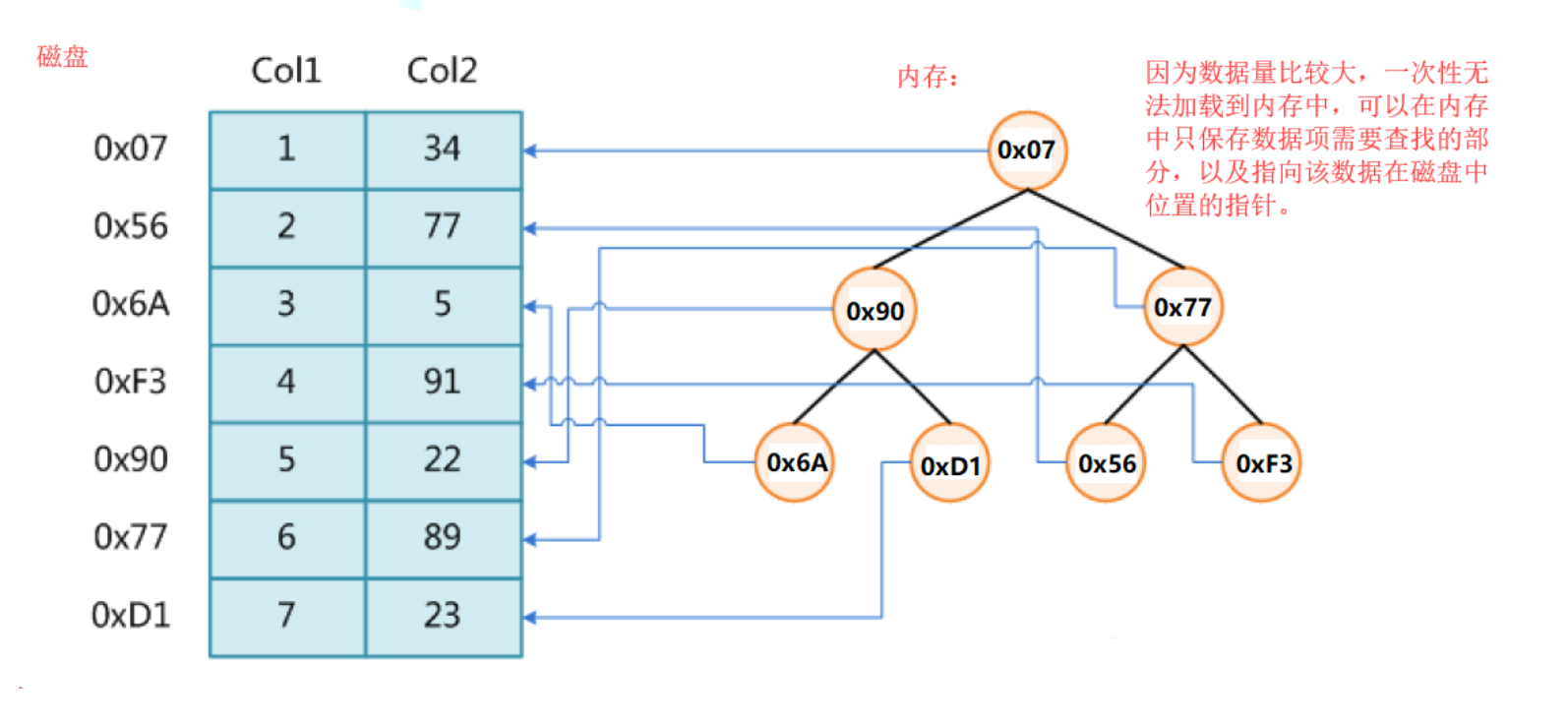
分析效率的缺陷:
使用平衡二叉樹搜索樹的缺陷:平衡二叉樹搜索樹的高度是 logN ,這個查找次數在內存中是很快的。但是當數據都在磁盤中時,訪問磁盤速度很慢,在數據量很大時,logN 次的磁盤訪問,是一個難以接受的結果。使用哈希表的缺陷:哈希表的效率很高是 O(1) ,但是一些極端場景下某個位置沖突很多,導致訪問次數劇增,也是難以接受的。那如何加速對數據的訪問呢?1. 提高 IO 的速度 (SSD 相比傳統機械硬盤快了不少,但是還是沒有得到本質性的提升 )2. 降低樹的高度 --- 多叉樹平衡樹
二、B樹概念
1970 年, R.Bayer 和 E.mccreight 提出了一種適合外查找的樹,它是一種平衡的多叉樹,稱為 B 樹。一 棵 m 階 (m>2) 的 B 樹,是一棵平衡的 M 路平衡搜索樹,可以是空樹 或者滿足一下性質:1. 根節點至少有兩個孩子2. 每個分支節點都包含 k-1 個關鍵字和 k 個孩子,其中 ceil(m/2) ≤ k ≤ m ?(ceil 是向上取整函數)3. 每個葉子節點都包含 k-1 個關鍵字,其中 ceil(m/2) ≤ k ≤ m4. 所有的葉子節點都在同一層5. 每個節點中的關鍵字從小到大排列,節點當中 k-1 個元素正好是 k 個孩子包含的元素的值域劃 分。6. 每個結點的結構為:( n , A0 , K1 , A1 , K2 , A2 , … , Kn , An ) 其中, Ki(1≤i≤n) 為關鍵字,且Ki<Ki+1(1≤i≤n-1) 。 Ai(0≤i≤n) 為指向子樹根結點的指針。且 Ai 所指子樹所有結點中的 關鍵字均小于Ki+1。 n為結點中關鍵字的個數,滿足 ceil(m/2)-1≤n≤m-1 。
三、B樹的插入
抽象情況分析:
1)根為空,創建新根,插入
2)根不為空,查找key,
若存在,不插入;
若不存在,插入到對應的葉子節點,若沒有滿,插入結束;若滿了就分裂出兄弟節點,分一半key和孩子給兄弟節點,提取key中位數,轉化成向父節點插入key中位數和兄弟節點,直到父節點滿足條件:沒有滿 或者 父節點的父節點為空,產生新的根節點。
具體情況分析:
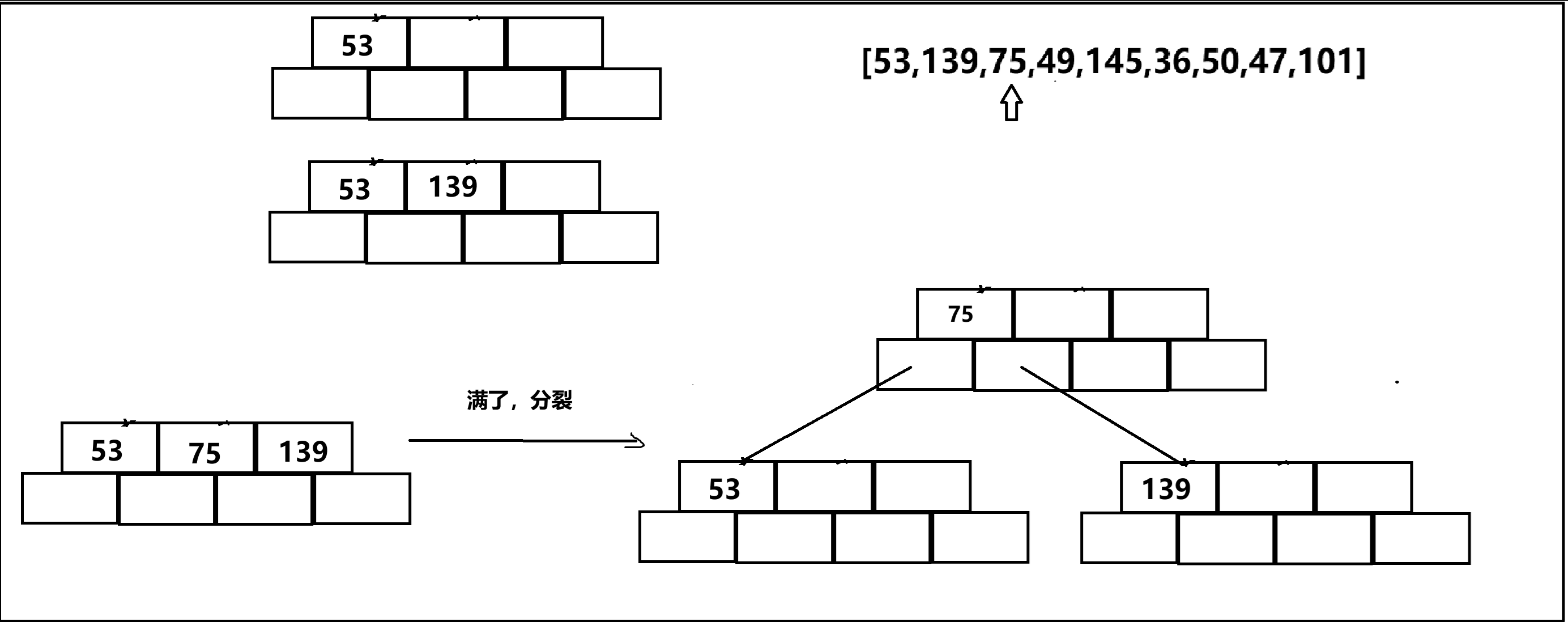
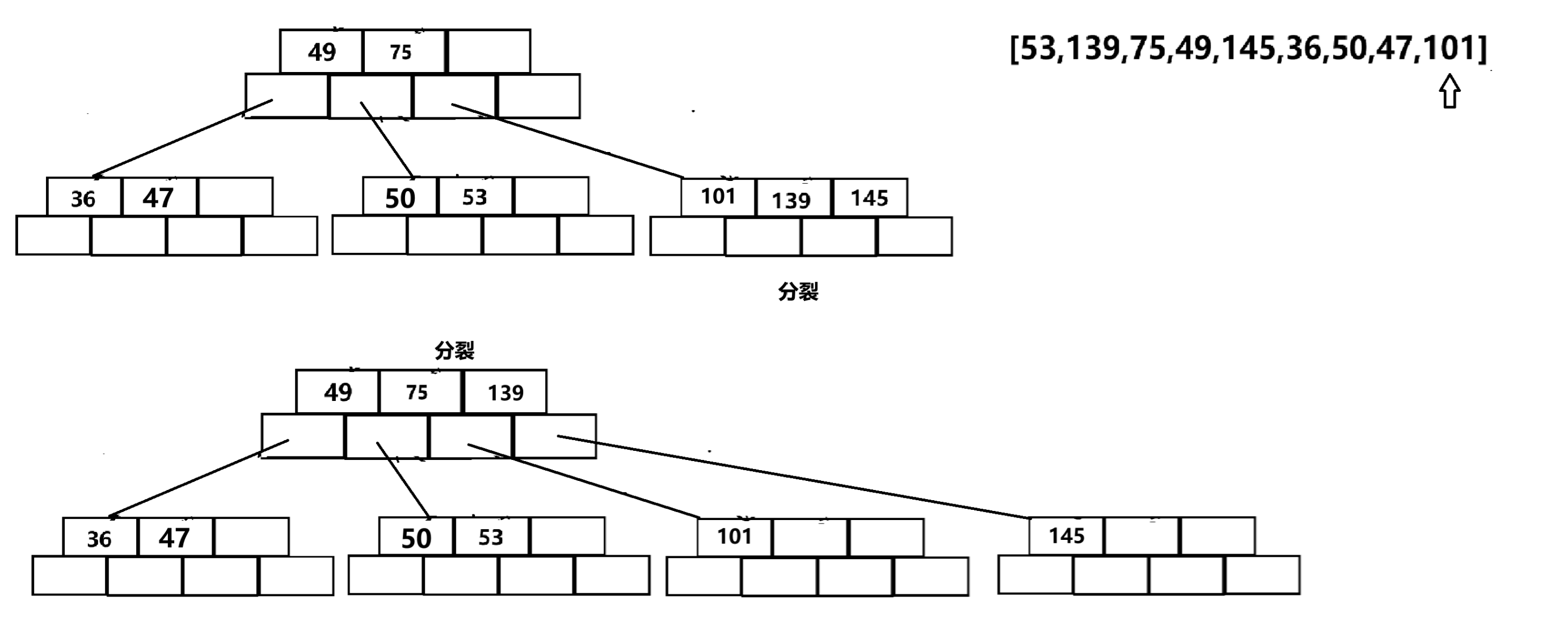
以{53,139,75,49,145,36,50,47,101}為例:
插入53,139,75:
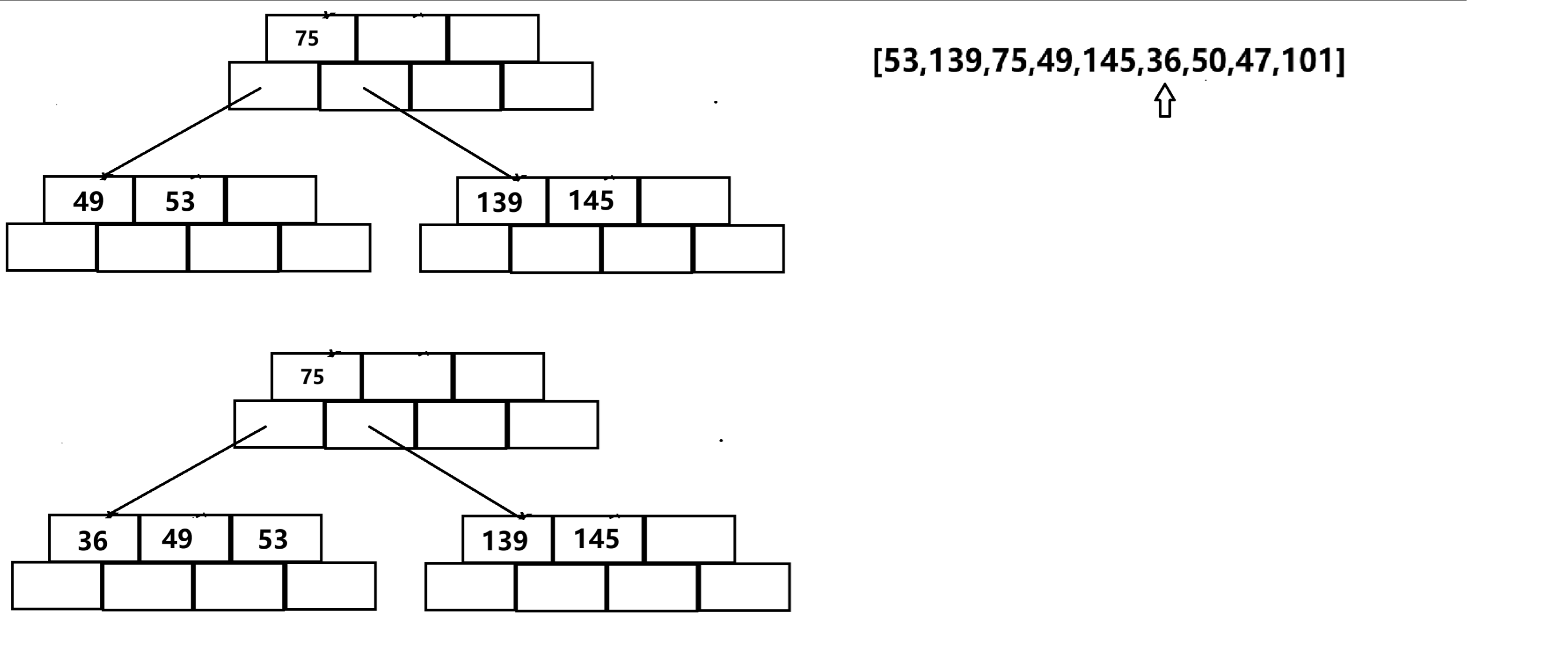
插入49,145,36:
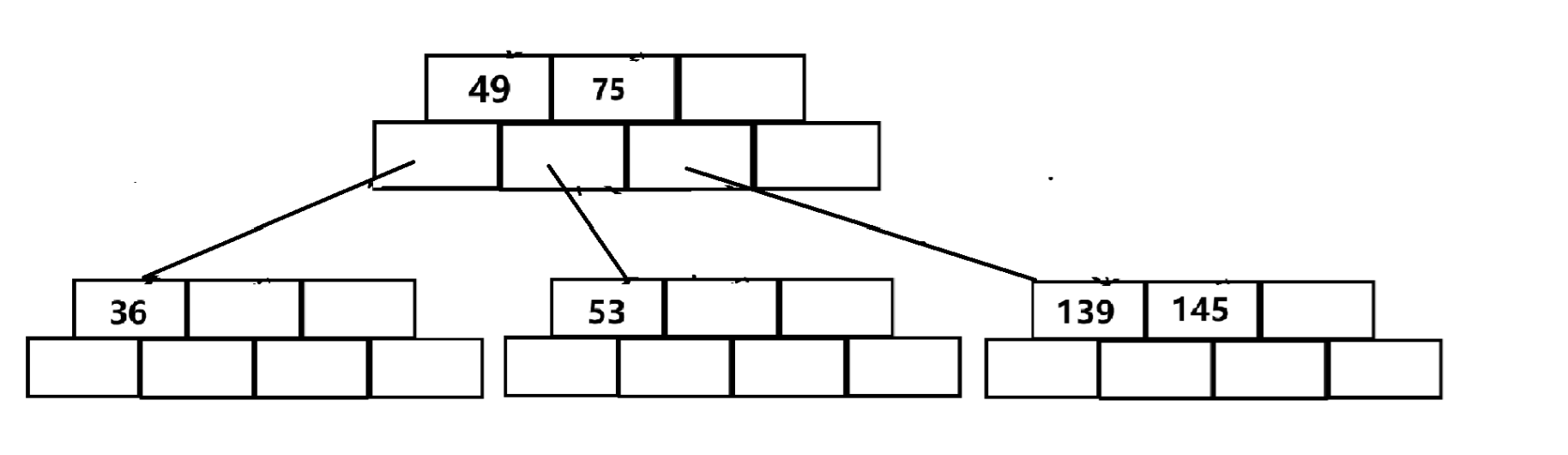
插入50,47,101:
實現插入時特別注意:
1)分裂出兄弟節點時,拷貝一半key和一半孩子,最后剩一個右孩子拷貝;拷貝的孩子若不為空,要鏈接父節點指針。
2)兄弟節點的_n和原始節點的_n都要修正
3)兄弟節點的父指針要指向cur->parent
4)若cur的父節點為空,造新根,新根左為cur,右為brother,注意鏈接cur和brother的父指針。
5)若cur的父節點不為空,cur迭代到cur->parent,轉化成向cur->parent插入midKey和brother。
循環直到 當前節點未滿 或 造出新根(4)。
insertKey細節:用index迭代從頭遍歷,直到找到比index大的位置,index及以后位置都往后挪動一位,同時挪動右孩子。若index一直走到尾,說明key是最大值,在尾賦值。最后統一鏈接右孩子,_n++。
代碼實現如下:
void insertKey(Node* cur, Node* sub, const K& key) {size_t index = 0;while (index < cur->_n){//key大于當前位置,往后走if (key > cur->_keys[index]){++index;}else{//把index及以后key往后挪動一位//右孩子都向右挪動一位for (int i = cur->_n - 1; i >= (int)index; --i){cur->_keys[i + 1] = cur->_keys[i];cur->_subs[i + 2] = cur->_subs[i + 1];}cur->_keys[index] = key;break;}}if (index == cur->_n){cur->_keys[index] = key;}//鏈接右孩子cur->_subs[index + 1] = sub;cur->_n++; }bool insert(const K& key) {if (_root == nullptr){_root = new Node;_root->_keys[0] = key;_root->_n++;return true;}pair<Node*, int> ret = find(key);//不允許冗余if (ret.second != -1){return false;}//cur為要插入的葉子結點Node* cur = ret.first;K newkey = key;Node* brother = nullptr;while (true){insertKey(cur, brother, newkey);//未滿,結束if (cur->_n < M){break;}//滿了,分裂出兄弟節點brother = new Node;size_t mid = M / 2;size_t k = 0;//左key1 左孩子1 ... 左keyM 左孩子M 右孩子for (size_t i = mid + 1; i < M; ++i){//分一半keybrother->_keys[k] = cur->_keys[i];cur->_keys[i] = K();//分左孩子brother->_subs[k] = cur->_subs[i];//鏈接父指針if (brother->_subs[k] != nullptr){brother->_subs[k]->_parent = brother;}cur->_subs[i] = nullptr;++k;}//最后一個右孩子brother->_subs[k] = cur->_subs[M];//鏈接父指針if (brother->_subs[k] != nullptr){brother->_subs[k]->_parent = brother;}cur->_subs[M] = nullptr;//修正borther的_n和cur的_n(cur->_n還要提一個中位數給parent)brother->_n += M - mid - 1;cur->_n -= M - mid;//brother的parent指向cur->_parentbrother->_parent = cur->_parent;newkey = cur->_keys[mid];cur->_keys[mid] = K();//轉換成向parent插入一個midkey和brotherif (cur->_parent == nullptr){_root = new Node;_root->_keys[0] = newkey;_root->_subs[0] = cur;_root->_subs[1] = brother;cur->_parent = _root;brother->_parent = _root;_root->_n++;break;}else{cur = cur->_parent;}}return true; }
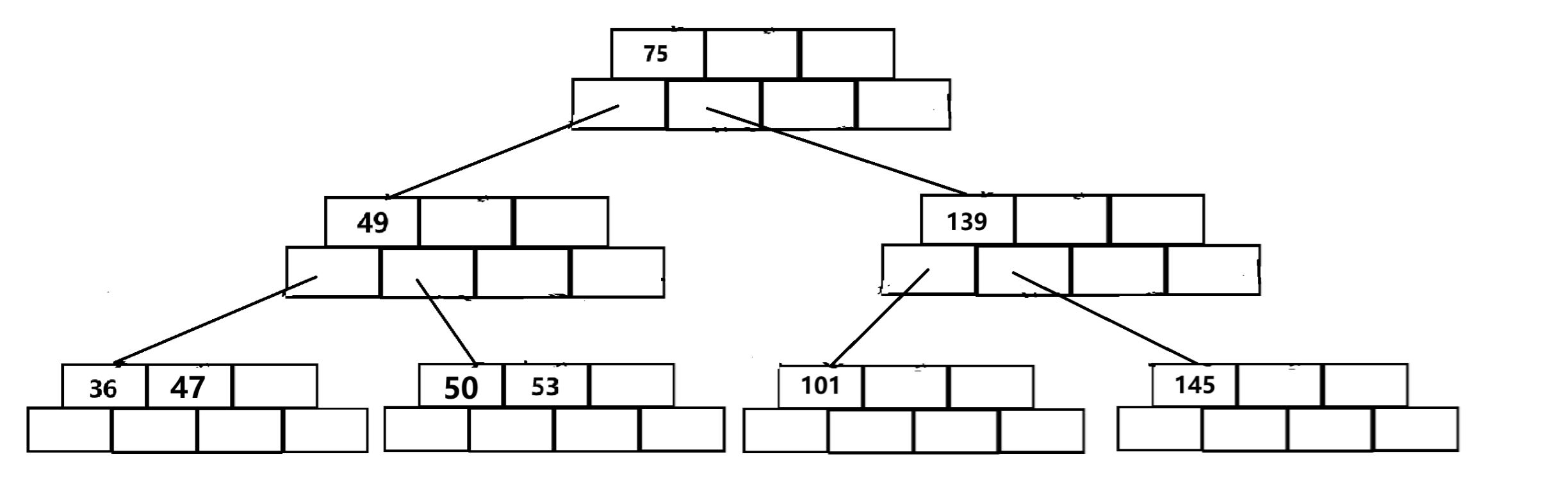
?B樹的查找:
分析:每個節點的key都是有序序列,且是一維數組,支持隨機訪問,因此選用二分查找。
問題就是如果二分查找當前序列找不到怎么辦?
二分查找如果找不到,找出來的數據是可能比key大,也可能比key小的。但由于二分查找定位的特性,找出來的數據一定是keys數組中和與key最接近的二者之一,可能在key左邊,也可能在右邊,判斷一下就行了,比key小就在key的右孩子里找,反之在key的左孩子里找。
注:由于查找在插入時也要用,要用parent記錄cur的parent,以便于走到空時能記錄下葉子節點的指針。
代碼試下如下:
pair<Node*, int> find(const K& key) {Node* cur = _root;Node* parent = nullptr;int begin, end, mid;while (cur){begin = 0;end = cur->_n - 1;//二分查找keywhile (begin <= end){mid = begin + ((end - begin) >> 1);// mid keyif (cur->_keys[mid] < key){begin = mid + 1;}//key midelse if (cur->_keys[mid] > key){end = mid - 1;}else{return { cur,mid };}}parent = cur;//沒有找到,mid是有效位置//可能大于或者小于keyif (cur->_keys[mid] < key){cur = cur->_subs[mid + 1];}else{cur = cur->_subs[mid];}}//cur走到nullptr,沒找到,返回葉子節點的指針return { parent,-1 }; }
B樹的中序遍歷:
分析:采用一個左孩子,一個關鍵字的方式遍歷,最后遍歷剩余的一個右孩子。
代碼如下:
void inorder() {_inorder(_root);cout << endl; } void _inorder(Node* root) {if (root == nullptr)return;//左1 根1 ... 左_n 根_n 右for (size_t i = 0; i < root->_n; ++i){_inorder(root->_subs[i]);cout << root->_keys[i] << " ";}_inorder(root->_subs[root->_n]); }
B樹性能分析:
B- 樹的效率是很高的,對于 N = 62*1000000000 個節點,如果度 M 為 1024,則logM/2(?N)≤4 ,即在620 億個元素中,如果這棵樹的度為 1024 ,則需要小于 4 次即可定位到該節點,然后利用 二分查找可以快速定位到該元素,大大減少了讀取磁盤的次數 。對于一顆滿的B樹, 查找的時間復雜度為O(logM(N))。
四、B+樹和B*樹
B+樹:
B+ 樹是 B 樹的變形,是在 B 樹基礎上優化的多路平衡搜索樹, B+ 樹的規則跟 B 樹基本類似,但是又在 B 樹的基礎上做了以下幾點改進優化:1)分支節點的子樹指針與關鍵字個數相同2)分支節點的子樹指針 p[i] 指向關鍵字值大小在 [k[i] , k[i+1]) 區間之間3)所有葉子節點增加一個鏈接指針鏈接在一起(核心)4)所有關鍵字及其映射數據都在葉子節點出現(核心)分析:1)和 2)優化了B樹操作的便捷性,等同于刪除了第一個節點的左孩子,且2)的優化存節點的最小值,進一步提高了查找的效率。3)和 4)優化了B樹的結構,將所有關鍵字及其映射數據都在葉子結點出現,并且葉子節點之間相連,方便遍歷。 B+ 樹的特性:1. 所有關鍵字都出現在葉子節點的鏈表中,且鏈表中的節點都是有序的。2. 不可能在分支節點中命中。3. 分支節點相當于是葉子節點的索引,葉子節點才是存儲數據的數據層。
B+ 樹的特性:1. 所有關鍵字都出現在葉子節點的鏈表中,且鏈表中的節點都是有序的。2. 不可能在分支節點中命中。3. 分支節點相當于是葉子節點的索引,葉子節點才是存儲數據的數據層。
B*樹:
B* 樹是 B+ 樹的變形,在 B+ 樹的非根和非葉子節點再增加指向兄弟節點的指針。 B* 樹的分裂:當一個結點滿時,如果它的下一個兄弟結點未滿,那么將一部分數據移到兄弟結點中,再在原結點插入關鍵字,最后修改父結點中兄弟結點的關鍵字(因為兄弟結點的關鍵字范圍改變了);如果兄弟也滿了,則在原結點與兄弟結點之間增加新結點,并各復制1/3 的數據到新結點,最后在父結點增加新結點的指針。總結:當一個節點滿時,轉移到下一個兄弟,直到所有的節點都滿了,分裂新的節點。
B* 樹的分裂:當一個結點滿時,如果它的下一個兄弟結點未滿,那么將一部分數據移到兄弟結點中,再在原結點插入關鍵字,最后修改父結點中兄弟結點的關鍵字(因為兄弟結點的關鍵字范圍改變了);如果兄弟也滿了,則在原結點與兄弟結點之間增加新結點,并各復制1/3 的數據到新結點,最后在父結點增加新結點的指針。總結:當一個節點滿時,轉移到下一個兄弟,直到所有的節點都滿了,分裂新的節點。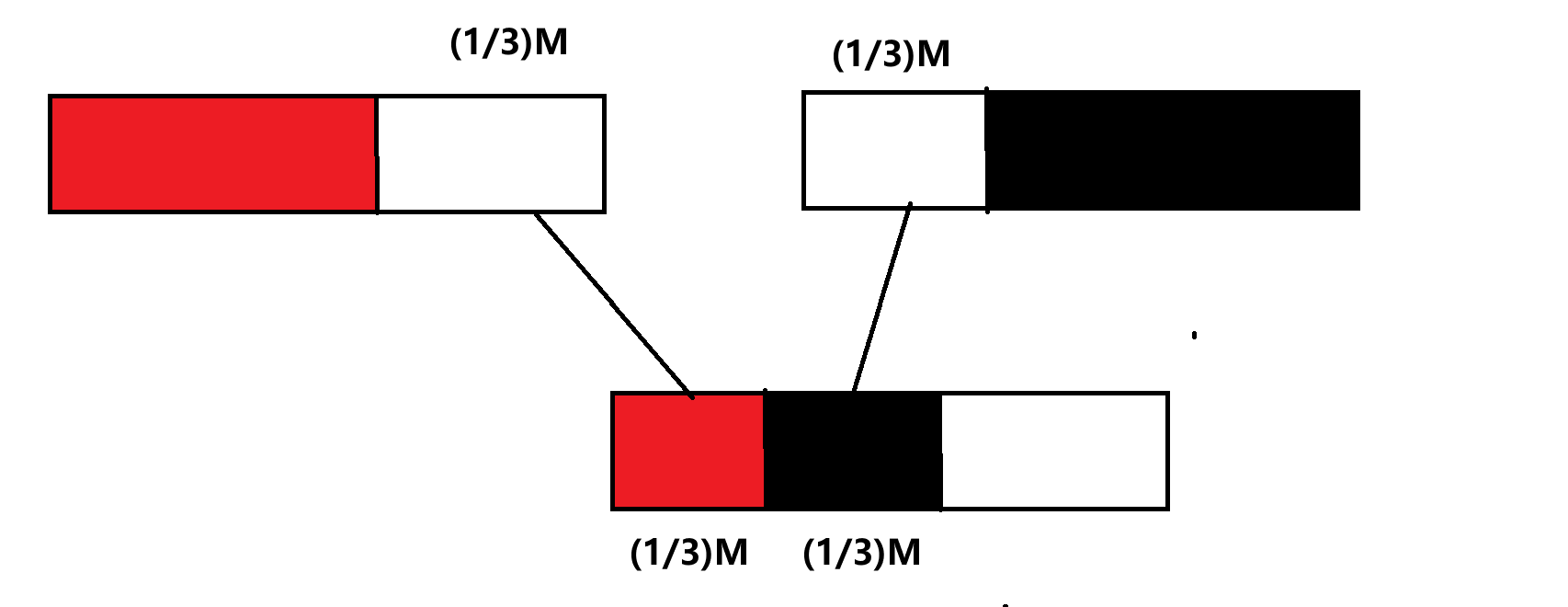 B* 樹分配新結點的概率比 B+ 樹要低,空間使用率更高。總結 :B 樹:有序數組 + 平衡多叉樹;B+ 樹:有序數組鏈表 + 平衡多叉樹;B* 樹:一棵更豐滿的,空間利用率更高的 B+ 樹。
B* 樹分配新結點的概率比 B+ 樹要低,空間使用率更高。總結 :B 樹:有序數組 + 平衡多叉樹;B+ 樹:有序數組鏈表 + 平衡多叉樹;B* 樹:一棵更豐滿的,空間利用率更高的 B+ 樹。
在內存中做內查找:?
B樹系列與哈希和平衡二叉搜索樹對比:
單純論樹高度,搜索效率而言,B樹快。
B樹系列隱形壞處:
1)空間利用率低,消耗高
2)插入刪除數據時,分裂和合并節點,那么必然挪動數據
3)在內存中而言,跟哈希和平衡二叉搜索樹還是一個量級。
結論:實質上B樹系列在內存中體現不出優勢。
五、B-樹的應用
B- 樹最常見的應用就是用來做索引 。MySQL 官方對索引的定義為: 索引 (index) 是幫助 MySQL 高效獲取數據的數據結構,簡單來說: 索引就是數據結構 。
mysql 是目前 非常流行的開源關系型數據庫,不僅是免費的,可靠性高,速度也比較快,而且擁 有靈活的插件式存儲引擎。 MySQL 中索引屬于存儲引擎級別的概念,不同存儲引擎對索引的實現方式是不同的。注 意:索引是基于表的,而不是基于數據庫的。
MySQL 中索引屬于存儲引擎級別的概念,不同存儲引擎對索引的實現方式是不同的。注 意:索引是基于表的,而不是基于數據庫的。
MyISAM 引擎是 MySQL5.5.8 版本之前默認的存儲引擎,不支持事物,支持全文檢索,使用 B+Tree作為索引結構,葉節點的data 域存放的是數據記錄的地址,其結構如下: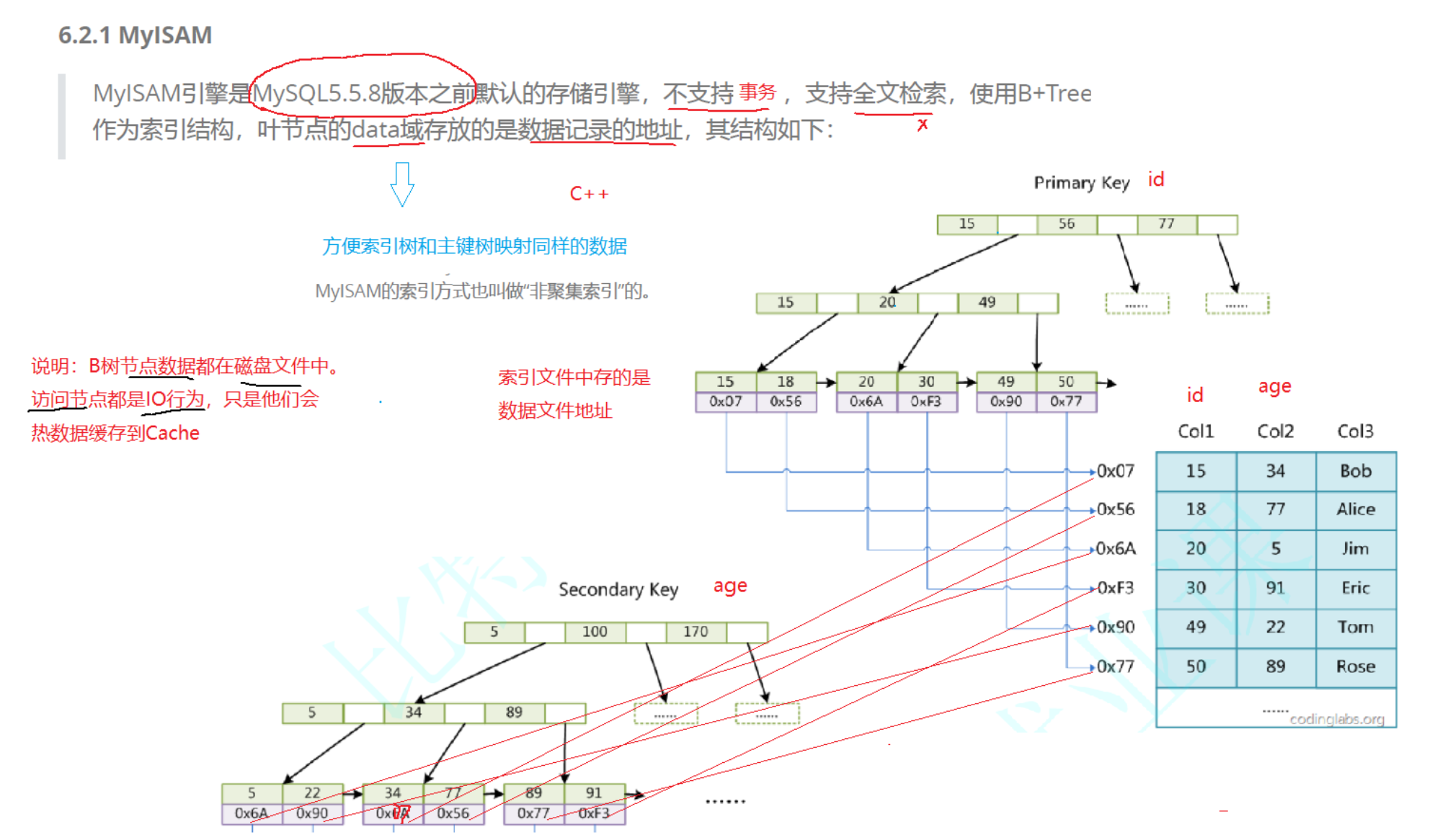 MyISAM 的索引文件僅僅保存數據記錄的 地址 。 在 MyISAM 中,主索引和輔助索引( Secondary key )在結構上沒有任何區別,只是主索 引要求 key 是唯一的,而輔助索引的 key 可以重復。Secondary key同樣也是一棵B+Tree , data 域保存數據記錄的地址。因此, MyISAM 中索引檢索的算法為首先按照B+Tree 搜索算法搜索索引,如果指定的 Key 存在,則取出其 data 域的值,然后以 data 域的值為地址,讀取相應數據記錄。MyISAM 的索引方式也叫做 “ 非聚集索引 ” 的。分支節點只存儲key,比較小。分支節點映射的磁盤塊就可以盡可能加載Cache。對于SQL分析:update stuInfo?set age = 35 where stuID = 50update stuInfo?set age = 35 where name?= 'Rose'這兩句SQL語句的性能不同。第一種,stuID為主鍵,主索引,結構是一顆B+樹,查找效率為O(logM(N))第二種,name不是主鍵,且沒有索引,查找時暴力遍歷,效率O(N)若想經常用name進行查找, 給name創建普通索引,相當于使用name做key創建一顆B+樹,value指向磁盤數據,這時候查找效率就高了。B+樹做主鍵索引比起B樹的優勢:1)B+樹所有值都在葉子,遍歷很方便,方便區間查找。2)對于沒有建立索引的字段,全表掃描很方便。3)分值節點存儲key,一個分支節點占用空間更少,可以盡可能加載到緩存。B樹優勢:不用帶葉子就能查找到值,但B+樹高度不高,效率差別不大。
MyISAM 的索引文件僅僅保存數據記錄的 地址 。 在 MyISAM 中,主索引和輔助索引( Secondary key )在結構上沒有任何區別,只是主索 引要求 key 是唯一的,而輔助索引的 key 可以重復。Secondary key同樣也是一棵B+Tree , data 域保存數據記錄的地址。因此, MyISAM 中索引檢索的算法為首先按照B+Tree 搜索算法搜索索引,如果指定的 Key 存在,則取出其 data 域的值,然后以 data 域的值為地址,讀取相應數據記錄。MyISAM 的索引方式也叫做 “ 非聚集索引 ” 的。分支節點只存儲key,比較小。分支節點映射的磁盤塊就可以盡可能加載Cache。對于SQL分析:update stuInfo?set age = 35 where stuID = 50update stuInfo?set age = 35 where name?= 'Rose'這兩句SQL語句的性能不同。第一種,stuID為主鍵,主索引,結構是一顆B+樹,查找效率為O(logM(N))第二種,name不是主鍵,且沒有索引,查找時暴力遍歷,效率O(N)若想經常用name進行查找, 給name創建普通索引,相當于使用name做key創建一顆B+樹,value指向磁盤數據,這時候查找效率就高了。B+樹做主鍵索引比起B樹的優勢:1)B+樹所有值都在葉子,遍歷很方便,方便區間查找。2)對于沒有建立索引的字段,全表掃描很方便。3)分值節點存儲key,一個分支節點占用空間更少,可以盡可能加載到緩存。B樹優勢:不用帶葉子就能查找到值,但B+樹高度不高,效率差別不大。
InnoDB 存儲引擎支持事務 ,其設計目標主要面向在線事務處理的應用,從 MySQL 數據庫 5.5.8 版 本開始, InnoDB 存儲引擎是默認的存儲引擎 。 InnoDB 支持 B+ 樹索引、全文索引、哈希索引。但InnoDB使用 B+Tree 作為索引結構時,具體實現方式卻與 MyISAM 截然不同。第一個區別是 InnoDB 的數據文件本身就是索引文件 。 MyISAM 索引文件和數據文件是分離的, 索引文件僅保存數據記錄的地址 。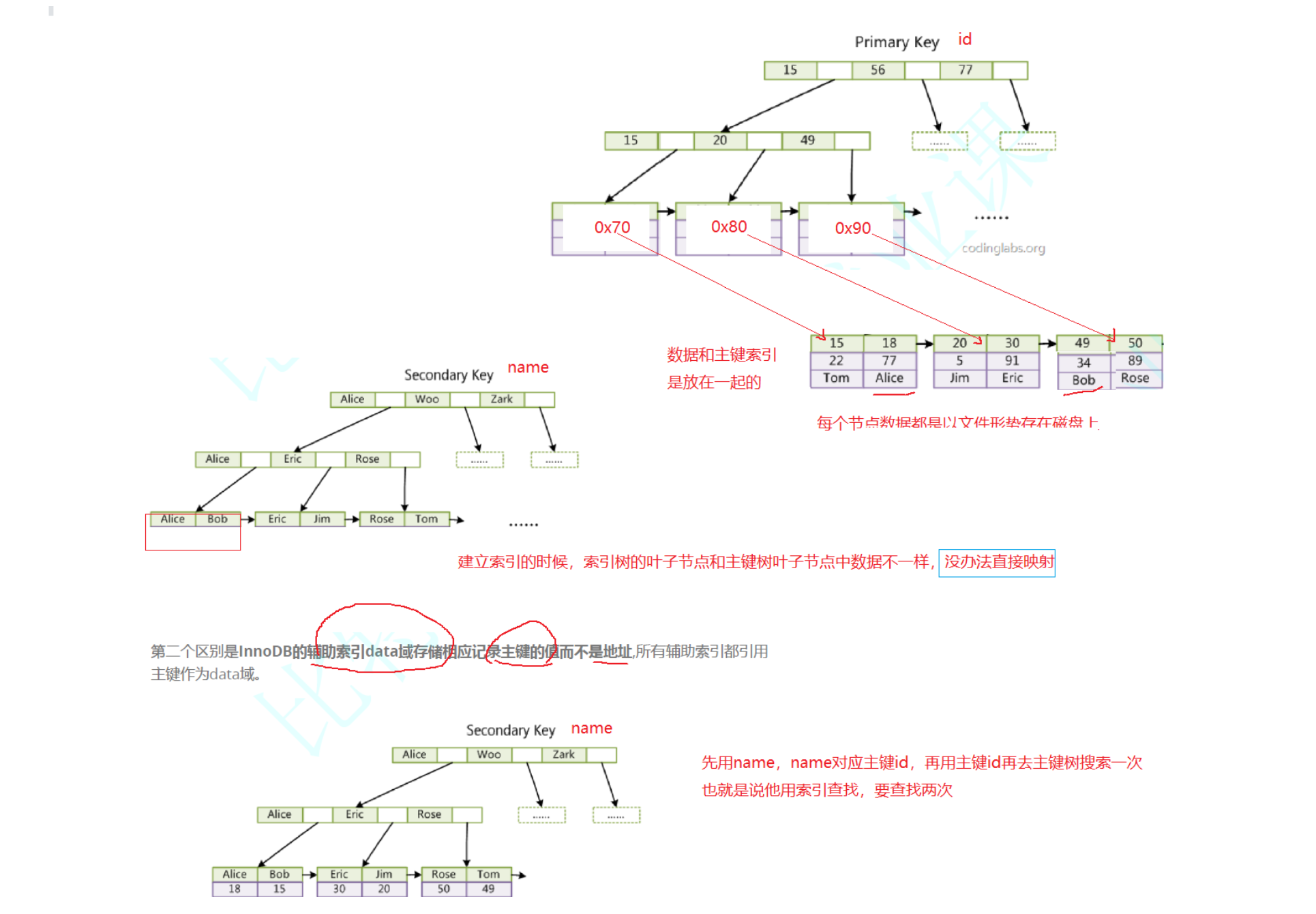 最大區別:每個葉子節點數據都是以文件形式存到磁盤上,數據和主鍵索引放在一起。 葉節點包含了完整的數據記錄, 這種索引叫做聚集索引 。所以 InnoDB 要求表必須有主鍵( MyISAM 可以沒有), 如果沒有顯式指定,則 MySQL 系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵, 如果不存在這種列,則 MySQL 自動為 InnoDB 表生成一個隱含字段作為主鍵,這個字段長度為6 個字節,類型為長整型。第二個區別是 InnoDB 的? 輔助索引data域存儲相應記錄主鍵的值而不是地址? , 所有輔助索引都引用主鍵作為data 域。聚集索引這種實現方式使得按主鍵的搜索十分高效 ,但是 輔助索引搜索需要檢索兩遍索引:首先 檢索輔助索引獲得主鍵,然后用主鍵到主索引中檢索獲得記錄。
最大區別:每個葉子節點數據都是以文件形式存到磁盤上,數據和主鍵索引放在一起。 葉節點包含了完整的數據記錄, 這種索引叫做聚集索引 。所以 InnoDB 要求表必須有主鍵( MyISAM 可以沒有), 如果沒有顯式指定,則 MySQL 系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵, 如果不存在這種列,則 MySQL 自動為 InnoDB 表生成一個隱含字段作為主鍵,這個字段長度為6 個字節,類型為長整型。第二個區別是 InnoDB 的? 輔助索引data域存儲相應記錄主鍵的值而不是地址? , 所有輔助索引都引用主鍵作為data 域。聚集索引這種實現方式使得按主鍵的搜索十分高效 ,但是 輔助索引搜索需要檢索兩遍索引:首先 檢索輔助索引獲得主鍵,然后用主鍵到主索引中檢索獲得記錄。

)






)
![[LeetCode 45] 跳躍游戲2 (Ⅱ)](http://pic.xiahunao.cn/[LeetCode 45] 跳躍游戲2 (Ⅱ))




)

)


