????????使用分頁作為核心機制來實現虛擬內存,可能會帶來較高的性能開銷。使用分頁,就要將內存地址空間切分成大量固定大小的單元(頁),并且需要記錄這些單元的地址映射信息。因為這些映射信息一般存儲在物理內存中,所以在轉換虛擬地址時,分頁邏輯上需要一次額外的內存訪問。每次指令獲取、顯式加載或保存,都要額外讀一次內存以得到轉換信息,這慢得無法接受。因此我們面臨如下問題:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??關鍵問題:如何加速地址轉換
????????如何才能加速虛擬地址轉換,盡量避免額外的內存訪問?需要什么樣的硬件支持?操作系統該如何 支持?
? ? ? ???硬件。增加所謂的地址轉換旁路緩沖存儲器(TLB 地址轉換緩存),它就是頻繁發生的虛擬到物理地址轉換的硬件緩存。對每次內存訪問,硬件先檢查TLB,看看其中是否有期望的轉換映射,如果有,就完成轉換(很快),不用訪問頁表 (其中有全部的轉換映射)。
一、TLB 的基本算法
? ? ? ? 圖 19.1 展示了一個大體框架,說明硬件如何處理虛擬地址轉換,假定使用簡單的線性頁表(即頁表是一個數組)和硬件管理的 TLB(硬件承擔許多頁表訪問的責任)。


????????硬件算法的大體流程如下:首先從虛擬地址中提取頁號(VPN)(見圖19.1第1行),然后檢查 TLB 是否有該 VPN 的轉換映射(第2行)。如果有,我們有了 TLB 命中(TLB hit),這意味著 TLB 有該頁的轉換映射。成功!接下來我們就可以從相關的 TLB 項中取出頁幀號(PFN),與原來虛擬地址中的偏移量組合形成期望的物理地址(PA),并訪問內存(第5~7 行),假定保護檢查沒有失敗(第4行)。
?????????如果 CPU 沒有在 TLB 中找到轉換映射(TLB未命中),我們有一些工作要做。在本例中,硬件訪問頁表來尋找轉換映射(第11~12行),并用該轉換映射更新 TLB(第 18 行),假設該虛擬地址有效,而且我們有相關的訪問權限(第 13、15 行)。上述系列操作開銷較大,主要是因為訪問頁表需要額外的內存引用(第12行)。最后,當 TLB 更新成功后,系統會重新嘗試該指令,這時 TLB 中有了這個轉換映射,內存引用得到很快處理。
?????????TLB 和其他緩存相似,前提是在一般情況下,轉換映射會在緩存中(即命中)。如果是這樣,只增加了很少的開銷,因為 TLB 處理器核心附近,設計的訪問速度很快。如果 TLB 未命中,就會帶來很大的分頁開銷。必須訪問頁表來查找轉換映射,導致一次額外的內存引用(或者更多,如果頁表更復雜)。因此,我們希望盡可能避免 TLB 未命中。
二、示例:訪問數組
?????????弄清楚 TLB 的操作,來看一個簡單虛擬地址追蹤,看看TLB如何提高性能。在本例中,假設有一個由10個4字節整型數組成的數組,起始虛地址是100。 進一步假定,有一個8位的小虛地址空間,頁大小為16B。 我們可以把虛地址劃分為 4 位的VPN(有16個虛擬內存頁)和 4位的偏移量(每個頁中有16個字節)。
????????圖19.2 展示了該數組的布局,在系統的 16 個 16 字節的頁上。數組的第一項(a[0])開始于(VPN=06, offset=04),只有 3 個 4字節整型數存放在該頁。數組在下一頁(VPN=07)繼續,其中有接下來4項(a[3] … a[6])。 10 個元素的數組的最后3項(a[7] … a[9])位于地址空間的下一頁(VPN=08)。
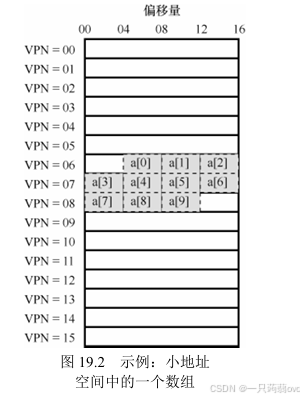
考慮一個簡單的循環,訪問數組中的每個元素,類似下面的?C 程序:
int sum=0;
for (i=0;i<10;i++){sum+=a[i];
}????????當訪問第一個數組元素(a[0])時,CPU 會看到載入虛存地址 100。硬件從中提取 VPN(VPN=06),然后用它來檢查 TLB,尋找有效的轉換映射。假設這里是程序第一次訪問該數組,結果是 TLB 未命中。
????????接下來訪問 a[1],TLB 命中!因為數組的第二個元素在第一個元素之后,它們在同一頁。因為我們之前訪問數組的第一個元素時,已經訪問了這一頁,所以TLB 中緩存了該頁的轉換映射。因此成功命中。訪問a[2]同樣成功(再次命中),因為它和a[0]、 a[1]位于同一頁。?
?????????遺憾的是,當程序訪問 a[3] 時,會導致 TLB 未命中。但同樣,接下來幾項(a[4] … a[6]) 都會命中TLB,因為它們位于內存中的同一頁。最后,訪問 a[7] 會導致最后一次TLB未命中。系統會再次查找頁表,弄清楚這個虛擬頁在物理內存中的位置,并相應地更新TLB。最后兩次訪問(a[8]、a[9])受益于這次 TLB 更新,當硬件在 TLB 中查找它們的轉換映射時,兩次都命中。
?????????我們來總結一下這 10 次數組訪問操作中 TLB 的行為表現:未命中、命中、命中、未命中、命中、命中、命中、未命中、命中、命中。命中的次數除以總的訪問次數,得到 TLB 命中率(hit rate)為 70%。即使這是程序首次訪問該數組,但得益于空間局部性(spatial locality),TLB 還是提高了性能。數組的元素被緊密存放在幾頁中(即它們在空間中緊密相鄰),因此只有對頁中第一個元素的訪問才會導致 TLB 未命中。

????????時間局部性:最近訪問過的指令或數據項可能很快會再次訪問。想想循環中的循環變量或指令,它們被多次反復訪問。
????????空間局部性:當程序訪問內存地址 x 時,可能很快會訪問鄰近 x 的內存。
三、處理 TLB 未命中
????????硬件或軟件(操作系統)。以前的硬件有復雜的指令集(有時稱為復雜指令集計算機,Complex-Instruction Set Computer,CISC)硬件全權處理 TLB 未命中。為了做到這一點,硬件必須知道頁表在內存中的確切位置(通過頁表基址寄存器, page-table base register,在圖 19.1 的第 11 行使用),以及頁表的確切格式。發生未命中時, 硬件會“遍歷”頁表,找到正確的頁表項,取出想要的轉換映射,用它更新 TLB,并重試該指令。這種“舊”體系結構有硬件管理的TLB,一個例子是x86架構,它采用固定的多級頁表(multi-level page table)
?????????更現代的體系結構,都是精簡指令集計算機,Reduced-Instruction Set Computer,RISC,有所謂的軟件管理 TLB(software- managed TLB)。發生 TLB 未命中時,硬件系統會拋出一個異常(見圖19.3第11行),這會暫停當前的指令流,將特權級提升至內核模式,跳轉至陷阱處理程序(trap handler)。接下來你可能已經猜到了,這個陷阱處理程序是操作系統的一段代碼,用于處理 TLB未命中。 這段代碼在運行時,會查找頁表中的轉換映射,然后用特別的“特權”指令更新 TLB,并從陷阱返回。此時,硬件會重試該指令(導致TLB命中)。

?????????首先,這里的從陷阱返回指令稍稍不同于之前提到的服務于系統調用的從陷阱返回。在后一種情況下,從陷阱返回應該繼續執行陷入操作系統之后那條指令,就像從函數調用返回后,會繼續執行此次調用之后的語句。在前一種情況下, 在從 TLB 未命中的陷阱返回后,硬件必須從導致陷阱的指令繼續執行。這次重試因此導致該指令再次執行,但這次會命中 TLB。因此,根據陷阱或異常的原因,系統在陷入內核時必須保存不同的程序計數器,以便將來能夠正確地繼續執行。
? ????????第二,在運行 TLB 未命中處理代碼時,操作系統需要格外小心避免引起 TLB 未命中的無限遞歸。有很多解決方案,例如,可以把 TLB未命中陷阱處理程序直接放到物理內存中 [它們沒有映射過(unmapped),不用經過地址轉換]。或者在 TLB 中保留一些項,記錄永久有效的地址轉換,并將其中一些永久地址轉換槽塊留給處理代碼本身,這些被監聽的(wired) 地址轉換總是會命中 TLB。
?????????軟件管理的方法,主要優勢是靈活性:操作系統可以用任意數據結構來實現頁表,不需要改變硬件。另一個優勢是簡單性。從 TLB 控制流中可以看出(見圖19.3的第 11 行, 對比圖19.1 的第11~19 行),硬件不需要對未命中做太多工作,它拋出異常,操作系統的未命中處理程序會負責剩下的工作。
四、TLB 內容
?????????硬件 TLB 中的內容。典型的 TLB 有 32 項、64 項或 128 項,并且是全相聯的(fully associative)。基本上,這就意味著一條地址映射可能存在TLB中的任意位置,硬件會并行地查找TLB,找到期望的轉換映射。一條TLB項內容可能像下面這樣:


?????????更有趣的是“其他位”。例如,TLB通常有一個有效(valid)位,用來標識該項是不是有效地轉換映射。通常還有一些保護(protection)位,用來標識該頁是否有訪問權限。例如,代碼頁被標識為可讀和可執行,而堆的頁被標識為可讀和可寫。還有其他一些位,包括地址空間標識符(address-space identifier)、臟位(dirty bit)等。
五、上下文切換時對 TLB 的處理
?????????有了TLB,在進程間切換時(因此有地址空間切換),會面臨一些新問題。具體來說,TLB 中包含的虛擬到物理的地址映射只對當前進程有效,對其他進程是沒有意義的。所以在發生進程切換時,硬件或操作系統(或二者)必須注意確保即將運行的進程不要誤讀了之前進程的地址映射。
?????????來看一個例子,當一個進程(P1)正在運行時,假設 TLB 緩存了對它有效的地址映射,即來自 P1 的頁表。對這個例子,假設 P1 的 10號虛擬頁映射到了 100 號物理幀。
? ? ? ? 在該例中,假設還有一個進程(P2),操作系統不久后決定進行一次上下文切換,運行 P2。這里假定 P2 的 10 號虛擬頁映射到170號物理幀。如果這兩個進程的地址映射都在TLB中,TLB的內容如表 19.1 所示。
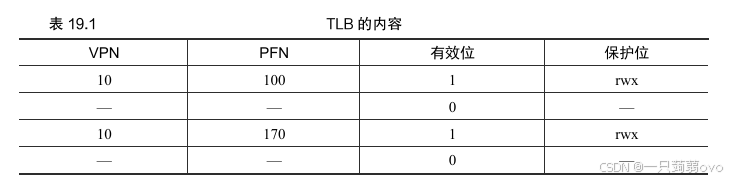 ?????????在上面的 TLB 中,很明顯有一個問題:VPN 10 被轉換成了 PFN 100(P1)和 PFN 170(P2),但硬件分不清哪個項屬于哪個進程。所以還需要做一些工作,讓 TLB 正確而高效地支持跨多進程的虛擬化。關鍵問題是:
?????????在上面的 TLB 中,很明顯有一個問題:VPN 10 被轉換成了 PFN 100(P1)和 PFN 170(P2),但硬件分不清哪個項屬于哪個進程。所以還需要做一些工作,讓 TLB 正確而高效地支持跨多進程的虛擬化。關鍵問題是:
????????????????????????????????????????關鍵問題:進程切換時如何管理TLB的內容
????????如果發生進程間上下文切換,上一個進程在 TLB 中的地址映射對于即將運行的進程是無意義的。 硬件或操作系統應該做些什么來解決這個問題呢?
????????一種方法是在上下文切換時,簡單地清空(flush)TLB, 這樣在新進程運行前TLB就變成了空的。如果是軟件管理 TLB 的系統,可以在發生上下文切換時,通過一條顯式(特權)指令來完成。如果是硬件管理?TLB,則可以在頁表基址寄存器內容發生變化時清空TLB(注意,在上下文切換時,操作系統必須改變頁表基址寄存器(PTBR) 的值)。不論哪種情況,清空操作都是把全部有效位(valid)置為0,本質上清空了TLB。?
?????????上下文切換的時候清空 TLB,這是一個可行的解決方案,進程不會再讀到錯誤的地址映射。但是,有一定開銷:每次進程運行,當它訪問數據和代碼頁時,都會觸發TLB未命中。如果操作系統頻繁地切換進程,這種開銷會很高。
?????????為了減少這種開銷,一些系統增加了硬件支持,實現跨上下文切換的 TLB共享。比如有的系統在 TLB 中添加了一個地址空間標識符(Address Space Identifier,ASID)。可以把 ASID 看作是進程標識符(Process Identifier,PID),但通常比 PID 位數少(PID一般32位, ASID 一般是8位)。
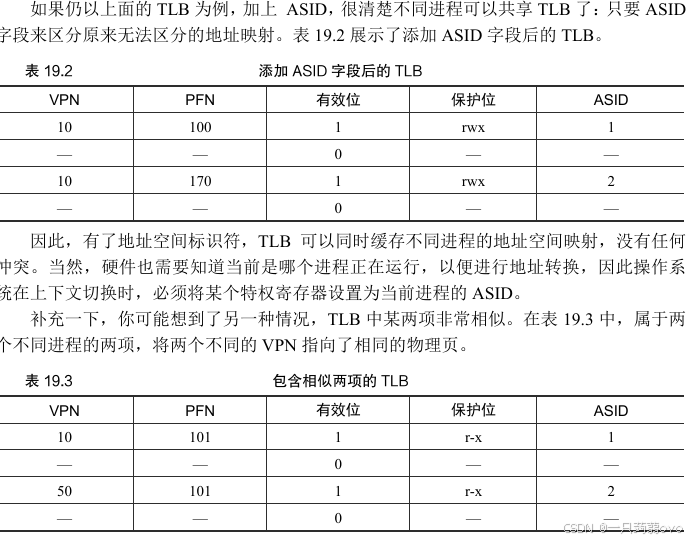
?????????如果兩個進程共享同一物理頁(例如代碼段的頁),就可能出現這種情況。在上面的例子中,進程 P1 和進程 P2 共享101號物理頁,但是 P1 將自己的10號虛擬頁映射到該物理頁,而P2將自己的50號虛擬頁映射到該物理頁。共享代碼頁(以二進制或共享庫的方式) 是有用的,因為它減少了物理頁的使用,從而減少了內存開銷。
六、TLB 替換策略
?????????TLB 和其他緩存一樣,還有一個問題要考慮,即緩存替換(cache replacement)。具體來 說,向 TLB 中插入新項時,會替換(replace)一個舊項,這樣問題就來了:應該替換哪一個?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?關鍵問題:如何設計TLB替換策略
????????在向TLB 添加新項時,應該替換哪個舊項?目標當然是減小TLB未命中率(或提高命中率),從而改進性能。
?????????一種常見的策略是替換最近最少使用(least-recently-used,LRU)的項。LRU 嘗試利用內存引用流中的局部性,假定最近沒有用過的項,可能是好的換出候選項。另一種典型策略就是隨機(random)策略,即隨機選擇一項換出去。這種策略很簡單,并且可以避免一種極端情況。例如,一個程序循環訪問 n+1 個頁,但TLB大小只能存放 n個頁。 這時之前看似“合理”的LRU策略就會表現得不可理喻,因為每次訪問內存都會觸發TLB 未命中,而隨機策略在這種情況下就好很多。
七、實際系統的 TLB 表項
?????????真實的 TLB,來自 MIPS R4000,是一種現代的系統,采用軟件管理 TLB。圖 19.4 展示了稍微簡化的 MIPS TLB 項。
?
?????????MIPS R4000 支持 32 位的地址空間,頁大小為4KB。所以在典型的虛擬地址中,預期會看到20位的VPN和12位的偏移量。但是,你可以在TLB中看到,只有19位的VPN。 事實上,用戶地址只占地址空間的一半(剩下的留給內核),所以只需要19位的 VPN。VPN 轉換成最大24位的物理幀號(PFN),因此可以支持最多有64GB(2^38)物理內存(2^24個4KB內存頁)的系統。
????????MIPS TLB 還有一些有趣的標識位。比如全局位(Global,G),用來指示這個頁是不是所有進程全局共享的。因此,如果全局位置為1,就會忽略ASID。我們也看到了8位的ASID,操作系統用它來區分進程空間(像上面介紹的一樣)。這里有一個問題:如果正在運行的進程數超過 256(2^8)個怎么辦?最后,我們看到 3 個一致性位(Coherence,C),決定硬件如何緩存該頁(其中一位超出了本書的范圍);臟位(dirty),表示該頁是否被寫入新數據(后面會介紹用法);有效位(valid),告訴硬件該項的地址映射是否有效。還有沒在圖 19.4 中展示的頁掩碼(page mask)字段,用來支持不同的頁大小。后面會介紹,為什么更大的頁可能有用。最后,64位中有一些未使用(圖19.4中灰色部分)。
????????MIPS 的 TLB 通常有32項或64項,大多數提供給用戶進程使用,也有一小部分留給操作系統使用。操作系統可以設置一個被監聽的寄存器,告訴硬件需要為自己預留多少 TLB 槽。這些保留的轉換映射,被操作系統用于關鍵時候它要使用的代碼和數據,在這些時候,TLB未命中可能會導致問題(例如,在TLB未命中處理程序中)。
?????????由于MIPS的 TLB 是軟件管理的,所以系統需要提供一些更新TLB的指令。MIPS提供了4個這樣的指令:TLBP,用來查找指定的轉換映射是否在TLB中;TLBR,用來將 TLB 中的內容讀取到指定寄存器中;TLBWI,用來替換指定的 TLB 項;TLBWR,用來隨機替換一個TLB項。操作系統可以用這些指令管理 TLB 的內容。當然這些指令是特權指令。
八、小結
?????????通過增加一個小的、芯片內的TLB作為地址轉換的緩存,大多數內存引用就不用訪問內存中的頁表了。
????????但是,TLB 也不能滿足所有的程序需求。具體來說,如果一個程序短時間內訪問的頁數超過了 TLB 中的頁數,就會產生大量的 TLB 未命中,運行速度就會變慢。這種現象被稱為超出 TLB 覆蓋范圍(TLB coverage),這對某些程序可能是相當嚴重的問題。解決這個問題的一種方案是支持更大的頁,把關鍵數據結構放在程序地址空間的某些區域,這些區域被映射到更大的頁,使 TLB 的有效覆蓋率增加。對更大頁的支持通常被數據庫管理系統 (Database Management System,DBMS)這樣的程序利用,它們的數據結構比較大,而且是隨機訪問。
?????????另一個TLB問題值得一提:訪問TLB很容易成為CPU流水線的瓶頸,尤其是有所謂的物理地址索引緩存(physically-indexed cache)。有了這種緩存,地址轉換必須發生在訪問該緩存之前,這會讓操作變慢。為了解決這個潛在的問題,人們研究了各種巧妙的方法, 用虛擬地址直接訪問緩存,從而在緩存命中時避免昂貴的地址轉換步驟。
創建docx文檔和表格)








)


之將對話記錄保存到數據庫中)

 - 多租戶的SAAS版實現(2))
架構方面的設計)

![[Python基礎速成]1-Python規范與核心語法](http://pic.xiahunao.cn/[Python基礎速成]1-Python規范與核心語法)

