引言
在當今數據驅動的時代,高效的數據存儲和檢索對于各類應用程序至關重要。Redis(Remote Dictionary Server)作為一款開源的內存鍵值數據庫,憑借其出色的性能、豐富的數據結構和靈活的特性,在眾多場景中得到了廣泛應用。本文將深入探討 Redis 的基本概念、核心特性、常用命令以及實際應用案例,幫助讀者全面了解和掌握 Redis
一.Redis相關命令詳解及其原理
1.redis是什么?
Redis 是 Remote Dictionary Service 的簡稱;也是遠程字典服務,通過tcp和redis建立連接交互,通過字典的方式索引存儲數據。
Redis 是內存數據庫,KV 數據庫,數據結構數據庫,數據都在內存中。
2.redis中存儲數據的數據結構都有哪些?
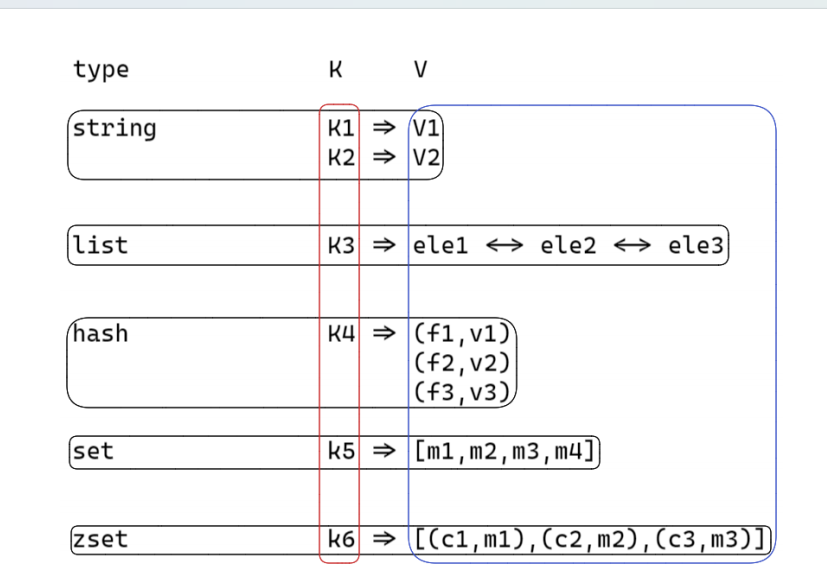
①string:是一個安全的二進制字符串。
②雙端隊列(鏈表)list :有序(插入有序)。
③散列表 hash :對順序不關注, field 是唯一的;
④無序集合 set :對順序不關注,里面的值都是唯一的;
⑤有序集合 zset :對順序是關注的,里面的值是唯一的;根據member 來確定唯一;根據 score 來確定有序;
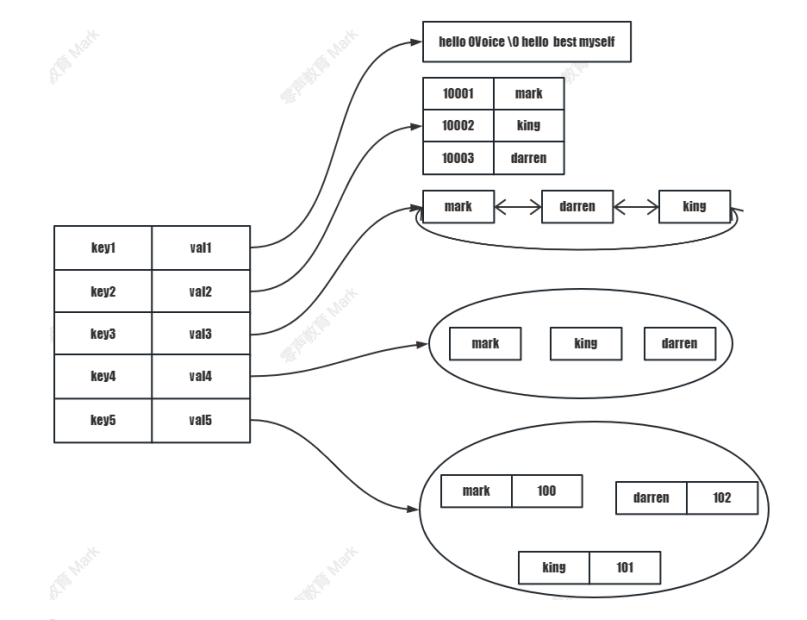
3.redis的存儲結構(KV)
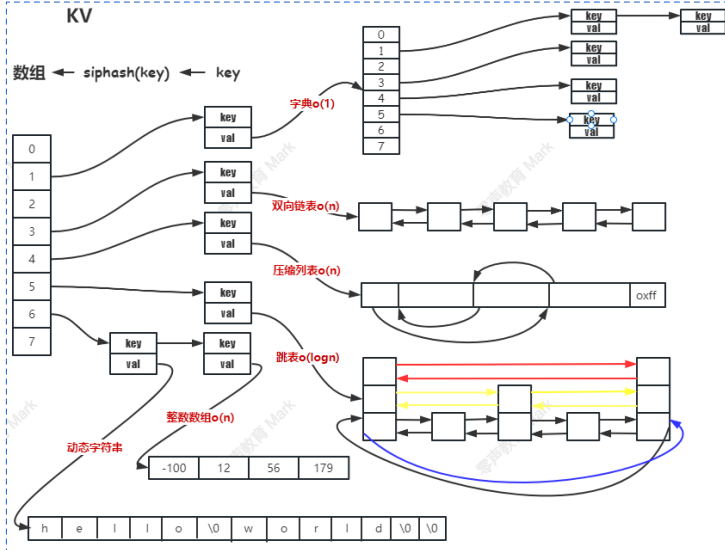
4.reidis中value編碼
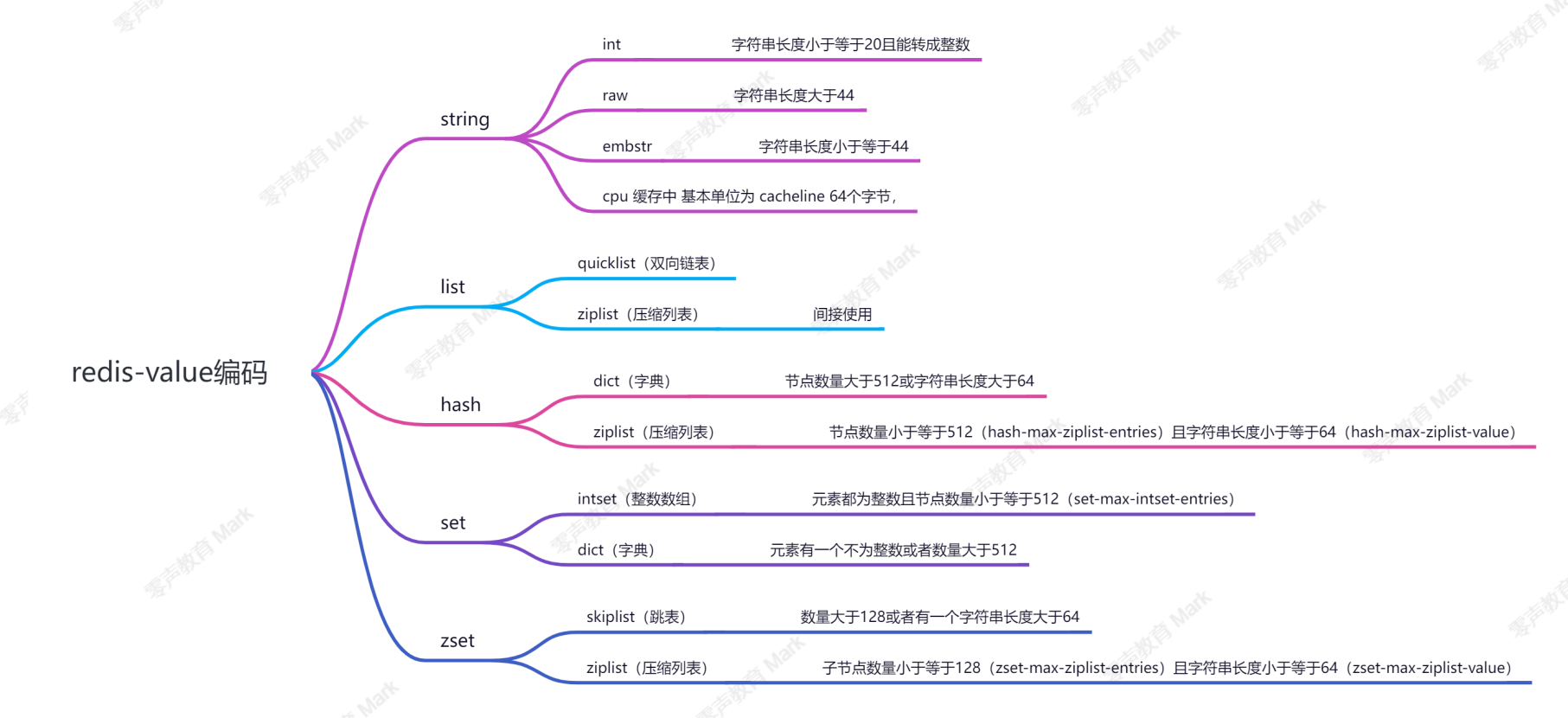
數據量 少 的時候,存儲效率高為主;數據量 多 的時候,運行速度快;
5.string的基本原理和相關命令
5.1基本原理
字符數組,該字符串是動態字符串 raw ,字符串長度小于 1M時,加倍擴容;超過 1M 每次只多擴 1M ;字符串最大長度為 512M ;注意: redis 字符串是二進制安全字符串;可以存儲圖片,二進制協議等二進制數據;
5.2基礎命令
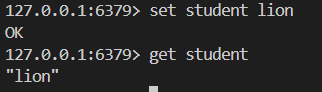
# 設置 key 的 value 值
SET key val
# 獲取 key 的 value
GET key
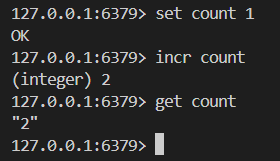
# 執行原子加一的操作
INCR key
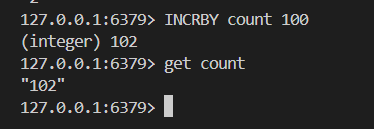
# 執行原子加一個整數的操作
INCRBY key increment
# 執行原子減一的操作
DECR key
# 執行原子減一個整數的操作
DECRBY key decrement
# 如果key不存在,這種情況下等同SET命令。當key存在時,什
么也不做
# set Not eXist ? ok 這個命令是否執行了 0,1 是不是操
作結果是不是成功
SETNX key value
# 刪除 key val 鍵值對
DEL key
# 設置或者清空key的value(字符串)在offset處的bit值。
setbit embstr raw int
# 動態字符串能夠節約內存
SETBIT key offset value
# 返回key對應的string在offset處的bit值
GETBIT key offset
# 統計字符串被設置為1的bit數.
BITCOUNT key我們來舉一些簡單的例子
5.3string存儲結構
字符串長度小于等于 20 且能轉成整數,則使用 int 存儲;字符串長度小于等于 44 ,則使用 embstr 存儲;字符串長度大于 44 ,則使用 raw 存儲;
5.4應用場景
對象存儲
SET role:10001 '{["name"]:"lion",["sex"]:"male",
["age"]:30}'
SET role:10002 '{["name"]:"xiaoyu",["sex"]:"female",
["age"]:30}'我們應該如何設置Key 才能讓它更有意義呢?單個功能的一個key:取有意義名字的key相同功能的多個key:我們可以以:作為分割

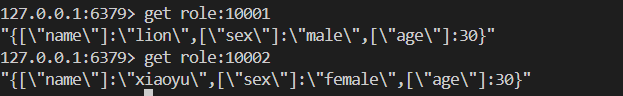
# 統計閱讀數 累計加1
incr reads
# 累計加100
incrby reads 100分布式鎖
# 加鎖 ? 加鎖 和 解析 redis 實現是 非公平鎖 ? ? ectd
zk 用來實現公平鎖
# 阻塞等待 ? 阻塞連接的方式
# 介紹簡單的原理: 事務
setnx lock 1 ? # 不存在才能設置 定義加鎖行為 占用鎖 ?
setnx lock uuid ?# expire 30 過期
set lock uuid nx ex 30
# 釋放鎖
del lock
if (get(lock) == uuid)del(lock);位運算
# 猜測一下 string 是用的 int 類型 還是 string 類型
# 月簽到功能 10001 用戶id 202106 2021年6月份的簽到 6月
份的第1天
setbit sign:10001:202106 1 1
# 計算 2021年6月份 的簽到情況
bitcount sign:10001:202106
# 獲取 2021年6月份 第二天的簽到情況 1 已簽到 0 沒有簽到
getbit sign:10001:202106 26.list的基本原理和相關命令
6.1基本原理
雙向鏈表實現,列表首尾操作(刪除和增加)時間復雜度O(1) ;查找中間元素時間復雜度為 O(n) ;列表中數據是否壓縮的依據:1. 元素長度小于 48 ,不壓縮;2. 元素壓縮前后長度差不超過 8 ,不壓縮;
6.2基礎命令
# 從隊列的左側入隊一個或多個元素
LPUSH key value [value ...]
# 從隊列的左側彈出一個元素
LPOP key
# 從隊列的右側入隊一個或多個元素
RPUSH key value [value ...]
# 從隊列的右側彈出一個元素
RPOP key
# 返回從隊列的 start 和 end 之間的元素 0, 1 2 負索引
LRANGE key start end
# 從存于 key 的列表里移除前 count 次出現的值為 value 的
元素
# list 沒有去重功能 ? hash set zset
LREM key count value
# 它是 RPOP 的阻塞版本,因為這個命令會在給定list無法彈出
任何元素的時候阻塞連接
BRPOP key timeout ?# 超時時間 + 延時隊列舉栗子
我們采用lpush從左邊插入五個人名
![]()
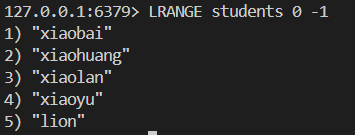
我們采用的是從左邊插入的方法 也就是所謂的頭插法? 簡易鏈表展示如下
lion
xiaoyu-->lion
xiaolan-->xiaoyu-->lion
xiaohuang-->xiaolan-->xiaoyu-->lion
xiaobai-->xiaohuang-->xiaolan-->xiaoyu-->lion
?我們分別從左邊和右邊彈出一個元素 結果如下
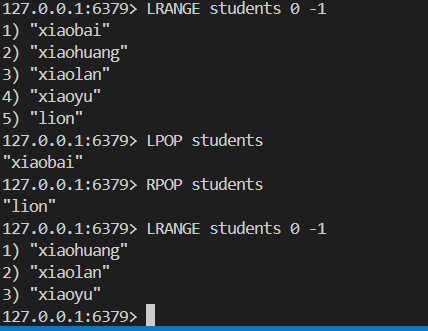
6.3存儲結構
/* Minimum ziplist size in bytes for attempting
compression. */
#define MIN_COMPRESS_BYTES 48
/* quicklistNode is a 32 byte struct describing a
ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32
bytes.
* count: 16 bits, max 65536 (max zl bytes is
65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is
temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for
verifying during testing.
* extra: 10 bits, free for future use; pads out
the remainder of 32 bits */
typedef struct quicklistNode {struct quicklistNode *prev;struct quicklistNode *next;unsigned char *zl;unsigned int sz; ? ? ? ? ? ? /* ziplist size
in bytes */unsigned int count : 16; ? ? /* count of
items in ziplist */unsigned int encoding : 2; ? /* RAW==1 or
LZF==2 */unsigned int container : 2; ?/* NONE==1 or
ZIPLIST==2 */unsigned int recompress : 1; /* was this node
previous compressed? */unsigned int attempted_compress : 1; /* node
can't compress; too small */unsigned int extra : 10; /* more bits to
steal for future usage */
} quicklistNode;
typedef struct quicklist {quicklistNode *head;quicklistNode *tail;unsigned long count; ? ? ? ?/* total count of
all entries in all ziplists */unsigned long len; ? ? ? ? ?/* number of
quicklistNodes */int fill : QL_FILL_BITS; ? ? ? ? ? ? ?/* fill
factor for individual nodes */unsigned int compress : QL_COMP_BITS; /*
depth of end nodes not to compress;0=off */unsigned int bookmark_count: QL_BM_BITS;quicklistBookmark bookmarks[];
} quicklist;6.4應用場景
LPUSH + LPOP
# 或者
RPUSH + RPOPLPUSH + RPOP
# 或者
RPUSH + LPOPLPUSH + BRPOP
# 或者
RPUSH + BLPOP-- redis lua腳本
local record = KEYS[1]
redis.call("LPUSH", "says", record)
redis.call("LTRIM", "says", 0, 4)7.hash的基本原理和相關命令
7.1基本原理
散列表,在很多高級語言當中包含這種數據結構; c++unordered_map 通過 key 快速索引 value ;
7.2基礎命令
# 獲取 key 對應 hash 中的 field 對應的值
HGET key field
# 設置 key 對應 hash 中的 field 對應的值
HSET key field value
# 設置多個hash鍵值對
HMSET key field1 value1 field2 value2 ... fieldn
valuen
# 獲取多個field的值
HMGET key field1 field2 ... fieldn
# 給 key 對應 hash 中的 field 對應的值加一個整數值
HINCRBY key field increment
# 獲取 key 對應的 hash 有多少個鍵值對
HLEN key
# 刪除 key 對應的 hash 的鍵值對,該鍵為field
HDEL key field舉栗子
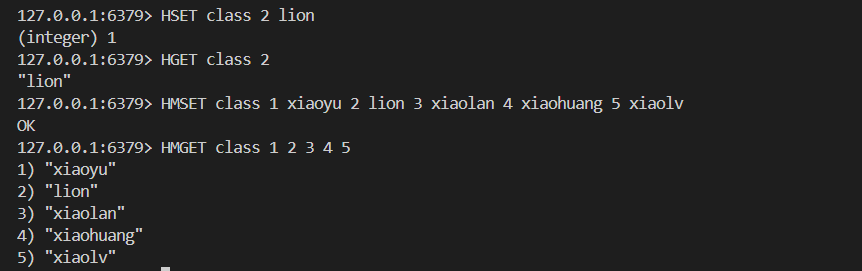

7.3存儲結構
節點數量大于 512 ( hash-max-ziplist-entries ) 或所有字符串長度大于 64 ( hash-max-ziplist-value ),則使用 dict 實現;節點數量小于等于 512 且有一個字符串長度小于 64 ,則使用ziplist 實現;
?7.4應用場景
存儲對象
hmset hash:10001 name lion age 18 sex male
# 與 string 比較
set hash:10001 '{["name"]:"lion",["sex"]:"male",
["age"]:18}'
# 假設現在修改 lion的年齡為19歲
# hash:hset hash:10001 age 19
# string:get hash:10001# 將得到的字符串調用json解密,取出字段,修改 age 值# 再調用json加密set hash:10001 '{["name"]:"lion",
["sex"]:"male",["age"]:19}'# 將用戶id作為 key
# 商品id作為 field
# 商品數量作為 value
# 注意:這些物品是按照我們添加順序來顯示的;# 添加商品:hmset MyCart:10001 40001 1 cost 5099 desc "戴爾
筆記本14-3400"lpush MyItem:10001 40001
# 增加數量:
hincrby MyCart:10001 40001 1hincrby MyCart:10001 40001 -1 // 減少數量1
# 顯示所有物品數量:hlen MyCart:10001
# 刪除商品:hdel MyCart:10001 40001lrem MyItem:10001 1 40001
# 獲取所有物品:lrange MyItem:10001# 40001 40002 40003hget MyCart:10001 40001hget MyCart:10001 40002hget MyCart:10001 400038.set的基本原理和相關命令
8.1基本原理
集合;用來存儲唯一性字段,不要求有序;存儲不需要有序,操作(交并差集的時候排序)?
?8.2基礎命令
# 添加一個或多個指定的member元素到集合的 key中
SADD key member [member ...]
# 計算集合元素個數
SCARD key
# SMEMBERS key
SMEMBERS key
# 返回成員 member 是否是存儲的集合 key的成員
SISMEMBER key member
# 隨機返回key集合中的一個或者多個元素,不刪除這些元素
SRANDMEMBER key [count]
# 從存儲在key的集合中移除并返回一個或多個隨機元素
SPOP key [count]# 返回一個集合與給定集合的差集的元素
SDIFF key [key ...]
# 返回指定所有的集合的成員的交集
SINTER key [key ...]
# 返回給定的多個集合的并集中的所有成員
SUNION key [key ...]舉栗子
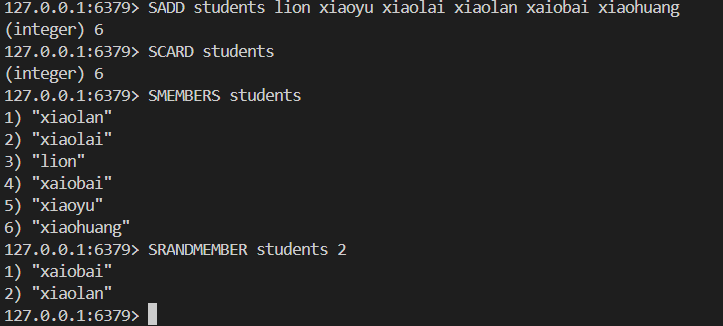
8.3存儲結構
元素都為整數且節點數量小于等于 512 ( set-max-intsetentries ),則使用整數數組存儲;元素當中有一個不是整數或者節點數量大于 512 ,則使用字典存儲;
8.4應用場景?
抽獎
# 添加抽獎用戶sadd Award:1 10001 10002 10003 10004 10005
10006sadd Award:1 10009
# 查看所有抽獎用戶smembers Award:1
# 抽取多名幸運用戶srandmember Award:1 10
# 如果抽取一等獎1名,二等獎2名,三等獎3名,該如何操作?共同關注
sadd follow:A mark king darren mole vico
sadd follow:C mark king darren
sinter follow:A follow:Csadd follow:A mark king darren mole vico
sadd follow:C mark king darren
# C可能認識的人:sdiff follow:A follow:C9.zset的基本原理和相關命令
9.1基本原理
有序集合;用來實現排行榜;它是一個有序唯一;
?9.2基礎命令
# 添加到鍵為key有序集合(sorted set)里面
ZADD key [NX|XX] [CH] [INCR] score member [score
member ...]
# 從鍵為key有序集合中刪除 member 的鍵值對
ZREM key member [member ...]
# 返回有序集key中,成員member的score值
ZSCORE key member
# 為有序集key的成員member的score值加上增量increment
ZINCRBY key increment member
# 返回key的有序集元素個數
ZCARD key
# 返回有序集key中成員member的排名
ZRANK key member
# 返回存儲在有序集合key中的指定范圍的元素 ? order by id
limit 1,100
ZRANGE key start stop [WITHSCORES]
# 返回有序集key中,指定區間內的成員(逆序)
ZREVRANGE key start stop [WITHSCORES]舉栗子


![]()
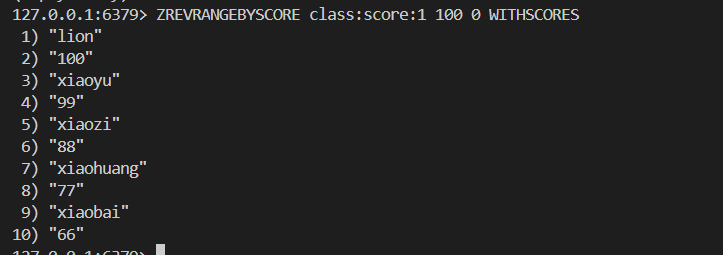
9.3存儲結構
節點數量大于 128 或者有一個字符串長度大于 64 ,則使用跳表( skiplist );節點數量小于等于 128 ( zset-max-ziplist-entries )且所有字符串長度小于等于 64 ( zset-max-ziplist-value ),則使用ziplist 存儲;數據少的時候,節省空間O(n)數據多的時候,訪問性能O(1) or O(logn)
?9.4應用場景
百度熱搜
# 點擊新聞:zincrby hot:20230612 1 10001zincrby hot:20230612 1 10002zincrby hot:20230612 1 10003zincrby hot:20230612 1 10004zincrby hot:20230612 1 10005zincrby hot:20230612 1 10006zincrby hot:20230612 1 10007zincrby hot:20230612 1 10008zincrby hot:20230612 1 10009zincrby hot:20230612 1 10010# 獲取排行榜:zrevrange hot:20230612 0 9 withscores將消息序列化成一個字符串作為 zset 的 member ;這個消息的到期處理時間作為 score ,然后用多個線程輪詢 zset 獲取到期的任務進行處理。
def delay(msg):msg.id = str(uuid.uuid4()) #保證 member 唯一value = json.dumps(msg)retry_ts = time.time() + 5 # 5s后重試redis.zadd("delay-queue", retry_ts, value)
# 使用連接池
def loop():while True:values = redis.zrangebyscore("delayqueue", 0, time.time(), start=0, num=1)if not values:time.sleep(1)continuevalue = values[0]success = redis.zrem("delay-queue",
value)if success:msg = json.loads(value)handle_msg(msg)
# 缺點:loop 是多線程競爭,兩個線程都從zrangebyscore獲
取到數據,但是zrem一個成功一個失敗,
# 優化:為了避免多余的操作,可以使用lua腳本原子執行這兩個
命令
# 解決:漏斗限流?分布式定時器
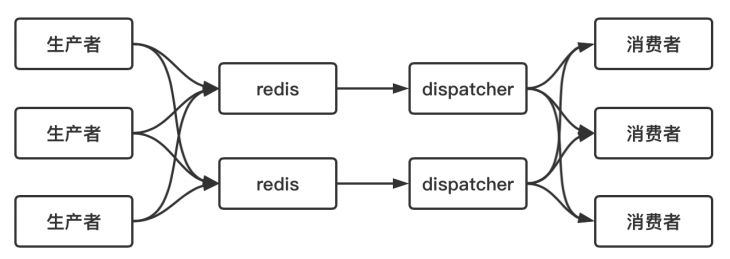
生產者將定時任務 hash 到不同的 redis 實體中,為每一個redis 實體分配一個 dispatcher 進程,用來定時獲取 redis 中超時事件并發布到不同的消費者中;
時間窗口限流?
系統限定用戶的某個行為在指定的時間范圍內(動態)只能發生 N 次;
# 指定用戶 user_id 的某個行為 action 在特定時間內
period 只允許發生該行為做大次數 max_count
local function is_action_allowed(red, userid,
action, period, max_count)local key = tab_concat({"hist", userid,
action}, ":")local now = zv.time()red:init_pipeline()-- 記錄行為red:zadd(key, now, now)-- 移除時間窗口之前的行為記錄,剩下的都是時間窗口內的
記錄red:zremrangebyscore(key, 0, now - period
*100)-- 獲取時間窗口內的行為數量red:zcard(key)-- 設置過期時間,避免冷用戶持續占用內存 時間窗口的長
度+1秒red:expire(key, period + 1)local res = red:commit_pipeline()return res[3] <= max_count
end# 維護一次時間窗口,將窗口外的記錄全部清理掉,只保留窗口內
的記錄;# 缺點:記錄了所有時間窗口內的數據,如果這個量很大,不適合
做這樣的限流;漏斗限流
# 注意:如果用 key + expire 操作也能實現,但是實現的是熔
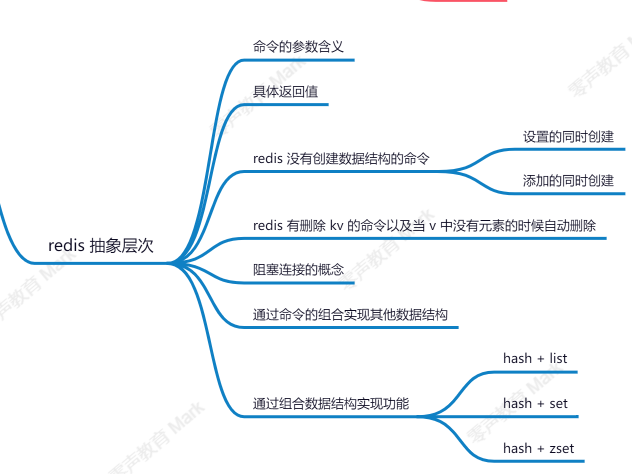
斷限流,這里是時間窗口限流的功能;score?10.redis的抽象層次
補充:redis設置過期時間
①expire
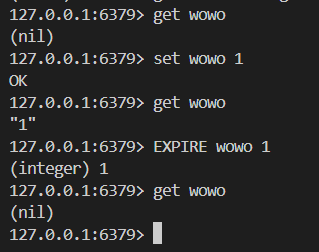
②setex
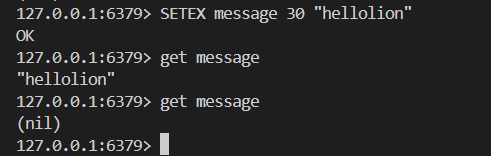
③ex
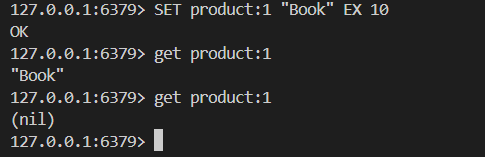
二.協議與異步方式
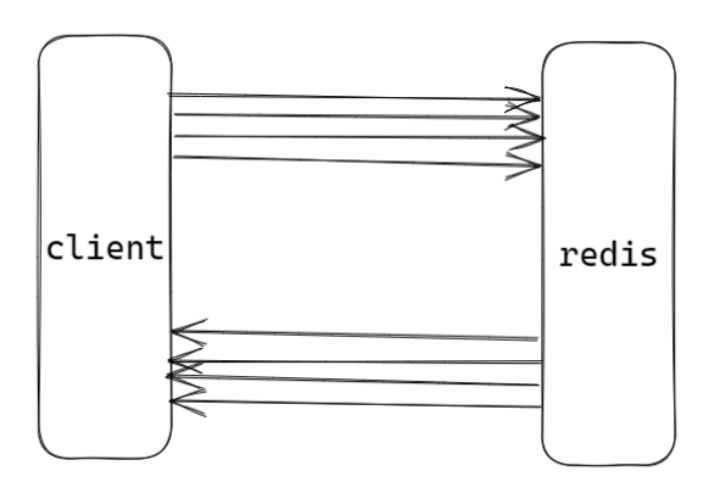
1.redis pipeline
redis pipeline 是一個客戶端提供的機制,而不是服務端提供的;pipeline 不具備事務性;目的:節約網絡傳輸時間;通過一次發送多次請求命令,從而減少網絡傳輸的時間一次性發送多個請求包,redis按序響應與http1.1解決的問題類似
2.發布訂閱模式
2.1基本原理
為了支持消息的多播機制, redis 引入了發布訂閱模塊;消息不一定可達;分布式消息隊列;stream 的方式確保一定可 達;
2.2基礎命令?
# 訂閱頻道
subscribe 頻道
# 訂閱模式頻道
psubscribe 頻道
# 取消訂閱頻道
unsubscribe 頻道
# 取消訂閱模式頻道
punsubscribe 頻道
# 發布具體頻道或模式頻道的內容
publish 頻道 內容
# 客戶端收到具體頻道內容
message 具體頻道 內容
# 客戶端收到模式頻道內容
pmessage 模式頻道 具體頻道 內容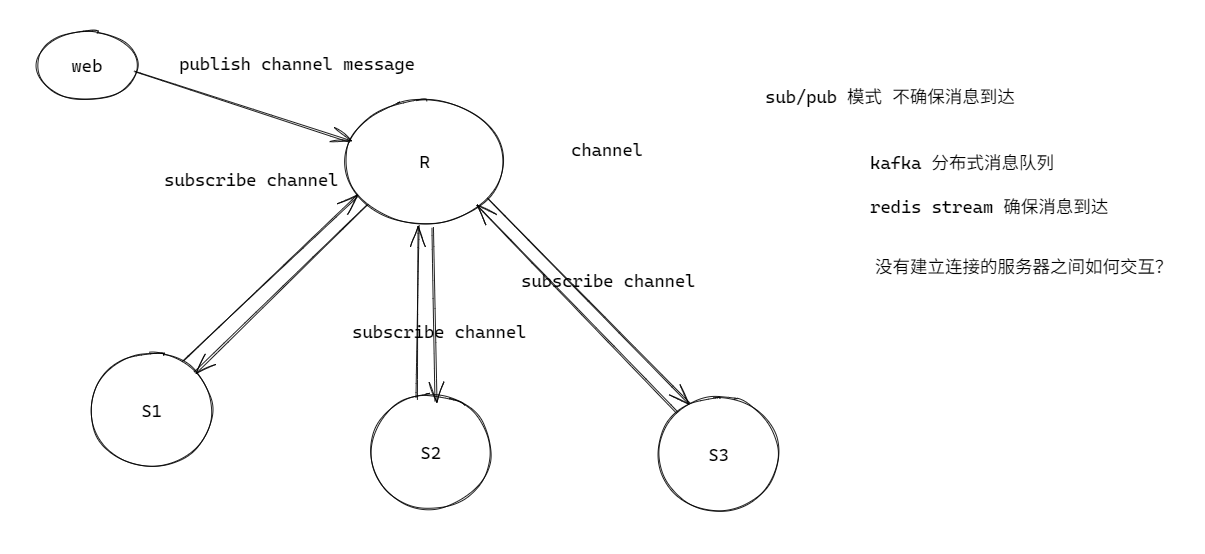
舉栗子?

2.3應用場景
發布訂閱功能一般要區別命令連接重新開啟一個連接;因為命令連接嚴格遵循請求回應模式;而 pubsub 能收到 redis 主動推送的內容;所以實際項目中如果支持 pubsub 的話,需要 另開一條連接 用于處理發布訂閱;
2.4缺點
發布訂閱的生產者傳遞過來一個消息, redis 會直接找到相應的消費者并傳遞過去;假如沒有消費者,消息直接丟棄;假如開始有 2 個消費者,一個消費者突然掛掉了,另外一個消費者依然能收到消息,但是如果剛掛掉的消費者重新連上后,在斷開連接期間的消息對于該消費者來說徹底丟失了;另外, redis 停機重啟, pubsub 的消息是不會持久化的,所有的消息被直接丟棄;
3.redis事務
3.1什么是事務,事務具有什么特性
事務:用戶定義一系列數據庫操作,這些操作視為一個完整的邏輯處理工作單元 ,要么全部執行,要么全部不執行,是不可分割的工作單元。MULTI 開啟事務,事務執行過程中,單個命令是入隊列操作,直到調用 EXEC 才會一起執行;樂觀鎖實現,所以失敗需要重試,增加業務邏輯的復雜度;acid①原子性②一致性③隔離性④持久性
3.2實現事務的基礎命令(不常用)
?
MULTI
開啟事務
begin / start transactionEXEC
提交事務
commitDISCARD
取消事務
rollbackWATCH
檢測 key 的變動,若在事務執行中,key 變動則取消事務;在事
務開啟前調用,樂觀鎖實現(cas);
若被取消則事務返回 nil ;3.3應用場景
事務實現 zpop?
WATCH zset
element = ZRANGE zset 0 0
MULTI
ZREM zset element
EXECWATCH score:10001
val = GET score:10001
MULTI
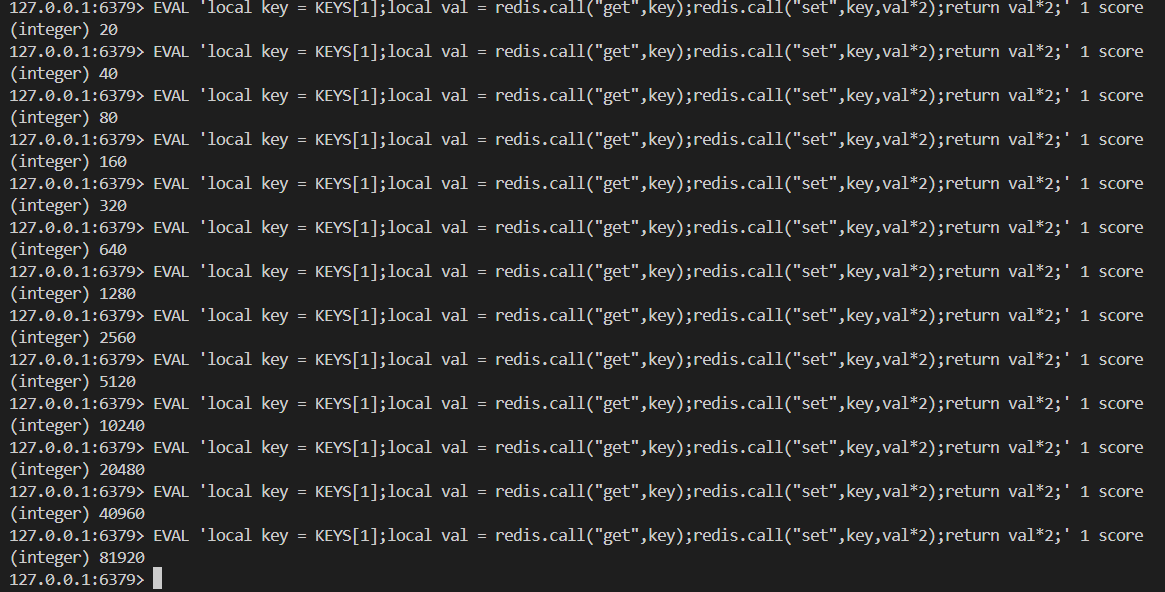
SET score:10001 val*2
EXEC4.lua腳本(常用)
4.1lua腳本怎么實現
lua 腳本實現原子性;redis 中加載了一個 lua 虛擬機;用來執行 redis lua 腳本; redislua 腳本的執行是原子性的;當某個腳本正在執行的時候,不會有其他命令或者腳本被執行;lua 腳本當中的命令會直接修改數據狀態;lua 腳本 mysql 存儲區別: MySQL 存儲過程不具備事務性,所以也不具備原子性;注意 :如果項目中使用了 lua 腳本,不需要使用上面的事務命令;
4.2.lua腳本一些基礎命令?
# 從文件中讀取 lua腳本內容
cat test1.lua | redis-cli script load --pipe
# 加載 lua腳本字符串 生成 sha1
> script load 'local val = KEYS[1]; return val'
"b8059ba43af6ffe8bed3db65bac35d452f8115d8"
# 檢查腳本緩存中,是否有該 sha1 散列值的lua腳本
> script exists
"b8059ba43af6ffe8bed3db65bac35d452f8115d8"
1) (integer) 1
# 清除所有腳本緩存
> script flush
OK
# 如果當前腳本運行時間過長(死循環),可以通過 script kill
殺死當前運行的腳本
> script kill
(error) NOTBUSY No scripts in execution right
now.?EVAL
# 測試使用
EVAL script numkeys key [key ...] arg [arg ...]# 線上使用
EVALSHA sha1 numkeys key [key ...] arg [arg ...]
4.3應用場景
# 1: 項目啟動時,建立redis連接并驗證后,先加載所有項目中使用的lua腳本(script load);# 2: 項目中若需要熱更新,通過redis-cli script flush;然后可以通過訂閱發布功能通知所有服務器重新加載lua腳本;# 3:若項目中lua腳本發生阻塞,可通過script kill暫停當前阻塞腳本的執行;
?5.ACID特性分析
A 原子性;事務是一個不可分割的工作單位,事務中的操作要么全部成功,要么全部失敗; redis 不支持回滾;即使事務隊列中的某個命令在執行期間出現了錯誤,整個事務也會繼續執行下去,直到將事務隊列中的所有命令都執行完畢為止。C 一致性;事務的前后,所有的數據都保持一個一致的狀態,不能違反數據的一致性檢測;這里的一致性是指預期的一致性而不是異常后的一致性;所以 redis 也不滿足;這個爭議很大:redis 能確保事務執行前后的數據的完整約束;但是并不滿足業務功能上的一致性;比如轉賬功能,一個扣錢一個加錢;可能出現扣錢執行錯誤,加錢執行正確,那么最終還是會加錢成功;系統憑空多了錢;I 隔離性;各個事務之間互相影響的程度; redis 是單線程執行,天然具備隔離性;D 持久性; redis 只有在 aof 持久化策略的時候,并且需要在redis.conf 中 appendfsync=always 才具備持久性;實際項目中幾乎不會使用 aof 持久化策略;面試時候回答: lua 腳本滿足原子性和隔離性;一致性和持久性不滿足;
6.redis異步連接?
6.1redis協議圖
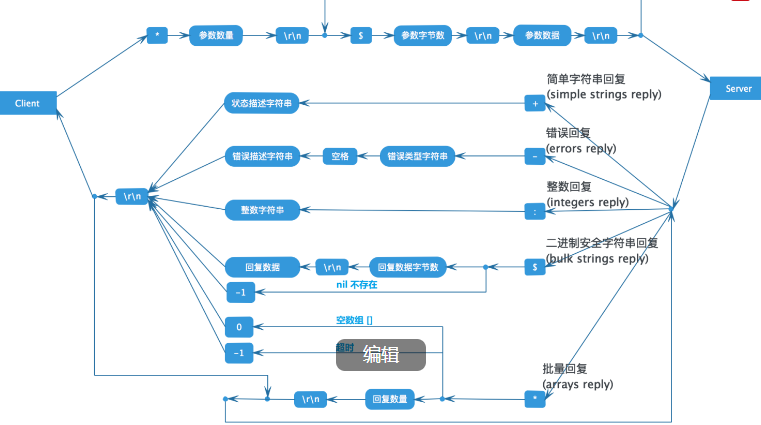
協議實現的第一步需要知道如何界定數據包:1. 長度 + 二進制流2. 二進制流 + 特殊分隔符
6.2異步連接?
同步連接方案采用阻塞 io 來實現;優點是代碼書寫是同步的,業務邏輯沒有割裂;缺點是阻塞當前線程,直至 redis 返回結果;通常用多個線程來實現線程池來解決效率問題;異步連接方案采用非阻塞 io 來實現;優點是沒有阻塞當前線程, redis 沒有返回,依然可以往 redis 發送命令;缺點是代碼書寫是異步的(回調函數),業務邏輯割裂,可以通過協程解決( openresty , skynet );配合 redis6.0 以后的 io 多線程(前提是有大量并發請求),異步連接池,能更好解決應用層的數據訪問性能;
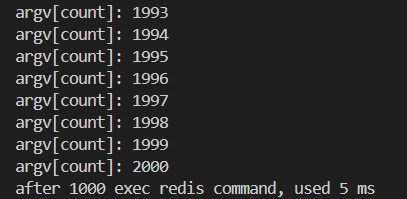
6.3實現方案?


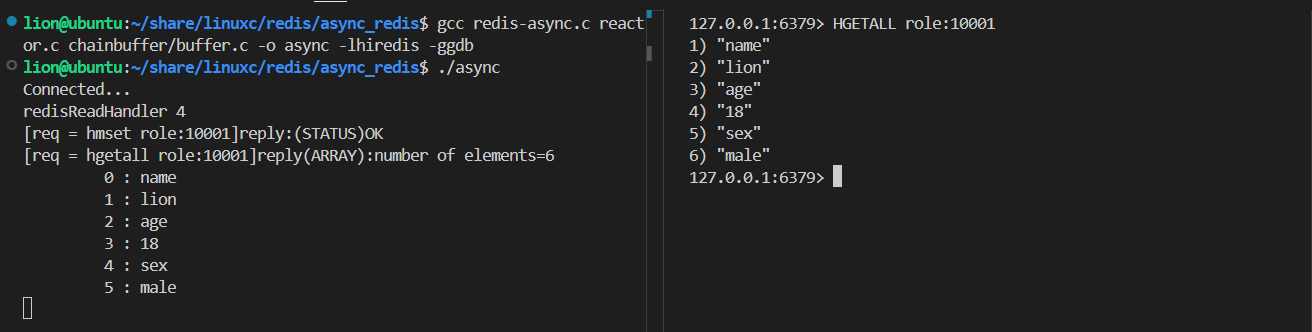
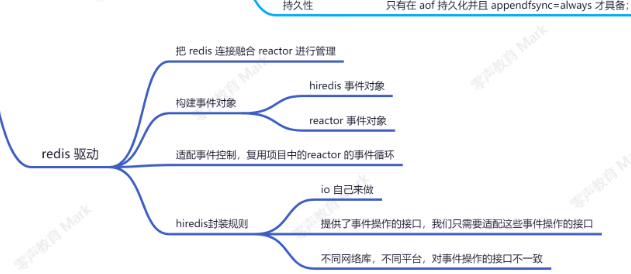
6.4原理是什么
hiredis 提供異步連接方式,提供 可以替換 IO 檢測 的接口;關鍵替換 addRead , delRead , addWrite , delWrite ,cleanup , scheduleTimer ,這幾個檢測接口;其他 io 操作,比如 connect , read , write , close 等都交由 hiredis 來處理;同時需要提供連接建立成功以及斷開連接的回調;用戶可以使用當前項目的網絡框架來替換相應的操作;從而實現跟項目網絡層兼容的異步連接方案;
三.存儲原理與數據模型
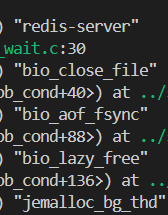
1.redis是單線程還是多線程
![]()
![]()

![]() ? ? ?
? ? ? ?
?
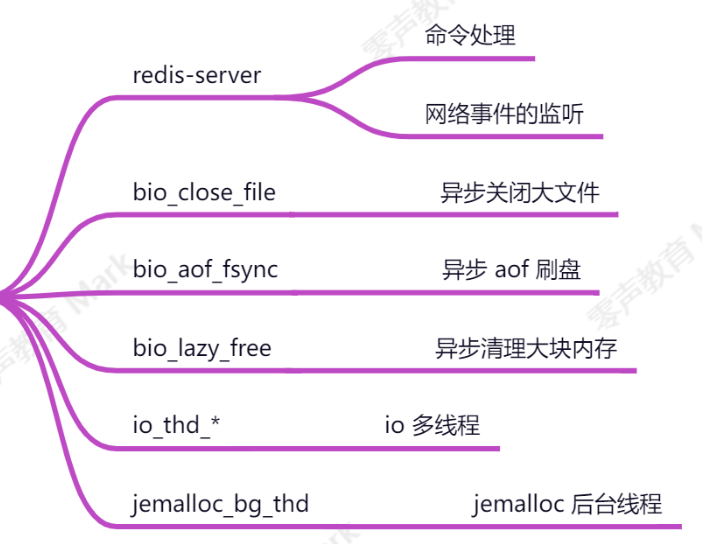
我們通過gdb調試redis 可以查看 起線程明顯有多個
這些線程的作用分別如下圖所示
?2.redis中說的單線程究竟是什么?
命令處理是在一個單線程中
處理客戶端請求的核心流程是單線程的 。
即從接收客戶端請求(網絡讀取 )、解析命令、執行命令到返回結果(網絡寫入 ),都由一個主線程順序串行處理 。
所有命令在這個過程中逐個執行,不會有兩條命令被同時執行,確保了操作的原子性,也避免了線程安全問題和不必要的上下文切換。
比如執行
SET key value?、GET key?等各種數據操作命令時,都是在這個單線程流程中完成 。
?3.命令處理為什么是單線程
3.1單線程的局限性(redis要避免)
不能有耗時的操作:cpu運算和阻塞的io
對于redis而言會影響性能
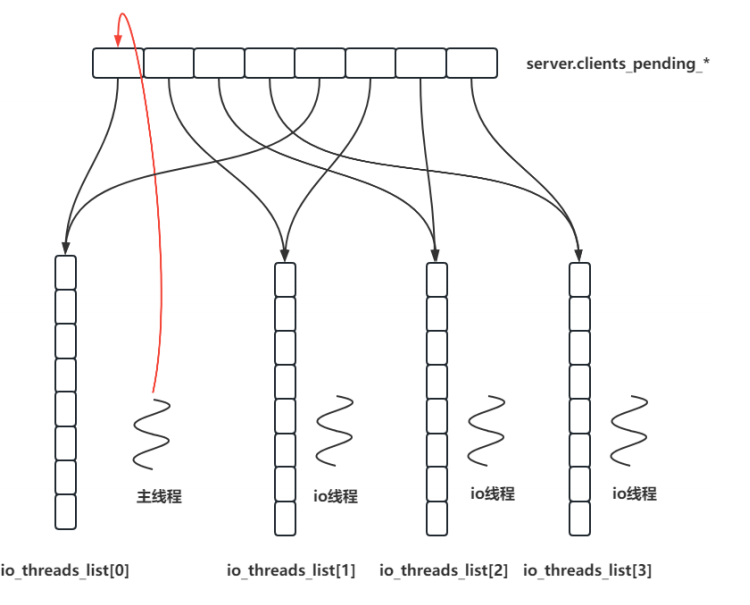
3.2redis有沒有io密集型和cpu密集型(有的)
IO密集型分為磁盤IO和網絡IO
redis在磁盤IO中可以fork子進程,在子進程中做持久化,還可以異步刷盤
redis在網絡IO中服務多個客戶,造成IO密集,數據請求和返回量比較大,redis會開啟IO多線程處理這個問題
4.命令處理為什么不采用多線程
加鎖復雜,鎖的粒度不好控制
頻繁的cpu上下文切換,抵消多線程的優勢
5.單線程是怎么做到這么快的呢?
5.1采用了哪些機制
內存型數據庫
數據的組織方式O(1):hashtable 可以擴容,縮容,還能漸進式rehash在cpu運算中,每步操作rehash,定時rehash 1ms 之類的.
數據高效:在執行效率與空間占用保持平衡,數據結構切換
高效的reactor網絡模型
5.2做了哪些優化?
分治思想
把rehash分攤到每一個操作步驟當中
在定時器當中,以100為步長最大rehash 1ms
耗時阻塞的操作,在其他線程處理
對象類型采用不同的數據結構實現
?6.負載因子,擴縮容機制,漸進式rehash
負載因子 = used / size ; used 是數組存儲元素的個數,size 是數組的長度;負載因子越小,沖突越小;負載因子越大,沖突越大;redis 的負載因子是 1 ;
擴容?
如果負載因子 > 1 ,則會發生擴容;擴容的規則是翻倍;如果正在 fork (在 rdb 、 aof 復寫以及 rdb-aof 混用情況下)時,會阻止擴容;但是此時若負載因子 > 5 ,索引效率大大降低, 則馬上擴容;這里涉及到寫時復制原理;
縮容
如果負載因子 < 0.1 ,則會發生縮容;縮容的規則是 恰好 包含used 的 ;恰好 的理解:假如此時數組存儲元素個數為 9 ,恰好包含該元素的就是 ,也就是 16 ;
?
?漸進式rehash
當 hashtable 中的元素過多的時候,不能一次性 rehash 到ht[1] ;這樣會長期占用 redis ,其他命令得不到響應;所以需要使用漸進式 rehash ;rehash 步驟 :將 ht[0] 中的元素重新經過 hash 函數生成 64 位整數,再對ht[1] 長度進行取余,從而映射到 ht[1] ;漸進式規則 :1. 分治的思想,將 rehash 分到之后的每步增刪改查的操作當中;2. 在定時器中,最大執行一毫秒 rehash ;每次步長 100 個數組槽位;面試 :處于漸進式 rehash 階段時,是否會發生擴容縮容?不會!
7.scan
scan cursor [MATCH pattern] [COUNT count] [TYPE
type]
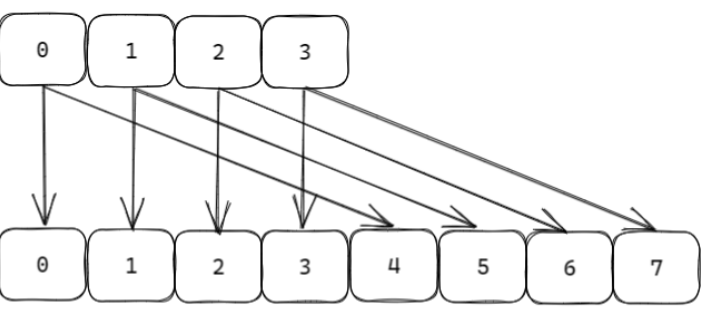
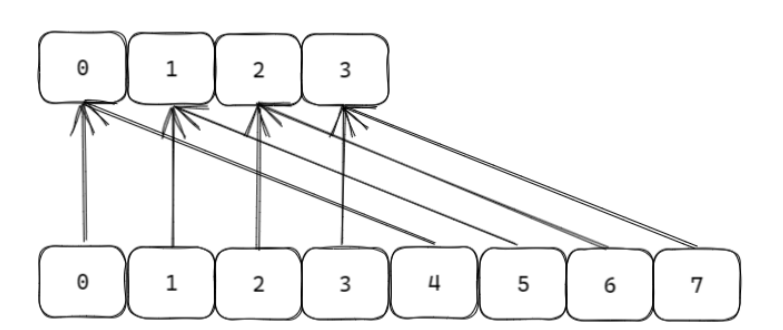
采用高位進位加法的遍歷順序, rehash 后的槽位在遍歷順序上是相鄰的;遍歷目標是:不重復,不遺漏 ;會出現一種重復的情況:在 scan 過程當中,發生兩次縮容的時候,會發生數據重復;注意 :上課時有一個問題表述錯誤;關于 scan , scan 要達到的目的是從 scan 開始那刻起 redis 已經存在的數據進行遍歷,不會重復和遺漏(例外是 scan 過程中兩次縮容可能造成數據重復), 因為比如我 scan 已經快結束了,現在插入大量數據,這些數據肯定遍歷不到;擴容和縮容造成映射算法發生改變,但是使用高位進位累加的算法,可以對 scan 那刻起已經存在數據的遍歷不會出錯;
舉栗子?
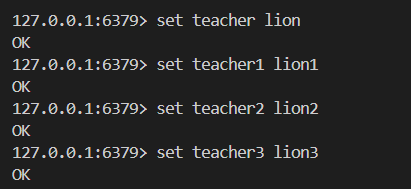
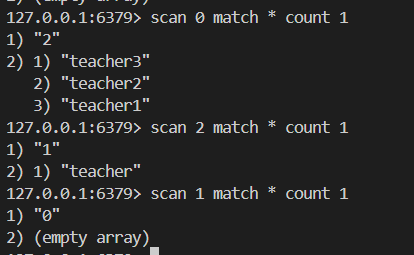
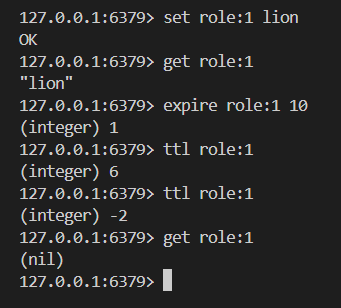
8.expire
# 只支持對最外層key過期;
expire key seconds
pexpire key milliseconds
ttl key
pttl key分布在每一個命令操作時檢查 key 是否過期;若過期刪除 key ,再進行命令操作;
定時刪除
在定時器中檢查庫中指定個數(25)個 key;?
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /*
Keys for each DB loop. */
/*The default effort is 1, and the maximum
configurable effort* is 10. */
config_keys_per_loop =
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
int activeExpireCycleTryExpire(redisDb *db,
dictEntry *de, long long now);?舉栗子
9.大Key
在 redis 實例中形成了很大的對象,比如一個很大的 hash 或很大的 zset ,這樣的對象在擴容的時候,會一次性申請更大的一塊內存,這會導致卡頓;如果這個大 key 被刪除,內存會一次性回收,卡頓現象會再次產生;如果觀察到 redis 的內存大起大落,極有可能因為大 key 導致的;
# 每隔0.1秒 執行100條scan命令
redis-cli -h 127.0.0.1 --bigkeys -i 0.110.對象編碼(補充)

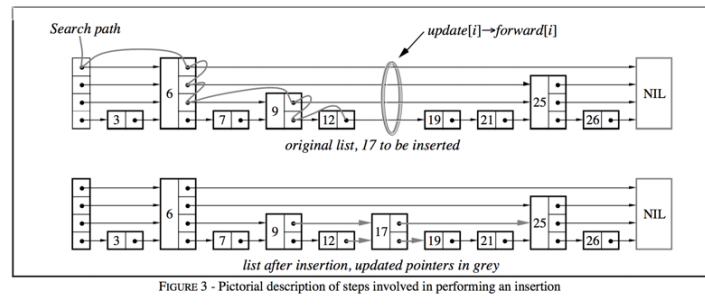
?11.skiplist(用在zset中)
從節約內存出發, redis 考慮犧牲一點時間復雜度讓跳表結構更加變扁平,就像二叉堆改成四叉堆結構;并且 redis 還限制了跳表的最高層級為 32 ;節點數量大于 128 或者有一個字符串長度大于 64 ,則使用跳表( skiplist );
 ?數據結構
?數據結構
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough
for 2^64 elements */
#define ZSKIPLIST_P 0.25 ? ? ?/* Skiplist P = 1/4
*/
/* ZSETs use a specialized version of Skiplists
*/
typedef struct zskiplistNode {sds ele;double score; // WRN: score 只能是浮點數struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span; // 用于 zrank} level[];
} zskiplistNode;
typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length; // zcardint level; // 最高層
} zskiplist;
typedef struct zset {dict *dict; // 幫助快速索引到節點zskiplist *zsl;
} zset;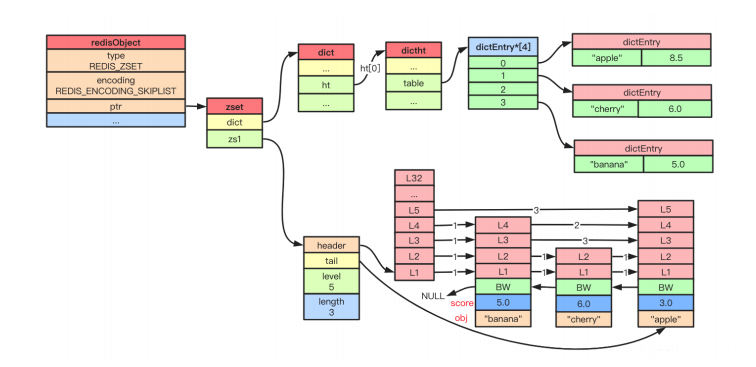











(藍橋杯常考點)—動態規劃(C/C++))


)
)



處理圖像顏色)