? 概述:在計算機科學領域,哈希表是一種非常重要的數據結構,它通過哈希函數將鍵映射到存儲桶中,從而實現快速的數據查找、插入和刪除操作。然而,哈希表在實際應用中會面臨 哈希沖突的問題。本文將深入探討哈希沖突的原理、常見的解決方案,并結合 Java 代碼進行實踐演示。
一.什么是哈希沖突
? 哈希函數是哈希表的核心,它將任意長度的輸入轉換為固定長度的輸出,這個輸出通常被稱為哈希值。理想情況下,不同的輸入應該產生不同的哈希值,但由于哈希值的范圍是有限的,而輸入的可能性是無限的,因此必然會出現兩個或多個不同的輸入產生相同哈希值的情況,這就是哈希沖突。
?
二.希沖突的原因
2.1哈希函數設計不合理
? 如果哈希函數不能均勻地將輸入分布到哈希表的各個存儲桶中,就會導致某些存儲桶中的元素過多,從而增加哈希沖突的概率。
2.2哈希表的容量有限
? 當哈希表的容量相對較小時,哈希沖突的概率會顯著增加。因為在有限的存儲空間內,更多的元素會被映射到相同的位置。
三.常見的哈希沖突解決方案
3.1開放地址法
? 開放尋址法通過探測數組中的其他位置來解決沖突。。當發生哈希沖突時,它會嘗試在哈希表中尋找下一個可用的位置。常見的開放尋址法有線性探測、二次探測和雙重哈希。
? 線性探測:是指當發生哈希沖突時,依次檢查下一個存儲桶,直到找到一個空的存儲桶為止。
import java.util.Arrays;class LinearProbingHashTable {private int[] table;private int size;public LinearProbingHashTable(int capacity) {table = new int[capacity];Arrays.fill(table, -1);size = 0;}private int hash(int key) {return key % table.length;}public void insert(int key) {int index = hash(key);while (table[index] != -1) {index = (index + 1) % table.length;}table[index] = key;size++;}public boolean search(int key) {int index = hash(key);int startIndex = index;while (table[index] != -1) {if (table[index] == key) {return true;}index = (index + 1) % table.length;if (index == startIndex) {break;}}return false;}
}
? 二次探測:是指當發生哈希沖突時,依次檢查 (hash(key) + i^2) % table.length 位置,其中 i 是探測次數。
import java.util.Arrays;class QuadraticProbingHashTable {private int[] table;private int size;public QuadraticProbingHashTable(int capacity) {table = new int[capacity];Arrays.fill(table, -1);size = 0;}private int hash(int key) {return key % table.length;}public void insert(int key) {int index = hash(key);int i = 1;while (table[index] != -1) {index = (index + i * i) % table.length;i++;}table[index] = key;size++;}public boolean search(int key) {int index = hash(key);int startIndex = index;int i = 1;while (table[index] != -1) {if (table[index] == key) {return true;}index = (index + i * i) % table.length;i++;if (index == startIndex) {break;}}return false;}
}3.2 鏈地址法
? 鏈地址法是一種更為常用的解決哈希沖突的方法。在鏈地址法中,每個存儲桶都是一個鏈表,當發生哈希沖突時,新的元素會被插入到對應的鏈表中。
import java.util.LinkedList;class ChainingHashTable {private LinkedList<Integer>[] table;private int size;public ChainingHashTable(int capacity) {table = new LinkedList[capacity];for (int i = 0; i < capacity; i++) {table[i] = new LinkedList<>();}size = 0;}private int hash(int key) {return key % table.length;}public void insert(int key) {int index = hash(key);table[index].add(key);size++;}public boolean search(int key) {int index = hash(key);return table[index].contains(key);}
}?
import java.util.HashMap;
import java.util.Map;public class JavaHashMapExample {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();map.put(1, "One");map.put(11, "Eleven"); // 可能會發生哈希沖突System.out.println(map.get(1));System.out.println(map.get(11));}
}?四.Java 中的哈希沖突處理?
? Java 的 HashMap 采用鏈地址法解決沖突,每個哈希桶對應一個鏈表或紅黑樹。當沖突發生時,新元素會被添加到鏈表的末尾。JDK 1.8 引入紅黑樹優化,當鏈表長度超過 8 時,會將鏈表轉換為紅黑樹,查找時間復雜度從 O (n) 降至 O (log n)。
// HashMap 中鏈表轉紅黑樹的關鍵代碼
final void treeifyBin(Node<K,V>() tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)hd.treeify(tab);}
}五.負載因子
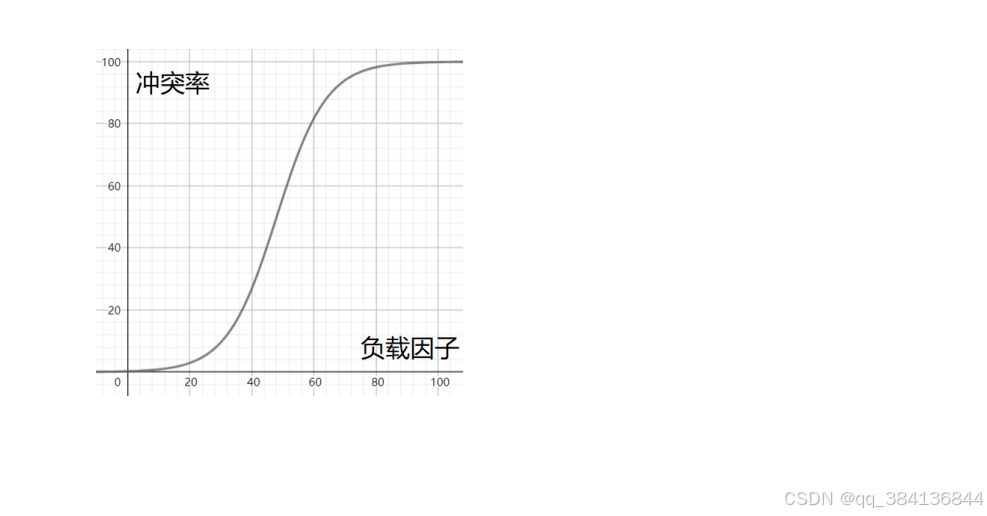
? 在哈希沖突的解決機制中,負載因子是一個核心參數,它決定了哈希表的擴容時機,直接影響哈希表的性能與空間利用率。
5.1負載因子的定義與計算
? 負載因子是哈希表中已存儲元素數量(size)與哈希表當前容量(capacity)的比值,計算公式為:負載因子=?元素數量 / 哈希表容量
?
例如,當哈希表容量為16,存儲了12個元素時,負載因子為?12/16=0.75
5.2負載因子的核心作用
擴容閾值
? 當元素數量超過 容量 × 負載因子 時,哈希表會觸發擴容(Resize)。例如,Java 的HashMap默認負載因子為 0.75,當元素數量達到容量的 75%(如容量 16 時元素數超過 12),會將容量翻倍至 32,并重新計算所有元素的哈希值以減少沖突。
平衡空間與時間效率
? 高負載因子(如 1.0):空間利用率高,但哈希沖突概率大幅增加。例如,若負載因子為 1.0,哈希表填滿時所有沖突只能通過鏈表或紅黑樹解決,導致查詢時間復雜度從 O (1) 退化為 O (n)。
低負載因子(如 0.5):沖突概率低,查詢效率高,但空間浪費嚴重。例如,容量 16 時僅存儲 8 個元素就會觸發擴容,導致頻繁的內存分配與數據遷移。
沖突管理
? 負載因子通過控制哈希表的填充密度,間接影響沖突解決的效率。例如:鏈地址法(如HashMap):負載因子過高會導致鏈表過長,JDK 8 后引入紅黑樹優化,但樹化本身也有開銷。開放尋址法(如線性探測):負載因子過高會增加探測次數,甚至導致 “聚簇” 現象,進一步降低性能。
典型實現與默認值
| 數據結構 | 默認負載因子 | 設計考量 |
|---|---|---|
Java?HashMap | 0.75 | 經過大量實驗驗證,0.75 在空間利用率與沖突概率之間取得最優平衡。例如,當容量為 2 的冪次方時,0.75 能確保擴容閾值為整數(如 16×0.75=12),避免計算誤差268 |
Java?ConcurrentHashMap | 0.75 | 與HashMap類似,但采用分段鎖機制,支持更高并發。負載因子過高可能導致鎖競爭加劇45。 |
| Redis 哈希表 | 動態調整 | 默認負載因子≥1,若正在進行持久化(如 BGSAVE),則需負載因子≥5 才擴容。這種動態策略避免了內存劇烈波動對持久化性能的影響6。 |
?5.3為何選擇 0.75?
5.3.1統計學依據
? 二項式哈希函數的理論分析表明,當負載因子接近?ln2≈0.693時,哈希沖突概率較低。0.75 是實際工程中對該理論值的近似,既能保證較高的空間利用率,又能有效控制沖突。
5.3.2工程實踐驗證
? 0.75 在大量實際場景中被證明是最優選擇。例如,若負載因子設為 0.5,哈希表的空間利用率將降低 50%,而查詢效率提升有限;若設為 1.0,沖突概率可能增加數倍,導致性能大幅下降。
5.4.調整負載因子的場景與方法
? 內存敏感場景:若設備內存有限,可適當提高負載因子(如 0.9)以減少擴容次數,但需評估沖突對性能的影響。
? 高并發場景:ConcurrentHashMap的負載因子過高可能導致鎖競爭,可適當降低(如 0.6)以減少鎖爭用。
? 數據分布不均:若哈希函數質量差,即使負載因子較低也可能引發大量沖突,此時需優化哈希函數而非調整負載因子。
? Java?HashMap:通過構造函數指定負載因子,例如
new HashMap<>(initialCapacity, loadFactor);? 總結:負載因子是哈希表性能優化的核心參數,其本質是空間與時間的權衡。默認值 0.75 是經過理論驗證與工程實踐的最優選擇,但在特定場景下可通過調整負載因子或優化哈希函數進一步提升性能。理解負載因子與擴容、沖突解決的關系,有助于在實際開發中合理設計哈希表,避免性能瓶頸。
六.性能優化與實踐建議
6.1負載因子的選擇
HashMap 默認的負載因子為 0.75,這是在空間利用率和沖突概率之間的平衡。如果內存充足,可以適當降低負載因子以減少沖突;如果對內存敏感,可以提高負載因子但需注意性能下降的風險。
?6.2擴容策略的影響
擴容會導致元素重新哈希和遷移,這是一個耗時操作。在已知數據量的情況下,可以通過預設置初始容量來減少擴容次數:
Map<String, Integer> map = new HashMap<>(1000); // 初始容量設為 1000
?
總結
? 哈希沖突是哈希表在實際應用中不可避免的問題,但通過合理的哈希函數設計和有效的沖突解決方法,可以將哈希沖突的影響降到最低。開放尋址法和鏈地址法是兩種常見的解決哈希沖突的方法,它們各有優缺點,在實際應用中需要根據具體情況選擇合適的方法。Java 中的?HashMap?提供了一種高效的哈希表實現,它通過鏈地址法和紅黑樹的結合,有效地處理了哈希沖突。
?
處理圖像顏色)















:TCP Socket 編程)

)
