語音識別part2——LAS

Listen
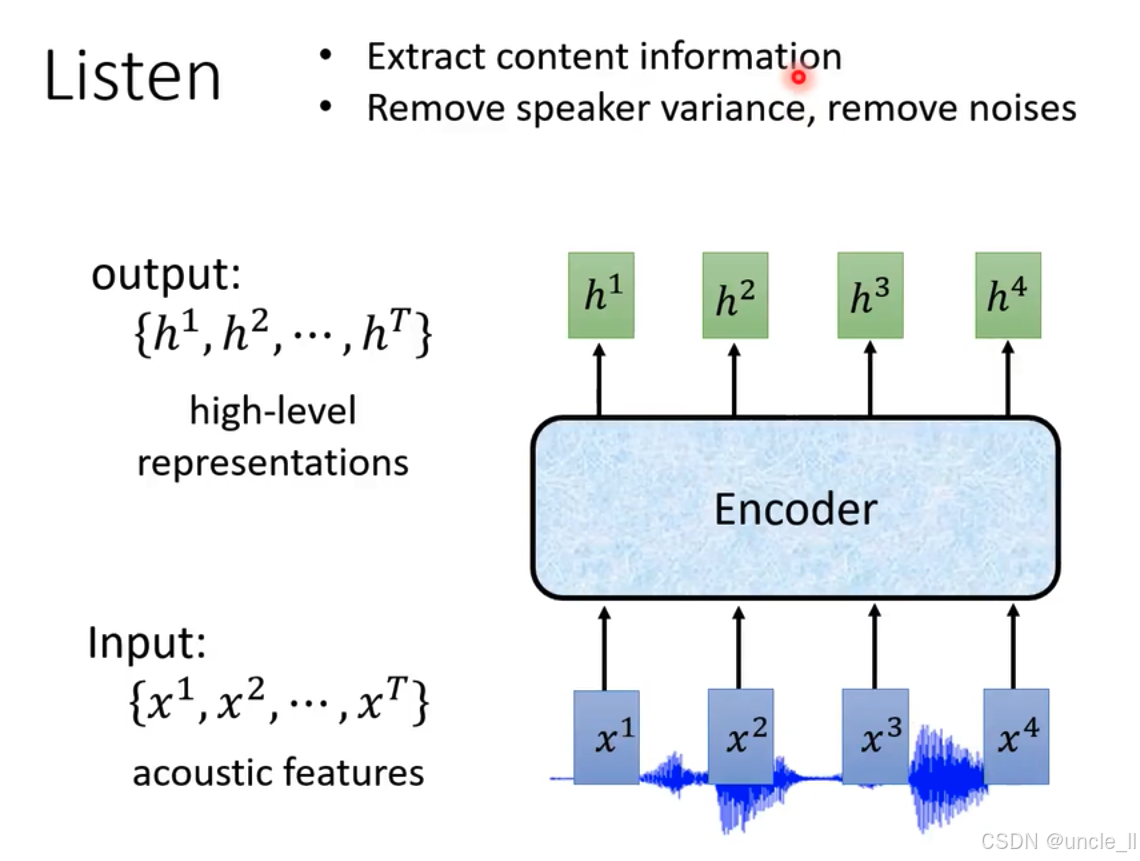
Listen主要功能是提取內容信息,去除說話人差異和噪聲 。編碼器(Encoder)結構,輸入是聲學特征,經過 Encoder 處理后,輸出為高級表示,這些高級表示可用于后續語音識別等任務 。
encoder有多種實現方式:
- RNN
- 1D CNN
- self-attention
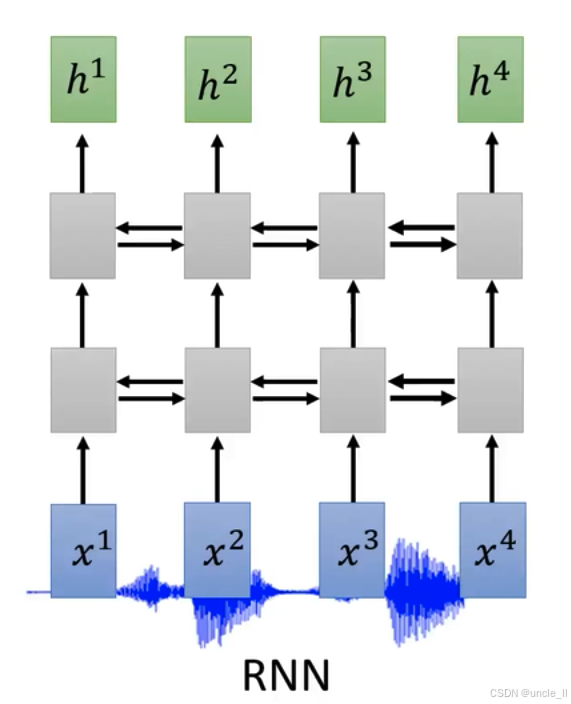
神經網絡在語音處理等序列數據任務中應用的要點:
高層濾波器特性
“Filters in higher layer can consider longer sequence” ,意思是在卷積神經網絡(CNN)中,高層的濾波器能夠考慮更長的序列信息。隨著網絡層數加深,濾波器感受野增大,可捕捉更廣泛的上下文信息 。比如在語音識別中,能整合更長語音片段的特征,提升對復雜語音模式的理解 。
網絡組合方式
“CNN+RNN is common” ,指出將卷積神經網絡(CNN)和循環神經網絡(RNN)結合使用是常見做法。CNN擅長提取局部特征,RNN擅長處理序列的時序信息,二者結合能兼顧語音數據的局部模式提取和整體時序關聯建模 ,在語音識別、自然語言處理等領域廣泛應用 。
現在更流行的趨勢是使用self-attention

自注意力機制能讓模型在處理序列數據時,根據不同位置元素間的關聯程度分配注意力權重,捕捉長距離依賴關系 。比如在語音識別中,可有效關注語音前后文信息,理解語義 。

為了降低輸入的向量,語音處理中回加入下采樣(Down Sampling),下采樣方法包含:
Pyramid RNN(金字塔循環神經網絡 )
- 來源:由Chan等人在ICASSP’16(國際聲學、語音和信號處理會議,2016年 )提出。
- 結構特點:輸入為聲學特征 x 1 x^1 x1、 x 2 x^2 x2、 x 3 x^3 x3、 x 4 x^4 x4 ,通過多層循環神經網絡處理,下層的輸出作為上層的輸入,呈金字塔式結構。隨著層數增加,時間維度上的信息被逐步聚合,最終輸出 h 1 h^1 h1、 h 2 h^2 h2 ,實現對語音特征的下采樣 。
Pooling over time(時間池化 )
- 來源:由Bahdanau等人在ICASSP’16提出。
- 結構特點:同樣以 x 1 x^1 x1、 x 2 x^2 x2、 x 3 x^3 x3、 x 4 x^4 x4作為聲學特征輸入,通過時間維度上的池化操作(如最大池化、平均池化等 ),對輸入特征進行降采樣處理,減少時間維度上的信息冗余,輸出 h 1 h^1 h1、 h 2 h^2 h2 。 圖中展示的兩種方法都是為了在語音處理中有效減少數據量,同時保留關鍵特征信息 。
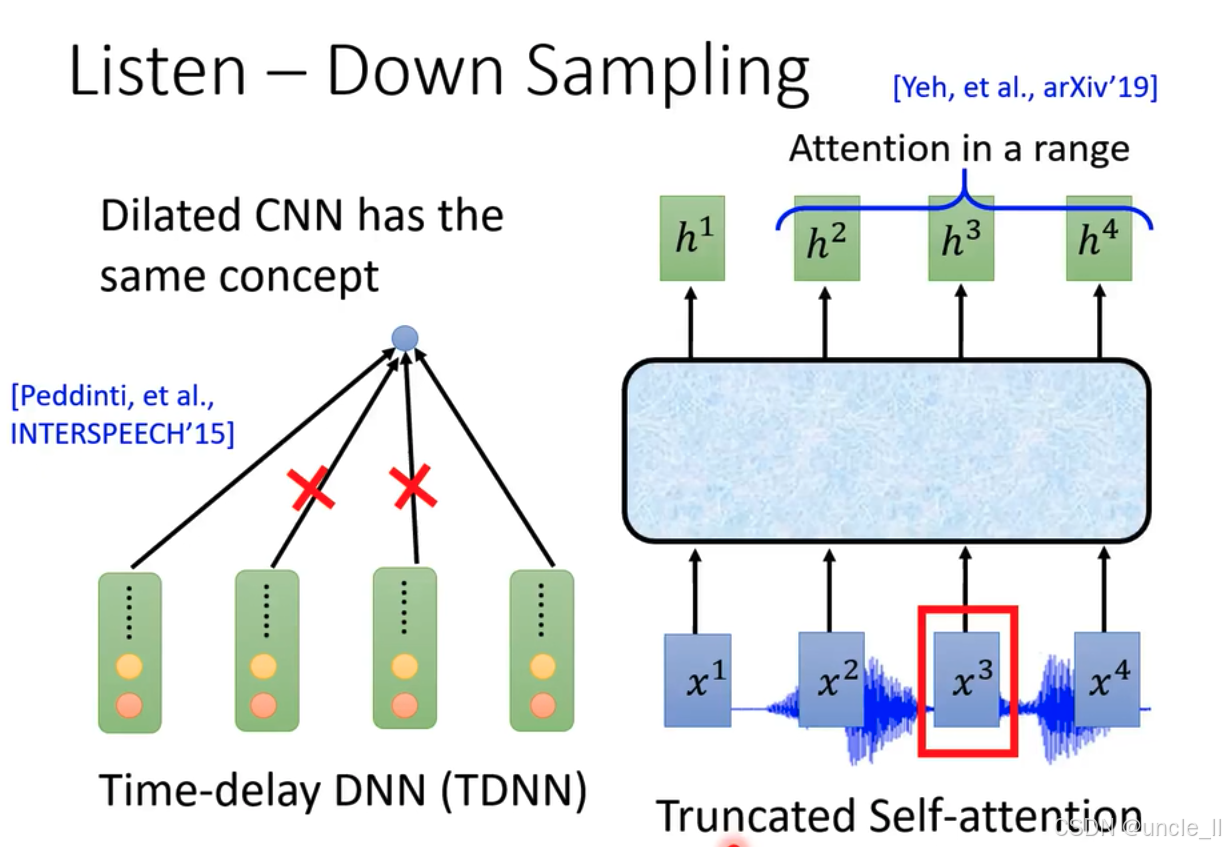
Time - delay DNN (TDNN,時延深度神經網絡 )
- 來源:由Peddinti等人在INTERSPEECH’15(國際語音通信協會年會,2015年 )提出。
- 結構特點:圖中顯示多個綠色模塊(代表網絡層 )通過黑色箭頭連接到一個中心點。TDNN通過在時間維度上設置延遲,能夠捕捉語音信號在不同時間步的局部上下文信息,有效處理語音的時序特征,實現對語音特征的下采樣 。擴張卷積神經網絡(Dilated CNN)與之概念相同,都通過特殊方式擴大感受野來處理序列數據 。
Truncated Self - attention(截斷自注意力 )
- 來源:出自Yeh等人在arXiv’19上的研究。
- 結構特點:輸入為聲學特征 x 1 x^1 x1、 x 2 x^2 x2、 x 3 x^3 x3、 x 4 x^4 x4 ,經過一個淺藍色模塊(代表截斷自注意力層 )處理,輸出為 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。截斷自注意力機制在自注意力基礎上,限制注意力計算范圍,減少計算量,同時能捕捉語音序列中的重要關聯信息,達到下采樣目的 。
Attention
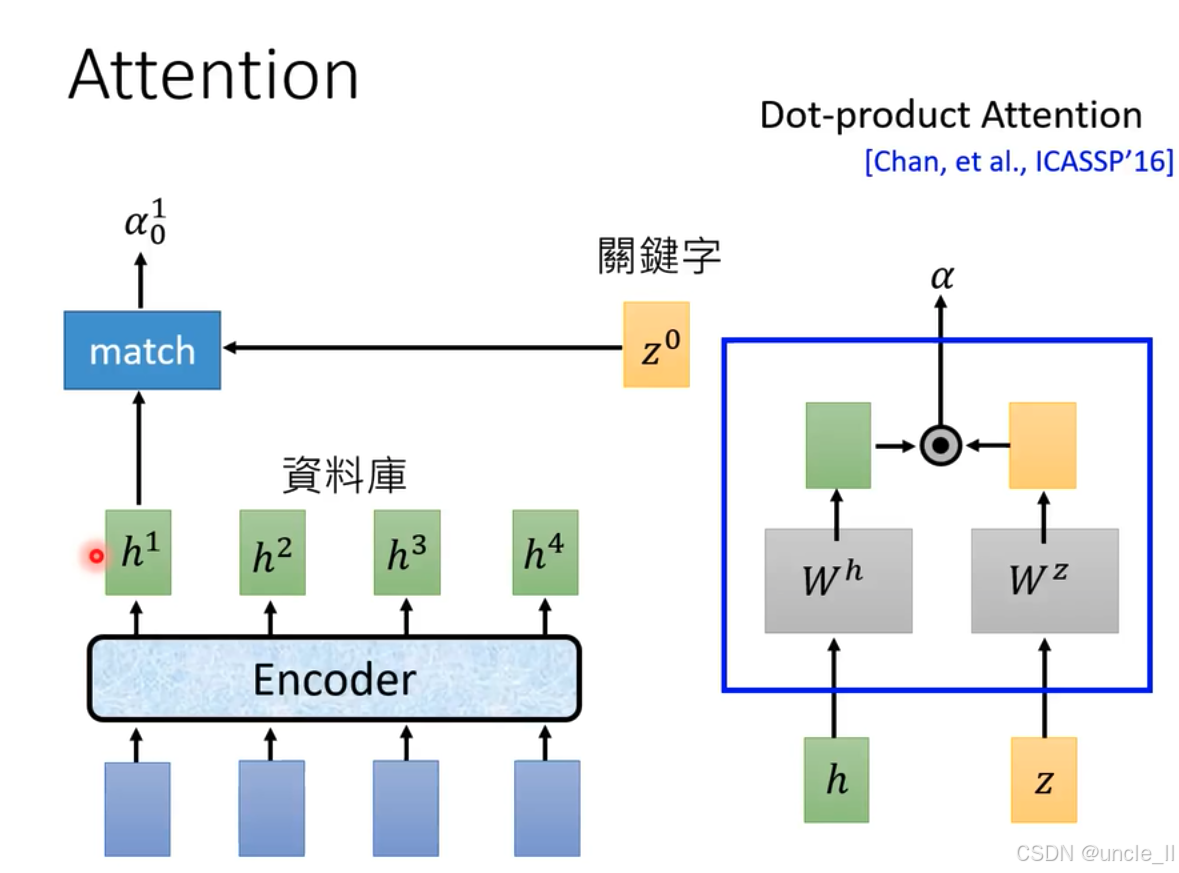
注意力機制(Attention)中的點積注意力(Dot - product Attention) :
- 點積注意力計算:詳細展示點積注意力計算過程。輸入為特征 h h h和 z z z ,分別經過權重矩陣 W h W^h Wh和 W z W^z Wz線性變換后,進行點積操作(圖中圓圈表示 ),得到注意力權重 α \alpha α 。該計算方式出自Chan等人在ICASSP’16(國際聲學、語音和信號處理會議,2016年 )的研究 。
- 作用:點積注意力通過這種計算方式,衡量不同特征間關聯程度,為后續任務分配注意力權重,在語音識別、自然語言處理等領域用于聚焦關鍵信息 。
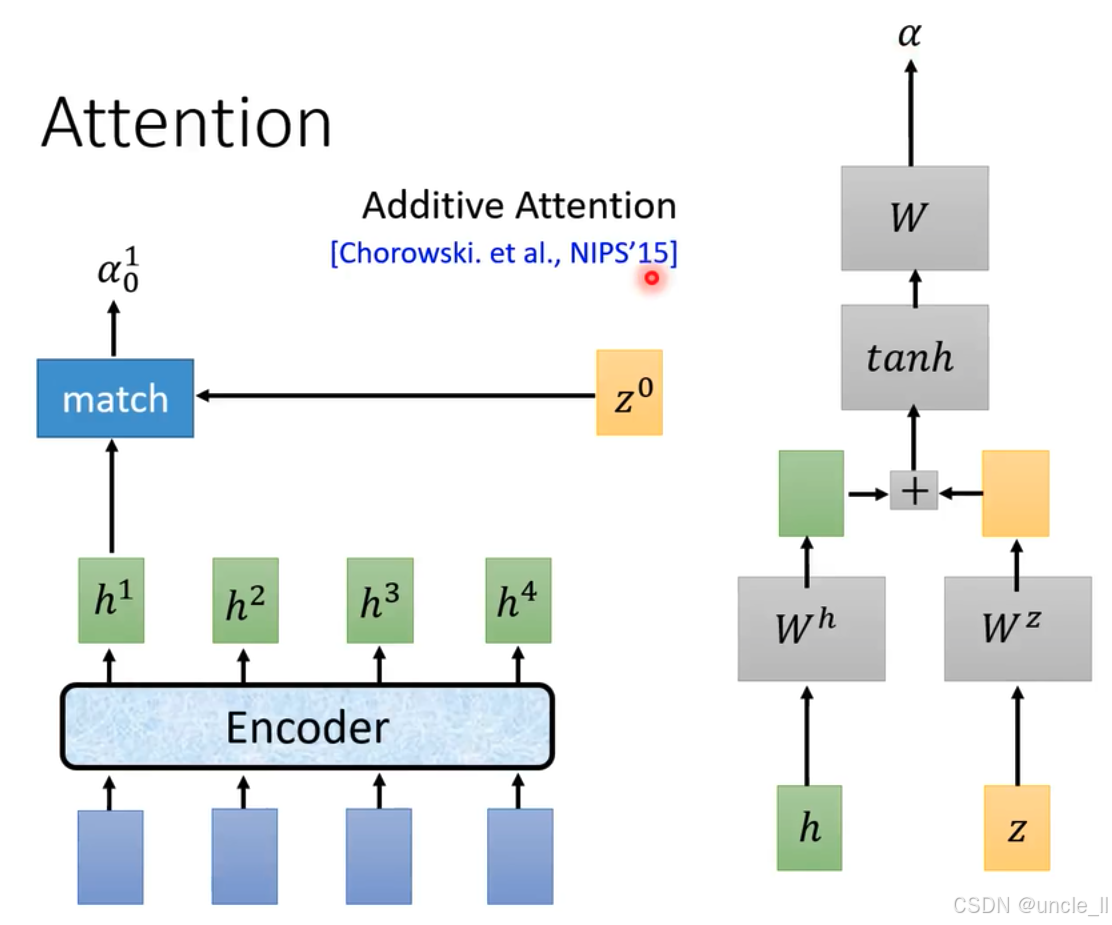
注意力機制(Attention)中的加法注意力(Additive Attention) :
- 加法注意力計算:詳細展示加法注意力計算過程。輸入為特征 h h h和 z z z ,分別經過權重矩陣 W h W^h Wh和 W z W^z Wz線性變換后,將變換結果相加,再經過 t a n h tanh tanh激活函數處理,最后通過權重矩陣 W W W得到注意力權重 α \alpha α 。該計算方式出自Chorowski等人在NIPS’15(神經信息處理系統大會,2015年 )的研究 。
Spell
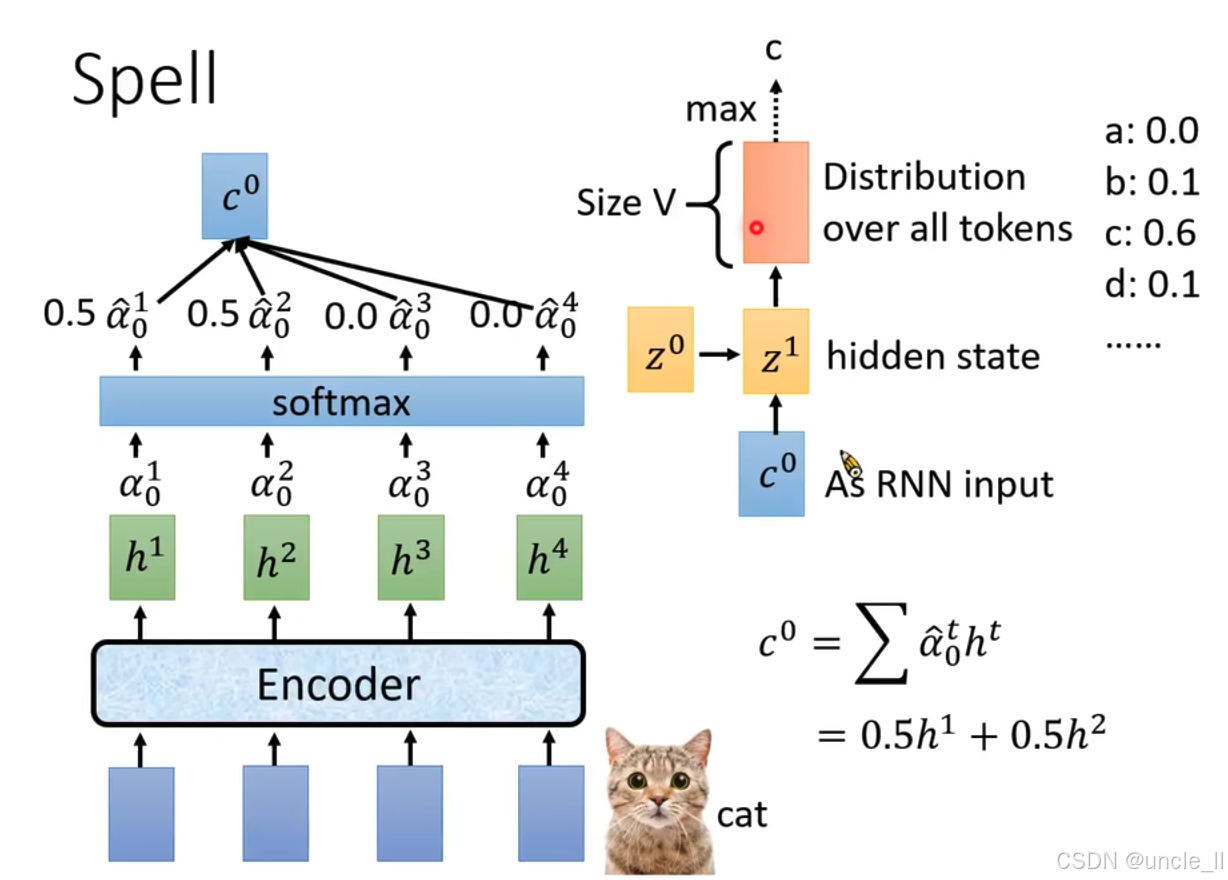 展示了語音識別中“Spell”(解碼 )環節的過程:
展示了語音識別中“Spell”(解碼 )環節的過程:
- 輸入與特征提取:底部藍色模塊是輸入,經“Encoder”(編碼器 )處理后得到特征表示 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。
- 注意力權重計算:這些特征經過注意力機制計算,得到注意力權重 α 0 1 \alpha_0^1 α01?、 α 0 2 \alpha_0^2 α02?、 α 0 3 \alpha_0^3 α03?、 α 0 4 \alpha_0^4 α04? ,再通過“softmax”函數處理,得到歸一化后的權重 α ^ 0 1 \hat{\alpha}_0^1 α^01?、 α ^ 0 2 \hat{\alpha}_0^2 α^02?、 α ^ 0 3 \hat{\alpha}_0^3 α^03?、 α ^ 0 4 \hat{\alpha}_0^4 α^04? ,圖中示例為0.5、0.5、0.0、0.0 。
- 上下文向量計算:根據歸一化權重計算上下文向量 c 0 c^0 c0 ,公式為 c 0 = ∑ α ^ 0 t h t c^0 = \sum \hat{\alpha}_0^t h^t c0=∑α^0t?ht ,示例中 c 0 = 0.5 h 1 + 0.5 h 2 c^0 = 0.5h^1 + 0.5h^2 c0=0.5h1+0.5h2 。
- 循環神經網絡輸入與處理: c 0 c^0 c0作為循環神經網絡(RNN)的輸入,與隱藏狀態 z 0 z^0 z0結合,得到新的隱藏狀態 z 1 z^1 z1 。
- 輸出與預測:基于新的隱藏狀態 z 1 z^1 z1 ,生成所有標記(tokens)上的概率分布,圖中“Size V”表示分布的維度(詞匯表大小 ),示例給出了標記a、b、c、d等的概率值,用于預測最終的語音識別結果 。
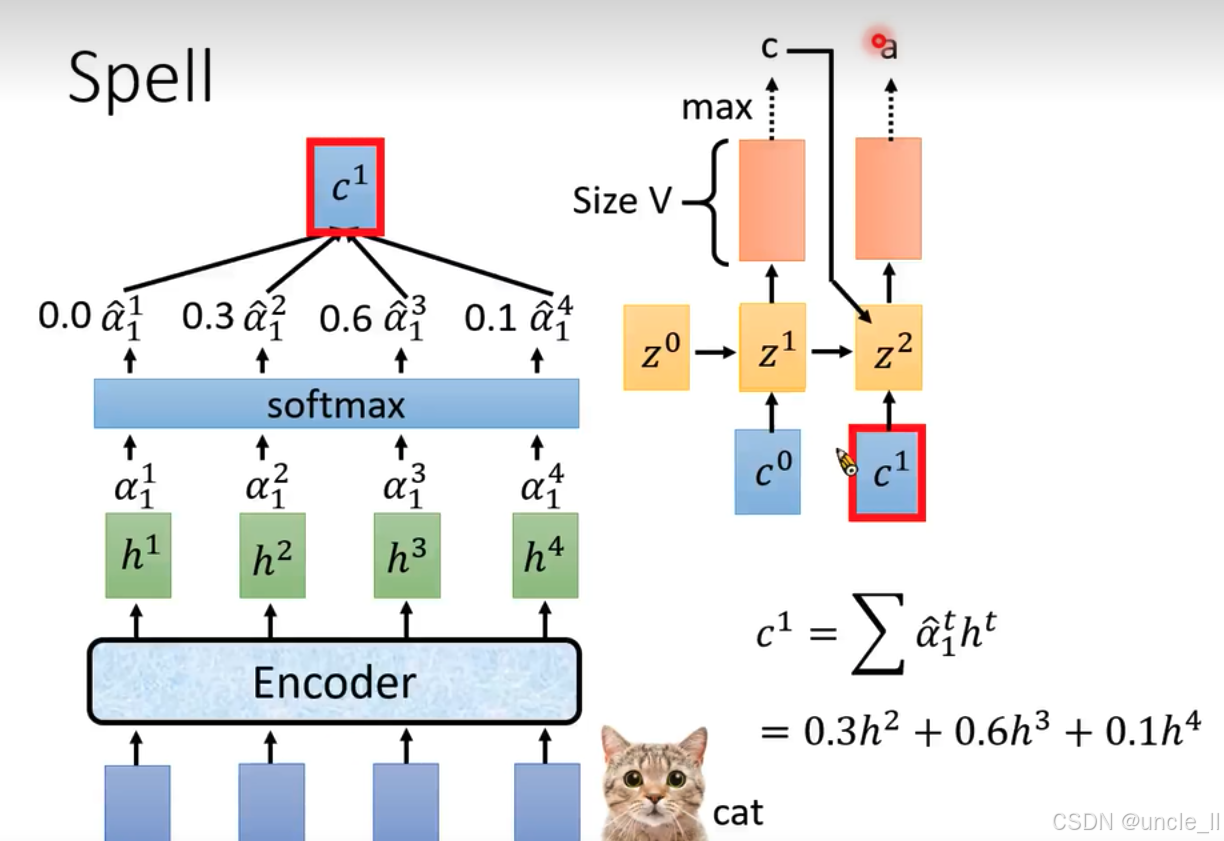
- 輸入與特征提取:依舊是底部藍色模塊作為輸入,經“Encoder”(編碼器 )得到特征表示 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。
- 注意力權重計算:這些特征經注意力機制計算出權重 α 1 1 \alpha_1^1 α11?、 α 1 2 \alpha_1^2 α12?、 α 1 3 \alpha_1^3 α13?、 α 1 4 \alpha_1^4 α14? ,再通過“softmax”函數得到歸一化權重 α ^ 1 1 \hat{\alpha}_1^1 α^11?、 α ^ 1 2 \hat{\alpha}_1^2 α^12?、 α ^ 1 3 \hat{\alpha}_1^3 α^13?、 α ^ 1 4 \hat{\alpha}_1^4 α^14? ,圖中示例為0.0、0.3、0.6、0.1 。
- 上下文向量計算:根據歸一化權重計算新的上下文向量 c 1 c^1 c1 ,公式為 c 1 = ∑ α ^ 1 t h t c^1 = \sum \hat{\alpha}_1^t h^t c1=∑α^1t?ht ,示例中 c 1 = 0.3 h 2 + 0.6 h 3 + 0.1 h 4 c^1 = 0.3h^2 + 0.6h^3 + 0.1h^4 c1=0.3h2+0.6h3+0.1h4 , c 1 c^1 c1用紅色方框特別標出 。
- 循環神經網絡迭代: c 1 c^1 c1作為RNN新的輸入,與隱藏狀態 z 1 z^1 z1結合得到 z 2 z^2 z2 。
- 輸出與預測:基于 z 2 z^2 z2生成所有標記(tokens)上的概率分布,“Size V”表示分布維度(詞匯表大小 ),通過取概率最大值(“max” )確定預測結果 。
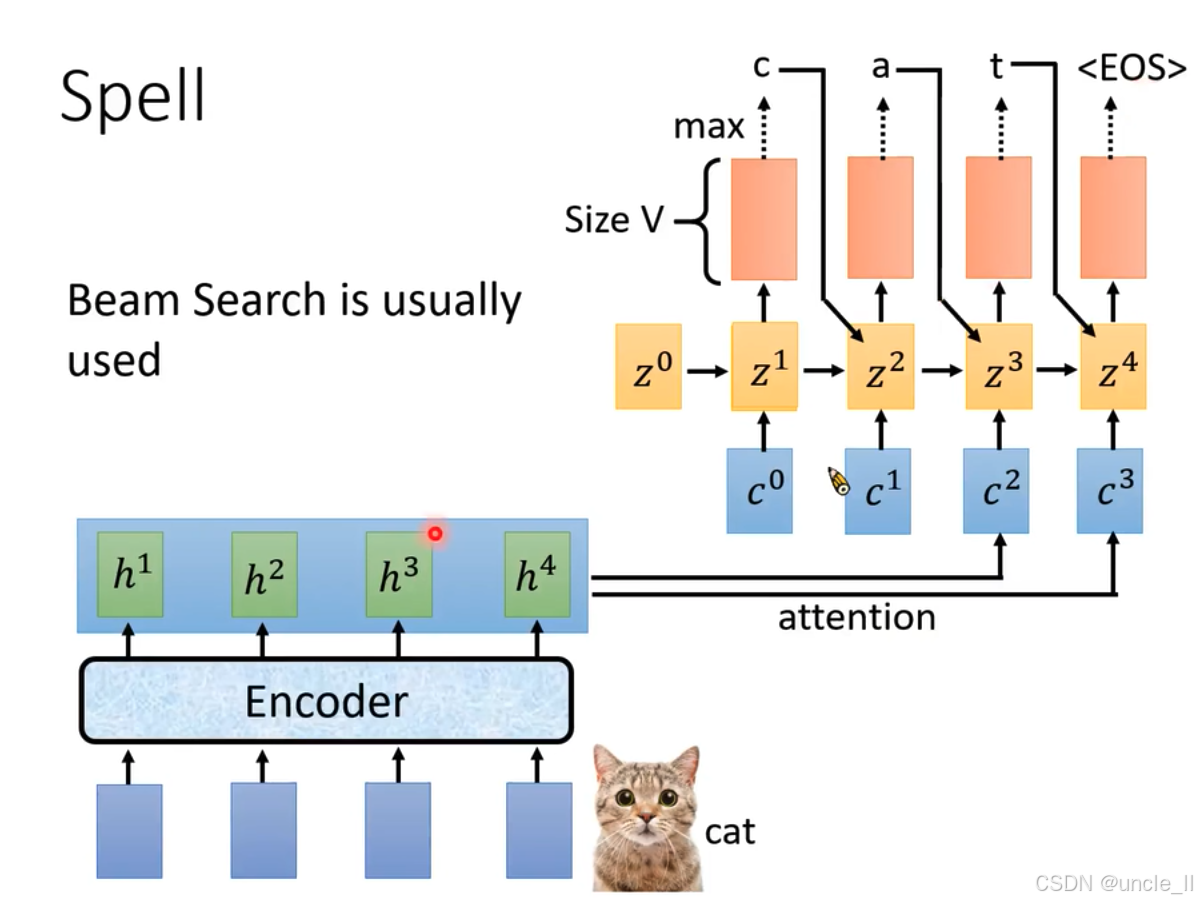
- 輸入與特征提取:底部藍色模塊作為輸入,經“Encoder”(編碼器 )得到特征表示 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。
- 注意力機制:這些特征通過注意力機制,為后續解碼提供加權信息 。
- 循環神經網絡迭代:展示了循環神經網絡隱藏狀態的迭代過程,從 z 0 z^0 z0開始,依次結合上下文向量 c 0 c^0 c0、 c 1 c^1 c1、 c 2 c^2 c2、 c 3 c^3 c3 ,得到 z 1 z^1 z1、 z 2 z^2 z2、 z 3 z^3 z3、 z 4 z^4 z4 。
- 輸出與預測:基于各隱藏狀態生成所有標記(tokens)上的概率分布,“Size V”表示分布維度(詞匯表大小 )。通過取概率最大值(“max” )逐步確定預測結果,圖中示例依次預測出“c”“a”“t” ,最終識別結果為“cat” 。
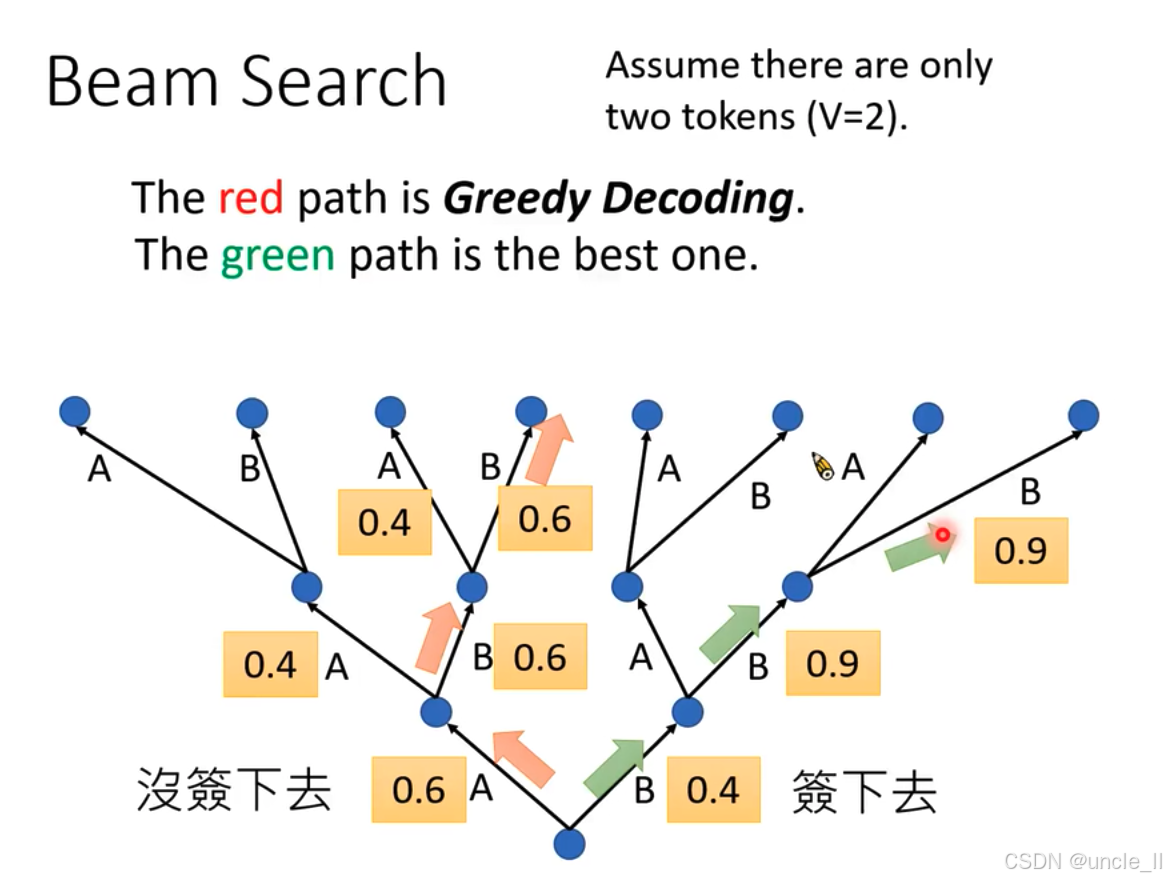
這張圖用于說明束搜索(Beam Search)算法,為便于理解做了簡化假設,假設詞匯表中只有兩個標記(tokens),即 V = 2 V = 2 V=2 ,分別用A和B表示 。
路徑對比
- 紅色路徑(Greedy Decoding,貪婪解碼 ):每一步都選擇當前概率最高的標記。但從全局看,這種策略可能無法得到最優解。圖中紅色箭頭指示其選擇路徑,每一步只關注當下最大概率,未考慮后續整體情況 。
- 綠色路徑:代表全局最優路徑。通過綜合考慮后續步驟,選擇能使最終結果概率最高的路徑,圖中綠色箭頭指示其選擇路徑 。
概率與選擇
圖中不同節點間連線上標注的數字(如0.4、0.6、0.9 )表示選擇相應路徑的概率。在束搜索中,會根據設定的束寬,保留每一步概率較高的若干路徑繼續搜索,而非像貪婪解碼只選當前最優,以此提升找到全局最優解的可能性。 但是實踐中無法計算所有的線路。
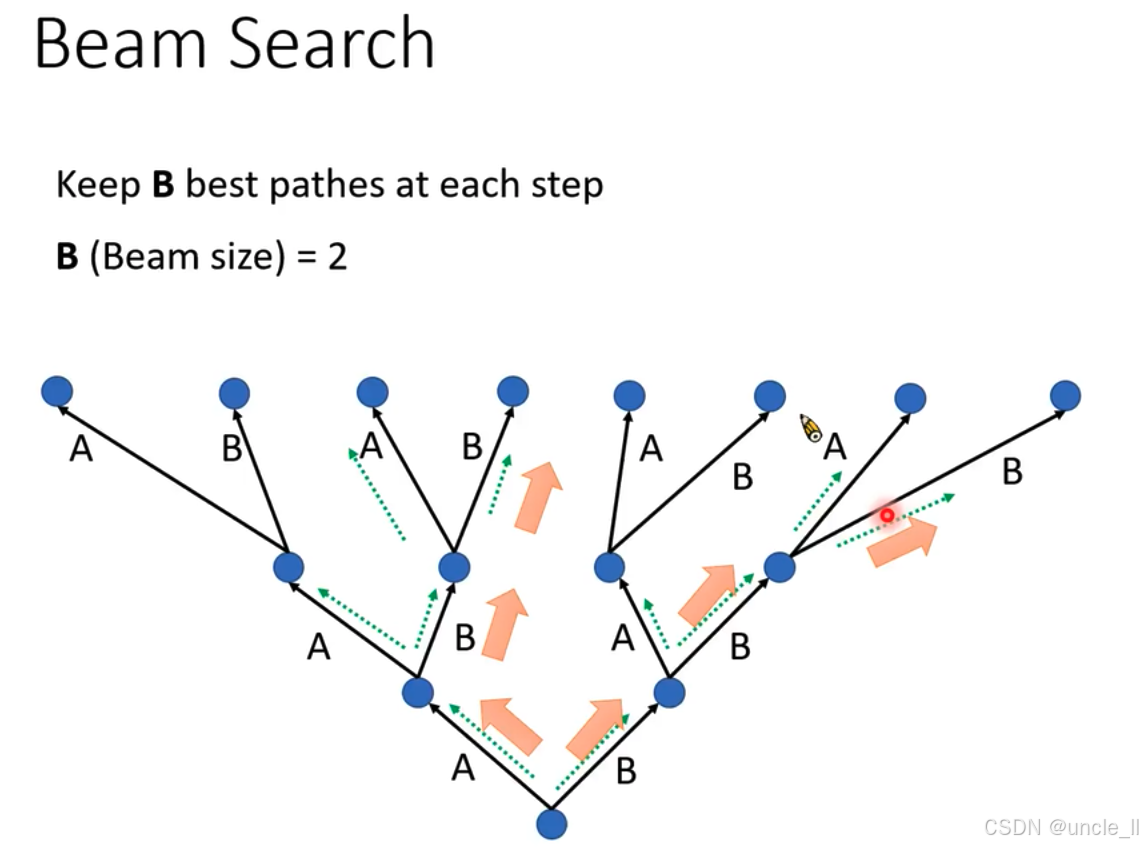
上方文字“Keep B best pathes at each step”說明算法在每一步會保留B條最佳路徑 ,這里設定束寬“B (Beam size) = 2” ,即每一步保留兩條最優路徑繼續搜索 。
- 從起始節點開始,每一步根據概率等因素評估各路徑優劣,保留概率最高的兩條路徑(用綠色箭頭表示 )繼續延伸搜索,舍棄其他路徑(用橙色箭頭表示 ) 。通過這種方式,在平衡計算量的同時,更有可能找到全局最優解,避免像貪婪解碼那樣陷入局部最優 。
Train
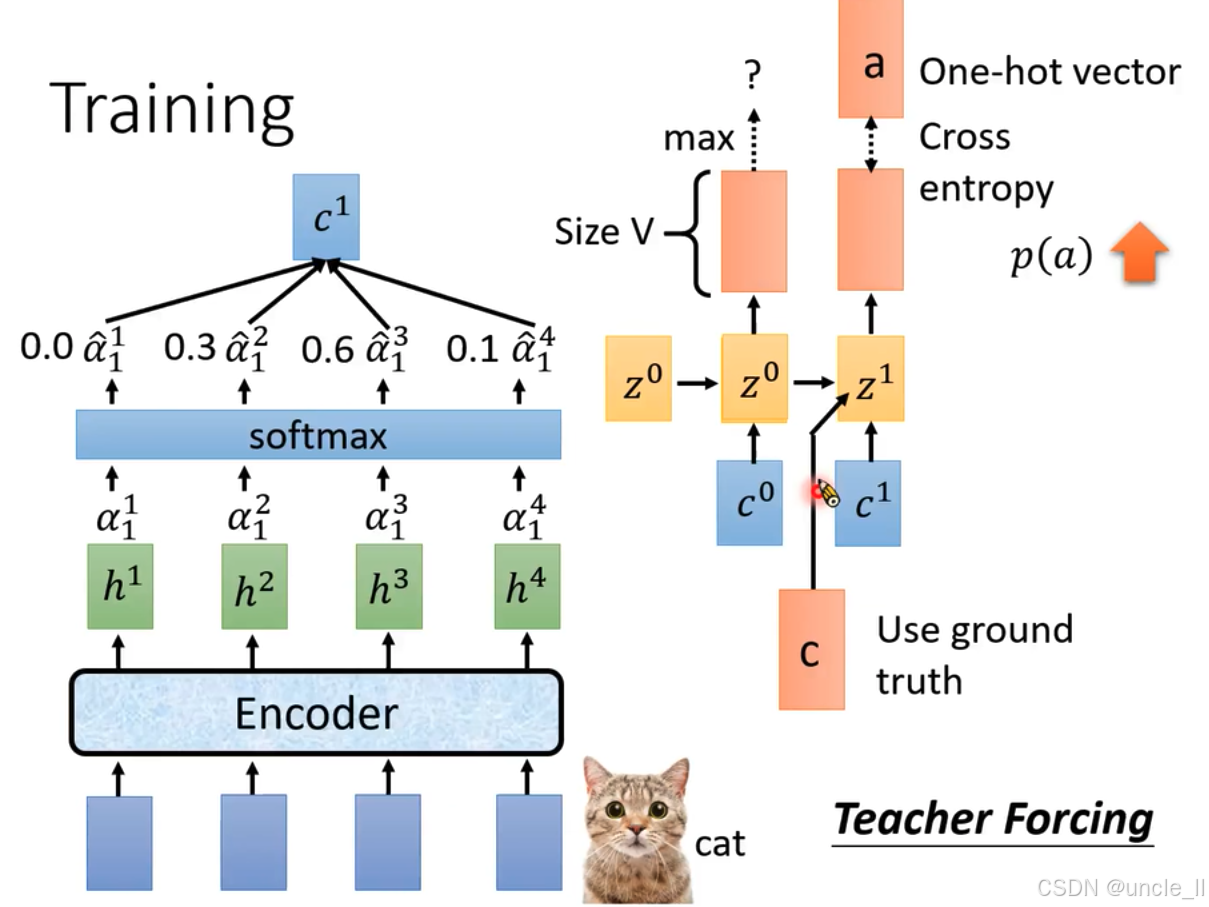
這張圖展示了語音識別模型的訓練過程,涉及Teacher Forcing(教師強制 )機制:
- 輸入與特征提取:底部藍色模塊為輸入,經“Encoder”(編碼器 )處理后得到特征表示 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。
- 注意力權重計算:這些特征通過注意力機制計算出權重 α 1 1 \alpha_1^1 α11?、 α 1 2 \alpha_1^2 α12?、 α 1 3 \alpha_1^3 α13?、 α 1 4 \alpha_1^4 α14? ,再經“softmax”函數得到歸一化權重 α ^ 1 1 \hat{\alpha}_1^1 α^11?、 α ^ 1 2 \hat{\alpha}_1^2 α^12?、 α ^ 1 3 \hat{\alpha}_1^3 α^13?、 α ^ 1 4 \hat{\alpha}_1^4 α^14? ,圖中示例值為0.0、0.3、0.6、0.1 。
- 上下文向量計算:根據歸一化權重計算上下文向量 c 1 c^1 c1 ,公式為 c 1 = ∑ α ^ 1 t h t c^1 = \sum \hat{\alpha}_1^t h^t c1=∑α^1t?ht 。
- 循環神經網絡迭代: c 1 c^1 c1與隱藏狀態 z 0 z^0 z0結合,得到新隱藏狀態 z 1 z^1 z1 。
- 輸出與損失計算:基于 z 1 z^1 z1生成所有標記(tokens)上的概率分布,“Size V”表示分布維度(詞匯表大小 )。通過“max”操作確定預測結果。真實值用獨熱向量(One - hot vector)表示,與預測概率分布通過交叉熵(Cross entropy)計算損失 p ( a ) p(a) p(a) 。
- Teacher Forcing機制:在訓練循環神經網絡時,不使用上一時刻的預測值作為下一時刻的輸入,而是直接使用真實的標簽值作為輸入。這樣能讓模型在訓練時學習到更準確的映射關系,加快收斂速度,避免錯誤累積,但可能導致模型在測試時對錯誤預測的魯棒性較差 。
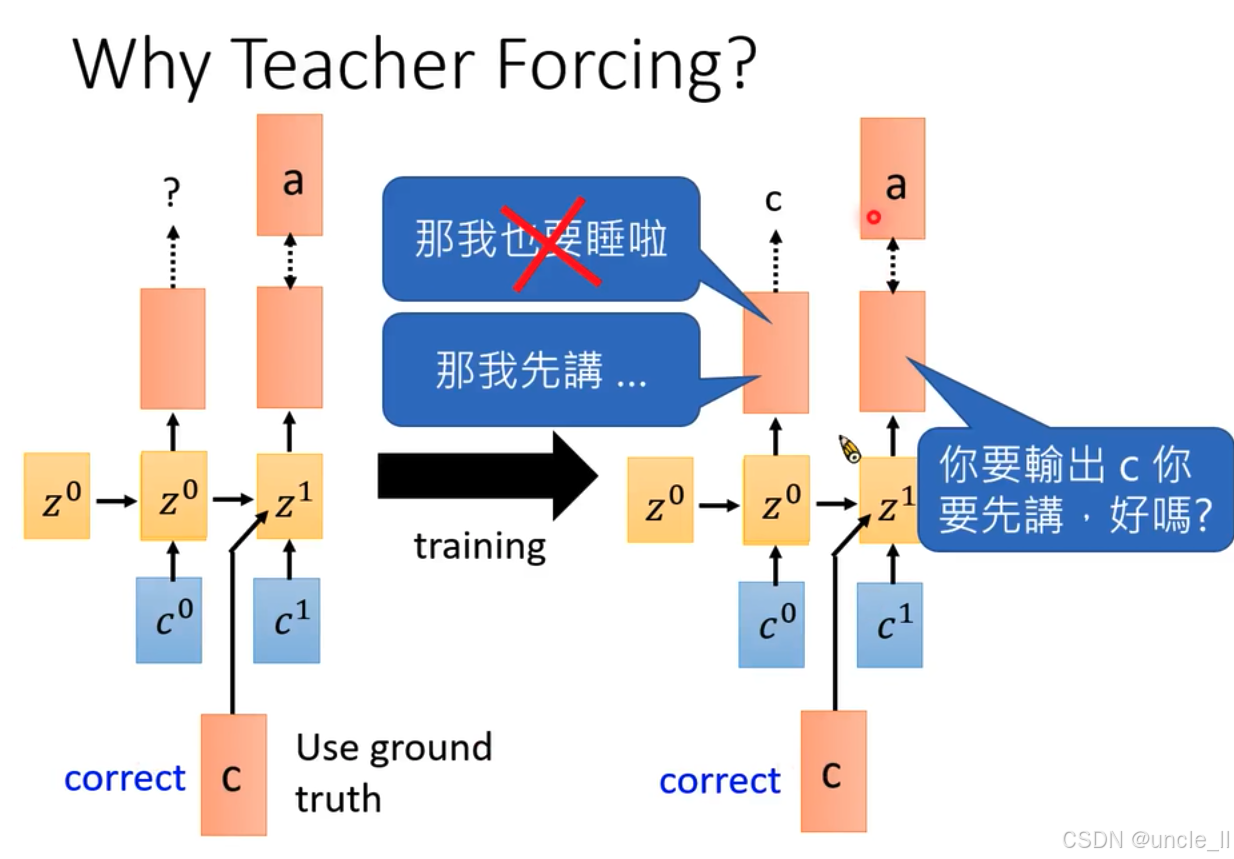
為什么使用教師強制(Teacher Forcing):
- 訓練方式:展示了循環神經網絡訓練時,隱藏狀態從 z 0 z^0 z0轉變到 z 1 z^1 z1 ,輸入為 c 0 c^0 c0和 c 1 c^1 c1 。這里使用真實標簽(標注“correct” )作為輸入,即Teacher Forcing機制 。上方橙色模塊代表輸出,其中一個輸出旁標注問號“?” ,表示模型預測不確定 。藍色對話框“那我也要睡啦”被劃掉,暗示這種方式避免模型因錯誤累積而“消極怠工” 。
- 訓練方式:同樣是隱藏狀態從 z 0 z^0 z0到 z 1 z^1 z1 ,輸入為 c 0 c^0 c0和 c 1 c^1 c1 ,且使用真實標簽(標注“correct” )。藍色對話框“那我先講…”表示模型使用正確標簽信息進行訓練 ,另一個對話框“你要輸出c你要先講,好嗎?” ,進一步強調使用真實標簽能讓模型更好學習正確輸出 。
- 對比說明:中間箭頭標注“training” ,表示從左側情況向右側情況的訓練轉變,強調Teacher Forcing機制在訓練中為模型提供準確信息,避免錯誤累積,使模型能更有效地學習正確映射關系 。
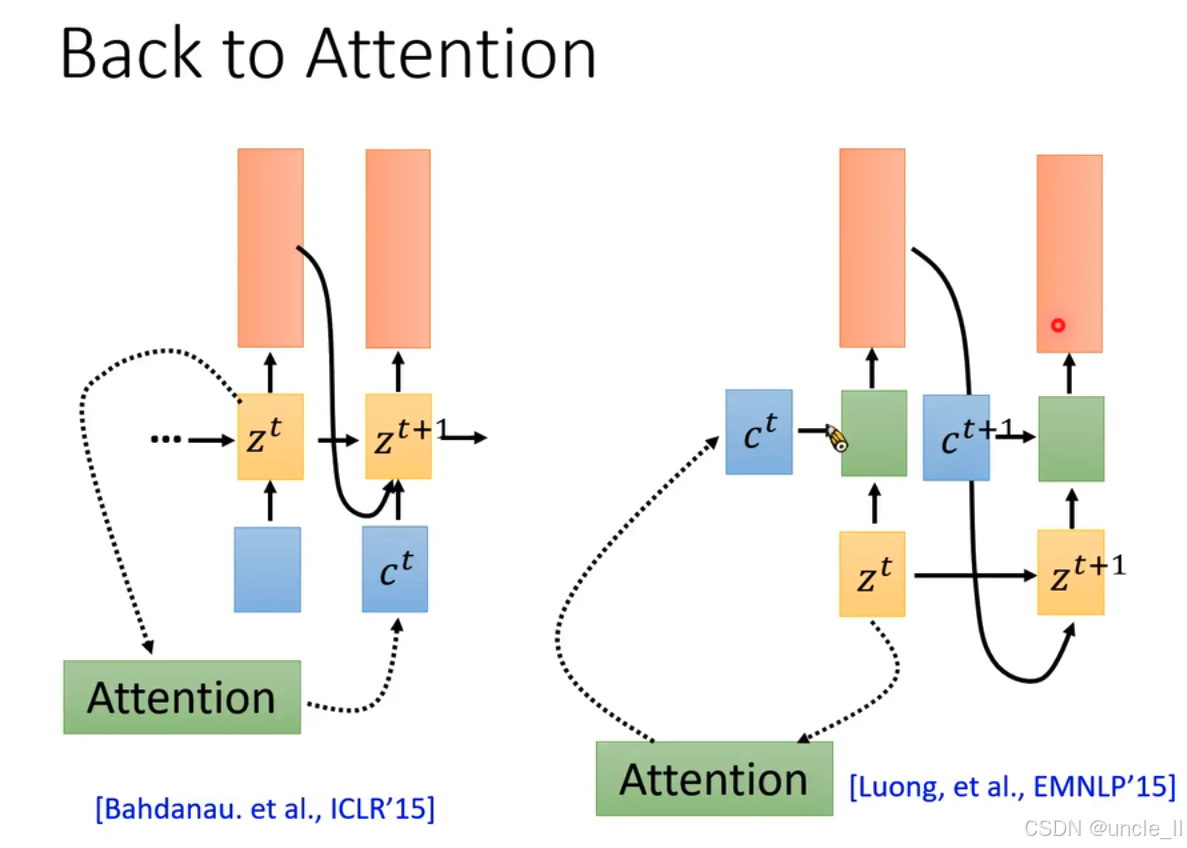
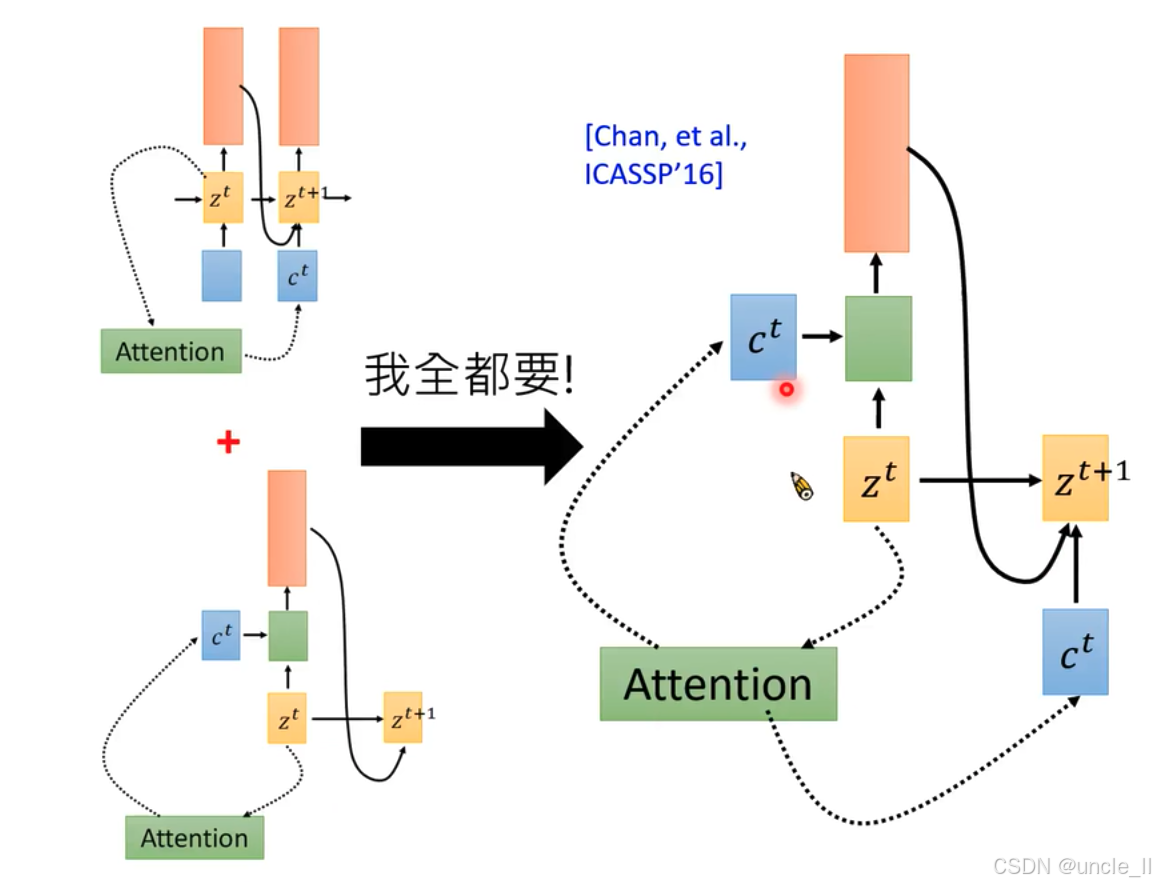
圍繞注意力機制,介紹了不同的注意力計算和應用方式:
- 左圖:出自Bahdanau等人在ICLR’15的研究。展示了注意力機制的一種結構, z t z^t zt和 z t + 1 z^{t + 1} zt+1為隱藏狀態, c t c^t ct是上下文向量,注意力機制(綠色模塊)通過虛線箭頭與其他模塊相連,計算注意力權重并影響隱藏狀態更新和輸出 。
- 右圖:出自Luong等人在EMNLP’15的研究。結構上, z t z^t zt、 z t + 1 z^{t + 1} zt+1、 c t c^t ct、 c t + 1 c^{t + 1} ct+1作用類似,但注意力機制與各模塊連接方式有別,體現不同的注意力計算和應用思路 。
- 二者都要:出自Chan等人在ICASSP’16的研究,是前兩者結合(圖中“我全都要!” )。綜合了不同注意力機制的優勢,展示了更復雜的信息交互,隱藏狀態 z t z^t zt、 z t + 1 z^{t + 1} zt+1 ,上下文向量 c t c^t ct ,注意力機制模塊(綠色 )之間通過虛線箭頭緊密連接,體現多方面信息整合用于計算注意力權重,為后續任務提供支持 。
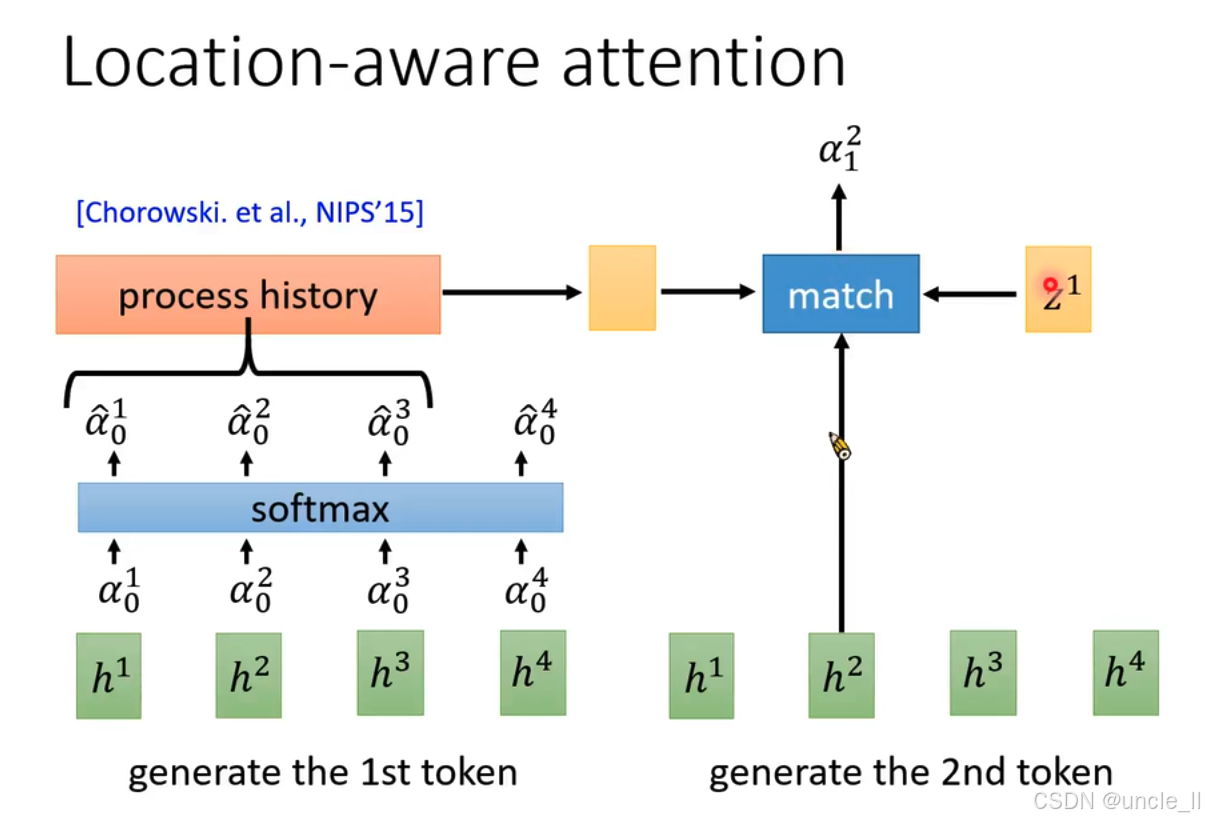
這張圖介紹了位置感知注意力(Location - aware attention)機制:
- 生成第一個標記(token) :輸入特征 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 ,通過注意力機制計算得到注意力權重 α 0 1 \alpha_0^1 α01?、 α 0 2 \alpha_0^2 α02?、 α 0 3 \alpha_0^3 α03?、 α 0 4 \alpha_0^4 α04? ,經“softmax”函數得到歸一化權重 α ^ 0 1 \hat{\alpha}_0^1 α^01?、 α ^ 0 2 \hat{\alpha}_0^2 α^02?、 α ^ 0 3 \hat{\alpha}_0^3 α^03?、 α ^ 0 4 \hat{\alpha}_0^4 α^04? 。這些權重用于計算“process history” ,最終生成第一個標記 。
- 生成第二個標記 :輸入特征仍為 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 ,結合之前的隱藏狀態 z 1 z^1 z1 ,通過“match”操作計算注意力權重 α 1 2 \alpha_1^2 α12? ,用于生成第二個標記 。
- 來源:該機制出自Chorowski等人在NIPS’15(神經信息處理系統大會,2015年 )的研究 。
- 特點:位置感知注意力機制在計算注意力權重時,會考慮輸入序列的位置信息,使得模型在生成標記時能更好地捕捉序列中不同位置的特征依賴關系,提升模型在處理序列數據(如語音識別、自然語言處理 )時的性能 。
Performance
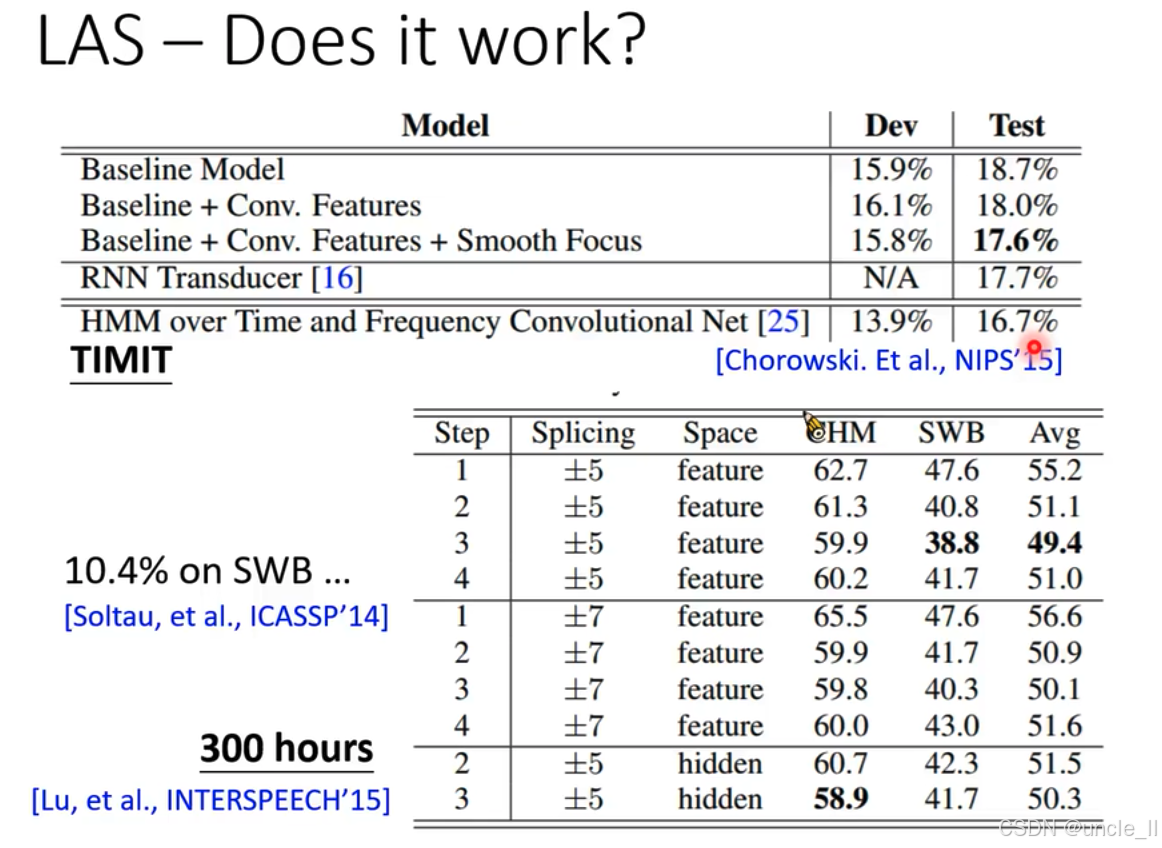
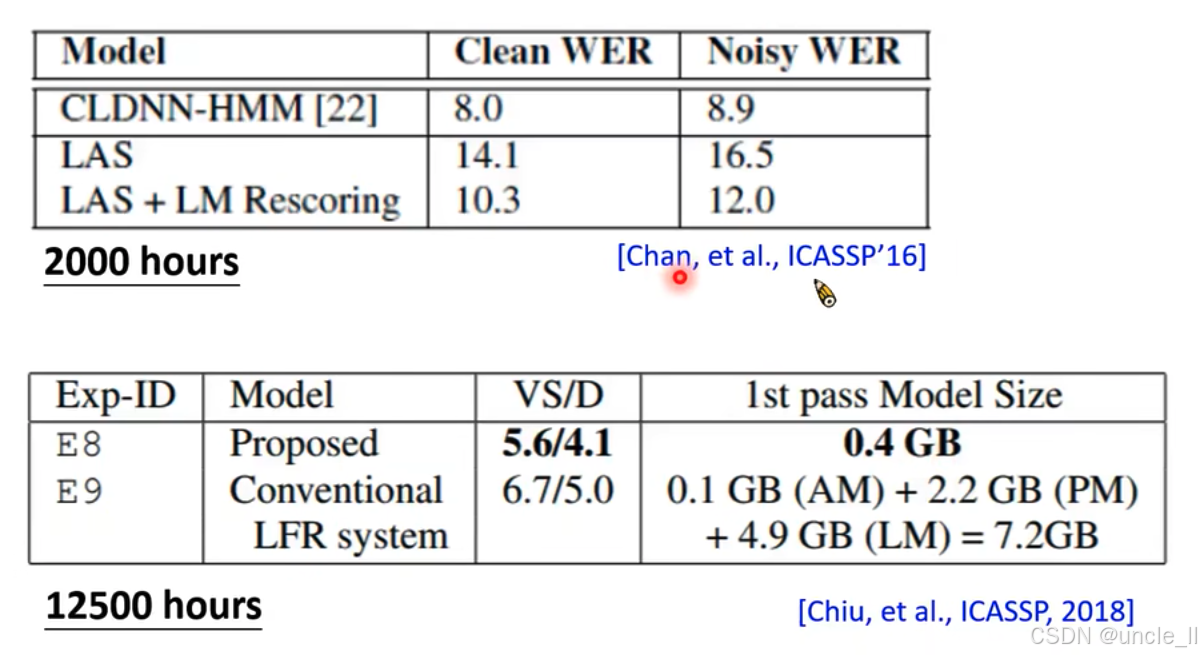
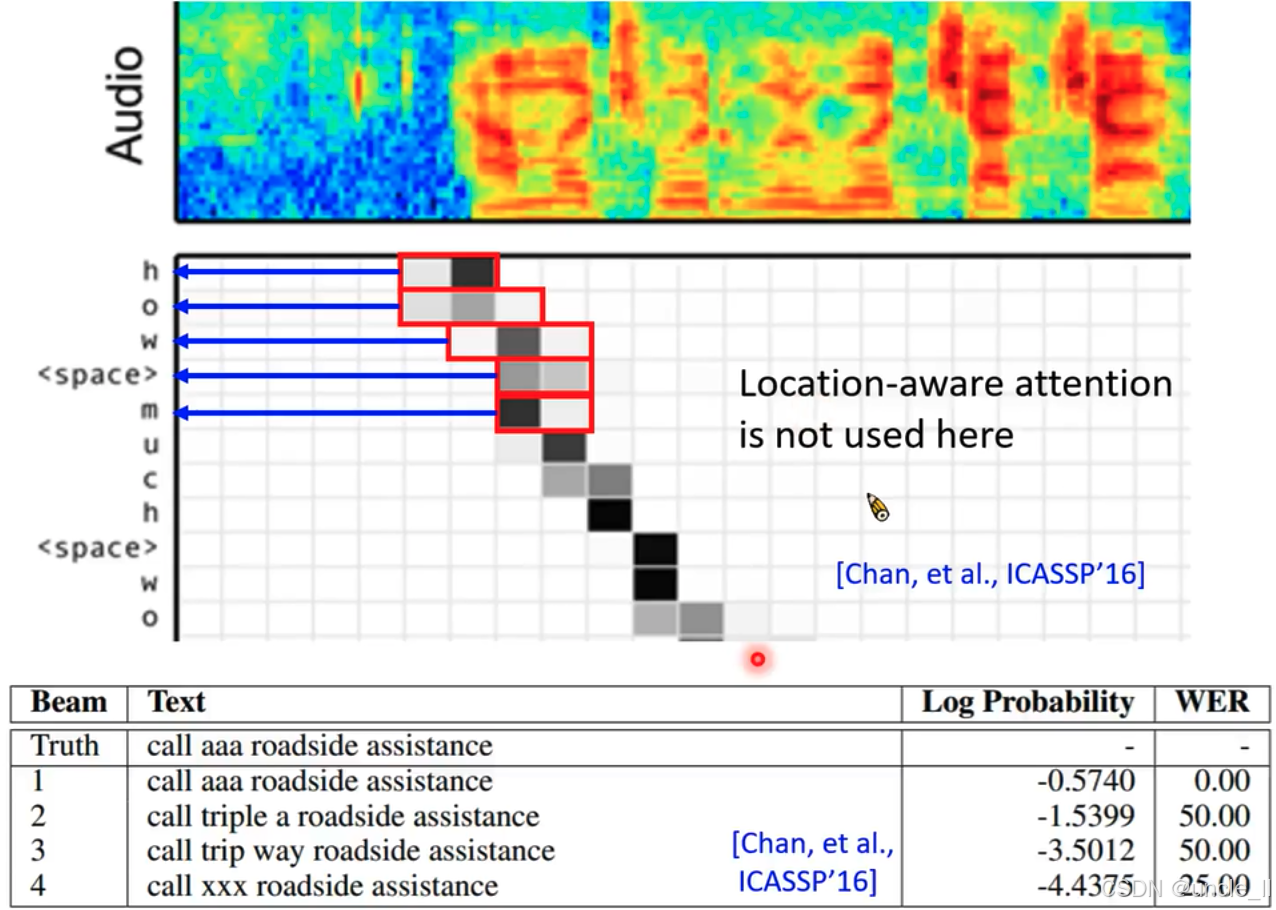
- aaa 和 triple a
- LAS能學到復雜的輸入和輸出
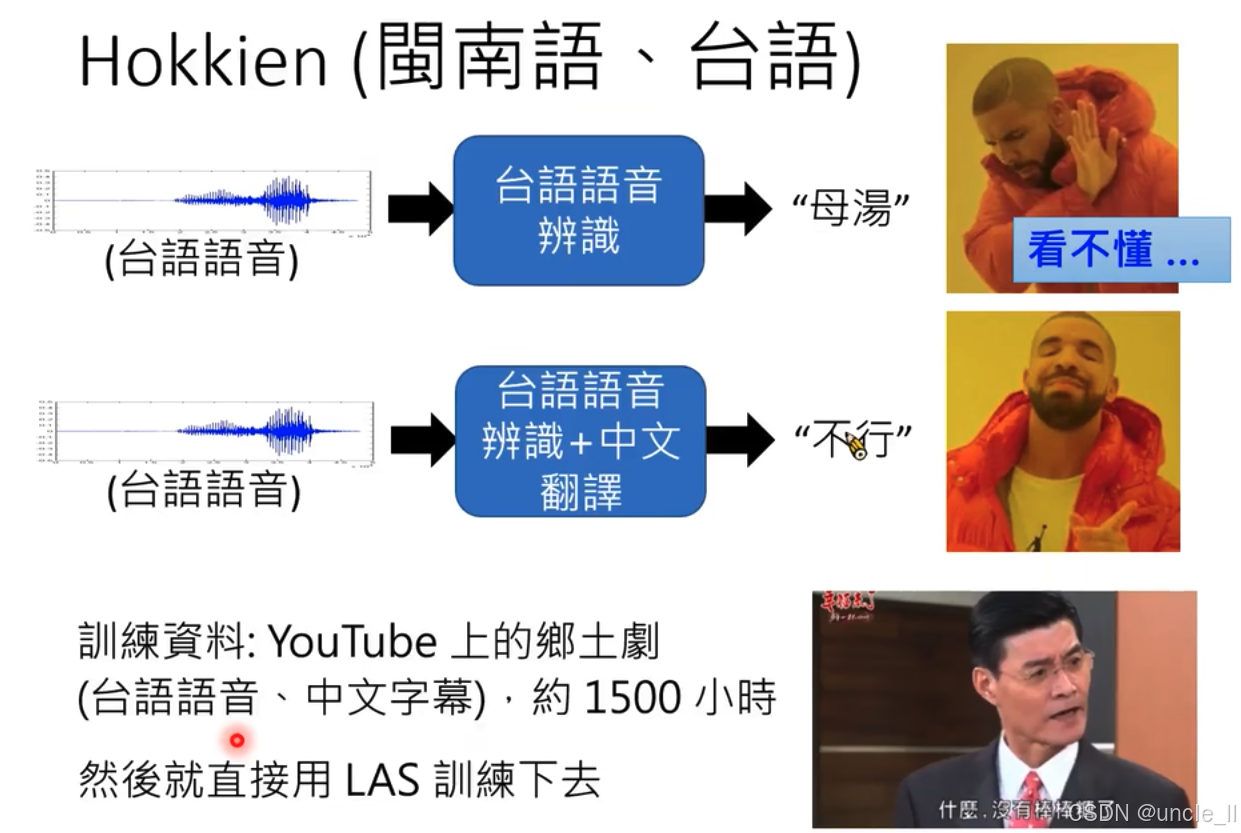
- 閩南語(臺語)語音識別及翻譯
- 不用考慮背景音樂,音效
Limitation

LAS(Listen, Attend and Spell)模型的局限性:
- LAS模型需聽完整個輸入語音后,才輸出第一個標記(token) 。這意味著在處理語音時,無法即時反饋識別結果,存在延遲。
- 用戶期望的是在線語音識別,即能實時、逐字地看到語音識別結果,而LAS模型的處理方式無法滿足這一需求 。


![AndroidTV D貝桌面-v3.2.5-[支持文件傳輸]](http://pic.xiahunao.cn/AndroidTV D貝桌面-v3.2.5-[支持文件傳輸])







-vsg中vulkan資源的編譯)



—— 聚類(二))
)



