過去自己學習深度強化學習的痛點:
-
只能看到各種術語、數學公式勉強看懂,沒有建立清晰且準確關聯
-
多變量交互關系浮于表面,有時候連環境、代理控制的變量都混淆
-
模型種類繁多,概念繁雜難整合、對比或復用,無框架分析所有模型
-
代碼實現步驟未清晰劃分:環境->定義獎勵->創建代理->訓練->部署
最根本的原因在于,我們需要一個既能全面表達復雜環境與交互結構,又能統一處理不確定性和動態決策的數學與計算(所有強化學習)框架。
概率圖模型的“圖結構”天然適合分解復雜依賴:
-
可以把一系列隨機變量之間的依賴關系用圖的結構直觀地呈現出來。
-
不管是MDP、HMM(隱馬爾可夫模型)還是更復雜的POMDP和Bayesian網絡,都可以視作是對一系列隨機變量之間依賴關系的“圖”式表達。
-
概率圖模型以直觀的圖形方式展示變量之間的因果或條件依賴關系,利于后續的解釋或擴展。
強化學習本質:一個序列決策過程,狀態?(St)、動作?(At)?以及獎勵?(Rt)?隨時間演化且相互影響
-
圖模型優勢:通過節點和有向邊,清晰地展現“誰依賴于誰”,幫助我們明確:
-
當前時刻狀態與動作是如何影響下一個時刻狀態與獎勵的?
-
代理(Agent)與環境(Environment)分別控制或決定哪些隨機變量?
-
哪些假設(如馬爾可夫性、完全可觀測或部分可觀測等)在圖中如何體現?
-
概率圖模型在統計推斷(如Bayesian推斷、最大似然估計)方面有完善的理論和工具,因此能與RL中的探索—利用(exploration-exploitation)過程自然結合。
當我們能用一個動態貝葉斯網絡或馬爾可夫隨機場來可視化時,序列之間的關系就變得更加透明。
對于多變量混雜可二分梳理,強化學習中的主體包括“環境”和“代理”。
-
環境負責提供狀態和獎勵
-
代理在環境中采取行動以實現累積收益最大化。
所有強化學習的“通用藍圖”:
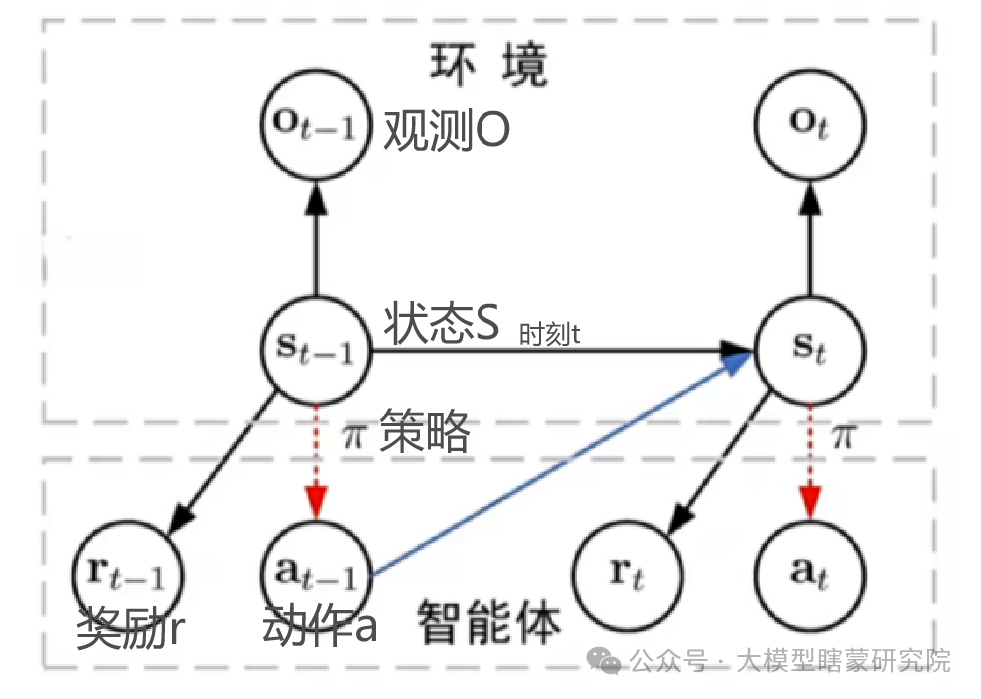
沒有限定狀態空間、動作空間、獎勵形式、策略結構、環境類型(確定性/隨機性/部分可觀測...)。
只展示了宏觀的交互關系,而任何“特例”都可以往里套。
環境根據動作(at)和當前狀態(st)給出下一時刻狀態(st+1)及相應的獎勵(rt),然后智能體再繼續與環境交互……
-
狀態(st):
-
抽象了環境在時刻?t?的完整信息;如果不可完全觀測,就用觀測(ot)或者在 POMDP 框架里再對隱藏狀態建模。
-
不同算法的差別,大多體現在怎樣定義或估計這個狀態,以及是否需要顯式建模環境動力學。
-
-
動作(at):
-
智能體在時刻?t?作出的決策,這個決策可來自直接表格型策略或神經網絡近似;既可以是離散的也可以是連續的。
-
但無論用什么表示方法,始終繞不開“在狀態下做動作”的這個核心過程。
-
-
獎勵(rt):
-
環境對當前狀態、動作的一次性反饋,用來指導智能體學習;兼容各種獎勵設計(稀疏獎勵、密集獎勵、多維獎勵等)。
-
強化學習最核心的目標即是最大化“回報”,即從獎勵推導的累計收益,這也體現了動態規劃的思想。
-
-
策略(π(at∣st)):
-
表示智能體在狀態?st?下選擇動作?at?的概率分布(或確定性函數),正是因為有這個策略才構成了完整的“閉環”。
-
所有算法都需要“如何表示策略、如何更新/優化策略、如何評價策略的好壞”。
-
-
狀態轉移和觀測模型:
-
用概率分布?P(st+1∣st,?at)?來刻畫環境動力學和不確定性;若有部分可觀測,則還要有?P(ot∣st)。
-
任何隨機性、噪聲、對未來的不確定,都能融入到這條“狀態演化”的概率分布里,并且與獎勵、動作緊密結合。
-



 -- 定制開發板)
)
)




)


和新方法())





