賽博·新聞
1、英偉達開源新模型,性能直逼DeepSeek-R1
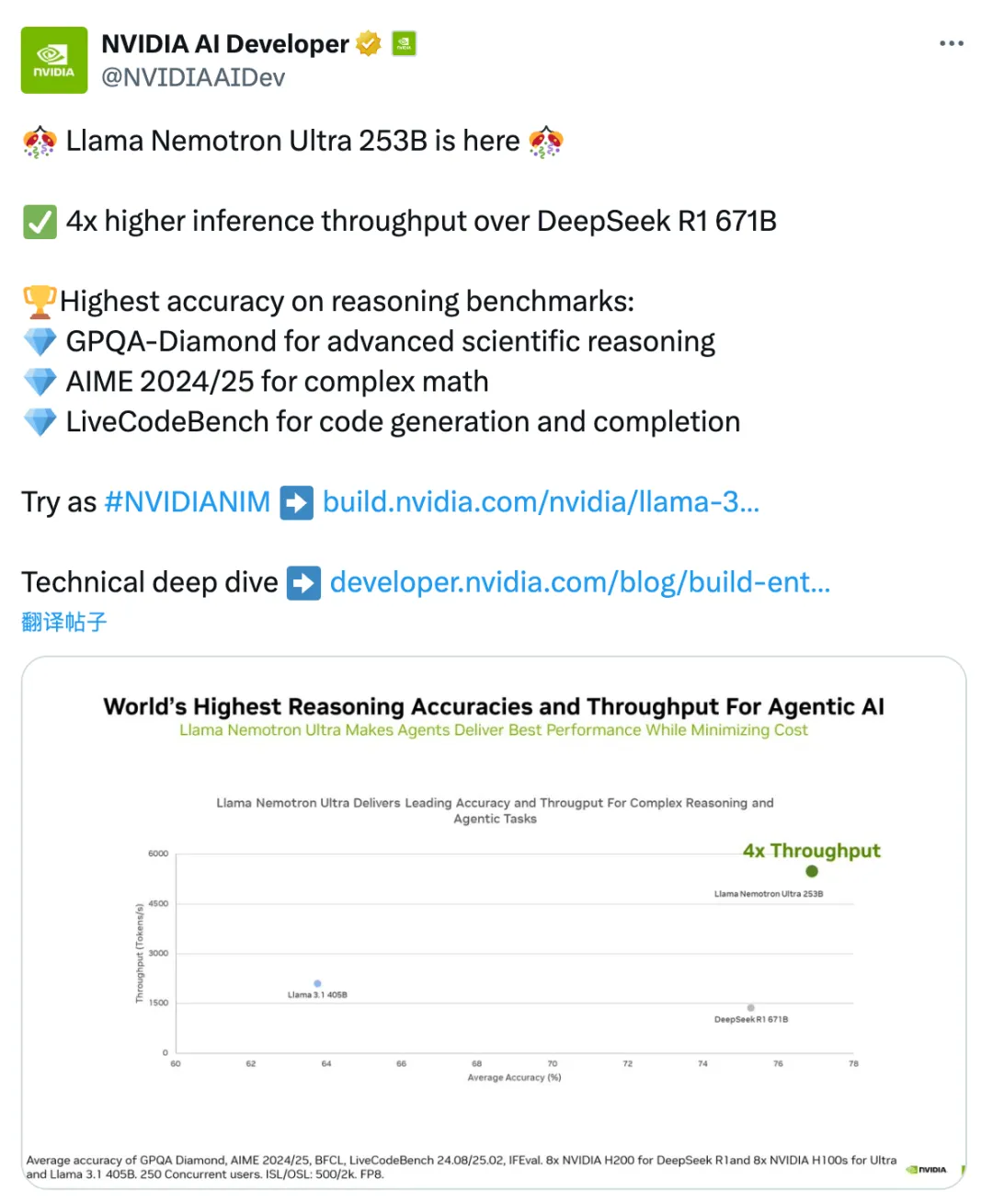
本周,英偉達開源了基于Meta早期Llama-3.1-405B-Instruct模型開發的Llama-3.1-Nemotron-Ultra-253B-v1大語言模型,該模型擁有2530億參數,在多項基準測試中展現出與6710億參數的DeepSeek-R1相媲美的性能,甚至在GPQA(76vs.71.5)、IFEval指令遵循(89.5vs.88.8)和LiveCodeBench編碼任務(66.3vs.65.9)中表現更優,同時推理吞吐量達到后者的4倍,但DeepSeek-R1在MATH500和ArenaHard基準測試中仍具微弱優勢。該模型通過神經架構搜索(NAS)優化架構設計,引入跳躍注意力層、融合前饋網絡(FFN)及可變FFN壓縮率等技術,有效降低內存占用與計算需求,在保持輸出質量的前提下支持高效部署,可運行于單個8xH100GPU節點,兼容B100和Hopper微架構硬件,并通過BF16與FP8精度驗證。其應用場景涵蓋聊天機器人開發、AIAgent工作流、檢索增強生成(RAG)及代碼生成,且根據英偉達開放模型許可證及Llama3.1社區許可協議,允許商業用途,模型代碼及權重已在HuggingFace平臺開源。
2、OpenAI宣布GPT-4退役
OpenAI在更新日志中宣布,自2025年4月30日起,GPT?4將在ChatGPT中退役,將完全被GPT?4o取代。不過這也不意味著GPT-4再也用不了,開發者依然可以在API中可調用GPT-4。OpenAI表示,GPT-4是ChatGPT進化中的里程碑時刻,它所實現的種種突破,以及那些塑造了其繼任者的寶貴反饋,團隊都心懷感激。而GPT-4o正是在這個基礎上,帶來更強大的能力、更優的一致性與更豐富的創造力。2023年3月15日,GPT-4正式發布,在多種專業和學術指標下展現了人類水平的表現,甚至已經達到哈佛、斯坦福的水平,在之后一年都是各家大模型唯一的對標對象。

?
3、OpenAI或將在下周發布多款新模型
日前,OpenAI CEO Sam Altman在回復網友時表示,o3和o4-mini兩款新模型會在不久之后發布。而據TheVerge消息,知名AI軟件工程師Tibor Blaho今天也在新版ChatGPT網頁中發現了o4mini、o4minihigh和o3的相關信息。而The Verge也表示,o3和o4mini系列都將會在下周推出,除非OpenAI調整發布計劃。另外,報道還指出OpenAI將會在下周推出GPT-4.1系列模型,包括更小版本的GPT-4.1mini和nano兩個版本。知情人士透露GPT-4.1將會是多模態模型GPT-4o的改進版。不止新模型,昨晚Altman還發文聲稱今天會推出一個「令人興奮」的新功能。而這一新功能目前已經揭曉——全面升級的記憶功能。據介紹,從今天開始,ChatGPT將能夠參考用戶所有的歷史對話內容,提供更加個性化的服務體驗,比如在寫作、建議、學習等方面,能給出貼合用戶喜好的回答。早在去年9月,ChatGPT就已全量推送記憶功能,并將其擴展到GPTs功能。而此次升級后,新的對話將在已保存的記憶信息上自然延伸,交互更加流暢,更符合用戶個人風格。

4、昆侖萬維開源7B/32B最強數學代碼推理模型
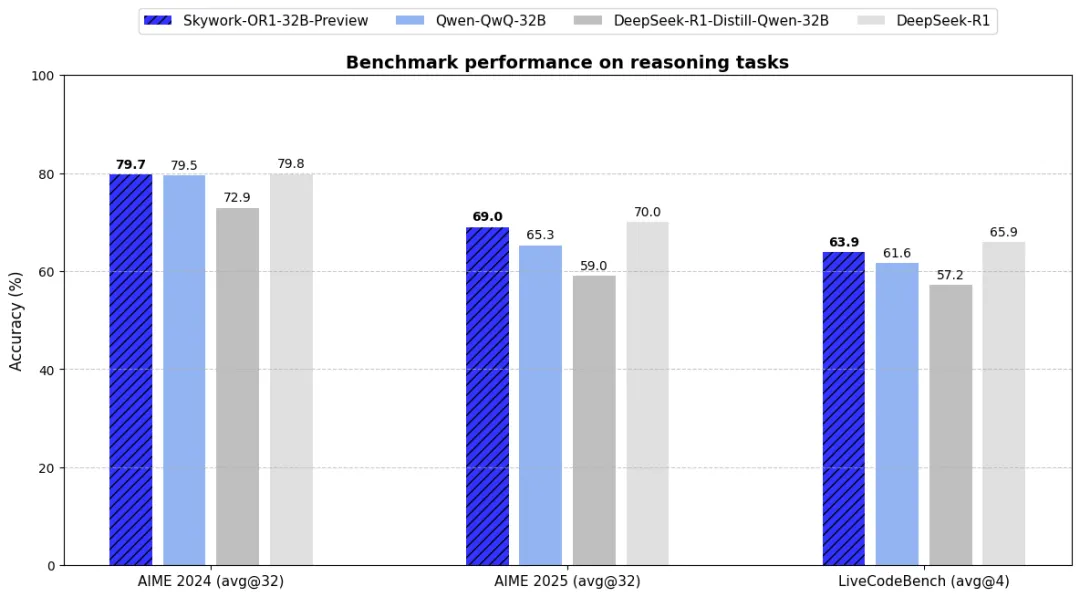
本周,昆侖萬維天工團隊推出全新開源推理模型SkyWork-OR1系列,包含7B和32B參數規模的數學專項模型與通用模型,在同等參數規模下實現業界領先的數學推理與代碼生成能力。該系列通過構建高質量數學與代碼數據集(11萬數學題和1.37萬代碼問題)、采用Group Relative Policy Optimization(GRPO)訓練方法及多階段訓練策略,顯著提升模型在復雜任務中的穩定性與推理深度。技術亮點包括動態數據過濾機制(離線/在線雙重篩選)、多階段上下文窗口擴展訓練、自適應熵控制探索策略,以及創新評估指標avg@k(替代傳統pass@k)以更全面衡量模型性能。其中SkyWork-OR1-32B-Preview在數學推理任務中超越阿里QwQ-32B,與DeepSeek-R1持平;專注數學的7B模型在AIME2024/2025分別取得69.8%和52.3%的avg@32成績,代碼能力亦同步提升至43.6%。團隊采用業界最高透明度開源策略,全面公開模型權重、訓練數據集、完整代碼及技術文檔,通過漸進式訓練優化與嚴格數據質量控制,在保持模型緊湊性的同時實現專業領域突破,為AI社區提供可復現的推理模型訓練范本。
5、字節開源新生圖模型
本周,字節開源的全新圖像生成模型UNO,通過統一架構實現了多任務圖像生成的突破性進展,其核心創新在于以Flux.1模型為基礎,采用“模型-數據共同進化”范式,有效解決了參考驅動生成中數據擴展性(單主體到多主體數據集的擴展)和主體擴展性(多物體協同生成)兩大挑戰。UNO整合了文生圖、單/多主體參考生成功能,支持最多四張參考圖的跨主體融合,例如將運動鞋與埃菲爾鐵塔背景結合,或保持人物特征生成吉卜力風格圖像,在虛擬試穿、產品設計等場景中展現應用潛力。技術層面,模型通過兩階段訓練策略(先單主體微調后多主體增強)和基于Object365分類樹的大規模數據合成框架,結合創新的通用旋轉位置編碼(UniRoPE),精準調控多模態交互并緩解屬性混淆問題。實驗表明,UNO在單主體生成任務中DINO得分0.542、多主體任務DINO得分0.760,全面超越OmniGen、RealCustom++等模型,用戶研究顯示其在主體相似度、文本忠實度和視覺吸引力上均領先競品。該模型通過HuggingFace開放體驗,其統一架構設計和技術路徑(如擴散Transformer的上下文生成能力)為AI生成內容的精細化控制開辟新方向,被業界視為推動定制化AI智能體發展的關鍵突破,其模型-數據協同進化范式可能成為擴散模型訓練的新標準,標志著多主體可控生成技術從單點突破邁向系統化解決方案的重要里程碑。

賽博·洞見
1、互聯網下一步,歡迎來到智能體互聯網(AgenticWeb)時代!
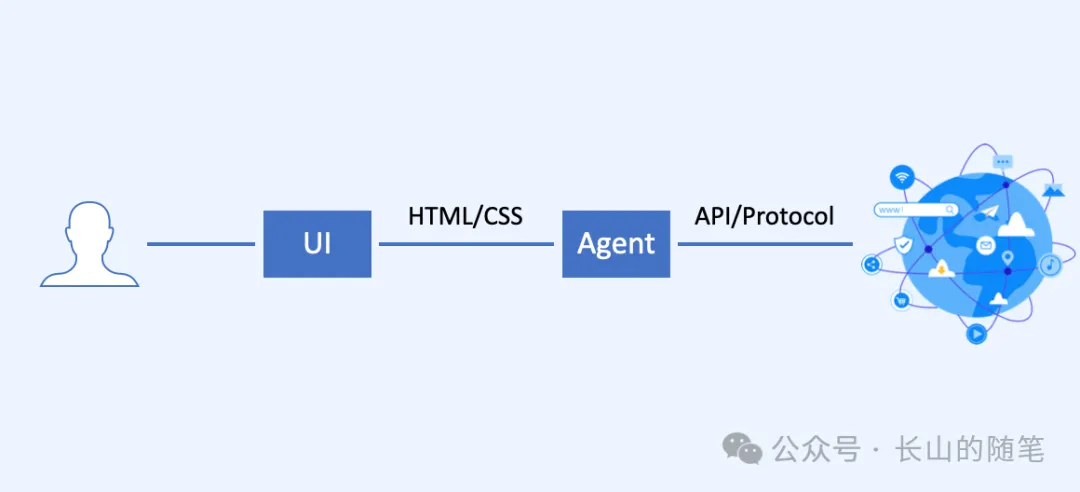
互聯網的演進方向由新技術驅動,當前生成式AI與大模型的發展將推動互聯網進入智能體互聯網(Agentic Web)時代。現有互聯網因數據孤島和人類中心化設計無法充分釋放AI能力,下一代互聯網需解決四大問題:讓AI獲取完整上下文信息、調用所有工具、以原生接口(API/協議)交互、實現智能體高效協作。文章否定了模仿人類操作的Computer Use技術和終端綁定的AI手機方案,認為Anthropic的MCP協議與去中心化的Agent Network Protocol更符合趨勢。未來智能體將取代人類成為互聯網主要節點,個人助理作為新入口通過個性化UI服務用戶,后端智能體通過自組織協議互聯互通,形成扁平化、去中心化的協作網絡。這一變革將重構現有應用生態,打破平臺壟斷,最終使互聯網從“人類操作界面”轉向“智能體協作網絡”,其市場規模潛力達千億美金級別。技術本質是通過開放協議釋放AI處理底層數據與自主協作的能力,而非適配現有圖形界面體系。
2、GPT4o又出15種腦洞玩法,吉卜力已經落后N個版本了
這篇文章全面展示了GPT-4o在創意生成領域的突破性應用,通過15種創新玩法揭示其超越傳統AI工具的潛力。核心在于GPT-4o憑借強大的多模態理解能力,能夠實現從潮玩手辦定制到藝術創作的全鏈路突破:用戶可通過精準提示詞生成真實感手辦模型(如甲亢哥手辦/泡泡瑪特盲盒)、創作3D浪漫場景擺件,甚至結合Kling制作把玩視頻;在文字領域,既可模擬人類涂鴉筆記實現圖文混排標注,又能通過HTML代碼精準控制視覺元素的色彩呈現;雙面人像功能將不同藝術風格(如吉卜力動畫與超現實主義)融合在同一肖像中,展現時空碰撞的戲劇張力;寵物擬人化功能可將貓狗轉化為特定風格的人類形象,并制作專屬表情包;微縮世界功能則通過剖面模型展現設備內部奇幻場景(如電話機里的太空植物園),結合粘土質感渲染打造虛實交融的微觀世界。這些玩法不僅突破了MidJourney等工具的風格局限,更通過語義理解實現跨模態創作,將AI從工具升維為創意合作伙伴,為藝術設計、IP開發、個性化定制等領域開辟全新可能性。

3、為什么AIAgent需要自己的瀏覽器?
隨著AI Agent逐漸成為互聯網流量的重要組成部分,傳統瀏覽器和現有無頭瀏覽器技術已無法滿足其自動化交互需求。當前互聯網40%流量來自機器人,但網站普遍缺乏結構化API接口,迫使AIAgent依賴傳統網頁交互方式,而現有瀏覽器在設計邏輯上以人類視覺交互為核心,存在動態內容加載、復雜頁面解析、反爬機制規避、交互流程自動化等天然缺陷。盡管Puppeteer等無頭瀏覽器技術提供代碼級控制能力,但其操作復雜度高且維護成本大,無法適應AIAgent所需的高效自然語言交互范式。Browserbase提出的云端專屬瀏覽器解決方案通過整合LLM和VLM技術,賦予瀏覽器理解網頁語義和自適應頁面變化的能力,將傳統基于DOM元素定位的機械操作轉化為自然語言驅動的智能交互,配合Stagehand框架實現開發者與網頁的自然語言對話。這種AI原生瀏覽器不僅解決動態內容加載、驗證碼識別等技術難題,更重要的是通過云端服務提供彈性擴展能力,大幅降低AIAgent與網頁交互的技術門檻和運維成本,為構建自主完成任務的高效AI系統提供基礎設施支撐,標志著瀏覽器從人類視覺交互工具向AI智能體操作系統的范式轉變。

4、為什么美國人的AI應用看起來跑的好像更快些?
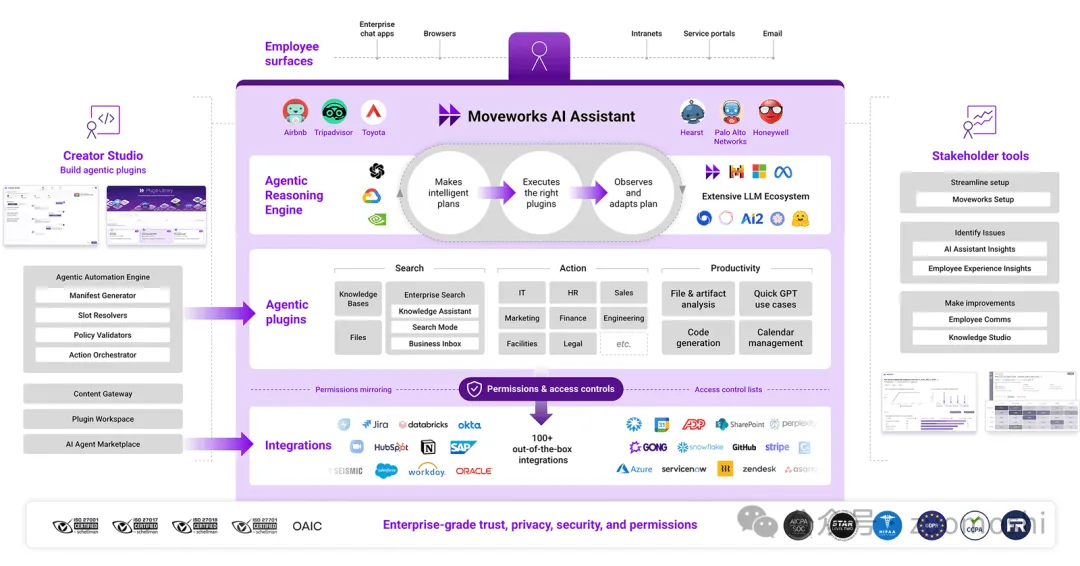
這篇文章的核心觀點認為,中美在AI應用發展速度的差異源于企業數據層的結構性缺失。美國AI應用的高速成長建立在成熟的SaaS生態之上,其B端數據層具備完整性、實時性和系統穿透性:企業數據全域打通形成"活數據",使Glean、Moveworks等產品能通過智能層實現精準服務(如企業知識管理、IT服務自動化),催生ARR超億美元的規模化營收。而中國長期受限于碎片化生產關系,企業數據割裂在部門墻與系統孤島中,既無法形成完整數據資產,也難以維持數據時效性——這些物理特性導致構建有效數據層的成本遠超技術投入,直接制約AI應用的商業價值。更深層矛盾在于,數據價值遵循"全有或全無"定律:局部數據價值趨零,全量實時數據才能激發指數級應用創新。當前路徑依賴下,簡單復制美國SaaS+AI模式難以奏效,需要探索新型生產關系支撐的AI商業形態(如AI驅動的全鏈條商業體),通過重構數據采集與價值分配機制突破既有瓶頸。未來變數或將出現在數據確權、流通機制突破或特定領域的系統性數字化重構進程中。
5、斯坦福2025年AI指數報告
報告顯示,全球人工智能領域呈現加速發展態勢,中國在AI技術研發、應用落地及產業化方面取得顯著突破,與美國的技術差距持續縮小。在核心能力測試中,中美頂尖模型的性能差距已收窄至微小幅度,如MMLU測試僅差0.3個百分點,HumanEval差距降至3.7個百分點,中國科技企業阿里、字節、騰訊、智譜、DeepSeek組成的“國產五英杰”躋身全球頭部模型開發機構,阿里巴巴以年度發布6個知名模型位列全球第三。中國在學術研究和知識產權方面表現尤為突出,清華大學2023年高被引論文數量與谷歌并列全球第一,AI授權專利占全球總量的69.7%,論文產出占比達23.2%。產業應用方面,中國企業AI使用率同比增長27%,工業機器人部署量占全球半數以上,83%的公眾對AI持積極態度。技術發展呈現模型規模擴大化與小模型高效化并存趨勢,訓練GPT-4o級模型需38B算力且周期縮短至百天,而Phi-3-mini等小模型以3.8B參數實現接近GPT-3.5的性能,模型推理成本三年間下降超280倍。全球AI能力在多模態、代碼生成等領域取得突破,Swe-bench測試準確率從4.4%躍升至71.7%,但數據資源面臨枯竭風險,預計高質量網絡數據將在2026-2032年間耗盡,這將成為行業持續發展的關鍵挑戰。

6、普通人的AI學習資源2025
在2025年AI技術高速發展引發全民焦慮與信息噪音泛濫的背景下,普通人應主動篩選高質量學習資源以對抗“數字文盲”困境。作者指出當前AI科普被大廠壟斷、自媒體販賣焦慮的現象導致信息繭房加劇,呼吁通過系統性學習獲取真實知識而非被動接受碎片化內容,強調自由源于主動求知而非被動投喂。為此推薦兩條路徑:技術側聚焦如Anthropic、斯坦福等機構的前沿研究及Karpathy等專家的中立科普;商業側關注頭部投行、風投報告及YC孵化器動態以把握產業趨勢。文章同時復盤了作者去年對AI發展的預測(如視頻生成、AI陪伴等應用基本實現,但倫理立法滯后),揭示技術突破與商業落地、社會風險之間的核心矛盾,最終提出在“AI內容壓倒人類內容”的轉折點下,普通人需以批判性思維持續學習,才能避免被技術浪潮淘汰,在“噪音壓過真實”的時代實現認知突圍。






包涉及相關類對比詳解)

)


)




 指針-深淺copy)

)

