????????在當今大數據和分布式系統盛行的時代,消息隊列作為一種關鍵的中間件技術,發揮著舉足輕重的作用。其中,Apache Kafka 以其卓越的性能、高可擴展性和強大的功能,成為眾多企業構建分布式應用的首選消息隊列解決方案。本篇文章將帶你深入了解 Kafka 的基礎概念、架構原理、核心組件,并通過實際代碼示例,讓你快速上手 Kafka,揭開分布式消息隊列的神秘面紗。
一、Kafka 簡介與背景?
Kafka 最初是由 LinkedIn 公司開發,用于處理公司內部大規模的實時數據流。隨著其開源并在社區的不斷發展壯大,Kafka 已成為一款廣泛應用于大數據處理、實時流計算、日志收集與處理、系統解耦等眾多領域的分布式消息隊列系統。?
與傳統消息隊列相比,Kafka 具有顯著的優勢。它能夠支持超高的吞吐量,每秒可以處理數十萬甚至數百萬條消息,這使得它在應對海量數據傳輸時表現出色。同時,Kafka 具備低延遲的特性,消息的生產和消費延遲可以控制在毫秒級,滿足了許多對實時性要求極高的應用場景。此外,Kafka 的分布式架構設計使其具有強大的可擴展性,能夠輕松應對不斷增長的數據處理需求。
二、關鍵概念剖析?
2.1 生產者(Producer)?
生產者是 Kafka 系統中負責發送消息的組件。在實際應用中,生產者通常是由業務系統中的某個模塊或服務擔當,它將業務數據封裝成 Kafka 能夠識別的消息格式,并發送到指定的主題(Topic)中。?
以 Java 語言為例,以下是一個簡單的 Kafka 生產者代碼示例:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {// 設置生產者屬性Properties props = new Properties();// Kafka集群地址,格式為host1:port1,host2:port2,...props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 鍵的序列化方式,這里使用字符串序列化props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 值的序列化方式,同樣使用字符串序列化props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 創建生產者實例KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 要發送的消息內容String messageKey = "key1";String messageValue = "Hello, Kafka!";// 創建消息對象,指定主題和鍵值對ProducerRecord<String, String> record = new ProducerRecord<>("test - topic", messageKey, messageValue);try {// 發送消息并獲取響應RecordMetadata metadata = producer.send(record).get();System.out.println("Message sent successfully to partition " + metadata.partition() +" with offset " + metadata.offset());} catch (Exception e) {e.printStackTrace();} finally {// 關閉生產者,釋放資源producer.close();}}
}2.2 消費者(Consumer)?
消費者負責從 Kafka 主題中讀取消息并進行處理。Kafka 的消費者是以消費者組(Consumer Group)的形式存在的,同一消費者組內的消費者共同消費主題中的消息,通過負載均衡的方式提高消息處理的效率。不同消費者組之間相互獨立,每個消費者組都可以完整地消費主題中的所有消息。?
以下是一個 Java 語言的 Kafka 消費者代碼示例:
import org.apache.kafka.clients.consumer.*;
import java.util.Arrays;
import java.util.Properties;public class KafkaConsumerExample {public static void main(String[] args) {// 設置消費者屬性Properties props = new Properties();// Kafka集群地址props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 消費者組ID,同一組內的消費者共享消費偏移量props.put(ConsumerConfig.GROUP_ID_CONFIG, "test - group");// 鍵的反序列化方式,這里使用字符串反序列化props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 值的反序列化方式,同樣使用字符串反序列化props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 自動提交消費偏移量,默認true,建議設置為false,手動管理偏移量以確保數據不丟失props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");// 創建消費者實例KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 訂閱主題consumer.subscribe(Arrays.asList("test - topic"));try {while (true) {// 拉取消息,設置拉取超時時間為100毫秒ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.println("Received message: " +"topic = " + record.topic() +", partition = " + record.partition() +", offset = " + record.offset() +", key = " + record.key() +", value = " + record.value());}// 手動提交消費偏移量consumer.commitSync();}} catch (Exception e) {e.printStackTrace();} finally {// 關閉消費者,釋放資源consumer.close();}}
}2.3 主題(Topic)?
主題是 Kafka 中消息分類存儲的邏輯概念,類似于數據庫中的表。每個主題可以包含多個分區(Partition),生產者發送的消息會被存儲到指定的主題中,消費者則通過訂閱主題來獲取消息。在實際應用中,通常會根據不同的業務類型或數據類型創建不同的主題。例如,在一個電商系統中,可以創建 “order - topic” 用于存儲訂單相關的消息,“user - behavior - topic” 用于存儲用戶行為數據相關的消息等。?
2.4 分區(Partition)?
分區是 Kafka 實現高吞吐量和可擴展性的關鍵機制。每個主題可以被劃分為多個分區,這些分區分布在 Kafka 集群的不同 Broker 節點上。當生產者發送消息時,Kafka 會根據一定的策略將消息分配到主題的某個分區中。常見的分區策略有按消息鍵的 Hash 值分配(如果消息帶有鍵)和輪詢分配(如果消息沒有鍵)。?
分區的好處主要有以下幾點:首先,通過將數據分散存儲在多個分區上,可以提高數據存儲和讀取的并行度,從而提升整體的吞吐量。例如,在一個擁有多個 Broker 節點的集群中,每個 Broker 可以同時處理不同分區的讀寫請求,大大加快了數據處理速度。其次,分區還可以實現數據的冗余備份。Kafka 會為每個分區創建多個副本,其中一個副本作為領導者(Leader)副本,負責處理讀寫請求,其他副本作為跟隨者(Follower)副本,從領導者副本同步數據。當領導者副本所在的 Broker 節點發生故障時,Kafka 會自動從跟隨者副本中選舉出一個新的領導者副本,確保數據的可用性和一致性。
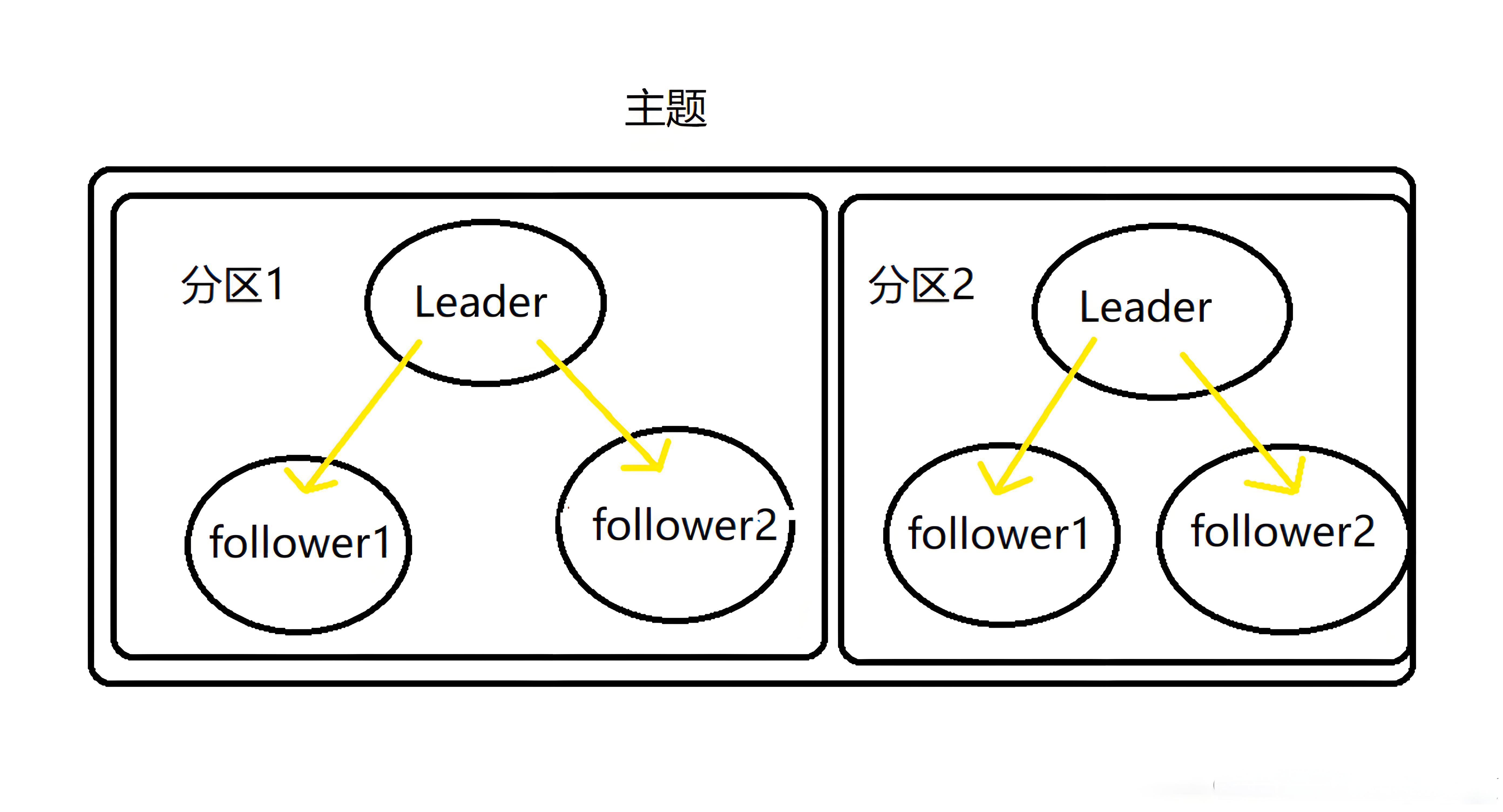
三、Kafka 集群架構?
Kafka 集群由多個 Broker 節點組成,每個 Broker 節點實際上就是一個 Kafka 服務器進程。這些 Broker 節點共同協作,實現了 Kafka 的分布式存儲和消息處理功能。?
在 Kafka 集群中,Zookeeper 扮演著至關重要的角色。Zookeeper 是一個分布式協調服務,它負責管理 Kafka 集群的元數據信息,包括 Broker 節點的注冊與發現、主題與分區的元數據管理、分區領導者副本的選舉等。具體來說,當一個新的 Broker 節點加入集群時,它會向 Zookeeper 注冊自己的信息,Zookeeper 會將這些信息同步給其他 Broker 節點,使得整個集群能夠感知到新節點的加入。在主題與分區管理方面,Zookeeper 存儲了每個主題的分區信息,包括分區的數量、每個分區的領導者副本和跟隨者副本所在的 Broker 節點等。當某個分區的領導者副本出現故障時,Zookeeper 會觸發領導者選舉過程,從跟隨者副本中選舉出一個新的領導者副本,確保分區的正常工作。
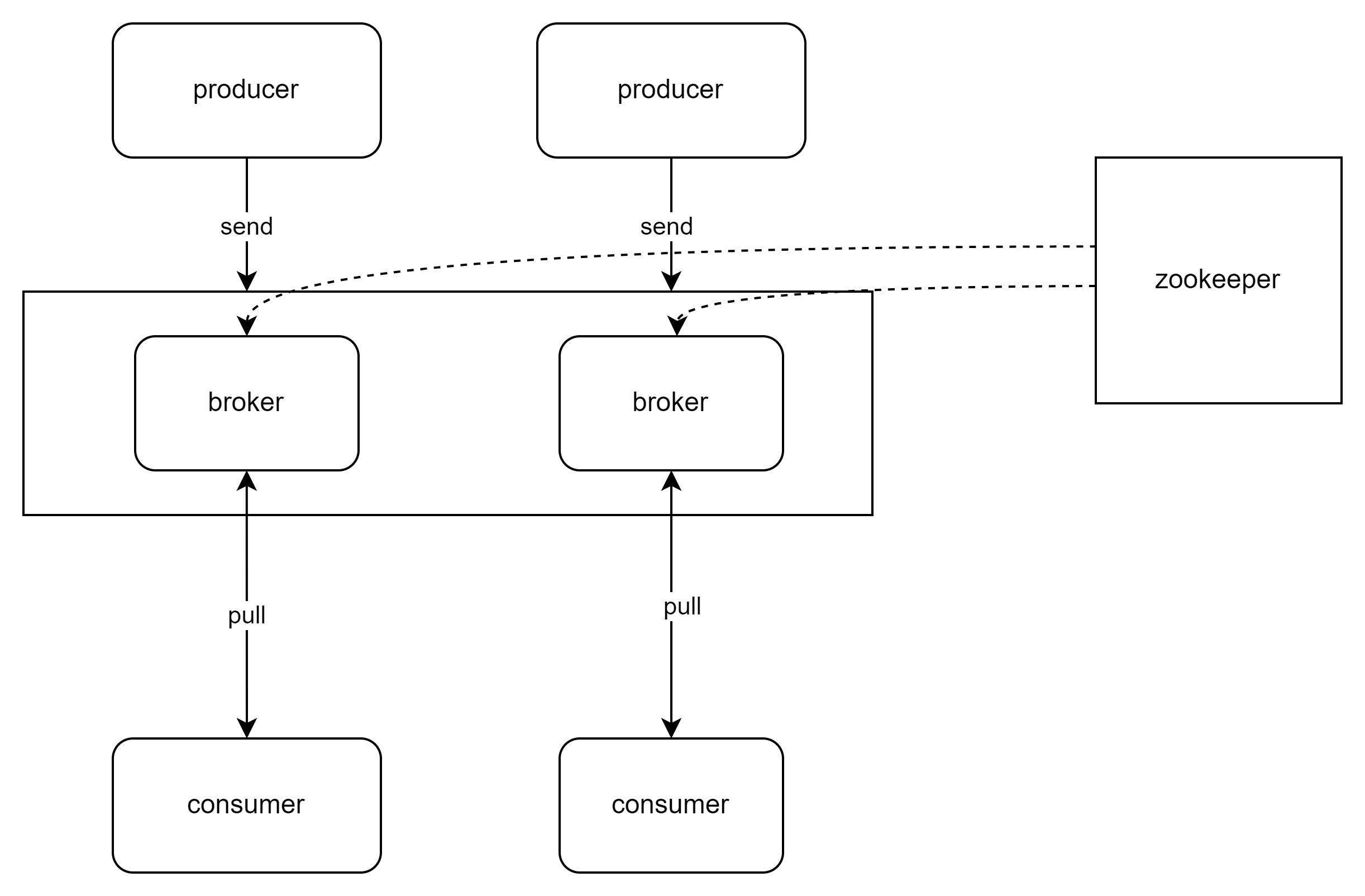
如上圖所示,Kafka 集群中的多個 Broker 節點通過 Zookeeper 進行協調和管理。生產者和消費者通過與 Broker 節點進行通信來發送和接收消息,而 Zookeeper 則在幕后負責維護集群的一致性和穩定性。
四、安裝與環境搭建?
4.1 下載 Kafka?
首先,從 Apache Kafka 官方網站(Apache Kafka)下載 Kafka 的安裝包。目前 Kafka 的最新版本可以在官網上找到,選擇適合自己操作系統的安裝包進行下載。例如,對于 Linux 系統,可以下載.tgz格式的壓縮包。?
4.2 解壓安裝包?
下載完成后,使用解壓命令將安裝包解壓到指定目錄。假設將安裝包下載到了/downloads目錄下,解壓命令如下:
tar -xzf kafka_2.13 - 3.3.1.tgz -C /usr/local/上述命令將 Kafka 安裝包解壓到了/usr/local/目錄下,解壓后的目錄名稱為kafka_2.13 - 3.3.1,其中2.13是 Scala 的版本號,3.3.1是 Kafka 的版本號。?
4.3 配置環境變量?
為了方便在命令行中使用 Kafka 的命令工具,需要將 Kafka 的bin目錄添加到系統的環境變量中。在 Linux 系統中,可以編輯~/.bashrc文件,在文件末尾添加以下行:
export PATH=$PATH:/usr/local/kafka_2.13 - 3.3.1/bin然后執行以下命令使環境變量生效:
source ~/.bashrc4.4 配置 Kafka?
Kafka 的主要配置文件位于其安裝目錄下的config文件夾中,其中最重要的配置文件是server.properties。在這個文件中,可以配置 Kafka 的各種參數,如 Kafka 監聽的端口、日志存儲路徑、連接 Zookeeper 的地址等。?
以下是一些常見的配置參數及說明:
# Kafka監聽的端口,默認9092
listeners=PLAINTEXT://localhost:9092
# 日志存儲路徑,可以配置多個路徑,用逗號分隔
log.dirs=/tmp/kafka - logs
# 連接Zookeeper的地址,格式為host1:port1,host2:port2,...
zookeeper.connect=localhost:2181
# 每個分區的副本因子,即每個分區有多少個副本,建議設置為大于1的奇數,以確保容錯
num.partitions=1
replica.fetch.max.bytes=10485764.5 啟動 Zookeeper 與 Kafka?
在完成 Kafka 配置后,需要先啟動 Zookeeper,因為 Kafka 依賴 Zookeeper 進行集群管理。在 Kafka 安裝目錄下,執行以下命令啟動 Zookeeper:
bin/zookeeper - server - start.sh config/zookeeper.properties上述命令會使用config/zookeeper.properties配置文件啟動 Zookeeper 服務。啟動成功后,終端會輸出一些啟動日志信息,顯示 Zookeeper 已正常運行并監聽在指定端口(默認為 2181)。?
接著,啟動 Kafka 服務,執行命令:
bin/kafka - server - start.sh config/server.properties此命令通過config/server.properties配置文件啟動 Kafka 服務器進程。啟動過程中,日志會顯示 Kafka 加載配置、注冊到 Zookeeper 等信息。當看到類似 “[KafkaServer id=0] started” 的日志時,表明 Kafka 已成功啟動。
4.6 使用 Kafka 命令行工具驗證安裝?
Kafka 提供了豐富的命令行工具,方便我們進行各種操作與驗證。例如,使用以下命令創建一個新的主題:
bin/kafka - topics.sh --create --bootstrap - servers localhost:9092 --replication - factor 1 --partitions 1 --topic new - topic參數說明:?
- --create:表示執行創建主題操作。?
- --bootstrap - servers localhost:9092:指定 Kafka 集群地址,這里是本地的 9092 端口。?
- --replication - factor 1:設置主題的副本因子為 1,即每個分區只有一個副本。在生產環境中,為了數據冗余與容錯,通常設置為大于 1 的奇數,如 3 或 5。?
- --partitions 1:指定主題的分區數量為 1。根據業務需求可調整,若業務數據量較大且對并行處理要求高,可設置多個分區。?
- --topic new - topic:指定要創建的主題名稱為new - topic。
創建成功后,可使用以下命令查看當前 Kafka 集群中的所有主題:
bin/kafka - topics.sh --list --bootstrap - servers localhost:9092該命令會列出所有已創建的主題名稱,若能看到剛剛創建的new - topic,則說明主題創建成功。?
還可以使用生產者和消費者命令行工具進行消息的發送與接收測試。首先,啟動一個生產者終端,執行命令:
bin/kafka - console - producer.sh --bootstrap - servers localhost:9092 --topic new - topic啟動后,終端會等待輸入消息。此時,輸入任意消息內容并回車,消息就會被發送到new - topic主題中。?
然后,在另一個終端啟動消費者,執行命令:
bin/kafka - console - consumer.sh --bootstrap - servers localhost:9092 --topic new - topic --from - beginning--from - beginning參數表示從主題的起始位置開始消費消息。
啟動消費者后,就能看到之前生產者發送的消息,這表明 Kafka 的基本功能正常,安裝與環境搭建成功。
通過這些命令行工具的操作,不僅驗證了安裝,也進一步熟悉了 Kafka 的基本使用方式。你將發現其在分布式消息處理領域的強大功能,無論是構建大規模數據處理系統,還是實現復雜業務系統的解耦與異步通信,Kafka 都能成為有力的技術支撐。


 指針-深淺copy)

)














)