人類正處在一個關鍵轉折點。自2012年起,基于深度神經網絡的人工智能系統研發進入快速通道,將這一技術推向了新高度:至2019年底,首個能夠撰寫與人類文章真假難辨的軟件系統問世,這個名為GPT-2(生成型預訓練變換模型2)的AI模型開啟了新紀元。2022年ChatGPT的發布標志著技術質變,它不僅革新了人機交互方式(推出5天即突破百萬用戶,2個月后活躍用戶過億),更展現出從文本生成、多語言翻譯到知識提煉的通用能力,迅速成為程序開發、教學科研領域的革命性工具。
ChatGPT現象級成功引發了對支撐技術——大型語言模型(LLM)的海量研究投入。在2023年,無論是科技巨頭推出的專有模型,還是開源社區發布的公共模型,都在功能表現上快速逼近甚至趕超ChatGPT。這場技術競賽使得語言人工智能領域(專注于開發理解與生成人類語言的智能系統)在短短一年間發生了根本性變革。
值得注意的是,盡管LLM主導了當前的研究版圖,但語言智能的疆域遠不止于此:各種輕量化模型依然保持著應用價值,而該領域數十年來積累的語義分析、知識圖譜等關鍵技術仍在持續演進。這種技術多樣性昭示著,在突破性創新與既有技術沉淀的相互作用中,語言人工智能正書寫著更宏大的篇章。
本書旨在幫助讀者建立對大型語言模型(LLMs)以及語言人工智能(Language AI)領域基礎知識的扎實理解。本章作為全書的框架,將介紹貫穿后續章節的核心概念與術語:
什么是語言人工智能?
術語“人工智能”(AI)通常用于描述致力于執行接近人類智能的任務的計算機系統,例如語音識別、語言翻譯和視覺感知。它是軟件的智能,而非人類的智能。
以下是由人工智能學科的創始人之一提出的一個更正式的定義:
[人工智能]是制造智能機器,特別是智能計算機程序的科學和工程學。這與使用計算機來理解人類智能的類似任務有關,但人工智能不必局限于生物學上可觀察到的方法。
-約翰?麥卡錫,20071
由于人工智能的不斷演變,這個術語被用來描述各種各樣的系統,其中一些可能并不真正體現智能行為。例如,電腦游戲中的角色(非玩家角色[NPCs])經常被稱為人工智能,盡管許多只是簡單的if-else語句。語言人工智能指的是人工智能的一個子領域,專注于開發能夠理解、處理和生成人類語言的技術。隨著機器學習方法在解決語言處理問題上的持續成功,"語言人工智能"這個術語通常可以與自然語言處理(NLP)互換使用。
1 J. McCarthy (2007). “What is artificial intelligence?” Retrieved from https://oreil.ly/C7sja and https://oreil.ly/ n9X8O.
我們使用“語言AI”這個術語來涵蓋那些技術上可能不是大型語言模型(LLM),但仍然對該領域產生重大影響的技術,例如檢索系統如何賦予LLM超能力(見第8章)。
在整本書中,我們希望關注在塑造語言AI領域中發揮重要作用的模型。這意味著不僅僅是孤立地探討LLM。然而,這引出了一個問題:什么是大型語言模型?為了在本章開始回答這個問題,讓我們首先探討語言AI的歷史。
語言人工智能的近代史
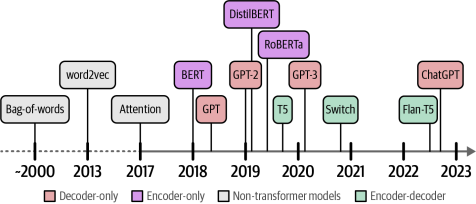
語言人工智能的歷史涵蓋了諸多旨在表示和生成語言的發展和模型,如圖1-1所示。
|
|
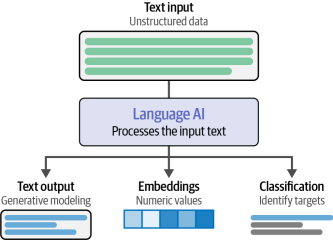
圖1-1窺探語言人工智能的歷史
然而,語言對計算機來說是一個棘手的概念。文本本質上是非結構化的,當用零和一(單個字符)表示時,它會失去意義。因此,在語言人工智能的歷史上,人們一直在努力以結構化的方式表示語言,以便計算機能夠更容易地使用它。這些語言人工智能任務的示例在圖1-2中提供。
|
|
圖1-2語言人工智能能夠通過處理文本輸入來執行許多任務。
將語言表示為詞袋模型
我們的語言人工智能歷史始于一種稱為詞袋的技術,這是一種表示非結構化文本的方法2。它在20世紀50年代左右首次被提及,但在21世紀初變得流行起來。
詞袋的工作原理如下:假設我們有兩個句子,我們想為它們創建數值表示。詞袋模型的第一步是分詞,即將句子拆分為單個單詞或子詞(詞元),如圖1-3所示。
|
|
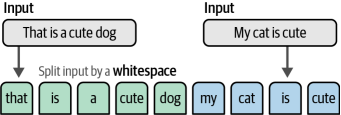
圖1-3每個句子通過空格分割成單詞(詞元)。
最常見的分詞方法是通過空格拆分來創建單個單詞。然而,這種方法有其缺點,因為有些語言,如普通話,并不在單個單詞周圍使用空格。在下一章中,我們將深入探討分詞以及該技術如何影響語言模型。如圖1-4所示,在分詞之后,我們合并每個句子中的所有獨特單詞以創建一個詞匯表,我們可以使用該詞匯表來表示句子。
2 Fabrizio Sebastiani. “Machine learning in automated text categorization.” ACM Computing Surveys (CSUR) 34.1 (2002): 1–47.
|
|
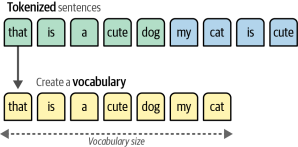
圖1-4語言人工智能能夠通過處理文本輸入來執行許多任務。
使用我們的詞匯表,我們簡單地計算每個句子中的單詞出現的頻率,字面上就是創建一個詞袋。因此,詞袋模型的目標是以數字(也稱為向量或向量表示)的形式創建文本的表示,如圖1-5所示。在整本書中,我們將這類模型稱為表示模型。
|
|

圖1-5通過計算單個單詞來創建詞袋模型,這些值被稱為向量表示。
盡管詞袋模型是一種經典方法,但它絕非完全過時。在第5章中,我們將探討如何將其仍然用于補充更近期的語言模型。
更好的密集向量嵌入表示
詞袋模型雖然是一種優雅的方法,但它有一個缺陷。它認為語言只不過是一個幾乎是字面上的詞袋,忽略了文本的語義本質或意義。
2013年發布的word2vec是最早成功捕捉文本嵌入意義的嘗試之一3。嵌入是數據的向量表示,試圖捕捉其意義。為此,word2vec通過在大量文本數據(如整個維基百科)上進行訓練來學習單詞的語義表示。
為了生成這些語義表示,word2vec利用神經網絡。這些網絡由相互連接的節點層組成,處理信息。如圖1-6所示,神經網絡可以有許多層,每個連接根據輸入具有一定的權重。這些權重通常被稱為模型的參數。
|
|
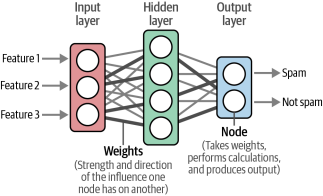
圖1-6?一個神經網絡由相互連接的節點層組成,其中每個連接都是一個線性方程
利用這些神經網絡,word2vec通過觀察哪些其他單詞傾向于在給定句子中出現在它們旁邊來生成詞嵌入。我們首先為詞匯表中的每個單詞分配一個向量嵌入,比如每個單詞初始化為50個隨機值的向量。然后,在每一個訓練步驟中,如圖1-7所示,我們從訓練數據中取出單詞對,模型嘗試預測它們是否可能在句子中成為鄰居。
3 Tomas Mikolov et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
在這個訓練過程中,word2vec 學習單詞之間的關系,并將這些信息提煉到嵌入中。如果兩個單詞傾向于有相同的鄰居,它們的嵌入將會彼此更接近,反之亦然。在第 2 章中,我們將更仔細地研究 word2vec 的訓練過程。
|
|

圖1-7.神經網絡被訓練用于預測兩個單詞是否為鄰居。在此過程中,嵌入(向量)會根據真實情況進行更新。
生成的嵌入捕捉了單詞的含義,但這到底意味著什么呢?為了說明這種現象,我們稍微簡化一下,假設我們有幾個單詞的嵌入,即“apple”(蘋果)和“baby”(嬰兒)。嵌入試圖通過表示單詞的屬性來捕捉含義。例如,“baby”這個詞可能在“新生兒”和“人類”這兩個屬性上得分很高,而“apple”這個詞在這兩個屬性上得分很低。
如圖1-8所示,嵌入可以有許多屬性來表示一個單詞的含義。由于嵌入的大小是固定的,因此選擇它們的屬性是為了創建單詞的心理表征。
|
|
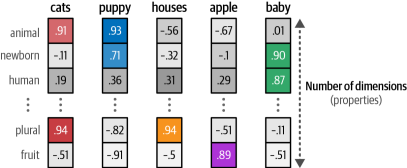
圖1-8?嵌入的值代表用于表示單詞的屬性。我們可能會過于簡化地想象維度代表概念(實際上它們并不代表),但這有助于表達這個想法。
在實踐中,這些屬性通常相當晦澀,很少與單個實體或人類可識別的概念相關聯。然而,這些屬性加在一起,對計算機來說就有意義,并且是將人類語言翻譯成計算機語言的好方法。
嵌入非常有用,因為它們讓我們能夠衡量兩個單詞之間的語義相似性。使用各種距離度量,我們可以判斷一個單詞與另一個單詞有多接近。如圖1-9所示,如果我們將這些嵌入壓縮成二維表示,你會注意到具有相似含義的單詞往往距離較近。在第5章中,我們將探討如何將這些嵌入壓縮成n維空間。
|
|
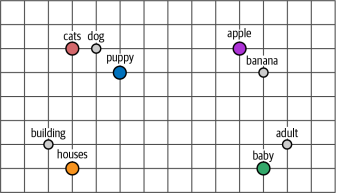
圖1-9?在維度空間中,相似單詞的嵌入將會彼此靠近。
嵌入類型
有許多類型的嵌入,如詞嵌入和句子嵌入,用于表示不同的抽象層次(詞與句子),如圖1-10所示。例如,詞袋模型在文檔級別創建嵌入,因為它表示整個文檔。相比之下,word2vec只為單詞生成嵌入。
在整本書中,嵌入將扮演一個核心角色,因為它們在許多用例中得到了應用,如分類(見第4章)、聚類(見第5章)以及語義搜索和檢索增強生成(見第8章)。在第2章中,我們將首次深入探討詞元嵌入。
|
|
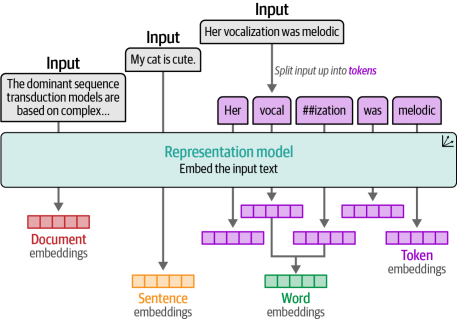
圖1-10?可以為不同類型的輸入創建嵌入
使用注意力機制進行上下文的編碼和解碼
word2vec的訓練過程創建了靜態的、可下載的單詞表示。例如,無論在什么上下文中使用,“bank”這個詞總是有相同的嵌入。然而,“bank”既可以指金融機構,也可以指河岸。其含義,因此其嵌入,應根據上下文而改變。
通過循環神經網絡(RNNs)實現了對這段文本編碼的一步。這些是神經網絡的變體,可以將序列作為額外的輸入進行建模。
為此,這些RNNs用于兩個任務,編碼或表示輸入句子和解碼或生成輸出句子。圖1-11通過展示像“I love llamas”這樣的句子如何被翻譯成荷蘭語“Ik hou van lama’s.”來說明這個概念。
|
|
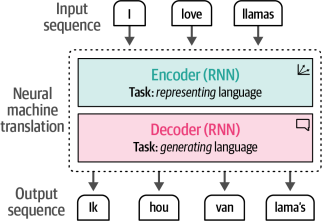
圖1-11?兩個遞歸神經網絡(解碼器和編碼器)轉換一個輸入從英語到荷蘭語的順序
這個體系結構中的每一步都是自回歸的。在生成下一個單詞時,此體系結構需?要消耗所有以前生成的單詞,如圖1-12所示。
|
|
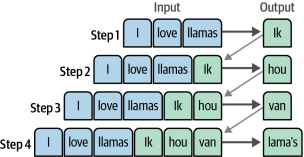
圖1-12?前面的每個輸出詞元都被用作生成下一個詞元的輸入
編碼步驟的目的是盡可能地表示輸入,以嵌入的形式生成上下文,嵌入作為解碼器的輸入。為了生成這種表示,它將嵌入作為單詞的輸入,這意味著我們可以使用word2vec作為初始表示。在圖1-13中,我們可以觀察到這個過程。注意輸入是如何按順序處理的,一次一個,以及輸出。
|
|
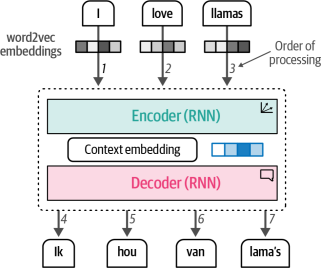
圖1-13?使用word2vec嵌入,生成一個上下文嵌入,代表整個序列
然而,這種上下文嵌入使得處理較長的句子變得困難,因為它僅僅是一個代表整個輸入的單個嵌入。在2014年,一種稱為“注意力”的解決方案被引入,它極大地改進了原始架構4。注意力允許模型專注于輸入序列中彼此相關的部分(“關注”彼此),并放大它們的信號,如圖1-14所示。注意力選擇性地確定哪些詞在給定句子中最為重要。
例如,輸出詞“lama's”是荷蘭語中的“llamas”,這就是為什么兩者之間的注意力很高。同樣,“lama's”和“I”之間的注意力較低,因為它們之間的關系不那么緊密。在第3章中,我們將更深入地探討注意力機制。
4 Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
|
|
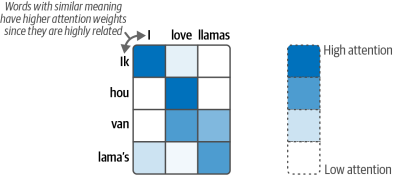
圖1-14?注意力允許模型“關注”序列中的某些部分,這些部分可能與彼此或多或少有關聯
通過在解碼器步驟中添加這些注意力機制,RNN可以為序列中的每個輸入詞生成與潛在輸出相關的信號。不是僅僅將上下文嵌入傳遞給解碼器,而是傳遞所有輸入詞的隱藏狀態。該過程在圖1-15中展示。
|
|

圖1-15 在生成了單詞“Ik”、“hou”和“van”之后,解碼器的注意力機制使其能夠在生成荷蘭語翻譯(“lama's”)之前專注于單詞“llamas”
因此,在生成“Ik hou van lama's”時,RNN會跟蹤它主要關注的單詞以執行翻譯。與word2vec相比,這種架構允許通過“關注”整個句子來表示文本的順序性和它出現的上下文。然而,這種順序性排除了在模型訓練期間進行并行化的可能性。
注意力是你所需要的
注意力的真正力量,以及驅動大型語言模型的驚人能力,首次在2017年發布的著名論文《注意力就是你所需的一切》中進行了探討5。作者提出了一種稱為Transformer的網絡架構,該架構完全基于注意力機制,并移除了我們之前看到的循環網絡。與循環網絡相比,Transformer可以并行訓練,這大大加快了訓練速度。在Transformer中,編碼器和解碼器組件堆疊在一起,如圖1-16所示。這種架構仍然是自回歸的,需要在創建新詞之前消耗每個生成的單詞。
|
|
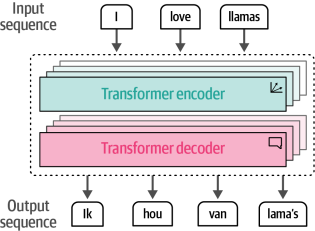
圖1-16.Transformer 是由堆疊的編碼器和解碼器模塊組成的,輸入會流經每個編碼器和解碼器。
現在,編碼器和解碼器模塊都將圍繞注意力機制展開,而不是利用帶有注意力特征的RNN。Transformer中的編碼器模塊由兩部分組成,自注意力和前饋神經網絡,如圖1-17所示。
5 Ashish Vaswani et al. “Attention is all you need.” Advances in Neural Information Processing Systems 30 (2017).
|
|
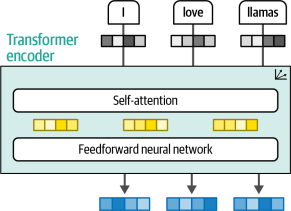
圖1-17?一個編碼器模塊圍繞自注意力來生成中間表示。
與之前的注意力方法相比,自注意力可以關注單個序列內的不同位置,從而更容易且更準確地表示輸入序列,如圖1-18所示。它不是處理一個詞元一次,而是可以一次性查看整個序列
|
|
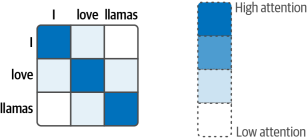
圖1-18.自注意力機制關注輸入序列的所有部分,使其能夠在單個序列中“向前看”和“向后看”。
與編碼器相比,解碼器有一個額外的層,它關注編碼器的輸出(以找到輸入的相關部分)。如圖1-19所示,這個過程與我們之前討論的RNN注意力解碼器類似。
|
|
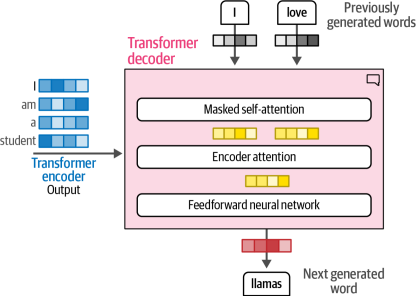
圖1-19?解碼器有一個額外的注意力層,用于關注編碼器的輸出
如圖1-20所示,解碼器中的自注意力層屏蔽了未來的位置,因此它只關注較早的位置,以防止在生成輸出時泄露信息。
|
|
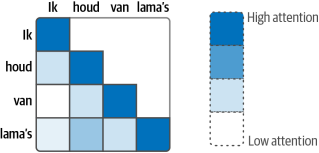
圖1-20?只關注前面的詞元以防止“預見未來”。
這些構建模塊共同構成了Transformer架構,并且是許多在語言AI中產生重大影響的模型的基礎,例如本章后面將要介紹的BERT和GPT-1。在整本書中,我們將使用的大多數模型都是基于Transformer的模型。
到目前為止,我們所探索的還只是Transformer架構的冰山一角。在第2章和第3章中,我們將探討Transformer模型為何如此有效的原因,包括多頭注意力、位置嵌入和層歸一化。
表示模型:僅編碼器的模型
原始的Transformer模型是一種編解碼器架構,非常適合翻譯任務,但不能輕易地用于其他任務,如文本分類。2018年,一種名為雙向Transformer表示(BERT)的新架構被引入,它可以用于廣泛的任務,并將成為未來幾年語言AI的基礎6。BERT是一種僅編碼器的架構,專注于表示語言,如圖1-21所示。這意味著它只使用編碼器,并完全去除解碼器。
|
|

圖1-21 具有12個編碼器的BERT基礎模型架構。
這些編碼器塊與我們之前看到的相同:自注意力之后是前饋神經網絡。輸入包含一個額外的詞元,即[CLS]或分類詞元,它被用作整個輸入的表示。通常,我們使用這個[CLS]詞元作為微調模型在特定任務(如分類)上的輸入嵌入。
6 Jacob Devlin et al. “BERT: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
訓練這些編碼器堆棧可能是一項困難的任務,BERT通過采用一種稱為掩碼語言建模的技術來解決這一問題(見第2章和第11章)。如圖1-22所示,這種方法會掩蓋輸入的一部分以供模型預測。這項預測任務雖然困難,但使得BERT能夠創建更準確的(中間)輸入表示。
|
|
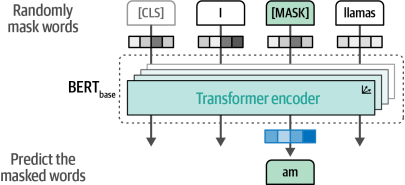
圖1-22 使用掩碼語言模型訓練BERT模型
這種架構和訓練程序使得BERT及相關架構在表示上下文語言方面表現非凡。類似BERT的模型通常用于遷移學習,這涉及首先對其進行語言建模預訓練,然后針對特定任務進行微調。例如,通過在維基百科的全部內容上訓練BERT,它學會了理解文本的語義和上下文特性。然后,如圖1-23所示,我們可以使用該預訓練模型針對特定任務(如文本分類)進行微調。
|
|
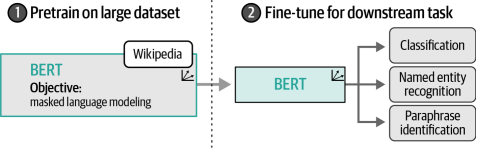
圖1-23?在BERT上預訓練了掩碼語言模型之后,我們針對特定任務對其進行微調。
預訓練模型的一個巨大優勢是大部分訓練已經為我們完成了。在特定任務上進行微調通常計算強度較小,且需要更少的數據。此外,類似BERT的模型在其架構的幾乎每個步驟都會生成嵌入。這也使得BERT模型成為特征提取機器,無需在特定任務上進行微調。
僅編碼器模型(如BERT)將在本書的許多部分中使用。多年來,它們一直被用于并在常見的任務中仍然被使用,包括分類任務(見第4章)、聚類任務(見第5章)和語義搜索(見第8章)。在整本書中,我們將僅編碼器模型稱為表示模型,以便將它們與僅解碼器模型區分開來,我們將僅解碼器模型稱為生成模型。請注意,主要區別不在于底層架構和這些模型的工作方式。表示模型主要關注表示語言,例如通過創建嵌入,并且通常不生成文本。相比之下,生成模型主要關注生成文本,并且通常不訓練生成嵌入。
表示模型和生成模型及其組件之間的區別也將在大多數圖像中顯示。表示模型以青色呈現,并帶有一個小的矢量圖標(以表示其對矢量和嵌入的關注),而生成模型以粉紅色呈現,并帶有一個小的聊天圖標(以表示其生成能力)。
生成模型:僅解碼器的模型
與BERT的僅編碼器架構類似,2018年提出了一種僅解碼器架構,用于針對生成任務7。這種架構被稱為生成預訓練變換器(GPT),因為其具有生成能力(現在稱為GPT-1,以便與后續版本區分)。如圖1-24所示,它堆疊了解碼器塊,類似于BERT的編碼器堆疊架構。
GPT-1在7,000本書的語料庫和Common Crawl(一個大型網頁數據集)上進行訓練。結果模型包含1.17億個參數。每個參數是一個數值,代表模型對語言的理解。如果一切保持不變,我們預計更多的參數將極大地影響語言模型的能力和性能。考慮到這一點,我們看到越來越大的模型以穩定的速度發布。如圖1-25所示,GPT-2擁有15億個參數8,緊接著GPT-3使用了1750億個參數9。
7 Alec Radford et al. “Improving language understanding by generative pre-training”, (2018).
?8 Alec Radford et al. “Language models are unsupervised multitask learners.” OpenAI Blog 1.8 (2019): 9.
?9 Tom Brown et al. “Language models are few-shot learners.” Advances in Neural Information Processing Systems 33 (2020): 1877–1901.
|
|
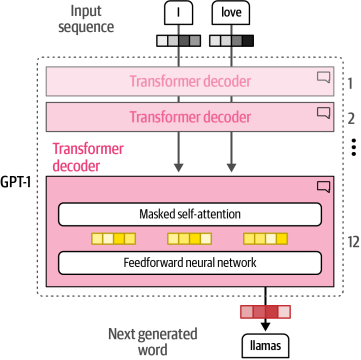
圖1-24?GPT-1的架構,它使用僅解碼器架構,并移除了編碼器注意力模塊。
|
|
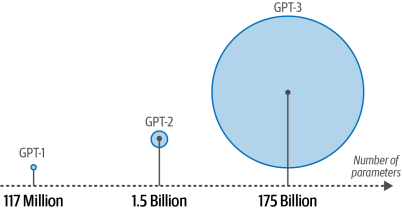
圖1-25?GPT模型在每次迭代中迅速變大
這些生成式僅解碼器模型,尤其是“較大”的模型,通常被稱為大型語言模型(LLMs)。正如我們將在本章后面討論的那樣,LLM這個術語不僅保留給生成式模型(解碼器-only),還保留給表示模型(編碼器-only)。
生成式LLMs作為序列到序列的機器,接收一些文本并嘗試將其補全。盡管這是一個方便的功能,但它們的真正力量來自于作為聊天機器人的訓練。如果它們可以被訓練來回答問題,而不僅僅是補全文本呢?通過對這些模型進行微調,我們可以創建能夠遵循指令的指導或聊天模型。
如圖1-26所示,所得模型可以接收用戶查詢(提示)并輸出最有可能跟隨該提示的響應。因此,您經常會聽到生成式模型被稱為補全模型。
|
|
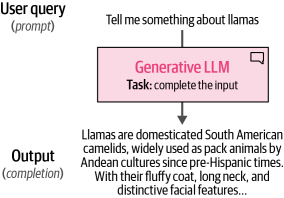
圖1-26. 生成式大型語言模型(LLMs)接收一些輸入并嘗試完成它。對于指令模型來說,這不僅僅是自動補全,而是試圖回答問題。
這些完成模型中的一個重要部分被稱為上下文長度或上下文窗口。上下文長度表示模型可以處理的最大詞元數,如圖1-27所示。較大的上下文窗口允許將整個文檔傳遞給LLM。請注意,由于這些模型的自回歸性質,當前上下文長度會隨著新詞元的生成而增加。
|
|
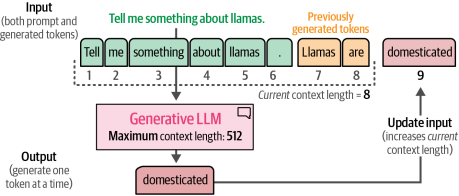
圖1-27?上下文長度是大型語言模型(LLM)可以處理的最大上下文。
生成式人工智能之年
大型語言模型(LLMs)對該領域產生了巨大影響,以至于有人稱2023年為生成式人工智能之年,這一稱號得益于ChatGPT(GPT-3.5)的發布、采用和媒體報道。當我們提到ChatGPT時,實際上是指產品而非底層模型。它首次發布時由GPT-3.5 LLM驅動,此后已發展到包括多個更高性能的變體,例如GPT-4.10。GPT-3.5并非生成式人工智能之年唯一產生影響的模型。如圖1-28所示,開源和專有LLMs都以驚人的速度走進了人們的生活。這些開源基礎模型通常被稱為基礎模型,可以針對特定任務(如遵循指令)進行微調。
10 OpenAI, “Gpt-4 technical report.” arXiv preprint arXiv:2303.08774 (2023). .
|
|
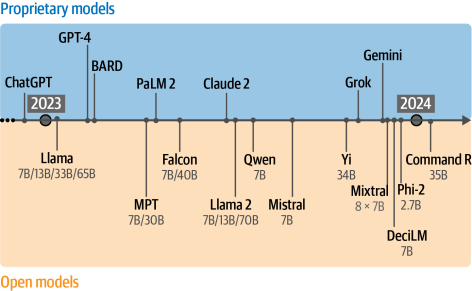
圖1-28?全面審視生成式人工智能的一年。請注意,這個概述中仍然缺少許多模型!
除了廣泛流行的Transformer架構外,還出現了諸如Mamba11,12和RWKV.13等有前景的新架構。這些新穎的架構試圖在具有額外優勢(如更大的上下文窗口或更快的推理速度)的情況下達到Transformer級別的性能。這些發展示例了該領域的演變,并展示了2023年作為AI真正繁忙的一年。我們竭盡全力才能跟上語言AI內部和外部的許多發展。因此,這本書探討的不僅僅是最新的LLM。我們將探討其他模型(如嵌入模型、僅編碼器模型,甚至詞袋模型)如何用來增強LLM。
11 Albert Gu and Tri Dao. “Mamba: Linear-time sequence modeling with selective state spaces.” arXiv preprint arXiv:2312.00752 (2023).
12 See “A Visual Guide to Mamba and State Space Models” for an illustrated and visual guide to Mamba as an alternative to the Transformer architecture.
13 Bo Peng et al. “RWKV: Reinventing RNNs for the transformer era.” arXiv preprint arXiv:2305.13048 (2023).
大型語言模型的動態定義
在我們對語言人工智能近期歷史的探索中,我們觀察到,主要是生成式解碼器-only(Transformer)模型通常被稱為大型語言模型。特別是當它們被認為是“大型”的時候。然而,在實踐中,這似乎是一個相當受限的描述!
如果我們創建一個與GPT-3具有相同功能但小10倍的模型會怎樣呢?這樣的模型會超出“大型”語言模型的分類嗎?
同樣,如果我們發布了一個和GPT-4一樣大,但只能進行準確文本分類而沒有生成能力的模型,它還會被認為是一個大型“語言模型”嗎?即使它仍然表示文本,但其主要功能不是語言生成。
這類定義的問題在于我們排除了有能力的模型。我們給一個模型或另一個模型起什么名字并不改變它的行為。
由于“大型語言模型”這個術語的定義隨著新模型的發布而不斷演變,我們想在這本書中明確它的含義。“大型”是任意的,今天可能被認為是大型模型的東西明天可能就是小型模型。目前對同一事物有很多名稱,對我們來說,“大型語言模型”也是那些不生成文本并可以在消費者硬件上運行的模型。
因此,除了涵蓋生成式模型外,這本書還將涵蓋參數少于10億且不生成文本的模型。我們將探討其他模型,如嵌入模型、表示模型,甚至詞袋模型如何用來增強LLMs。
大型語言模型的訓練范式
傳統的機器學習通常涉及為特定任務(如分類)訓練模型。如圖1-29所示,我們將其視為一個一步過程。
|
|

圖1-29?傳統的機器學習包括一個步驟:為特定目標任務(如分類或回歸)訓練模型
相比之下,創建大型語言模型(LLMs)通常至少包括兩個步驟:
語言建模
第一步,稱為預訓練,占據了大部分的計算和訓練時間。大型語言模型(LLM)在大量互聯網文本上進行訓練,使模型能夠學習語法、上下文和語言模式。這個廣泛的訓練階段還沒有針對特定任務或應用,僅僅是預測下一個單詞。訓練出的模型通常被稱為基礎模型或基本模型。這些模型通常不遵循指令。
微調
第二步,微調或有時稱為后期訓練,涉及使用先前訓練過的模型并在更狹窄的任務上進一步訓練它。這使大型語言模型(LLM)能夠適應特定任務或表現出期望的行為。例如,我們可以微調一個基礎模型,使其在分類任務上表現良好或遵循指令。這節省了大量資源,因為預訓練階段相當昂貴,通常需要數據和計算資源,這些資源對于大多數人和組織來說是難以承受的。例如,Llama 2 已經在包含 2 萬億詞元的數據集上進行了訓練14。想象一下創建該模型所需的計算量!在第 12 章中,我們將介紹幾種在您的數據集上微調基礎模型的方法。
任何經過第一步預訓練的模型,我們都認為是預訓練模型,這也包括微調后的模型。這種兩步訓練法在圖1-30中進行了可視化展示。
|
|
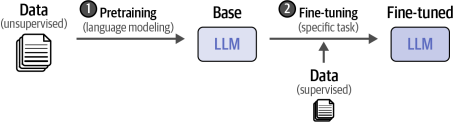
圖1-30 與傳統的機器學習相比,大型語言模型(LLM)訓練采用多步驟方法。
可以添加額外的微調步驟,以使模型與用戶的偏好進一步一致,我們將在第12章中探討。
14 Hugo Touvron et al. “Llama 2: Open foundation and fine-tuned chat models.” arXiv preprint arXiv:2307.09288 (2023).
大型語言模型應用:是什么讓它們如此有用?
大型語言模型(LLM)的性質使它們適用于廣泛的任務。通過文本生成和提示,它幾乎就好像你的想象力是極限。為了說明這一點,讓我們探索一些常見的任務和技術:
檢測顧客留下的評論是積極的還是消極的
這是(監督)分類,可以使用僅編碼器和僅解碼器模型來處理,既可以使用預訓練模型(見第4章),也可以通過微調模型(見第11章)。
開發一個用于查找票據問題中的常見主題的系統
這是(無監督)分類,我們沒有預定義的標簽。我們可以利用僅編碼器模型來執行分類本身,以及僅解碼器模型來詞元主題(見第5章)。
構建檢索和檢查相關文件的系統
語言模型系統的一個主要組成部分是它們添加外部信息資源的能力。使用語義搜索,我們可以構建系統,使我們能夠輕松訪問和查找信息供大型語言模型(LLM)使用(見第8章)。
通過創建或微調自定義嵌入模型來改進您的系統(見第12章)。構建能夠利用外部資源(如工具和文檔)的LLM聊天機器人
這是一種技術組合,展示了通過額外組件可以發現LLM的真正力量。諸如提示工程(見第6章)、檢索增強生成(見第8章)和微調LLM(見第12章)等方法都是LLM難題的一部分。
構建能夠根據展示冰箱中產品的圖片編寫食譜的LLM
這是一個多模態任務,LLM接收圖像并對其所看到的內容進行推理(見第9章)。LLM正在適應其他模態,如視覺,這開啟了廣泛有趣的用例。
大型語言模型(LLM)應用非常令人滿意,因為它們的部分邊界是由你的想象力所限定的。隨著這些模型變得越來越精確,在實踐中將它們用于創意用例,如角色扮演和編寫兒童書籍,就變得越來越有趣。
負責任的大語言模型開發與使用
大型語言模型(LLM)的影響已經而且可能繼續十分顯著,因為它們被廣泛采用。在我們探索LLM的驚人能力時,記住它們的社會和倫理影響很重要。有幾個關鍵點需要考慮:
偏見與公平性
大型語言模型(LLM)在訓練過程中使用了大量可能包含偏見的數據。LLM 可能會從這些偏見中學習,開始復制它們,并可能放大它們。由于 LLM 的訓練數據很少共享,除非嘗試使用它們,否則很難知道它們可能包含哪些潛在偏見。
透明度與問責制
由于 LLM 的強大能力,有時候很難判斷您是在與一個人還是與 LLM 交談。因此,在沒有人類參與的情況下,使用 LLM 與人類互動可能會產生意想不到的后果。例如,醫療領域使用的基于 LLM 的應用程序可能會被視為醫療器械進行監管,因為它們可能會影響患者的健康狀況。
生成有害內容
LLM 不一定會生成真實的內容,可能會自信地輸出錯誤的文本。此外,它們還可以用于生成假新聞、文章和其他誤導性的信息來源。
知識產權
LLM 的輸出是您的知識產權還是 LLM 創建者的知識產權?當輸出與訓練數據中的短語相似時,知識產權是否屬于該短語的作者?在沒有訪問訓練數據的情況下,很難知道 LLM 是否在使用受版權保護的材料。
監管
由于 LLM 的巨大影響,各國政府開始對商業應用進行監管。一個例子是歐洲人工智能法案,該法案規定了包括 LLM 在內的基礎模型的開發和部署。
在您開發和使用 LLM 時,我們想強調道德考慮的重要性,并敦促您了解更多關于安全和負責任地使用 LLM 和人工智能系統的信息。
你所需要的只有有限的資源
我們迄今為止多次提到的計算資源通常與您系統上可用的GPU(圖形處理器)有關。一個強大的GPU(顯卡)將使訓練和使用大型語言模型(LLM)更加高效和快速。
在選擇GPU時,一個重要組成部分是你擁有的VRAM(視頻隨機存取存儲器)數量。這指的是你的GPU上可用的內存量。實際上,你擁有的VRAM越多越好。原因是一些模型如果你沒有足夠的VRAM根本就無法使用。
因為訓練和微調LLMs可能是一個昂貴的過程,從GPU的角度來看,那些沒有強大GPU的人通常被稱為GPU-poor。這說明了為了訓練這些巨大的模型而進行的計算資源爭奪。例如,為了創建Llama 2系列模型,Meta使用了A100-80 GB GPU。假設租用這樣的GPU每小時需要1.50美元,那么創建這些模型的總成本將超過500萬美元!15
不幸的是,沒有一條單一的規則可以確定你為一個特定模型需要多少VRAM。這取決于模型的架構和大小、壓縮技術、上下文大小、運行模型的后端等。
這本書是為GPU-poor準備的!我們將使用用戶可以在沒有最昂貴的GPU或大預算的情況下運行的模型。為此,我們將在Google Colab實例中提供所有代碼。在撰寫本文時,Google Colab的一個免費實例將為你提供一個帶有16 GB VRAM的T4 GPU,這是我們建議的最低VRAM量。
與大型語言模型交互
與大型語言模型(LLM)進行交互不僅是使用它們的重要部分,也是理解其內部工作原理的關鍵。由于該領域的許多發展,已經出現了大量用于與LLM通信的技術、方法和軟件包。在整本書中,我們打算探討最常見的交互技術,包括使用專有的(閉源)和公開可用的開源模型。
專有,私有模型
閉源大型語言模型(LLMs)是指不公開其權重和架構的模型。它們由特定組織開發,底層代碼保密。此類模型的示例包括OpenAI的GPT-4和Anthropic的Claude。這些專有模型通常得到大量商業支持,并已在他們的服務中開發和集成。
15 The models were trained for 3,311,616 GPU hours, which refers to the amount of time it takes to train a model on a GPU, multiplied by the number of GPUs available..
你可以通過一個與LLM(大型語言模型)通信的接口來訪問這些模型,這個接口被稱為API(應用程序編程接口),如圖1-31所示。例如,要在Python中使用ChatGPT,你可以使用OpenAI的包來與該服務進行交互,而無需直接訪問它。
|
|
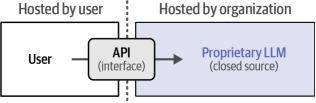
圖1-31?閉源LLM通過接口(API)進行訪問。因此,LLM本身的詳細信息,包括其代碼和架構,不會與用戶共享。
專有模型的一個巨大優勢是用戶不需要擁有強大的GPU就可以使用大型語言模型(LLM)。提供商負責托管和運行模型,并且通常擁有更多的計算資源。關于托管和使用模型,沒有必要具備專業知識,這大大降低了進入門檻。此外,由于這些組織的重大投資,這些模型往往比開源同行更具性能。
然而,這樣做的缺點是它可能是一項昂貴的服務。提供商管理托管LLM的風險和成本,這通常轉化為付費服務。此外,由于無法直接訪問模型,沒有辦法自己對其進行微調。最后,您的數據與提供商共享,這在許多常見用例中是不可取的,例如共享患者數據。
開放模型
開放大型語言模型(Open LLMs)是與公眾共享權重和架構的模型。它們仍然由特定組織開發,但通常會共享用于在本地創建或運行模型的代碼——這些代碼具有不同的許可級別,可能允許也可能不允許商業使用該模型。Cohere 的 Command R、Mistral 模型、微軟的 Phi 以及 Meta 的 Llama 模型都是開放模型的例子。
關于什么真正代表開源模型,目前仍在進行討論。例如,一些公開共享的模型具有寬松的商業許可證,這意味著該模型不能用于商業目的。對許多人來說,這不是開源的真正定義,開源的定義是使用這些模型不應有任何限制。同樣,模型訓練所用的數據以及其源代碼很少被共享。
你可以下載這些模型,并在你的設備上使用它們,只要你有一個強大的GPU,?可以處理這些類型的模型,如圖1-32所示。
|
|
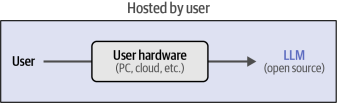
圖1-32?開源大型語言模型(LLM)直接由用戶使用。因此,包括其代碼和架構在內的LLM本身的詳細信息會與用戶共享。
這些本地模型的一個主要優勢是,作為用戶的您對模型擁有完全的控制權。您可以在不依賴API連接的情況下使用模型,對其進行微調,并通過它處理敏感數據。您不依賴于任何服務,并且對導致模型輸出的過程具有完全的透明度。這一優勢得到了諸如Hugging Face等大型社區的支持,這些社區展示了協作努力的可能性。
然而,一個缺點是您需要強大的硬件來運行這些模型,而在訓練或微調它們時更是如此。此外,設置和使用這些模型需要特定的知識(我們將在本書中詳細介紹)。
我們通常更喜歡使用開源模型,只要我們能做到。這種自由讓我們可以隨意嘗試各種選項,探索內部工作機制,并在本地使用模型,可以說比使用專有的大型語言模型(LLM)提供了更多的好處。
開源框架
與閉源LLM相比,開源LLM需要您使用某些包來運行它們。在2023年,發布了許多不同的包和框架,它們都以各自的方式與LLM互動并加以利用。在成百上千個可能有價值的框架中篩選并不是最愉快的體驗。
因此,您甚至可能會錯過本書中介紹的您最喜歡的框架!我們并不試圖涵蓋所有現有的LLM框架(太多,而且還在不斷增加),而是旨在為您提供一個利用LLM的堅實基礎。這樣,在閱讀本書后,您可以輕松掌握大多數其他框架,因為它們的工作方式都非常相似。
我們試圖實現的直覺是這一目標的重要組成部分。如果您不僅對LLM有直觀的理解,而且還在實踐中使用常見框架,那么擴展到其他框架應該是一項簡單的任務。
更具體地說,我們關注后端包。這些包沒有圖形用戶界面(GUI),旨在高效地加載和運行您的設備上的任何大型語言模型(LLM),例如llama.cpp、LangChain 以及許多框架的核心 Hugging Face Transformers。
我們主要將介紹通過代碼與大型語言模型交互的框架。盡管這些框架有助于你學習它們的基本原理,但有時你只是想要一個具有本地LLM的類似ChatGPT的界面。幸運的是,有許多出色的框架可以實現這一點。一些例子包括text-generation-webui、KoboldCpp和LM Studio。
生成第一個文本
使用語言模型的重要組成部分是選擇它們。尋找和下載大型語言模型(LLM)的主要來源是Hugging Face Hub。Hugging Face是著名的Transformers包背后的組織,該包多年來一直推動著語言模型的發展。顧名思義,該包是建立在我們在第5頁的“語言AI近期歷史”中討論的transformers框架之上的。
在撰寫本文時,您將在Hugging Face平臺上找到超過800,000個模型,用于許多不同的目的,從LLM和計算機視覺模型到處理音頻和表格數據的模型。在這里,您幾乎可以找到任何開源的LLM。
盡管我們將在整本書中探討各種模型,但讓我們從生成模型開始我們的第一行代碼。我們在整本書中使用的主要生成模型是Phi-3-mini,這是一個相對較小(38億參數)但相當高效的模型16。由于其小巧的尺寸,該模型可以在少于8 GB VRAM的設備上運行。如果您執行量化(一種我們將在第7章和第12章進一步討論的壓縮類型),您甚至可以使用少于6 GB的VRAM。此外,該模型采用MIT許可證授權,允許無限制地用于商業目的!
請記住,新的和改進的LLM會頻繁發布。為了確保本書保持最新,大多數示例都設計為可以與任何LLM一起使用。我們還會在與本書關聯的代碼倉庫中突出顯示不同的模型供您嘗試。
讓我們開始吧!當您使用LLM時,會加載兩個模型:
16 Marah Abdin et al. “Phi-3 technical report: A highly capable language model locally on your phone.” arXiv preprint arXiv:2404.14219 (2024).
? 生成模型本身
? 其底層的詞元器
分詞器負責在將輸入文本輸入生成模型之前將其拆分為詞元。您可以在Hugging Face網站上找到分詞器和模型,只需傳遞相應的ID即可。在這種情況下,我們使用“microsoft/Phi-3-mini-4k-instruct”作為模型的主要路徑。
我們可以使用transformers來加載分詞器和模型。請注意,我們假設您有一臺NVIDIA GPU(device_map="cuda"),但您也可以選擇其他設備。如果您無法使用GPU,可以使用我們在本書的存儲庫中提供的免費Google Colab筆記本:
from transformers import AutoModelForCausalLM, AutoTokenizer# Load model and tokenizermodel = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct",device_map="cuda",torch_dtype="auto",trust_remote_code=True,)tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")運行代碼將開始下載模型,根據您的互聯網連接可能需要幾分鐘的時間。
雖然我們現在已經有足夠的條件開始生成文本,但在transformers中有一個很好的技巧可以簡化這個過程,即transformers.pipeline。它將模型、分詞器和文本生成過程封裝到一個函數中:
from transformers import pipeline# Create a pipelinegenerator = pipeline("text-generation",model=model,tokenizer=tokenizer,return_full_text=False,max_new_tokens=500,do_sample=False)以下參數值得一提:
return_full_text
通過將此設置為False,將不會返回提示,而僅返回模型的輸出。
max_new_tokens
模型將生成的最大詞元數。通過設置限制,我們可以防止過長且笨重的輸出,因為某些模型可能會繼續生成輸出,直到達到其上下文窗口。
do_sample
模型是否使用采樣策略來選擇下一個詞元。通過將其設置為False,模型將始終選擇下一個最可能的詞元。在第6章中,我們探討了幾個采樣參數,這些參數在模型的輸出中引入了一些創造力。
要生成我們的第一個文本,讓我們指示模型講一個關于雞的笑話。為此,我們將提示格式化為一個字典列表,其中每個字典與對話中的一個實體相關。我們的角色是“用戶”,我們使用“content”鍵來定義我們的提示:
# The prompt (user input / query)messages = [{"role": "user", "content": "Create a funny joke about chickens."}]# Generate outputoutput = generator(messages)print(output[0]["generated_text"])Why don't chickens like to go to the gym? Because they can't crack the eggsistence of it!
就這樣!這本書中生成的第一個文本是一個關于雞的不錯笑話。
總結
在這本書的第一章中,我們深入探討了大型語言模型(LLM)對語言人工智能領域的革命性影響。它顯著改變了我們處理翻譯、分類、摘要等任務的方式。通過語言人工智能的近期歷史,我們探討了幾種類型的大型語言模型的基礎,從簡單的詞袋表示法到使用神經網絡的更復雜表示法。
我們討論了注意力機制作為在模型中編碼上下文的一步,這是使大型語言模型(LLM)如此強大的關鍵組成部分。我們涉及了使用這種驚人機制的兩大類模型:表示模型(僅編碼器)如BERT和生成模型(僅解碼器)如GPT系列模型。在這本書中,這兩類都被認為是大型語言模型。
總的來說,本章概述了語言AI領域的概況,包括其應用、社會和倫理影響以及運行這些模型所需的資源。我們最后使用Phi-3生成了我們第一段文本,這本書將貫穿使用這個模型。
在接下來的兩章中,您將了解一些基本過程。我們從第2章開始探討分詞和嵌入,這兩個部分常常被低估,但在語言AI領域至關重要。第3章將深入研究語言模型,您將發現用于生成文本的確切方法。










:回文日期)








