目錄
前言
一、pyquery 初始化
1.1 字符串初始化
1.2 URL 初始化
1.3 文件初始化
二、基本 CSS 選擇器
三、pyquery 查找節點
3.1 子節點
3.2 父節點
3.3 兄弟節點
四、遍歷
五、獲取信息
5.1 獲取屬性
5.2 獲取文本
六、節點操作
6.1 addClass 和 removeClass
6.2 attr、text、html
6.3 remove
七、偽類選擇器
前言
??????? 上兩節我們講了Beautiful Soup這個網頁解析庫,它確實很厲害。不過,大家用它的一些方法時,會不會感覺不太順手?還有它的CSS選擇器,用起來是不是覺得功能沒那么強呢?
????????要是你接觸過Web開發,平時習慣用CSS選擇器,或者對jQuery有一定了解,那我得給你介紹一個更稱手的解析庫,它就是pyquery。 下面,咱們就一起來見識下pyquery有多厲害。
一、pyquery 初始化
??????? 在正式開始前,得先確認你已經把pyquery正確安裝好了。要是還沒安裝,就得自己動手通過pip或pip3安裝一下。 和Beautiful Soup類似,初始化pyquery時,同樣要傳入HTML文本,以此來創建一個PyQuery對象。它有好幾種初始化的辦法,既可以直接傳入字符串,也能傳入URL,還能傳入文件名等等。接下來,我們就詳細講講這些方法。?
1.1 字符串初始化
????????咱們先通過一個實際例子來體驗體驗:
html = '''
<div><ul><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
for item in doc('li').items():print(item.outer_html())運行結果如下:

????????咱們先引入PyQuery對象,給它取個pq的別名。接著弄了個很長的HTML字符串,把這個字符串作為參數,傳給PyQuery類,這樣就完成了初始化。初始化完之后,再把得到的對象放到CSS選擇器里。在這個例子里,我們輸入li節點,這么一來,就能選中所有的li節點了 。?
1.2 URL 初始化
????????初始化時,參數不只能用字符串形式來傳遞。要是你想傳入網頁的URL,也完全沒問題,只要把參數指定為url就行 :?
from pyquery import PyQuery as pq
doc = pq(url='https://linshantang.blog.csdn.net/')
print(doc('title'))運行結果:
<title>攻城獅7號-CSDN博客</title>
????????這么操作后,PyQuery對象會先對這個URL發起請求。等拿到網頁的HTML內容,就用這些內容完成初始化。這和直接把網頁的源代碼,以字符串形式傳給PyQuery類來初始化,效果是一樣的 。?
??????? 它與下面的代碼功能是相同的:
from pyquery import PyQuery as pq
import requests
doc = pq(requests.get('https://linshantang.blog.csdn.net/').text)
print(doc('title'))1.3 文件初始化
????????當然啦,初始化的時候,除了能傳一個URL,要是你想傳本地的文件名也是可以的,只要把參數指定成filename就行:?
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
print(doc('li'))????????當然,得先有個本地的HTML文件,叫demo.html,里面的內容就是要解析的HTML字符串。這樣一來,它會先讀取這個本地文件里的內容,接著把文件內容當成字符串,傳給PyQuery類進行初始化。?
????????上面這3種初始化方法都能用,不過在實際使用中,最常用的初始化方式還是用字符串來傳遞 。?
二、基本 CSS 選擇器
????????咱們先通過一個實際例子,來體驗體驗pyquery里CSS選擇器該怎么用:
html = '''
<div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))
print(type(doc('#container .list li')))運行結果:

????????這里呢,我們先初始化了PyQuery對象,接著輸入了一個CSS選擇器#container .list li 。這個選擇器的意思是,先找到id是container的節點,再從這個節點里面,找到class是list的節點,最后把這個list節點里面所有的li節點選出來。然后我們把選出來的結果打印出來,能看到,確實成功找到了符合條件的節點。 最后呢,我們把選出來結果的類型也打印出來。可以看到,它還是PyQuery類型 。
三、pyquery 查找節點
????????接下來給大家講講一些常用的查詢方法,這些方法的使用方式跟jQuery里的方法一模一樣 。
3.1 子節點
????????要是想查找子節點,就得用find方法,這個方法的參數是CSS選擇器。咱們還是拿上面那個HTML做例子來說:?
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis)運行結果:
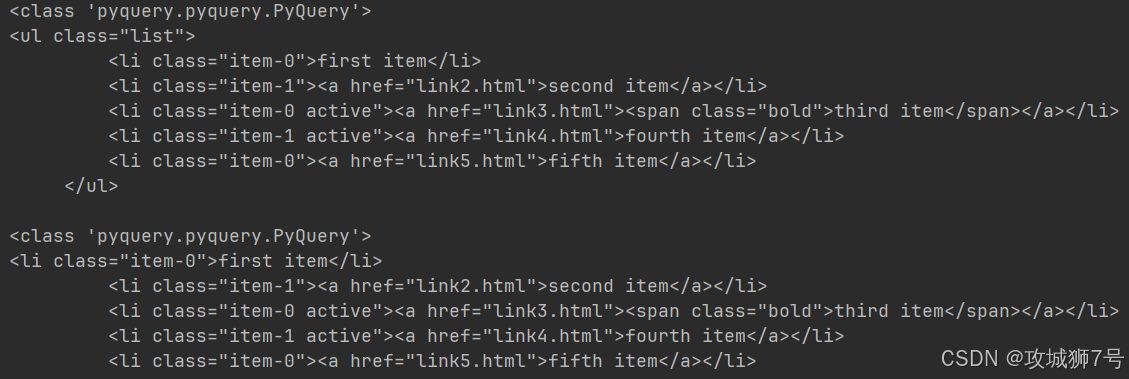
????????首先,我們選中class是list的節點,接著調用find()方法,把CSS選擇器作為參數傳進去,這樣就選中了這個節點里面的li節點,最后把結果打印出來。可以看到,find()方法會把所有符合條件的節點都選出來,選出來的結果是PyQuery類型。 實際上,find方法會在節點的所有子孫節點里查找。要是我們只想找子節點,那就可以用children方法。
lis = items.children()
print(type(lis))
print(lis)運行結果如下:

????????要是想從所有子節點里挑出符合條件的節點,就拿篩選出子節點里class是active的節點來說,可以給children()方法傳入CSS選擇器.active。?
lis = items.children('.active')
print(lis)運行結果:

????????從輸出結果能明顯看出,已經篩選過了,只剩下class是active的節點 。
3.2 父節點
????????我們可以用parent方法獲取某個節點的父節點,下面通過一個例子來看看效果:?
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)運行結果如下:
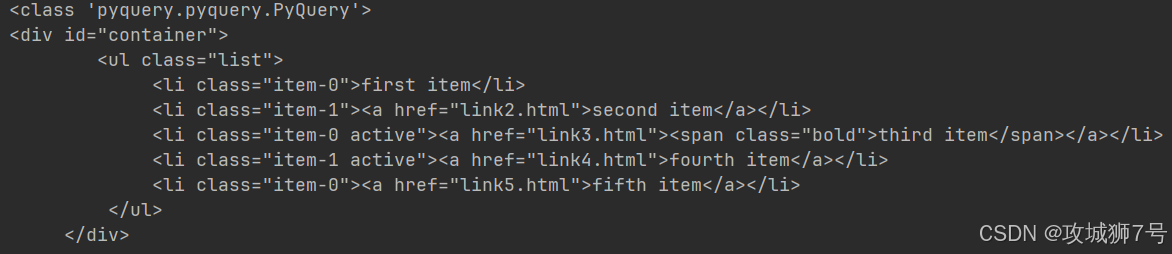
????????這里我們先用.list選中class是list的節點,接著調用parent方法,就能得到這個節點的父節點,這個父節點也是PyQuery類型。 這里得到的父節點是直接的父節點,不會再去查父節點的父節點,也就是不會找祖先節點。 要是想獲取某個祖先節點,該咋整呢?這時候就可以用parents方法。
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents)運行結果:
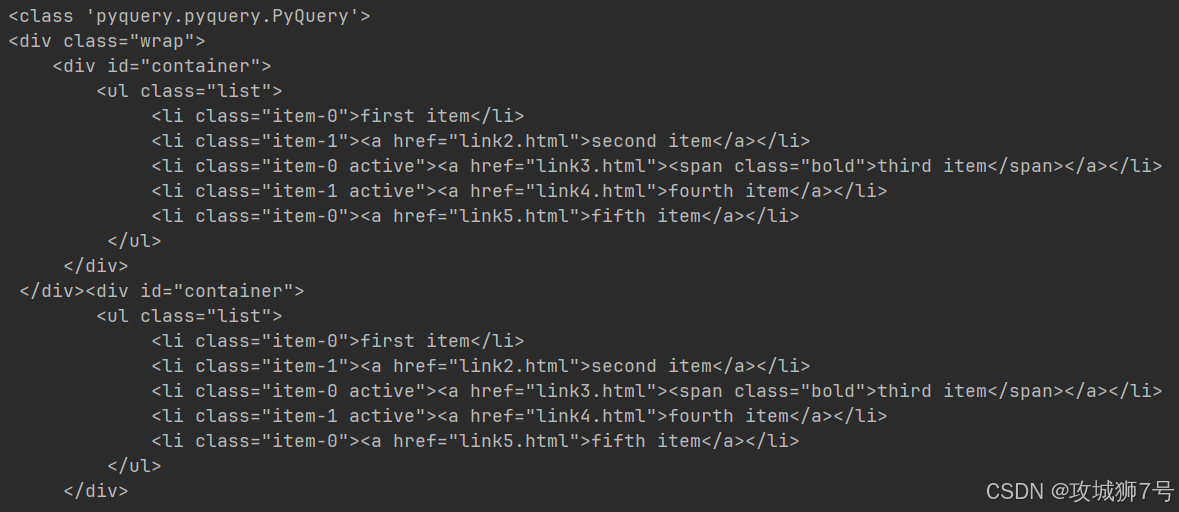
????????能看到,輸出結果有倆:一個是class為wrap的節點,另一個是id為container的節點。這說明,parents()方法會把所有的祖先節點都返回。 要是想篩選出某個祖先節點,就可以給parents方法傳入CSS選擇器,這樣就能得到祖先節點里符合這個CSS選擇器的節點。
parent = items.parents('.wrap')
print(parent)運行結果:
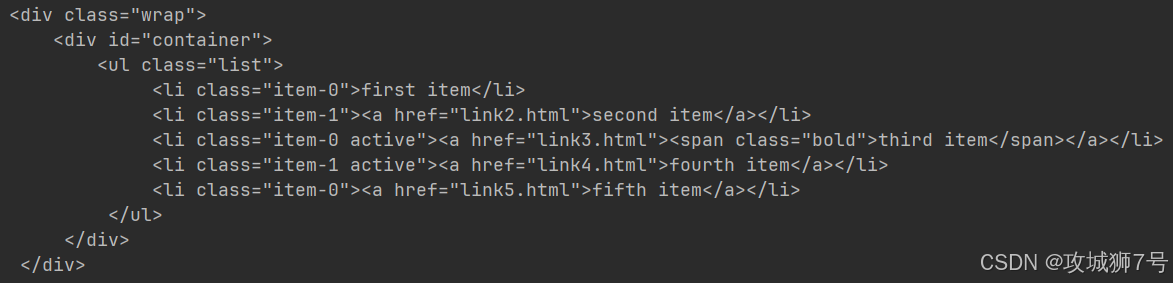
????????從輸出結果能明顯看出來,少了一個節點,現在只剩下class是wrap的那個節點了。
3.3 兄弟節點
??????? 上面我們講了子節點和父節點的用法,還有一種節點叫兄弟節點。要是想獲取兄弟節點,可以用siblings()方法。咱們還是接著用上面的HTML代碼來說明:?
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())????????這里先選中class是list的節點里面,class分別為item - 0和active的節點,也就是第三個li節點。顯然,它有4個兄弟節點,分別是第一個、第二個、第四個和第五個li節點。?
運行結果:

????????能看到,這就是我們剛才說的那4個兄弟節點。 要是想篩選出某個兄弟節點,還是可以給siblings方法傳入CSS選擇器,這樣就能從所有兄弟節點里挑出符合條件的節點。
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings('.active'))????????這里我們篩選了 class 為 active 的節點,通過剛才的結果可以觀察到,class 為 active 的兄弟節點只有第四個 li 節點,所以結果應該是一個。我們再看一下運行結果:
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
四、遍歷
????????剛才能看到,pyquery選擇出來的結果可能是多個節點,也可能是單個節點,但類型都是PyQuery類型,不會像Beautiful Soup那樣返回列表。 要是選出來的是單個節點,既可以直接打印,也能直接轉成字符串。
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(str(li))運行結果:

????????要是選擇結果有多個節點,就得通過遍歷來獲取每個節點。就像這里,要遍歷每個li節點的話,就得調用items方法。?
from pyquery import PyQuery as pq
doc = pq(html)
lis = doc('li').items()
print(type(lis))
for li in lis:print(li, type(li))運行結果如下:
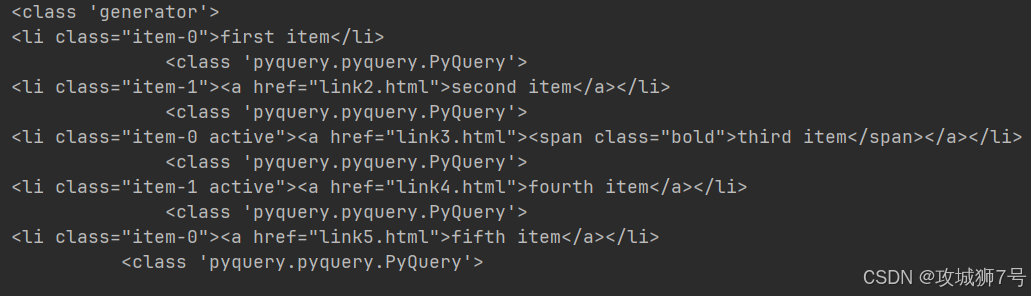
????????能發現,調用items()方法后會得到一個生成器,對這個生成器進行遍歷,就能逐個拿到li節點對象,這些對象也是PyQuery類型。每個li節點都能調用前面提到的方法來做選擇操作,像接著查找子節點、找某個祖先節點之類的,用起來很靈活。
五、獲取信息
????????把節點提取出來以后,我們的最終目標肯定是要提取出節點里包含的信息。其中比較關鍵的信息有兩種,一種是獲取節點的屬性,另一種是獲取節點的文本內容。下面我就分別給大家講一講。?
5.1 獲取屬性
當提取到一個PyQuery類型的節點后,就能調用attr()方法來獲取這個節點的屬性了。
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a, type(a))
print(a.attr('href'))運行結果如下:
<a href="link3.html"><span class="bold">third item</span></a> <class 'pyquery.pyquery.PyQuery'>
link3.html
????????這里先選中class是item - 0和active的li節點里面的a節點,這個節點是PyQuery類型。 接著調用attr方法,在方法里傳入屬性名,就能得到對應的屬性值。 另外,也能通過調用attr屬性來獲取屬性,具體用法如下:?
print(a.attr.href)??????? 這兩種方法得到的結果是完全相同的。 要是選中了多個元素,再去調用attr方法,會得到什么樣的結果呢?下面我們通過實際例子來測試看看。
a = doc('a')
print(a, type(a))
print(a.attr('href'))
print(a.attr.href)運行結果如下:

????????按道理,我們選中的a節點應該有4個,打印結果也該是4個。但調用attr方法時,返回的卻只有第一個節點的屬性。這是因為,當返回結果包含多個節點時,調用attr方法只能得到第一個節點的屬性。 要是遇到這種情況,想獲取所有a節點的屬性,就得用前面說過的遍歷方法了。?
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('a')
for item in a.items():print(item.attr('href'))運行結果:
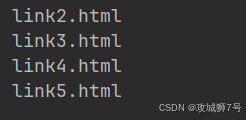
????????所以,在獲取屬性的時候,要先看返回的節點是一個還是多個。要是返回多個節點,就得通過遍歷才能逐個獲取每個節點的屬性。?
5.2 獲取文本
????????提取到節點后,另一個重要操作就是獲取其內部的文本內容,這時調用text方法就能達成這一目的。?
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())運行結果:

????????這里先選中一個a節點,接著調用text方法,就能獲取該節點內部的文本信息。這時它會把節點內部的所有HTML內容忽略掉,只返回純文本。 不過要是想獲取這個節點內部的HTML文本,那就得使用html方法了。
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.html())????????這里我們選定了第三個li節點,隨后調用了html()方法。該方法返回的結果會是這個li節點內包含的所有HTML文本內容。?
運行結果:

????????這里存在一個疑問,如果我們選中的結果包含多個節點,那么調用 text() 或 html() 方法會返回什么樣的內容呢?下面我們通過實際例子來探究一下。
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('li')
print(li.html())
print(li.text())
print(type(li.text()))
運行結果如下:

????????結果可能有點讓人意外,html方法返回的是第一個li節點內部的HTML文本,而text方法返回的是所有li節點內部的純文本,各文本間用一個空格分隔,也就是返回一個字符串。 所以這里要特別留意,如果得到的結果是多個節點,還想獲取每個節點內部的HTML文本,那就需要對每個節點進行遍歷。而text()方法不用遍歷就能獲取文本,它會把所有節點的文本提取出來并合并成一個字符串。
六、節點操作
????????pyquery提供了一系列可對節點進行動態修改的方法,像給某個節點添加一個class,或者移除某個節點等。這些操作有時能為信息提取帶來極大便利。 鑒于節點操作的方法眾多,下面我會列舉幾個典型例子來說明其用法。
6.1 addClass 和 removeClass
????????那咱們先通過一個具體的實例來體驗一番:
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)????????先是選中了第三個li節點,接著調用removeClass()方法,把li節點上的active這個class給去掉了,之后又調用了addClass()方法,再把這個class添加回來。每次執行完一次操作,就把當前li節點的內容打印輸出。 運行后得到的結果如下:

????????從結果能看到,總共輸出了3次。在第二次輸出的時候,li節點的active這個class已經被移除掉了,而到第三次輸出時,這個class又被重新添加回來了。 由此可見,addClass和removeClass這兩個方法是能夠對節點的class屬性進行動態修改的。
6.2 attr、text、html
????????當然,除了對 class 屬性進行操作外,還能使用 attr 方法操作其他屬性。另外,也可借助 text 和 html 方法來改變節點內部的內容。下面是相關示例:?
html = '''
<ul class="list"><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
</ul>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.text('changed item')
print(li)
li.html('<span>changed item</span>')
print(li)????????這里我們先選中了li節點,之后調用attr方法修改屬性。attr方法的第一個參數是屬性名,第二個參數是屬性值。接著,我們又調用text和html方法來改變節點內部的內容。每次操作完成后,都會打印輸出當前的li節點。 下面是運行結果:

????????可以看出,調用attr方法后,li節點新增了一個原本不存在的屬性“name”,其值為“link”。隨后調用text方法并傳入文本,li節點內部的文本就都變成了傳入的字符串文本。最后,調用html方法并傳入HTML文本,li節點內部又變成了傳入的HTML文本。 由此可知,attr方法若只傳入第一個參數即屬性名,是用于獲取該屬性值;若傳入第二個參數,則可用來修改屬性值。text和html方法若不傳入參數,分別是獲取節點內的純文本和HTML文本;若傳入參數,則是進行賦值操作。
6.3 remove
????????從名字就能知道,remove 方法的作用是移除節點,在某些情況下,它能極大地便利信息提取。下面給出一段 HTML 文本,咱們接著分析它的應用。?
html = '''
<div class="wrap">Hello, World<p>This is a paragraph.</p></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())????????現在你想提取“Hello, World”這個字符串,同時排除 p 節點內部的字符串,該怎么做呢? 這里直接先試著提取 class 為 wrap 的節點的內容,看看是否是我們想要的結果。下面是運行結果:?
?
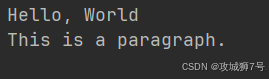
?
????????從這個結果能看出,它還包含了內部 p 節點的內容,也就是說 text 方法把所有純文本都提取出來了。若想去掉 p 節點內部的文本,一種做法是先提取 p 節點內的文本,再從整個結果里移除這個子串,但這種做法顯然比較繁瑣。 這時就可以發揮 remove 方法的作用了,我們可以接著這樣操作:?
wrap.find('p').remove()
print(wrap.text())????????首先我們選中 p 節點,接著調用 remove() 方法把它移除掉。此時,wrap 節點內部就只剩下“Hello, World”這句話了,之后利用 text() 方法就能把它提取出來。 此外,實際上還有不少節點操作的方法,像 append()、empty() 和 prepend() 等,這些方法的用法和 jQuery 完全相同。若想了解詳細用法,可以參考官方文檔:[http://pyquery.readthedocs.io/en/latest/api.html](http://pyquery.readthedocs.io/en/latest/api.html)?
?
七、偽類選擇器
?
????????CSS 選擇器如此強大,一個重要原因是它支持豐富多樣的偽類選擇器。這些偽類選擇器能實現很多特殊的選擇功能,比如選擇第一個節點、最后一個節點、奇偶數節點,以及包含特定文本的節點等。下面通過示例來具體說明:?
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('li:first-child')
print(li)
li = doc('li:last-child')
print(li)
li = doc('li:nth-child(2)')
print(li)
li = doc('li:gt(2)')
print(li)
li = doc('li:nth-child(2n)')
print(li)
li = doc('li:contains(second)')
print(li)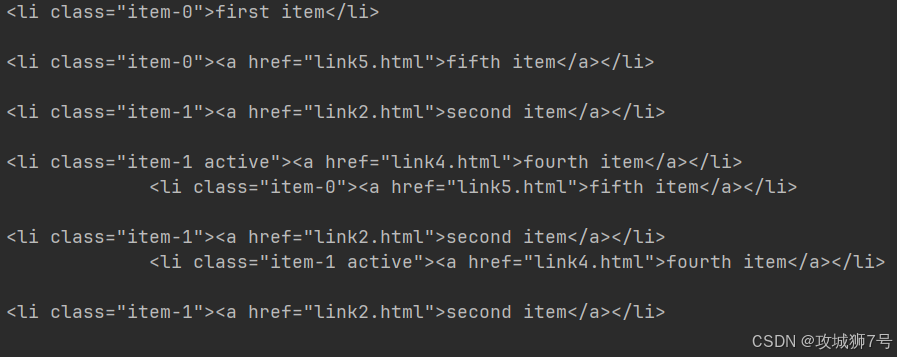
?????????在這個示例里,我們運用了 CSS3 的偽類選擇器,分別選中了第一個 li 節點、最后一個 li 節點、第二個 li 節點、第三個 li 節點之后的所有 li 節點、偶數位置的 li 節點,以及包含“second”文本的 li 節點。 若你想了解 CSS 選擇器更多的用法,可以參考 [http://www.w3school.com.cn/css/index.asp](http://www.w3school.com.cn/css/index.asp)。?
????????至此,pyquery 的常用用法就介紹完畢了。要是你還想了解更多內容,可查閱 pyquery 的官方文檔:[http://pyquery.readthedocs.io](http://pyquery.readthedocs.io)。我們相信,有了 pyquery 的助力,網頁解析將不再困難。?
?
學習參考書籍:Python 3網絡爬蟲開發實戰
?









)






_39)


