什么是QwQ-32B?
QwQ-32B并非普通的聊天機器人模型,而是推理模型。推理模型專注于邏輯拆解問題、分步推導,并輸出結構化答案。
通過下面的示例,我們可以直觀看到QwQ-32B的思考過程:
qwq-32b思考過程
如果你需要寫作輔助、頭腦風暴或內容總結,它并不是最佳選擇。但如果你需要解決技術難題、驗證多步驟解決方案,或在科研、金融、軟件開發等領域尋求幫助,QwQ-32B適用于這類結構化推理任務,尤其需要AI處理邏輯工作流的工程師、研究人員和開發者。
這里還有一個行業趨勢值得關注:類似小型語言模型(SLM)的興起,QwQ-32B或許正預示著“小型推理模型”的誕生。
QwQ-32B架構設計
QwQ-32B專為復雜問題推理而構建,不同于僅依賴預訓練和微調的傳統AI模型,它融入了強化學習(RL),通過“試錯學習”不斷優化推理能力。
這種訓練方法在AI領域漸成趨勢,DeepSeek-R1等模型正是通過多階段強化學習訓練,實現了更強的推理能力。
強化學習如何提升AI推理?
大多數語言模型通過預測句子中下一個詞來學習海量文本數據,這種方式雖能保證表達流暢,卻不擅長解決問題。強化學習引入反饋機制:模型不再僅生成文本,而是因找到正確答案或遵循正確推理路徑獲得獎勵。長期訓練后,AI在處理數學、編程、邏輯推理等復雜問題時,會形成更精準的判斷能力。
QwQ-32B更進一步,集成了代理相關能力,可根據環境反饋調整推理過程。這意味著模型不再局限于記憶模式,而是能動態使用工具、驗證輸出并優化回答。這些改進讓它在僅靠詞語預測無法勝任的結構化推理任務中表現更佳。
更小模型,更智能訓練
QwQ-32B最大亮點是效率。盡管只有320億參數,性能不比6710億參數(激活參數370億)的DeepSeek-R1差。這表明,強化學習的規模化應用與模型擴容同樣重要。另一亮點是支持131,072token的上下文窗口,支持處理和記憶長文本信息。
QwQ-32B基準測試
QwQ-32B在對標其他推理模型,基準測試結果顯示,盡管參數規模小,性能卻接近DeepSeek-R1。模型在數學、編程和結構化推理等多項基準測試中,表現與DeepSeek-R1持平或接近。
qwq-32b基準測試數據(此處保留原文表格,需根據實際內容補充)
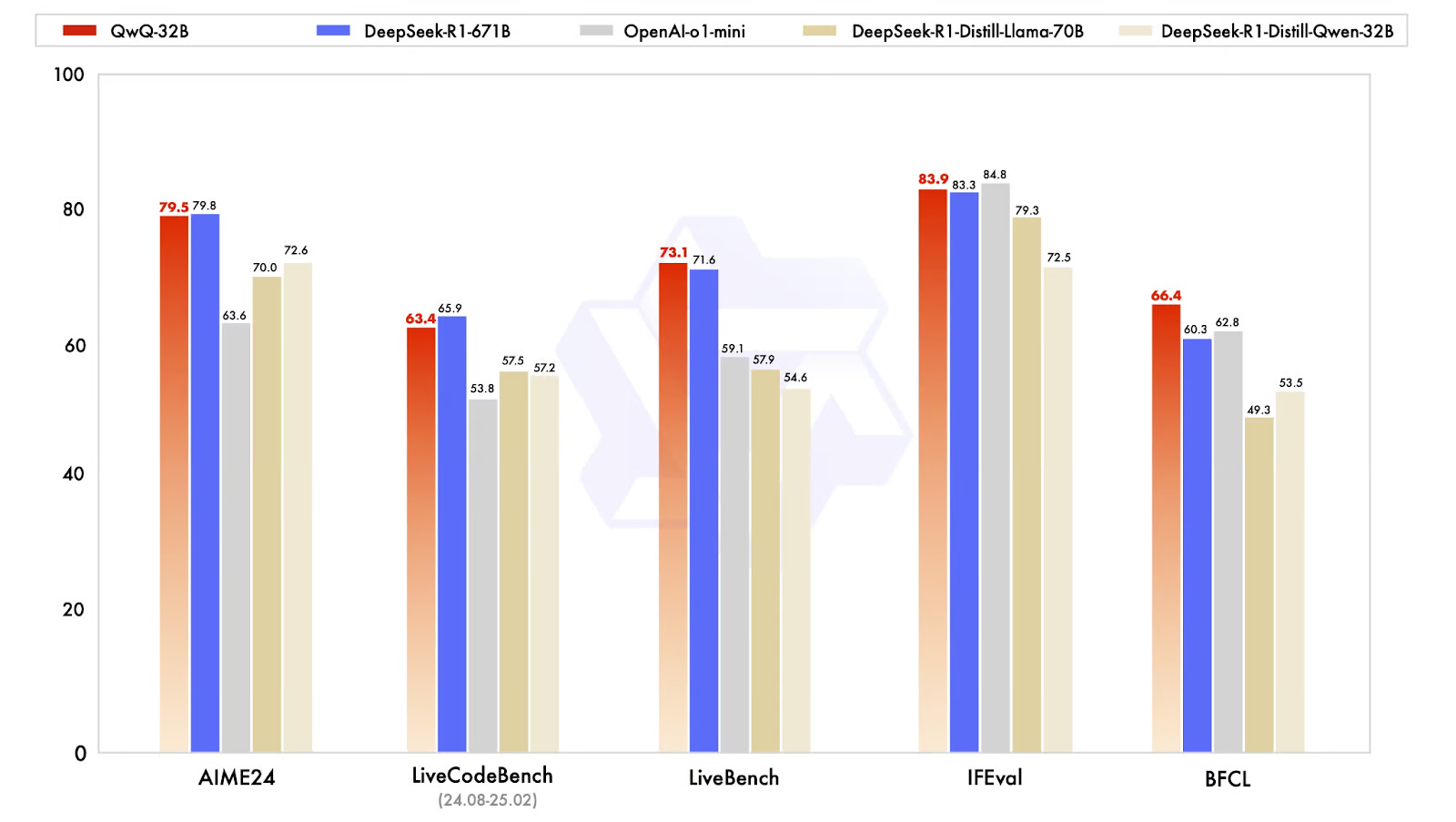
數學與邏輯推理優勢
數學基準測試AIME24:QwQ-32B得分79.5,略低于DeepSeek-R1的79.8,超過OpenAI的o1-mini(63.6)和DeepSeek蒸餾模型(70.0–72.6)。另一項IFEval基準測試中,QwQ-32B得分83.9,小幅超越DeepSeek-R1,僅以微弱差距落后o1-mini(84.8)。
對于輔助軟件開發的AI模型,在編程基準測試LiveCodeBench中,QwQ-32B得分63.4,略低于DeepSeek-R1的65.9,高于o1-mini的53.8。這表明強化學習提升了模型在編程問題中迭代推理的能力,而非僅生成單次解決方案。
如何使用QwQ-32B?
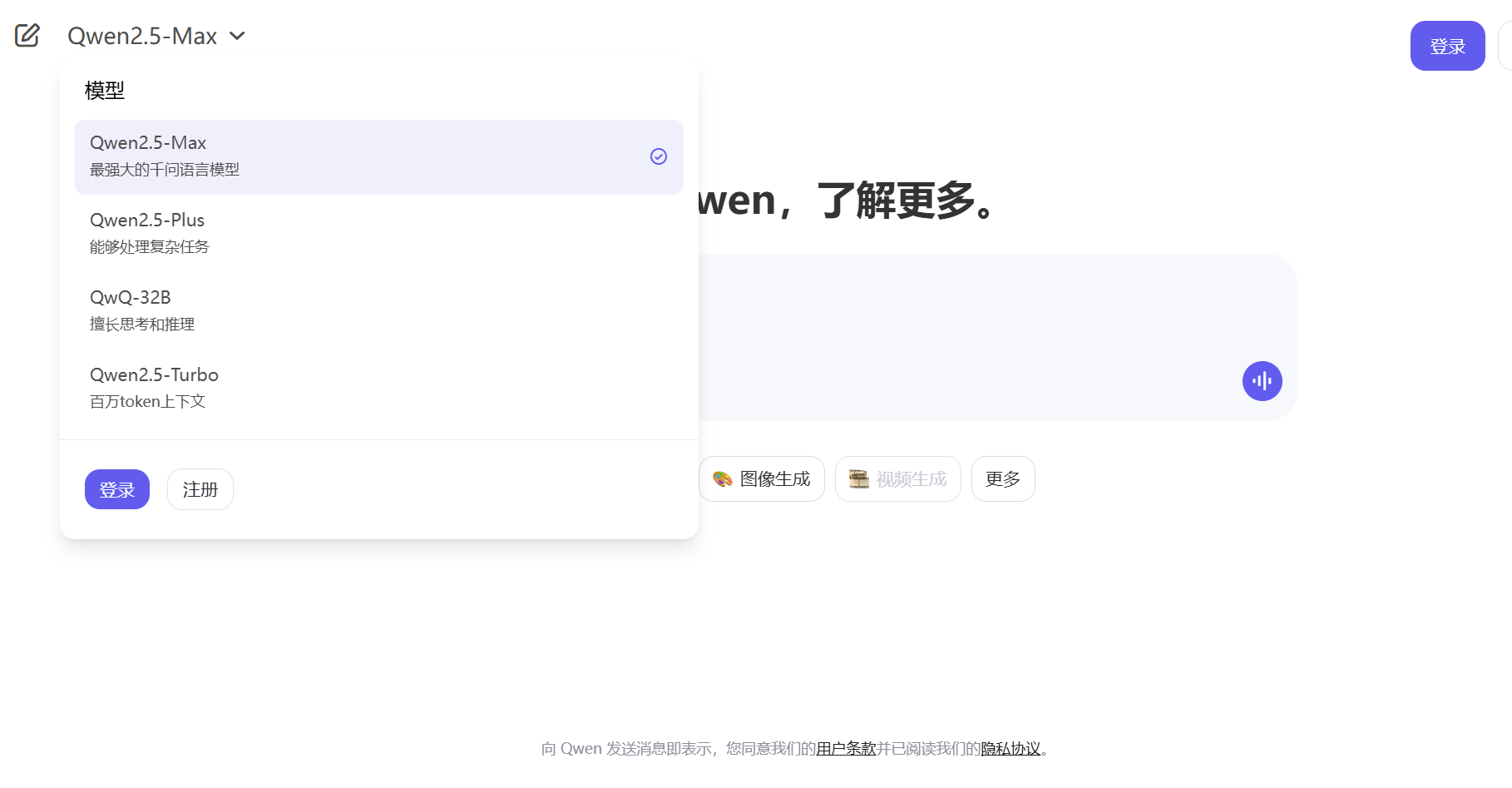
QwQ-32B完全開源,在線體驗QwQ-32B,無需任何部署,通過通義聊天(Qwen Chat)即可輕松體驗。網頁版支持測試模型的推理、數學和編程能力。訪問Qwen Chat注冊賬號,在模型選擇菜單中選中QwQ-32B。 默認啟用“思考(QwQ)模式”,無需手動開啟,直接在聊天框輸入提示詞即可。
從Hugging Face和ModelScope下載部署:開發者若想將QwQ-32B集成到自有工作流,可從Hugging Face或ModelScope平臺下載。這些平臺提供模型權重、配置文件和推理工具,便于科研或生產環境部署。




)






_39)







