【深度學習】【目標檢測】【Ultralytics-YOLO系列】YOLOV3源碼整體結構解析
文章目錄
- 【深度學習】【目標檢測】【Ultralytics-YOLO系列】YOLOV3源碼整體結構解析
- 前言
- 代碼結構整體
- data文件結構
- 模型訓練超參數配置文件解析
- 數據集配置文件解析
- models文件結構
- utils文件結構
- runs文件結構
- 總結
前言
Ultralytics YOLO 是一系列基于 YOLO(You Only Look Once)算法的檢測、分割、分類、跟蹤和姿勢估計模型,此前博主已經搭建完成紹Ultralytics–YOLOv人臉檢測項目【Windows11下YOLOV3人臉檢測】,本博文解析Ultralytics–YOLOV3源碼的整體結構。
代碼結構整體
核心結構部分如下圖所示:
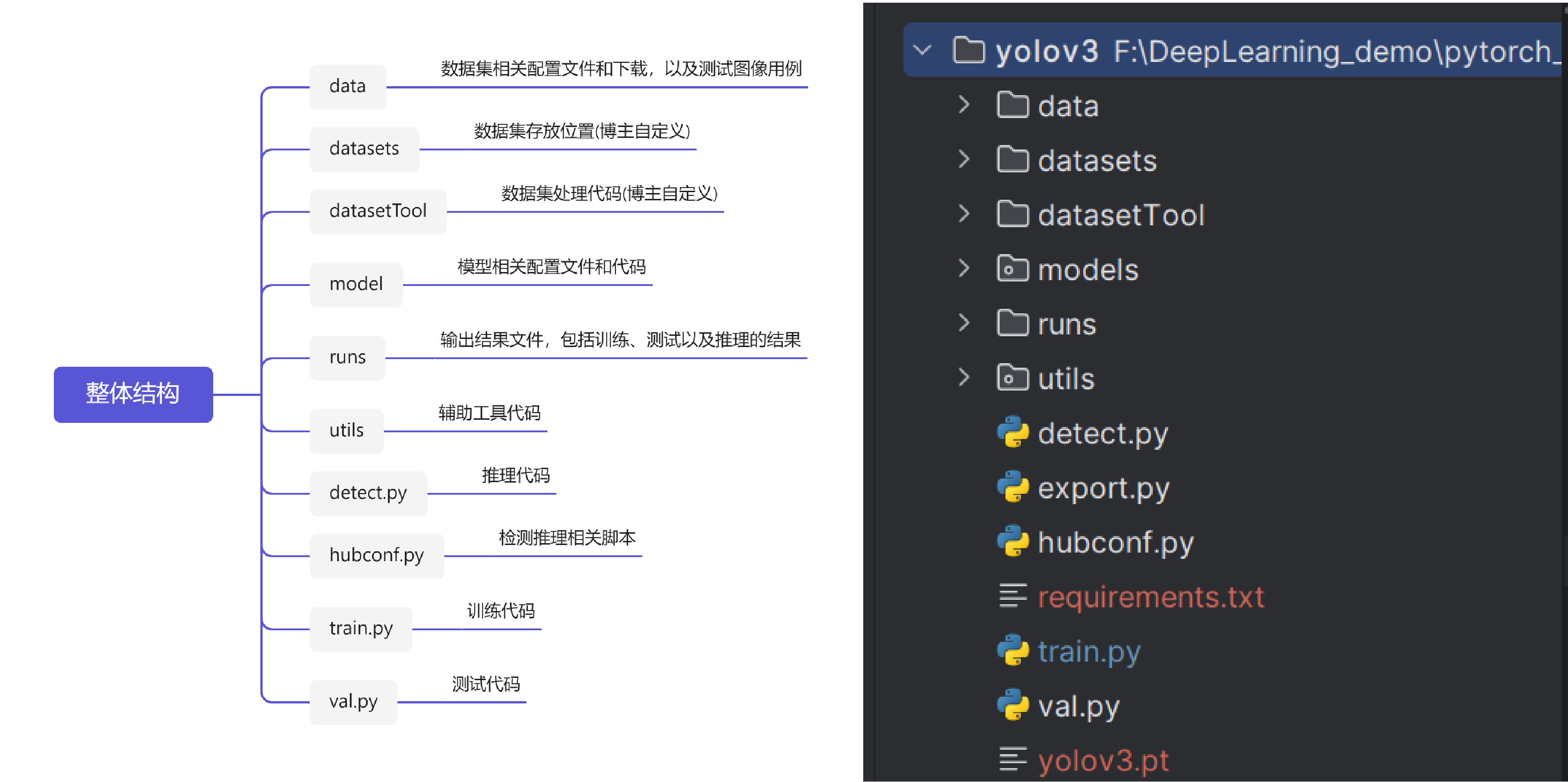
本博文不對具體的代碼進行講解,只對主要的yaml配置文件進行解析。
data文件結構

模型訓練超參數配置文件解析
hyp.scratch.yaml內容解析:
################## 1、學習率相關參數 ##################
lr0: 0.01 # 學習率的初始值:通常使用SGD時為0.01,使用Adam時為0.001.
lrf: 0.1 # 學習率調度器OneCycleLR中的最終學習率(lr0 * lrf):在一個訓練周期內逐步增加然后減少學習率來加速模型的收斂,有助于模型跳出局部最優解.
momentum: 0.937 # 學習率動量:記錄之前梯度(方向和大小)的加權平均值并將其用于參數更新以決定當前梯度的大小和方向
weight_decay: 0.0005 # optimizer權重衰減系數5e-4:有效地限制模型復雜度,減少過擬合的風險.
warmup_epochs: 3.0 # 預熱階段:先用較小的學習率在訓練初始時預熱,避免出現不穩定的梯度或損失的情況.
warmup_momentum: 0.8 # 預熱學習率動量
warmup_bias_lr: 0.1 # 預熱學習率
################## 學習率相關參數 ####################################### 2、損失函數相關參數 ###################
box: 0.05 # 預測邊界框損失的系數(位置和尺寸)
cls: 0.5 # 分類損失的系數
cls_pw: 1.0 # 分類損失的二元交叉熵損失中正樣本的權重
obj: 1.0 # 置信度損失權重
obj_pw: 1.0 # 置信度損失的二元交叉熵損失中正樣本的權重
iou_t: 0.20 # Iou閾值:當預測框和真實框之間的IoU大于閾值時為檢測正確,否則為檢測錯誤.
anchor_t: 4.0 # anchor的閾值:真實框與預測框的尺寸的比例在閾值范圍內為檢測正確,否則為檢測錯誤.
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5) 通過調節因子降低容易分類樣本的權重,gamma值越大模型更加關注難分類的樣本.
################### 損失函數相關參數 ########################################### 3、數據增強相關參數 ####################
# hsv_h、hsv_s、hsv_v表示圖像HSV顏色空間的色調、飽和度、明度的增強參數,取值范圍都是[0, 1],值越大強度越大.
hsv_h: 0.015 # 色調
hsv_s: 0.7 # 飽和度
hsv_v: 0.4 # 明度
# degrees、translate、scale、shear表示圖像旋轉、平移、縮放、扭曲的增強參數
degrees: 0.0 # 旋轉角度
translate: 0.1 # 水平和垂直隨機平移,取值范圍都是[0,1],這里允許的最大水平和垂直平移比例分別為原圖寬高的0.1
scale: 0.5 # 隨機縮放,圖像會被隨機縮放到原圖大小的0.5到1之間。
shear: 0.0 # 剪切:沿著某個方向對圖像進行傾斜或拉伸
# 模擬從不同的角度拍攝圖像:將圖像中的點映射到一個新的位置,產生類似傾斜、拉伸或壓縮的效果,取值范圍都是[0, 0.001].
perspective: 0.0 # 透視變換參數
# flipud、fliplr表示圖像上下翻轉、左右翻轉的增強概率,取值范圍都是[0, 1]。
flipud: 0.0 # 上下翻轉
fliplr: 0.5 # 左右翻轉
# mosaic、mixup、copy_paste表示選擇不同方式增強訓練集多樣性的概率,取值范圍都是[0, 1].
mosaic: 1.0 # 將四張圖片拼接成一張,增強了模型對多物體的感知能力和位置估計能力
mixup: 0.0 # 對兩張圖片進行線性混合,增強了模型對物體形狀和紋理的學習能力
copy_paste: 0.0 # 將一張圖片的一部分復制到另一張圖片上,增強了模型對物體的位置和尺度變化的魯棒性。
#################### 數據增強相關參數 ######################
其他的模型訓練超參數配置文件只是一些具體超參數數值上不同。
數據集配置文件解析
coco.yaml內容解析:
path: ../datasets/coco128 # 數據集源路徑
train: images/train2017 # path下訓練集地址,
val: images/train2017 # path下驗證集地址
test: # path下測試集地址nc: 80 # 檢測的類別數量
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light','fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee','skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard','tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple','sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch','potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear','hair drier', 'toothbrush'] # 檢測的類別名,避免用中文# 數據集下載URL(可選)
download: https://ultralytics.com/assets/coco128.zip
coco128.yaml內容解釋: 調用了utils中的函數,采用腳本方式下載數據集。
path: ../datasets/coco # 數據集源路徑
# txt列出了訓練集/驗證集/測試集中的所有圖像文件名或相對路徑
train: train2017.txt # path下訓練集地址
val: val2017.txt # path下驗證集地址
test: test-dev2017.txt # path下測試集地址nc: 80 # 檢測的類別數量
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light','fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee','skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard','tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple','sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch','potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear','hair drier', 'toothbrush'] # 檢測的類別名,避免用中文# 數據集下載腳本(可選)
download: |# 導入模塊utils下的函數from utils.general import download, Path# 下載標簽segments = False # 決定下載的標簽類型(分割標簽或者檢測標簽)dir = Path(yaml['path']) # 指定了數據集的路徑# 構建標簽下載URLurl = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/' # 基礎URLurls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # 下載指定標簽的URLdownload(urls, dir=dir.parent) # 下載標簽文件# 下載數據文件urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)# 使用3個線程并行下載提高下載速度download(urls, dir=dir / 'images', threads=3)
voc.yaml內容解釋: 調用了utils中的函數,采用腳本方式下載數據集。
path: ../datasets/VOC # 數據集源路徑
train: # path下訓練集地址- images/train2012 # YAML語法格式中 - 表示一個列表項- images/train2007- images/val2012- images/val2007
val: # path下驗證集地址- images/test2007
test: # path下測試集地址- images/test2007nc: 20 # 檢測的類別數量
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # 檢測的類別名,避免用中文# 數據集下載腳本(可選)
download: |# 導入模塊import xml.etree.ElementTree as ETfrom tqdm import tqdm# 導入utils下的函數from utils.general import download, Path# 將PASCAL VOC的XML標注文件轉換為YOLO格式的標注文件def convert_label(path, lb_path, year, image_id):# 將PASCAL VOC的邊界框坐標(xmin, xmax, ymin, ymax)轉換為YOLO格式的歸一化的中心點坐標和寬高def convert_box(size, box):dw, dh = 1. / size[0], 1. / size[1]x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]return x * dw, y * dh, w * dw, h * dh# 讀取XML文件in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')# 保存YOLO格式的.txt文件out_file = open(lb_path, 'w')# 并解析XML文件內容tree = ET.parse(in_file)root = tree.getroot()# 獲取圖像的尺寸size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)# 遍歷XML文件中的每個目標對象for obj in root.iter('object'):# 獲取目標對象的類別名稱cls = obj.find('name').text# 類別屬于數據集配置文件中的內容中且不是困難樣本,則進行轉換if cls in yaml['names'] and not int(obj.find('difficult').text) == 1:# 獲取目標對象的邊界框信息xmlbox = obj.find('bndbox')# 轉化為YOLO格式的歸一化的中心點坐標和寬高bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])# 類別序號cls_id = yaml['names'].index(cls)# 保存數據out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')# 下載數據集# 數據集存儲的根目錄dir = Path(yaml['path'])# : 需要下載的文件 URL 列表url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'urls = [url + 'VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 imagesurl + 'VOCtest_06-Nov-2007.zip', # 438MB, 4953 imagesurl + 'VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images# 下載urls指定的數據集download(urls, dir=dir / 'images', delete=False)# 轉換數據集path = dir / f'images/VOCdevkit'# 遍歷年份和數據集類型for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):# 創建對應的圖像和標簽文件夾imgs_path = dir / 'images' / f'{image_set}{year}'lbs_path = dir / 'labels' / f'{image_set}{year}'imgs_path.mkdir(exist_ok=True, parents=True)lbs_path.mkdir(exist_ok=True, parents=True)# 讀取每組數據集的圖像ID列表image_ids = open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt').read().strip().split()# 遍歷所有圖片for id in tqdm(image_ids, desc=f'{image_set}{year}'):# 移動圖像文件到目標目錄f = path / f'VOC{year}/JPEGImages/{id}.jpg' # 舊圖像路徑lb_path = (lbs_path / f.name).with_suffix('.txt') # 新圖像路徑f.rename(imgs_path / f.name) # 移動圖像convert_label(path, lb_path, year, id) # 生成YOLO格式的標簽文件
其他的數據集配置文件基本結構都與這三種相似,除了下載數據集腳本略微不同。
models文件結構
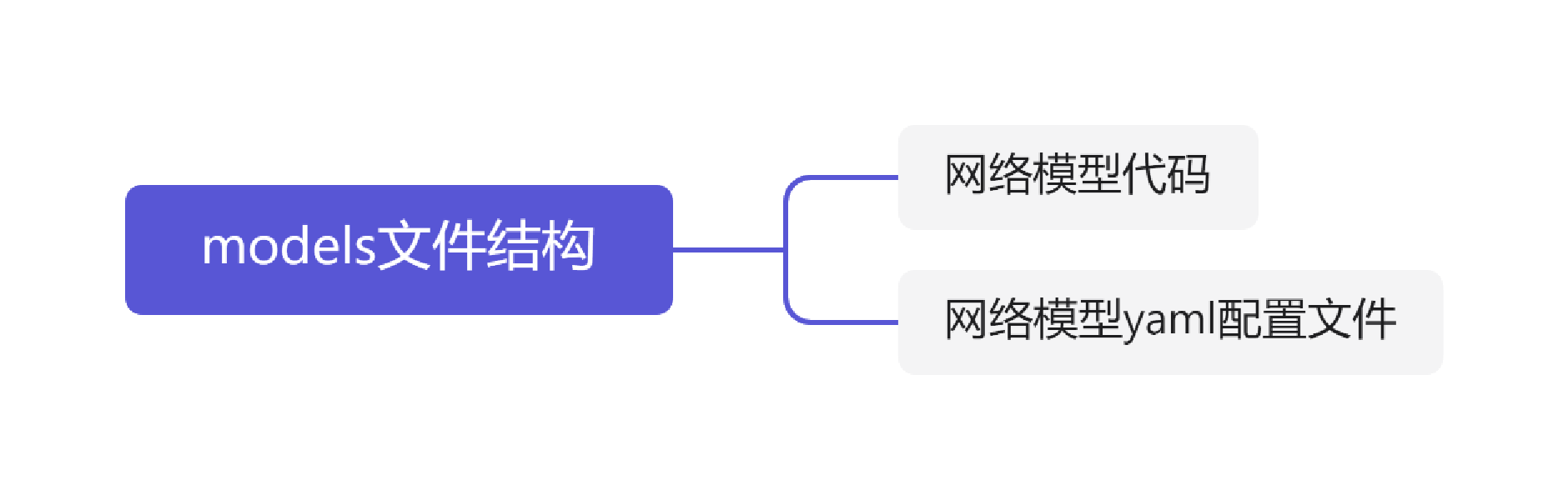
網絡模型配置文件yolov3.yaml內容解析:
nc: 80 # 模型識別的類別數量
# 通過以下兩個參數就可以實現不同復雜度的模型設計(原本Joseph Redmon的YOLOV3版本沒有以下倆個參數的)
depth_multiple: 1.0 # 模型深度系數:卷積模塊的縮放因子,原始模型的所有模塊乘以縮放因子,得到當前模型的模塊數
width_multiple: 1.0 # 模型通道系數:卷積層通道的縮放因子,backbone和head中所有卷積層的通道數乘以縮放因子得到,得到當前模型的所有卷積層的新通道數# 初始化了9個anchors,在3個檢測頭中中使用,每個檢測頭對應的特征圖中,每個網格單元都有3個anchor進行預測
anchors: # 以下3組anchors不能保證適用于所有的數據集- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# darknet53 主干網絡
backbone:# [from, number, module, args]# from表示當前模塊的輸入來自那一層的輸出,-1表示來自上一層的輸出.# number表示本模塊的理論重復次數,實際的重復次數:number×depth_multiple.# module表示模塊名,通過模塊名在common.py中尋找相應的類完成模塊化的搭建網絡.# args表示模塊搭建所需參數的列表,包括channel,kernel_size,stride,padding,bias等.[[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2[-1, 1, Bottleneck, [64]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4[-1, 2, Bottleneck, [128]],[-1, 1, Conv, [256, 3, 2]], # 5-P3/8[-1, 8, Bottleneck, [256]],[-1, 1, Conv, [512, 3, 2]], # 7-P4/16[-1, 8, Bottleneck, [512]],[-1, 1, Conv, [1024, 3, 2]], # 9-P5/32[-1, 4, Bottleneck, [1024]], # 10]# 檢測頭(包含了neck模塊)
head:# [from, number, module, args] 同理[[-1, 1, Bottleneck, [1024, False]],[-1, 1, Conv, [512, [1, 1]]],[-1, 1, Conv, [1024, 3, 1]],[-1, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)[-2, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 8], 1, Concat, [1]], # cat backbone P4[-1, 1, Bottleneck, [512, False]],[-1, 1, Bottleneck, [512, False]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)[-2, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P3[-1, 1, Bottleneck, [256, False]],[-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)[[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
模型配置文件與模型結構圖的對應關系如下圖所示:
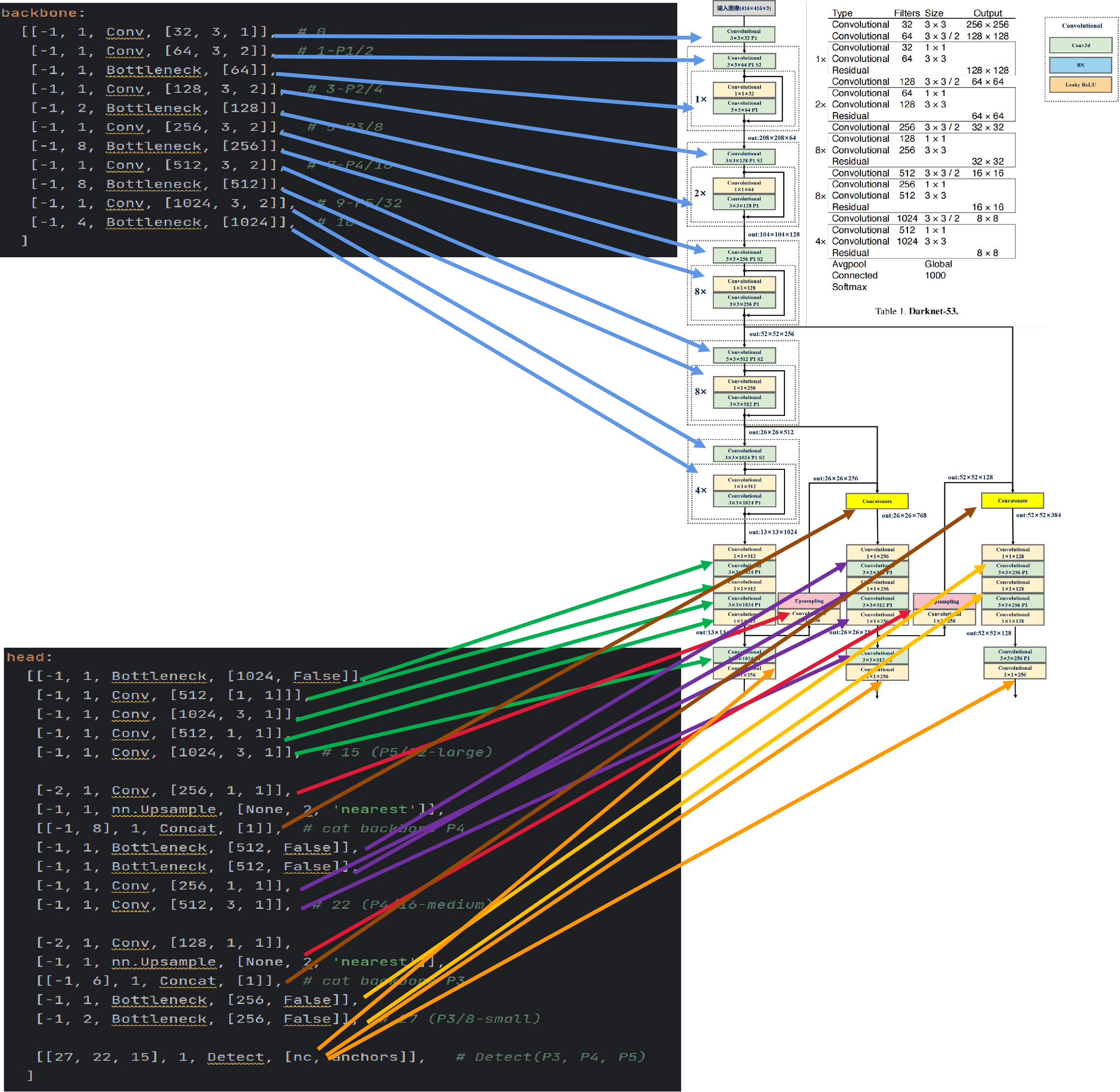
這里注意一個點,Bottleneck是2個卷積層組成:1×1卷積層和3×3卷積層,所以在head配置部分與模型結構圖的對應有點差異,即模型結構圖展現了1×1卷積層和3×3卷積層,但是在head配置部分用Bottleneck代替了。
其他網絡模型配置文件基本與yolov3.yaml相似。
utils文件結構
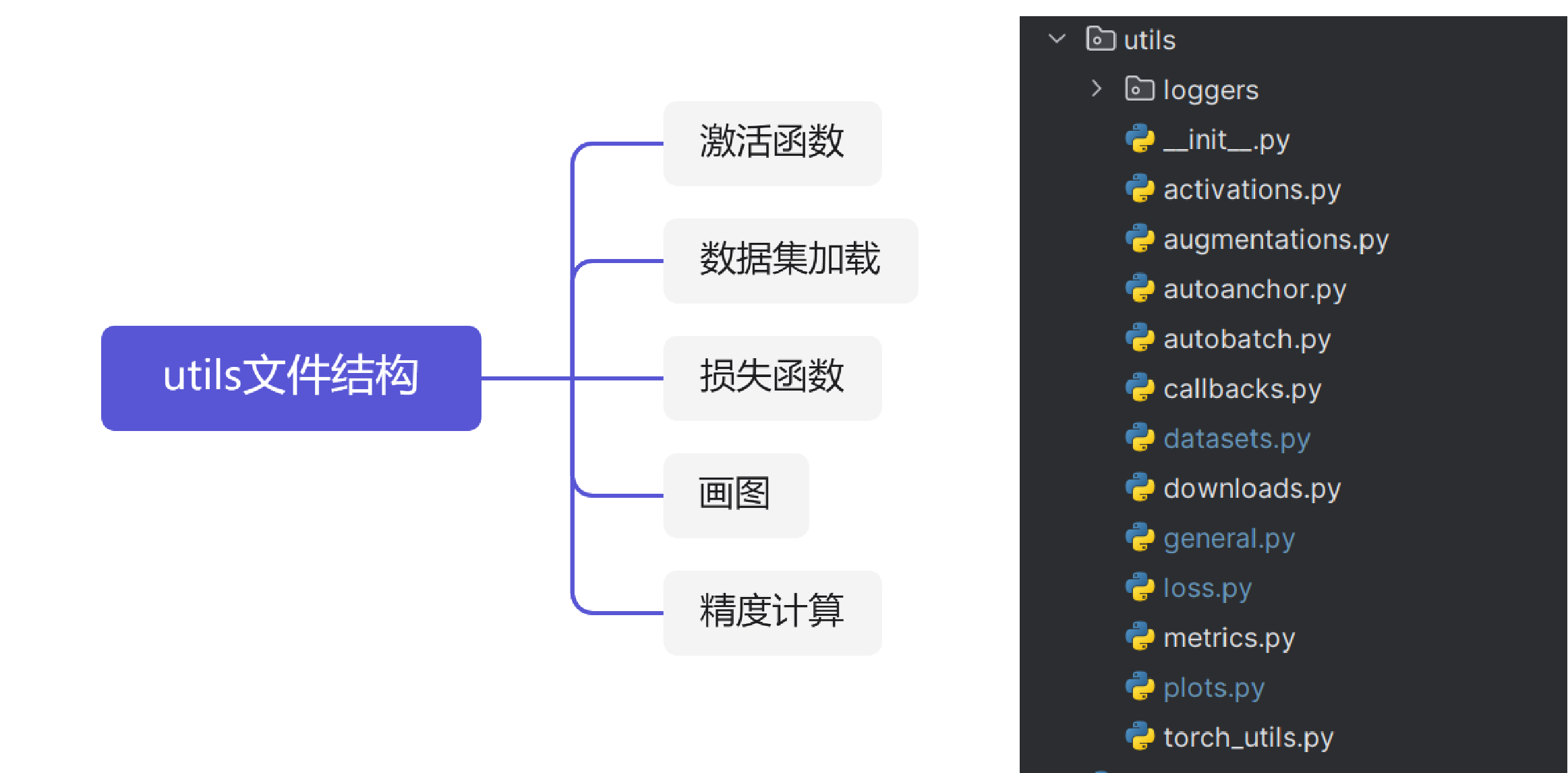
功能性代碼部分,在使用到這部分代碼時候再詳細講解內容。
runs文件結構
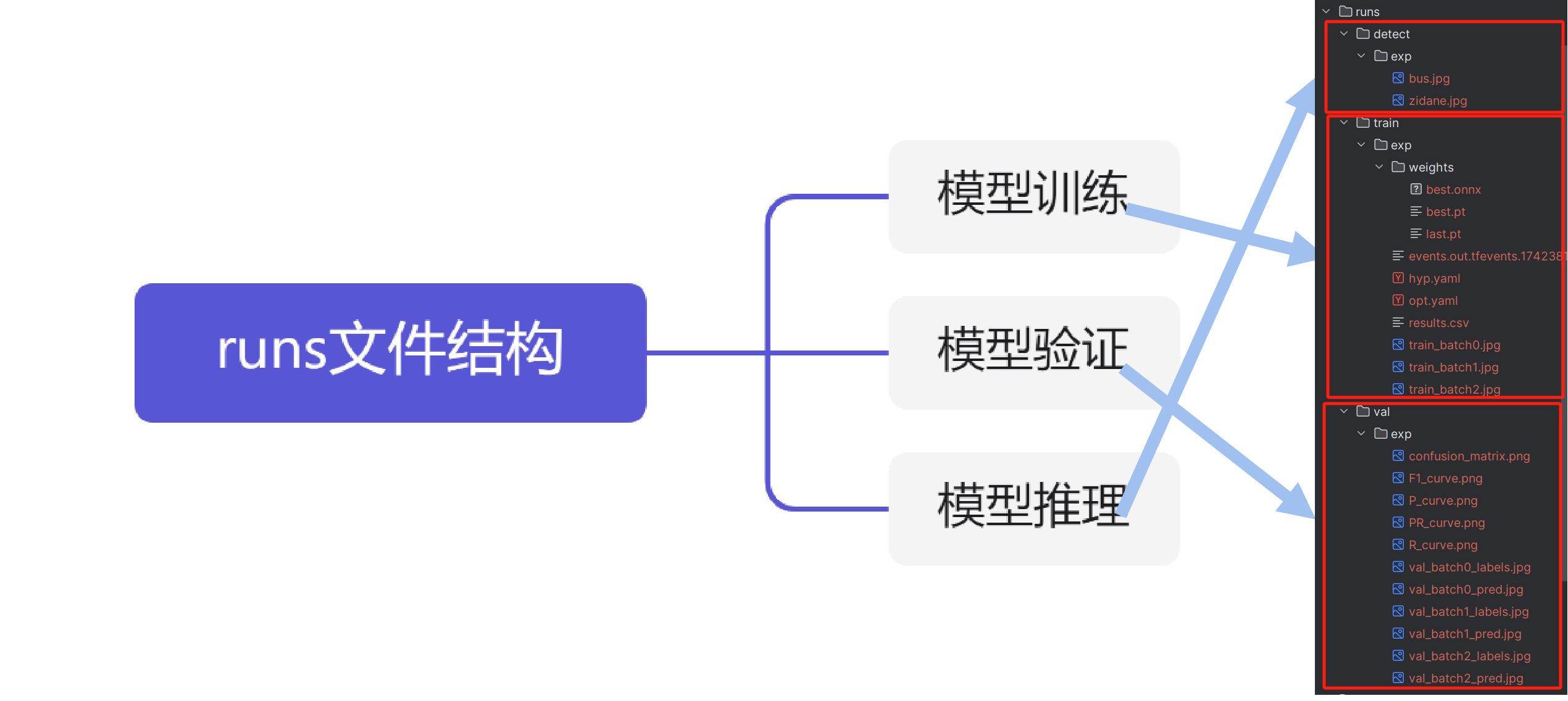
執行訓練、驗證和推理三個不同階段都會得出相應的輸出結果,具體輸出的含義在后續不同階段內容時候詳細講解。
總結
盡可能簡單、詳細的介紹了YOLOV3源碼整體結構解析。后續會根據自己學到的知識結合個人理解講解YOLOV3的每個階段的詳細代碼。



和入侵防御系統(IPS)有啥區別?)




)
)

)

 操作系統上添加 ollama 作為系統服務的步驟)





)