思維導圖:
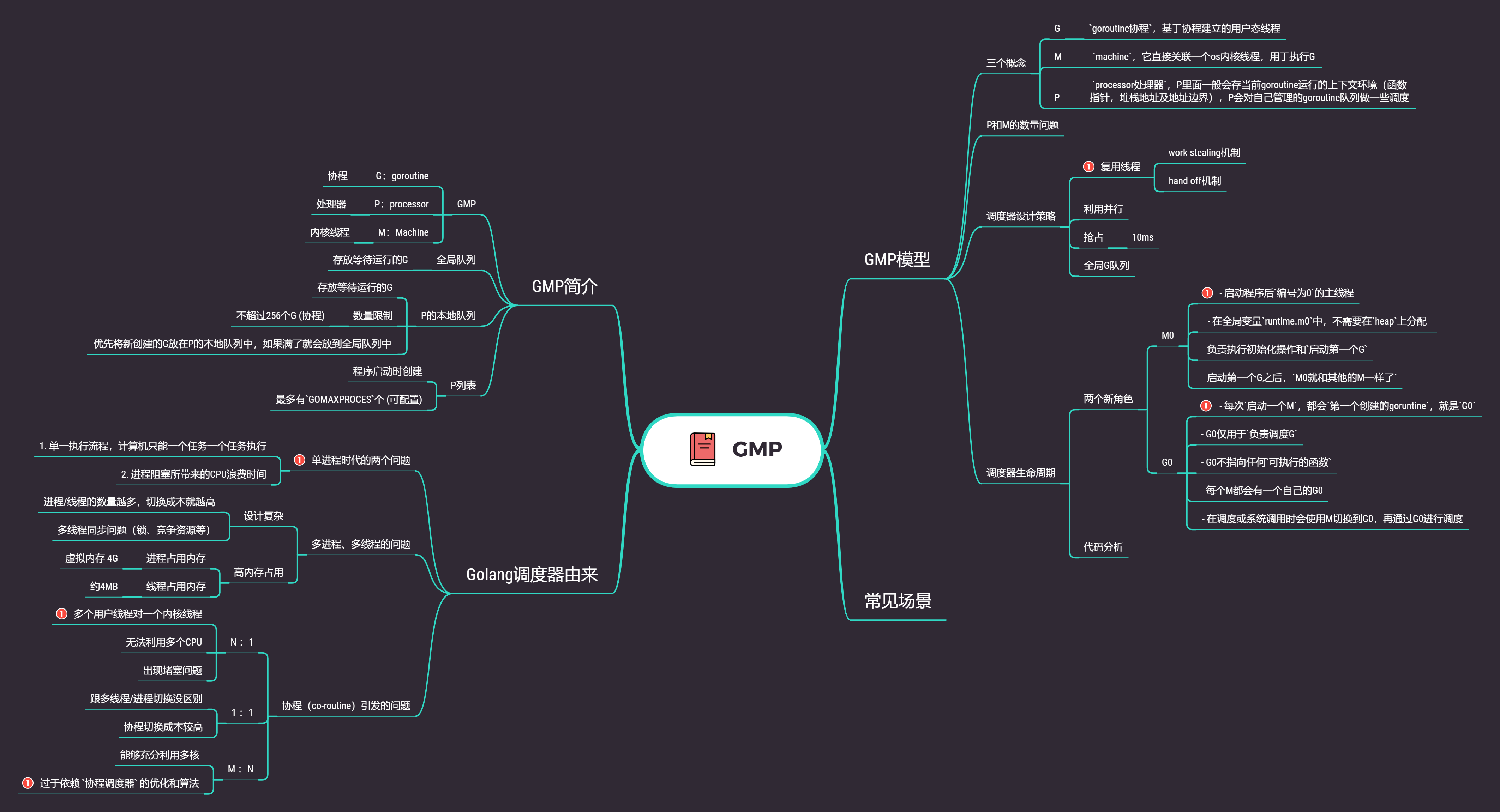
1. 發展過程
思維導圖:
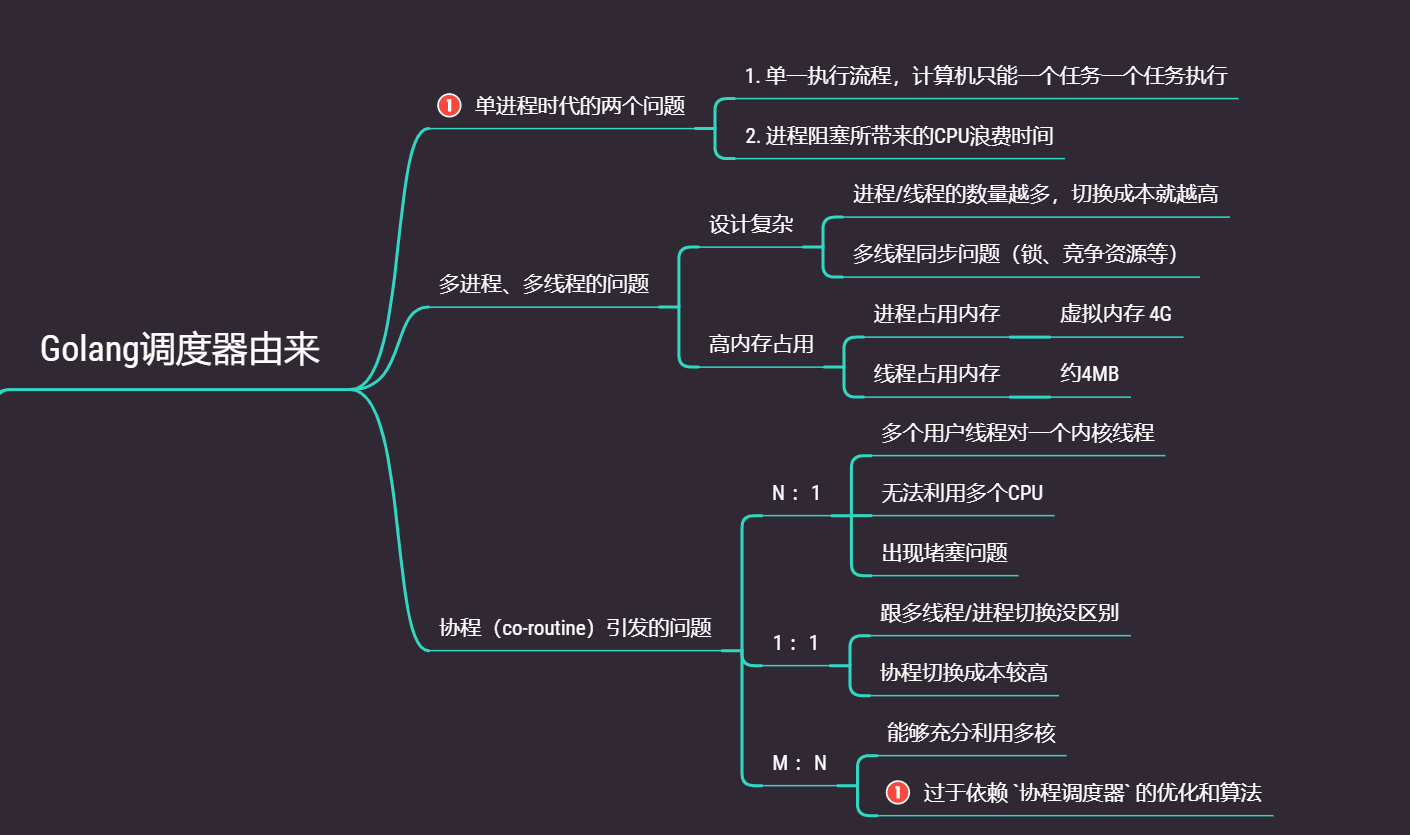
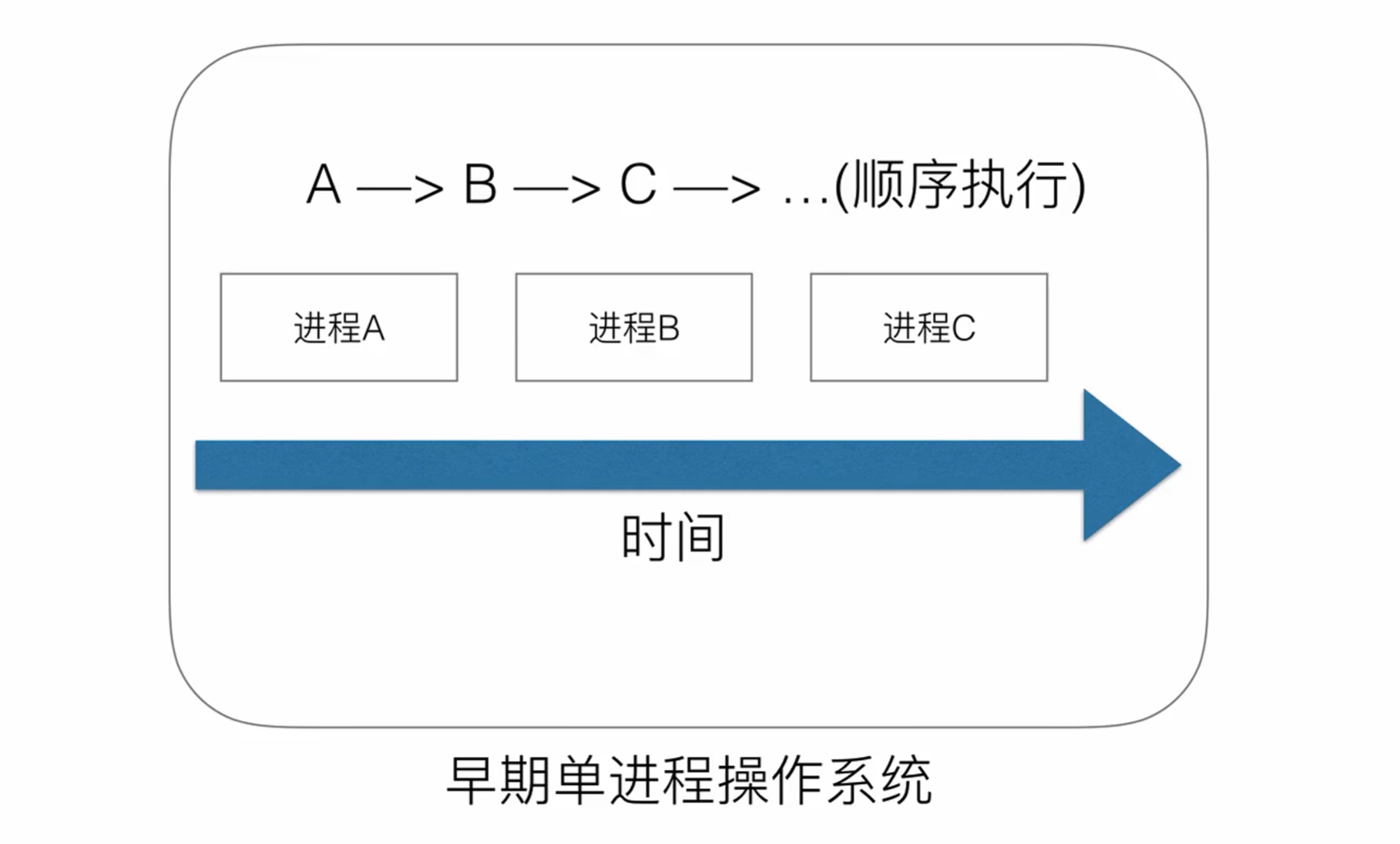
在單機時代是沒有多線程、多進程、協程這些概念的。早期的操作系統都是順序執行
單進程的缺點有:
- 單一執行流程、計算機只能一個任務一個任務進行處理
- 進程阻塞所帶來的CPU時間的浪費
處于對CPU資源的利用,發展出多線程/多進程操作系統,采用時間片輪訓算法
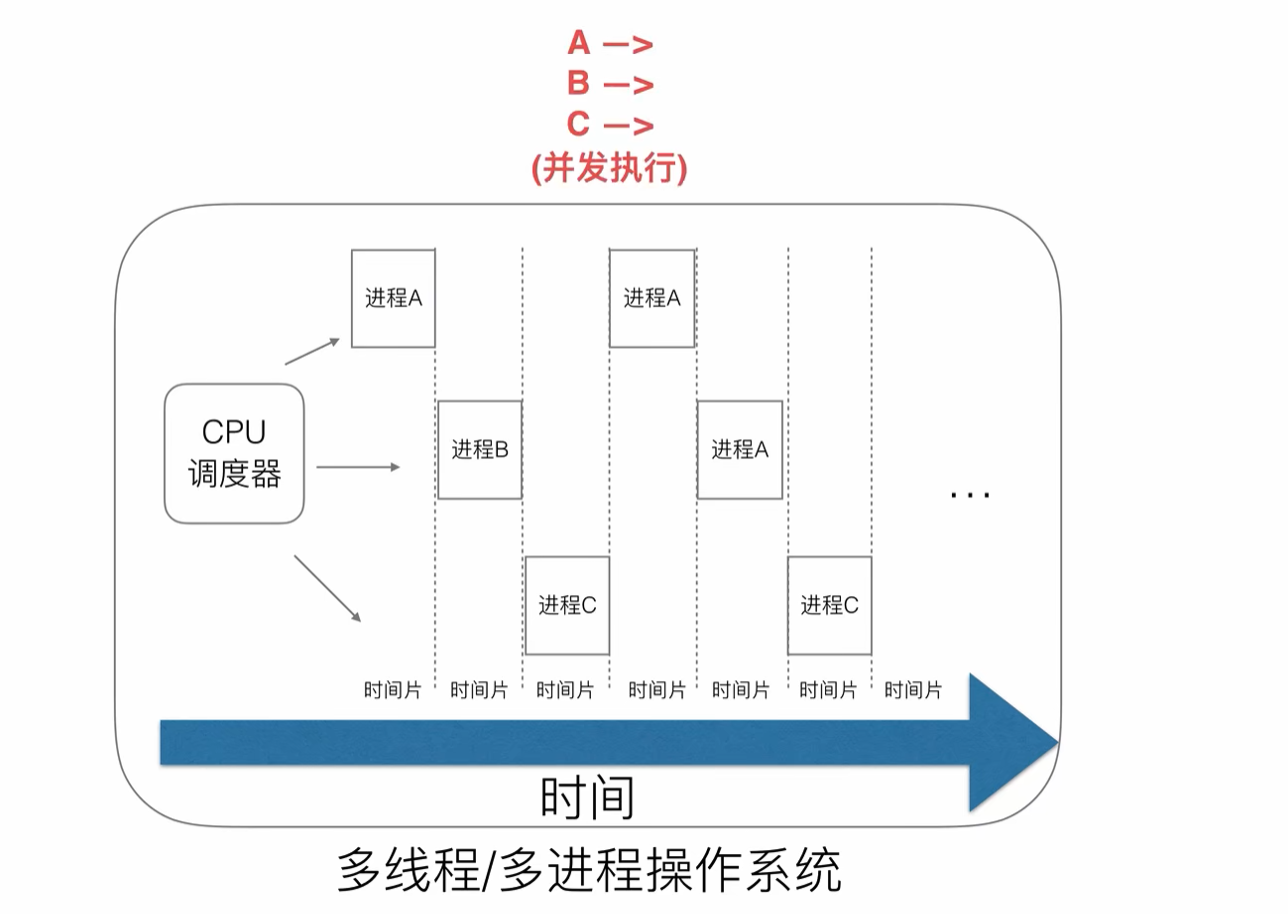
宏觀上來說,就算只有一個cpu,也能并發執行多個進程
這樣的好處是充分利用了CPU,但是也帶來了一些問題,例如時間片切換需要花費額外的開銷
- 進程/線程的數量越多,切換
成本就越大,也就越浪費
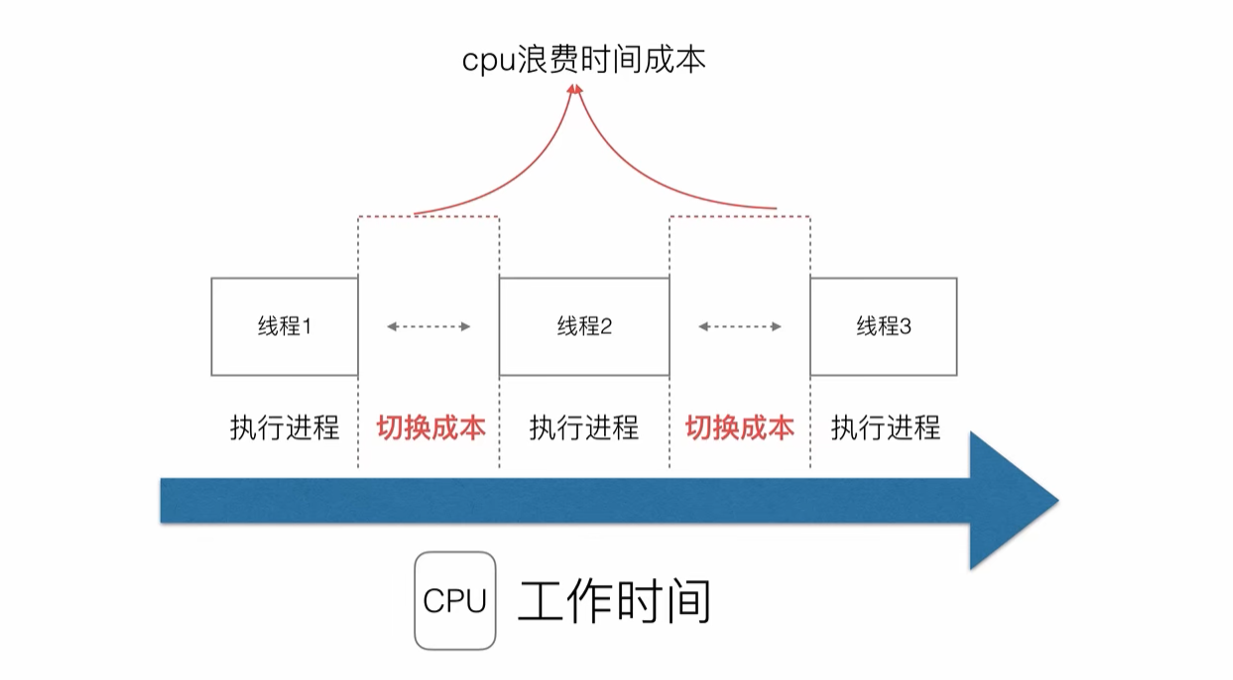
對于開發人員來說,盡管線程看起來很美好,但實際上多線程開發設計會變得更加復雜,要考慮很多同步競爭等問題,如鎖、競爭沖突等
進程擁有太多的資源,進程的創建、切換、銷毀,都會占用很長的時間,CPU雖然利用起來了,但如果進程過多,CPU有很大的一部分都被用來進行進程調度了

所以提高cpu的利用率成為我們需要解決的問題
既然問題出現在線程上下文切換中,那么首先我們需要好好想一想什么是線程的上下文切換
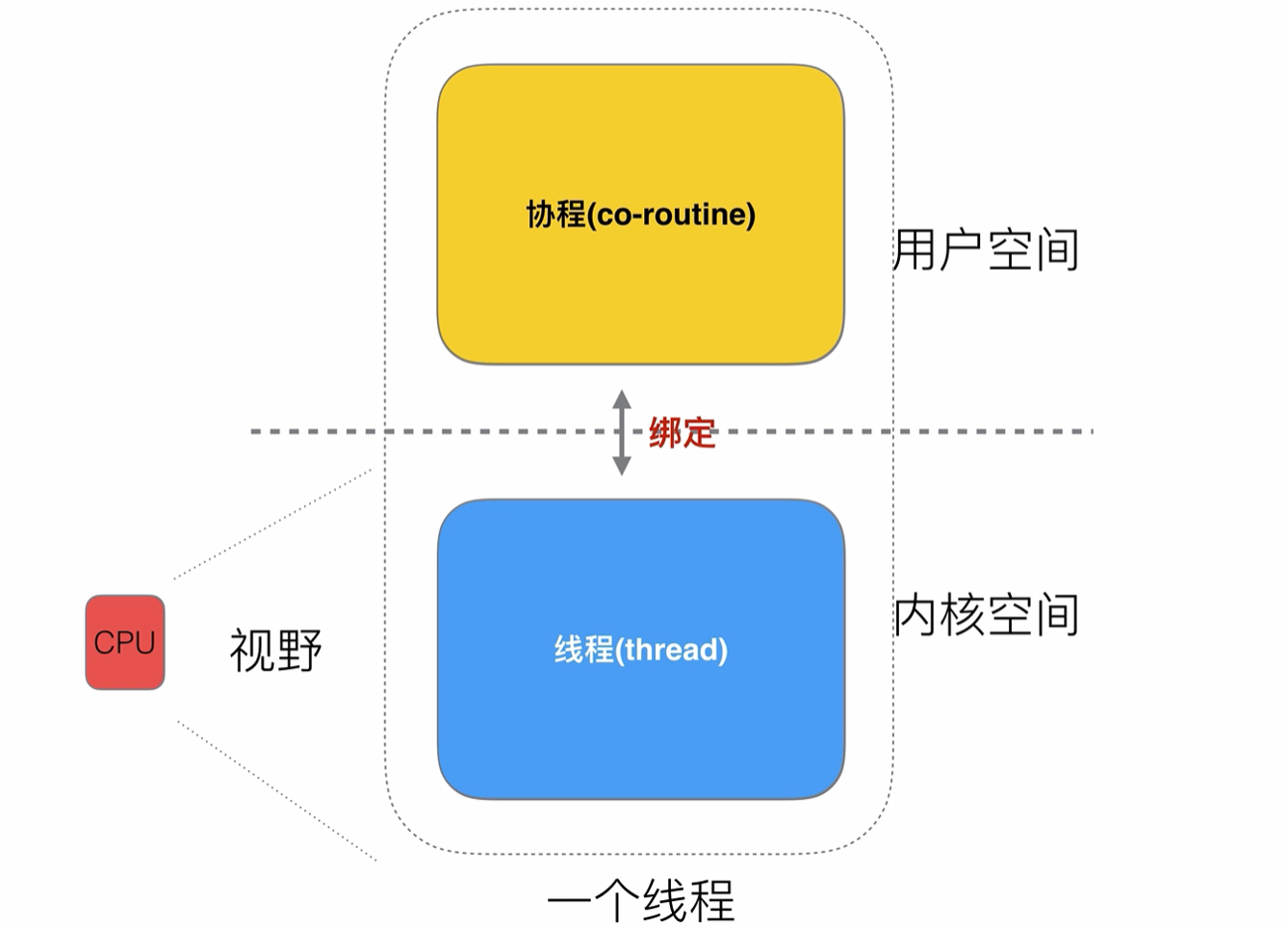
我們知道操作系統的一些核心接口是不能被進程隨意調度的,例如進行io流的讀寫操作,需要將最終的執行權交給操作系統(內核態)進行調度,所以就會有用戶態和內核態之前的切換
這個時候我們的線程模型是這樣的
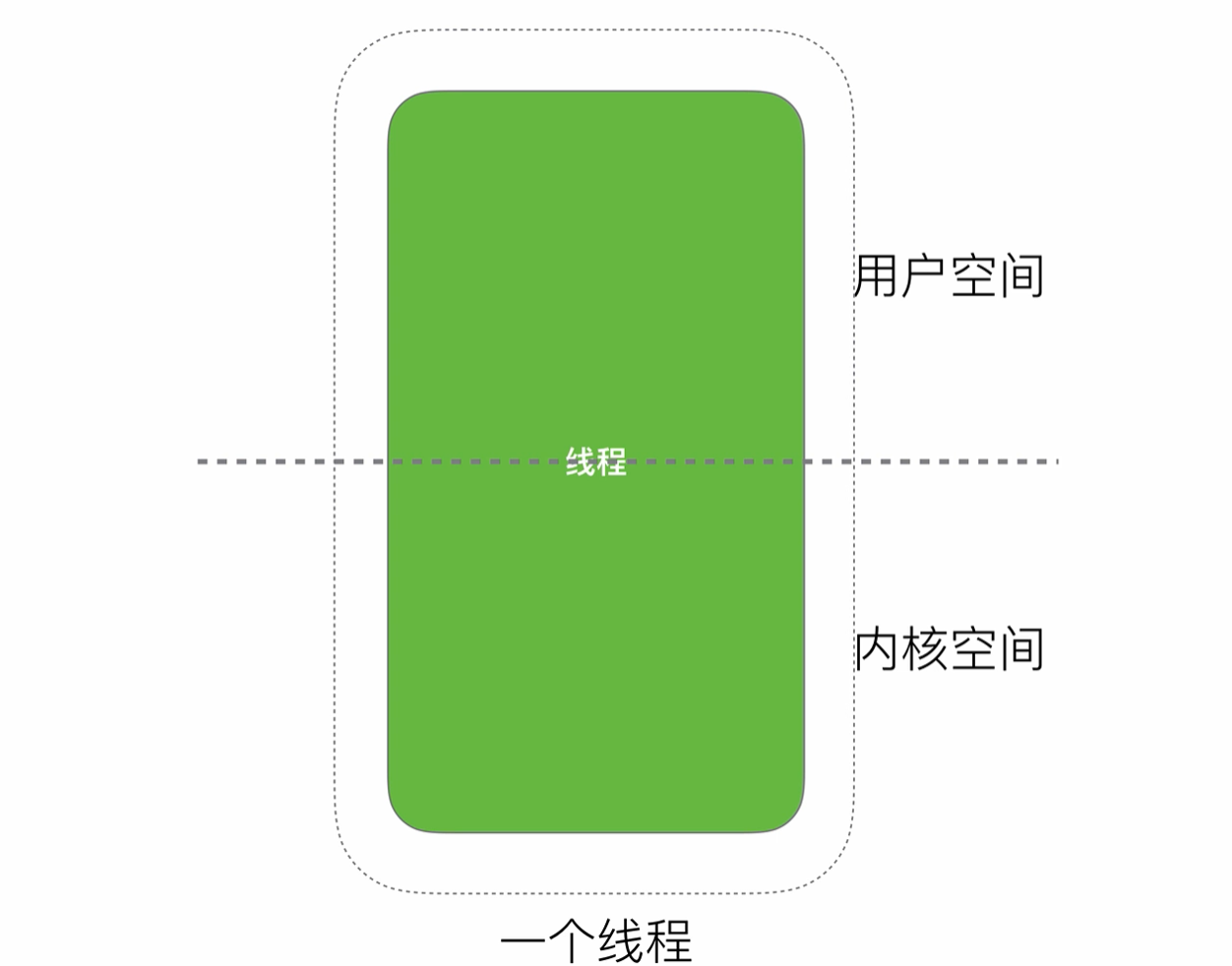
一個線程需要在內核態與用戶態之間進行切換,并且切換是受到操作系統控制的,可能這個現在需要等待多個時間片才能切換到內核態再調用操作系統底層的接口
那么我們是否可以用兩個線程分別處理這兩種狀態呢?兩個線程之間再
做好綁定,當用戶線程將任務提交給內核線程后,就可以不用堵塞了,可以去執行其他的任務了
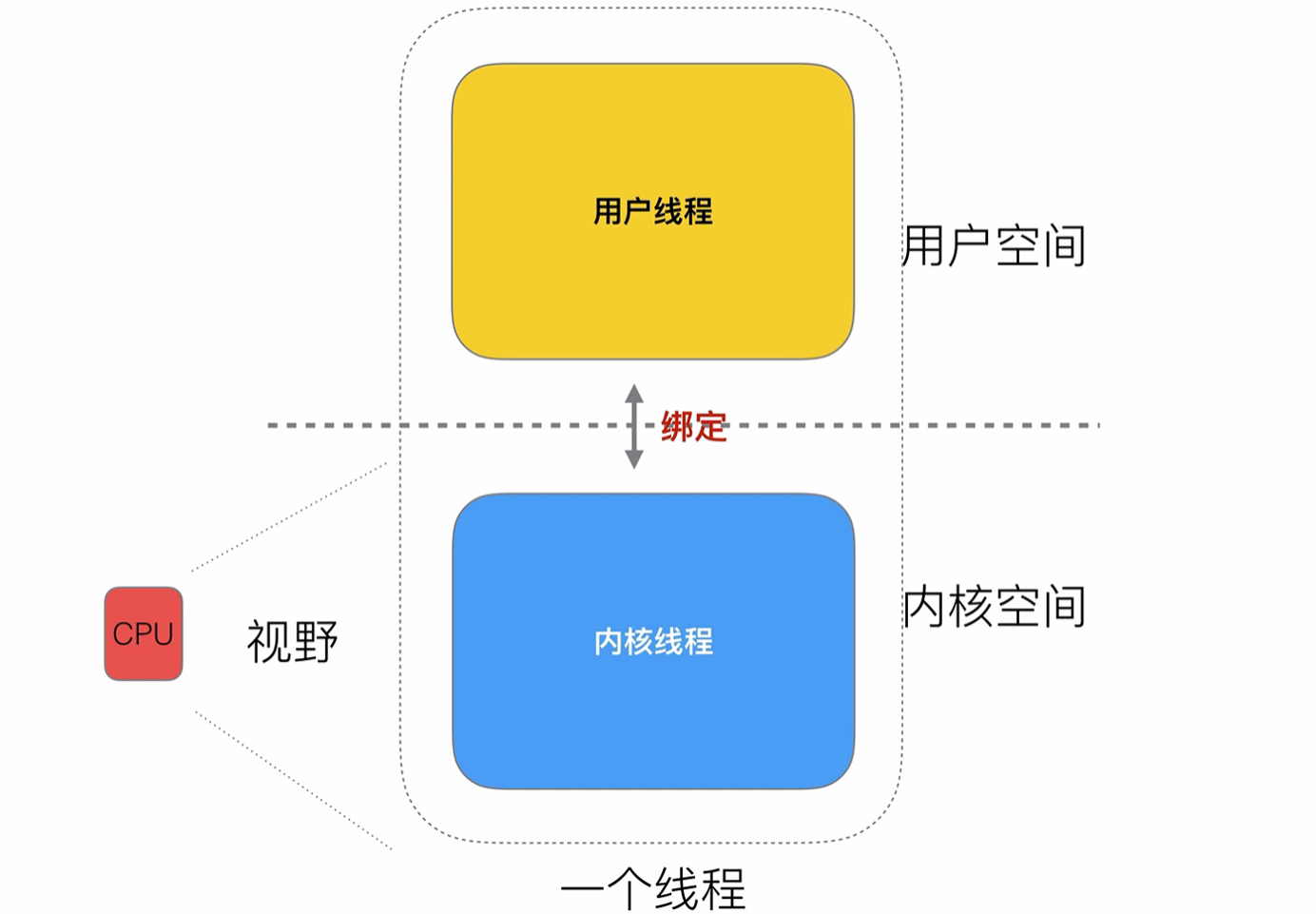
對于CPU來說(多核CPU),不需要關注線程切換的問題,只需要分配系統資源給內核線程進行調度即可
我們來給用戶線程換個名字——協程(co-runtine)
如果是一比一的關系的話,其實還是可能需要等待內核線程的執行
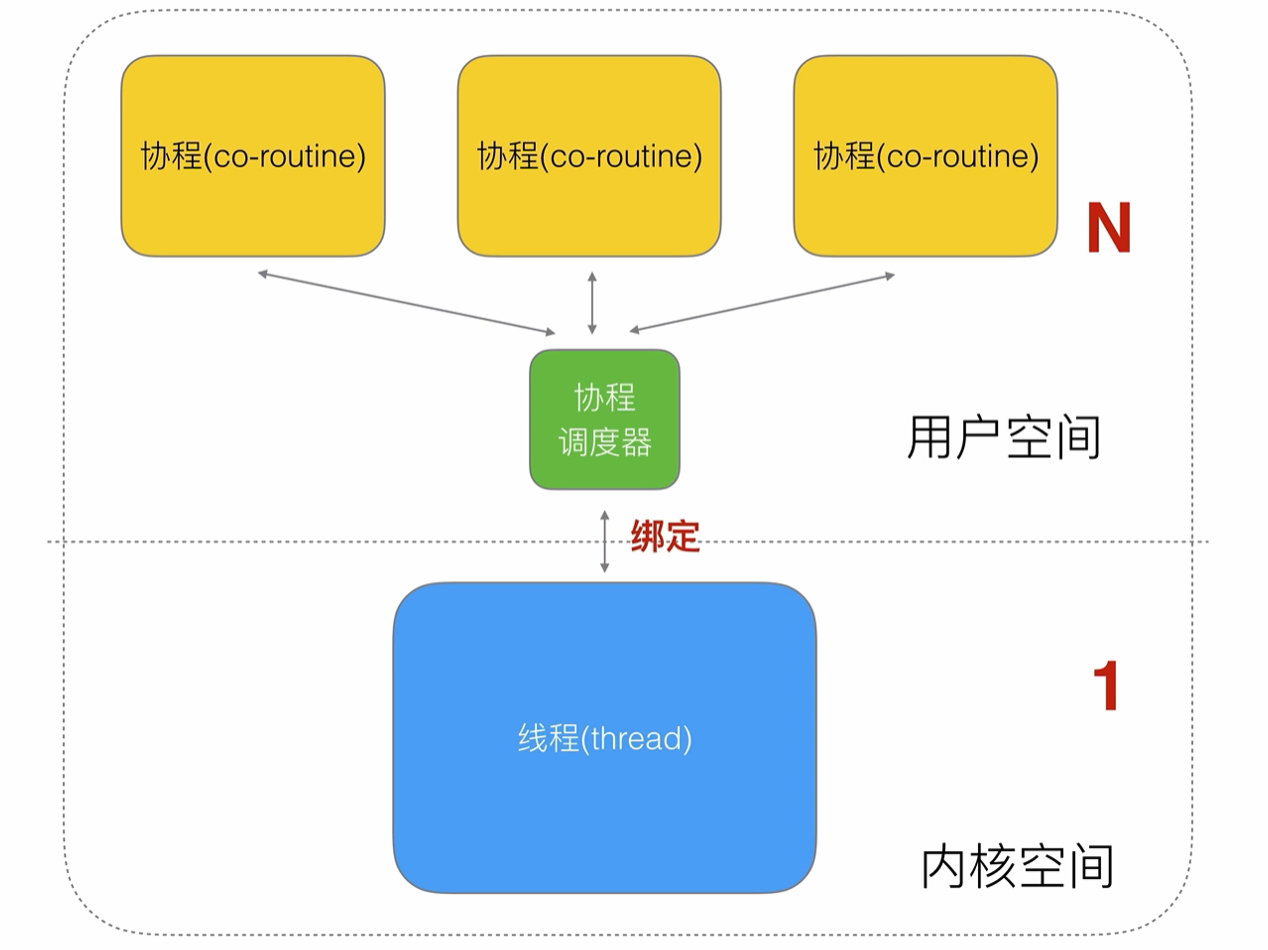
所以可以設計為N 比 1的形式,多個協程可以將任務一股腦的交給內核線程去完成,但是這樣又有問題,如果其中一個問題在提交任務的過程中,堵塞住了,就會影響其他線程的工作
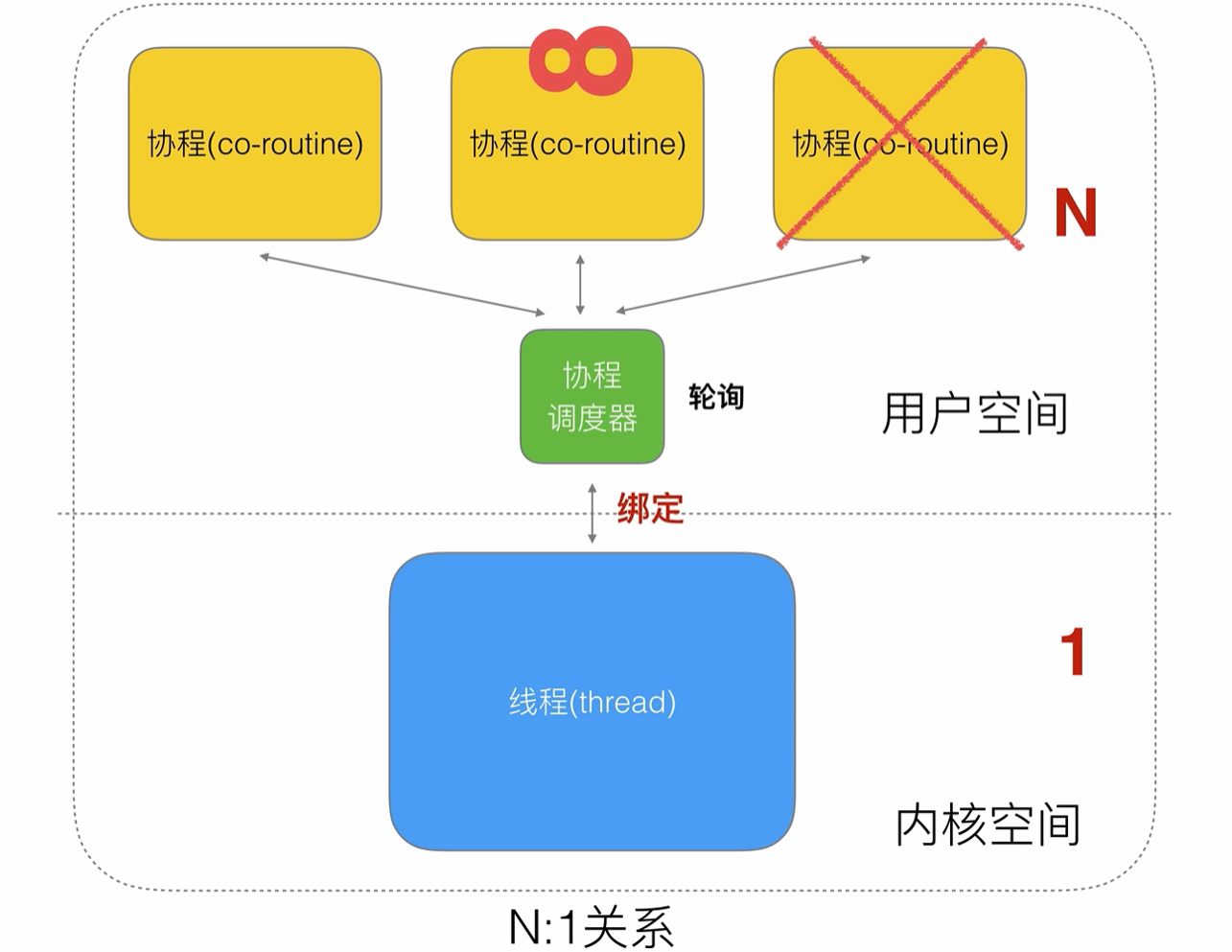
這個就是python的event-loop遇到的問題,一個阻塞,其余全阻塞
所以一般為M 比 N的關系
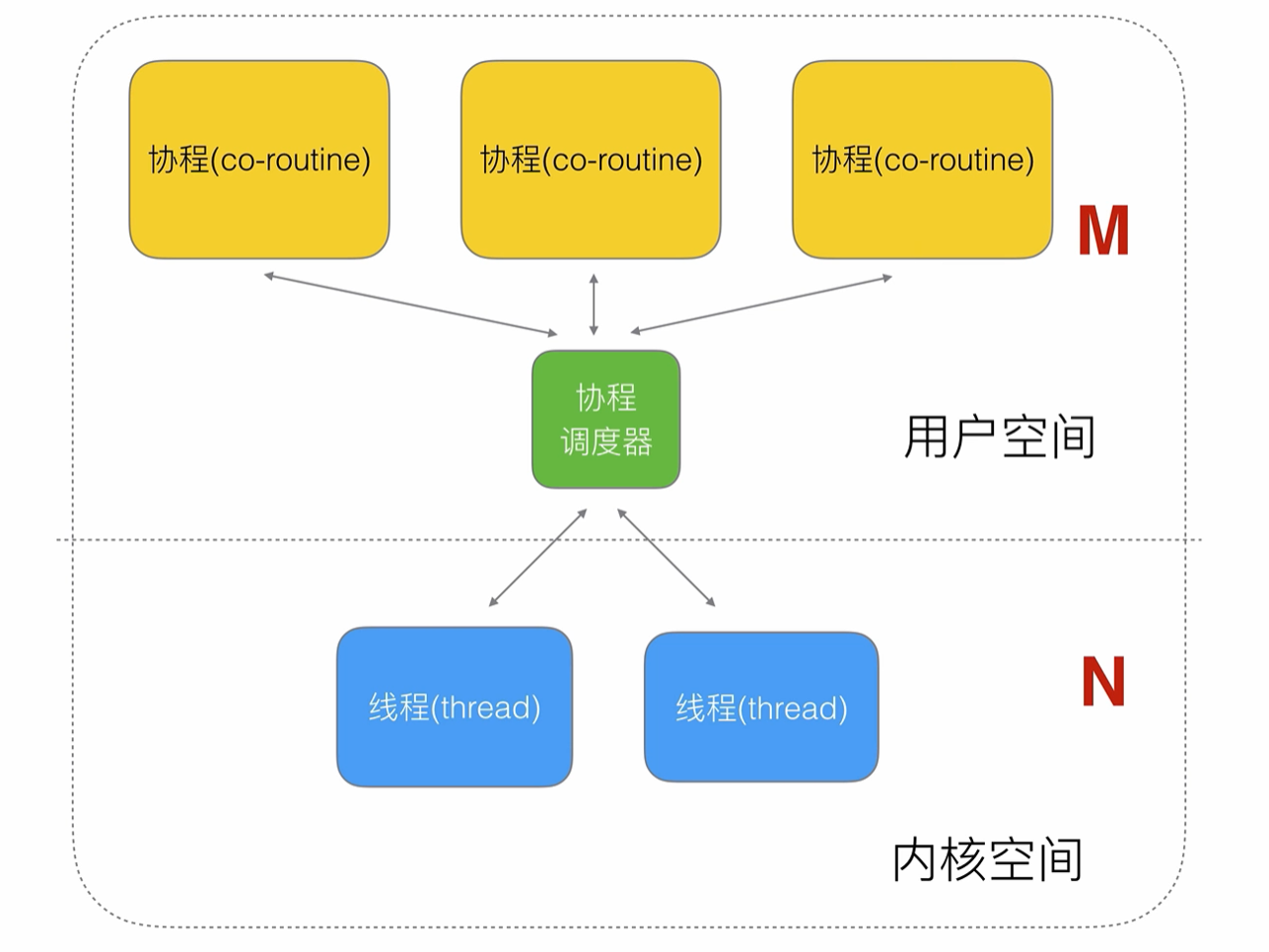
在M 比 N的關系中,大部分的精力都會放在協程調度器上,如果調度器效率高就能讓協程之間阻塞時間盡可能的少
在golang中對
協程調度器和協程內存進行了優化
- 協程調度器:可以支持靈活調度
- 內存輕量化:可以擁有大量的協程

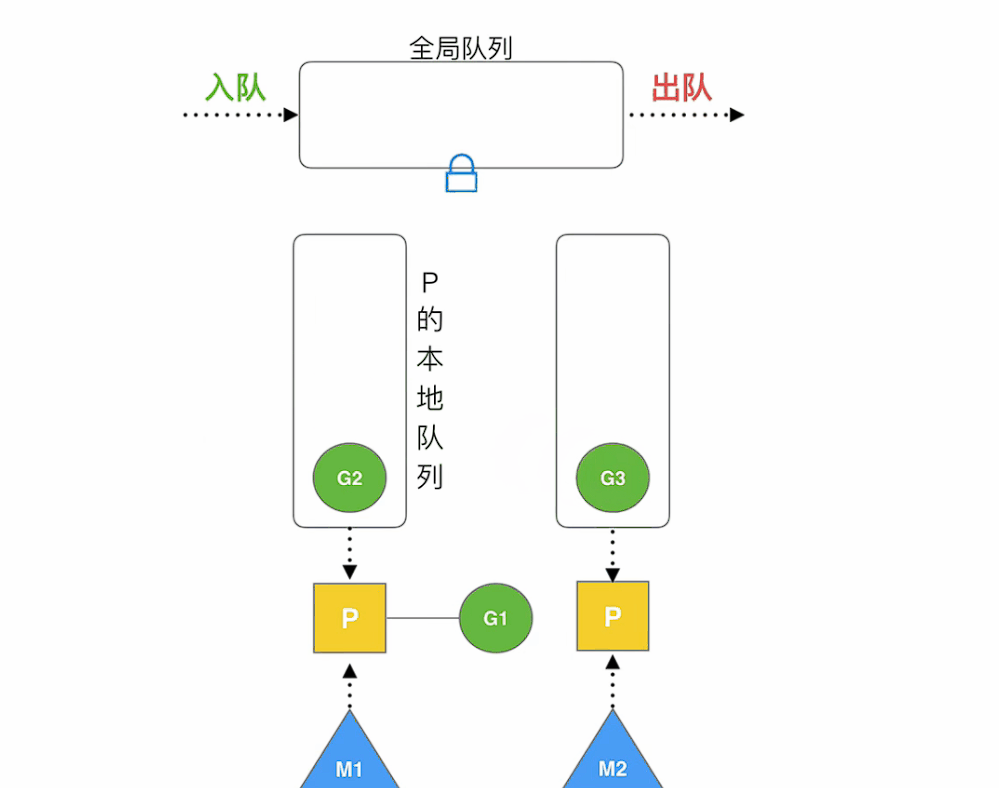
在golang早期的協程調度器中,采用的是隊列的方式,M想要執行、放回G都必須訪問全局G隊列,并且M有多個,即多線程訪問同一資源需要加鎖進行保證互斥/同步,所以全局G隊列是有互斥鎖進行保護的
老調度器有幾個缺點:
- 創建、銷毀、調度G都需要每個M獲取鎖,這就形成了
激烈的鎖競爭 - M轉移G會造成
延遲和額外的系統負載。比如當G中包含創建新協程的時候,M創建了G',為了繼續執行G,需要把G'交給M'執行,也造成了很差的局部性,因為G'和G是相關的,最好放在M上執行,而不是其他M' - 系統調用(CPU在M之間的切換)導致頻繁的線程阻塞和取消阻塞操作增加了系統開銷
2. GMP模型設計思想
思維導圖:
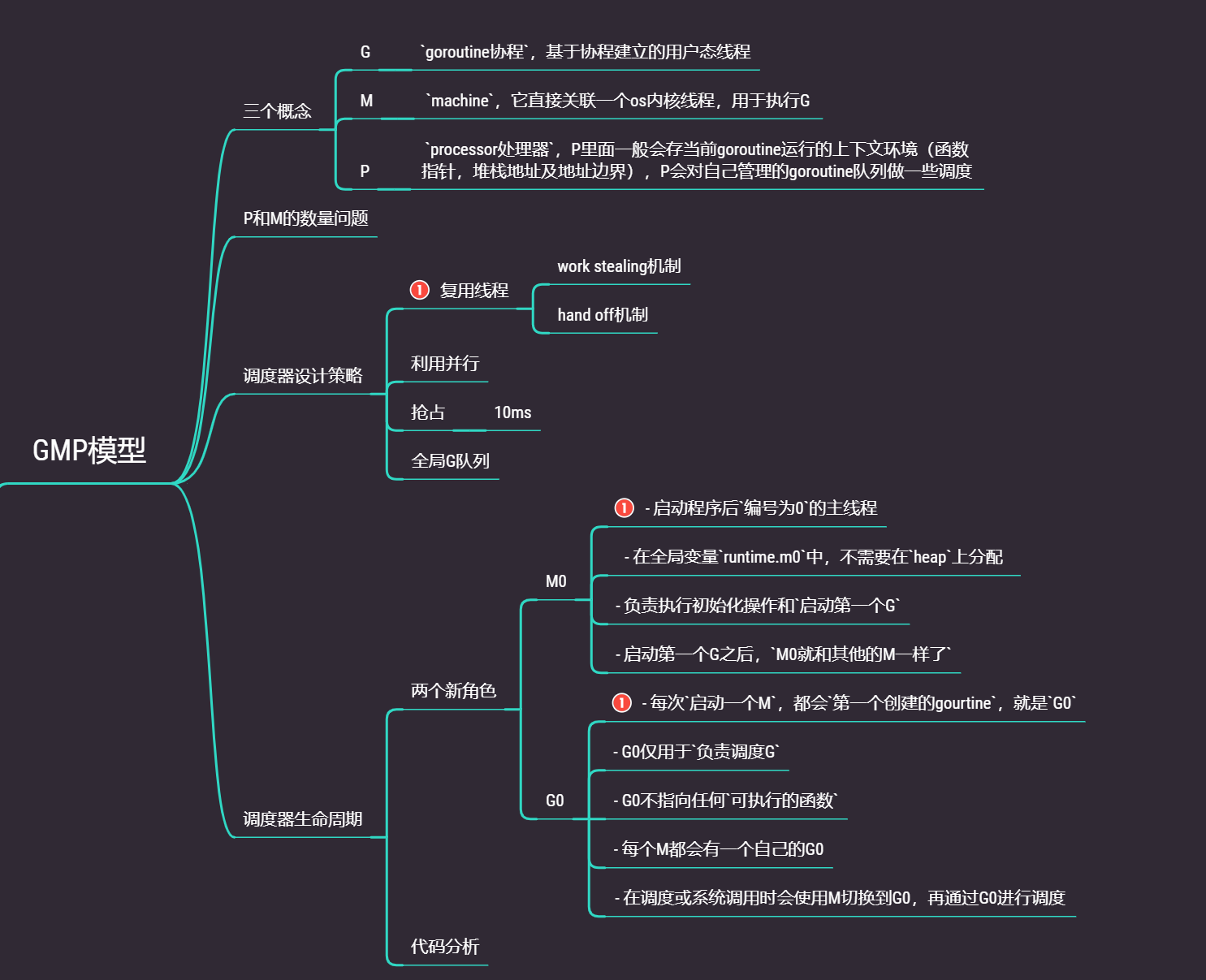
2.1 GMP模型
GMP是goalng的線程模型,包含三個概念:內核線程(M),goroutine(G),G的上下文環境(P)
- G:
goroutine協程,基于協程建立的用戶態線程- M:
machine,它直接關聯一個os內核線程,用于執行G- P:
processor處理器,P里面一般會存當前goroutine運行的上下文環境(函數指針,堆棧地址及地址邊界),P會對自己管理的goroutine隊列做一些調度
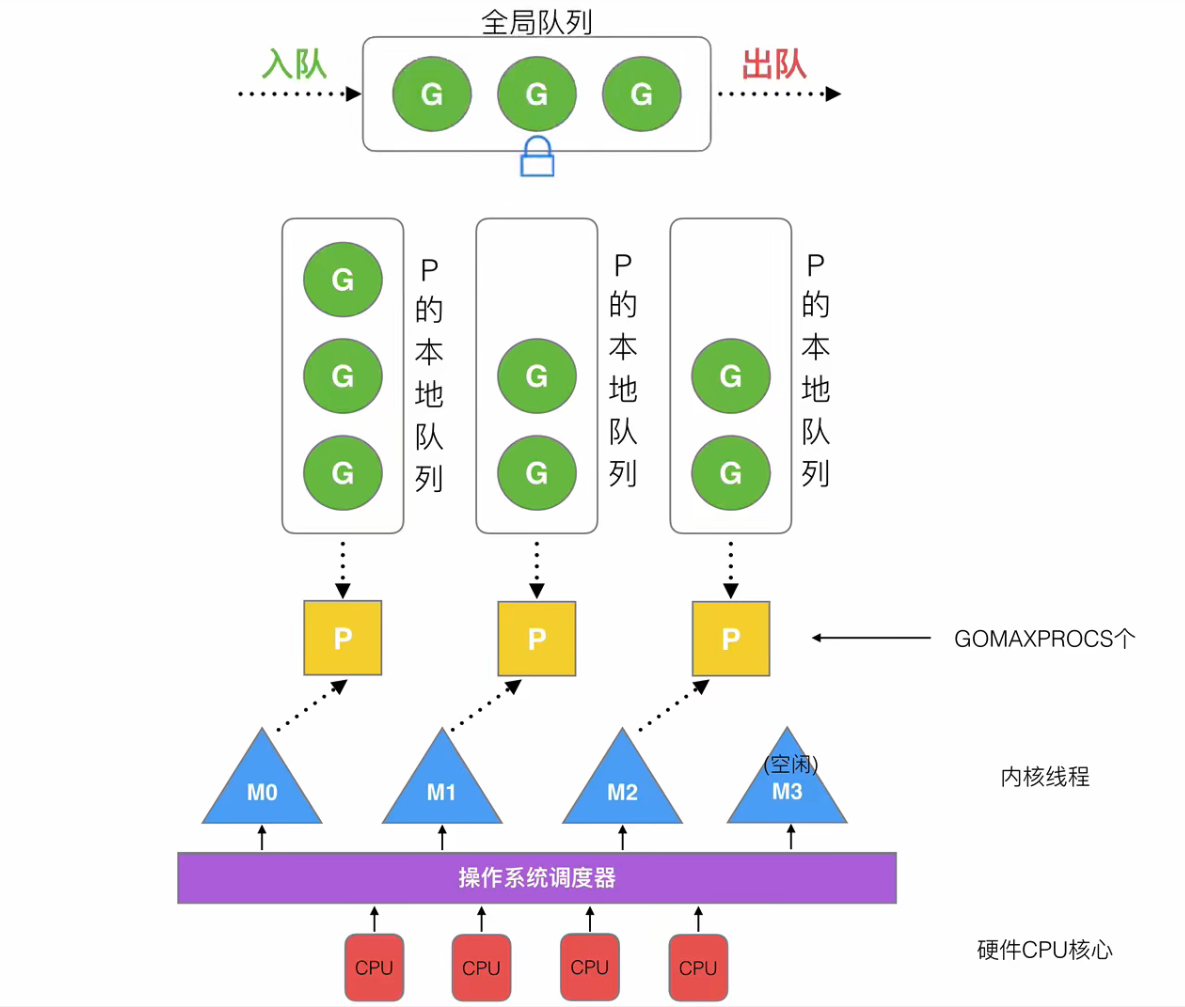
在Go中,線程是運行goroutine的實體,調度器的功能是把可運行的goroutine分配到工作線程上
- 全局隊列(Global Queue):存放等待運行的
G - P的本地隊列:同全局隊列類似,存放的也是等待運行的
G,存的數量有限,不超過256個。新建G'時,G'優先加入到P的本地隊列,如果隊列滿了,則會把本地隊列中一半的G移動到全局隊列 - P列表:所有的
P都在程序啟動時創建,并保存在數組中,最多有GOMAXPROCS(可配置)個 - M:線程想運行任務就得獲取
P,從P的本地隊列獲取G,P隊列為空時,M也會嘗試從全局隊列拿一批G放到P的本地隊列,或從其他P的本地隊列一半放到自己P的本地隊列。M運行G,G執行之后,M會從P獲取下一個G,不斷重復下去
P和M的數量問題
- P的數量:環境變量
$GOMAXPROCS;在程序中通過runtime.GOMAXPROCS()來設置- M的數量:GO語言本身限定
一萬?(但是操作系統達不到);通過runtime/debug包中的SetMaxThreads函數來設置;有一個M阻塞,會創建一個新的M;如果有M空閑,那么就會回收或者休眠M與P的數量沒有絕對關系,一個M阻塞,P就會去創建或者切換另一個M,所以,即使P的默認數量是1,也有可能會創建很多個M出來
2.2 調度器的設計策略
golang調度器的設計策略思想主要有以下幾點:
- 復用線程
- 利用并行
- 搶占
- 全局G隊列
2.2.1 復用線程
golang在復用線程上主要體現在work stealing機制和hand off機制(偷別人的去執行,和自己扔掉執行)
首先我們看work stealing,我們在學習java的時候學過fork/join,其中也是通過工作竊取方式來提升效率,充分利用線程進行并行計算,并減少了線程間的競爭
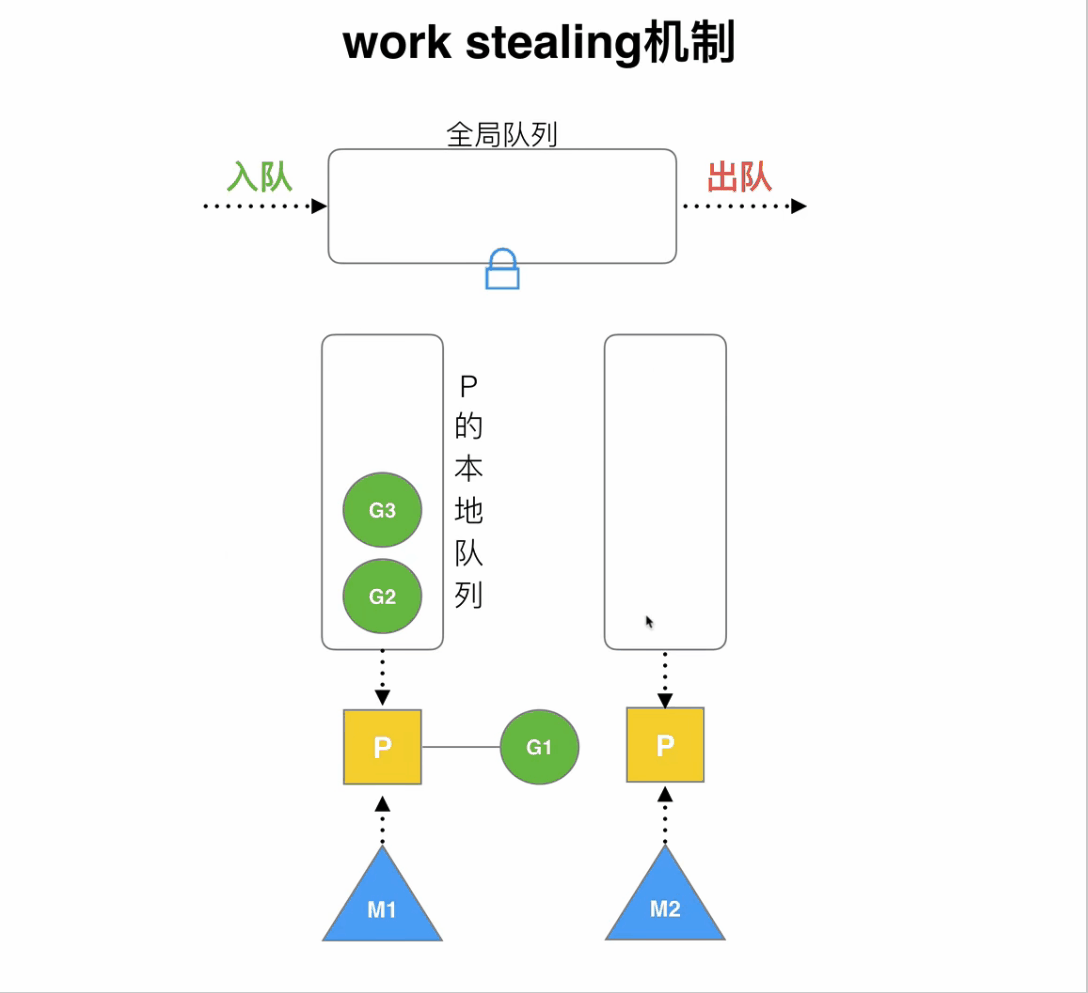
干完活的線程與其等著,不如去幫其他線程干活,于是它就去其他線程的隊列里竊取一個任務來執行。而在這時它們會訪問同一個隊列,所以為了減少竊取任務線程和被竊取任務線程之間的競爭,通常會使用雙端隊列,被竊取任務線程永遠從雙端隊列的頭部拿任務執行,而竊取任務的線程永遠從雙端隊列的尾部拿任務執行
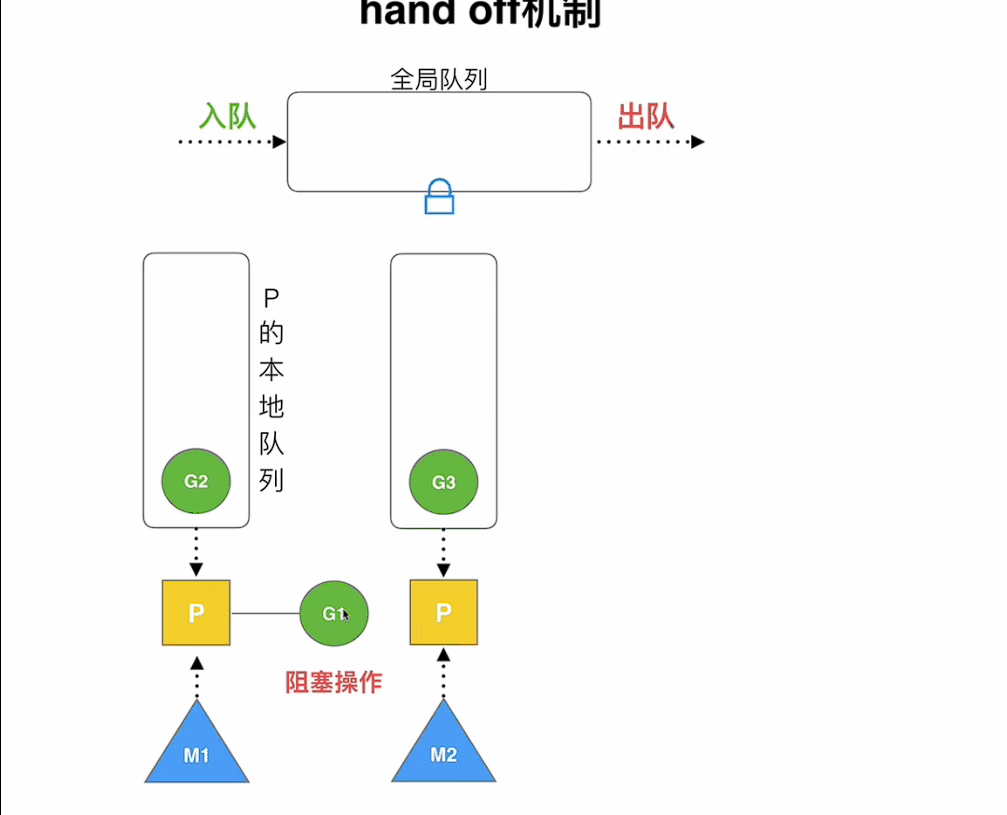
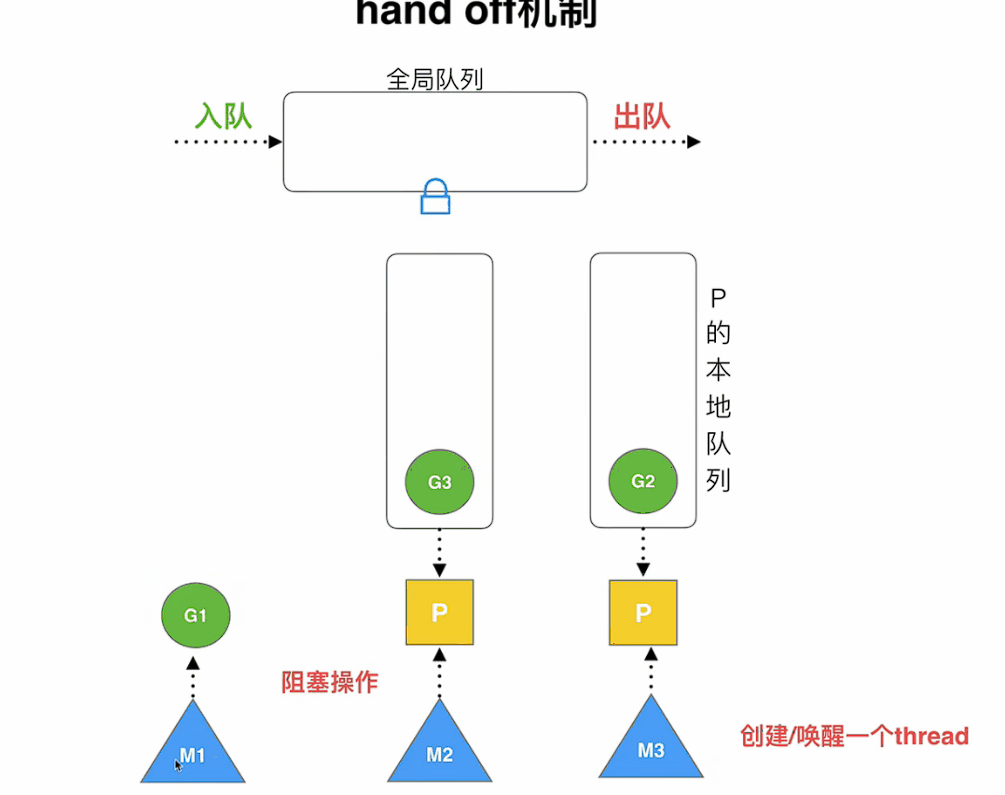
hand off機制
當本線程因為G進行系統調用阻塞時,線程釋放綁定的P,把P轉移給其他空閑的線程執行,此時
M1如果長時間阻塞,可能會執行睡眠或銷毀
2.2.2 利用并行
我們可以使用GOMAXPROCS設置P的數量,這樣的話最多有GOMAXPROCS個線程分布在多個CPU上同時運行。GOMAXPROCS也限制了并發的程度,比如GOMAXPROCS = 核數/2,則最多利用了一半的CPU核進行并行
2.2.3 搶占策略
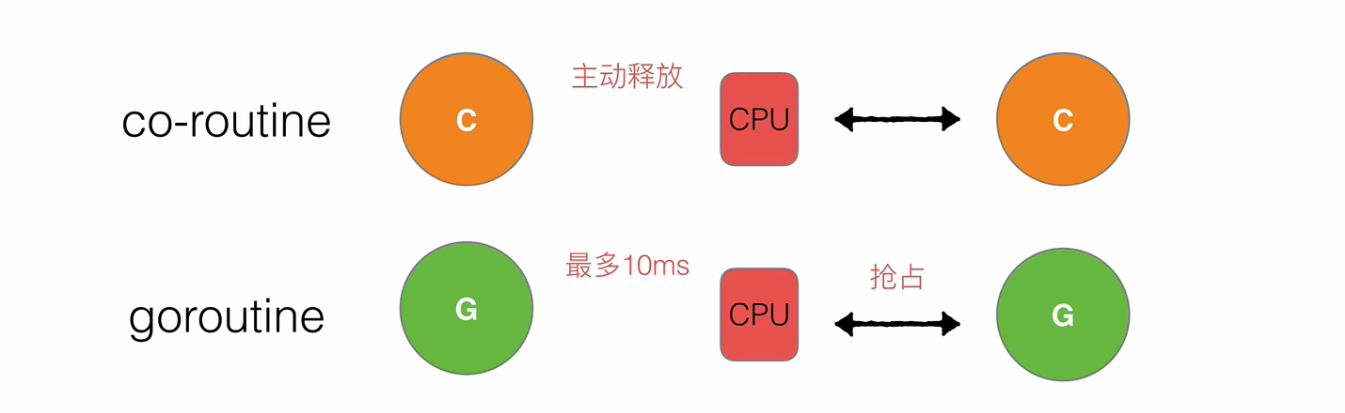
- 1對1模型的調度器,需要等待一個
co-routine主動釋放后才能輪到下一個進行使用 - golang中,如果一個
goroutine使用10ms還沒執行完,CPU資源就會被其他goroutine所搶占
2.2.4 全局G隊列
-
全局G隊列其實是復用線程的補充,當工作竊取時,優先從全局隊列去取,取不到才從別的p本地隊列取(1.17版本)
-
在新的調度器中依然有全局G隊列,但功能已經被弱化了,當M執行work stealing從其他P偷不到G時,它可以從全局G隊列獲取G
-
從其他隊列的偷取過程是從隊列尾部偷取,而隊列的執行過程是順序執行,該隊列是雙端隊列可無鎖進行。
-
每次偷取數量為隊列一半的量。
2.3?go func()經歷了那些過程
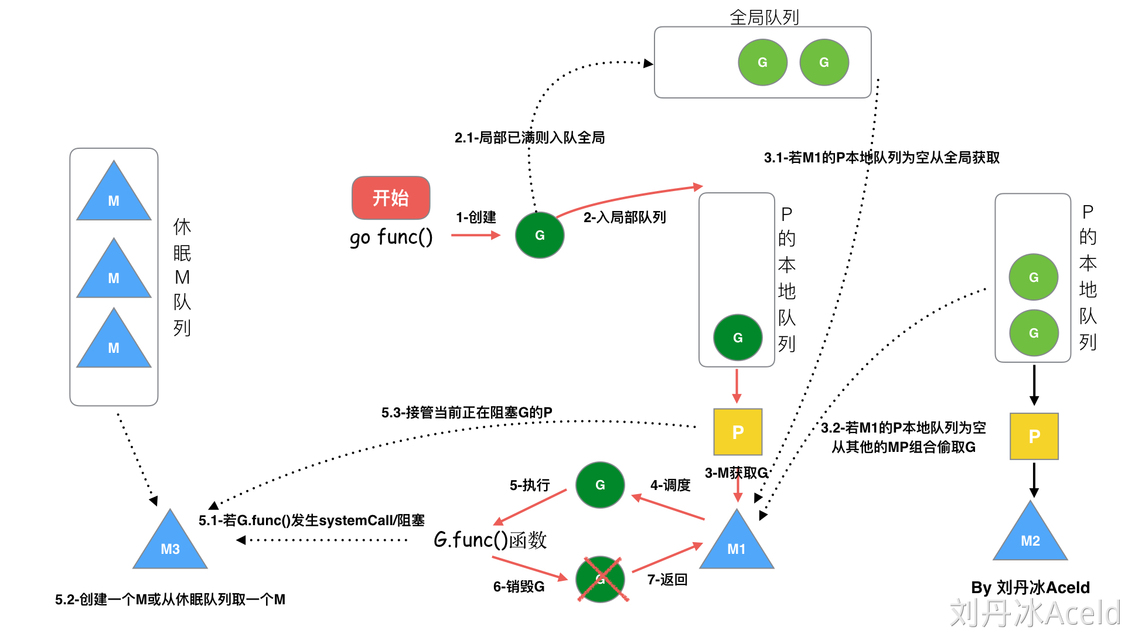
- 我們通過
go func()來創建一個goroutine - 有兩個存儲
G的隊列,一個是局部調度器P的本地隊列、一個是全局G隊列。新創建的G會先保存在P的本地隊列中,如果P的本地隊列已經滿了就會保存在全局的隊列中 - G只能運行在M中,一個
M必須持有一個P,M與P是1:1的關系。M會從P的本地隊列彈出一個可執行狀態的G來執行,如果P的本地隊列為空,就會想其他的MP組合偷取一個可執行的G來執行 - 一個M調度G執行的過程是一個循環機制
- 當M執行某一個G時候如果發生了
syscall或者其他阻塞操作,M會阻塞,如果當前有一些G在執行,runtime會把這個線程M從P中摘除(detach),然后再創建一個新的操作系統的線程(如果有空閑的線程可用就復用空閑線程)來服務于這個P - 當M系統調用結束時候,這個G會嘗試獲取一個
空閑的P執行,并放入到這個P的本地隊列。如果獲取不到P,那么這個線程M變成休眠狀態, 加入到空閑線程中,然后這個G會被放入全局隊列中
2.4 調度器的生命周期
在了解調度器生命周期之前,我們需要了解兩個新的角色
M0和G0M0(跟進程數量綁定,一比一):
- 啟動程序后
編號為0的主線程- 在全局變量
runtime.m0中,不需要在heap上分配- 負責執行初始化操作和
啟動第一個G- 啟動第一個G之后,
M0就和其他的M一樣了G0(每個M都會有一個G0):
- 每次
啟動一個M,都會第一個創建的gourtine,就是G0- G0僅用于
負責調度G- G0不指向任何
可執行的函數- 每個M都會有一個自己的G0
- 在調度或系統調用時會使用M切換到G0,再通過G0進行調度
M0和G0都是放在全局空間的
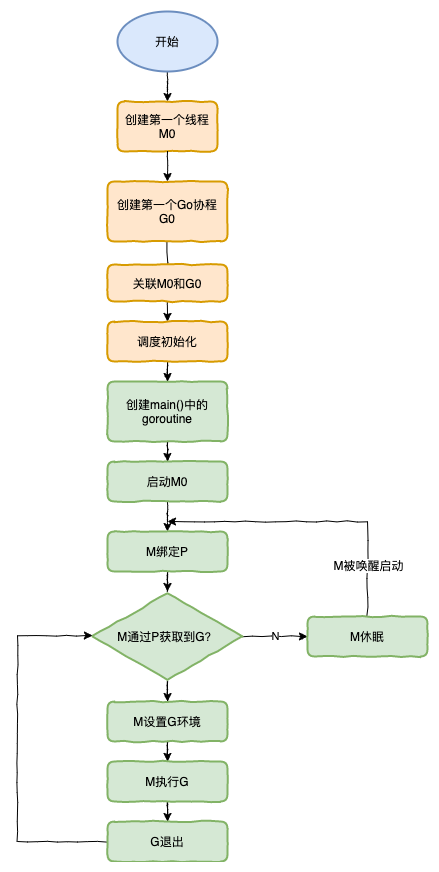
具體流程為:
我們來分析一段代碼:
package mainimport "fmt"func main() {fmt.Println("Hello world")
}
- runtime創建最初的線程m0和goroutine g0,并把2者關聯。
- 調度器初始化:初始化m0、棧、垃圾回收,以及創建和初始化由GOMAXPROCS個
P構成的P列表。 - 示例代碼中的main函數是
main.main,runtime中也有1個main函數——runtime.main,代碼經過編譯后,runtime.main會調用main.main,程序啟動時會為runtime.main創建goroutine,稱它為main goroutine吧,然后把main goroutine加入到P的本地隊列。 - 啟動m0,m0已經綁定了P,會從P的本地隊列獲取G,獲取到main goroutine。
- G擁有棧,M根據G中的棧信息和調度信息設置運行環境
- M運行G
- G退出,再次回到M獲取可運行的G,這樣重復下去,直到
main.main退出,runtime.main執行Defer和Panic處理,或調用runtime.exit退出程序。
調度器的生命周期幾乎占滿了一個Go程序的一生,
runtime.main的goroutine執行之前都是為調度器做準備工作,runtime.main的goroutine運行,才是調度器的真正開始,直到runtime.main結束而結束
2.5?協程的主動讓渡與搶占
理解
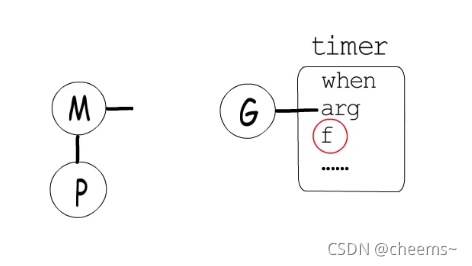
我們已經知道,協程執行time.Sleep時,狀態會從_Grunning變為_Gwaiting ,并進入到對應timer中等待,而timer中持有一個回調函數,在指定時間到達后調用這個回調函數,把等在這里的協程恢復到_Grunnable狀態,并放回到runq中。
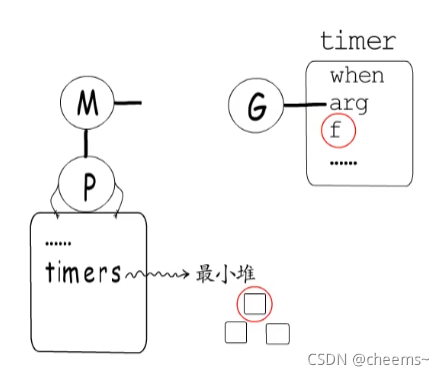
那誰負責在定時器時間到達時,觸發定時器注冊的回調函數呢?其實每個P都持有一個最小堆,存儲在P.timers中,用于管理自己的timer,堆頂timer就是接下來要觸發的那一個。
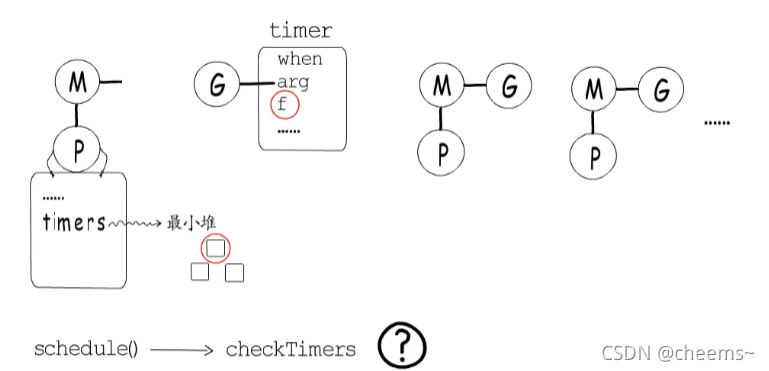
而每次調度時,都會調用checkTimers函數,檢查并執行已經到時間的那些timer,不過這還不夠穩妥,萬一所有M都在忙,不能及時觸發調度的話,可能會導致timer執行時間發生較大的偏差。
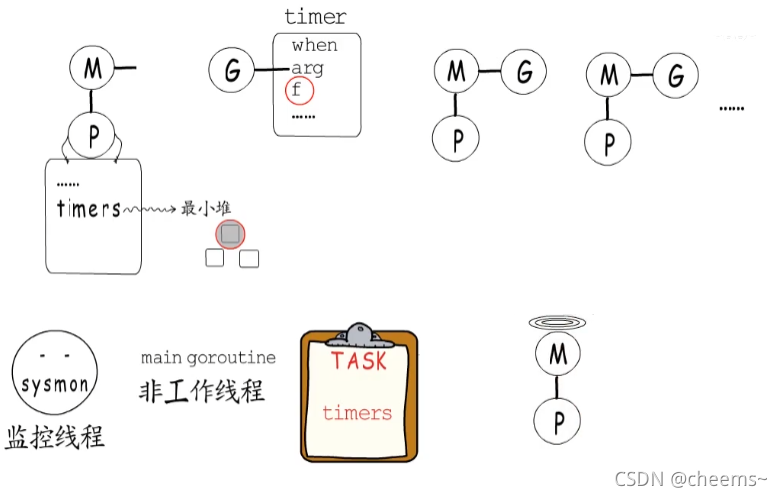
所以還會通過監控線程來增加一層保障,在介紹HelloGoroutine(GMP一)的執行過程時,我們提過監控線程是由main goroutine創建的,這個監控線程與GMP中的工作線程不同。并不需要依賴P,也不由GMP模型調度,它會重復執行一系列任務,只不過會視情況調整自己的休眠時間。其中一項任務便是保障timer正常執行,監控線程檢測到接下來有timer要執行時,不僅會按需調整休眠時間,還會在空不出M時創建新的工作線程,以保障timer可以順利執行。
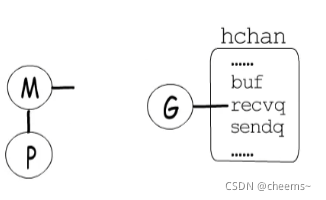
當協程等待一個channel時,其狀態也會從_Grunnig變成_Gwaiting,并進入到對應的channel的讀隊列或寫隊列中等待。
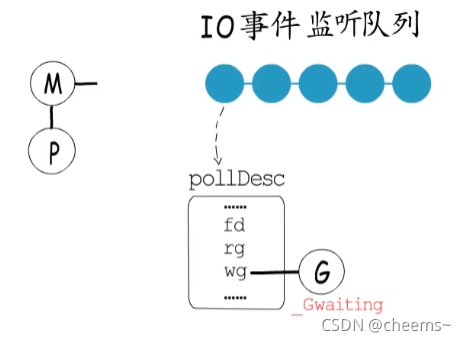
如果協程需要等待IO事件,就也需要讓出,以epoll為例,若IO事件尚未就緒,需要注冊要等待的IO事件到監聽隊列中,而每個監聽對象都可以關聯一個event data。所以就在這里記錄是哪個協程在等待,等到事件就緒時再把它恢復到runq中即可 。
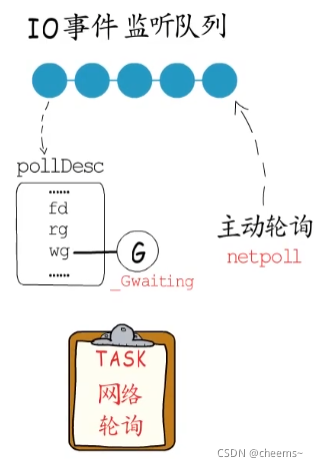
不過timer計時器有設置好的觸發時間 ,等待的channel可讀可寫或關閉了,也自會通知到相關協程,而獲取就緒的IO時間需要主動輪詢,所以為了降低IO延遲,需要時不時的那么輪詢一下,也就是執行netpoll。實際上監控線程,調度器,GC等工作過程中都會按需執行netpoll。
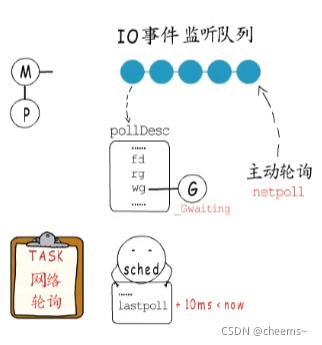
全局變量sched中會記錄上次netpoll執行的時間,監控線程檢測到距離上次輪詢已超過了10ms,就會再執行一次netpoll。
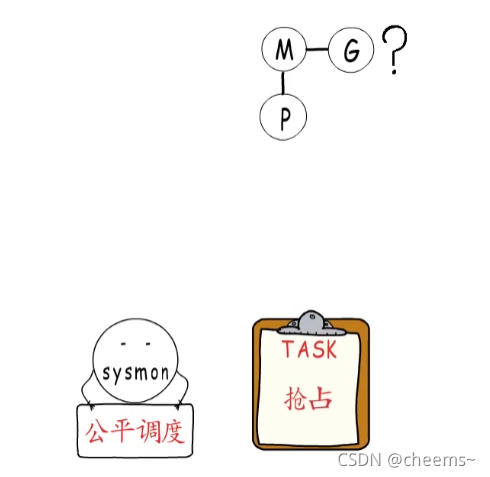
上面說的無一例外,都是協程會主動讓出的情況,那要是一個協程不會等待timer,channel或者IO事件,就不讓出了嗎?那必須不能啊,否則調度器豈不成了擺設?那怎么讓那些不用等待的協程”讓出“呢,這就是監控線程的另一個工作任務了,那就是本著公平調度的原則,對運行時間過長的G,實行”搶占“操作。
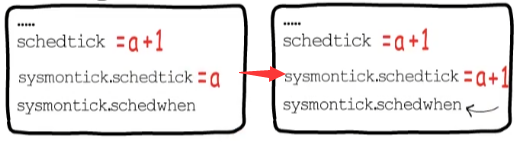
就是告訴那些運行時間超過特定閾值(10ms)的G,該讓一讓了,怎么知道運行時間過長了呢,P里面有一個schedtick字段,每當調度執行一個新的G,并且不繼承上個G的時間片時,就會把它自增1,而這個p.sysmontick中,schedwhen記錄的是上一次調度的時間,監控線程如果檢測到p.sysmontick.schedtick與p.schedtick不相等,說明這個P又發生了新的調度,就會同步這里的調度次數,并更新這個調度時間。

但是若2者相等,就說明自schedwhen這個時間點之后,這個P并未發生新的調度,或者即使發生了新的調度,也延用了之前G的時間片,所以可以通過當前時間與schedwhen的差值來判斷當前G是否運行時間過長了。
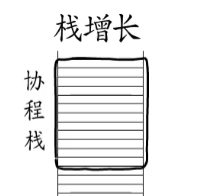
那如果真的運行時間過長了,要怎么通知它讓出呢?這就不得不提到棧增長了,除了對協程棧沒什么消耗的函數調用,Go語言編譯器都會在函數頭部插入棧相關代碼。實際上編譯器插入的棧增長代碼一共有三種。注意這里為什么是”<=“,棧是向下增長的,上面是高地址,下面是低地址
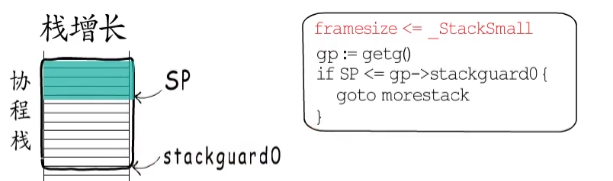
如果棧幀比較小,插入的代碼就是這樣的,這個SP表示當前協程棧使用到了什么位置,stackguard0是協程棧空間下界,所以當協程棧的消耗達到或超過這個位置時,就需要進行棧增長了。
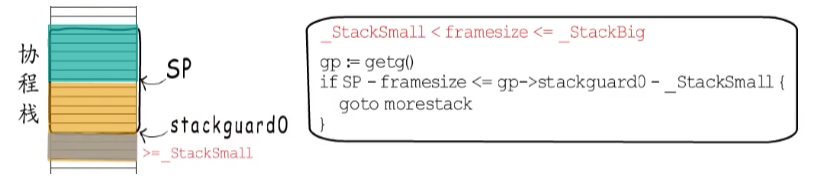
如果棧幀大小處在_StackSmall和_StackBig之間,插入的代碼是這樣的,也就是說,當前協程棧使用到這里,若再使用framesize這么多,超出stackguard0的部分大于_StackSmall了,就要進行棧增長了

而對于棧幀大小超過_StackBig的函數,插入的代碼就有所有不同了,判斷是否要棧增長的方式,本質上同第二種情況相同,而我們要關注的,是這里的stackPreempt ,它是和協程調度相關的重要標識,當runtime希望某個協程讓出CPU時,就會把它的stackguard0賦值為stackPreempt。這是一個非常大的值,真正的棧指針不可能指向這個位置,所以可以安全的用作特殊標識。

正因為stackPreempt這個值足夠大,所以這兩段代碼種的判斷結果也都會為true,進而跳轉到morestack處。

而morestack‘這里,最終會調用runtime.newstack函數,它負責棧增長工作,不過它在進行棧增長之前,會先判斷stackguard0是否等于stackPreempt,等于的話就不進行棧增長了,而是執行一次協程調度。
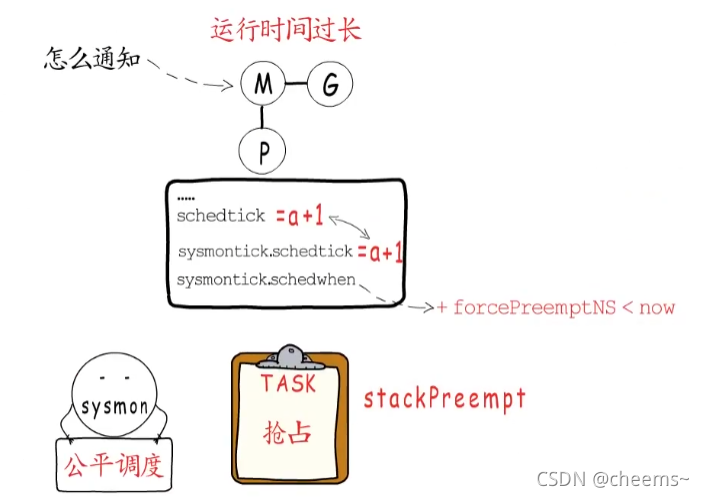
所以在協程不主動讓出時,也可以設置stackPreempt標識,通知它讓出。
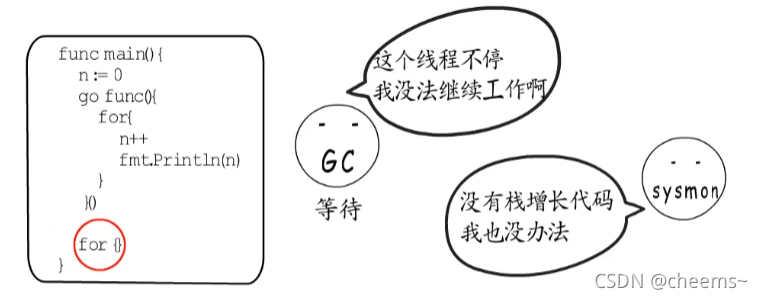
不過這種搶占方式的缺陷,就是過于依賴棧增長代碼,如果來個空的for循環,因為與棧增長無關,監控線程等也無法通過設置stackPreempt標識來實現搶占,所以最終導致程序卡死。

這一問題在1.14版本中得到了解決,因為它實現了異步搶占,具體實現在不同平臺種不盡相同。例如在Unix平臺中,會向協程關聯的M發送信號(sigPreempt),接下來目標線程會被信號中斷,轉去執行runtime.sighandler,在sighandler函數中檢測到函數信號為sigPreempt后,就會調用runtime.doSigPreempt函數,它會向當前被打斷的協程上下文中,注入一個異步搶占函數調用,處理完信號后sighandler返回,被中斷的協程得以恢復,立刻執行被注入的異步搶占函數, 該函數最終會調用runtime中的調度邏輯,這不就讓出了嘛。所以在1.14版本中,這段代碼執行之前就不會卡死了。
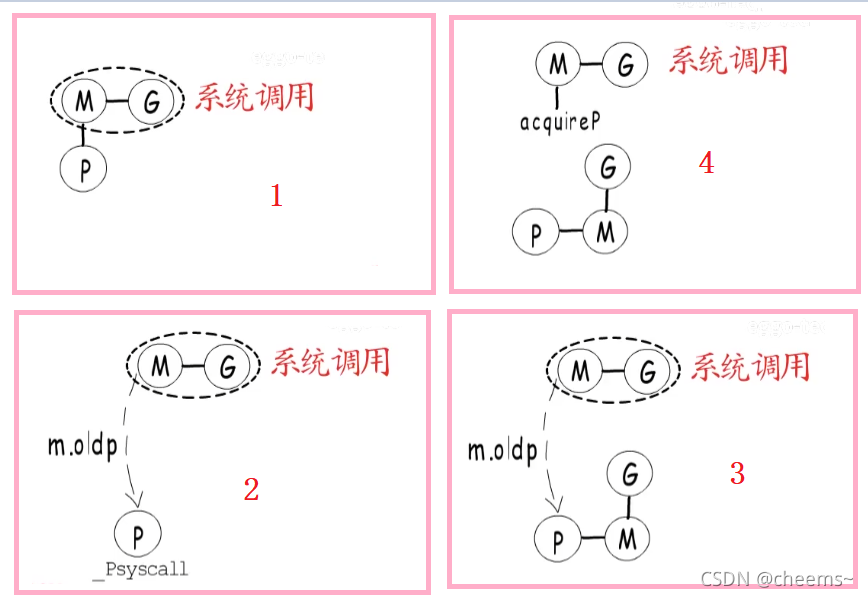
而監控線程的搶占方式又多了一種,異步搶占,其實為了充分利用CPU,監控線程還會搶占處在系統調用中的P,因為一個協程要執行系統調用,就要切換到g0棧,在系統調用沒執行完之前,這個M和這個G算是抱團了,不能被分開,也就用不到P,所以在陷入系統調用之前,當前M會讓出P,解除m.p與當前p的強關聯,只在m.oldp中記錄這個p,P的數目畢竟有限,如果有其他協程在等待執行,那么放任P如此閑置就著實浪費了,還是把它關聯到其他M繼續工作比較劃算,不過如果當前M從系統調用中恢復,會先檢測之前的P是否被占用,沒有的話就繼續使用,否則就再去申請一個,沒申請到的話,就把當前G放到全局runq中去,然后當前線程m就睡眠了。

說了這么多,不是讓出就是搶占。
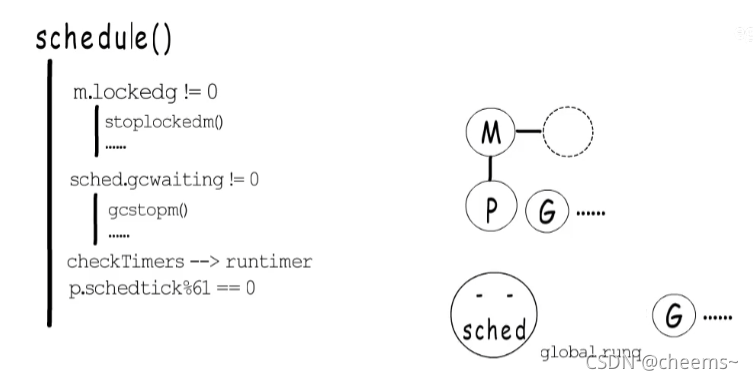
那讓出了,搶占了之后,M也不能閑著,得找到下一個待執行的G來運行,這就是schedule()的職責了。schedul這里要給這個M找到一個待執行的G,首先要確定當前M是否和當前G綁定了,如果綁定了,那當前M就不能執行其他G,所以需要阻塞當前M,等到當前G再次得到調度執行時,自會把當前M喚醒。如果沒有綁定,就先看看GC是不是在等待執行,全局變量sched這里,有一個gcwaiting標識,如果GC在等待執行,就去執行GC,回來再繼續執行調度程序。接下來還會檢查一下有沒有要執行的timer。調度程序還有一定幾率會去全局runq中獲取一部分G到本地runq中。
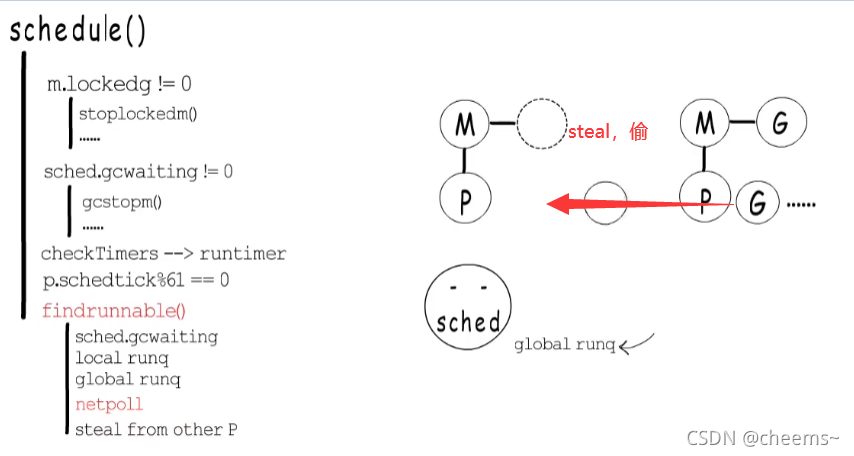
而獲取下一個待執行的G時,會先去本地runq中查找,沒有的話,就調用findrunnable(),這個函數直到獲取到待運行的G才會返回。在findrunnable()函數這里,也會判斷是否要執行GC,然后先嘗試從本地runq中獲取,沒有的話就從全局runq獲取一部分,如果還沒有,就先嘗試執行netpoll,恢復那些IO事件已經就緒了的G,它們會被放回到全局runq中,然后才會嘗試從其他P那里steal一些G 。
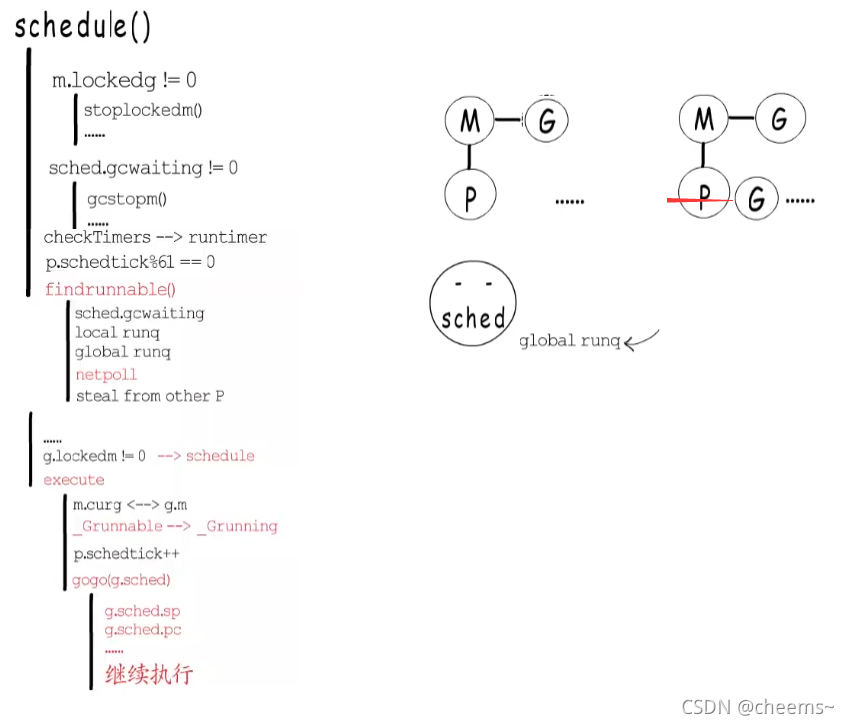
當調度程序終于獲得一個待執行的G以后,還要看看人家有沒有綁定的M,如果有的話還得乖乖的把G還給對應的M。而當前M就不得不再次進行調度了。如果沒有綁定的M,就調用excute函數在當前M上執行這個G。excute函數這里會簡歷當前M和這個G的關聯關系,并把G的狀態從_Grunnable修改為_Grunning,如果不繼承上一個執行中協程的時間片,就把P這里的調度計數加一,最后會調用gogo函數,從g.sched這里恢復協程棧指針,指令指針等,接著繼續協程的執行。
之前介紹過,協程創建時,會偽裝一個執行現場存到g.sched中,所以即使這個G初次執行,也是有一個完美的執行現場的。
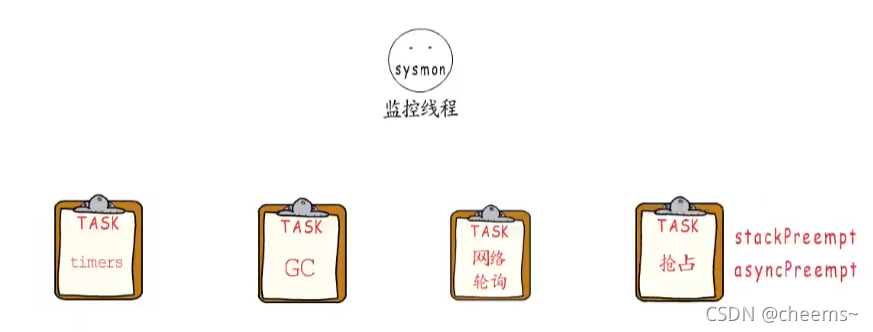
現在我們已經知道,協程在某些情況下會主動讓出,但有時也需要設置stackPreemt標識,或異步搶占的方式來通知它讓出。也了解了調度程序如何獲取待執行的G并把它運行起來。期間還穿插介紹了監控線程的主要工作任務”保障計時器正常工作,執行網絡輪詢,搶占長時間運行的,或處在系統調用的P“,這些都是為了保障程序健康高效的執行,其實監控線程還有一項任務,就是強制執行GC,待到內存管理部分再展開~
2.6 可視化的CMP編程
2.6.1 trace方式
在這里我們需要使用trace編程,三步走:
- 創建trace文件:f, err := os.Create("trace.out")
- 啟動trace:err = trace.Start(f)
- 停止trace:trace.Stop()
然后再通過
go tool trace工具打開trace文件go tool trace trace.out
package mainimport ("fmt""os""runtime/trace"
)// trace的編碼過程
// 1. 創建文件
// 2. 啟動
// 3. 停止
func main() {// 1.創建一個trace文件f, err := os.Create("trace.out")if err != nil {panic(err)}defer func(f *os.File) {err := f.Close()if err != nil {panic(err)}}(f)// 2. 啟動traceerr = trace.Start(f)if err != nil {panic(err)}// 正常要調試的業務fmt.Println("hello GMP")// 3. 停止tracetrace.Stop()
}
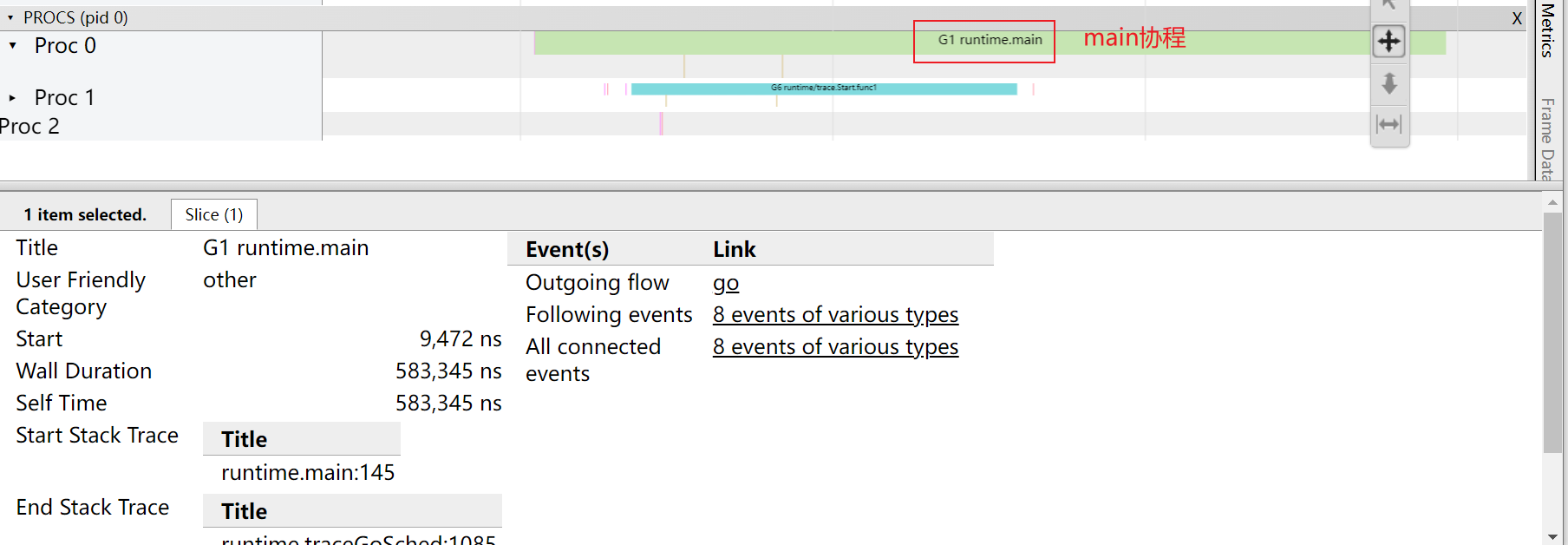
打開后我們進入網頁點擊view trace,然后就能看到分析信息

G的信息:
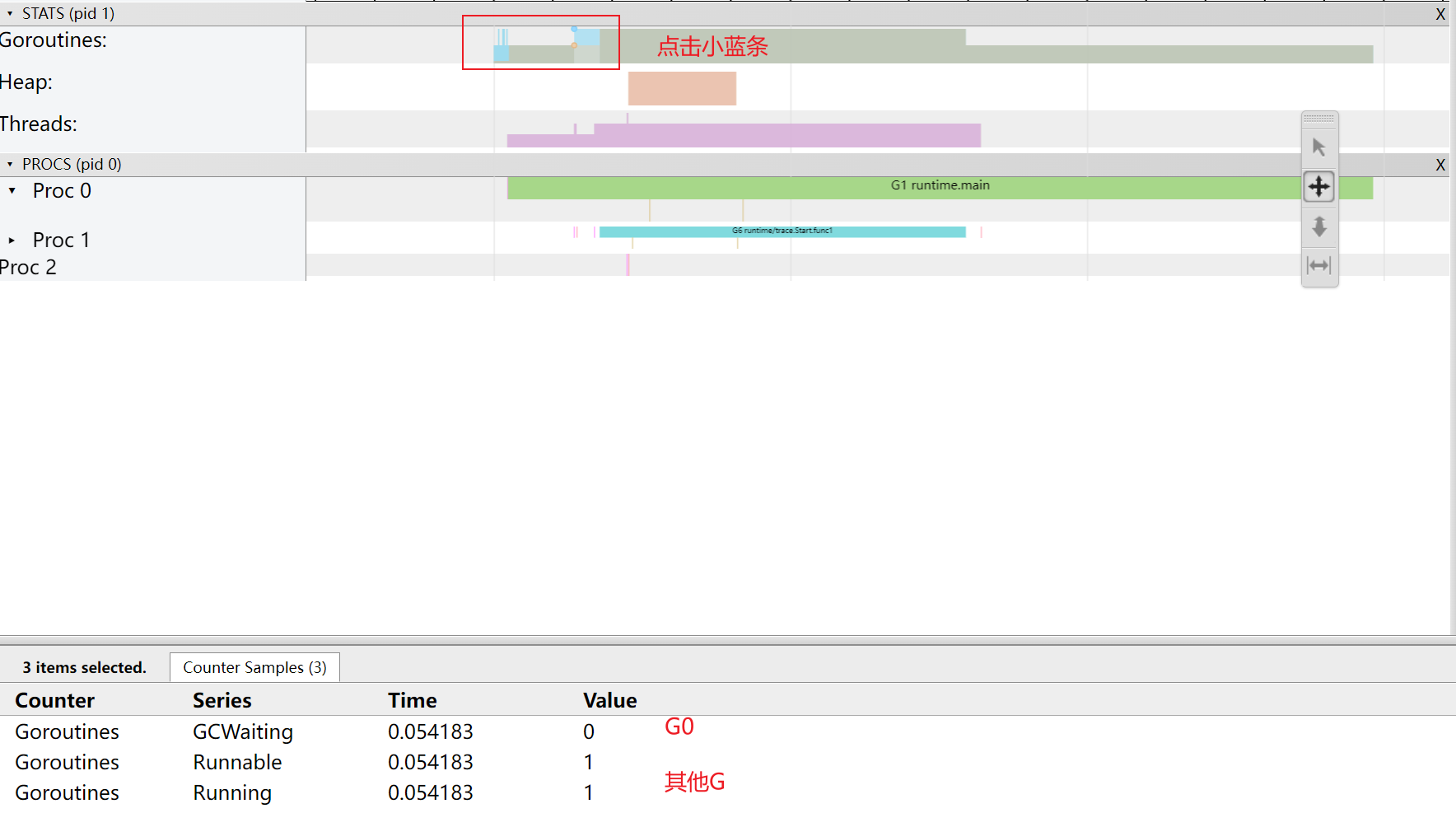
M的信息:
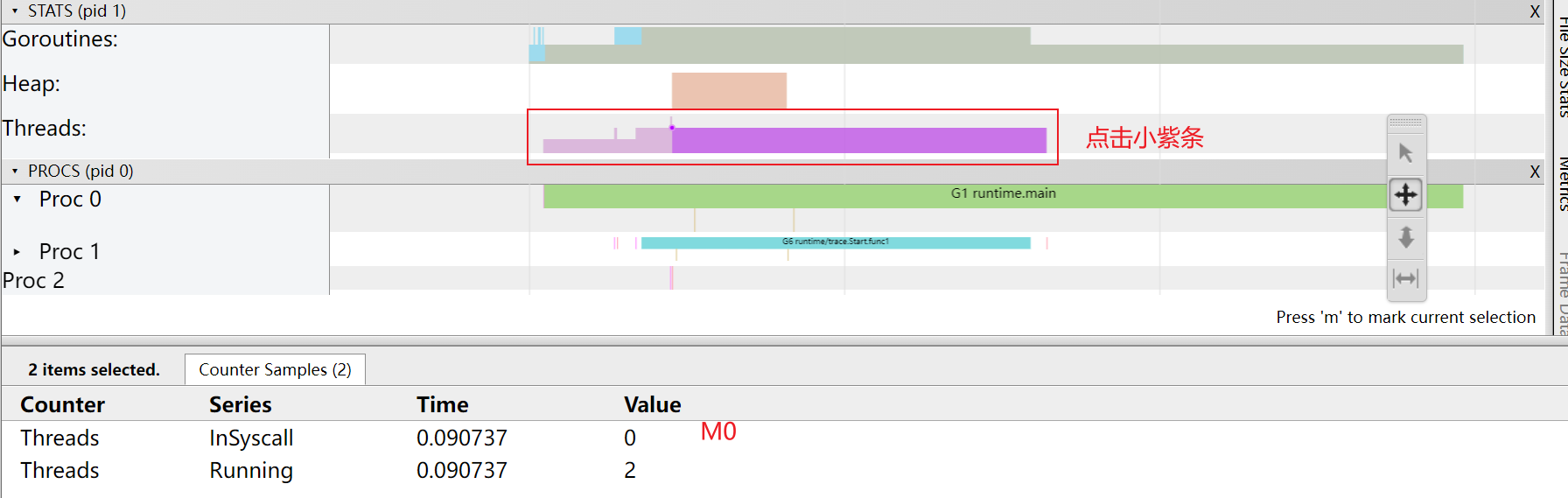
P的信息:
2.6.2 debug方式
使用debug方式可以不需要trace文件
先搞一段代碼
package mainimport ("fmt""time"
)func main() {for i := 0; i < 5; i++ {time.Sleep(time.Second)fmt.Println("hello GMP")}
}
debug執行一下
$ GODEBUG=schedtrace=1000 ./debug.exe SCHED 0ms: gomaxprocs=8 idleprocs=7 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] SCHED 1008ms: gomaxprocs=8 idleprocs=8 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] hello GMP SCHED 2009ms: gomaxprocs=8 idleprocs=8 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] hello GMP SCHED 3010ms: gomaxprocs=8 idleprocs=8 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] hello GMP hello GMP SCHED 4017ms: gomaxprocs=8 idleprocs=8 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] hello GMP
SCHED:調試信息輸出標志字符串,代表本行是goroutine調度器的輸出;0ms:即從程序啟動到輸出這行日志的時間;gomaxprocs: P的數量,本例有2個P, 因為默認的P的屬性是和cpu核心數量默認一致,當然也可以通過GOMAXPROCS來設置;idleprocs: 處于idle狀態的P的數量;通過gomaxprocs和idleprocs的差值,我們就可知道執行go代碼的P的數量;threads: os threads/M的數量,包含scheduler使用的m數量,加上runtime自用的類似sysmon這樣的thread的數量;spinningthreads: 處于自旋狀態的os thread數量;idlethread: 處于idle狀態的os thread的數量;runqueue=0: Scheduler全局隊列中G的數量;[0 0]: 分別為2個P的local queue中的G的數量。
參考文章
GolangGMP模型 GMP(三):協程讓出,搶占,監控與調度 - cheems~ - 博客園
https://github.com/fengyuan-liang/notes/blob/main/GoLang/golang%E5%A4%A7%E6%9D%80%E5%99%A8GMP%E6%A8%A1%E5%9E%8B.md
)





)



)

mysql 8.0.41圖文詳細安裝教程)


)



