250408_解決加載Cifar10等大量數據集速度過慢,耗時過長的問題(加載數據時多線程的坑)
在做Cifar10圖像分類任務時,發現每個step時間過長,且在資源管理器中查看顯卡資源調用異常,主要表現為,顯卡周期性調用,呈現隔一會兒動一下的情況(間隔時間過大導致不能同時截到兩個峰值)。
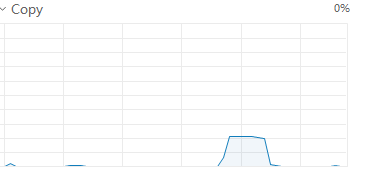
通過檢測每步耗費時間發現,載入數據集的時間遠遠大于前向處理的時間。
在以下參數情況下
batch_size=16
num_workers=20 # 線程數
載入Cifai10數據集的時間為60s左右,前向計算時間僅為0.002s,浪費了大量的時間用于載入及傳輸數據。
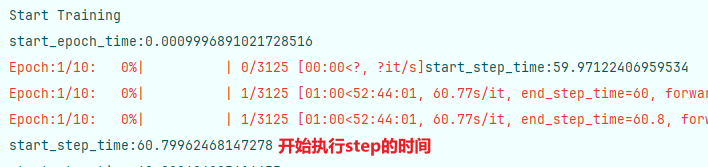
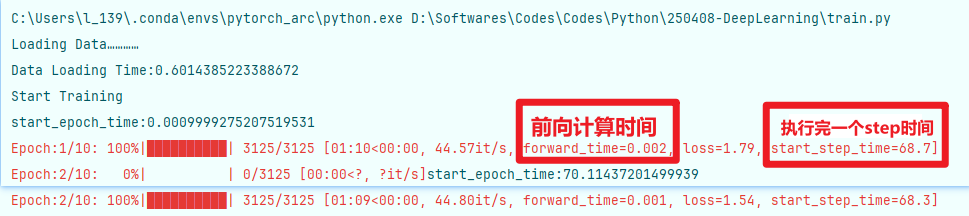
先說結論,是多線程的問題,線程過多導致多線程沖突,修改num_workers=0即可解決問題
解決過程
修改過程中查閱很多資料和大佬博客,嘗試了重新定義自己的dataset方法,將transform定義到初始化方法中,避免每獲取一次數據就執行一遍transform,而是改為在把數據載入內存時一次全部處理完(詳見解決pytorch中Dataloader讀取數據太慢的問題_dataloader數據讀取慢-CSDN博客)
然后重新定義自己加載數據的方法,大佬文中沒給加載的方法,我這里補充
def data_loader(batch_size=4,num_workers=2):""":param batch_size: 批次大小:param num_workers: 線程數:return:train_loader:訓練數據加載器test_loader:測試數據加載器class:分類類別"""root_dir="./data"transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)),])train_dataset = CUDACIFAR10(root=root_dir,train=True,to_cuda=True, # 使用XPU(或GPU)half=False, # 不使用半精度浮點數download=True, # 如果數據集尚未下載,則下載pre_transform=transform)trainloader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True,num_workers=num_workers)test_dataset = CUDACIFAR10(root=root_dir,train=False,to_cuda=True, # 使用XPU(或GPU)half=False, # 不使用半精度浮點數download=True, # 如果數據集尚未下載,則下載pre_transform=transform)testloader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=True,num_workers=num_workers)classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')return trainloader,testloader,classes
然后加載數據集發現報錯:
RuntimeError: _share_filename_: only available on CPU
多線程加載僅支持在cpu上進行,我們這樣的處理方法已經提前將數據載入到gpu或xpu上,無法使用多線程,遂將num_workers修改為0,發現問題解決了。數據載入速度變得很快。遂準備復現并記錄問題,發現把大佬數據類代碼注釋后,使用官方cifar10數據類代碼,加載速度仍較快,核實發現應該是多線程的問題。
嘗試多組參數
batch_size=16
num_workers=0
每個step執行時間為11-12s左右
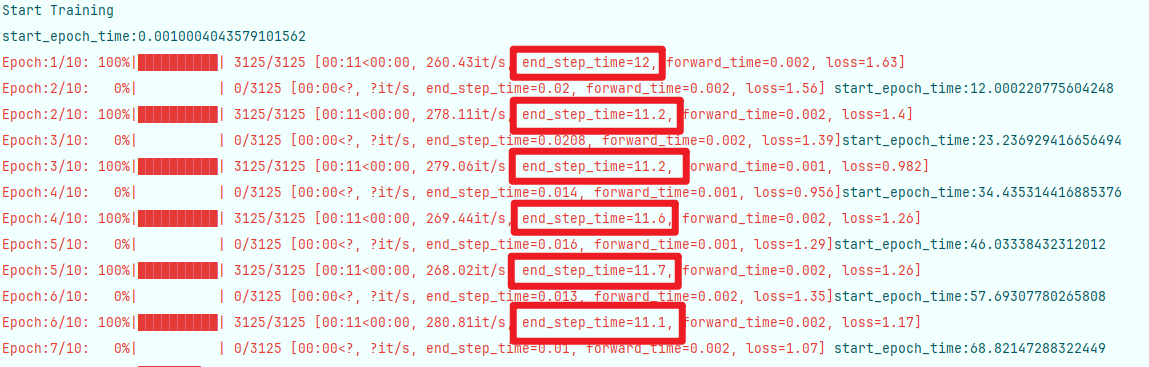
調整參數
batch_size=32
num_workers=1
此時顯卡調用情況為長矩形,持續調用,但占用率并不高,在33-34左右波動
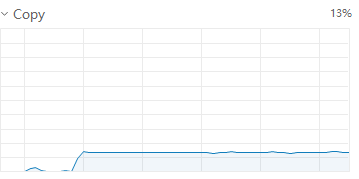
此時顯卡占用情況呈現連續峰谷,占用波峰為50左右,每個step執行時間縮短為6-8秒
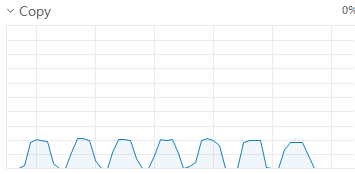
因顯卡調用仍有間隙,嘗試增大batchsize
batch_size=64
num_workers=1
顯卡占用情況仍呈現連續峰谷,占用波峰為30左右,每個step執行時間縮短為6-7秒
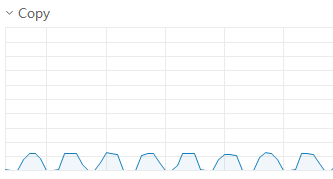
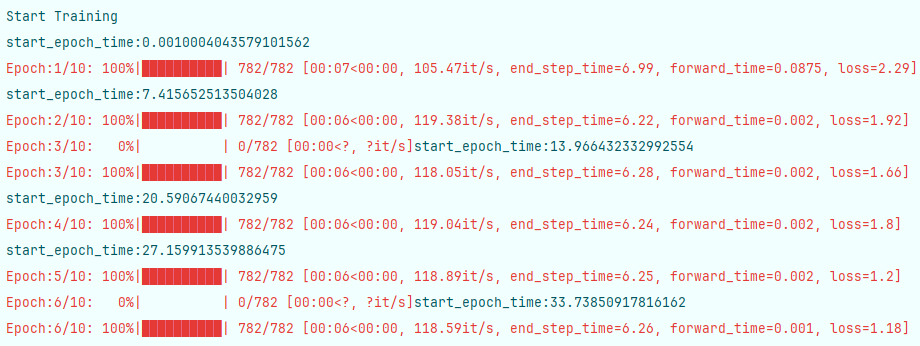
將batch_size進一步放大到128,顯卡占用波峰繼續縮小為20左右,但每個step的時間未明顯降低
嘗試64與2的搭配,仍與32與1的搭配執行時間及顯卡占用大致相同,執行時間誤差1s,占用誤差50%。
嘗試128與2的搭配,結果與64,1的搭配情況大致相同,得結論,與比值有關。
| batch_size | num_workers | 每個step執行時間(秒) | 顯卡占用情況描述 | 顯卡占用率波峰(%) | 性能優化效果(與初始參數對比) |
|---|---|---|---|---|---|
| 16 | 20 | 70 | 顯卡周期性調用,間隔時間過長,不能充分利用顯卡資源,大部分時間在等待數據加載 | - | 數據載入時間過長,顯卡資源浪費嚴重 |
| 16 | 0 | 11-12 | 顯卡調用情況為長矩形,持續調用,但占用率不高,波動在33-34%左右 | 33-34 | 數據載入速度顯著提高,顯卡資源利用率有所提升,但仍有提升空間 |
| 32 | 1 | 6-8 | 顯卡調用情況呈現連續峰谷,占用波峰約為50% | 50 | 數據載入速度進一步提高,顯卡資源利用率提升,step執行時間縮短 |
| 64 | 1 | 6-7 | 顯卡調用情況仍呈現連續峰谷,占用波峰約為30% | 30 | 數據載入速度進一步提高,顯卡資源利用率提升,step執行時間進一步縮短 |
| 128 | 1 | 未明顯降低 | 顯卡占用波峰繼續縮小為20%左右 | 20 | 數據載入速度未明顯提升,顯卡資源利用率降低,step執行時間未明顯縮短 |
| 64 | 2 | 與32,1搭配大致相同 | 與32,1搭配大致相同 | - | 與32,1搭配大致相同,執行時間誤差1秒,占用誤差5% |
| 128 | 2 | 與64,1搭配大致相同 | 與64,1搭配大致相同 | - |
batch_size 和 num_workers 的比值對性能影響較大,需要根據具體情況進行調整。在測試中,batch_size=32, num_workers=1 和 batch_size=64, num_workers=1 的搭配效果較好,能夠在數據載入速度和顯卡資源利用率之間取得較好的平衡
進一步思考
發現若如所測數據,
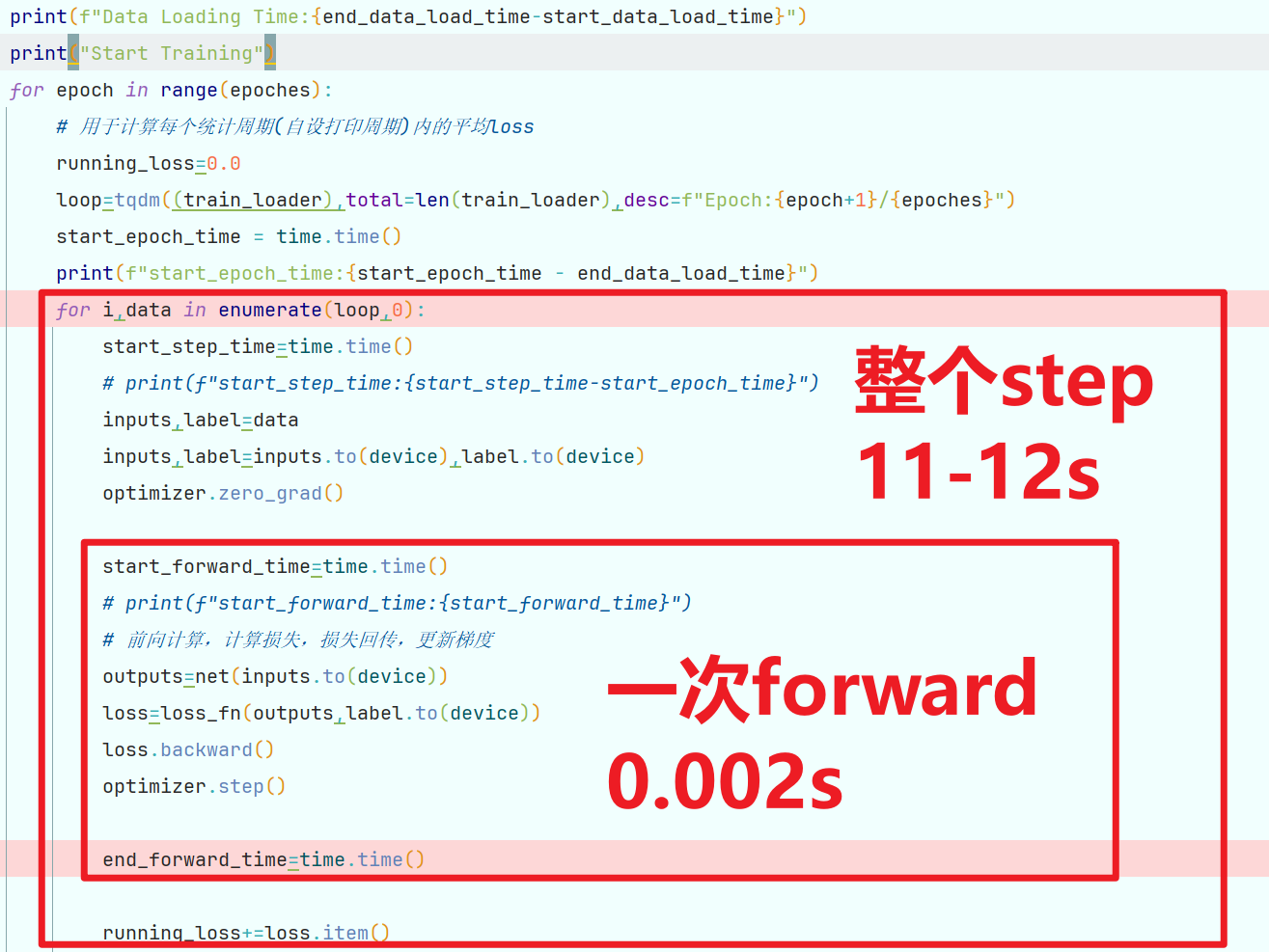
仍有大量時間浪費在cpu與gpu的通信及其他步驟上
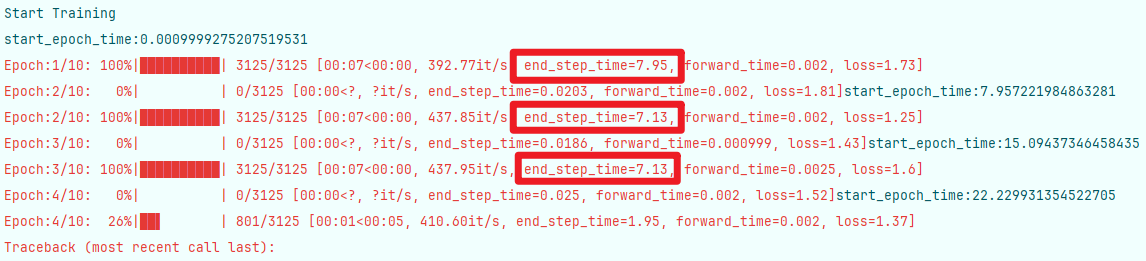
使用前文所提到的大佬的數據類初始化方法(避免多次transform),在batch_size=16,num_workers=0的參數基礎上,測得單次step時間可壓縮到7-8s,即節省3-4s。其余參數大家自行嘗試。
本人初學小白,如有錯誤勞煩大佬指正

)



- 4)



 —— 理論、案例與交互式 GUI 實現)
-- 動畫)

——創建自己的GradioTool)






