論文標題
WorkTeam: Constructing Workflows from Natural Language with Multi-Agents
論文地址
https://arxiv.org/pdf/2503.22473
作者背景
華為,北京大學
動機
當下AI-agent產品百花齊放,盡管有ReAct、MCP等框架幫助大模型調用工具,可以初步實現【需求】->【任務規劃】,但在實踐中我們或多或少還是往會去編排工作流——單純依靠大模型本身的任務理解與規劃能力,難以生成滿足復雜業務需要的執行計劃;
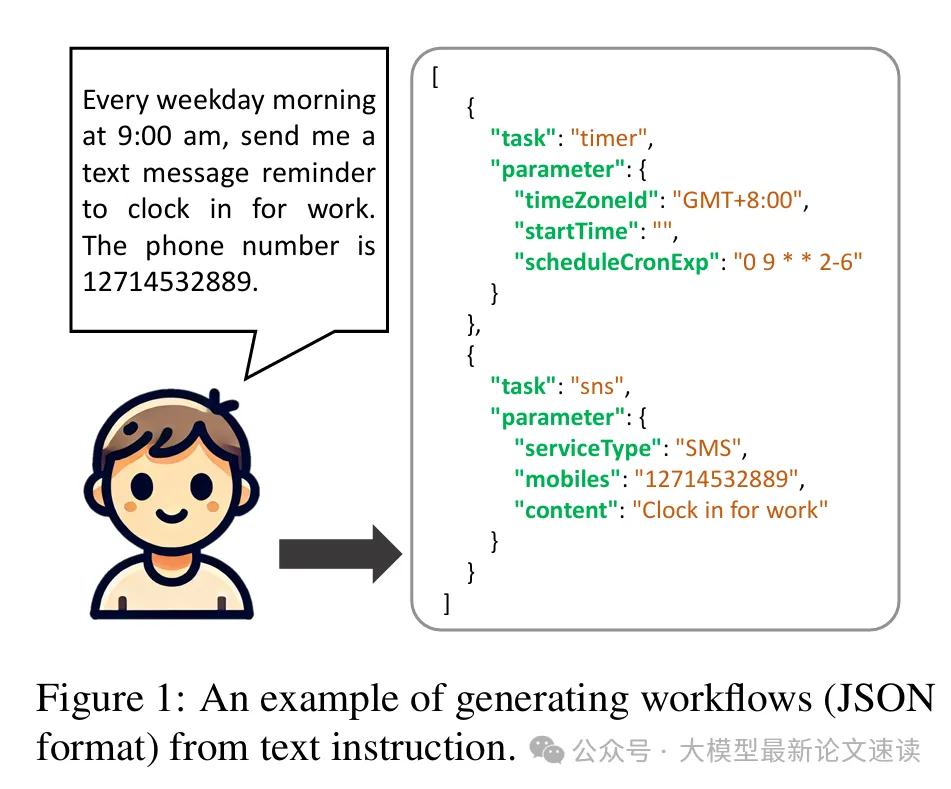
于是本文設計了一種新的工作流生成框架,旨在提高大模型理解任務并調用工具的準確性
本文方法
本文提出WorkTeam框架,對原本由一個LLM規劃器承擔的職責進行了拆分:
一、監督agent
理解并拆分用戶問題,生成解決問題的子步驟(高層計劃),委派另外兩個agent生成工具編排結果與可執行的工作流,并檢查它們是否滿足用戶意圖、步驟是否完整正確。如果發現問題,監督者可以要求返工,或者嘗試其他解決思路?
二、協調agent
基于監督agent委派的子任務,生成工具編排結果。具體地,協調agent會規劃調用兩個工具:
組件篩選工具: 基于SentenceBERT嵌入模型,從組件庫中檢索出與當前指令最相關的一組候選組件
組件編排工具: 基于一個尺寸小一些的大模型,根據用戶指令和篩選出來的候選組件,生成符合邏輯的組件調用序列
三、填充agent
專注于填充工具調用序列的參數,它也會調用兩個工具:
模板查找工具: 根據編排流程中的每個組件,從工具庫中提取該組件的參數說明以及一個空白參數模板?(列出了該組件所需參數和上默認值,目的是降低參數填充任務的復雜度)
參數填充工具: 根據模板查找的結果,利用LLM分析用戶query和監督agent的指示,從中提取出所需要的具體信息并填入對應的參數模板,最終得到一個可執行的工作流
整個流程如下圖所示:
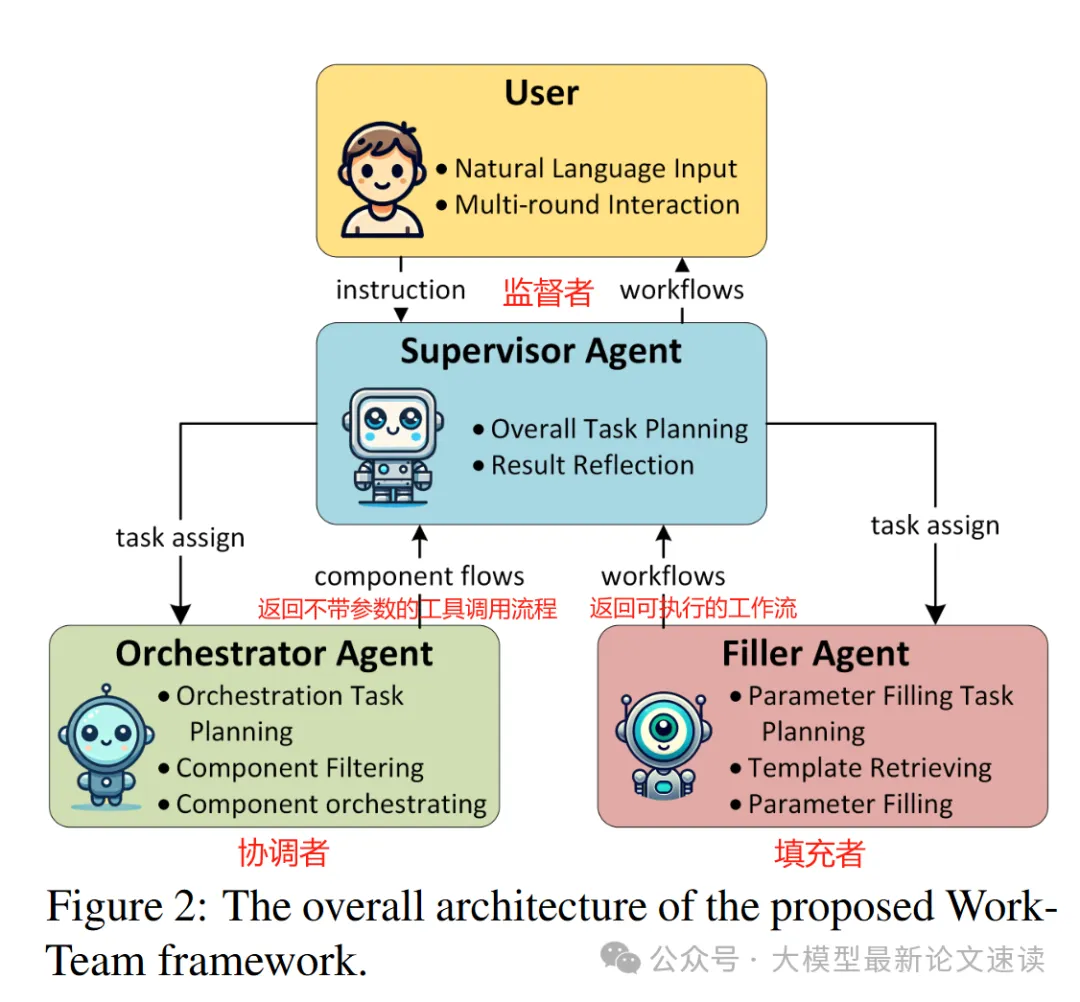
這樣的拆分看起來十分簡單,但它其實抓住了當前單一大模型難以生成準確工作流的痛點。考慮我們在多agent系統中對大模型規劃器的期望:
- 理解用戶問題并規劃解決思路;
- 理解工具并編排工具調用過程;
- 填充符合工具協議的參數;
- 處理不符合預期的結果
這些任務都有一定難度,并且在執行過程中一般會產生極長的上下文,揉在一起交給大模型的是一個難度很大的任務,于是導致實踐中不得不像打補丁一樣,添加各種人工書寫的業務邏輯以解決大模型的紕漏。
這時候將上述職能拆分到多個agent中,便可以大大降低每個大模型處理任務的難度
實驗結果
一、測試數據
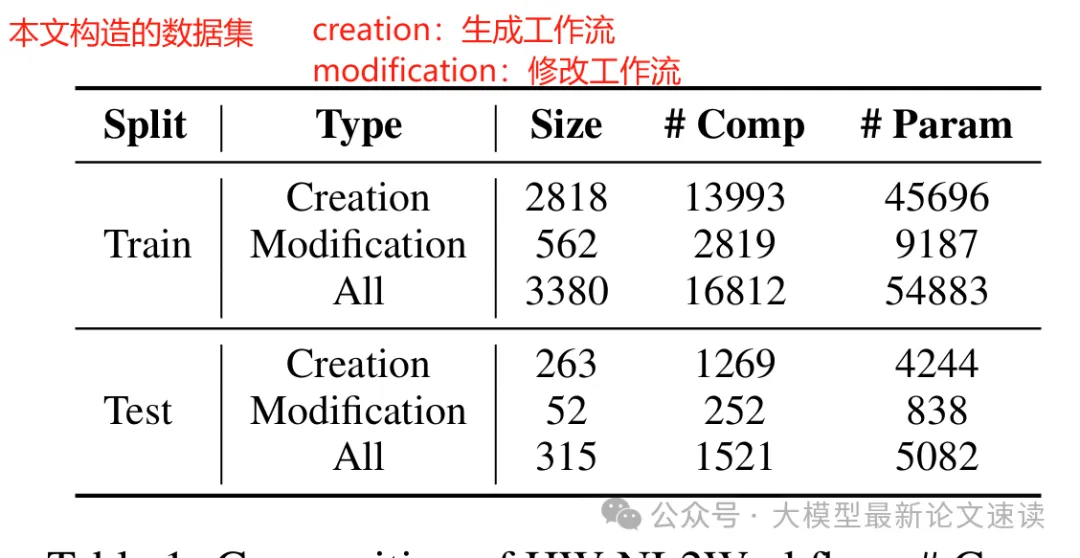
由于目前沒有公開可用的NL2Workflow基準數據集,作者構建了HW-NL2Workflow,包含3695個真實的企業工作流樣本,用于訓練和評估(也是此工作的貢獻之一)
二、測試對象
實驗組: 三個agent都基于Qwen2.5-72B-Instruct構建;組件編排工具和參數填充工具使用LLaMA3-8B-Instruct實現,并在上述數據集上進行了微調;組件過濾工具則使用了微調后的SentenceBERT
對照組: GPT-4o、Qwen2.5-72B-Instruct、Qwen2.5-7B-Instruct、LLaMA3-8B-Instruct(單規劃器),以及一個針對NL2Workflow場景的RAG
三、測試指標
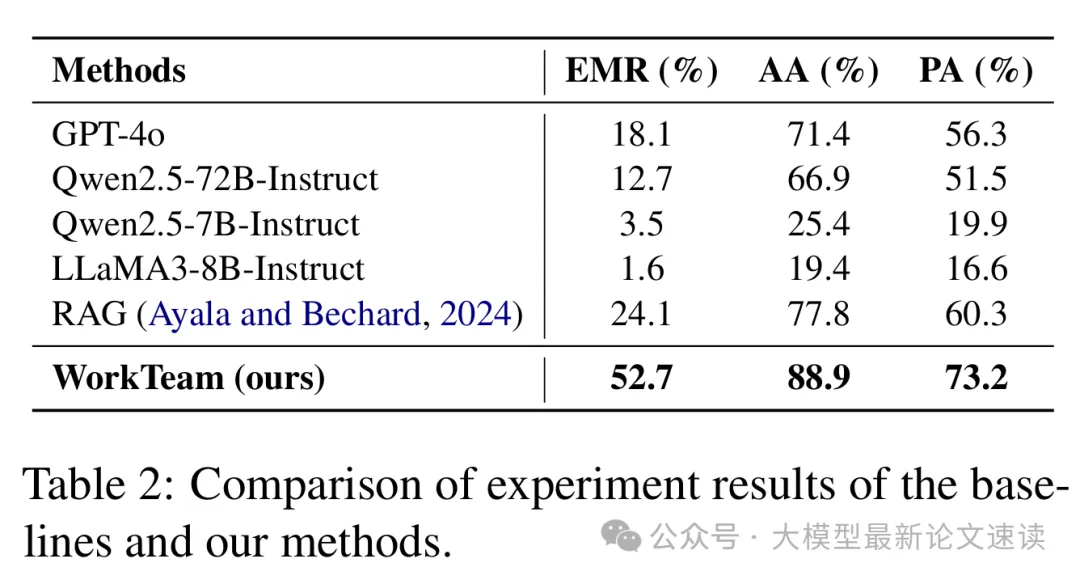
精確匹配率(EMR): 模型生成的整個工作流與參考答案完全一致的比例,包括組件的種類、順序以及所有參數值都要匹配。這是一個嚴格的“全對”指標,只有工作流毫無差錯地重現參考方案才算成功
流程編排準確率(AA): 只關注組件序列的正確性,忽略參數填充是否正確。如果模型選用了正確的組件并按正確順序排列,即視為該樣本在編排上是正確的,即使某些參數值有誤也不影響此指標。該指標反映模型理解用戶指令中邏輯步驟的能力。
參數填充準確率(PA): 評價參數層面的正確性。它統計生成的所有組件參數中,有多少比例的參數值與參考答案一致。計算方式為匹配的參數數量除以測試集中參數總數,不關心流程是否正確
四、測試結果
單Agent模型在復雜任務上表現不佳——即便是最強的GPT-4,其EMR也僅有18.1%,Qwen-72B為12.7%,而較小模型(Qwen-7B、LLaMA-8B)幾乎完全失敗;
檢索增強的基線(引用現有工作的RAG-NL2Workflow方法)后,性能有所改善,而本文提出的WorkTeam效果大幅領先
總結
本文提出的workTeam方法,盡管有更大的計算開銷(需要3個大尺寸LLM),但從效果上來看極大提升了LLM生成復雜工作流的準確性;
agent的拆分簡單易實現,實際上就是對大模型規劃器職責進行分治,不讓一個LLM去負責多個高難度的長上下文任務






)



)


)
)




