
接著上篇文章《輕量化大模型微調工具XTuner指令微調實戰(上篇)》來接著寫教程。
一、模型轉換
模型訓練后會自動保存成 PTH 模型(例如?iter_500.pth),我們需要利用?xtuner?convert?pth_to_hf?將其轉換為 HuggingFace 模型,以便于后續使用。具體命令為:
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH} ${SAVE_PATH}# 例如:xtuner convert pth_to_hf ./config.py ./iter_500.pth ./iter_500_hfxtuner convert pth_to_hf ./qwen1_5_1_8b_chat_qlora_alpaca_e3.py /root/autodl-tmp/project/day11/xtuner/work_dirs/qwen1_5_1_8b_chat_qlora_alpaca_e3/iter_4000.pth /root/autodl-tmp/llm/hf第1個參數CONFIG_NAME_OR_PATH:配置文件路徑,也就是執行微調指令的配置文件。
第2個參數PTH:XTuner微調生成文件,給絕對路徑。
第3個參數SAVE_PATH:模型轉換保存的地方,需手動創建一個目錄。
二、模型合并
如果您使用了 LoRA / QLoRA 微調,則模型轉換后將得到 adapter 參數,而并不包含原 LLM 參數。如果您期望獲得合并后的模型權重,那么可以利用?xtuner?convert?merge?:
xtuner convert merge ${LLM} ${ADAPTER_PATH} ${SAVE_PATH}
# 例如:xtuner convert merge internlm/internlm2-chat-7b ./iter_500_hf ./iter_500_merged_llmxtuner convert merge /root/autodl-tmp/llm/Qwen/Qwen1.5-1.8B-Chat /root/autodl-tmp/llm/hf /root/autodl-tmp/llm/Qwen1.5-1.8B-Chat-hf第1個參數LLM:微調時選擇的原始的大模型;
第2個參數ADAPTER_PATH:模型轉換時保存的路徑;
第3個參數SAVE_PATH:模型合并成功保存的路徑,需手動創建一個目錄;
三、驗證模型效果
1、安裝和運行LMDeploy推理框架
安裝和運行的教程請看《Ollama、vLLM和LMDeploy這三款主流大模型部署框架》?。
2、Python寫一個chat對話
寫一個python代碼,名字為:chat_to_llm.py
#多輪對話
from openai import OpenAI#定義多輪對話方法
def run_chat_session():#初始化客戶端client = OpenAI(base_url="http://localhost:23333/v1/",api_key="token-abc123")#初始化對話歷史chat_history = []#啟動對話循環while True:#獲取用戶輸入user_input = input("用戶:")if user_input.lower() == "exit":print("退出對話。")break#更新對話歷史(添加用戶輸入)chat_history.append({"role":"user","content":user_input})#調用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/llm/Qwen1.5-1.8B-Chat-hf")#獲取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新對話歷史(添加AI模型的回復)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("發生錯誤:",e)break
if __name__ == '__main__':run_chat_session()LMDeploy默認的端口號是23333? ,api_key隨便填寫一個即可。
python chat_to_llm.py # 運行python文件用數據集里的input與大模型對話 ,效果還不錯。
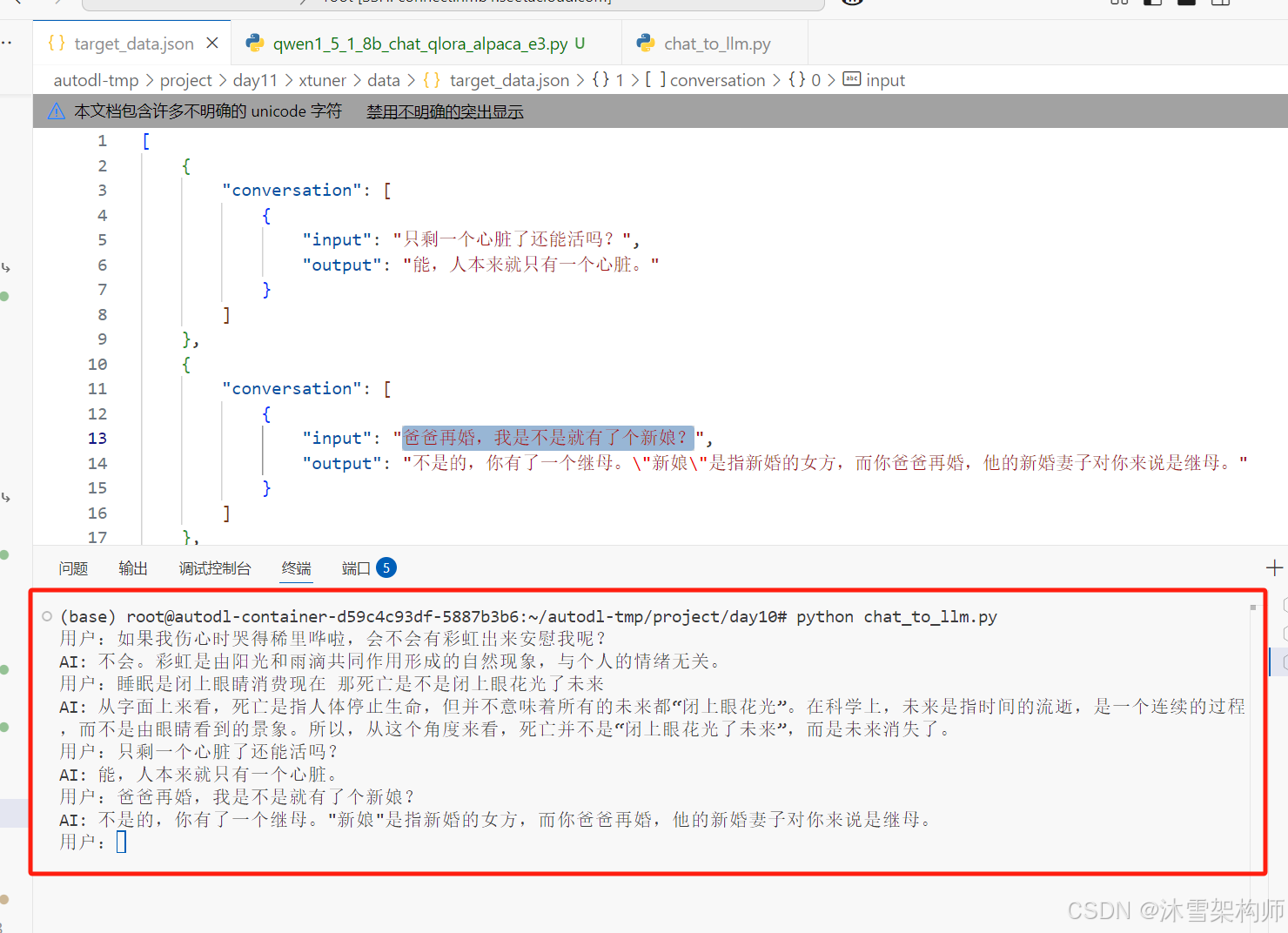
注意:
1、之所以使用LMDeploy,是因為XTuner與LMDeploy都是一家公司出品,使用的對話模版是一致的。
2、若使用vLLM等其他推理框架,請確保對話模版要一致,可以將XTuner的對話模版轉成vLLM需要的jinja2格式的文件。

introduction to RL)

與官方源要求的版本(`24.2.7`)不一致)

語音專業版高質量的分析)

![洛谷題單3-P1217 [USACO1.5] 回文質數 Prime Palindromes-python-流程圖重構](http://pic.xiahunao.cn/洛谷題單3-P1217 [USACO1.5] 回文質數 Prime Palindromes-python-流程圖重構)




![P1036 [NOIP 2002 普及組] 選數(DFS)](http://pic.xiahunao.cn/P1036 [NOIP 2002 普及組] 選數(DFS))




![[C++面試] new、delete相關面試點](http://pic.xiahunao.cn/[C++面試] new、delete相關面試點)

)