一、TL;DR
- 數據集蒸餾的任務是合成一個較小的數據集,使得在該合成數據集上訓練的模型能夠達到在完整數據集上訓練的模型相同的測試準確率,號稱優于coreset的選擇方法
- 本文中,對于給定的網絡,我們在蒸餾數據上對其進行幾次迭代訓練,預先計算并存儲在真實數據集上訓練的專家網絡的訓練軌跡,并根據合成訓練參數與在真實數據上訓練的參數之間的距離來優化蒸餾數據。
- 有一個問題哈,這種蒸餾方法強依賴GT,如果新增數據優化模型,沒有GT可能還是只能使用coreset的方法來做
二、方法介紹
數據蒸餾的目標是從大型訓練數據集中提取知識,將其濃縮到一個非常小的合成訓練圖像集合中(每個類別低至一張圖像),以便在蒸餾數據上訓練模型能夠獲得與在原始數據集上訓練相似的測試性能,如下圖所示: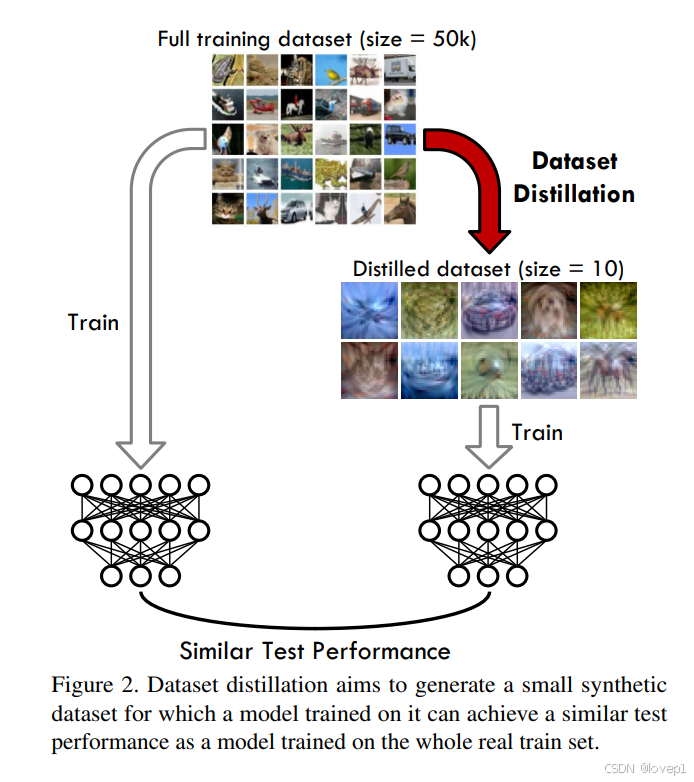
與經典的數據壓縮不同,數據集蒸餾旨在保留足夠的任務相關的信息,以便在小的合成數據集上訓練的模型能夠泛化到未見過的測試數據,如圖2所示。因此,蒸餾算法必須在大量壓縮信息的同時,保留區分性特征。
之前的方法的問題:
- 大多數先前的方法都集中在小型數據集(如MNIST和CIFAR)上,而在真實、更高分辨率的圖像上卻難以取得進展
- 一些方法考慮了端到端的訓練,但往往需要巨大的計算和內存資源,并且存在近似松弛或訓練不穩定性的問題
- 另外一些方法專注于短期行為,強制在蒸餾數據上進行單次訓練步驟以匹配真實數據上的訓練步驟,在評估中可能會累積誤差。
在本工作中:
- 提出了一種新的數據集蒸餾方法,不僅在性能上超越了以前的工作,而且適用于大規模數據集,如圖1所示。
- 本文方法試圖直接模仿在真實數據集上訓練的網絡的長期訓練動態;
- 我們將合成數據上訓練的參數軌跡段與從在真實數據上訓練的模型記錄的專家軌跡段進行匹配,從而避免了短視(即,專注于單個步驟)或難以優化(即,建模完整軌跡)的問題
- 將真實數據集視為引導網絡訓練動態的黃金標準,我們可以認為誘導的網絡參數序列是一個專家軌跡。如果我們的蒸餾數據集能夠誘導網絡的訓練動態遵循這些專家軌跡,那么合成訓練的網絡將在參數空間中接近于在真實數據上訓練的模型,并實現類似的測試性能。

在我們的方法中,我們的損失函數直接鼓勵蒸餾數據集引導網絡優化沿著類似的軌跡進行(圖3)。
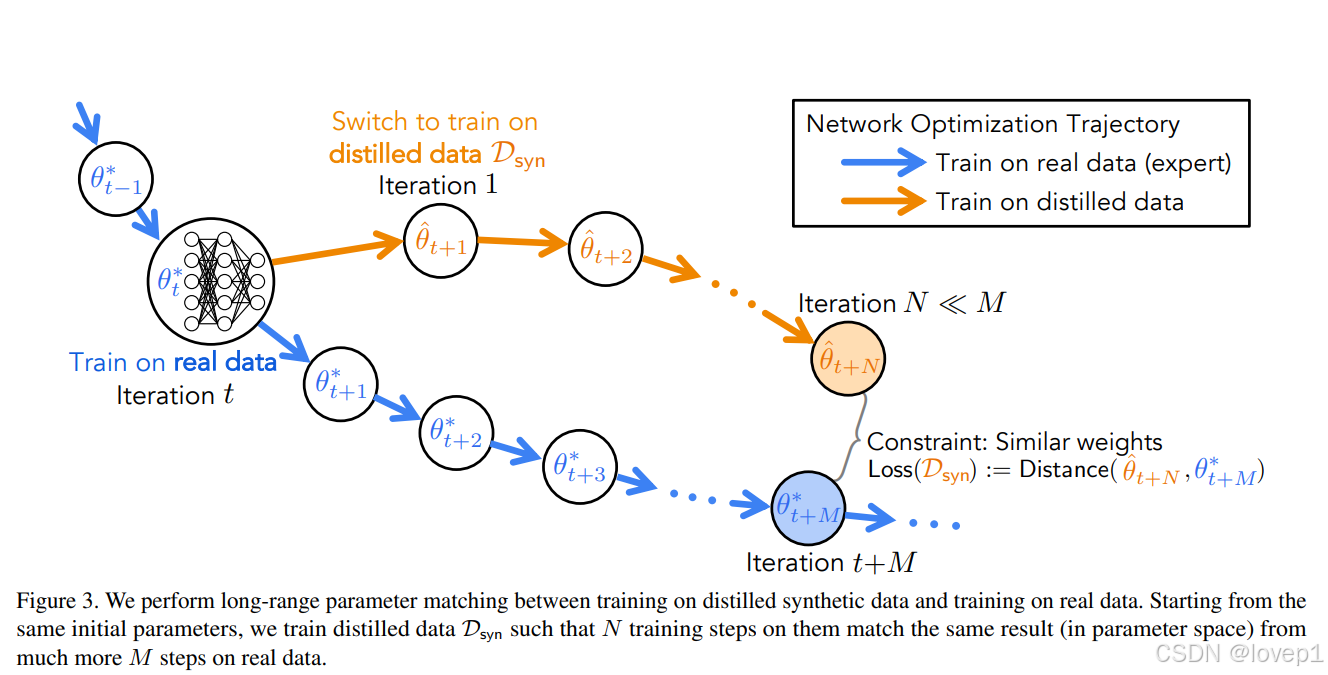
訓練流程:
- 從頭開始在真實數據集上訓練一組模型,并記錄它們的專家訓練軌跡。
- 從隨機選擇的專家軌跡中隨機選擇一個時間步來初始化一個新模型,并在合成數據集上進行幾次迭代訓練。
- 我們根據這個合成訓練的網絡與專家軌跡的偏離程度來懲罰蒸餾數據,并通過訓練迭代進行反向傳播。本質上,我們將許多專家訓練軌跡的知識轉移到了蒸餾圖像上。
實驗結果:
- 輕松超越了現有的數據集蒸餾方法以及核心集選擇方法,在標準數據集上表現優異,包括CIFAR-10、CIFAR-100和Tiny ImageNet。
- CIFAR-10上,我們使用每個類別一張圖像時達到了46.3%,每個類別50張圖像時達到了71.5%的準確率
- 首次能夠從ImageNet中蒸餾出高128×128分辨率的圖像
三、近期工作(直接翻譯)
3.1 數據集蒸餾
數據集蒸餾最早由Wang等人[44]提出,他們提出將模型權重表示為蒸餾圖像的函數,并使用基于梯度的超參數優化方法對其進行優化[23],這種方法在元學習研究中也得到了廣泛應用[8, 27]。隨后,通過學習軟標簽[2, 38]、通過梯度匹配放大學習信號[47]、采用數據增強[45]以及針對無限寬度核極限進行優化[25, 26],一些工作顯著提高了結果。數據集蒸餾已經實現了多種應用,包括持續學習[44, 45, 47]、高效的神經架構搜索[45, 47]、聯邦學習[11, 37, 50]以及針對圖像、文本和醫學影像數據的隱私保護機器學習[22, 37]。正如引言中提到的,我們的方法不依賴于單步行為匹配[45, 47]、成本高昂的完整優化軌跡展開[38, 44]或大規模神經切線核計算[25, 26]。相反,我們的方法通過從預訓練的專家中轉移知識來實現長期軌跡匹配。
與我們的工作同時進行的,Zhao和Bilen[46]的方法完全忽略了優化步驟,而是專注于合成數據和真實數據之間的分布匹配。盡管這種方法由于降低了內存需求而適用于更高分辨率的數據集(例如Tiny ImageNet),但在大多數情況下,其性能表現不如以往的工作(例如,與之前的作品[45, 47]相比)。相比之下,我們的方法在標準基準測試和更高分辨率數據集上同時降低了內存成本,同時超越了現有作品[45, 47]和同時進行的方法[46]。
還有一條相關的研究路線是學習一個生成模型來合成訓練數據[24, 36]。然而,這些方法并沒有生成一個小尺寸的數據集,因此不能直接與數據集蒸餾方法進行比較。
3.2 模仿學習
模仿學習試圖通過觀察一系列專家演示來學習一個良好的策略[29, 30, 31]。行為克隆訓練學習策略以與專家演示相同的方式行動。一些更復雜的形式涉及使用專家的標記進行在線策略學習[33],而其他方法則完全避免任何標記,例如通過分布匹配[16]。這些方法(特別是行為克隆)已被證明在離線環境中效果良好[9, 12]。我們的方法可以被視為模仿通過在真實數據集上訓練獲得的一系列專家網絡訓練軌跡。因此,它可以被視為在優化軌跡上進行模仿學習。
3.3 核心集和實例選擇
與數據集蒸餾類似,核心集[1, 4, 13, 34, 41]和實例選擇[28]旨在選擇整個訓練數據集的一個子集,其中在這個小子集上進行訓練能夠獲得良好的性能。這些方法中的大多數并不適用于現代深度學習,但基于雙層優化的新公式在持續學習等應用中已經顯示出有希望的結果[3]。與核心集相關,其他研究路線旨在了解哪些訓練樣本對現代機器學習是“有價值的”,包括測量單個樣本的準確性[20]和計算誤分類率[39]。事實上,數據集蒸餾是這類想法的推廣,因為蒸餾數據不需要是真實的,也不需要來自訓練集。
四、方法詳細介紹
數據集蒸餾指的是策劃一個小的、合成的訓練集 Dsyn?,使得在該合成數據上訓練的模型在真實測試集上的表現與在大型真實訓練集 Dreal? 上訓練的模型相似。本文方法直接模仿真實數據訓練的長期行為,將蒸餾數據上的多個訓練步驟與真實數據上的更多步驟進行匹配。
3.1 專家軌跡
如何獲取在真實數據集上訓練的網絡的專家軌跡?
方法的核心:
- 利用專家軌跡 τ? 來指導我們合成數據集的蒸餾。專家軌跡是指在完整的真實數據集上訓練神經網絡時獲得的參數時間序列 {θt??}0T?。
如何生成這些專家軌跡?
- 我們簡單地在真實數據集上訓練大量網絡,每個模型不同epoch組成一條expert trajectory。作者稱這些參數序列為“expert trajectory”,因為它們代表了數據集蒸餾任務的理論上限:在完整的真實數據集上訓練的網絡的性能。
- 同樣,我們定義學生參數 θ^t? 為在訓練步驟 t 時在合成圖像上訓練的網絡參數。我們的目標是蒸餾一個數據集,使其誘導出與真實訓練集誘導的軌跡(給定相同的起始點)相似的軌跡,從而使我們最終得到一個類似的模型。
由于這些專家軌跡僅使用真實數據計算,因此我們可以在蒸餾之前預先計算它們。對于給定數據集的所有實驗,我們都使用相同的預先計算的專家軌跡集合,這使得蒸餾和實驗能夠快速進行。
3.2 長期參數匹配
本文方法通過鼓勵蒸餾數據集誘導與真實數據集相似的長期網絡參數軌跡,從而使得在合成數據上訓練的網絡表現類似于在真實數據上訓練的網絡。
我們的蒸餾過程從構成我們expert trajectories中的參數序列 {θt??}0T? 中學習。與以往工作不同,我們的方法直接鼓勵我們合成數據集誘導的長期訓練動態與在真實數據上訓練的網絡的動態相匹配。
在每個蒸餾步驟中,我們首先從我們的專家軌跡之一中隨機時間步采樣參數 θt??,并用這些參數初始化我們的學生參數 θ^t?:=θt??。在初始化我們的學生網絡后,我們接著對合成數據的分類損失進行 N 次梯度下降更新,更新學生參數:
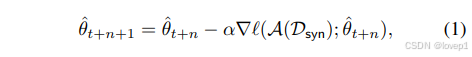
其中A是可微分增強操作,α是個可學習的學習率。然后計算更新后的學生參數和expert trajectory的模型參數的匹配損失,根據權重匹配損失更新我們的蒸餾圖像,即更新后學生參數 θ^t+N? 與已知未來的專家參數 θt+M?? 之間的歸一化平方 L2 誤差:
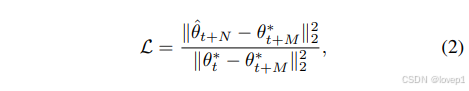
通過將反向傳播通過學生網絡的所有 N 次更新來最小化這個目標,更新我們蒸餾數據集的像素,以及我們的可訓練學習率 α。可訓練學習率 α 的優化起到了自動調整學生和專家更新次數(超參數 M 和 N)的作用。我們使用帶有動量的隨機梯度下降(SGD)來優化 Dsyn? 和 α,以達到上述目標。整體如下所示:

3.3 內存限制
本文如何減少內存消耗?
原式是這樣進行梯度更新的,由于Dataset太大,因此可以將一式轉化為三式
我們可以為學生網絡的每次更新(即算法 1 第 10 行的內循環)采樣一個新的小批量 b,這樣在計算最終權重匹配損失(方程 2)時,所有的蒸餾圖像都將被看到。小批量 b 仍然包含來自不同類別的圖像,但每個類別的圖像數量要少得多。在這種情況下,我們的學生網絡更新變為
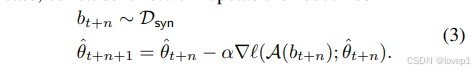
這種分批方法允許我們在確保同一類別蒸餾圖像之間存在一定程度的異質性的同時,蒸餾出一個更大的合成數據集。
五、實驗
對于 CIFAR-10,這些蒸餾圖像可以在圖 4 中看到。CIFAR-100 的圖像在補充材料中進行了可視化。

如表 1 所示,我們的方法在每種設置中都顯著優于所有基線。事實上,在每個類別一張圖像的設置中,我們在兩個數據集上都將次優方法(DSA [45])的測試準確率幾乎提高了一倍。

在表 2 中,我們還與最近的方法 KIP [25, 26] 進行了比較:
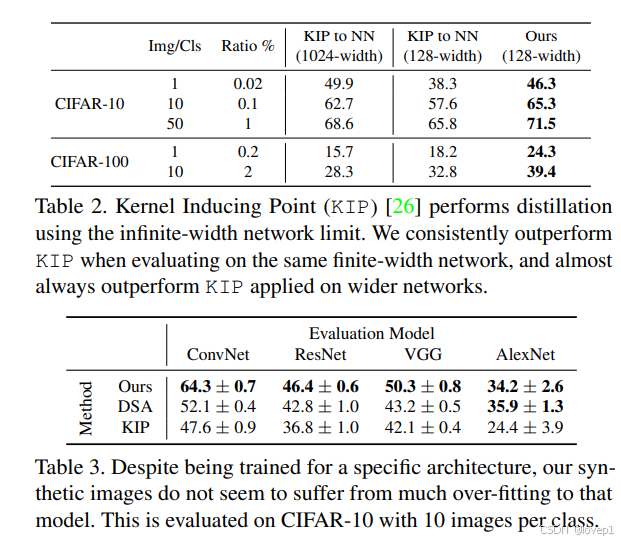
正如之前的方法 [44] 所指出的,我們還發現在合成數據集中允許更多圖像時,收益會顯著減少。
- 例如,在 CIFAR-10 上,當我們將每個類別的圖像數量從 1 增加到 10 時,分類準確率從 46.3% 提高到 65.3%,
- 但當我們將每個類別的蒸餾圖像數量從 10 增加到 50 時,僅從 65.3% 提高到 71.5%。
如果我們查看圖 4(頂部)中每個類別一張圖像的可視化,我們會看到每個類別的非常抽象但仍然可以識別的表示。當我們只允許每個類別有一張合成圖像時,優化被迫將盡可能多的類別區分信息壓縮到一個樣本中。當我們允許更多圖像來分散類別的信息時,優化有自由度將類別的區分特征分散到多個樣本中,從而產生我們在圖 4(底部)中看到的多樣化的一組結構化圖像(例如,不同類型的汽車和馬,具有不同的姿勢)。
跨架構泛化。我們還在 CIFAR-10、每個類別一張圖像的任務上評估了我們的合成數據在與用于蒸餾它的架構不同的架構上的表現。在表 3 中,我們展示了我們的基線 ConvNet 性能,并在 ResNet 、VGG 和 AlexNet 上進行了評估。

表明我們的方法對架構的變化具有魯棒性。
4.2 短期匹配與長期匹配
非常短期的匹配(N=1 且 M 較小)通常比長期匹配表現更差,當 N 和 M 都相對較大時,達到最佳性能
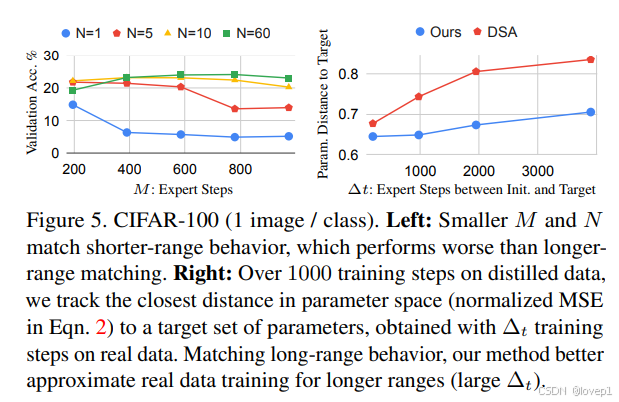
對于這兩種方法,我們測試它們使用蒸餾數據從相同的初始參數訓練網絡到目標參數的接近程度。DSA 僅針對短期行為進行優化,因此在更長時間的訓練過程中可能會累積誤差。實際上,隨著 Δt 變得更大,DSA 在更長距離上無法模仿真實數據的行為。相比之下,我們的方法針對長期匹配進行了優化,因此表現更好。
六、總結
在這項工作中,我們介紹了一種數據集蒸餾算法,通過直接優化合成數據來誘導與真實數據相似的網絡訓練動態。我們的方法與以往方法的主要區別在于,我們既不受限于短期單步匹配,也不受優化整個訓練過程的不穩定性以及計算強度的影響。我們的方法在這兩個方面都取得了平衡,并且在這兩方面都顯示出改進。與以往方法不同,我們的方法首次擴展到128×128的ImageNet圖像
局限性。我們使用預先計算的軌跡,雖然節省了大量內存,但以增加磁盤存儲和專家模型訓練的計算成本為代價。訓練和存儲專家軌跡的計算開銷相當高。例如,CIFAR專家每個epoch大約需要3秒(所有200個CIFAR專家總共需要8個GPU小時),而每個ImageNet(子集)專家每個epoch大約需要11秒(所有100個ImageNet專家總共需要15個GPU小時)。在存儲方面,每個CIFAR專家大約占用60MB的存儲空間,而每個ImageNet專家大約占用120MB。

![P1036 [NOIP 2002 普及組] 選數(DFS)](http://pic.xiahunao.cn/P1036 [NOIP 2002 普及組] 選數(DFS))




![[C++面試] new、delete相關面試點](http://pic.xiahunao.cn/[C++面試] new、delete相關面試點)

)

- 排序-內部排序知識點)
:構建、部署與 Docker 化)


(成果展示))

)


