免責申明
本文和工具截圖中涉及題庫和題目,均為本人自學使用,并未有商業和傳播企圖。如有侵害,聯系刪改。
概述
筆者本人醫學專業從業人員,編程只是業余愛好。在自己的專業應考學習過程當中:
- 有時候不太喜歡紙質題庫的排版,比如題目與答案分開,甚至是分開在兩本書上。
- 想要翻錄下來,轉存到筆記軟件中,作為自己積累的一個題庫,而且方便隨時查看、修改和擴充筆記。
這項工作,我從2024年頭就開始實踐,并且已經積累了一定的題目量。作為專業學習和考試的專用復習資料。
翻錄操作
我的具體做法是:
- 攤開書,翻頁,手機拍照后轉存PDF
- 在WPS中進行掃描件識別,獲取文本
- 在VSCode中進行批量替換和初步處理
- 復制到筆記軟件(我用的是語雀),進行更詳細的優化排版
- 學習和補充筆記,手機隨時查看記憶
- 選擇性打印為冊子,方便查看
翻錄環節一直是很順暢和熟練的。但是,后續處理有時候比較麻煩。尤其是很多紙質題庫是將題目和參考答案以及解析分開的。手動排版是個海量的工作。因此,需要編程實現題目與答案的合并。
之前的Python版本
2024年11月11日創建的Python版本,其原理是:
- 把題目和答案都預處理為
---分隔的形式 - 各自拆分為字符串數組,檢測題目總數和答案總數一致后,進行題目和答案解析的合并
# 讀取文件內容
def read_file(path):with open(path, 'r',encoding="utf-8") as file:content = file.read()return content# 讀取文件內容
def save_file(path,content):with open(path, 'w',encoding="utf-8") as file:content = file.write(content)# 獲取題目和答案合并的結果
def get_result(qus_path,ans_path):result = ""qus = read_file(qus_path) # 問題ans = read_file(ans_path) # 答案# 用 --- 劃分qus_arr = qus.split("---")ans_arr = ans.split("---")if len(qus_arr) == len(ans_arr): # 答案和題目數量一致# 遍歷生成合并字符串for i in range(len(qus_arr)):q = qus_arr[i]a = ans_arr[i]result += f"""{q}
:::tips
{a}
:::"""return resultsave_file("result.md",get_result("qus.txt","ans.txt"))
這個版本的壞處的,必須依靠VSCode和工作目錄,并且需要將題目和答案分別存儲到固定名稱的文件中。
而字符串處理的大部分操作還是需要手動在VSCode中進行。
創建Godot版本
為了更方便快捷的合并,編寫了一個簡單的Godot應用。
- 用Godot創建合并器,以復制粘貼文本形式,而不是文件形式,處理起來會更靈活。
- 而且代碼和處理的靈活性也會進一步上升
初步界面設計

初步實現
extends HSplitContainer
@onready var qus_txt: TextEdit = %qusTxt
@onready var ans_txt: TextEdit = %ansTxt
@onready var result_txt: TextEdit = %resultTxt# ================================= 按鈕點擊 =================================
# 整體添加分隔線
func _on_splits_btn_pressed() -> void:qus_txt.text = add_splits(qus_txt.text)ans_txt.text = add_splits(ans_txt.text)# 執行合并
func _on_join_btn_pressed() -> void:result_txt.text = do_joins_result(qus_txt.text,ans_txt.text)pass# ================================= 自定義方法 =================================
# 查找題目或答案序號,并添加 --- 分隔符
func add_splits(old_str:String) -> String:var regex = RegEx.new()regex.compile(r"\n\d\.")for result in regex.search_all(old_str):var res = result.get_string()old_str = old_str.replace(res,"\n --- %s" % res)return old_str# 執行合并
func do_joins_result(qus_str:String,ans_str:String) -> String:var result:PackedStringArray = []var qus_arr = qus_str.split("---",false)var ans_arr = ans_str.split("---",false)if qus_arr.size() == ans_arr.size(): # 題目數量與答案解析數量一致# 遍歷生成合并字符串for i in range(qus_arr.size()):var qus = qus_arr[i]var ans = ans_arr[i]result.append(qus_ans_str(qus,ans))return "\n".join(result)# 根據模版字符串生成題目和答案解析的合并字符串
func qus_ans_str(qus:String,ans:String) -> String:var tmp = """%s
:::tips
%s
:::""" % [qus,ans]return tmp已經實現基礎的題目與答案解析合并功能,復制到語雀自動識別后,也是可以正常顯示:
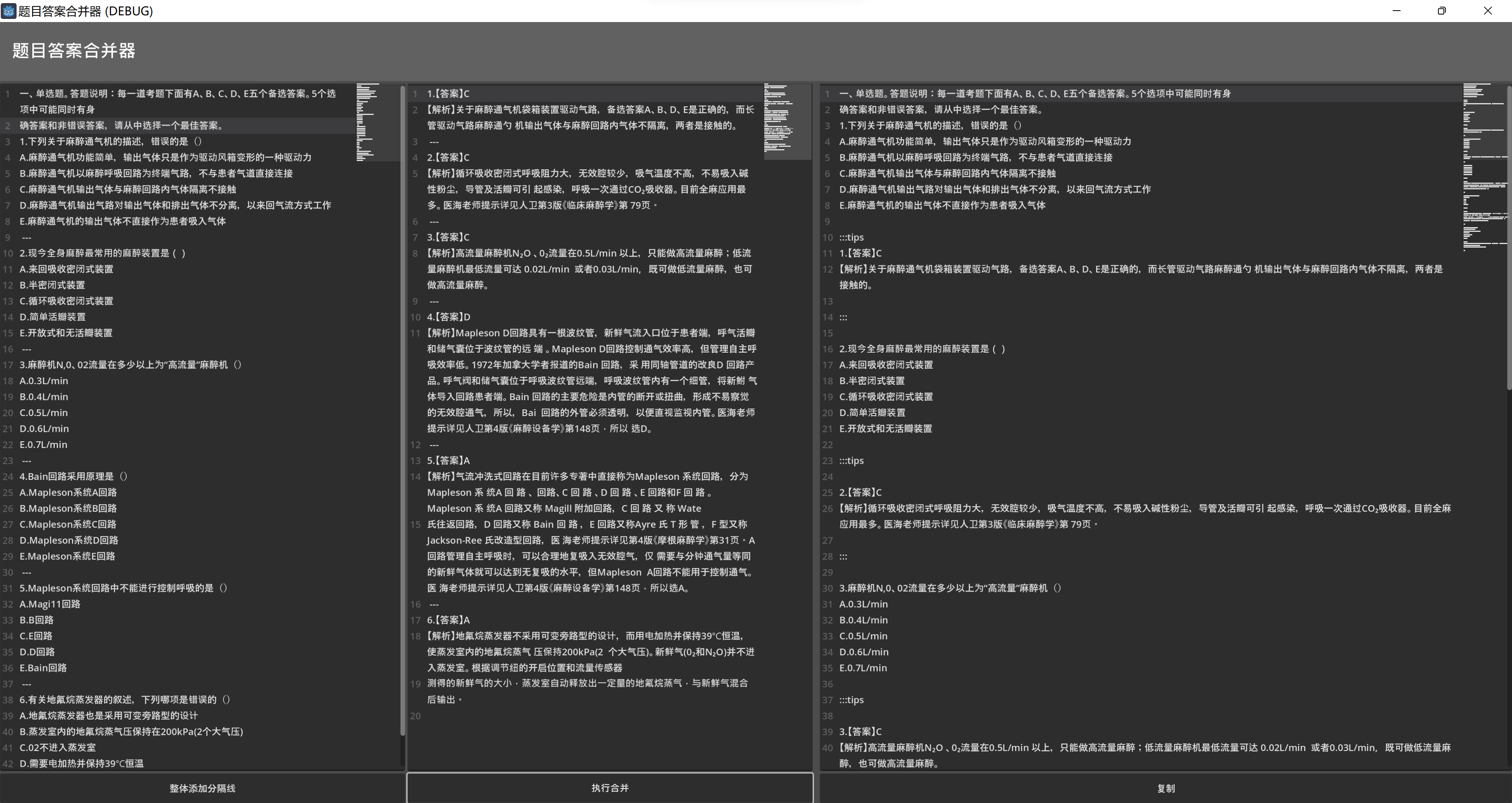
編寫處理類
上面將處理邏輯編寫為三個函數,混雜在主場景中,顯得并不優秀。
好的辦法是進一步編寫類,來固定處理相似的邏輯。這樣也就讓邏輯和UI部分分離了。
新類設想
- 新的類將自動處理輸入的普通的題目和答案解析字符串,并維護題目和答案兩個數組
- 將可以編寫簡單的題庫系統,順序查看題目和答案
新類實現
# =========================================================
# 名稱:QusAnsList
# 類型:GDSCript類
# 描述:解析和處理普通的題目和答案解析字符串,生成合并字符串的處理類
# Godot版本:v4.3.stable.steam [77dcf97d8]
# 創建時間:2025年2月12日13:08:13
# 最后修改時間:2025年2月12日21:38:46
# =========================================================
class_name QusAnsList
# 切分后的題目與答案集合
var qus_arr:PackedStringArray
var ans_arr:PackedStringArray# 原始字符串
var qus_str:String
var ans_str:String
# 添加分隔符后的字符串
var split_qus_str:String
var split_ans_str:String# 創建實例
func _init(qus_str:String,ans_str:String) -> void:self.qus_str = inline_opts(qus_str)self.ans_str = ans_str# 添加分隔線self.split_qus_str = add_lines(self.qus_str,true)self.split_ans_str = add_lines(ans_str)# 分割添加了分隔線的字符串,獲得題目與答案集合splits()# ================================ 方法 ================================# 將ABCDE選項放置到一行
func inline_opts(old_str:String) -> String:var new_str = old_strfor opt in ["B","C","D","E"]:new_str = new_str.replace("\n%s." % opt,"%s%s." % ["\t".repeat(2),opt])return new_str# 查找題目或答案序號,并添加 --- 分隔符
# old_str 要添加分隔符的原始字符串
# ignore_first 是否忽略第一項,用于題目序號不是在第一行的情況
func add_lines(old_str:String,ignore_first:=false) -> String:# 創建對序號的正則匹配var regex = RegEx.new()regex.compile(r"\n\d+\.")# 遍歷所有搜索到的序號,替換為 --- var results = regex.search_all(old_str)for i in range(results.size()):if ignore_first and i==0: # 忽略第一次continuevar res = results[i].get_string()old_str = old_str.replace(res,"\n---%s" % res)return old_str# 分割添加了分隔線的字符串獲得題目與答案集合
func splits() -> void:qus_arr = split_qus_str.split("\n---\n",false)ans_arr = split_ans_str.split("\n---\n",false)# 檢測題目與答案集合的數目是否相等
func is_qus_equal_ans_count() -> bool:return qus_arr.size() == ans_arr.size()# 獲取執行合并的字符串
func get_joins_result() -> String:var result:PackedStringArray = []if qus_arr.size() == ans_arr.size(): # 題目數量與答案解析數量一致# 遍歷生成合并字符串for i in range(qus_arr.size()):var qus = qus_arr[i]var ans = ans_arr[i]result.append(qus_ans_str(qus,ans))return "\n".join(result)# 根據模版字符串生成題目和答案解析的合并字符串
func qus_ans_str(qus:String,ans:String) -> String:var tmp = """%s
:::tips
%s
:::""" % [qus,ans]return tmp
基于新類,主場景的代碼簡化如下:
extends HSplitContainervar QAlist:QusAnsList
var current_index:int = 0@onready var qus_txt: TextEdit = %qusTxt
@onready var ans_txt: TextEdit = %ansTxt
@onready var result_txt: TextEdit = %resultTxt
@onready var tk_qus_txt: CodeEdit = %tkQusTxt
@onready var tk_ans_txt: CodeEdit = %tkAnsTxt# ================================= 按鈕點擊 =================================# 執行合并
func _on_join_btn_pressed() -> void:QAlist = QusAnsList.new(qus_txt.text,ans_txt.text)result_txt.text = QAlist.get_joins_result()# 題庫顯示第一題show_tk_qus_ans(0)# 題庫顯示指定的第幾題
func show_tk_qus_ans(index:int) -> void:tk_qus_txt.text = QAlist.qus_arr[index]tk_ans_txt.text = QAlist.ans_arr[index]# 顯示上一題
func _on_last_btn_pressed() -> void:current_index = clamp(current_index-1,0,QAlist.qus_arr.size()-1)show_tk_qus_ans(current_index)# 顯示下一題
func _on_next_btn_pressed() -> void:current_index = clamp(current_index+1,0,QAlist.qus_arr.size()-1)show_tk_qus_ans(current_index)
程序效果
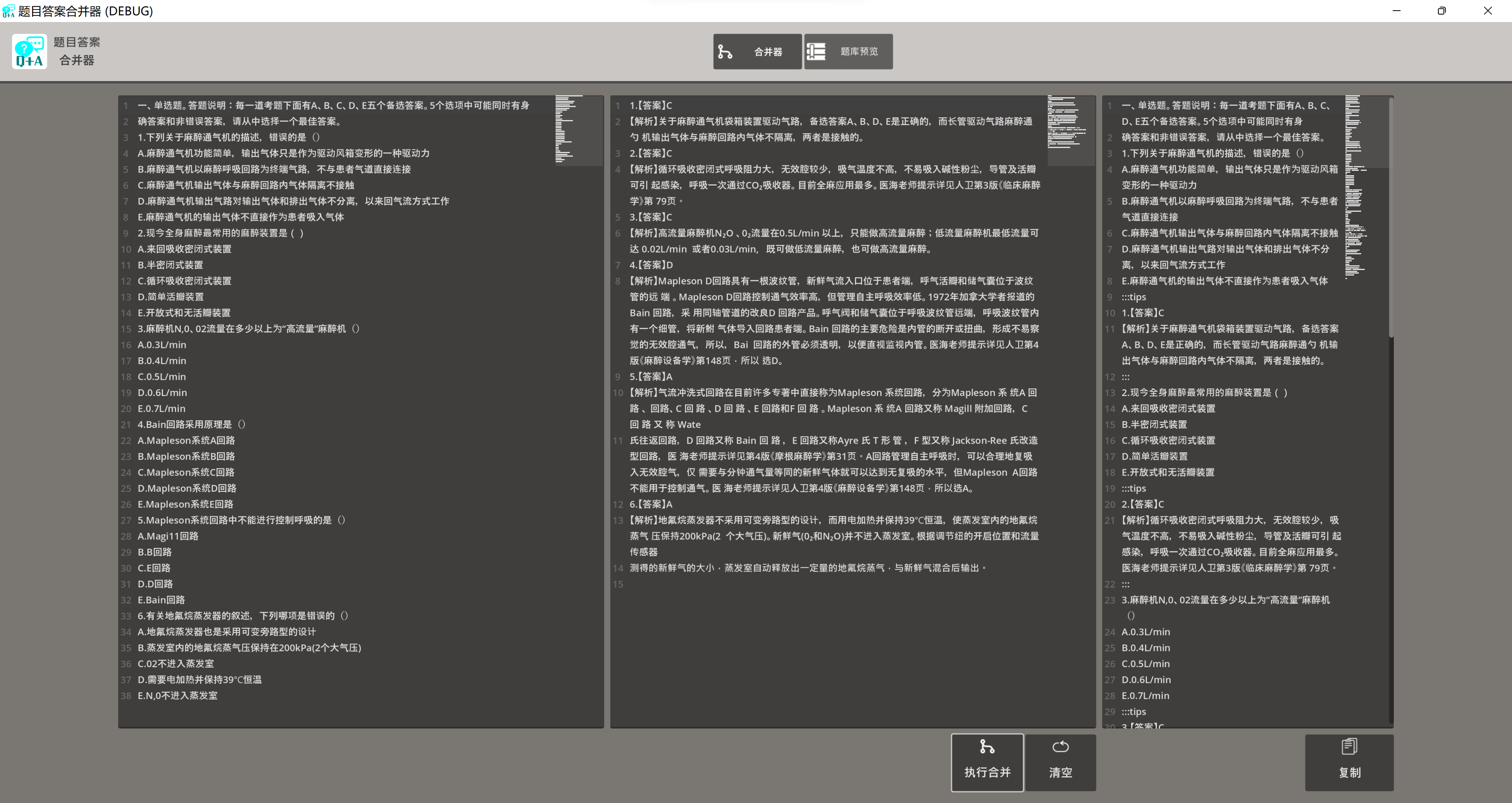
一鍵處理和合并題目與答案
- 生成合并字符串并進行展示,可以復制到語雀中自動識別和排版
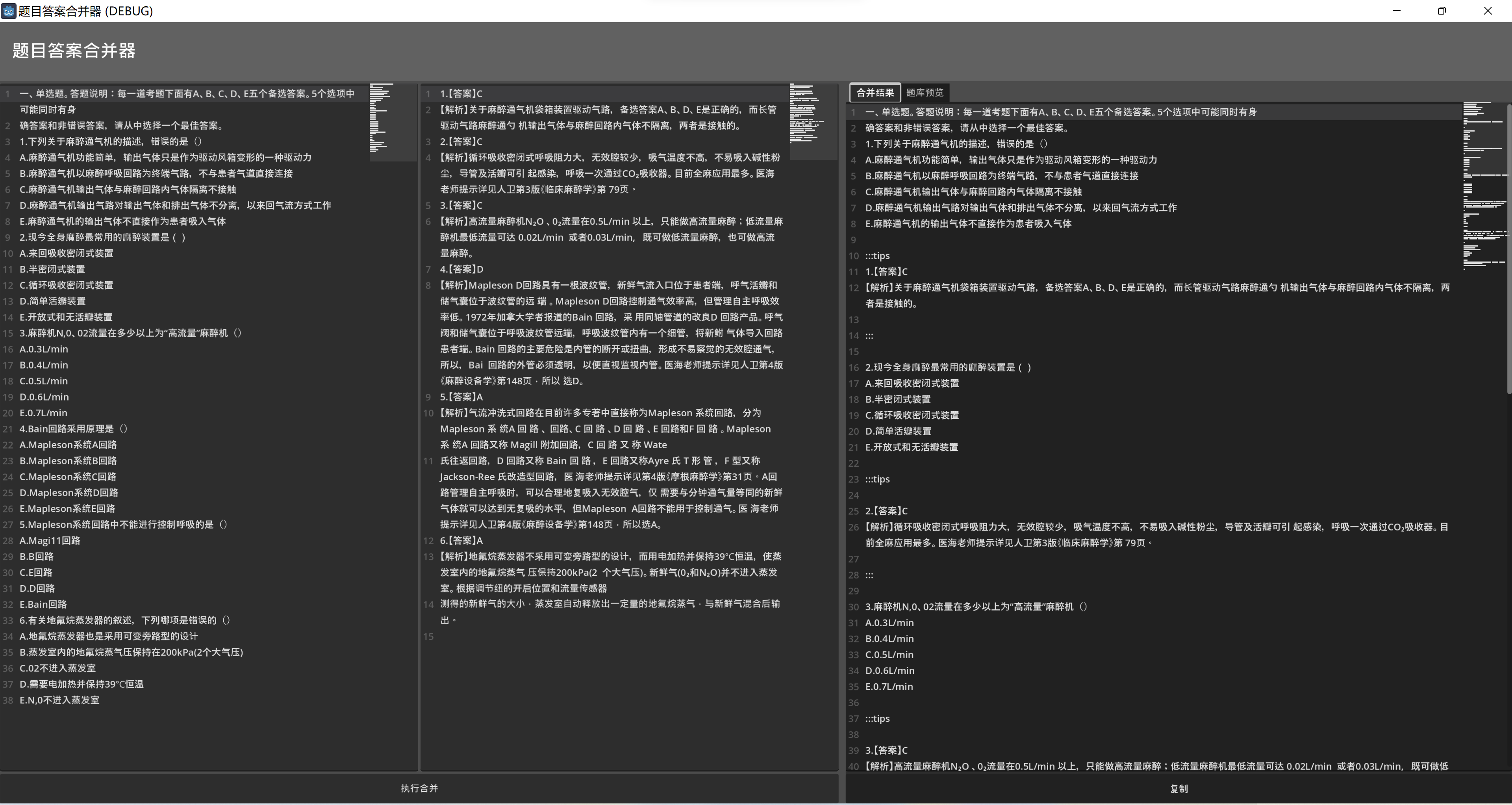
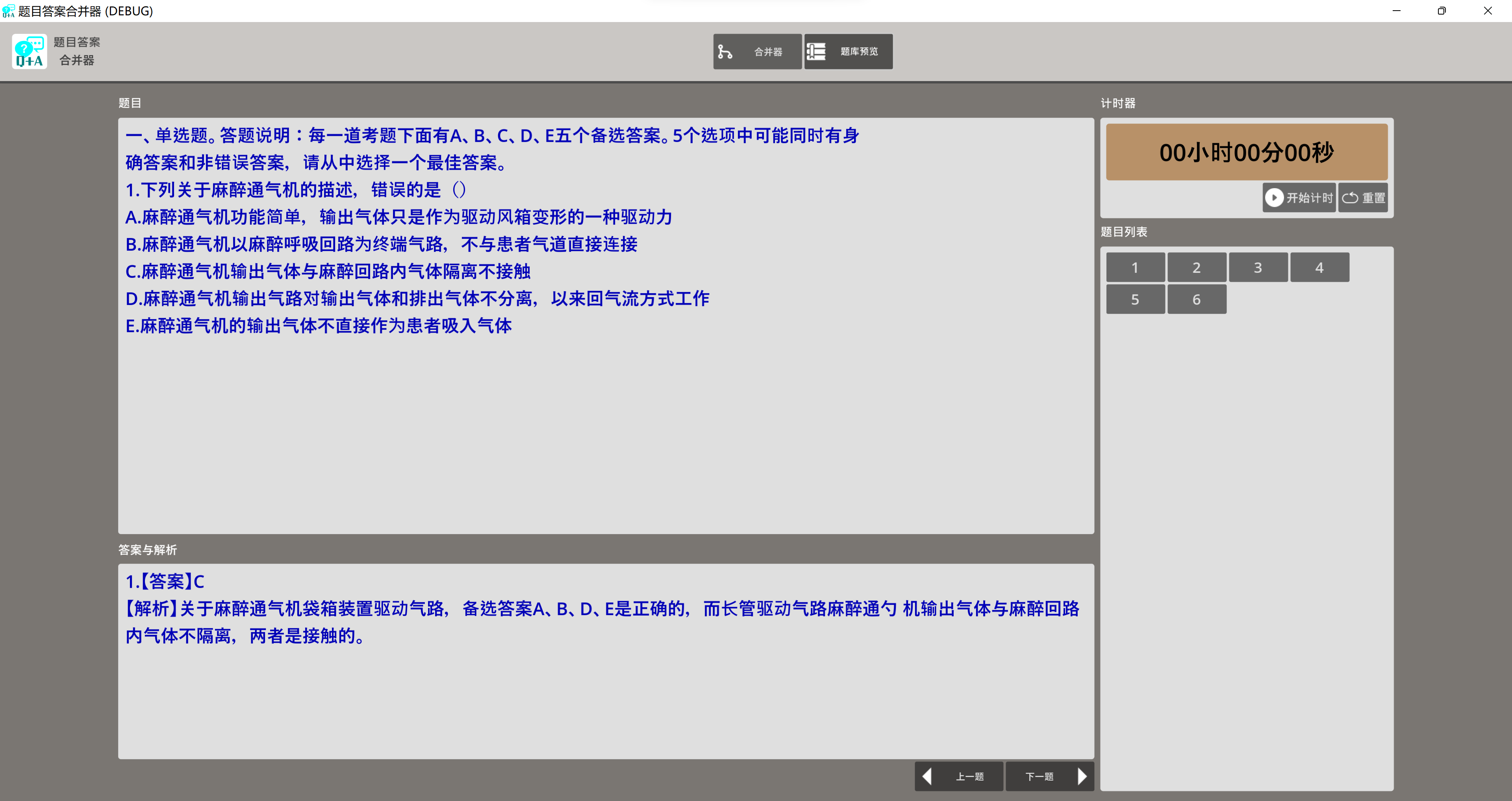
生成題庫預覽
- 因為新類內部維護兩個數組,存儲題目和答案
- 所以可以搭建簡易的題庫預覽界面,來按順序查看每一道題目
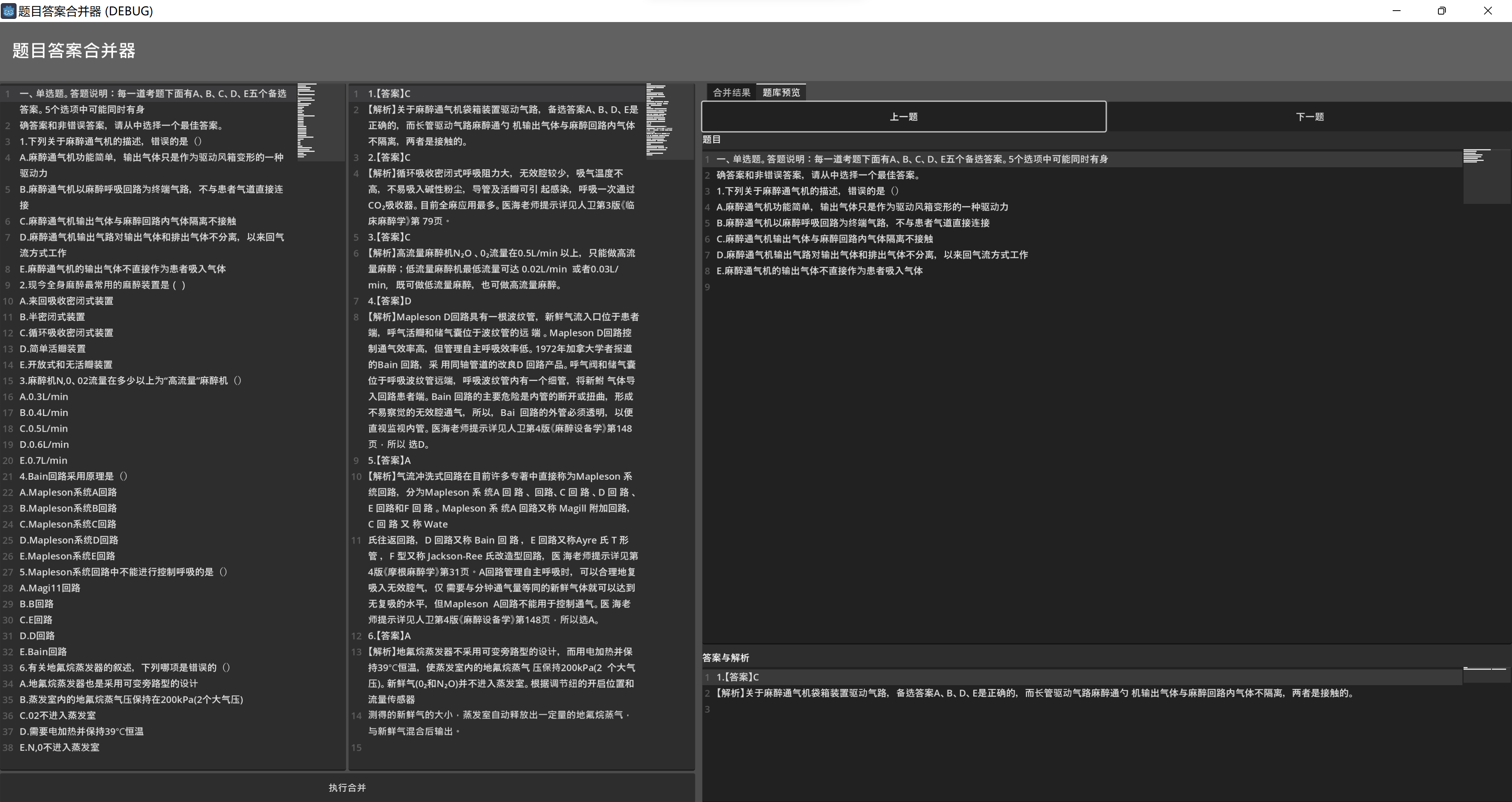
后續改進
界面分開
- 將界面分為合并器和題庫預覽兩部分,通過頂欄的按鈕進行界面的切換
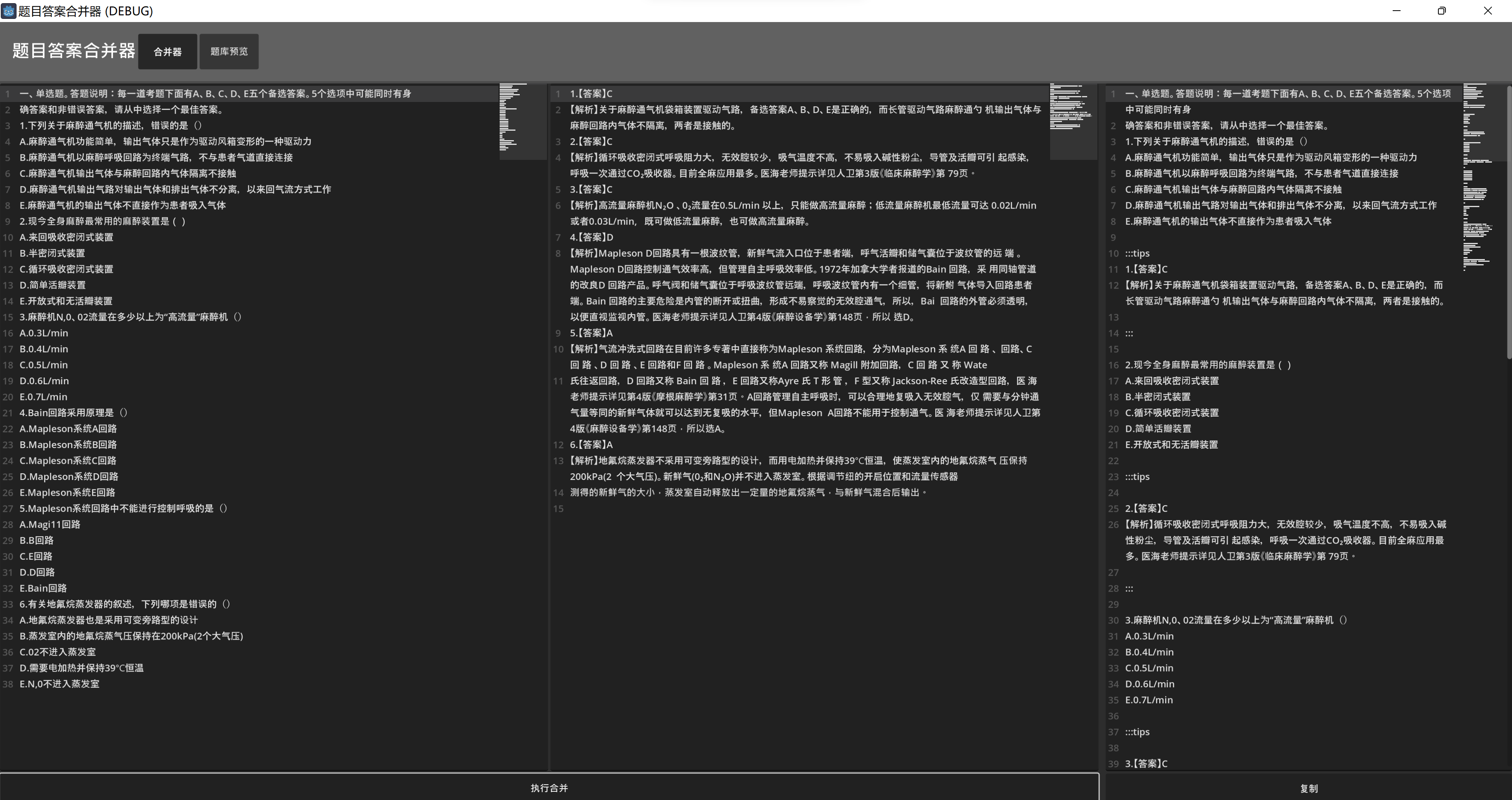
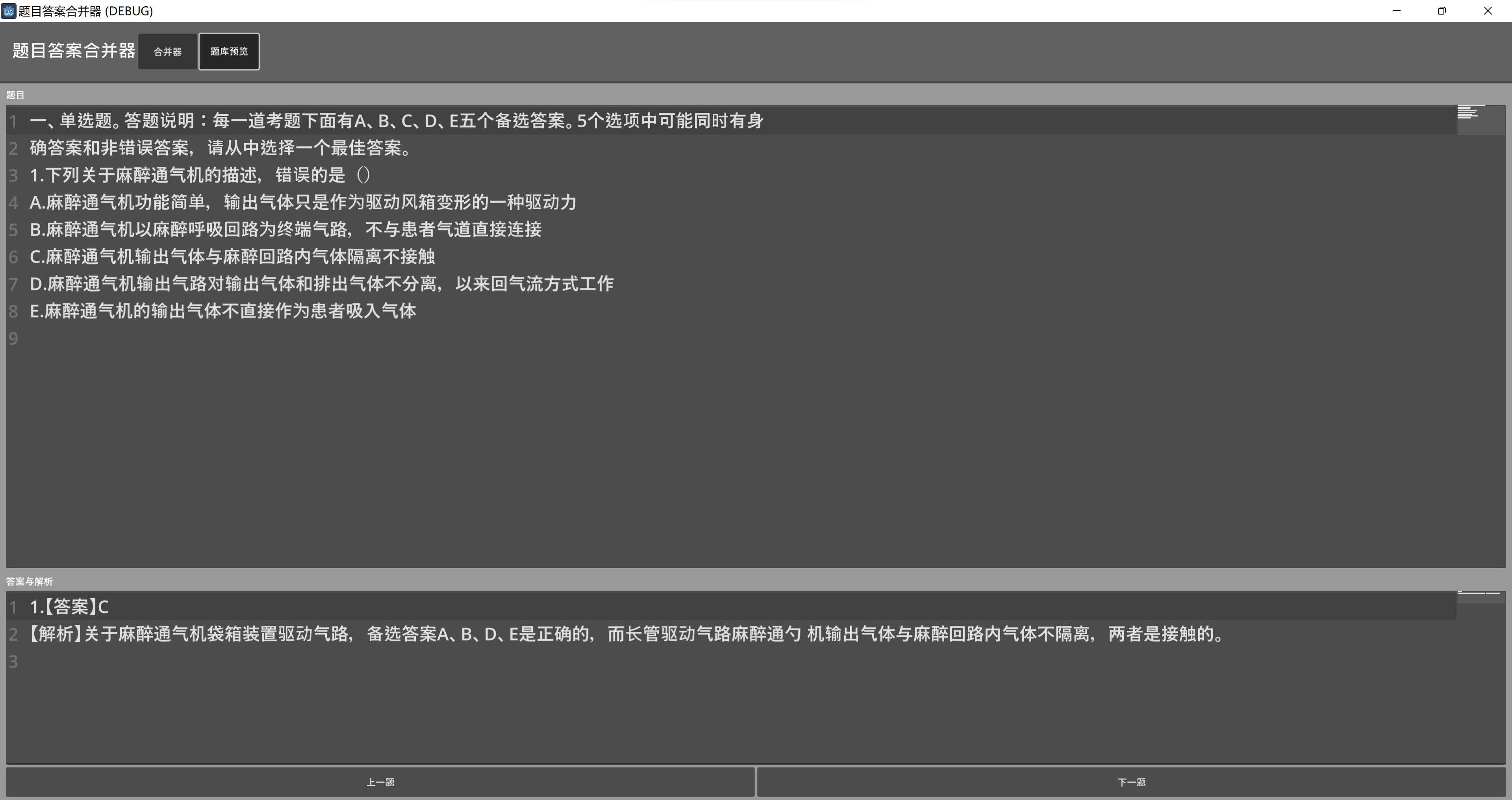
題號列表
- 只通過上一題,下一題查看題庫并不方便,可以生成題號按鈕,點擊快速查看。
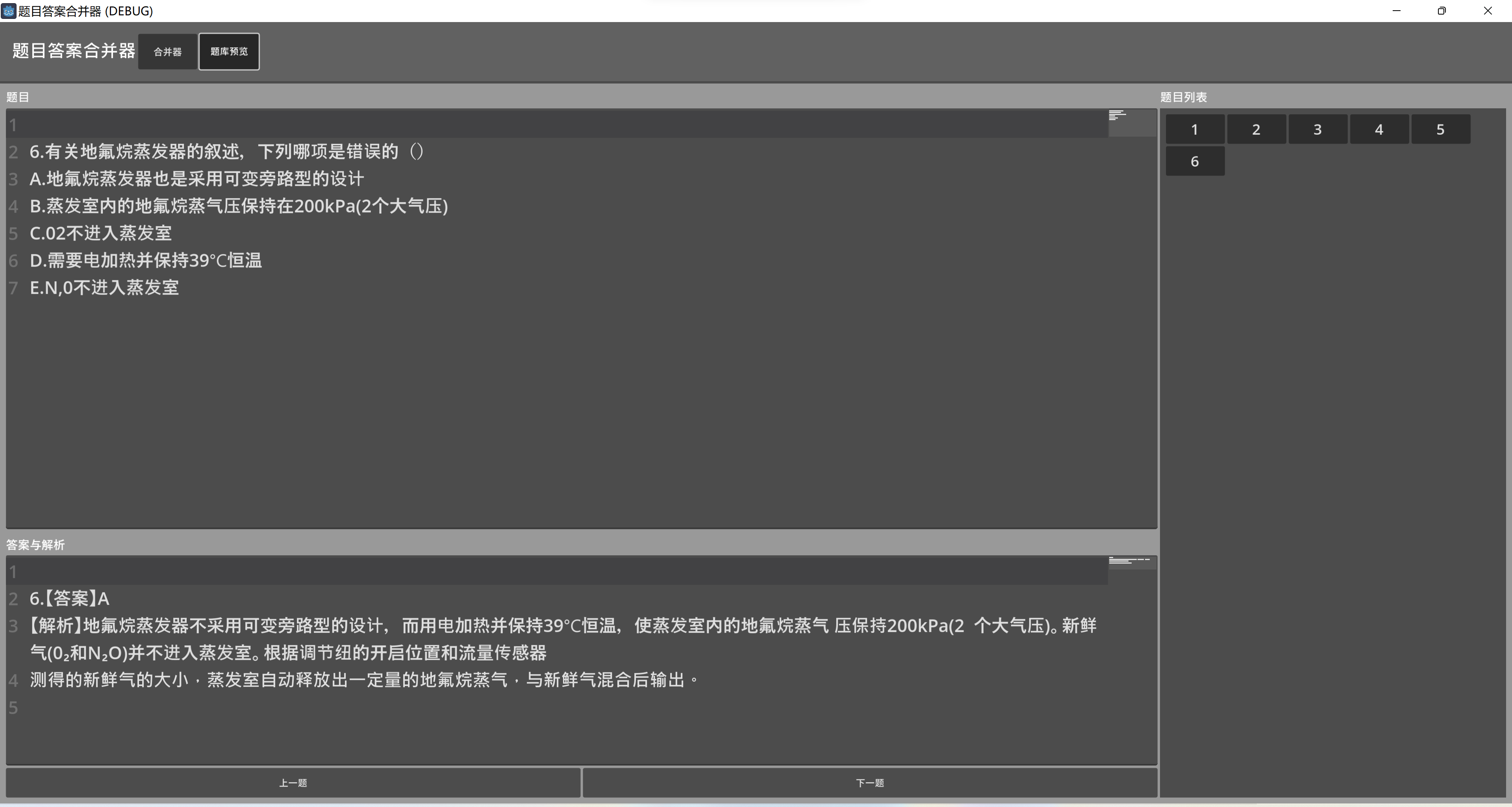
修改題庫預覽界面樣式
- 兩邊留白,讓視野寬度略小于屏幕寬度,中心聚焦且看的不是太累。
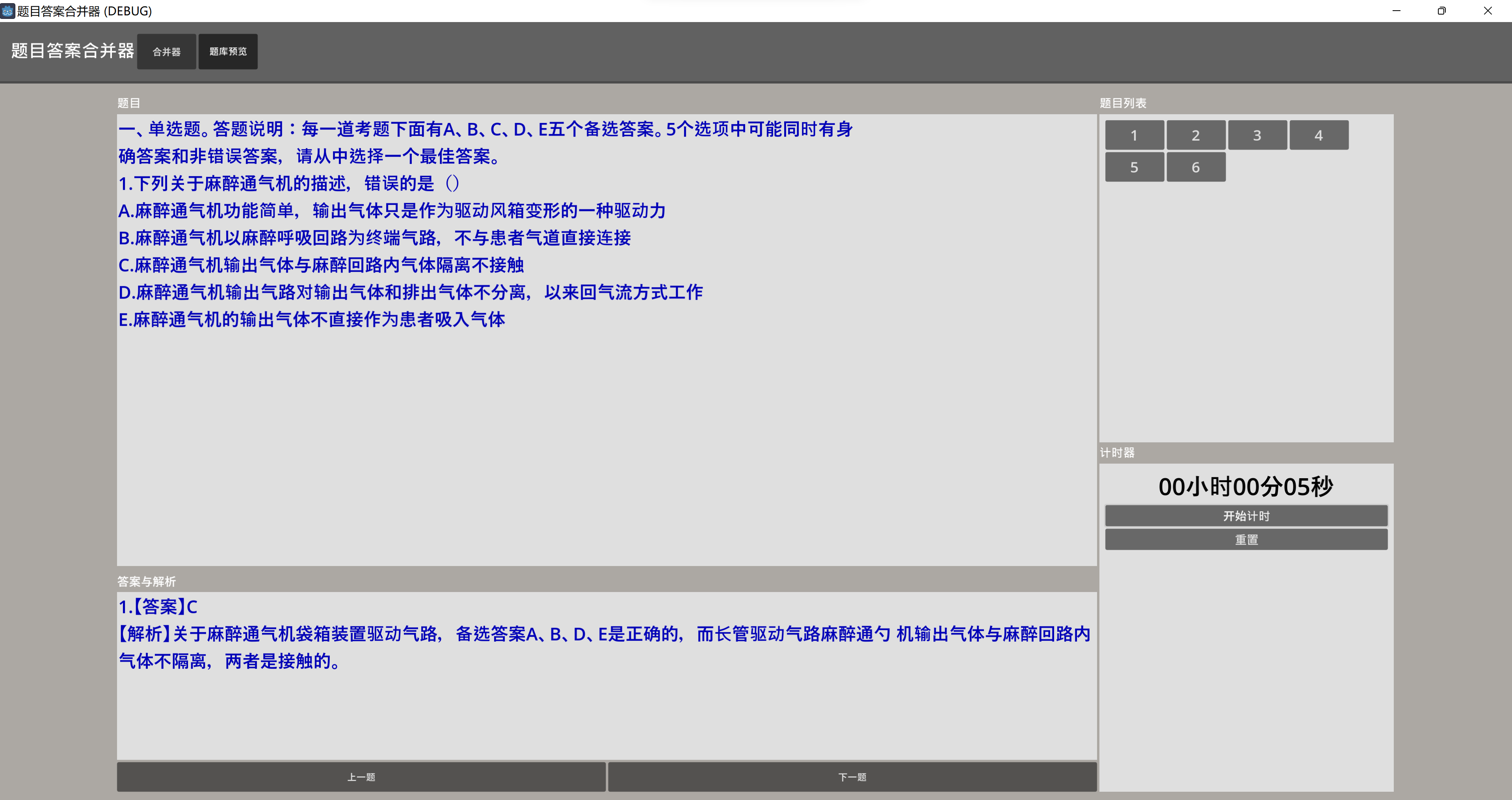
刷題計時器
- 設計一個簡單的刷題計時器,可以重置、開始、暫停,用以記錄刷題時間
- 首先是編寫一個函數獲取累計時間的
HH:MM:SS形式字符串
# 返回累計時間的時分秒的字符串形式 HH:MM:SS
func get_time_str(time:int) -> String:var dic = Time.get_time_dict_from_unix_time(time)return "%02d:%02d:%02d" % [dic["hour"],dic["minute"],dic["second"]]
# 返回累計時間的時分秒的字符串形式 HH小時MM分SS秒
func get_time_str(time:int) -> String:var dic = Time.get_time_dict_from_unix_time(time)return "%02d小時%02d分%02d秒" % [dic["hour"],dic["minute"],dic["second"]]
- 接著就是使用和控制
Timer節點顯示累計時間
UI美化
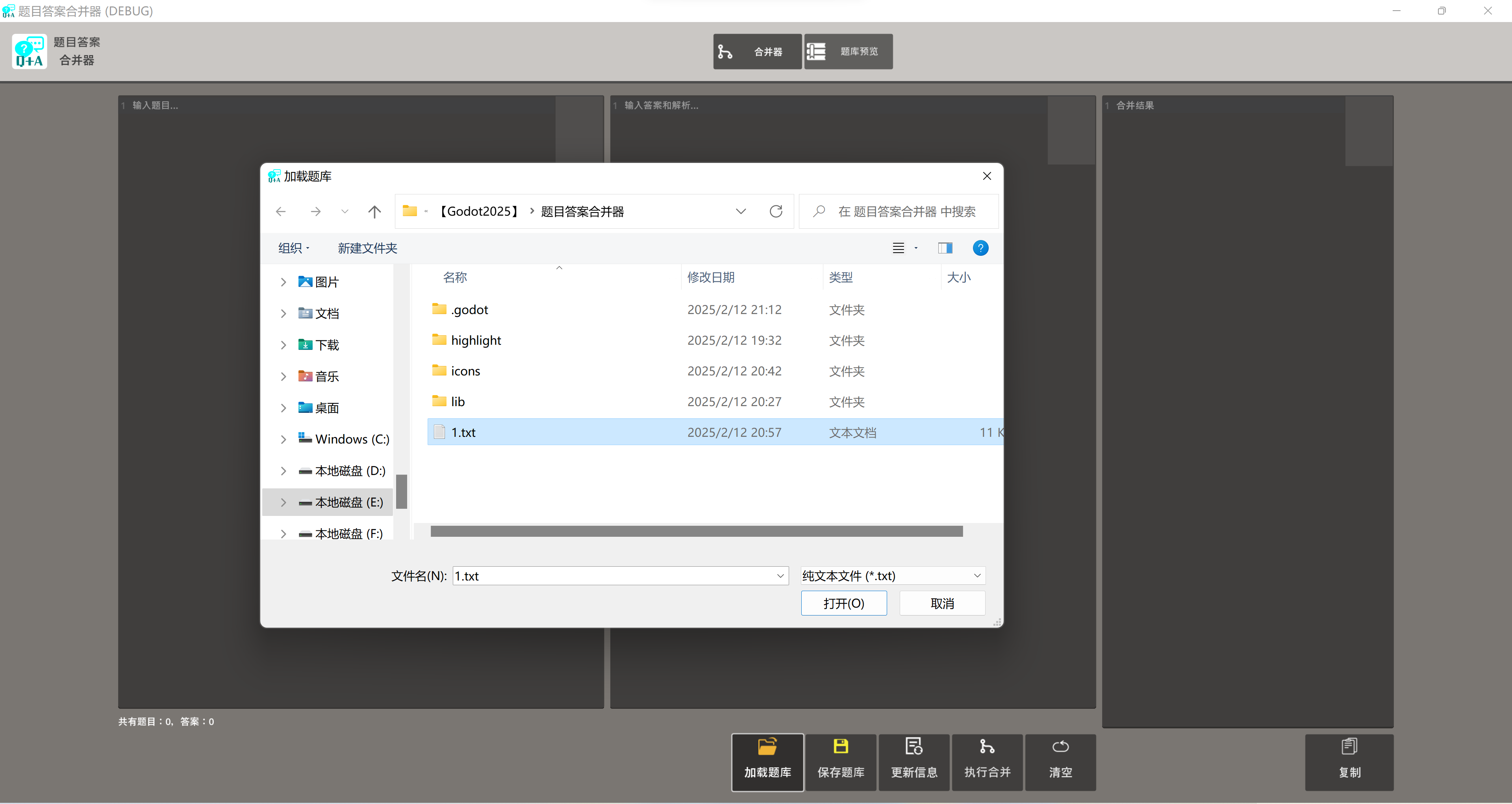
加載和保存題庫
- 題庫文件是題目和答案用特殊解析字符串
#================;所連接的純文本文件

總結
- 至此,意為著利用純文本形式的題目和答案字符串,快速合并獲得適用于語雀顯示的格式將變得異常方便
- 同時,可以以非常簡便的方式創建刷題系統。只需要維護和保存一堆
.txt文件即可。






)

)










在 NLP 中的使用場景)