
前言:零基礎學Python:Python從0到100最新最全教程。 想做這件事情很久了,這次我更新了自己所寫過的所有博客,匯集成了Python從0到100,共一百節課,幫助大家一個月時間里從零基礎到學習Python基礎語法、Python爬蟲、Web開發、 計算機視覺、機器學習、神經網絡以及人工智能相關知識,成為學習學習和學業的先行者!
歡迎大家訂閱專欄:零基礎學Python:Python從0到100最新最全教程!
本文目錄:
- 一、WISDM數據集分析及介紹
- 二、CNN網絡結構及介紹
- 1. CNN的核心組件
- 1.1 卷積層(Convolutional Layer)
- 1.2 池化層(Pooling Layer)
- 1.3 激活函數層(Activation Layer)
- 1.4 全連接層(Fully Connected Layer)
- 2. CNN的層次化特征提取
- 3. CNN的變體與擴展
- 3.1 深度可分離卷積(Depthwise Separable Convolution)
- 3.2 空洞卷積(Dilated Convolution)
- 3.3 注意力機制(Attention Mechanism)
- 4. CNN在時間序列數據中的應用
- 4.1 1D卷積
- 4.2 時序池化
- 4.3 混合架構
- 5. CNN的優化策略
- 5.1 正則化方法
- 5.2 學習率調整
- 6. 典型CNN架構示例
- 三、WISDM數據集分割及處理
- 四、CNN網絡訓練WISDM數據集
- 1.常用的仿真指標
- 1.1 準確率 (Accuracy)
- 1.2 精確率 (Precision)
- 1.3 召回率 (Recall)
- 1.4 F1分數 (F1-Score)
- 1.5 參數量 (Parameters)
- 1.6 推理時間 (Inference Time)
- 2.具體的訓練過程
- 1.數據集加載
- 2.模型實例化
- 3.創建數據加載器
- 4.優化器和學習率調度器設置
- 5.混合精度訓練設置
- 6.訓練循環
- 3.結果展示
- 五、可視化維度分析
- 1.混淆矩陣圖
- 2.雷達圖
- 3.準確率和損失率的收斂曲線圖
- 4.仿真指標柱狀圖
- 5.仿真指標折線圖
- 六、總結
卷積神經網絡(CNN)因其強大的特征提取能力和深度學習架構而備受推崇,CNN在處理圖像數據時展現出的卓越性能,使其成為解決各種視覺識別任務的首選工具。WISDM數據集是一個廣泛用于運動估計研究的基準數據集,它包含了多個視頻序列,每個序列都記錄了攝像頭在不同方向上移動時捕捉到的圖像。在本研究中,我們將探討如何利用 CNN來訓練和優化WISDM數據集,以提高運動估計的準確性和魯棒性。
一、WISDM數據集分析及介紹
WISDM數據集是一個用于人類活動識別(Human Activity Recognition, HAR)的公共數據集。它包含了從智能手機和智能手表收集的傳感器數據,這些數據被用來識別多種不同的人類活動:
-
數據集來源與構成:
- WISDM數據集由福特漢姆大學計算機與信息科學系的Gary Weiss博士領導的團隊創建。
- 數據集包含了51名參與者進行的18種不同的活動,每種活動的數據都是通過佩戴在身體不同部位的智能手機和智能手表上的加速度計和陀螺儀以20Hz的頻率收集得到的。
-
數據集特點:
- 數據集中的活動包括但不限于走路、跑步、上下樓梯、坐、站等。
- 每個活動的數據長度為3分鐘,為研究者提供了充足的時間序列數據進行分析。
-
數據集的應用:
- WISDM數據集適用于開發和測試各種HAR模型,尤其是基于深度學習的模型,如卷積神經網絡(CNN)。
二、CNN網絡結構及介紹
卷積神經網絡是一種專門用來處理具有類似網格結構的數據的神經網絡,如圖像。CNN在圖像識別、視頻分析和自然語言處理等領域取得了巨大的成功。
1. CNN的核心組件
1.1 卷積層(Convolutional Layer)
- 功能:通過卷積核(filter)在輸入數據上滑動,提取局部特征。
- 數學表示:
( I ? K ) ( i , j ) = ∑ m ∑ n I ( i ? m , j ? n ) ? K ( m , n ) (I * K)(i,j) = \sum_{m}\sum_{n} I(i-m, j-n) \cdot K(m,n) (I?K)(i,j)=m∑?n∑?I(i?m,j?n)?K(m,n)
其中, I I I為輸入, K K K為卷積核。 - 參數:
- 卷積核大小(kernel size):通常為3×3或5×5
- 步幅(stride):控制滑動步長
- 填充(padding):保持特征圖尺寸
1.2 池化層(Pooling Layer)
- 功能:對特征圖進行下采樣,降低計算復雜度,增強特征不變性。
- 類型:
- 最大池化(Max Pooling):取局部區域最大值
- 平均池化(Average Pooling):取局部區域平均值
- 參數:
- 池化窗口大小:通常為2×2
- 步幅:通常與窗口大小一致
1.3 激活函數層(Activation Layer)
- 功能:引入非線性,增強模型的表達能力。
- 常用激活函數:
- ReLU(Rectified Linear Unit): f ( x ) = max ? ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
- Leaky ReLU: f ( x ) = max ? ( 0.01 x , x ) f(x) = \max(0.01x, x) f(x)=max(0.01x,x)
- Swish: f ( x ) = x ? σ ( x ) f(x) = x \cdot \sigma(x) f(x)=x?σ(x),其中 σ \sigma σ為sigmoid函數
1.4 全連接層(Fully Connected Layer)
- 功能:將提取的特征映射到輸出空間(如分類概率)。
- 特點:
- 參數量較大
- 通常位于網絡末端
2. CNN的層次化特征提取
CNN通過多層卷積和池化操作,逐步提取從低級到高級的特征:
- 低級特征:邊緣、角點、紋理等
- 中級特征:局部形狀、簡單模式
- 高級特征:語義信息、復雜結構
3. CNN的變體與擴展
3.1 深度可分離卷積(Depthwise Separable Convolution)
- 結構:
- 深度卷積(Depthwise Convolution):每個輸入通道單獨卷積
- 逐點卷積(Pointwise Convolution):1×1卷積融合通道信息
- 優點:
- 顯著減少參數量和計算量
- 公式: 1 N + 1 D k 2 \frac{1}{N} + \frac{1}{D_k^2} N1?+Dk2?1?( N N N為輸出通道數, D k D_k Dk?為卷積核大小)
3.2 空洞卷積(Dilated Convolution)
- 特點:
- 通過增加卷積核采樣間隔,擴大感受野
- 公式: F d i l a t e d ( i , j ) = ∑ m ∑ n I ( i + r ? m , j + r ? n ) ? K ( m , n ) F_{dilated}(i,j) = \sum_{m}\sum_{n} I(i+r\cdot m, j+r\cdot n) \cdot K(m,n) Fdilated?(i,j)=∑m?∑n?I(i+r?m,j+r?n)?K(m,n)
- 其中, r r r為空洞率
3.3 注意力機制(Attention Mechanism)
- 作用:
- 動態調整特征權重
- 增強重要特征的表達能力
- 常見形式:
- 通道注意力(SENet)
- 空間注意力(CBAM)
4. CNN在時間序列數據中的應用
4.1 1D卷積
- 特點:
- 卷積核沿時間維度滑動
- 適用于傳感器數據、語音信號等
- 示例:
tf.keras.layers.Conv1D(filters=64, kernel_size=3, strides=1, padding='same')
4.2 時序池化
- 方法:
- 全局平均池化(Global Average Pooling)
- 自適應最大池化(Adaptive Max Pooling)
4.3 混合架構
- CNN-LSTM:
- CNN提取局部特征
- LSTM捕捉時序依賴
- CNN-Transformer:
- CNN提取空間特征
- Transformer建模長時依賴
5. CNN的優化策略
5.1 正則化方法
- Dropout:隨機丟棄神經元,防止過擬合
- Batch Normalization:標準化層輸入,加速訓練
- 權重衰減(L2正則化):約束權重幅度
5.2 學習率調整
- 策略:
- 學習率衰減(Learning Rate Decay)
- 余弦退火(Cosine Annealing)
- 預熱(Warmup)
6. 典型CNN架構示例
def cnn(input_shape, num_classes):inputs = tf.keras.Input(shape=input_shape)# 卷積模塊x = tf.keras.layers.Conv1D(64, 5, padding='same', activation='relu')(inputs)x = tf.keras.layers.MaxPooling1D(2)(x)x = tf.keras.layers.Conv1D(128, 3, padding='same', activation='relu')(x)x = tf.keras.layers.GlobalAveragePooling1D()(x)# 分類頭x = tf.keras.layers.Dense(128, activation='relu')(x)outputs = tf.keras.layers.Dense(num_classes, activation='softmax')(x)return tf.keras.Model(inputs, outputs)
三、WISDM數據集分割及處理
WISDM數據集下載鏈接:https://www.cis.fordham.edu/wisdm/includes/datasets/latest/WISDM_ar_latest.tar.gz
加載、預處理和準備WISDM數據集,以便用于人類活動識別(HAR)任務:
- 參數設定:
dataset_dir: 指定原始數據存放的目錄。WINDOW_SIZE: 定義滑窗的大小。OVERLAP_RATE: 定義滑窗的重疊率。SPLIT_RATE: 定義訓練集和驗證集的分割比例。VALIDATION_SUBJECTS: 定義留一法驗證時使用的特定主題(subject)集合。Z_SCORE: 決定是否進行標準化處理。SAVE_PATH: 定義預處理后數據保存的路徑。
def WISDM(dataset_dir='./WISDM_ar_v1.1', WINDOW_SIZE=200, OVERLAP_RATE=0.5, SPLIT_RATE=(8, 2), VALIDATION_SUBJECTS={}, Z_SCORE=True, SAVE_PATH=os.path.abspath('D:/PycharmProjects/xyp-task')):
- 數據集下載:
- 使用
download_dataset函數,從福特漢姆大學提供的URL下載WISDM數據集,并將其存儲在dataset_dir指定的目錄中。
download_dataset(dataset_name='WISDM',file_url='https://www.cis.fordham.edu/wisdm/includes/datasets/latest/WISDM_ar_latest.tar.gz', dataset_dir=dataset_dir
)
- 數據清洗與讀取:
- 從指定路徑的文本文件中讀取原始數據,該文件包含了多個以逗號分隔的條目。
- 清洗數據,移除不完整的條目,確保每行數據都包含參與者ID、活動標簽和三個傳感器信號。
- 將清洗后的數據轉換為NumPy數組,便于后續處理。
- 標簽編碼:
- 使用
category_dict字典,將活動標簽的字符串表示(如’Walking’、'Jogging’等)映射為整數ID,以便于機器學習模型處理。
- 滑窗處理:
- 對清洗并編碼后的數據應用滑窗分割,生成固定大小的樣本窗口。這些窗口將用于訓練和測試機器學習模型。
- 分割數據集:
- 根據是否提供了
VALIDATION_SUBJECTS,選擇留一法或平均法來分割數據集。留一法是為每個參與者ID分別創建訓練集和測試集,而平均法則是按照SPLIT_RATE比例分割數據。
- 數據整合:
- 將分割后的數據和標簽分別整合到
xtrain、xtest、ytrain、ytest列表中,這些列表將包含所有訓練和測試數據。
- 標準化處理:
- 如果
Z_SCORE參數為True,則對整合后的xtrain和xtest進行Z分數標準化處理,以消除不同傳感器信號量級的影響。
- 數據保存:
- 如果提供了
SAVE_PATH,則使用save_npy_data函數將預處理后的訓練集和測試集數據保存為.npy格式的文件,這有助于后續加載和使用數據。
準備WISDM數據集,使其適合用于CNN網絡模型的訓練和測試。通過滑窗處理,可以將原始的長時間序列傳感器數據轉換為固定大小的短時間序列數據,這有助于訓練卷積神經網絡等模型進行人類活動識別。此外,通過留一法或平均法分割數據集,可以為模型提供訓練集和驗證集,以評估模型性能。最后,通過Z分數標準化,可以提高模型對數據分布變化的魯棒性。
四、CNN網絡訓練WISDM數據集
1.常用的仿真指標
1.1 準確率 (Accuracy)
準確率是所有正確預測樣本數占總樣本數的比例。它是最直觀的性能指標,計算公式如下:
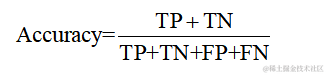
1.2 精確率 (Precision)
精確率是所有預測為正類中真正為正類的比例,它關注的是預測為正類的結果的準確性。計算公式如下:
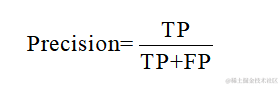
1.3 召回率 (Recall)
召回率是所有實際為正類中被正確預測為正類的比例,它衡量的是模型捕捉正類樣本的能力。計算公式如下:
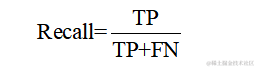
1.4 F1分數 (F1-Score)
F1分數是精確率和召回率的調和平均值,它在兩者之間取得平衡,是評價分類模型性能的一個重要指標。計算公式如下:

1.5 參數量 (Parameters)
參數量指的是網絡模型中需要訓練的參數總數。參數量越多,模型的容量越大,但也越容易過擬合。
1.6 推理時間 (Inference Time)
推理時間指的是模型對數據進行預測的時間。它可以是單個樣本的推理時間,也可以是整個數據集推理所需的總時間。推理時間是評估模型在實際應用中效率的重要指標,尤其是在需要實時響應的應用場景中。
2.具體的訓練過程
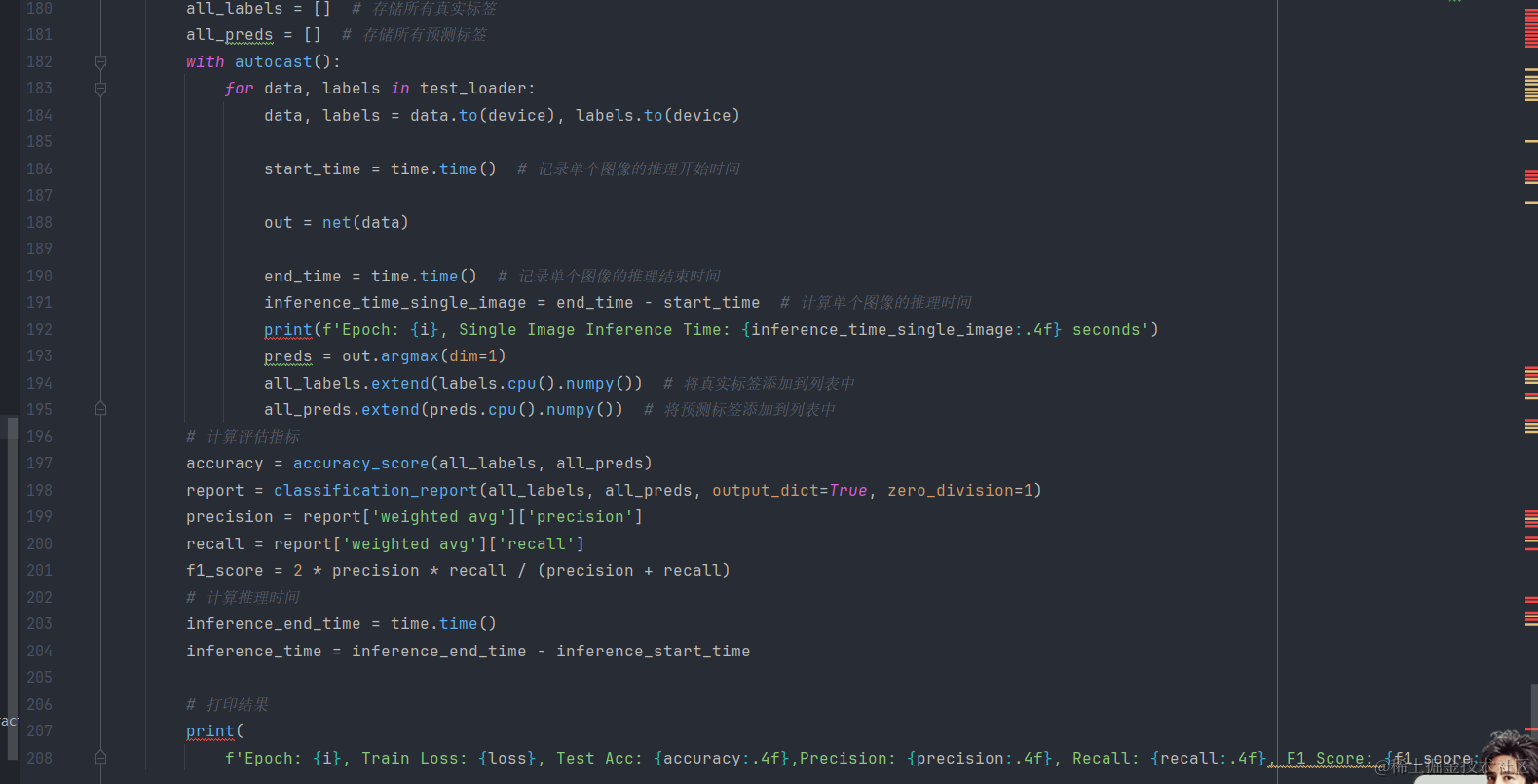
1.數據集加載
根據選擇的數據集和模型,加載數據集,并進行必要的預處理。
2.模型實例化
根據選擇的模型,實例化一個模型對象,并將其移動到選定的設備上。
3.創建數據加載器
使用DataLoader創建訓練和測試數據的加載器,允許在訓練中以小批量方式加載數據。
4.優化器和學習率調度器設置
定義了AdamW優化器和學習率調度器,用于在訓練過程中更新模型參數和調整學習率。
5.混合精度訓練設置
實例化GradScaler對象,用于在訓練中使用混合精度,可以提高訓練效率和精度。
6.訓練循環
對于每個訓練輪次,執行以下步驟:
- 設置模型為訓練模式。
- 在每個小批量數據上執行前向傳播、計算損失、執行反向傳播并更新模型參數。
- 學習率調度器步進。
- 設置模型為評估模式。
- 在測試集上進行預測,并計算模型的準確率、精確率、召回率和F1分數。
- 打印每個輪次的訓練損失、測試準確率和其他評估指標。
for i in range(EP):net.train()inference_start_time = time.time()for data, label in train_loader:data, label = data.to(device), label.to(device)# 前向過程(model + loss)開啟 autocast,混合精度訓練with autocast():out = net(data)loss = loss_fn(out, label)optimizer.zero_grad() # 梯度清零scaler.scale(loss).backward() # 梯度放大scaler.step(optimizer) # unscale梯度值scaler.update()lr_sch.step()
3.結果展示
在每個訓練輪次結束時,打印出當前輪次的訓練信息和模型評估指標。
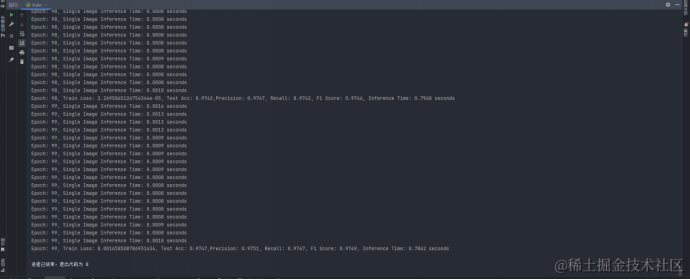
從訓練結果中可以看出,基于CNN網絡訓練得到的以上六種指標數據分別為:
| CNN | 0.9729 | 0.9734 | 0.9729 | 0.9732 | 528390 | 0.0008 0.7563 |
|---|
五、可視化維度分析
將CNN網絡訓練WISDM數據集的結果進行可視化維度分析:
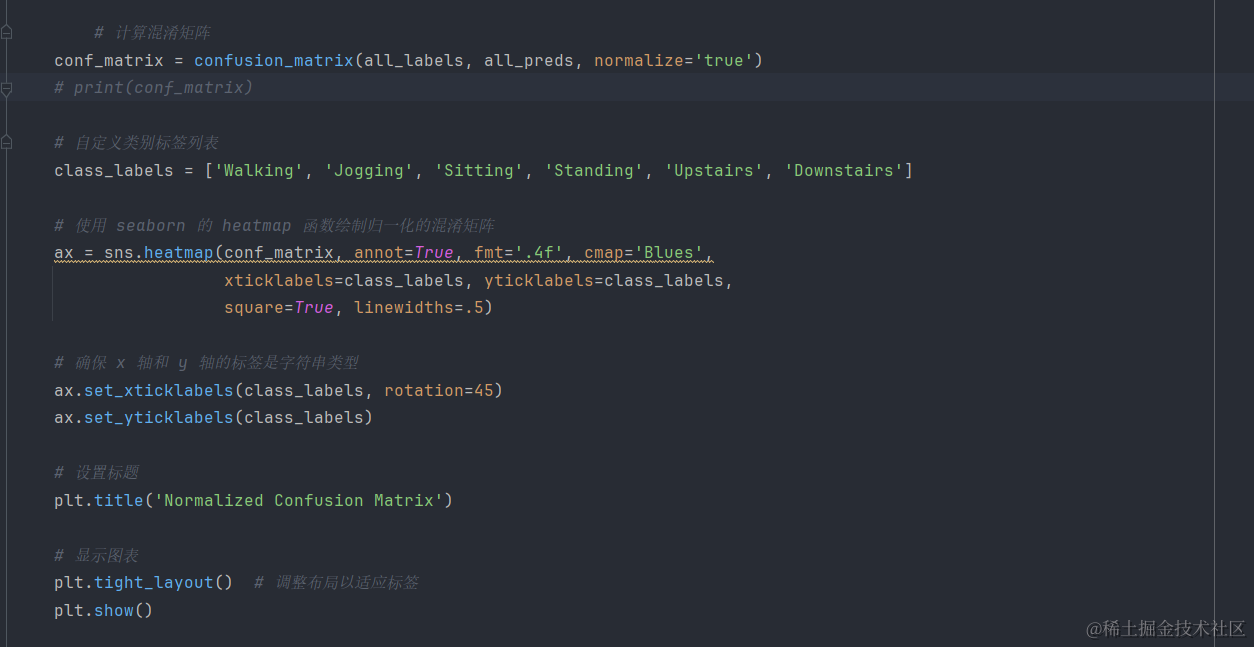
1.混淆矩陣圖
混淆矩陣是一個N×N的矩陣,N代表的是你的分類標簽個數。混淆矩陣的橫縱坐標軸分別為模型預測值和真實值,在圖中縱軸是真實值而橫軸代表模型預測值。
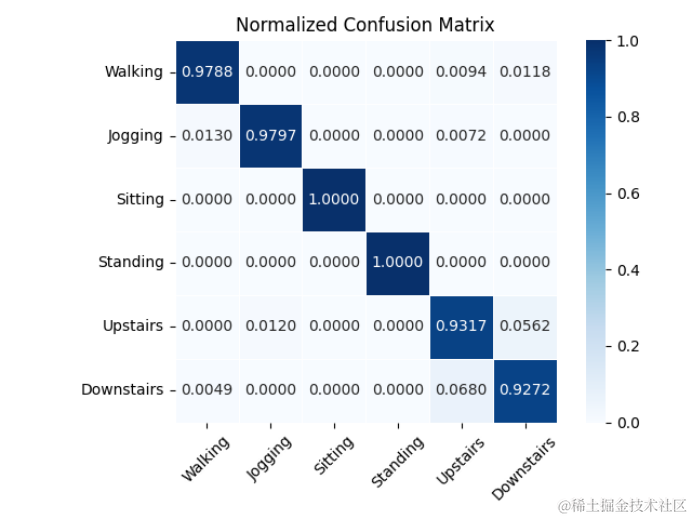
2.雷達圖
雷達圖可以反映多個行為的某個指標值映射在坐標軸上,可以更直觀的觀察出每個行為的指標值大小。
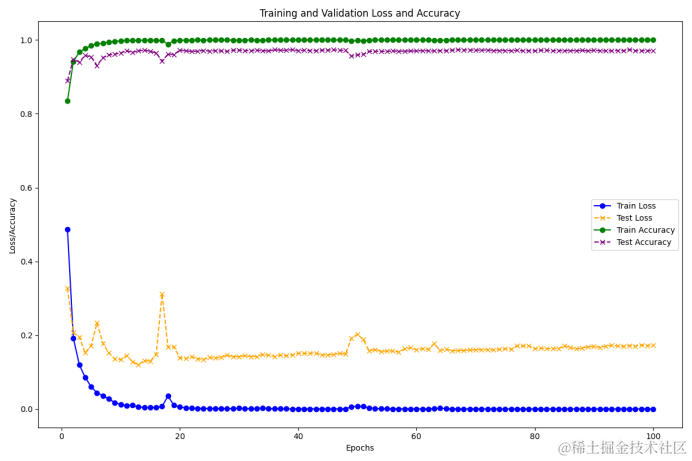
3.準確率和損失率的收斂曲線圖
準確率和損失率的收斂曲線圖橫坐標是訓練輪次,縱坐標是模型的準確率以及損失率,這個圖可以直觀的看出你的模型在訓練以及測試過程中的準確率和損失率走向和模型收斂以后的準確率的數值范圍,也可以反映出你的模型在訓練過程中是否穩定。
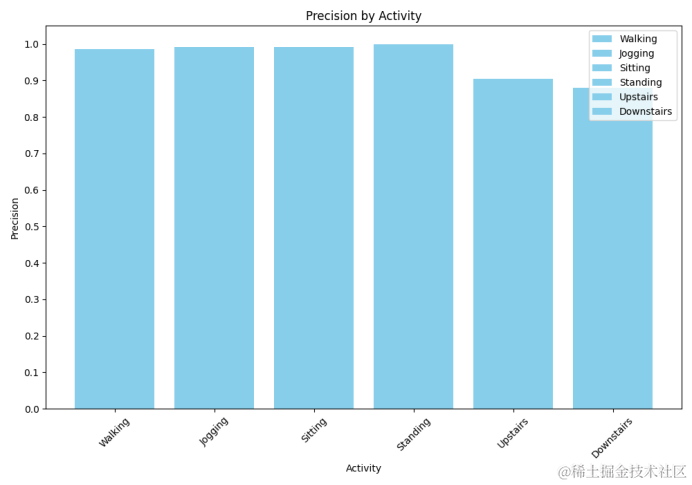
4.仿真指標柱狀圖
仿真指標柱狀圖是一種以長方形的長度為變量來表示各個行為的指標值,例如可以表示你的模型在WISDM數據集中的每個行為精確率的值,通過由一系列高度不等的縱向條紋表示數據分布的情況。
5.仿真指標折線圖
仿真指標折線圖是一種用來表示超參數設置大小對模型效果影響的可視化方式,可以表示我們的CNN網絡模型在WISDM數據集中Batch size對加權F1分數的影響。

六、總結
在本研究中,我們深入探討了卷積神經網絡(CNN)在處理WISDM數據集時的應用,該數據集是一個用于人類活動識別(HAR)的公共數據集。通過一系列數據處理步驟,我們將原始的長時間序列傳感器數據轉換為適合CNN模型訓練的固定大小的短時間序列數據。此外,我們還介紹了CNN的核心思想、優點、缺點以及基本的網絡結構,并通過可視化方法對訓練結果進行了全面的分析。
通過本研究,我們證明了CNN在處理時間序列數據和人類活動識別任務中的有效性。未來的工作可以探索更先進的網絡結構和訓練策略,以進一步提高模型的性能和應用范圍。






 MIT6.S081 2023 學習筆記 (Day7: LAB6 Multithreading))












