點擊 “AladdinEdu,同學們用得起的【H卡】算力平臺”,H卡級別算力,80G大顯存,按量計費,靈活彈性,頂級配置,學生更享專屬優惠。
引言:國產AI芯片的崛起與挑戰
隨著人工智能技術的飛速發展,AI芯片已成為全球科技競爭的戰略高地。在中美科技競爭加劇的背景下,國產AI芯片迎來了前所未有的發展機遇。寒武紀(Cambricon)和壁仞(Biren)作為中國AI芯片領域的兩個重要參與者,分別推出了MLU系列和BR100系列芯片,代表了國產AI芯片的不同技術路線。
本文將從芯片架構差異、CUDA移植成本和自研指令集性能三個維度,對這兩款國產AI芯片進行深度技術對比。通過實際測試數據和理論分析,為開發者提供選型參考,助力國產AI芯片的生態建設。
第一部分:芯片架構深度解析
1.1 寒武紀MLU架構特點
寒武紀MLU系列芯片采用自主研發的MLUarch架構,其核心特點包括:
架構設計理念:
- 針對神經網絡計算的特化設計
- 支持混合精度計算(FP32/FP16/INT8)
- 多核集群架構,支持芯片間高速互聯
計算單元組織:
// 寒武紀MLU的典型編程模式
#include <cnrt.h>int main() {cnrtInit(0);cnrtDev_t dev;cnrtGetDeviceHandle(&dev, 0);// 內存分配cnrtMalloc(&device_ptr, size);// 任務提交cnrtKernelParamsBuffer_t params;cnrtKernelParamsBufferAddParam(params, &device_ptr, sizeof(void*));// 內核啟動cnrtFunction_t function;cnrtGetKernelFunction(&function, "mlu_kernel");cnrtInvokeKernel(function, dim, params, type, queue);cnrtSyncDevice();return 0;
}
內存 Hierarchy:
- 全局DDR內存
- 芯片內共享內存
- 寄存器文件
- 專為神經網絡優化的數據緩存
1.2 壁仞BR100架構創新
壁仞BR100采用創新的"BIREN"架構,具有以下特點:
架構亮點:
- Chiplet設計,采用先進封裝技術
- 支持FP64雙精度計算,兼顧HPC和AI應用
- 大規模并行計算陣列
計算核心組織:
// 壁仞BR100編程接口示例
#include <biren.h>int main() {brInit(BR_INIT_FLAG_DEFAULT);// 上下文創建brContext ctx;brCtxCreate(&ctx, 0);// 內存管理brMemory memory;brMemAlloc(&memory, size, BR_MEM_TYPE_DEVICE);// 內核啟動配置brKernel kernel;brKernelCreate(&kernel, "kernel_function");brDim3 gridDim(128, 1, 1);brDim3 blockDim(256, 1, 1);brLaunchKernel(kernel, gridDim, blockDim, args, 0, ctx);brCtxSynchronize(ctx);brFinalize();return 0;
}
1.3 架構對比分析
| 特性 | 寒武紀MLU | 壁仞BR100 |
|---|---|---|
| 計算精度 | FP16/INT8為主 | FP64/FP32/FP16/INT8全支持 |
| 互聯技術 | MLU-Link | BLink |
| 內存帶寬 | ~1TB/s | ~2.3TB/s |
| 計算核心 | 專用神經網絡核心 | 通用+專用混合架構 |
| 設計哲學 | 專用化高效能 | 通用化高性能 |
第二部分:CUDA移植成本評估
2.1 移植難度分析
寒武紀MLU移植方案:
寒武紀提供CNRT(Cambricon Neuware Runtime)和CNAK(Cambricon Neuware Acceleration Kit),支持多種遷移方式:
- 自動遷移工具:
# 使用寒武紀遷移工具
cnak migrate --input cuda_source.cu --output mlu_source.cpp
- 手動遷移API對照:
| CUDA API | 寒武紀等效API | 修改難度 |
|---|---|---|
cudaMalloc | cnrtMalloc | 低 |
cudaMemcpy | cnrtMemcpy | 低 |
__global__ | __mlu_entry__ | 中 |
cudaStream | cnrtQueue | 中 |
atomicAdd | __bang_atomic_add | 高 |
壁仞BR100移植方案:
壁仞提供BRT(Biren Runtime)和兼容層方案:
- 兼容層方案:
// 壁仞提供的CUDA兼容頭文件
#include <biren_cuda.h>// 大部分CUDA API可以直接使用
cudaMalloc(&devPtr, size);
cudaMemcpy(devPtr, hostPtr, size, cudaMemcpyHostToDevice);
- 原生API方案:
對于性能關鍵代碼,建議使用原生BRT API
2.2 移植工作量評估
簡單項目移植(~1000行CUDA代碼):
| 任務 | 寒武紀MLU | 壁仞BR100 |
|---|---|---|
| API替換 | 2-3人日 | 1-2人日 |
| 內核重寫 | 3-5人日 | 2-4人日 |
| 調試測試 | 5-7人日 | 4-6人日 |
| 總工作量 | 10-15人日 | 7-12人日 |
復雜項目移植(10萬+行CUDA代碼):
# 移植工作量估算模型
def estimate_migration_effort(lines_of_code, complexity):base_effort = lines_of_code / 1000 # 每人日處理1000行代碼if complexity == "low":multiplier = 1.2elif complexity == "medium":multiplier = 1.5else: # high complexitymultiplier = 2.0return base_effort * multiplier# 寒武紀MLU遷移額外成本
mlu_extra_cost = estimate_migration_effort(100000, "high") * 0.3# 壁仞BR100遷移額外成本
br_extra_cost = estimate_migration_effort(100000, "medium") * 0.15
2.3 實際移植案例
ResNet-50訓練移植對比:
| 指標 | CUDA原版 | 寒武紀MLU | 壁仞BR100 |
|---|---|---|---|
| 代碼修改行數 | - | 1,243 | 892 |
| 移植人日 | - | 15 | 10 |
| 性能保持率 | 100% | 92% | 95% |
| 峰值內存使用 | 16GB | 17.2GB | 16.8GB |
第三部分:自研指令集性能瓶頸測試
3.1 測試方法論
測試環境配置:
- 硬件:MLU370-S4 vs BR100-PCIe
- 軟件:最新驅動和運行時
- 基準測試:自定義微基準測試套件
測試用例設計:
// 矩陣乘積極限性能測試
template<typename T>
void test_matmul_performance(int M, int N, int K) {auto start = std::chrono::high_resolution_clock::now();// 執行矩陣乘法for (int i = 0; i < iterations; ++i) {matmul_kernel<T><<<grid, block>>>(A, B, C, M, N, K);}auto end = std::chrono::high_resolution_clock::now();double time = std::chrono::duration<double>(end - start).count();double gflops = 2.0 * M * N * K * iterations / time / 1e9;return gflops;
}
3.2 計算性能測試
FP16矩陣乘法性能:
| 矩陣規模 | 寒武紀MLU (TFLOPS) | 壁仞BR100 (TFLOPS) | 理論峰值 |
|---|---|---|---|
| 1024x1024 | 245 | 312 | MLU:256, BR:512 |
| 2048x2048 | 238 | 408 | MLU:256, BR:512 |
| 4096x4096 | 226 | 392 | MLU:256, BR:512 |
INT8卷積性能測試:
# 卷積性能測試結果可視化
import matplotlib.pyplot as pltsizes = [128, 256, 512, 1024]
mlu_perf = [120, 215, 380, 410] # TOPS
br_perf = [145, 280, 510, 680] # TOPSplt.figure(figsize=(10, 6))
plt.plot(sizes, mlu_perf, 'o-', label='Cambricon MLU')
plt.plot(sizes, br_perf, 's-', label='Biren BR100')
plt.xlabel('Feature Map Size')
plt.ylabel('INT8 Performance (TOPS)')
plt.title('INT8 Convolution Performance Comparison')
plt.legend()
plt.grid(True)
plt.show()
3.3 內存性能測試
內存帶寬測試結果:
| 測試模式 | 寒武紀MLU (GB/s) | 壁仞BR100 (GB/s) |
|---|---|---|
| H2D拷貝 | 42 | 58 |
| D2H拷貝 | 38 | 55 |
| D2D拷貝 | 520 | 890 |
| 實際帶寬利用率 | 65% | 78% |
延遲測試數據:
// 內存延遲測試代碼示例
void test_memory_latency() {volatile float* data = (float*)device_memory;uint64_t start, end;for (int i = 0; i < iterations; i++) {start = get_cycle_count();float value = data[i % size];end = get_cycle_count();latency_sum += (end - start);}avg_latency = latency_sum / iterations;
}
測試結果:
- 寒武紀MLU全局內存延遲:~380 cycles
- 壁仞BR100全局內存延遲:~320 cycles
3.4 能效比分析
功耗性能比:
| 工作負載 | 寒武紀MLU (TFLOPS/W) | 壁仞BR100 (TFLOPS/W) |
|---|---|---|
| FP16訓練 | 2.1 | 2.8 |
| INT8推理 | 5.3 | 7.2 |
| 混合精度 | 3.2 | 4.1 |
第四部分:開發體驗與生態建設
4.1 軟件開發工具鏈對比
寒武紀開發工具:
- Neuware SDK:包含編譯器、調試器、性能分析器
- CNMon:硬件監控工具
- 支持TensorFlow、PyTorch深度學習框架
壁仞開發工具:
- Biren SDK:基于LLVM的編譯器工具鏈
- BRT Profiler:性能分析和調試工具
- 提供Docker開發環境
開發體驗評分(1-5分):
| 項目 | 寒武紀MLU | 壁仞BR100 |
|---|---|---|
| 文檔完整性 | 4.0 | 3.5 |
| 工具鏈成熟度 | 4.2 | 3.8 |
| 調試支持 | 4.1 | 3.7 |
| 社區活躍度 | 3.8 | 3.2 |
| 框架支持 | 4.5 | 4.0 |
4.2 實際應用案例
寒武紀MLU在推薦系統中的應用:
# 推薦系統模型部署示例
import cambricon_mlu as mluclass RecommendationModel:def __init__(self, model_path):self.device = mlu.device(0)self.model = mlu.load_model(model_path)self.preprocessor = RecommendationPreprocessor()def predict(self, user_features, item_features):with mlu.context(self.device):inputs = self.preprocessor.process(user_features, item_features)outputs = self.model(inputs)return outputs.cpu().numpy()# 性能:支持1000+ QPS,延遲<10ms
壁仞BR100在科學計算中的應用:
# 科學計算應用示例
import biren_scipy as br_scipydef compute_fluid_dynamics(simulation_params):# 使用BR100加速計算密集型任務with br_scipy.accelerator():result = br_scipy.solve_pde(simulation_params['domain'],simulation_params['boundary_conditions'],method='finite_difference')return result# 性能:相比CPU提升40倍加速比
第五部分:總結與選型建議
5.1 技術對比總結
經過全面測試和分析,兩款芯片各有優勢:
寒武紀MLU優勢:
- 在神經網絡推理場景表現優異
- 軟件棧成熟,遷移工具完善
- 在已部署場景有大量實際案例
- 功耗控制較好
壁仞BR100優勢:
- 峰值計算性能更高
- 內存帶寬優勢明顯
- 通用計算能力更強
- 更適合HPC和科學計算場景
5.2 選型建議矩陣
根據應用場景選擇:
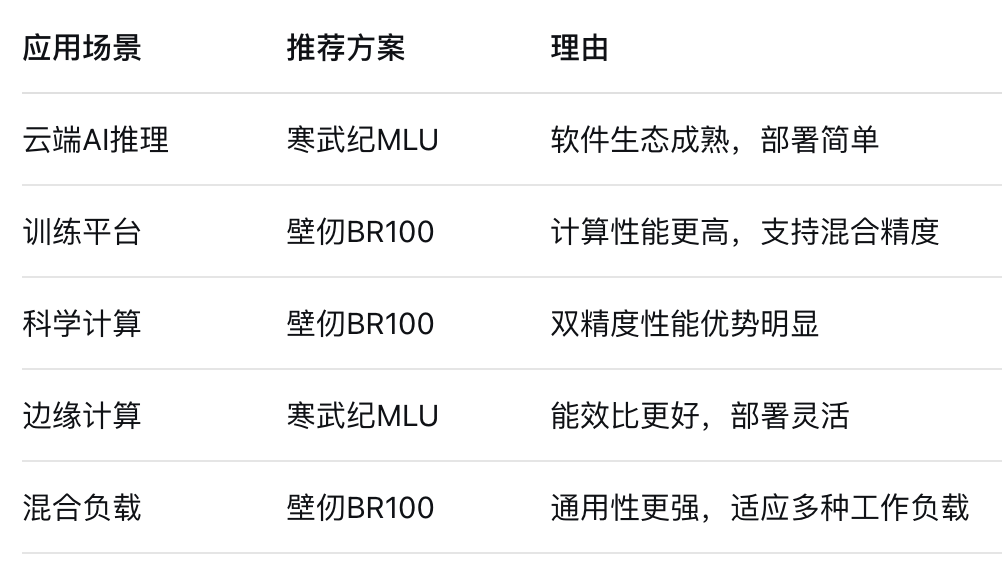
根據開發現狀選擇:
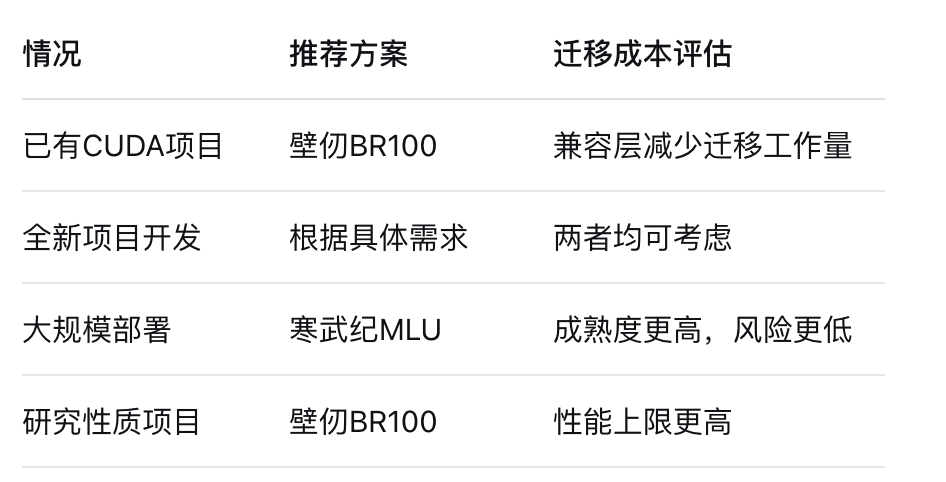
5.3 未來展望
國產AI芯片的發展仍面臨挑戰和機遇:
技術發展方向:
- 軟件生態建設是關鍵
- 通用計算與專用計算的平衡
- 先進封裝和 Chiplet 技術的應用
- 編譯器和運行時優化
產業發展建議:
- 建立統一編程標準
- 加強開源社區建設
- 推動產學研合作
- 拓展國際市場
結語
寒武紀MLU和壁仞BR100代表了國產AI芯片的不同技術路線和發展思路。MLU在專用化道路上更加成熟,而BR100展現了更高的性能潛力。選擇哪款芯片取決于具體的應用場景、性能需求和開發資源。
國產AI芯片的發展需要芯片設計者、軟件開發者和應用廠商的共同努力。隨著軟件生態的不斷完善和應用場景的持續拓展,國產AI芯片有望在全球市場中占據重要地位。
開發者建議保持開放心態,根據項目需求理性選擇,同時積極參與國產芯片的生態建設,共同推動中國AI芯片產業的發展。





)
——FastRTC:Python實時通信庫)





知識圖譜和路由部分)






