目錄
PEP8 代碼風格指南
知識點
介紹
愚蠢的一致性就像沒腦子的妖怪
代碼排版
縮進
制表符還是空格
每行最大長度
空行
源文件編碼
導入包
字符串引號
表達式和語句中的空格
不能忍受的情況
其他建議
注釋
塊注釋
行內注釋
文檔字符串
版本注記
命名約定
覆蓋原則
規定:命名約定
規定:命名約定
公共和內部接口
程序編寫建議
總結
參考文獻
版權說明
迭代器、生成器、裝飾器
知識點
迭代器
生成器
生成器表達式
閉包
裝飾器
總結
Virtualenv
一、實驗介紹
實驗知識點
二、安裝 virtualenv
三、用法
四、總結
測試
一、實驗介紹
知識點
二、測試范圍
三、單元測試
單元測試模塊
階乘計算程序
3.1 第一個測試用例
測試哪個函數
3.2 各類 assert 語句
3.3 異常測試
3.4 mounttab.py
3.5 測試覆蓋率
覆蓋率示例
四、總結
項目結構
一、實驗介紹
知識點
二、創建 Python 項目
2.1 MANIFEST.in
2.2 安裝 python-setuptools 包
2.3 setup.py
2.3.1. setup.py 用例
2.4 Python Package Index (PyPI)
三、總結
Flask 介紹
一、實驗介紹
知識點
二、基本概念
什么是 Flask?
什么是模板引擎?
三、"Hello World" 應用
四、Flask 中使用參數
五、額外工作
六、總結
PEP8 代碼風格指南
編程語言不是藝術,而是工作或者說是工具,所以整理并遵循一套編碼規范是十分必要的。 這篇文章原文實際上來自于這里:pep-0008
知識點
- 代碼排版
- 字符串引號
- 表達式和語句中的空格
- 注釋
- 版本注記
- 命名約定
- 公共和內部接口
- 程序編寫建議
建議在實驗樓中打開 Python 解釋器或者 vim 自己照著做一下,或者看看以前自己寫的代碼
介紹
這份文檔給出的代碼約定適用于主要的 Python 發行版所有標準庫中的 Python 代碼。請參閱相似的 PEP 信息,其用于描述實現 Python 的 C 代碼規范[1]。
這份文檔和 ?PEP 257(文檔字符串約定) 改編自 Guido 的 Python 風格指南原文,從 Barry 的風格指南里添加了一些東西[2]。
隨著時間的推移,這份額外約定的風格指南已經被認可了,過去的約定由于語言自身的發展被淘汰了。
許多項目有它們自己的編碼風格指南。如果有沖突,優先考慮項目規定的編碼指南。
愚蠢的一致性就像沒腦子的妖怪
Guido 的一個主要見解是讀代碼多過寫代碼。這里提供指南的意圖是強調代碼可讀性的重要性,并且使大多數 Python 代碼保持一致性。如 ?PEP 20? 所述,“Readability counts”。
風格指南是關于一致性的。風格一致對于本指南來說是重要的,對一個項目來說是更重要的,對于一個模塊或者方法來說是最重要的。
但是最最重要的是:知道什么時候應該破例–有時候這份風格指南就是不適用。有疑問時,用你最好的判斷力,對比其它的例子來確定這是不是最好的情況,并且不恥下問。
特別說明:不要為了遵守這份風格指南而破壞代碼的向后兼容性。
這里有一些好的理由去忽略某個風格指南:
- 當應用風格指南的時候使代碼更難讀了,對于嚴格依循風格指南的約定去讀代碼的人也是不應該的。
- 為了保持和風格指南的一致性同時也打破了現有代碼的一致性(可能是歷史原因)–雖然這也是一個整理混亂代碼的機會(現實中的 XP 風格)。
- 因為問題代碼的歷史比較久遠,修改代碼就沒有必要性了。
- 當代碼需要與舊版本的 Python 保持兼容,而舊版 Python 又不支持風格指南中提到的特性的時候。
代碼排版
縮進
每層縮進使用 4 個空格。
續行要么與圓括號、中括號、花括號這樣的被包裹元素保持垂直對齊,要么放在 Python 的隱線(注:應該是相對于 def 的內部塊)內部,或者使用懸掛縮進。使用懸掛縮進的注意事項:第一行不能有參數,用進一步的縮進來把其他行區分開。
好的示例:
# Aligned with opening delimiter.
foo = long_function_name(var_one, var_two,var_three, var_four)# More indentation included to distinguish this from the rest.
def long_function_name(var_one, var_two, var_three,var_four):print(var_one)# Hanging indents should add a level.
foo = long_function_name(var_one, var_two,var_three, var_four)
不好的示例:
# Arguments on first line forbidden when not using vertical alignment.
foo = long_function_name(var_one, var_two,var_three, var_four)# Further indentation required as indentation is not distinguishable.
def long_function_name(var_one, var_two, var_three,var_four):print(var_one)
空格規則是可選的:
# Hanging indents *may* be indented to other than 4 spaces.
foo = long_function_name(var_one, var_two,var_three, var_four)
當 if 語句的條件部分足夠長,需要將它寫入到多個行,值得注意的是兩個連在一起的關鍵字(i.e. if),添加一個空格,給后續的多行條件添加一個左括號形成自然地 4 空格縮進。如果和嵌套在 if 語句內的縮進代碼塊產生了視覺沖突,也應該被自然縮進 4 個空格。這份增強建議書對于怎樣(或是否)把條件行和 if 語句的縮進塊在視覺上區分開來是沒有明確規定的。可接受的情況包括,但不限于:
# No extra indentation.
if (this_is_one_thing andthat_is_another_thing):do_something()# Add a comment, which will provide some distinction in editors
# supporting syntax highlighting.
if (this_is_one_thing andthat_is_another_thing):# Since both conditions are true, we can frobnicate.do_something()# Add some extra indentation on the conditional continuation line.
if (this_is_one_thingand that_is_another_thing):do_something()
在多行結構中的右圓括號、右中括號、右大括號應該放在最后一行的第一個非空白字符的正下方,如下所示:
my_list = [1, 2, 3,4, 5, 6,]
result = some_function_that_takes_arguments('a', 'b', 'c','d', 'e', 'f',)
或者放在多行結構的起始行的第一個字符正下方,如下:
my_list = [1, 2, 3,4, 5, 6,
]
result = some_function_that_takes_arguments('a', 'b', 'c','d', 'e', 'f',
)
制表符還是空格
空格是首選的縮進方法。
制表符(Tab)應該被用在那些以前就使用了制表符縮進的地方。
Python 3 不允許混合使用制表符和空格來縮進代碼。
混合使用制表符和空格縮進的 Python 2 代碼應該改為只使用空格。
當使用-t選項來調用 Python 2 的命令行解釋器的時候,會對混合使用制表符和空格的代碼發出警告。當使用-tt選項的時候,這些警告會變成錯誤。這些選項是強烈推薦的!
每行最大長度
限制每行的最大長度為 79 個字符。
對于那些約束很少的文本結構(文檔字符串或注釋)的長塊,應該限制每行長度為 72 個字符。
限制編輯窗口的寬度使并排打開兩個窗口成為可能,使用通過代碼審查工具時,也能很好的通過相鄰列展現不同代碼版本。
一些工具的默認換行設置打亂了代碼的可視結構,使其更難理解。限制編輯器窗口寬為 80 來避免自動換行,即使有些編輯工具在換行的時候會在最后一列放一個標識符。一些基于 Web 的工具可能根本就不提供動態換行。
一些團隊更傾向于長的代碼行。對于達成了一致意見來統一代碼的團隊而言,把行提升到 80~100 的長度是可接受的(實際最大長度為 99 個字符),注釋和文檔字符串的長度還是建議在 72 個字符內。
Python 標準庫是非常專業的,限制最大代碼長度為 79 個字符(注釋和文檔字符串最大長度為 72 個字符)。
首選的換行方式是在括號(小中大)內隱式換行(非續行符?\)。長行應該在括號表達式的包裹下換行。這比反斜杠作為續行符更好。
反斜杠有時仍然適用。例如,多個很長的?with?語句不能使用隱式續行,因此反斜杠是可接受的。
with open('/path/to/some/file/you/want/to/read') as file_1, \open('/path/to/some/file/being/written', 'w') as file_2:file_2.write(file_1.read())
(見前面關于?多行 if 語句?的討論來進一步思考這種多行?with?語句該如何縮進。)
另一種使用反斜杠續行的案例是?assert?語句。
確保續行的縮進是恰到好處的。遇到二元操作符,首選的斷行位置是操作符的后面而不是前面。這有一些例子:
class Rectangle(Blob):def __init__(self, width, height,color='black', emphasis=None, highlight=0):if (width == 0 and height == 0 andcolor == 'red' and emphasis == 'strong' orhighlight > 100):raise ValueError("sorry, you lose")if width == 0 and height == 0 and (color == 'red' oremphasis is None):raise ValueError("I don't think so -- values are?%s,?%s" %(width, height))Blob.__init__(self, width, height,color, emphasis, highlight)
空行
頂級函數和類定義上下使用兩個空行分隔。
類內的方法定義使用一個空行分隔。
可以使用額外的空行(有節制的)來分隔相關聯的函數組。在一系列相關聯的單行代碼中空行可以省略(e.g. 一組虛擬的實現)。
在函數中使用空白行(有節制的)來表明邏輯部分。
Python 接受使用換頁符(i.e.?Ctrl+L)作為空格;許多工具都把?Ctrl+L?作為分頁符,因此你可以用它們把你的文件中相似的章節分頁。注意,一些編輯器和基于 Web 的代碼查看工具可能不把?Ctrl+L?看做分頁符,而是在這個位置放一個其它的符號。
源文件編碼
在核心 Python 發布版中的代碼應該總是使用UTF-8編碼(或者在 Python 2 中使用?ASCII)。
使用?ASCII(Python 2)或?UTF-8(Python 3)的文件不需要有編碼聲明(注:它們是默認的)。
在標準庫中,非缺省的編碼應該僅僅用于測試目的,或者注釋或文檔字符串中的作者名包含非?ASCII?碼字符;否則,優先使用?\x、\u、\U?或者?\N?來轉義字符串中的非?ASCII?數據。
對于 Python 3.0 和之后的版本,以下是有關標準庫的政策(見PEP 3131):所有 Python 標準庫中的標識符必須使用只含?ASCII?的標識,并且只要可行,應該使用英語單詞(在多數情況下,縮略語和技術術語哪個不是英語)。此外,字符串和注釋也必須是?ASCII。僅有的例外是:(a)測試用例測試非?ASCII?特性時,(b)作者名。作者的名字不是基于拉丁字母的必須提供他們名字的拉丁字母音譯。
面向全球用戶的開源項目,鼓勵采取相似的政策。
導入包
-
import?不同的模塊應該獨立一行,如:好的:
import os
import sys
不好的:
import sys, os
這樣也是可行的:
from subprocess import Popen, PIPE
-
import?語句應該總是放在文件的頂部,在模塊注釋和文檔字符串之下,在模塊全局變量和常量之前。import?語句分組順序如下:- 導入標準庫模塊
- 導入相關第三方庫模塊
- 導入當前應用程序 / 庫模塊
每組之間應該用空行分開。
然后用?
__all__?聲明本文件內的模塊。 -
絕對導入是推薦的,它們通常是更可讀的,并且在錯誤的包系統配置(如一個目錄包含一個以?
os.path?結尾的包)下有良好的行為傾向(至少有更清晰的錯誤消息):
import mypkg.sibling
from mypkg import sibling
from mypkg.sibling import example
當然,相對于絕對導入,相對導入是個可選替代,特別是處理復雜的包結構時,絕對導入會有不必要的冗余:
from . import sibling
from .sibling import example
標準庫代碼應該避免復雜的包結構,并且永遠使用絕對導入。
應該從不使用隱式的相對導入,而且在 Python 3 中已經被移除。
- 從一個包含類的模塊導入類時,這樣寫通常是可行的:
from myclass import MyClass
from foo.bar.yourclass import YourClass
如果上面的方式會本地導致命名沖突,則這樣寫:
import myclass
import foo.bar.yourclass
以?myclass.MyClass和foo.bar.yourclass.YourClass?這樣的方式使用。
-
應該避免通配符導入(
from import *),這會使名稱空間里存在的名稱變得不清晰,迷惑讀者和自動化工具。這里有一個可辯護的通配符導入用例,,重新發布一個內部接口作為公共 API 的一部分(例如,使用純 Python 實現一個可選的加速器模塊的接口,但并不能預知這些定義會被覆蓋)。當以這種方式重新發布名稱時,下面關于公共和內部接口的指南仍然適用。
字符串引號
在 Python 里面,單引號字符串和雙引號字符串是相同的。這份指南對這個不會有所建議。選擇一種方式并堅持使用。一個字符串同時包含單引號和雙引號字符時,用另外一種來包裹字符串,而不是使用反斜杠來轉義,以提高可讀性。
對于三引號字符串,總是使用雙引號字符來保持與文檔字符串約定的一致性(PEP 257)。
表達式和語句中的空格
不能忍受的情況
避免在下列情況中使用多余的空格:
- 與括號保持緊湊(小括號、中括號、大括號):
# Yes
spam(ham[1], {eggs: 2})
# No
spam( ham[ 1 ], { eggs: 2 } )
- 與后面的逗號、分號或冒號保持緊湊:
# Yes
if x == 4: print x, y; x, y = y, x
# No
if x == 4 : print x , y ; x , y = y , x
- 切片內的冒號就像二元操作符一樣,任意一側應該被等同對待(把它當做一個極低優先級的操作)。在一個可擴展的切片中,冒號兩側必須有相同的空格數量。例外:切片參數省略時,空格也省略。
好的:
ham[1:9], ham[1:9:3], ham[:9:3], ham[1::3], ham[1:9:]
ham[lower:upper], ham[lower:upper:], ham[lower::step]
ham[lower+offset : upper+offset]
ham[: upper_fn(x) : step_fn(x)], ham[:: step_fn(x)]
ham[lower + offset : upper + offset]
不好的:
ham[lower + offset:upper + offset]
ham[1: 9], ham[1 :9], ham[1:9 :3]
ham[lower : : upper]
ham[ : upper]
- 函數名與其后參數列表的左括號應該保持緊湊:
# Yes
spam(1)
#No
spam (1)
- 與切片或索引的左括號保持緊湊:
# Yes
dct['key'] = lst[index]
# No
dct ['key'] = lst [index]
-
在賦值操作符(或其它)的兩側保持多余一個的空格:
好的:
x = 1
y = 2
long_variable = 3
不好的:
x = 1
y = 2
long_variable = 3
其他建議
-
總是在這些二元操作符的兩側加入一個空格:賦值(
=),增量賦值(+=,-=,...),比較(==,<,>,!=,<>,<=,>=,in,not in,is,is not),布爾運算(and,or,not)。 -
在不同優先級之間,考慮在更低優先級的操作符兩側插入空格。用你自己的判斷力;但不要使用超過一個空格,并且在二元操作符的兩側有相同的空格數。
好的:
i = i + 1
submitted += 1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)
不好的:
i=i+1
submitted +=1
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)
-
不要在關鍵值參數或默認值參數的等號兩邊加入空格。
好的:
def complex(real, imag=0.0):return magic(r=real, i=imag)
不好的:
def complex(real, imag = 0.0):return magic(r = real, i = imag)
-
Python 3 帶注釋的函數定義中的等號兩側要各插入空格。此外,在冒號后用一個單獨的空格,也要在表明函數返回值類型的?
->?左右各插入一個空格。
好的:
def munge(input: AnyStr):
def munge(sep: AnyStr = None):
def munge() -> AnyStr:
def munge(input: AnyStr, sep: AnyStr = None, limit=1000):
不好的:
def munge(input: AnyStr=None):
def munge(input:AnyStr):
def munge(input: AnyStr)->PosInt:
- 打消使用復合語句(多條語句在同一行)的念頭。
好的:
if foo == 'blah':do_blah_thing()
do_one()
do_two()
do_three()
寧可不:
if foo == 'blah': do_blah_thing()
do_one(); do_two(); do_three()
- 有時候把?
if/for/while? 和一個小的主體放在同一行也是可行的,千萬不要在有多條語句的情況下這樣做。此外,還要避免折疊,例如長行。
寧可不:
if foo == 'blah': do_blah_thing()
for x in lst: total += x
while t < 10: t = delay()
絕對不:
if foo == 'blah': do_blah_thing()
else: do_non_blah_thing()try: something()
finally: cleanup()do_one(); do_two(); do_three(long, argument,list, like, this)if foo == 'blah': one(); two(); three()注釋
與代碼相矛盾的注釋不如沒有。注釋總是隨著代碼的變更而更新。
注釋應該是完整的句子。如果注釋是一個短語或語句,第一個單詞應該大寫,除非是一個開頭是小寫的標識符(從不改變標識符的大小寫)。
如果注釋很短,末尾的句點可以省略。塊注釋通常由一個或多個有完整句子的段落組成,并且每個句子應該由句點結束。
你應該在一個句子的句點后面用兩個空格。
寫英語時,遵循《Strunk and White》(注:《英文寫作指南》,參考維基百科)。
來自非英語國家的程序員:請用英語寫注釋,除非你 120% 確定你的代碼永遠不會被那些不說你的語言的人閱讀。
塊注釋
塊注釋通常用來說明跟隨在其后的代碼,應該與那些代碼有相同的縮進層次。塊注釋每一行以#起頭,并且#后要跟一個空格(除非是注釋內的縮進文本)。
行內注釋
有節制的使用行內注釋。
一個行內注釋與語句在同一行。行內注釋應該至少與語句相隔兩個空格。以#打頭,#后接一個空格。
無謂的行內注釋如果狀態明顯,會轉移注意力。不要這樣做:
x = x + 1 # Increment x
但有的時候,這樣是有用的:
x = x + 1 # Compensate for border
文檔字符串
編寫良好的文檔字符串(a.k.a “docstring”)的約定常駐在 ?PEP 257
- 為所有的公共模塊、函數、類和方法編寫文檔字符串。對于非公共的方法,文檔字符串是不必要的,但是也應該有注釋來說明代碼是干什么的。這個注釋應該放在方法聲明的下面。
- PEP 257? 描述了良好的文檔字符串的約定。注意,文檔字符串的結尾?
"""?應該放在單獨的一行,例如:
"""Return a foobangOptional plotz says to frobnicate the bizbaz first.
"""
- 對于單行的文檔字符串,把結尾?
"""?放在同一行。
版本注記
如果必須要 Subversion,CVS 或 RCS 標記在你的源文件里,像這樣做:
__version__ = "$Revision$"
# $Source$
這幾行應該在模塊的文檔字符串后面,其它代碼的前面,上下由一個空行分隔。
命名約定
Python 庫的命名規則有點混亂,因此我們永遠也不會使其完全一致的 – 不過,這里有一些當前推薦的命名標準。新的模塊和包(包括第三方框架)應該按照這些標準來命名,但是已存在庫有不同的風格,內部一致性是首選。
覆蓋原則
API 里對用戶可見的公共部分應該遵循約定,反映的是使用而不是實現。
規定:命名約定
有許多不同的命名風格。這有助于識別正在使用的命名風格,獨立于它們的用途。
下面的命名風格通常是有區別的:
- b (一個小寫字母)
- B (一個大寫字母)
- lowercase
- lower_case_with_underscores
- UPPERCASE
- UPPER_CASE_WITH_UNDERSCORES
- CapitalizedWords (又叫 CapWords,或者 CamelCase(駱駝命名法) – 如此命名因為字母看起來崎嶇不平[3]。有時候也叫 StudlyCaps。
注意:在 CapWords 使用縮略語時,所有縮略語的首字母都要大寫。因此HTTPServerError比HttpServerError要好。
- mixedCase (和上面不同的是首字母小寫)
- Capitalized_Words_With_Underscores (丑陋無比!)
也有種風格用獨一無二的短前綴來將相似的命名分組。在 Python 里用的不是很多,但是為了完整性被提及。例如,os.stat()函數返回一個元組,通常有像st_mode,st_size,st_mtime等名字。(強調與 POSIX 系統調用的字段結構一致,有助于程序員對此更熟悉)
X11 庫的所有公共函數都用 X 打頭。在 Python 中這種風格被認為是不重要的,因為屬性和方法名的前綴是一個對象,函數名的前綴為一個模塊名。
此外,下面的特許形式用一個前導或尾隨的下劃線進行識別(這些通常可以和任何形式的命名約定組合):
- _single_leading_underscore :僅內部使用的標識,如
from M import *不會導入像這樣一下劃線開頭的對象。 - singletrailing_underscore?: 通常是為了避免與 Python 規定的關鍵字沖突,如
Tkinter.Toplevel(master, class_='ClassName')。 - **double_leading_underscore : 命名一個類屬性,調用的時候名字會改變(在類
FooBar中,**boo變成了\_FooBar\_\_boo;見下)。 - double_leading_and_trailing_underscore?:”魔術”對象或屬性,活在用戶控制的命名空間里。例如,
__init__,__import__和__file__。永遠不要像這種方式命名;只把它們作為記錄。
規定:命名約定
- 應該避免的名字
永遠不要使用單個字符l(小寫字母 el),O(大寫字母 oh),或I(大寫字母 eye)作為變量名。
在一些字體中,這些字符是無法和數字1和0區分開的。試圖使用l時用L代替。
- 包和模塊名
模塊名應該短,且全小寫。如果能改善可讀性,可以使用下劃線。Python 的包名也應該短,全部小寫,但是不推薦使用下劃線。
因為模塊名就是文件名,而一些文件系統是大小寫不敏感的,并且自動截斷長文件名,所以給模塊名取一個短小的名字是非常重要的 – 在 Unix 上這不是問題,但是把代碼放到老版本的 Mac, Windows,或者 DOS 上就可能變成一個問題了。
用 C/C++ 給 Python 寫一個高性能的擴展(e.g. more object oriented)接口的時候,C/C++ 模塊名應該有一個前導下劃線。
- 類名
類名通常使用 CapWords 約定。
The naming convention for functions may be used instead in cases where the interface is documented and used primarily as a callable.
注意和內建名稱的區分開:大多數內建名稱是一個單獨的單詞(或兩個單詞一起),CapWords 約定只被用在異常名和內建常量上。
- 異常名
因為異常應該是類,所以類名約定在這里適用。但是,你應該用Error作為你的異常名的后綴(異常實際上是一個錯誤)。
- 全局變量名
(我們希望這些變量僅僅在一個模塊內部使用)這個約定有關諸如此類的變量。
若被設計的模塊可以通過from M import *來使用,它應該使用__all__機制來表明那些可以可導出的全局變量,或者使用下劃線前綴的全局變量表明其是模塊私有的。
- 函數名
函數名應該是小寫的,有必要的話用下劃線來分隔單詞提高可讀性。
混合大小寫僅僅在上下文都是這種風格的情況下允許存在(如 thread.py),這是為了維持向后兼容性。
- 函數和方法參數
總是使用?self?作為實例方法的第一個參數。
總是使用?cls?作為類方法的第一個參數。
如果函數參數與保留關鍵字沖突,通常最好在參數后面添加一個尾隨的下劃線,而不是使用縮寫或胡亂拆減。因此?class_?比?clss?要好。(或許避免沖突更好的方式是使用近義詞)
- 方法名和實例變量
用函數名的命名規則:全部小寫,用下劃線分隔單詞提高可讀性。
用一個且有一個前導的下劃線來表明非公有的方法和實例變量。
為了避免與子類變量或方法的命名沖突,用兩個前導下劃線來調用 Python 的命名改編規則。
Python 命名改編通過添加一個類名:如果類?Foo?有一個屬性叫?__a,它不能被這樣?Foo.__a?訪問(執著的人可以通過這樣?Foo._Foo__a?來訪問)通常,雙前導的下劃線應該僅僅用來避免與其子類屬性的命名沖突。
注意:這里有一些爭議有關?__names?的使用(見下文)。
- 常量
常量通常是模塊級的定義,全部大寫,單詞之間以下劃線分隔。例如MAX_OVERFLOW和TOTAL。
- 繼承的設計
總是決定一個類的方法和變量(屬性)是應該公有還是非公有。如果有疑問,選擇非公有;相比把共有屬性變非公有,非公有屬性變公有會容易得多。
公有屬性是你期望給那些與你的類無關的客戶端使用的,你應該保證不會出現不向后兼容的改變。非公有的屬性是你不打算給其它第三方使用的;你不需要保證非公有的屬性不會改變甚至被移除也是可以的。
我們這里不適用“私有”這個術語,因為在 Python 里沒有真正的私有屬性(一般沒有不必要的工作量)。
另一種屬性的分類是“子類 API”的一部分(通常在其它語言里叫做“Protected”)。一些類被設計成被繼承的,要么擴展要么修改類的某方面行為。設計這樣一個類的時候,務必做出明確的決定,哪些是公有的,其將會成為子類 API 的一部分,哪些僅僅是用于你的基類的。
處于這種考慮,給出 Pythonic 的指南:
- 共有屬性不應該有前導下劃線。
- 如果你的公有屬性與保留關鍵字發生沖突,在你的屬性名后面添加一個尾隨的下劃線。這比使用縮寫或胡亂拆減要好。(盡管這條規則,已知某個變量或參數可能是一個類情況下,
cls是首選的命名,特別是作為類方法的第一個參數)
注意一:見上面推薦的類方法參數命名方式。
- 對于簡單的公有數據屬性,最好的方式是暴露屬性名,不要使用復雜的訪問屬性/修改屬性的方法。記住,Python 提供了捷徑去提升特性,如果你發現簡單的數據屬性需要增加功能行為。在這種情況下,使用
properties把功能實現隱藏在簡單的數據屬性訪問語法下面。
注意一:properties僅僅在新式類下工作。 ?? 注意二:盡量保持功能行為無邊際效應,然而如緩存有邊際效應也是好的。 ?? 注意三:避免為計算開銷大的操作使用properties;屬性標記使調用者相信這樣來訪問(相對來說)是開銷很低的。
- 如果你的類是為了被繼承,你有不想讓子類使用的屬性,給屬性命名時考慮給它們加上雙前導下劃線,不要加尾隨下劃線。這會調用 Python 的名稱重整算法,把類名加在屬性名前面。避免了命名沖突,當子類不小心命名了和父類屬性相同名稱的時候。
注意一:注意只是用了簡單的類名來重整名字,因此如果子類和父類同名的時候,你仍然有能力避免沖突。
注意二:命名重整有確定的用途,例如調試和__getattr__(),就不太方便。命名重整算法是有據可查的,易于手動執行。
注意三:不是每個人都喜歡命名重整。盡量平衡名稱的命名沖突與面向高級調用者的潛在用途
公共和內部接口
保證所有公有接口的向后兼容性。用戶能清晰的區分公有和內部接口是重要的。
文檔化的接口考慮公有,除非文檔明確的說明它們是暫時的,或者內部接口不保證其的向后兼容性。所有的非文檔化的應該被假設為非公開的。
為了更好的支持內省,模塊應該用?__all__?屬性來明確規定公有 API 的名字。設置?__all__?為空?list?表明模塊沒有公有 API。
甚至與?__all__?設置相當,內部接口(包、模塊、類、函數、屬性或者其它的名字)應該有一個前導的下劃線前綴。
被認為是內部的接口,其包含的任何名稱空間(包、模塊或類)也被認為是內部的。
導入的名稱應始終視作一個實現細節。其它模塊不能依賴間接訪問這些導入的名字,除非它們是包含模塊的 API 明確記載的一部分,例如?os.path?或一個包的?__init__?模塊暴露了來自子模塊的功能。
程序編寫建議
-
代碼的編寫方式不能對其它 Python 的實現(PyPy、Jython、IronPython、Cython、Psyco,諸如此類的)不利。
例如,不要依賴于 CPython 在字符串拼接時的優化實現,像這種語句形式
a += b和a = a + b。即使是 CPython(僅對某些類型起作用) 這種優化也是脆弱的,不是在所有的實現中都不使用引用計數。在庫中性能敏感的部分,用''.join形式來代替。這會確保在所有不同的實現中字符串拼接是線性時間的。 -
比較單例,像
None應該用is或is not,從不使用==操作符。當你的真正用意是
if x is not None的時候,當心if x這樣的寫法 – 例如,測試一個默認值為None的變量或參數是否設置成了其它值,其它值可能是那些布爾值為 false 的類型(如空容器)。 -
用?
is not?操作符而不是?not ... is。雖然這兩個表達式是功能相同的,前一個是更可讀的,是首選。好的:
if foo is not None:
不好的:
if not foo is None:
-
用富比較實現排序操作的時候,實現所有六個比較操作符(?
__eq__,__ne__,__lt__,__le__,__gt__,__ge__)是更好的,而不是依賴其它僅僅運用一個特定比較的代碼為了最大限度的減少工作量,
functools.total_ordering()?裝飾器提供了一個工具去生成缺少的比較方法。PEP 207? 說明了 Python 假定的所有反射規則。因此,解釋器可能交換?
y > x?與?x < y,y >= x?與?x <= y,也可能交換?x == y?和?x != y。sort()?和?min()?操作肯定會使用?<?操作符,max()?函數肯定會使用?>?操作符。當然,最好是六個操作符都實現,以便不會在其它上下文中有疑惑。 -
始終使用?
def?語句來代替直接綁定了一個lambda表達式的賦值語句。好的:
def f(x): return 2*x
不好的:
f = lambda x: 2*x
第一種形式意味著函數對象的?__name__?屬性值是?'f'?而不是?'<lambda>'?。通常這對異常追蹤和字符串表述是更有用的。使用賦值語句消除的唯一好處,lambda?表達式可以提供一個顯示的def語句不能提供的,如,lambda?能鑲嵌在一個很長的表達式里。
-
異常類應派生自?
Exception?而不是?BaseException。直接繼承自?BaseException?是為?Exception?保留的,如果從?BaseException?繼承,捕獲到的錯誤總是錯的。設計異常結構層次,應基于那些可能出現異常的代碼,而不是在出現異常后的。編碼的時候,以回答“出了什么問題?”為目標,而不是僅僅指出“這里出現了問題”(見 ?PEP 3151? 一個內建異常結構層次的例子)。
類的命名約定適用于異常,如果異常類是一個錯誤,你應該給異常類加一個后綴?
Error。用于非本地流程控制或者其他形式的信號的非錯誤異常不需要一個特殊的后綴。 -
適當的使用異常鏈。在 Python 3 里,
raise X from Y?用于表明明確的替代者,不丟失原有的回溯信息。有意替換一個內部的異常時(在 Python 2 用?
raise X,Python 3.3+ 用?raise X from None),確保相關的細節全部轉移給了新異常(例如,把?KeyError?變成?AttributeError?時保留屬性名,或者把原始異常的錯誤信息嵌在新異常里)。 -
在 Python 2 里拋出異常時,用?
raise ValueError('message')?代替舊式的?raise ValueError, 'message'。在 Python 3 之后的語法里,舊式的異常拋出方式是非法的。
使用括號形式的異常意味著,當你傳給異常的參數過長或者包含字符串格式化時,你就不需要使用續行符了,這要感謝括號!
-
捕獲異常時,盡可能使用明確的異常,而不是用一個空的
except:語句。例如,用:
try:import platform_specific_module
except ImportError:platform_specific_module = None
一個空的except:語句將會捕獲到SystemExit和KeyboardInterrupt異常,很難區分程序的中斷到底是Ctrl+C還是其他問題引起的。如果你想捕獲程序的所有錯誤,使用except Exception:(空except:等同于except BaseException)。
一個好的經驗是限制使用空except語句,除了這兩種情況:
- 如果異常處理程序會打印出或者記錄回溯信息;至少用戶意識到錯誤的存在。
- 如果代碼需要做一些清理工作,但后面用
raise向上拋出異常。try .. finally是處理這種情況更好的方式。
- 綁定異常給一個名字時,最好使用 Python 2.6 里添加的明確的名字綁定語法:
try:process_data()
except Exception as exc:raise DataProcessingFailedError(str(exc))
Python 3 只支持這種語法,避免與基于逗號的舊式語法產生二義性。
-
捕獲操作系統錯誤時,最好使用 Python 3.3 里引進的明確的異常結構層次,而不是自省的
errno值。 -
此外,對于所有的
try/except語句來說,限制try里面有且僅有絕對必要的代碼。在強調一次,這能避免屏蔽錯誤。
好的:
try:value = collection[key]
except KeyError:return key_not_found(key)
else:return handle_value(value)
不好的:
try:# Too broad!return handle_value(collection[key])
except KeyError:# Will also catch KeyError raised by handle_value()return key_not_found(key)
-
當資源是本地的特定代碼段,用
with語句確保其在使用后被立即干凈的清除了,try/finally也是也接受的。 -
當它們做一些除了獲取和釋放資源之外的事的時候,上下文管理器應該通過單獨的函數或方法調用。例如:
好的:
with conn.begin_transaction():do_stuff_in_transaction(conn)
不好的:
with conn:do_stuff_in_transaction(conn)
第二個例子沒有提供任何信息來表明__enter__和__exit__方法在完成一個事務后做了一些除了關閉連接以外的其它事。在這種情況下明確是很重要的。
-
堅持使用
return語句。函數內的return語句都應該返回一個表達式,或者None。如果一個return語句返回一個表達式,另一個沒有返回值的應該用return None清晰的說明,并且在一個函數的結尾應該明確使用一個return語句(如果有返回值的話)。好的:
def foo(x):if x >= 0:return math.sqrt(x)else:return Nonedef bar(x):if x < 0:return Nonereturn math.sqrt(x)
不好的:
def foo(x):if x >= 0:return math.sqrt(x)def bar(x):if x < 0:returnreturn math.sqrt(x)
-
用字符串方法代替字符串模塊。
字符串方法總是更快,與 unicode 字符串共享 API。如果需要向后兼容性覆蓋這個規則,需要 Python 2.0 以上的版本。
-
用
''.startswith()和''.endswith()代替字符串切片來檢查前綴和后綴。startswith()和endswith()是更簡潔的,不容易出錯的。例如:
Yes: if foo.startswith('bar'):
No: if foo[:3] == 'bar':
- 對象類型的比較應該始終使用
isinstance()而不是直接比較。
Yes: if isinstance(obj, int):No: if type(obj) is type(1):
當比較一個對象是不是字符串時,記住它有可能也是一個 unicode 字符串!在 Python 2 里面,str和unicode有一個公共的基類叫basestring,因此你可以這樣做:
if isinstance(obj, basestring):
注意,在 Python 3 里面,unicode和basestring已經不存在了(只有str),byte對象不再是字符串的一種(被一個整數序列替代)。
-
對于序列(字符串、列表、元組)來說,空的序列為
False:
好的:
if not seq:
if seq:
不好的:
if len(seq):
if not len(seq):
- 不要讓字符串對尾隨的空格有依賴。這樣的尾隨空格是視覺上無法區分的,一些編輯器(or more recently, reindent.py)會將其裁剪掉。
- 不要用
==比較True和False。
Yes: if greeting:
No: if greeting == True:
Worse: if greeting is True:
-
Python 標準庫將不再使用函數標注,以至于給特殊的標注風格給一個過早的承若。代替的,這些標注是留給用戶去發現和體驗的有用的標注風格。
建議第三方實驗的標注用相關的修飾符指示標注應該如何被解釋。
早期的核心開發者嘗試用函數標注顯示不一致、特別的標注風格。例如:
[str]是很含糊的,它可能代表一個包含字符串的列表,也可能代表一個為字符串或為空的值。open(file:(str,bytes))可能用來表示file的值可以是一個str或者bytes,也可能用來表示file的值是一個包含str和bytes的二元組。- 標注
seek(whence:int)體現了一個過于明確又不夠明確的混合體:int太嚴格了(有__index__的應該被允許),又不夠嚴格(只有 0,1,2 是被允許的)。同樣的,標注write(b: byte)太嚴格了(任何支持緩存協議的都應該被允許)。 - 像
read1(n: int=None)這樣的標注自我矛盾,因為None不是int。像source_path(self, fullname:str) -> object標注是迷惑人的,返回值到底是應該什么類型? - 除了上面之外,在具體類型和抽象類型的使用上是不一致的:
int對integral(整數),set/fronzenset對MutableSet/Set。 - 不正確的抽象基類標注規格。例如,集合之間的操作需要另一個對象是集合的實例,而不只是一個可迭代序列。
- 另一個問題是,標注成為了規范的一部分,但卻沒有經受過考驗。
- 在大多數情況下,文檔字符串已經包括了類型規范,比函數標注更清晰。在其余的情況下,一旦標注被移除,文檔字符串應該被完善。
- 觀察到的函數標注太標新立異了,相關的系統不能一致的處理自動類型檢查和參數驗證。離開這些標注的代碼以后很難做出更改,使自動化工具可以支持。
總結
即使內容有點多,但每一個 Python 開發者都應該盡量遵守 PEP8 規范。
參考文獻
[1]:PEP 7, Style Guide for C Code, van Rossum
[2]:Barry's GNU Mailman style guide?http://barry.warsaw.us/software/STYLEGUIDE.txt
[3]:http://www.wikipedia.com/wiki/CamelCase
版權說明
This document has been placed in the public domain.
Source:?peps: 65c5d45eab5f pep-0008.txt
迭代器、生成器、裝飾器
在這個實驗里我們學習迭代器、生成器、裝飾器有關知識。
這幾個概念是 Python 中不容易理解透徹的概念,務必把所有的實驗代碼都完整的輸入并理解清楚其中每一行的意思。
知識點
- 迭代器
- 生成器
- 生成器表達式
- 閉包
- 裝飾器
迭代器
Python 迭代器(_Iterators_)對象在遵守迭代器協議時需要支持如下兩種方法。
__iter__(),返回迭代器對象自身。這用在?for?和?in?語句中。__next__(),返回迭代器的下一個值。如果沒有下一個值可以返回,那么應該拋出?StopIteration?異常。
class Counter(object):def __init__(self, low, high):self.current = lowself.high = highdef __iter__(self):return selfdef __next__(self):#返回下一個值直到當前值大于 highif self.current > self.high:raise StopIterationelse:self.current += 1return self.current - 1
現在我們能把這個迭代器用在我們的代碼里。
>>> c = Counter(5,10)
>>> for i in c:
... print(i, end=' ')
...
5 6 7 8 9 10
請記住迭代器只能被使用一次。這意味著迭代器一旦拋出?StopIteration,它會持續拋出相同的異常。
>>> c = Counter(5,6)
>>> next(c)
5
>>> next(c)
6
>>> next(c)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 11, in next
StopIteration
>>> next(c)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 11, in next
StopIteration
我們已經看過在?for?循環中使用迭代器的例子了,下面的例子試圖展示迭代器被隱藏的細節:
>>> iterator = iter(c)
>>> while True:
... try:
... x = iterator.__next__()
... print(x, end=' ')
... except StopIteration as e:
... break
...
5 6 7 8 9 10生成器
在這一節我們學習有關 Python 生成器(_Generators_)的知識。生成器是更簡單的創建迭代器的方法,這通過在函數中使用?yield?關鍵字完成:
>>> def my_generator():
... print("Inside my generator")
... yield 'a'
... yield 'b'
... yield 'c'
...
>>> my_generator()
<generator object my_generator at 0x7fbcfa0a6aa0>
在上面的例子中我們使用?yield?語句創建了一個簡單的生成器。我們能在?for?循環中使用它,就像我們使用任何其它迭代器一樣。
>>> for char in my_generator():
... print(char)
...
Inside my generator
a
b
c
在下一個例子里,我們會使用一個生成器函數完成與 Counter 類相同的功能,并且把它用在 for 循環中。
>>> def counter_generator(low, high):
... while low <= high:
... yield low
... low += 1
...
>>> for i in counter_generator(5,10):
... print(i, end=' ')
...
5 6 7 8 9 10
在 While 循環中,每當執行到?yield?語句時,返回變量?low?的值并且生成器狀態轉為掛起。在下一次調用生成器時,生成器從之前凍結的地方恢復執行然后變量?low?的值增一。生成器繼續?while?循環并且再次來到?yield?語句...
當你調用生成器函數時它返回一個生成器對象。如果你把這個對象傳入?dir()?函數,你會在返回的結果中找到?__iter__?和?__next__?兩個方法名。

我們通常使用生成器進行惰性求值。這樣使用生成器是處理大數據的好方法。如果你不想在內存中加載所有數據,你可以使用生成器,一次只傳遞給你一部分數據。
os.path.walk()?函數是最典型的這樣的例子,它使用一個回調函數和當前的?os.walk?生成器。使用生成器實現節約內存。
我們可以使用生成器產生無限多的值。以下是一個這樣的例子。
>>> def infinite_generator(start=0):
... while True:
... yield start
... start += 1
...
>>> for num in infinite_generator(4):
... print(num, end=' ')
... if num > 20:
... break
...
4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
如果我們回到?my_generator()?這個例子,我們會發現生成器的一個特點:它們是不可重復使用的。
>>> g = my_generator()
>>> for c in g:
... print(c)
...
Inside my generator
a
b
c
>>> for c in g:
... print(c)
...
我們無法創建一個可重復使用的生成器,但可以創建一個對象,將它的?__iter__?方法調用得到一個生成器,舉例如下:
>>> class Counter(object):
... def __init__(self, low, high):
... self.low = low
... self.high = high
... def __iter__(self):
... counter = self.low
... while self.high >= counter:
... yield counter
... counter += 1
...
>>> gobj = Counter(5, 10)
>>> for num in gobj:
... print(num, end=' ')
...
5 6 7 8 9 10
>>> for num in gobj:
... print(num, end=' ')
...
5 6 7 8 9 10
上面的?gobj?并不是生成器或迭代器,因為它不具有?__next__?方法,只是一個可迭代對象,生成器是一定不能重復循環的。而?gobj.__iter__()?是一個生成器,因為它是一個帶有 yield 關鍵字的函數。
如果想要使類的實例變成迭代器,可以用?__iter__?+?__next__?方法實現:
>>> from collections import Iterator
>>> class Test():
...: def __init__(self, a, b):
...: self.a = a
...: self.b = b
...: def __iter__(self):
...: return self
...: def __next__(self):
...: self.a += 1
...: if self.a > self.b:
...: raise StopIteration()
...: return self.a
...:>>> test = Test(5, 10)>>> isinstance(test, Iterator)
True生成器表達式
在這一節我們學習生成器表達式(_Generator expressions_),生成器表達式是列表推導式和生成器的一個高性能,內存使用效率高的推廣。
舉個例子,我們嘗試對 1 到 9 的所有數字進行平方求和。
>>> sum([x*x for x in range(1,10)])
這個例子實際上首先在內存中創建了一個平方數值的列表,然后遍歷這個列表,最終求和后釋放內存。你能理解一個大列表的內存占用情況是怎樣的。
我們可以通過使用生成器表達式來節省內存使用。
>>> sum(x*x for x in range(1,10))
生成器表達式的語法要求其總是直接在在一對括號內,并且不能在兩邊有逗號。這基本上意味著下面這些例子都是有效的生成器表達式用法示例:
>>> sum(x*x for x in range(1,10))
285
>>> g = (x*x for x in range(1,10))
>>> g
<generator object <genexpr> at 0x7fc559516b90>
我們可以把生成器和生成器表達式聯系起來,在下面的例子中我們會讀取文件?'/var/log/cron'?并且查看任意指定任務(例中我們搜索?'anacron'?)是否成功運行。
我們可以用 shell 命令?tail -f /etc/crontab |grep anacron?完成同樣的事(按 Ctrl + C 終止命令執行)。
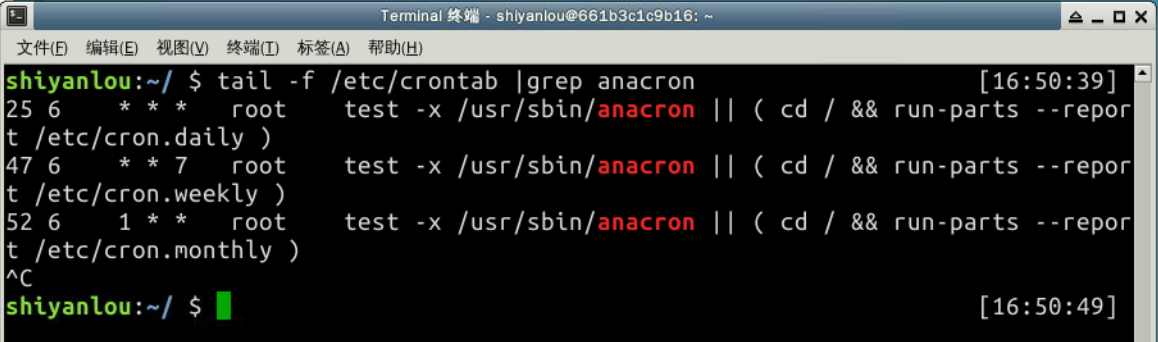
>>> jobtext = 'anacron'
>>> all = (line for line in open('/etc/crontab', 'r') )
>>> job = ( line for line in all if line.find(jobtext) != -1)
>>> text = next(job)
>>> text
'25 6\t* * *\troot\ttest -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )\n'
>>> text = next(job)
>>> text
'47 6\t* * 7\troot\ttest -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )\n'
>>> text = next(job)
>>> text
'52 6\t1 * *\troot\ttest -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )\n'
你可以寫一個?for?循環遍歷所有行。
閉包
閉包(_Closures_)是由另外一個函數返回的函數。我們使用閉包去除重復代碼。在下面的例子中我們創建了一個簡單的閉包來對數字求和。
>>> def add_number(num):
... def adder(number):
... #adder 是一個閉包
... return num + number
... return adder
...
>>> a_10 = add_number(10)
>>> a_10(21)
31
>>> a_10(34)
44
>>> a_5 = add_number(5)
>>> a_5(3)
8
adder?是一個閉包,把一個給定的數字與預定義的一個數字相加。
裝飾器
裝飾器(_Decorators_)用來給一些對象動態的添加一些新的行為,我們使用過的閉包也是這樣的。
我們會創建一個簡單的示例,將在函數執行前后打印一些語句。
>>> def my_decorator(func):
... def wrapper(*args, **kwargs):
... print("Before call")
... result = func(*args, **kwargs)
... print("After call")
... return result
... return wrapper
...
>>> @my_decorator
... def add(a, b):
... #我們的求和函數
... return a + b
...
>>> add(1, 3)
Before call
After call
4總結
知識點回顧:
- 迭代器
- 生成器
- 生成器表達式
- 閉包
- 裝飾器
本實驗我們學習了迭代器和生成器以及裝飾器這幾個高級特性的定義方法和用法,也了解了怎樣使用生成器表達式和怎樣定義閉包。
Virtualenv
一、實驗介紹
Virtualenv 是一個創建隔離 Python 環境的工具,可以幫助你在本地目錄安裝不同版本 Python 模塊的 Python 環境,你可以不再需要在你系統中安裝所有東西就能開發并測試你的代碼。
實驗知識點
- virtualenv 的安裝
- 創建虛擬環境
- 激活虛擬環境
- 使用多個虛擬環境
- 關閉虛擬環境
二、安裝 virtualenv
首先安裝 pip3,打開 xfce 終端輸入下面的命令:
sudo apt-get update
sudo apt-get install python3-pip
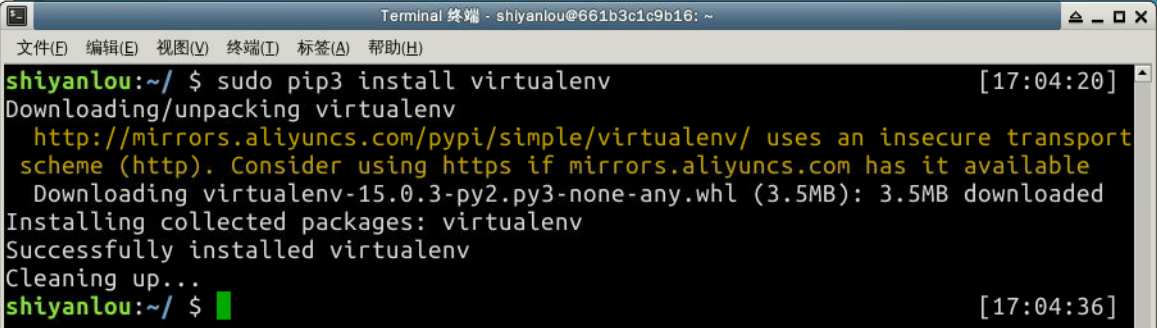
用如下命令安裝 virtualenv:
sudo pip3 install virtualenv
三、用法
我們會創建一個叫做?virtual?的目錄,在里面我們會創建兩個不同的虛擬環境。
cd /home/shiyanlou
mkdir virtual
下面的命令創建一個叫做 virt1 的環境。
cd virtual
virtualenv virt1

現在我們激活這個 virt1 環境。
source virt1/bin/activate

提示符的第一部分是當前虛擬環境的名字,當你有多個環境的時候它會幫助你識別你在哪個環境里面。
現在我們將安裝?redis?這個 Python 模塊。
pip install redis
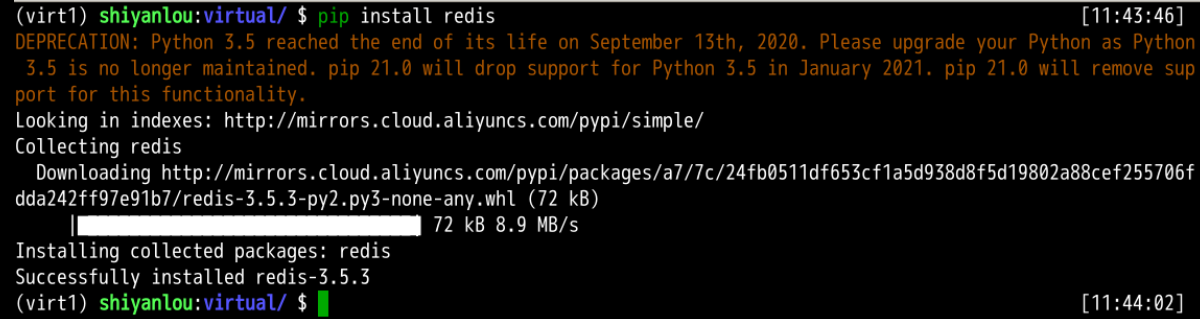
使用?deactivate?命令關閉虛擬環境。
deactivate

現在我們將創建另一個虛擬環境 virt2,我們會在里面同樣安裝?redis?模塊,但版本是 2.8 的舊版本。
virtualenv virt2
source virt2/bin/activate
pip install redis==2.8
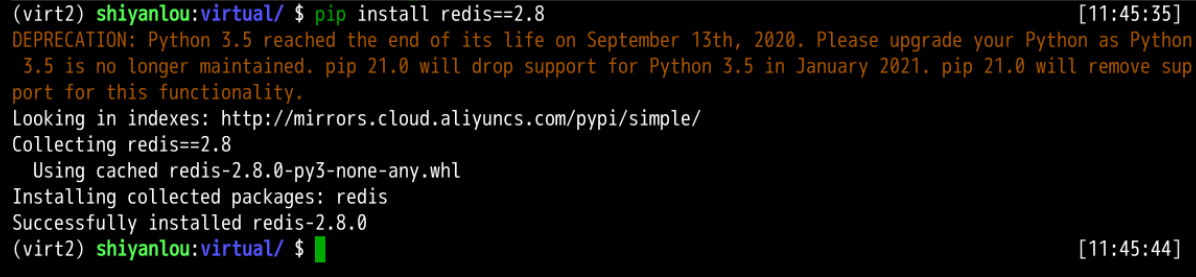
這樣可以為你的所有開發需求擁有許多不同的環境。
四、總結
本節知識點回顧:
- virtualenv 的安裝
- 創建虛擬環境
- 激活虛擬環境
- 使用多個虛擬環境
- 關閉虛擬環境
永遠記住當開發新應用時創建虛擬環境,這會幫助你的系統模塊保持干凈。
測試
一、實驗介紹
編寫測試檢驗應用程序所有不同的功能。每一個測試集中在一個關注點上驗證結果是不是期望的。定期執行測試確保應用程序按預期的工作。當測試覆蓋很大的時候,通過運行測試你就有自信確保修改點和新增點不會影響應用程序。
知識點
- 單元測試概念
- 使用 unittest 模塊
- 測試用例的編寫
- 異常測試
- 測試覆蓋率概念
- 使用 coverage 模塊
二、測試范圍
如果可能的話,代碼庫中的所有代碼都要測試。但這取決于開發者,如果寫一個健壯性測試是不切實際的,你可以跳過它。就像 _Nick Coghlan_(Python 核心開發成員) 在訪談里面說的:有一個堅實可靠的測試套件,你可以做出大的改動,并確信外部可見行為保持不變。
三、單元測試
這里引用維基百科的介紹:
在計算機編程中,單元測試(英語:Unit Testing)又稱為模塊測試, 是針對程序模塊(軟件設計的最小單位)來進行正確性檢驗的測試工作。程序單元是應用的最小可測試部件。在過程化編程中,一個單元就是單個程序、函數、過程等;對于面向對象編程,最小單元就是方法,包括基類(超類)、抽象類、或者派生類(子類)中的方法。
單元測試模塊
在 Python 里我們有 unittest 這個模塊來幫助我們進行單元測試。
階乘計算程序
在這個例子中我們將寫一個計算階乘的程序?/home/shiyanlou/factorial.py:
import sysdef fact(n):"""階乘函數:arg n: 數字:returns: n 的階乘"""if n == 0:return 1return n * fact(n -1)def div(n):"""只是做除法"""res = 10 / nreturn resdef main(n):res = fact(n)print(res)if __name__ == '__main__':if len(sys.argv) > 1:main(int(sys.argv[1]))
運行程序:
$ python3 factorial.py 53.1 第一個測試用例
測試哪個函數
正如你所看到的,?fact(n)?這個函數執行所有的計算,所以我們至少應該測試這個函數。
編輯?/home/shiyanlou/factorial_test.py?文件,代碼如下:
import unittest
from factorial import factclass TestFactorial(unittest.TestCase):"""我們的基本測試類"""def test_fact(self):"""實際測試任何以 `test_` 開頭的方法都被視作測試用例"""res = fact(5)self.assertEqual(res, 120)if __name__ == '__main__':unittest.main()
運行測試:
$ python3 factorial_test.py
.
----------------------------------------------------------------------
Ran 1 test in 0.000sOK
說明
我們首先導入了 unittest 模塊,然后測試我們需要測試的函數。
測試用例是通過子類化 ?unittest.TestCase? 創建的。
現在我們打開測試文件并且把 120 更改為 121,然后看看會發生什么?
3.2 各類 assert 語句
| Method | Checks that | New in |
|---|---|---|
| assertEqual(a, b) | a == b | |
| assertNotEqual(a, b) | a != b | |
| assertTrue(x) | bool(x) is True | |
| assertFalse(x) | bool(x) is False | |
| assertIs(a, b) | a is b | 2.7 |
| assertIsNot(a, b) | a is not b | 2.7 |
| assertIsNone(x) | x is None | 2.7 |
| assertIsNotNone(x) | x is not None | 2.7 |
| assertIn(a, b) | a in b | 2.7 |
| assertNotIn(a, b) | a not in b | 2.7 |
| assertIsInstance(a, b) | isinstance(a, b) | 2.7 |
| assertNotIsInstance(a, b) | not isinstance(a, b) | 2.7 |
3.3 異常測試
如果我們在?factorial.py?中調用?div(0),我們能看到異常被拋出。
我們也能測試這些異常,就像這樣:
self.assertRaises(ZeroDivisionError, div, 0)
完整代碼:
import unittest
from factorial import fact, divclass TestFactorial(unittest.TestCase):"""我們的基本測試類"""def test_fact(self):"""實際測試任何以 `test_` 開頭的方法都被視作測試用例"""res = fact(5)self.assertEqual(res, 120)def test_error(self):"""測試由運行時錯誤引發的異常"""self.assertRaises(ZeroDivisionError, div, 0)if __name__ == '__main__':unittest.main()3.4 mounttab.py
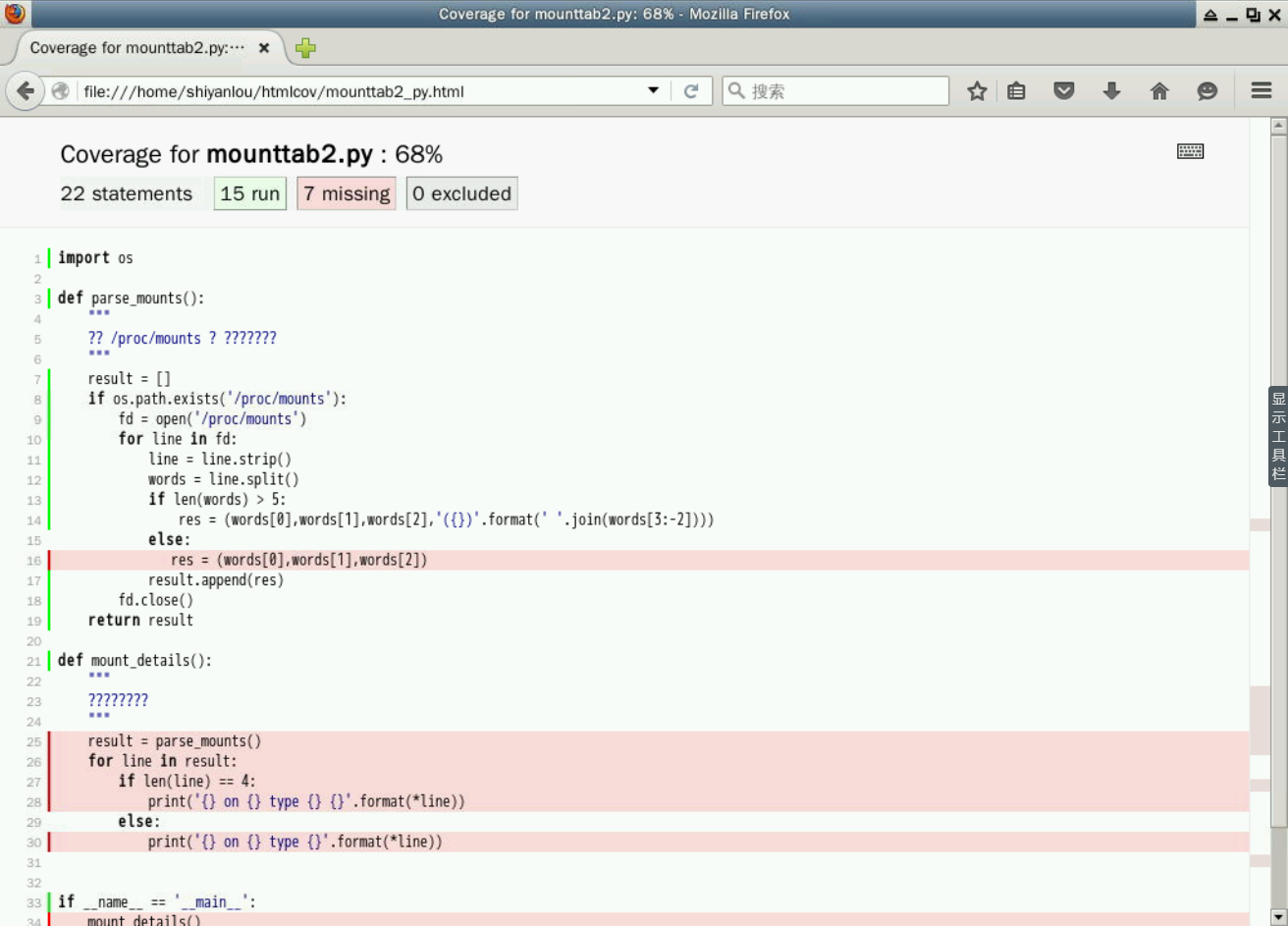
mounttab.py 中只有一個?mount_details()?函數,函數分析并打印掛載詳細信息。
import osdef mount_details():"""打印掛載詳細信息"""if os.path.exists('/proc/mounts'):fd = open('/proc/mounts')for line in fd:line = line.strip()words = line.split()print('{} on {} type {}'.format(words[0],words[1],words[2]), end=' ')if len(words) > 5:print('({})'.format(' '.join(words[3:-2])))else:print()fd.close()if __name__ == '__main__':mount_details()
重構 mounttab.py
現在我們在 mounttab2.py 中重構了上面的代碼并且有一個我們能容易的測試的新函數?parse_mounts()。
import osdef parse_mounts():"""分析 /proc/mounts 并返回元組的列表"""result = []if os.path.exists('/proc/mounts'):fd = open('/proc/mounts')for line in fd:line = line.strip()words = line.split()if len(words) > 5:res = (words[0],words[1],words[2],'({})'.format(' '.join(words[3:-2])))else:res = (words[0],words[1],words[2])result.append(res)fd.close()return resultdef mount_details():"""打印掛載詳細信息"""result = parse_mounts()for line in result:if len(line) == 4:print('{} on {} type {} {}'.format(*line))else:print('{} on {} type {}'.format(*line))if __name__ == '__main__':mount_details()
同樣我們測試代碼,編寫 mounttest.py 文件:
#!/usr/bin/env python
import unittest
from mounttab2 import parse_mountsclass TestMount(unittest.TestCase):"""我們的基本測試類"""def test_parsemount(self):"""實際測試任何以 `test_` 開頭的方法都被視作測試用例"""result = parse_mounts()self.assertIsInstance(result, list)self.assertIsInstance(result[0], tuple)def test_rootext4(self):"""測試找出根文件系統"""result = parse_mounts()for line in result:if line[1] == '/' and line[2] != 'rootfs':self.assertEqual(line[2], 'ext4')if __name__ == '__main__':unittest.main()
運行程序
$ python3 mounttest.py
..
----------------------------------------------------------------------
Ran 2 tests in 0.001sOK3.5 測試覆蓋率
測試覆蓋率是找到代碼庫未經測試的部分的簡單方法。它并不會告訴你的測試好不好。
在 Python 中我們已經有了一個不錯的覆蓋率工具來幫助我們。你可以在實驗樓環境中安裝它:
$ sudo pip3 install coverage
覆蓋率示例
$ coverage3 run mounttest.py
..
----------------------------------------------------------------------
Ran 2 tests in 0.013sOK
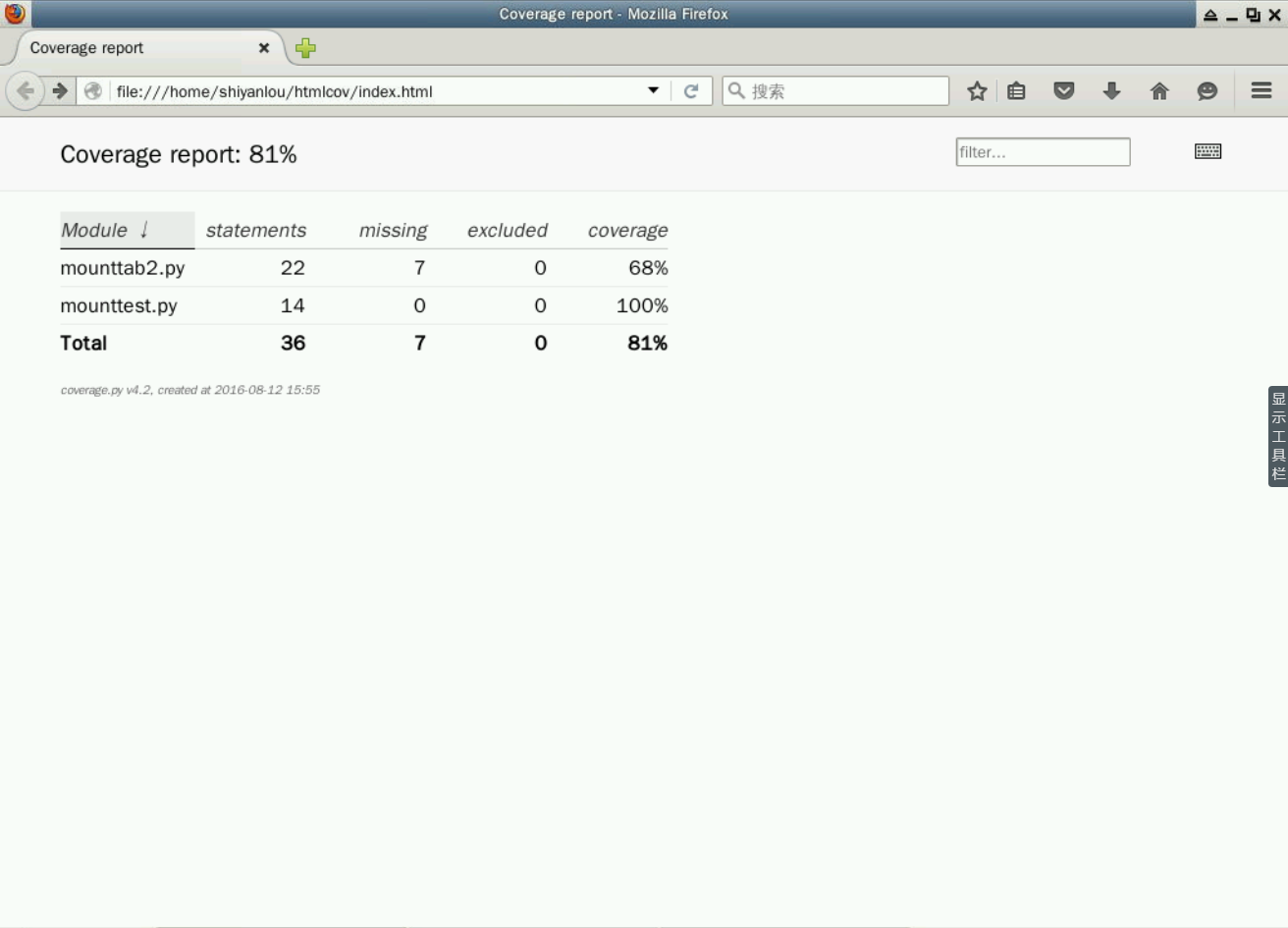
$ coverage3 report -m
Name Stmts Miss Cover Missing
--------------------------------------------
mounttab2.py 22 7 68% 16, 25-30, 34
mounttest.py 14 0 100%
--------------------------------------------
TOTAL 36 7 81%
我們還可以使用下面的命令以 HTML 文件的形式輸出覆蓋率結果,然后在瀏覽器中查看它。
$ coverage3 html
四、總結
知識點回顧:
- 單元測試概念
- 使用 unittest 模塊
- 測試用例的編寫
- 異常測試
- 測試覆蓋率概念
- 使用 coverage 模塊
本實驗了解了什么是單元測試,unittest 模塊怎么用,測試用例怎么寫。以及最后我們使用第三方模塊 coverage 進行了覆蓋率測試。
在實際生產環境中,測試環節是非常重要的的一環,即便志不在測試工程師,但以后的趨勢就是 DevOps,所以掌握良好的測試技能也是很有用的。
項目結構
一、實驗介紹
本實驗闡述了一個完整的 Python 項目結構,你可以使用什么樣的目錄布局以及怎樣發布軟件到網絡上。
知識點
- 創建項目,編寫?
__init__?文件 - 使用 setuptools 模塊,編寫 setup.py 和 MANIFEST.in 文件
- 創建源文件的發布版本
- 項目注冊&上傳到 PyPI
二、創建 Python 項目
我們的實驗項目名為 _factorial_,放到?/home/shiyanlou/factorial?目錄:
$ cd /home/shiyanlou
$ mkdir factorial
$ cd factorial/
我們給將要創建的 Python 模塊取名為?myfact_,因此我們下一步創建 _myfact?目錄。
$ mkdir myfact
$ cd myfact/
主代碼將在?fact.py?文件里面。
"myfact module"def factorial(num):"""返回給定數字的階乘值:arg num: 我們將計算其階乘的整數值:return: 階乘值,若傳遞的參數為負數,則為 -1"""if num >= 0:if num == 0:return 1return num * factorial(num -1)else:return -1
我們還有模塊的?__init__.py?文件,內容如下:
from fact import factorial
__all__ = [factorial, ]
我們還在?factorial?目錄下添加了一個 ?README.rst? 文件。因此,目錄結構看起來像下面這樣:
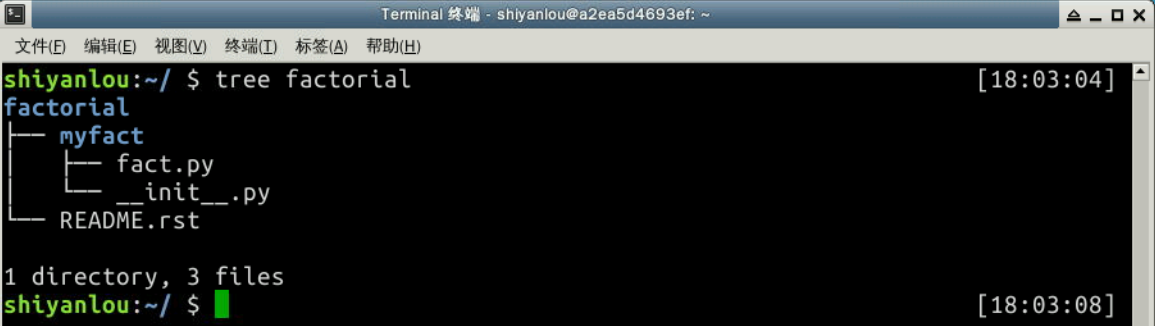
2.1 MANIFEST.in
現在我們要寫一個?/home/shiyanlou/factorial/MANIFEST.in?文件,它用來在使用?sdist?命令的時候找出將成為項目源代碼壓縮包一部分的所有文件。
include *.py
include README.rst
如果你想要排除某些文件,你可以在這個文件中使用?exclude?語句。
2.2 安裝 python-setuptools 包
我們使用 _virtualenv_(這里不示范步驟)。
$ sudo pip3 install setuptools2.3 setup.py
最終我們需要寫一個?/home/shiyanlou/factorial/setup.py,用來創建源代碼壓縮包或安裝軟件。
#!/usr/bin/env python3
"""Factorial project"""
from setuptools import find_packages, setupsetup(name = 'factorial', # 注意這里的name不要使用factorial相關的名字,因為會重復,需要另外取一個不會與其他人重復的名字version = '0.1',description = "Factorial module.",long_description = "A test module for our book.",platforms = ["Linux"],author="ShiYanLou",author_email="support@shiyanlou.com",url="/courses/596",license = "MIT",packages=find_packages())
name?是項目名稱,version?是發布版本,description?和?long_description_ 分別是項目介紹,項目長描述。platforms?是此模塊的支持平臺列表。_find_packages()?是一個能在你源目錄下找到所有模塊的特殊函數,packaging docs。
2.3.1. setup.py 用例
要創建一個源文件發布版本,執行以下命令。
$ python3 setup.py sdist
執行完畢會返回類似下面的信息:
running sdist
running egg_info
creating factorial.egg-info
writing factorial.egg-info/PKG-INFO
writing top-level names to factorial.egg-info/top_level.txt
writing dependency_links to factorial.egg-info/dependency_links.txt
writing manifest file 'factorial.egg-info/SOURCES.txt'
reading manifest file 'factorial.egg-info/SOURCES.txt'
reading manifest template 'MANIFEST.in'
writing manifest file 'factorial.egg-info/SOURCES.txt'
running check
creating factorial-0.1
creating factorial-0.1/factorial.egg-info
creating factorial-0.1/myfact
making hard links in factorial-0.1...
hard linking MANIFEST.in -> factorial-0.1
hard linking README.rst -> factorial-0.1
hard linking setup.py -> factorial-0.1
hard linking factorial.egg-info/PKG-INFO -> factorial-0.1/factorial.egg-info
hard linking factorial.egg-info/SOURCES.txt -> factorial-0.1/factorial.egg-info
hard linking factorial.egg-info/dependency_links.txt -> factorial-0.1/factorial.egg-info
hard linking factorial.egg-info/top_level.txt -> factorial-0.1/factorial.egg-info
hard linking myfact/__init__.py -> factorial-0.1/myfact
hard linking myfact/fact.py -> factorial-0.1/myfact
Writing factorial-0.1/setup.cfg
creating dist
Creating tar archive
removing 'factorial-0.1' (and everything under it)
我們能在?dist?目錄下看到一個 tar 壓縮包。
$ ls dist/
factorial-0.1.tar.gz
記住嘗試安裝代碼時使用 virtualenv。
執行下面的命令從源代碼安裝。
$ sudo python3 setup.py install
學習更多可前往?packaging.python.org。
2.4 Python Package Index (PyPI)
你還記得我們經常使用的?pip?命令嗎?有沒有想過這些包是從哪里來的?答案是 _PyPI_。這是 Python 的軟件包管理系統。
為了實驗,我們會使用?PyPI?的測試服務器 ?https://testpypi.python.org/pypi。
2.4.1 創建賬號
首先在這個鏈接注冊賬號。你會收到帶有鏈接的郵件,點擊這個鏈接確認你的注冊。
創建 ~/.pypirc 文件,存放你的賬號詳細信息,其內容格式如下:
[distutils]
index-servers = pypitestpypi[pypi]
repository: https://upload.pypi.org/legacy/
username: <username>
password: <password>[testpypi]
repository:https://test.pypi.org/legacy/
username: <username>
password: <password>
替換 ?<username>?和 ?<password>?為您新創建的帳戶的詳細信息。在這里,由于我們是到?testpypi的網頁上去注冊賬號,即將相應的服務上傳到?testpypi,所以在這里,你只需修改[testpypi]的用戶名和密碼
記得在?setup.py?中更改項目的名稱為其它的名字來測試下面的指令,在接下來的命令中我將項目名稱修改為 factorial2,為了不重復,大家需要自行修改至其它名稱(不要使用 factorial 和 factorial2,因為已經被使用了)。
2.4.2 上傳到 TestPyPI 服務
下一步我們會將我們的項目到 TestPyPI 服務。這通過?twine?命令完成。
我們也會使用?-r?把它指向測試服務器。
$ sudo pip3 install twine
$ twine upload dist/* -r testpypi
執行完畢會返回類似下面的信息:
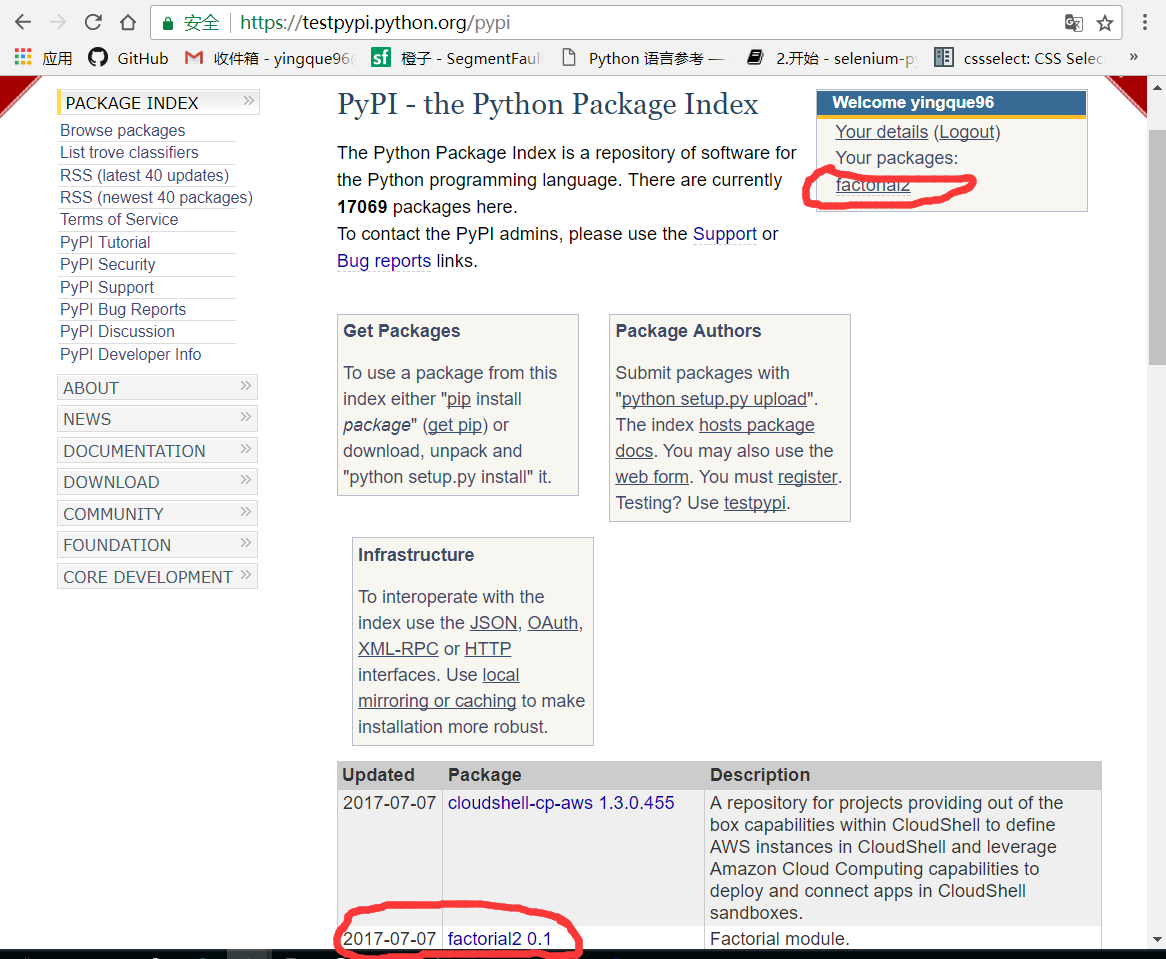
Uploading distributions to https://test.pypi.org/legacy/
Uploading factorial2-0.1.tar.gz
現在如果你瀏覽這個頁面,你會發現你的項目已經準備好被別人使用了。
在這里你也可以使用下面的命令上傳到 PyPI 服務上,但這里需要注意,在?~/.pypirc?里面,你需要到?https://pypi.python.org頁面,按照上面的步驟去注冊一個賬號,然后到~/.pypirc?的?[pypi]?下填寫相應的用戶名和密碼。testpypi?和?pypi?的賬號密碼并不通用。
$ twine upload dist/* -r pypi三、總結
實驗知識點回顧:
- 創建項目,編寫?
__init__?文件 - 使用 setuptools 模塊,編寫 setup.py 和 MANIFEST.in 文件
- 創建源文件的發布版本
- 項目注冊&上傳到 PyPI
本實驗使用了 setuptools 包,并完成了較為完整的項目創建&發布流程,最后還將項目發布到了網絡 (PyPI)上。
Flask 介紹
一、實驗介紹
本節實驗通過一些簡單的示例,學習 Flask 框架的基本使用。
知識點
- 微框架、WSGI、模板引擎概念
- 使用 Flask 做 web 應用
- 模板的使用
- 根據 URL 返回特定網頁
二、基本概念
什么是 Flask?
Flask 是一個 web 框架。也就是說 Flask 為你提供工具,庫和技術來允許你構建一個 web 應用程序。這個 web 應用程序可以是一些 web 頁面、博客、wiki、基于 web 的日歷應用或商業網站。
Flask 屬于微框架(_micro-framework_)這一類別,微架構通常是很小的不依賴于外部庫的框架。這既有優點也有缺點,優點是框架很輕量,更新時依賴少,并且專注安全方面的 bug,缺點是,你不得不自己做更多的工作,或通過添加插件增加自己的依賴列表。Flask 的依賴如下:
- Werkzeug? 一個 WSGI 工具包
- jinja2? 模板引擎
維基百科 WSGI 的介紹:
Web 服務器網關接口(Python Web Server Gateway Interface,縮寫為 WSGI)是為Python語言定義的Web 服務器和Web 應用程序或框架之間的一種簡單而通用的接口。自從 WSGI 被開發出來以后,許多其它語言中也出現了類似接口。
什么是模板引擎?
你搭建過一個網站嗎?你面對過保持網站風格一致的問題嗎,你不得不寫多次相同的文本嗎?你有沒有試圖改變這種網站的風格?
如果你的網站只包含幾個網頁,改變網站風格會花費你一些時間,這確實可行。盡管如此,如果你有許多頁面(比如在你商店里的售賣物品列表),這個任務便很艱巨。
使用模板你可以設置你的頁面的基本布局,并提及哪個元素將發生變化。這種方式可以定義您的網頁頭部并在您的網站的所有頁面使它保持一致,如果你需要改變網頁頭部,你只需要更新一個地方。
使用模板引擎創建/更新/維護你的應用會節約你很多時間。
三、"Hello World" 應用
我們將使用 flask 完成一個非常基礎的應用。
- 安裝 flask
$ sudo pip3 install flask
- 創建項目結構
$ cd /home/shiyanlou
$ mkdir -p hello_flask/{templates,static}
這是你的 web 應用的基本結構:
$ tree hello_flask/
hello_flask
|-- static
`-- templates2 directories, 0 files
templates?文件夾是存放模板的地方,static?文件夾存放 web 應用所需的靜態文件(images, css, javascript)。
- 創建應用文件
$ cd hello_flask
$ vim hello_flask.py
hello_flask.py 文件里編寫如下代碼:
#!/usr/bin/env python3import flask# Create the application.
APP = flask.Flask(__name__)@APP.route('/')
def index():""" 顯示可在 '/' 訪問的 index 頁面"""return flask.render_template('index.html')if __name__ == '__main__':APP.debug=TrueAPP.run()
- 創建模板文件 ?
index.html
$ vim templates/index.html
index.html 文件內容如下:
<!doctype html>
<html lang="en"><head><meta charset="utf-8" /><title>Hello world!</title><linktype="text/css"rel="stylesheet"href="{{ url_for('static',filename='hello.css')}}"/></head><body>It works!</body>
</html>
- 運行 flask 應用程序
$ python3 hello_flask.py
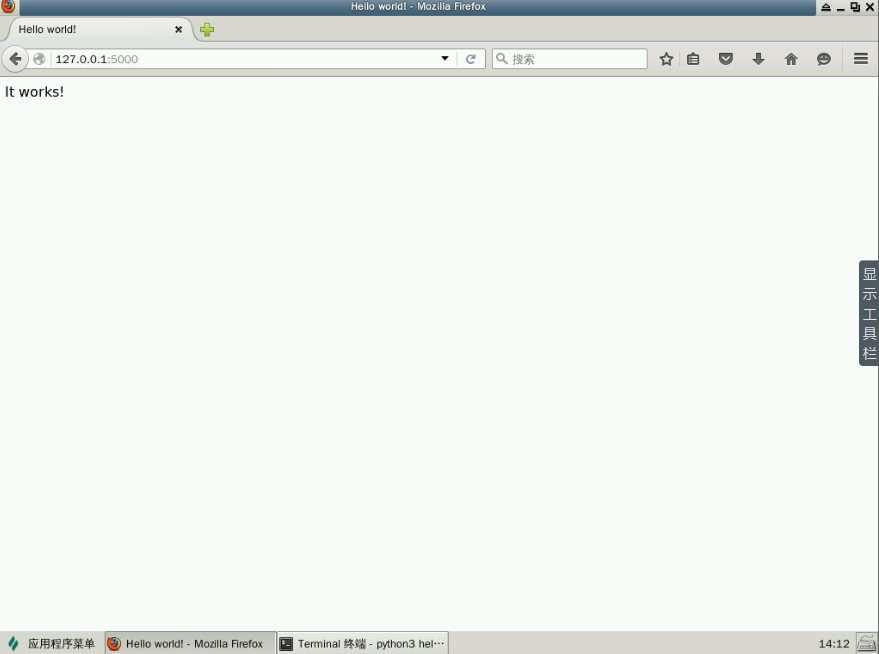
訪問?http://127.0.0.1:5000/,這應該只是顯示黑字白底的 "It works!" 文本,如下圖:
四、Flask 中使用參數
在本節中我們將要看到如何根據用戶使用的 ?URL 返回網頁。
為此我們更新 hello_flask.py 文件。
- 在 hello_flask.py 文件中添加以下條目
@APP.route('/hello/<name>/')
def hello(name):""" Displays the page greats who ever comes to visit it."""return flask.render_template('hello.html', name=name)
- 創建下面這個模板 hello.html
<!doctype html>
<html lang="en"><head><meta charset="utf-8" /><title>Hello</title><linktype="text/css"rel="stylesheet"href="{{ url_for('static',filename='hello.css')}}"/></head><body>Hello {{name}}</body>
</html>
- 運行 flask 應用
$ python3 hello_flask.py
訪問?http://127.0.0.1:5000/?,這應該只是顯示黑字白底的 "It works!" 文本。
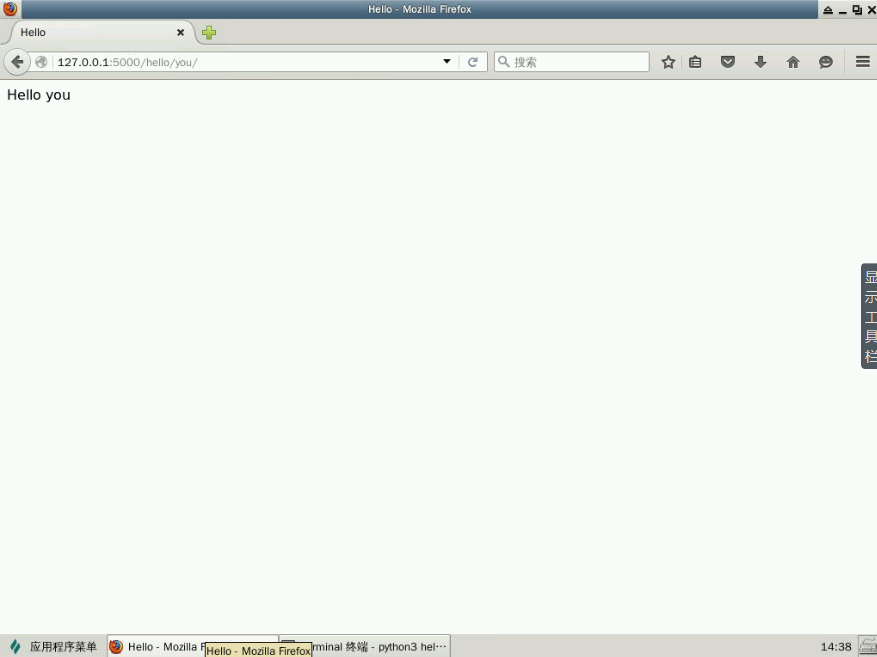
訪問http://127.0.0.1:5000/hello/you,這應該返回文本 "Hello you",見下圖:
無論你在 URL 中?/hello/?后填寫的什么,都會出現在返回的網頁中。
這是你第一次使用模板,我們在 hello_flask.py 中建立了?name?變量(參見 hello 函數的 return 行)。通過語法?{{name}},name 變量之后在頁面中顯示其自身。
五、額外工作
目前,對于每一個頁面我們都創建了一個模板,其實這是不好的做法,我們應該做的是創建一個主模板并且在每個頁面使用它。
- 創建模板文件 master.html。
<!doctype html>
<html lang="en"><head><meta charset="utf-8" /><title>{% block title %}{% endblock %} - Hello Flask!</title><linktype="text/css"rel="stylesheet"href="{{ url_for('static',filename='hello.css')}}"/></head><body>{% block body %}{% endblock %}</body>
</html>
- 調整模板 index.html。
{% extends "master.html" %} {% block title %}Home{% endblock %} {% block body %}
It works! {% endblock %}
正如你所看到的,在 master.html 模板中我們定義了兩部分,名為?title?和?body?的?blocks。
在模板 index.html 中,我們聲明這個模板擴展自 master.html 模板,然后我們定義了內容來放在這兩個部分中(blocks)。在第一個 block?title?中,我們放置了?Home?單詞,在第二個 block?body?中我們定義了我們想要在頁面的 body 中有的東西。
- 作為練習,更改其他模板 hello.html,同樣要使用 master.html。
- 在 hello 頁面添加首頁鏈接。
調整模板 hello.html,添加到首頁的鏈接。
<a href="{{ url_for('index') }}"><button>Home</button></a>
- 作為你的任務,在首頁添加到 hello 頁面的鏈接。
六、總結
實驗知識點回顧:
- 微框架、WSGI、模板引擎概念
- 使用 Flask 做 web 應用
- 模板的使用
- 根據 URL 返回特定網頁
本實驗中我們了解了微框架、WSGI、模板引擎等概念,學習使用 Flask 做一個 web 應用,在這個 web 應用中,我們使用了模板。而用戶以正確的不同 URL 訪問服務器時,服務器返回不同的網頁。最后還給大家留了一個小任務,希望大家能完成。
當然,在學習過程中有任何不懂的地方或者對 Flsak 非常感興趣,推薦學習 Flask官方文檔。
![[BJDCTF2020]EasySearch1](http://pic.xiahunao.cn/[BJDCTF2020]EasySearch1)




)






)
)

)


四十八 PCA主成分分析降維與圖像重建)
)