亞信科技在Apache SeaTunnel的實踐分享
自我介紹
各位同學好,很榮幸通過Apache SeaTunnel社區和大家進行分享交流。我是來自亞信科技的潘志宏,主要負責公司內部數據中臺產品的開發。

本次分享的主題是Apache SeaTunnel在亞信科技的集成實踐,具體講我們的數據中臺是如何集成SeaTunnel的。
分享內容概述
在本次分享中,我將重點講解以下幾個方面:
- 為什么選擇SeaTunnel
- 如何集成SeaTunnel
- 集成SeaTunnel過程中遇到的問題
- SeaTunnel的二次開發
- 對SeaTunnel的期待
為什么選擇SeaTunnel
首先介紹一下,我主要負責亞信數據中臺產品DATAOS的迭代開發。DATAOS是一個比較標準的數據中臺產品,涵蓋數據集成、數據開發、數據治理、數據開放等功能模塊。與SeaTunnel相關的主要是數據集成模塊,該模塊主要負責數據的整合。
在引入SeaTunnel之前,我們的數據集成模塊的功能架構如下:
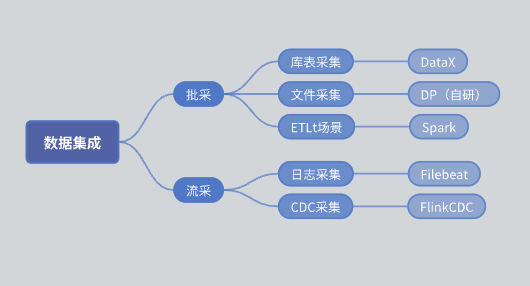
- 批采:分為庫表采集和文件采集。
- 庫表采集:主要使用DataX實現。
- 文件采集:自研的DP引擎。
- ETLt采集:自研的ETLt采集引擎。DataX偏向于ELT(抽取、加載、轉換),適用于數據抽取入庫后再進行復雜的轉換,但在某些場景下需要進行EL小T(抽取、加載、簡單的轉換),DataX并不適合。因此,我們基于Spark SQL自研了一個引擎。
- 流采:日志采集主要基于Filebeat,CDC采集主要基于Flink CDC。
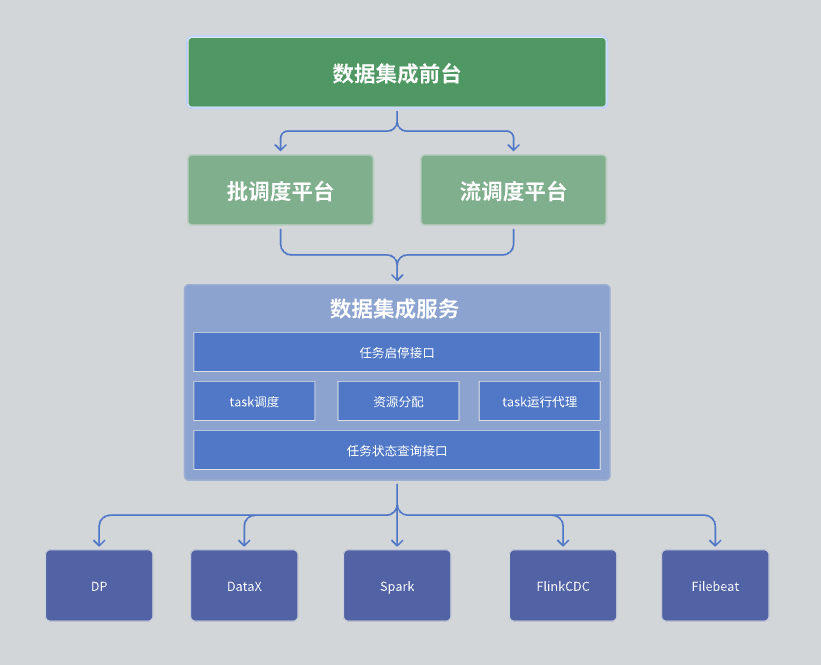
在我們的數據集成模塊中,整體架構分為三層,分別是數據集成前臺、調度平臺以及數據集成服務。
下面是每一層的詳細描述:
第一層:數據集成前臺
數據集成前臺主要負責數據集成任務的管理。具體包括任務的開發、調度開發和運行監控。這些任務通過DAG(有向無環圖)的方式將各個集成算子組合起來,實現復雜的數據處理流程。前臺界面提供了直觀的任務管理界面,使得用戶可以方便地配置、監控數據集成任務。
第二層:調度平臺
調度平臺負責任務運行的調度管理。它支持批處理和流處理兩種模式,并能夠根據任務的依賴關系和調度策略拉起相應的任務。
第三層:數據集成服務
數據集成服務是整個數據中心服務的核心,它提供了一系列關鍵功能:
- 任務管理接口:包括任務的創建、刪除、更新和查詢等功能。
- 任務啟停接口:允許用戶啟動或停止特定的任務。
- 任務狀態查詢接口:查詢任務的當前狀態信息,便于監控和管理。
數據集成服務還負責任務的具體運行。由于我們的采集任務可能包含多個引擎,這就需要在任務運行時實現多引擎的協調和調度。
任務運行流程
任務的運行主要包括以下幾個步驟:
- 任務調度:根據預定的調度策略和依賴關系,調度平臺拉起相應的任務。
- 任務執行:任務執行過程中,根據任務的DAG配置,依次執行各個算子。
- 多引擎協調:對于包含多個引擎的任務(如DataX和Spark混合任務),需要在執行過程中協調各個引擎的運行,確保任務的順利執行。
資源分配
同時為了使DataX這種單機運行的任務能夠更好地分布式運行,并實現資源復用,我們對DataX任務進行了資源分配的優化:
- 分布式調度:通過資源分配機制,將DataX任務分布到多個節點上運行,避免單點瓶頸,提高任務的并行度和執行效率。
- 資源復用:通過合理的資源管理和分配策略,確保不同任務在資源使用上的高效復用,減少資源浪費。
任務運行代理
我們對每個執行引擎實現了相應的任務執行代理,以實現任務的統一管理和監控:
- 執行引擎代理:在數據集成服務中,代理管理各個執行引擎,如DataX、Spark、Flink CDC等。代理負責任務的啟動、停止以及狀態監控。
- 統一接口:提供統一的任務管理接口,使得不同引擎的任務可以通過相同的接口進行管理,簡化了運維和管理工作。
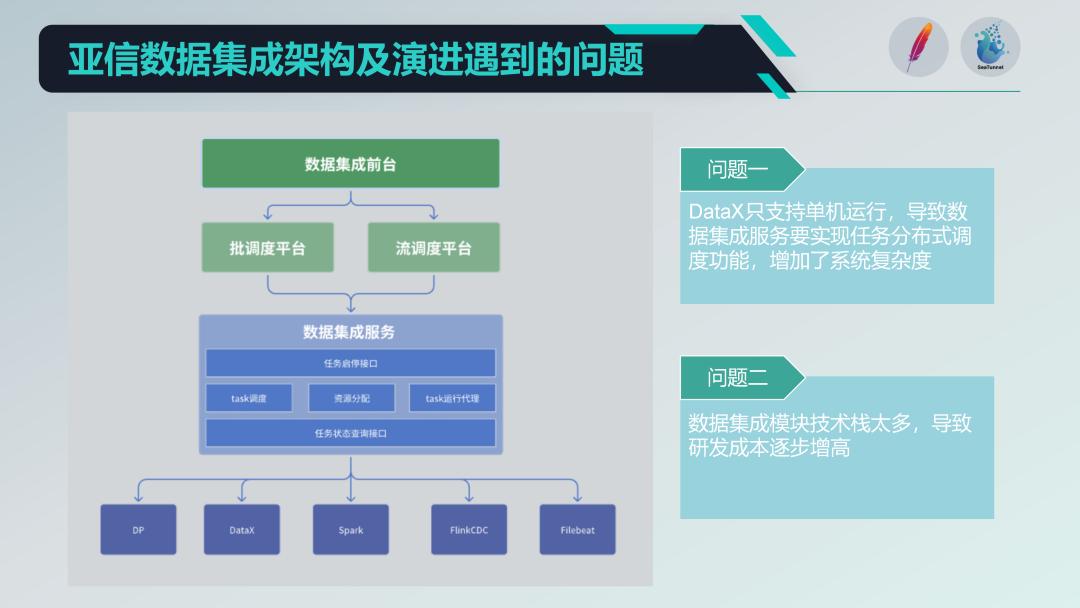
老的數據集成架構存在的一些問題
我們集成了一些開源項目,如DataX、Spark、Flink CDC、Filebeat等,形成了一個功能強大的數據集成服務平臺。但也面臨一些問題:
- 單機運行限制:DataX只支持單機運行,這導致我們需要在其基礎上實現分布式調度功能,增加了系統的復雜度。
- 技術棧過于多樣化:引入了多個技術棧(如Spark和Flink),雖然功能豐富,但也導致研發成本較高,每次開發新功能都需要應對多個技術棧的兼容性和集成問題。
架構演進
為了優化架構并降低復雜度,我們對現有架構進行了演進:
- 整合多引擎功能:引入SeaTunnel后,我們可以統一多個引擎的功能,實現單一平臺上的多種數據處理能力。
- 簡化資源管理:通過SeaTunnel的資源管理功能,簡化了DataX等單機任務的分布式調度,降低了資源分配和管理的復雜度。
- 降低研發成本:通過統一的架構和接口設計,減少了多技術棧帶來的開發和維護成本,提高了系統的可擴展性和易維護性。
通過對架構的優化和演進,我們成功地解決了DataX單機運行限制和多技術棧帶來的高研發成本問題。
引入SeaTunnel后,我們能夠在一個平臺上實現多種數據處理功能,同時簡化了資源管理和任務調度,提高了系統的整體效率和穩定性。
為什么選擇 SeaTunnel?
我們與 SeaTunnel 的接觸可以追溯到Waterdrop時期,針對于Waterdrop進行過多次應用實踐。
去年,SeaTunnel 推出了 Zeta 引擎,支持分布式架構,并成為 Apache 頂級項目,這使得我們在去年找到了一個合適的時間節點,進行了深入的調研,并決定引入 SeaTunnel。
以下是我們選擇 SeaTunnel 的幾個主要原因:
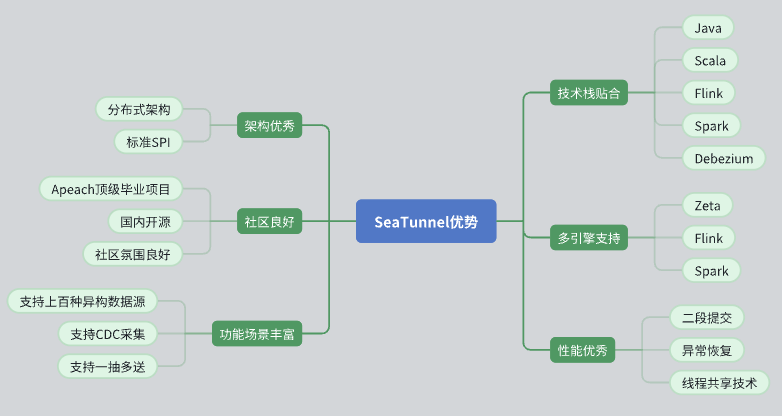
- 優秀的架構設計
- SeaTunnel 具有分布式架構,能夠很好地適應我們的需求。
- 它的 API 設計標準化,采用了 SPI(Service Provider Interface)模式,便于擴展和集成。
- 活躍的社區支持
- SeaTunnel 是 Apache 頂級項目,社區氛圍良好,活躍的開發者和用戶群體為問題的解決和功能的擴展提供了強大的支持。
- 國內開源項目的背景,使我們在溝通和協作上更加順暢。
- 豐富的功能和數據源支持
- SeaTunnel 支持多種數據源,功能豐富,能夠滿足我們多樣化的數據處理需求。
- 支持 CDC(Change Data Capture),可以進行實時數據同步和處理。
- 支持一抽多送(one-to-many)的數據傳輸模式,提升了數據傳輸的靈活性。
- 技術棧的貼合
- SeaTunnel 兼容 Java,并且支持 Flink 和 Spark,使我們能夠在現有技術棧上無縫集成和應用。
- 使用 Debezium 進行 CDC 數據捕獲,技術實現成熟穩定。
- 多引擎支持
- SeaTunnel 支持多種計算引擎,包括 Zeta、Flink 和 Spark,能夠根據具體需求選擇最適合的引擎進行計算。
- 這一點非常重要,因為它允許我們在不同場景下選擇最優的計算模式,提升了系統的靈活性和效率。
- 出色的性能
- SeaTunnel 設計了諸如二階段提交(two-phase commit)、異常恢復(fault-tolerance recovery)以及線程共享(thread sharing)等性能優化機制,確保數據處理的高效和穩定。
引入SeaTunnel后解決的問題
SeaTunnel 能夠解決我們之前提到的兩個主要問題:
- 分布式調度
- DataX 只能單機運行,我們需要額外實現分布式調度功能。而 SeaTunnel 天生支持分布式架構,無論是使用 Zeta、Flink 還是 Spark 作為計算引擎,都能輕松實現分布式數據處理,大大簡化了我們的工作。
- 技術棧整合
- 我們之前使用了多種技術棧,包括 DataX、Spark、Flink CDC 等,這使得研發成本高昂且系統復雜。而 SeaTunnel 通過統一封裝這些技術棧,提供了一個集成化的平臺,能夠同時支持 ELT 和 ETL 流程,極大地簡化了系統架構,降低了開發和維護成本。
如何集成 SeaTunnel
在集成 SeaTunnel 之前,我們的舊架構已經存在并運行了一段時間,整體上分為三層:前臺、調度平臺以及數據集成服務。前臺負責任務的管理與開發,調度平臺負責任務的調度與依賴管理,而數據集成服務則是執行和管理所有數據集成任務的核心部分。
以下是我們在集成 SeaTunnel 后的新架構。
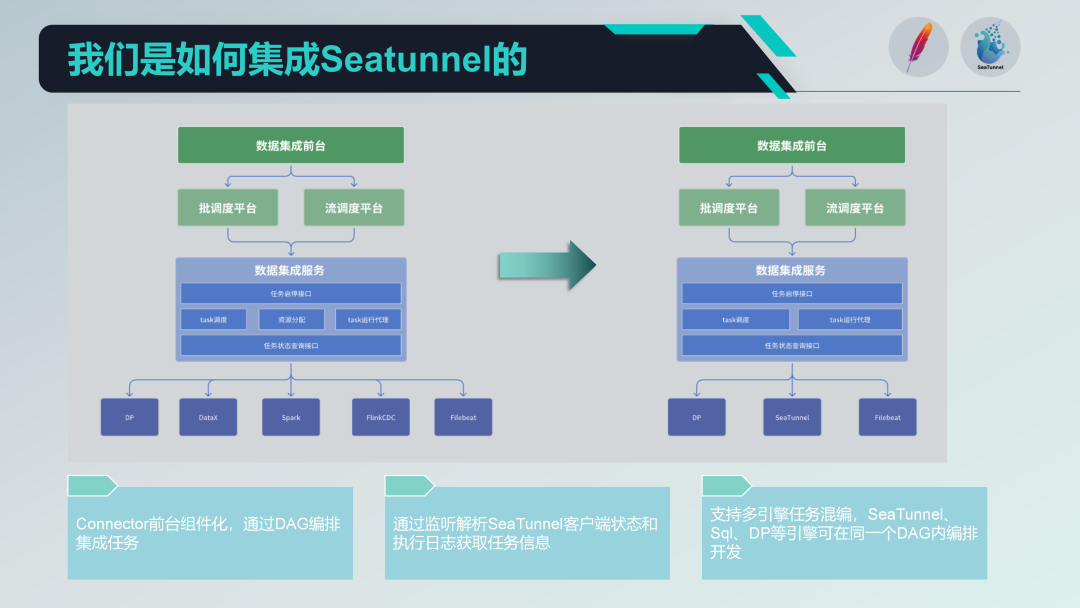
首先,我們將舊架構中涉及 DataX 的資源分配部分取消了。由于 SeaTunnel 本身支持分布式架構,不再需要額外的資源分配管理。這一調整極大地簡化了我們的架構。
技術棧的替換
我們逐步使用 SeaTunnel 替換了舊有的技術棧。具體步驟如下:
- 替換批處理任務:我們先替換了舊架構中使用 DataX 和 Spark 進行批處理 ETL 的部分。
- 替換流處理任務:接下來,我們將逐步替換使用 Flink CDC 進行流處理的部分。 通過這種分步走的方式,我們可以確保系統在逐步過渡過程中始終保持穩定。
組件化 SeaTunnel Connector
我們基于 SeaTunnel 的 Connector 進行了組件化設計,并在前臺通過表單方式進行配置和 DAG 編排。雖然 SeaTunnel Web 也在進行類似的工作,但我們根據自身需求進行了定制化開發,以便更好地與現有系統集成。
任務運行代理
在任務運行代理方面,我們通過 SeaTunnel 客戶端提交任務,并監聽 SeaTunnel 客戶端的狀態和執行日志。通過解析這些日志,我們可以獲取任務的執行狀態信息,確保任務執行的可監控性和可追蹤性。
多引擎混編開發
我們支持多引擎混編開發,在前臺頁面可以對一個調度任務進行多引擎的 DAG 編排。這樣,我們可以在一個調度任務中同時使用不同的引擎(如 SQL 引擎和 DP 引擎)進行任務開發,提高系統的靈活性和擴展性。
集成SeaTunnel過程中遇到的問題
在集成 SeaTunnel 的過程中,我們遇到了一些問題,以下是幾個具有代表性的問題及其解決方案:
問題一:報錯處理
在使用 SeaTunnel 的過程中,我們遇到了一些報錯,這些報錯涉及到框架的代碼。由于官方文檔中沒有相關說明,我們通過加入社區微信群,向群內的開發者求助,及時解決了問題。
問題二:任務割接
我們的舊采集任務是使用 DataX 實現的,在替換為 SeaTunnel 時,需要考慮任務的割接問題。
我們通過以下方案進行解決:
- 組件化設計:我們的數據中臺采集任務是組件化設計的,前臺的組件和后臺的執行引擎之間有一層轉換層。前臺配置表單,后臺通過轉換層生成 DataX 需要執行的 JSON 文件。
- 相似的 JSON 文件生成:SeaTunnel 的配置與 DataX 類似,前臺同樣是通過表單配置,后臺生成 SeaTunnel 需要執行的 JSON 文件。通過這種方式,我們能夠無縫地將舊任務轉移到新的 SeaTunnel 平臺上,確保任務的平滑過渡。
- SQL 腳本轉換:編寫 SQL 腳本,對舊有的 DataX 任務進行清洗和轉換,使其能夠適配 SeaTunnel。這種方法更具靈活性和適應性,因為 SeaTunnel 會頻繁更新,直接寫硬編碼進行兼容不是長久之計。通過腳本轉換,可以更高效地遷移任務,適應 SeaTunnel 的更新。
問題三:版本管理
我們在使用 SeaTunnel 的過程中遇到了版本管理的問題。SeaTunnel 的更新頻繁,而我們團隊的二開版本需要持續跟進最新版本。以下是我們的解決方案:
本地分支管理:我們基于 SeaTunnel 2.3.2 版本拉了一個本地分支,對其進行二次開發,包括修復個性化需求和臨時修復的 bug。為了盡量減少本地維護的代碼,我們僅保留必要的改動,其他部分盡量使用社區的最新版本。
定期合并社區更新:我們定期將社區的新版本合并到本地分支,特別是對我們改動的部分進行更新和兼容。雖然這種方法比較笨拙,但可以保證我們及時跟進社區的最新功能和修復。
回饋社區:為了更好地管理和維護代碼,我們計劃將我們的一些改動和個性化需求提交給社區,爭取社區的接納和支持。這不僅有助于減少我們本地的維護工作,也有助于社區的共同發展。
SeaTunnel 二次開發與實踐
在 SeaTunnel 的使用過程中,我們針對實際業務需求進行了多項二次開發,特別是在連接器(Connector)層面。以下是我們在二次開發中遇到的問題及解決方案。
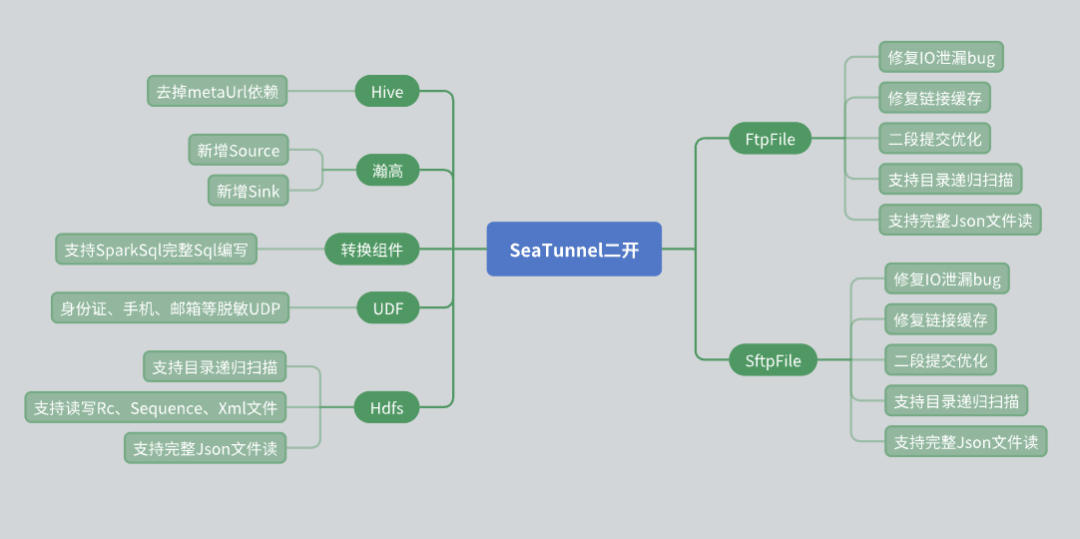
Hive Connector 的改造
- 原始的 SeaTunnel Hive Connector 需要依賴 Meta URL 來獲取元數據。然而,在實際應用中,很多第三方用戶因安全問題無法提供 Meta URL。為了應對這一情況,我們進行了如下改造:
- 使用 Hive Server 2 的 JDBC 接口來獲取表的元數據信息,從而避免了對 Meta URL 的依賴。
- 通過這種方式,我們能夠更靈活地為用戶提供 Hive 數據的讀寫能力,同時確保數據安全。
瀚高數據庫的支持
- 瀚高數據庫在我們的項目中有廣泛應用,因此我們增加了對瀚高數據庫的數據源讀寫支持。同時,針對瀚高數據庫的一些特殊需求,我們開發了轉換組件:
- 支持行轉列、列轉行等復雜轉換操作。
- 編寫了多種 UDF(用戶自定義函數),用于數據脫敏等操作。
文件連接器的改造
- 文件系統連接器在我們的使用中占有重要地位,因此我們對其進行了多項改造:
- HDFS Connector:增加了目錄遞歸和正則表達式掃描文件的功能,同時支持讀取和寫入多種文件格式(如 RC、Sequence、XML、JSON)。
- FTP 和 SFTP Connector:修復了 I/O 泄露的 bug,并優化了連接緩存機制,確保同一 IP 不同賬號之間的獨立性。
二段提交機制的優化
在使用 SeaTunnel 的過程中,我們深入了解了其二段提交機制,以確保數據的一致性。以下是我們在此過程中遇到的問題及解決方案: 
問題描述:在使用 FTP 和 SFTP 進行文件寫入時,報錯提示沒有寫入權限。排查發現,SeaTunnel 為了保證數據一致性,會先將文件寫入臨時目錄,然后再進行移動。
然而,由于不同賬號對臨時目錄的權限設置問題,導致寫入失敗。
解決方案:在創建臨時目錄時,設置更大的權限(如 777),以確保所有賬號都有權限寫入。同時,解決了文件移動過程中由于跨文件系統導致的 rename 命令失敗的問題,通過在同一文件系統下創建臨時目錄,避免了跨文件系統操作。
二次開發管理
在二次開發過程中,我們面臨著如何管理和同步 SeaTunnel 新版本的問題。我們的解決方案如下:
- 本地分支管理:基于 SeaTunnel 2.3.2 版本拉了一個本地分
- 定期合并社區更新:定期將社區的新版本合并到本地分支,確保我們能夠及時獲得社區的新功能和修復。
- 回饋社區:計劃將我們的一些改動和個性化需求提交給社區,以期獲得社區的接納和支持,從而減少本地維護的工作量。
SeaTunnel 集成與應用
在集成 SeaTunnel 過程中,我們主要關注以下幾點:
- 資源分配優化:利用 SeaTunnel 的分布式架構,簡化了資源分配問題,不再需要額外的分布式調度功能。
- 技術棧整合:將 DataX、Spark、FlinkCDC 等不同技術棧的功能整合到 SeaTunnel 中,統一封裝,實現 ETL 和 ELT 的一體化。
通過以上步驟和策略,我們成功地將 SeaTunnel 集成到我們的數據集成服務中,解決了舊有系統中的一些關鍵問題,優化了系統的性能和穩定性。
在這個過程中,我們積極參與社區,尋求幫助并反饋問題,確保集成工作的順利進行。這種積極的互動不僅提高了我們的技術水平,也推動了 SeaTunnel 社區的發展。
參與開源社區的心得體會
在參與 SeaTunnel 的過程中,我有以下幾點體會:
- 時間合適:我們在 SeaTunnel 快速發展的階段選擇了這個項目,時機非常好。SeaTunnel 的發展給了我們很大的信心,讓我們覺得有很多事情可以做。
- 個人目標:我在今年年初就定下了參與開源社區的目標,并積極付諸行動。
- 社區的友好:SeaTunnel 社區非常友好,大家交流順暢,相互幫助。這種積極的氛圍讓我覺得參與其中非常值得。
對于那些一直想參與開源社區但還沒有邁出第一步的人,我想鼓勵大家勇敢地邁出這一步。社區最重要的是人,只要你加入,你就是社區中不可或缺的一部分。
對 SeaTunnel 的期待
最后,我想分享一下對 SeaTunnel 的一些期待:
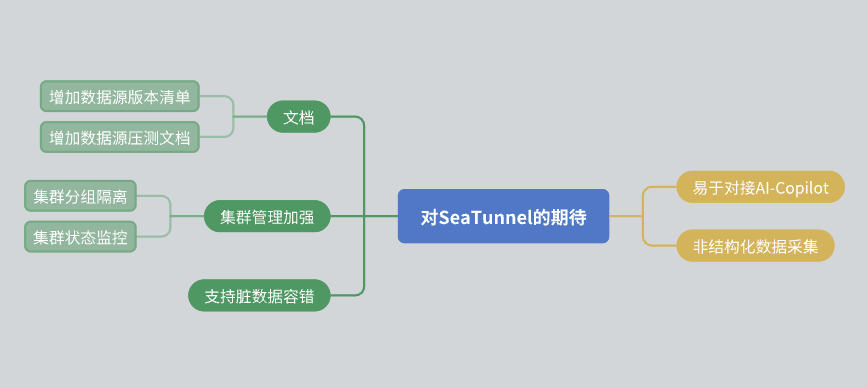
- 文檔改進:希望社區能進一步完善文檔,包括數據源的版本清單和壓測報告。
- 集群管理:希望 SeaTunnel 在集群內部能實現資源隔離,并提供更豐富的集群狀態監控信息。
- 數據容錯:雖然 SeaTunnel 已經有容錯機制,但希望未來能進一步優化。
- AI 集成:希望 SeaTunnel 能提供更多接口,方便 AI 輔助接入。
感謝 SeaTunnel 社區的每一位成員,感謝你們的付出。我的分享就到這里,謝謝大家!
本文由 白鯨開源科技 提供發布支持!


-----TSO機制詳解)
:基礎知識)


)







)


)

)