0. 摘要
| Traditional methods for reasoning segmentation rely on supervised fine-tuning with categorical labels and simple descriptions, limiting its out-of-domain generalization and lacking explicit reasoning processes. To address these limitations, we propose Seg-Zero, a novel framework that demonstrates remarkable generalizability and derives explicit chain-of-thought reasoning through cognitive reinforcement. Seg-Zero introduces a decoupled architecture consisting of a reasoning model and a segmentation model. The reasoning model interprets user intentions, generates explicit reasoning chains, and produces positional prompts, which are subsequently used by the segmentation model to generate precious pixel-level masks. We design a sophisticated reward mechanism that integrates both format and accuracy rewards to effectively guide optimization directions. Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Seg-Zero achieves robust zero-shot generalization and exhibits emergent testtime reasoning capabilities. Experiments show that SegZero-7B achieves a zero-shot performance of 57.5 on the ReasonSeg benchmark, surpassing the prior LISA-7B by 18%. This significant improvement highlights Seg-Zero’s ability to generalize across domains while presenting an explicit reasoning process. All code will be made publicly available for future research. | 傳統的推理分割方法依賴于基于分類標簽和簡單描述的監督式微調,這限制了其跨領域泛化能力,并且缺乏明確的推理過程。為了突破這些限制,我們提出了 Seg-Zero,這是一個新穎的框架,它展現出卓越的泛化能力,并通過認知強化獲得明確的思路鏈推理。Seg-Zero 引入了一個由推理模型和分割模型組成的解耦架構。推理模型能夠解讀用戶意圖,生成明確的推理鏈,并生成位置提示,隨后分割模型會利用這些提示生成精確的像素級掩碼。我們設計了一個復雜的獎勵機制,將格式獎勵和準確度獎勵相結合,以有效地引導優化方向。Seg-Zero 僅通過強化學習(GRPO)進行訓練,無需明確的推理數據,實現了穩健的零樣本泛化,并展現出突現的測試時推理能力。實驗表明,SegZero-7B 在 ReasonSeg 基準測試中實現了 57.5 的零樣本性能,比之前的 LISA-7B 高出 18%。這一顯著提升凸顯了 Seg-Zero 在呈現清晰推理過程的同時,還具備跨領域泛化的能力。所有代碼將公開發布,以供未來研究使用。 |
1.Introduction
| Reasoning segmentation generates pixel-wise masks by interpreting implicit queries through logical reasoning. This task shows significant potential in real-world applications, such as robots. Unlike conventional segmentation tasks that rely on simple categorical labels (e.g., “person” or “car”), reasoning segmentation addresses more complex and nuanced queries, such as “identify food that provides sustained energy.” Such queries require logical reasoning and the integration of cross-domain knowledge to produce accurate segmentation masks. | 推理分割通過邏輯推理解釋隱式查詢,生成像素級掩碼。這項任務在機器人等實際應用中展現出巨大的潛力。與依賴簡單分類標簽(例如“人”或“車”)的傳統分割任務不同,推理分割能夠處理更復雜、更細致的查詢,例如“識別能夠提供持續能量的食物”。這類查詢需要邏輯推理并整合跨領域知識才能生成準確的分割掩碼。 |
| Early attempts [3, 17, 32], such as LISA [17], have explored the use of multimodal large language models (MLLMs) to enhance reasoning segmentation capabilities, These methods bridge the gap between MLLMs and segmentation models by leveraging implicit semantic tokens. However, typical methods [7, 17, 32] rely solely on supervised fine-tuning (SFT) applied to mixed datasets containing only simple categorical information or basic factual descriptions [12, 13, 43]. Although this paradigm effectively aligns MLLMs [23, 24, 40] with segmentation models [14] in specific datasets, we observe that it lacks generalization capabilities. This can be demonstrated by: (i) Although existing methods excel on in-domain data, their performance significantly degrades on out-of-distribution (OOD) samples. (ii) SFT inevitably leads to catastrophic forgetting of general capabilities. (iii) The lack of an explicit reasoning process hinders their effectiveness in complex scenarios. These limitations motivate us to enhance general segmentation capabilities and improve reasoning performance by integrating an explicit reasoning process. | 早期的嘗試 [3, 17, 32],例如 LISA [17],探索了使用多模態大型語言模型 (MLLM) 來增強推理分割能力。這些方法通過利用隱式語義標記來彌合 MLLM 和分割模型之間的差距。然而,典型的方法 [7, 17, 32] 僅僅依賴于對僅包含簡單分類信息或基本事實描述的混合數據集進行監督微調 (SFT) [12, 13, 43]。雖然這種范式有效地將 MLLM [23, 24, 40] 與特定數據集中的分割模型 [14] 對齊,但我們觀察到它缺乏泛化能力。這可以通過以下方式證明:(i) 雖然現有方法在域內數據上表現出色,但它們在分布外 (OOD) 樣本上的性能顯著下降。(ii) SFT 不可避免地會導致對一般能力的災難性遺忘。 (三)缺乏明確的推理過程阻礙了它們在復雜場景中的有效性。這些局限性促使我們通過整合明確的推理過程來增強通用的分割能力并提升推理性能。 |
| Recent studies [11] demonstrate that training with pure reinforcement learning (RL) activates the emergent testtime reasoning process, highlighting that reward-driven optimization is effective in enhancing model reasoning ability. Moreover, this approach often promotes generalization rather than overfitting to specific datasets. Inspired by this, we introduce Seg-Zero, a novel framework designed to enhance reasoning and cognitive capabilities for reasoning segmentation. Seg-Zero adopts a decoupled architecture, including a reasoning model and a segmentation model. The reasoning model is an MLLM capable of processing both image and user instructions. It outputs not only regionlevel bounding boxes (bbox) but also pixel-level points to precisely localize the target object. Subsequently, the segmentation model utilizes the bbox and points to produce pixel-level segmentation masks. | 最近的研究 [11] 表明,純強化學習 (RL) 訓練可以激活緊急測試時推理過程,突出表明獎勵驅動的優化對于增強模型推理能力是有效的。此外,這種方法通常會促進泛化,而不是過度擬合到特定數據集。受此啟發,我們介紹了 Seg-Zero,這是一個旨在增強推理分割的推理和認知能力的新穎框架。Seg-Zero 采用解耦架構,包括推理模型和分割模型。推理模型是一個能夠同時處理圖像和用戶指令的 MLLM。它不僅輸出區域級邊界框 (bbox),還輸出像素級點,以精確定位目標對象。隨后,分割模型利用 bbox 和點來生成像素級分割蒙版。 |
| During training, we employ pure reinforcement learning, specifically GRPO [34], to fine-tune the reasoning model while keeping the segmentation model frozen. Rather than constructing datasets with explicitly annotated reasoning processes, we investigate the self-evolution potential of MLLM to develop reasoning capabilities, thereby achieving emergent reasoning from zero. To achieve this, we develop a sophisticated reward mechanism to enhance the reasoning process and regulate the output. These reward functions comprise two types: format rewards, which enforce constraints on the structure of the reasoning process and segmentation outputs, and accuracy rewards, which are calculated based on intersection over union (IoU) and L1 distance metrics. As illustrated in Figure 1, by leveraging optimized reward-driven reinforcement learning, our SegZero exhibits emergent test-time reasoning abilities, similar to those demonstrated in LLMs [11, 27]. This reasoning process enables the model to effectively handle complex instructions by breaking them down into sequential analytical steps, thus achieving the precise localization of target objects. Seg-Zero demonstrates exceptional performance on both in-domain and OOD data, significantly exceeding the model trained through SFT. Furthermore, Seg-Zero maintains robust visual QA capability, without the need for VQA training data. | 在訓練過程中,我們采用純強化學習,特別是 GRPO [34],對推理模型進行微調,同時保持分割模型的穩定。我們并未構建帶有明確注釋推理過程的數據集,而是探究 MLLM 的自進化潛力,以提升推理能力,從而實現從零開始的自發推理。為此,我們開發了一種復雜的獎勵機制來增強推理過程并調節輸出。這些獎勵函數包含兩種類型:格式獎勵,用于對推理過程的結構和分割輸出施加約束;準確度獎勵,基于交并比 (IoU) 和 L1 距離指標計算。如圖 1 所示,通過利用優化的獎勵驅動強化學習,我們的 SegZero 展現出與 LLM [11, 27] 類似的自發測試時推理能力。該推理過程使模型能夠通過將復雜指令分解為連續的分析步驟來有效地處理它們,從而實現目標對象的精確定位。 Seg-Zero 在領域內數據和 OOD 數據上均表現出色,顯著超越了通過 SFT 訓練的模型。此外,Seg-Zero 無需 VQA 訓練數據,即可保持強大的視覺問答能力。 |
| Experimental results show that, with only 9,000 training samples derived from RefCOCOg [43], our Seg-Zero-7B exhibits strong test-time reasoning capabilities and achieves superior generalization performance compared to models of the same scale. It achieves a zero-shot performance of 57.5 on ReasonSeg [17], surpassing the previous LISA-7B by 18%. We summarize our contributions as follows: ? We propose Seg-Zero, a novel architecture designed for reasoning segmentation. Through the pure RL algorithm, Seg-Zero exhibits emergent reasoning abilities. ? We present a detailed comparison between SFT and RL, as well as the integration of reasoning chain. Results demonstrates that RL, combined with the reasoning chain, consistently enhances model performance. ? Extensive experiments demonstrate the effectiveness of our design and offer valuable insight for fine-tuning models using RL. | 實驗結果表明,僅使用來自 RefCOCOg [43] 的 9,000 個訓練樣本,我們的 Seg-Zero-7B 就展現出強大的測試時推理能力,并且與同規模的模型相比實現了更優異的泛化性能。它在 ReasonSeg [17] 上的零樣本性能達到了 57.5,比之前的 LISA-7B 高出 18%。我們的貢獻總結如下: ? 我們提出了一種專為推理分割而設計的新穎架構 Seg-Zero。通過純 RL 算法,Seg-Zero 展現出涌現的推理能力。 ? 我們對 SFT 和 RL 進行了詳細的比較,以及推理鏈的集成。結果表明,RL 與推理鏈相結合,可以持續提升模型性能。 ? 大量實驗證明了我們設計的有效性,并為使用 RL 微調模型提供了寶貴的見解。 |

Figure 1. Seg-Zero generates a reasoning chain before producing the final segmentation mask. It utilizes a pure reinforcement learning (RL) strategy, learning the reasoning process from zero. In comparison to supervised fine-tuning (SFT), the RL-based model demonstrates superior performance on both in-domain and out-of-domain data, and the integration of reasoning chain further enhances its effectiveness.
圖 1. Seg-Zero 在生成最終分割蒙版之前生成推理鏈。它采用純強化學習 (RL) 策略,從零開始學習推理過程。與監督微調 (SFT) 相比,基于 RL 的模型在域內和域外數據上均表現出色,推理鏈的集成進一步增強了其有效性。
2. Related Works
2.1. Reasoning in Large Models
| In recent years, Large Language Models (LLMs) have exhibited remarkable reasoning capabilities. By extending the length of the Chain-of-Thought (CoT) reasoning process, OpenAI-o1 [27] introduces inference-time scaling, significantly improving its reasoning performance. In the research community, several studies have attempted to achieve testtime scaling through various approaches, including processbased reward models [20, 38, 39], reinforcement learning (RL) [15, 34], and search algorithms [10, 37]. In particular, the recent DeepSeek-R1 [11], which uses the GRPO [34] algorithm, achieves superior performance with only a few thousand RL training steps. Building on advances in the LLMs community, several recent works have attempted to leverage the reasoning capabilities of MLLMs [16, 36]. For example, Open-R1-Multimodal [16] emphasizes mathematical reasoning, while R1-V [36] shows exceptional performance in counting tasks. However, these works primarily address high-level reasoning and do not consider finegrained pixel-level understanding of images. To fill this gap, our Seg-Zero is designed to enhance pixel-level reasoning through reinforcement learning. | 近年來,大型語言模型 (LLM) 展現出卓越的推理能力。OpenAI-o1 [27] 通過延長思路鏈 (CoT) 推理過程的長度,引入了推理時間擴展,顯著提升了其推理性能。在研究界,一些研究嘗試通過各種方法實現測試時間擴展,包括基于過程的獎勵模型 [20, 38, 39]、強化學習 (RL) [15, 34] 和搜索算法 [10, 37]。尤其是最近的 DeepSeek-R1 [11],它采用了 GRPO [34] 算法,僅需幾千個強化學習訓練步驟就實現了卓越的性能。基于 LLM 社區的進展,最近的一些研究嘗試利用 MLLM [16, 36] 的推理能力。例如,Open-R1-Multimodal [16] 強調數學推理,而 R1-V [36] 在計數任務中表現出色。然而,這些研究主要關注高級推理,并未考慮圖像的細粒度像素級理解。為了填補這一空白,我們的 Seg-Zero 旨在通過強化學習來增強像素級推理。 |
2.2. Semantic Segmentation with Reasoning
| Semantic segmentation aims at predicting segmentation masks for specific classes. Numerous studies [1, 4, 5, 8, 21, 25, 33, 44], including DeepLab [6], MaskFormer [9] and SAM [14] have made significant progress in this task, making it a well-addressed problem. Instead of segmenting objects with explicit class labels, referring expression segmentation [13, 43] focuses on segmenting target objects based on short, explicit text queries. LISA [17] advances this field further by introducing the reasoning segmentation task. In this task, text queries are either more intricate or longer, demanding models with strong reasoning capabilities to accurately interpret and segment the target objects. | 語義分割旨在預測特定類別的分割掩碼。包括 DeepLab [6]、MaskFormer [9] 和 SAM [14] 在內的眾多研究 [1, 4, 5, 8, 21, 25, 33, 44] 已在此任務上取得了重大進展,使其成為一個備受關注的課題。與使用明確類別標簽進行對象分割不同,表達式分割 [13, 43] 側重于基于簡短、明確的文本查詢來分割目標對象。LISA [17] 通過引入推理分割任務,進一步推進了這一領域。在此任務中,文本查詢要么更復雜,要么更長,需要具有強大推理能力的模型來準確地解釋和分割目標對象。 |
2.3. MLLMs for Segmentation
| Since LISA [17, 41] introduced the ’ ’ token to bridge the gap between MLLMs and segmentation models, several subsequent works [3, 7, 32] have explored the use of MLLMs for segmentation tasks. Most of these approaches, including OneTokenSegAll [3] and PixelLM [32], follow LISA’s paradigm by using special tokens to connect MLLMs with segmentation models. However, this design necessitates extensive data to fine-tune both the MLLM and the segmentation decoder, and may even compromise the pixel precious of the original segmentation models. Our proposed Seg-Zero also employs a decoupled design for ease of adoption, while further leveraging the reasoning ability of MLLMs to achieve superior results. | 自從 LISA [17, 41] 引入“ ”標記來連接 MLLM 和分割模型以來,后續的一些研究 [3, 7, 32] 也探索了 MLLM 在分割任務中的應用。大多數方法,包括 OneTokenSegAll [3] 和 PixelLM [32],都遵循 LISA 的范式,使用特殊標記連接 MLLM 和分割模型。然而,這種設計需要大量數據來微調 MLLM 和分割解碼器,甚至可能損害原始分割模型的像素精度。我們提出的 Seg-Zero 也采用了解耦設計,以便于應用,同時進一步利用 MLLM 的推理能力來獲得更優的結果。 |
3. Method
| In this section, we introduce our Seg-Zero model and the associated reinforcement learning framework. We first describe how we address the segmentation problem in Section 3.1. Next, we present the architecture of the Seg-Zero in Section 3.2. Finally, we describe the reward functions (Section 3.3) and the training details (Section 3.4) in the reinforcement learning framework. | 在本節中,我們將介紹我們的 Seg-Zero 模型及其相關的強化學習框架。首先,我們將在第 3.1 節中描述如何解決分割問題。接下來,我們將在第 3.2 節中介紹 Seg-Zero 的架構。最后,我們將描述強化學習框架中的獎勵函數(第 3.3 節)和訓練細節(第 3.4 節)。 |
3.1. Pipeline Formulation
| Given an image III and a label TTT , the segmentation task aims to produce a binary segmentation mask MMM that accurately identifies the region corresponding to TTT. The label TTT can vary in complexity, ranging from a simple class label (e.g., “bird”), to a straightforward phrase (e.g., “woman in blue”), or even to long and intricate expressions (e.g., “The unusual thing in the image”). The latter two types of expression require the model to perform reasoning to accurately segment the most relevant objects. | 給定圖像 III 和標簽 TTT,分割任務旨在生成一個二值分割掩碼 MMM,以準確識別與 TTT 對應的區域。標簽 T 的復雜程度各不相同,從簡單的類別標簽(例如“鳥”)到簡單的短語(例如“穿藍衣服的女人”),甚至到冗長復雜的表達(例如“圖像中不尋常的東西”)。后兩種表達方式需要模型進行推理,以準確分割出最相關的對象。 |
| Inspired by recent advancements in the reasoning capabilities of large models [11, 34, 36], we leverage this ability to develop a pipeline for reasoning-based segmentation. Specifically, we decouple the reasoning process and the segmentation process. We first employ reinforcement learning to an MLLM to activate its reasoning ability, enabling it to generate the reasoning process and produce accurate bounding box BBB and two points P1P_1P1?, P2P_2P2? that best localize the target object. These bounding box and points are then used as prompts for SOTA segmentation models [14, 30] to produce fine-grained segmentation masks. Seg-Zero is trained using reinforcement learning, as illustrated in Figure 2. | 受大型模型推理能力近期進展的啟發 [11, 34, 36],我們利用這一能力開發了一套基于推理的分割流程。具體而言,我們將推理過程與分割過程解耦。首先,我們將強化學習應用于多模態學習模型 (MLLM),以激活其推理能力,使其能夠生成推理過程并生成精確的邊界框 BBB 以及兩個點 P1P_1P1? 和 P2P_2P2?,從而最佳地定位目標對象。然后,這些邊界框和點將作為 SOTA 分割模型 [14, 30] 的提示,以生成細粒度的分割蒙版。Seg-Zero 采用強化學習進行訓練,如圖 2 所示。 |

Figure 2. Illustration of our RL training process. In this case, the model generates three samples by itself, calculates the rewards, and optimizes towards samples that achieve higher rewards.
圖 2. 我們的 RL 訓練過程說明。在本例中,模型自行生成三個樣本,計算獎勵,并針對獲得更高獎勵的樣本進行優化。
3.2. Seg-Zero Model
| Current MLLMs [2, 18, 24, 40, 45] exhibit impressive performance in processing multi-modal inputs but are unable to generate fine-grained segmentation masks. Conversely, modern segmentation models [14, 30] provide fine-grained segmentation ability but lack robust reasoning capabilities. To bridge this gap, we propose Seg-Zero, a framework that includes a reasoning model and a segmentation model. Additionally, we introduce the novel strategy to effectively activate the reasoning ability of MLLM within the framework. Its whole architecture is shown in Figure 3. | 當前的MLLM [2, 18, 24, 40, 45] 在處理多模態輸入方面表現出色,但無法生成細粒度的分割掩模。相反,現代分割模型 [14, 30] 提供了細粒度的分割能力,但缺乏魯棒的推理能力。為了彌補這一差距,我們提出了 Seg-Zero,一個包含推理模型和分割模型的框架。此外,我們引入了一種新穎的策略,可以在框架內有效激活MLLM的推理能力。其整體架構如圖3所示。 |
| Reasoning Model. We employ Qwen2.5-VL [2] as our reasoning model FreasonF_{reason}Freason?. Although Qwen2.5-VL demonstrates exceptional performance in object detection by predicting the bbox, this region-level bbox is insufficient to provide more fine-grained pixel-level localization. Unlike object detection, segmentation requires a more precise understanding of pixel-level details, as multiple objects may exist within a single bounding box. Therefore, in addition to the bounding box, we also incorporate points that lie within the target object to improve localization accuracy. During the reinforcement learning stage, the format rewards are employed to ensure the model generates structured outputs, which are subsequently processed by a postprocessing function GGG to extract the bounding box B and the two points P1P_1P1?, P2P_2P2? . This process can be formulated as follows: | 推理模型。我們采用 Qwen2.5-VL [2] 作為我們的推理模型 FreasonF_{reason}Freason?。盡管 Qwen2.5-VL 通過預測邊界框在目標檢測中表現出色,但這種區域級邊界框不足以提供更細粒度的像素級定位。與目標檢測不同,分割需要更精確地理解像素級細節,因為單個邊界框內可能存在多個目標。因此,除了邊界框之外,我們還結合了位于目標對象內的點以提高定位精度。在強化學習階段,采用格式獎勵來確保模型生成結構化輸出,隨后由后處理函數 GGG 處理這些輸出以提取邊界框 BBB 和兩個點 P1P_1P1?、P2P_2P2?。該過程可以表述如下: |
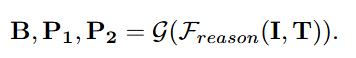 | |
| Segmentation Model. Modern segmentation models [14, 30] accept various types of prompt, including bounding boxes and points, to generate accurate segmentation masks. We employ SAM2 [30] as our segmentation model FsegF_{seg}Fseg? due to its superior performance and efficient inference speed. Leveraging the bounding boxes and points provided by the reasoning model, the segmentation model can generate a precise, fine-grained mask for the target object. This process can be formally expressed as follows: | 分割模型。現代分割模型 [14, 30] 接受各種類型的提示,包括邊界框和點,以生成精確的分割蒙版。我們采用 SAM2 [30] 作為分割模型 FsegF_{seg}Fseg?,因為它性能卓越且推理速度快。利用推理模型提供的邊界框和點,分割模型可以為目標對象生成精確的細粒度蒙版。該過程可以正式表示如下: |
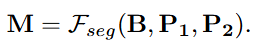 | |
| Test-time Reasoning. Reasoning is the crucial part in reasoning segmentation tasks. Inspired by DeepSeek-R1-Zero, we intentionally avoid using any explicit Chain-of-Thought (CoT) data to teach Seg-Zero reasoning skills. Instead, we aim to activate its reasoning capabilities from zero, enabling the model to autonomously generate a logical CoT before producing the final answer. To achieve this, we design a structured user prompt and a sophisticated reward mechanism to guide the reasoning model toward the correct optimization direction. As shown in Figure 4, the user prompt instructs Seg-Zero to analyze and compare objects in the image, beginning by generating a reasoning process, followed by the final answer in a pre-defined format. The reward mechanism then evaluates the answers and directs the optimization process, as illustrated in Figure 2. | 測試時推理。推理是推理分割任務中的關鍵環節。受 DeepSeek-R1-Zero 的啟發,我們刻意避免使用任何顯式的思路鏈 (CoT) 數據來教授 Seg-Zero 的推理技能。相反,我們的目標是從零開始激活其推理能力,使模型能夠在得出最終答案之前自主生成邏輯思路鏈 (CoT)。為此,我們設計了結構化的用戶提示和完善的獎勵機制,以引導推理模型朝著正確的優化方向發展。如圖 4 所示,用戶提示指示 Seg-Zero 分析和比較圖像中的對象,首先生成推理過程,然后以預定義格式提供最終答案。之后,獎勵機制評估答案并指導優化過程,如圖 2 所示。 |

Figure 3. Seg-Zero includes a reasoning model and a segmentation model. The reasoning model is a MLLM that generates a reasoning chain and provides segmentation prompts. Subsequently the segmentation model produces pixel-wise mask.
圖 3. Seg-Zero 包含一個推理模型和一個分割模型。推理模型是一個 MLLM,它生成推理鏈并提供分割提示。隨后,分割模型生成逐像素掩碼。

" 請使用 bbox 和 points 找出 ’ {Question} '。
“” 比較對象之間的差異,并找出最接近的匹配項。 “”
在 <think> <\think> 中輸出思考過程,在 <answer> <\answer> 標簽中輸出最終答案。
“” 以 JSON 格式輸出感興趣對象內部的一個 bbox 和兩個最大內切圓的中心點。 “” 即 <think> 思考過程在這里 <\think> “” <answer> { ’ bbox ’ : [10,100,200,210], ’ points 1 ’ : [30,110], ’ points 2 ’ : [35,180] } <\answer> "
Figure 4. User prompt for Seg-Zero. ‘{Question}’ is replaced with object description T in the training and inference.
3.3. Reward Functions
| Reward functions play a pivotal role in reinforcement learning, as they determine the optimization directions of the model. We manually design the following five reward functions for reinforcement learning. | 獎勵函數在強化學習中起著至關重要的作用,它決定了模型的優化方向。我們手動設計了以下五個用于強化學習的獎勵函數。 |
| Thinking Format Reward. This reward is designed to force the model engage in a structured thinking process. It guides the model output its reasoning steps within the <think> and </think>tags, and the final answer is included between the <answer> and </answer>tags. | 思考格式獎勵。此獎勵旨在強制模型進行結構化的思考過程。它引導模型在 <think> 和 </think> 標簽內輸出其推理步驟,最終答案則包含在 <answer> 和 </answer> 標簽之間。 |
| Segmentation Format Reward. Different from counting or other QA tasks, the segmentation task is highly dependent on the format of the answer. We provide two types of segmentation format rewards: soft and strict. Under soft constraints, if the keywords bbox and points appear in the answer, and their corresponding values consist of four and two coordinates, respectively, the format is considered correct. Under strict constraints, the format is only considered correct if the model outputs exact keywords (e.g., bbox,points 1, points 2) in the required structure. | 分割格式獎勵。與計數或其他問答任務不同,分割任務高度依賴于答案的格式。我們提供兩種類型的分割格式獎勵:軟約束和嚴格約束。在軟約束下,如果關鍵詞 bbox 和 points 出現在答案中,并且它們對應的值分別由四個和兩個坐標組成,則格式被認為是正確的。在嚴格約束下,只有當模型輸出符合要求結構的精確關鍵詞(例如,bbox,points 1, points 2)時,格式才被認為是正確的。 |
| Bbox IoU Reward. This reward evaluates the IoU between the predicted bbox and the ground-truth bbox. A reward of 1 is assigned if their IoU greater than 0.5; otherwise, the reward is 0. | 邊界框 IoU 獎勵。此獎勵評估預測邊界框與真實邊界框之間的 IoU。如果 IoU 大于 0.5,則獎勵為 1;否則,獎勵為 0。 |
| Bbox L1 Reward. This reward evaluates the L1 distance between the predicted bbox and the ground-truth bbox. A reward of 1 is assigned if their L1 distance less than 10 pixels; otherwise, the reward is 0. | 邊界框 L1 獎勵。此獎勵評估預測邊界框與真實邊界框之間的 L1 距離。如果 L1 距離小于 10 像素,則獎勵為 1;否則,獎勵為 0。 |
| Point L1 Reward. This reward evaluates the L1 distance between the predicted points and the ground-truth points. We first determine whether the predicted points are inside the bounding box. Then the reward is set to 1 if the minimal distance between the predicted points and the ground-truth points is less than 100 pixels; otherwise, the reward is 0. | 點 L1 獎勵。此獎勵評估預測點與真實點之間的 L1 距離。我們首先判斷預測點是否位于邊界框內。如果預測點與真實點之間的最小距離小于 100 像素,則獎勵為 1;否則,獎勵為 0。 |
3.4. Training
| We build the training data from publicly available segmentation datasets and train our Seg-Zero using the GRPO algorithm. | 我們從公開可用的分割數據集構建訓練數據,并使用 GRPO 算法訓練我們的 Seg-Zero。 |
| Data Preparation. The training data is generated using the original mask annotations from existing referring expression segmentation datasets (e.g., RefCOCOg [43]). Based on the mask, we extract the leftmost, topmost, rightmost, and bottommost pixels of the mask to generate the bounding box B. Additionally, we compute the center points of the two largest inscribe circles within the mask, denoted as P1P1P1 and P2P2P2 . Consequently, the ground truth data comprises the bbox coordinates [Bx1,By1,Bx2,By2][B_{x1}, B_{y1}, B_{x2}, B_{y2}][Bx1?,By1?,Bx2?,By2?] and the coordinates of the two center points [P1x,P1y][P_{1x}, P_{1y} ][P1x?,P1y?] and [P2x,P2y][P_{2x}, P_{2y} ][P2x?,P2y?]. We do not incorporate any CoT processing into the training data. To ensure consistency, all images are rescaled to a uniform resolution of 840x840 pixels. | 數據準備。訓練數據使用現有referring expression分割數據集(例如 RefCOCOg [43])中的原始掩碼注釋生成。基于掩碼,我們提取掩碼最左、最上、最右和最下的像素,以生成邊界框 BBB。此外,我們計算掩碼內兩個最大內切圓的中心點,分別記為 P1P_1P1? 和 P2P_2P2?。因此,ground truth 數據包含邊界框坐標 [Bx1,By1,Bx2,By2][B_{x1}, B_{y1}, B_{x2}, B_{y2}][Bx1?,By1?,Bx2?,By2?] 以及兩個中心點 [P1x,P1y][P_{1x}, P_{1y} ][P1x?,P1y?] 和 [P2x,P2y][P_{2x}, P_{2y} ][P2x?,P2y?] 的坐標。我們沒有在訓練數據中加入任何 CoT 處理。為了確保一致性,所有圖像都重新縮放為 840x840 像素的統一分辨率。 |
| GRPO. We do not include any reasoning data for a coldstart training process to teach the model’s reasoning ability. Instead, we let our Seg-Zero evolve from zero. Specifically, we initiate training directly from the pre-trained Qwen2.5-VL-3B model, utilizing the aforementioned rewards and applying the GRPO algorithm [34]. We illustrate our RL training process in Figure 2. | GRPO。我們沒有在冷啟動訓練過程中包含任何推理數據來訓練模型的推理能力。相反,我們讓 Seg-Zero 從零開始演化。具體來說,我們直接從預訓練的 Qwen2.5-VL-3B 模型開始訓練,利用前面提到的獎勵并應用 GRPO 算法 [34]。圖 2 展示了我們的強化學習訓練流程。 |
4. Experiment
4.1. Experimental Settings
| Datasets. We training our Seg-Zero with only 9,000 samples adopted from RefCOCOg, using the data preparation strategy mentioned in Section 3.4. The test data includes ReasonSeg [17] and RefCOCO(+/g) [43]. | 數據集。我們僅使用來自 RefCOCOg 的 9,000 個樣本來訓練 Seg-Zero,并使用 3.4 節中提到的數據準備策略。測試數據包括 ReasonSeg [17] 和 RefCOCO(+/g) [43]。 |
| Implementation Details. We employ Qwen2.5-VL-3B [2] and SAM2-Large [30] as our default reasoning model and segmentation model, respectively. Seg-Zero is trained using the DeepSpeed [29] library. During training, we use a total batch size of 16 with a sampling number of 8 per training step. The initial learning rate is set to 1e-6 and the weight decay is 0.01. | 實施細節。我們分別采用 Qwen2.5-VL-3B [2] 和 SAM2-Large [30] 作為默認推理模型和分割模型。Seg-Zero 使用 DeepSpeed [29] 庫進行訓練。訓練期間,我們使用的總批次大小為 16,每個訓練步驟的采樣數為 8。初始學習率設置為 1e-6,權重衰減為 0.01。 |
| Evaluation Metrics. Following previous works [13, 43], we calculate gIoU and cIoU. The gIoU is the average of all per-image Intersection-over-Unions (IoUs), while the cIoU calculates the cumulative intersection over the cumulative union. Unless specified, we use gIoU as our default metric, as it equally considers both large and small objects. | 評估指標。參照先前的研究 [13, 43],我們計算 gIoU 和 cIoU。gIoU 是每幅圖像所有 IoU 的平均值,而 cIoU 計算的是累積交集除以累積并集。除非另有說明,否則我們使用 gIoU 作為默認指標,因為它能夠同時考慮大目標和小目標。 |
4.2. SFT vs. RL
| We compare the performance of SFT and RL. The baseline model is Qwen2.5-VL-3B + SAM2-Large. For the nonCoT setting, we eliminate the thinking format reward, thus the model does not generate a CoT reasoning process before outputting the final answer. Our comparison includes both in-domain and OOD segmentation tasks [26, 35], as well as general QA tasks. The corresponding results are shown in Table 1, Figure 1 and Figure 5. | 我們比較了 SFT 和 RL 的性能。基線模型是 Qwen2.5-VL-3B + SAM2-Large。對于非 CoT 設置,我們消除了思維格式獎勵,因此模型在輸出最終答案之前不會生成 CoT 推理過程。我們的比較涵蓋了領域內和面向對象 (OOD) 分割任務 [26, 35],以及通用問答任務。相應結果如表 1、圖 1 和圖 5 所示。 |
| SFT vs. RL without CoT. From the first two rows in Table 1, we observe that on the in-domain dataset RefCOCOg, SFT achieves nearly the same performance as the baseline model. This may be due to the strong baseline performance of the original Qwen2.5-VL-3B. However, its performance significantly declines on the OOD ReasonSeg dataset, suggesting that SFT negatively impacts the model’s generalization ability. In contrast, comparing the first and third rows, we find that RL consistently improves performance on both in-domain and OOD datasets, demonstrating the effectiveness of RL. Besides, from Figure 5, we observe that the SFT model suffers from catastrophic forgetting of its original visual QA ability, while the RL model effectively preserves this capability. | SFT 與不使用 CoT 的 RL。從表 1 的前兩行可以看出,在領域內數據集 RefCOCOg 上,SFT 取得了與基線模型幾乎相同的性能。這可能是由于原始 Qwen2.5-VL-3B 的強勁基線性能。然而,其在 OOD ReasonSeg 數據集上的性能顯著下降,這表明 SFT 對模型的泛化能力產生了負面影響。相比之下,比較第一行和第三行,我們發現 RL 在領域內數據集和 OOD 數據集上的性能均持續提升,證明了 RL 的有效性。此外,從圖 5 中我們觀察到,SFT 模型遭受了其原有視覺問答能力的災難性遺忘,而 RL 模型則有效地保留了這種能力。 |
| RL without CoT vs. RL with CoT. From the last two rows in Table 1, we find that both RL and RL with CoT achieve superior performance on both the in-domain RefCOCOg and OOD ReasonSeg datasets, significantly outperforming the baseline. This indicates that RL effectively boosts the models’ capabilities. However, with CoT, our Seg-Zero demonstrates even better performance compared to its counterparts without CoT, indicating that the reasoning process enhances the model’s ability to handle OOD data samples. From Figure 5, it is noteworthy that the introduction of CoT reasoning leads to a slight performance improvement in visual QA tasks for models trained without CoT. | 不帶 CoT 的強化學習 vs. 帶 CoT 的強化學習。從表 1 的最后兩行可以看出,強化學習和帶 CoT 的強化學習在領域內 RefCOCOg 和 OOD ReasonSeg 數據集上均取得了優異的性能,顯著超越了基線。這表明強化學習有效地提升了模型的性能。然而,在引入 CoT 后,我們的 Seg-Zero 的表現甚至優于不帶 CoT 的同類模型,這表明推理過程增強了模型處理 OOD 數據樣本的能力。從圖 5 可以看出,值得注意的是,對于未使用 CoT 訓練的模型,引入 CoT 推理后,其在視覺問答任務上的性能略有提升。 |

4.3. Ablation Study
| We conduct several ablation studies to verify the effectiveness of our design. For the ablation study, the default settings are as follows: we perform reinforcement learning using the GRPO algorithm on 9,000 samples and evaluate the model on the RefCOCOg test and the ReasonSeg test. | 我們進行了多項消融研究來驗證設計的有效性。消融研究的默認設置如下:我們使用 GRPO 算法對 9,000 個樣本進行強化學習,并在 RefCOCOg 測試和 ReasonSeg 測試上對模型進行評估。 |
| Design of Bbox and Points. Table 2 demonstrates the effectiveness of our bbox and points prompt design. We observe that using only point prompts results in worst performance. When both bbox and point prompts are utilized, Seg-Zero achieves its best performance, indicating that the combination of these prompts enhances pixel-level localization accuracy. | 邊界框和點的設計。表 2 展示了我們邊界框和點提示設計的有效性。我們觀察到,僅使用點提示會導致性能最差。當同時使用邊界框和點提示時,Seg-Zero 的性能最佳,這表明這些提示的組合可以提高像素級定位精度。 |
| KL Loss Coefficient. The KL loss coefficient balances the model’s ‘pre-existing knowledge’ with ‘new knowledge’. Table 3 presents the performance variations across different KL loss coefficients. We find that a coefficient of 5e-3 performs optimally on both in-domain and OOD data. A higher coefficient leads to performance degradation. | KL 損失系數。KL 損失系數平衡了模型的“既有知識”和“新知識”。表 3 展示了不同 KL 損失系數下的性能變化。我們發現,當系數為 5e-3 時,無論是在領域內數據還是 OOD 數據上,其性能都達到最佳。系數過高會導致性能下降。 |
| Number of Samples. We investigate the impact of the number of samples during the sampling stage. As shown in Table 4, we observe that as the number of samples increases, the model achieves better performance on both in-domain and out-of-distribution (OOD) data. This is reasonable because a larger number of samples expands the exploration space, enabling the model to identify more effective optimization directions. | 樣本數量。我們研究了采樣階段樣本數量的影響。如表 4 所示,我們觀察到,隨著樣本數量的增加,模型在域內和分布外 (OOD) 數據上都取得了更好的性能。這是合理的,因為更大的樣本數量擴展了探索空間,使模型能夠識別更有效的優化方向。 |
| User Prompt Sensitivity. The last two rows of Figure 4 show that we include output examples in the user prompt. We investigate the impact of this example in Table 5 and observe that its inclusion significantly enhances the model’s performance. Through analysis of the output, we find that models without this example often fail to generate a reasoning process in their responses. | 用戶提示敏感度。圖 4 的最后兩行表明我們在用戶提示中包含了輸出示例。我們在表 5 中研究了此示例的影響,并觀察到其加入顯著提升了模型的性能。通過對輸出的分析,我們發現,沒有此示例的模型通常無法在其響應中生成推理過程。 |
| Soft vs. Hard Accuracy Rewards. In Section 3.3, we describe the bbox IoU reward, the bbox L1 reward, and the point L1 reward. We apply specific thresholds to convert these metrics into binary rewards. Additionally, we conduct ablation studies on soft counterparts. For the bbox IoU reward, we directly use the IoU value as the soft reward. For L1-based rewards, we define the soft reward as 1?L1distmax{imagesize}1?\frac{L1 dist}{max\{image size\}}1?max{imagesize}L1dist?. From Table 6, we observe that while the soft reward achieves a minor improvement on ReasonSeg, it significantly underperforms compared to the hard reward on RefCOCOg. | 軟獎勵 vs. 硬獎勵。在第 3.3 節中,我們描述了 bbox IoU 獎勵、bbox L1 獎勵和點 L1 獎勵。我們應用特定閾值將這些指標轉換為二元獎勵。此外,我們還對軟獎勵進行了消融研究。對于 bbox IoU 獎勵,我們直接使用 IoU 值作為軟獎勵。對于基于 L1 的獎勵,我們將軟獎勵定義為 1?L1distmax{imagesize}1?\frac{L1 dist}{max\{image size\}}1?max{imagesize}L1dist?。從表 6 中我們觀察到,雖然軟獎勵在 ReasonSeg 上取得了微小的改進,但與 RefCOCOg 上的硬獎勵相比,其表現明顯不佳。 |
| Soft vs. Strict Format Rewards. In Section 3.3, we introduce two types of segmentation format rewards: the soft and strict. From Table 7, we find that the strict format reward significantly improves performance gain on OOD data in ReasonSeg. Through qualitative analysis of the training steps, we find that the strict format reward progresses slowly in the initial stages, as it is more challenging to sample formats that precisely match the strict criteria. However, as training step increases, model with strict format reward tend to output longer response. | 軟格式獎勵 vs. 嚴格格式獎勵。在第 3.3 節中,我們介紹了兩種分割格式獎勵:軟格式獎勵和嚴格格式獎勵。從表 7 可以看出,嚴格格式獎勵顯著提升了 ReasonSeg 在 OOD 數據上的性能。通過對訓練步驟的定性分析,我們發現嚴格格式獎勵在初始階段進展緩慢,因為采樣完全符合嚴格標準的格式更具挑戰性。然而,隨著訓練步驟的增加,具有嚴格格式獎勵的模型往往會輸出更長的響應。 |
| Reasoning Model Scale. We conduct an ablation study on reasoning models of varying scales, ranging from 2B to 7B parameters, under the same rewards and training settings. As shown in Table 8, we observe that model performance on both in-domain and OOD data improves as the model scale increases. | 推理模型規模。在相同的獎勵和訓練設置下,我們對不同規模(參數范圍從 2B 到 7B)的推理模型進行了消融研究。如表 8 所示,我們觀察到,隨著模型規模的增加,模型在領域內數據和 OOD 數據上的性能均有所提升。 |
| Changes in Completion Length. Figure 6 illustrates the trends in completion lengths between different model sizes.The results indicate that a larger model tends to generate longer responses. As training progresses, the minimal completion length gradually increases. However, there is a drop in average completion length during the initial few steps. By analyzing the output during the training process, we find that this occurs because the model initially prioritizes learning the correct output format, which often results in shorter responses. Once the format reward saturates, the model shifts its focus to generating answer with higher accuracy, leading to longer and more detailed responses. Supplementary materials provide more analysis. | 完成長度的變化。圖 6 展示了不同模型大小之間完成長度的趨勢。結果表明,較大的模型往往會生成更長的響應。隨著訓練的進行,最小完成長度逐漸增加。然而,在最初的幾個步驟中,平均完成長度有所下降。通過分析訓練過程中的輸出,我們發現這是因為模型最初優先學習正確的輸出格式,這通常會導致響應較短。一旦格式獎勵達到飽和,模型就會將重點轉移到生成更準確率的答案,從而產生更長、更詳細的響應。補充材料提供了更多分析。 |


4.4. Comparison with Other Methods
| In this part, we train our Seg-Zero using hard accuracy rewards and strict format rewards. The sampling number is set to 16. And we only train our Seg-Zero on 9,000 samples from RefCOCOg. We compare OVSeg [19], Grounded-SAM [31], LISA [17], SAM4MLLM [7], LAVT [42], ReLA [22], PixelLM [32], PerceptionGPT [28]. | 在本部分中,我們使用硬精度獎勵和嚴格格式獎勵來訓練 Seg-Zero。樣本數量設置為 16。我們僅使用來自 RefCOCOg 的 9,000 個樣本來訓練 Seg-Zero。我們比較了 OVSeg [19]、Grounded-SAM [31]、LISA [17]、SAM4MLLM [7]、LAVT [42]、ReLA [22]、PixelLM [32] 和 PerceptionGPT [28]。 |
| Reasoning Segmentation. We compare the zero-shot performance on ReasonSeg [17], results are shown in Table 9. We can find our Seg-Zero achieves the SOTA zero-shot performance across various methods. | 推理分割。我們比較了 ReasonSeg [17] 上的零樣本性能,結果如表 9 所示。我們發現,我們的 Seg-Zero 在各種方法中都實現了 SOTA 零樣本性能。 |
| Referring Expression Segmentation. The results on referring expression segmentation are shown on Table 10. Moreover, we find that the ground-truth annotations in RefCOCO(+/g) are not precise enough, which suggests that our Seg-Zero model should, in principle, achieve better performance than values in the table. Supplementary materialsprovide detailed analysis. | 指稱表情分割。指稱表情分割的結果如表 10 所示。此外,我們發現 RefCOCO(+/g) 中的真實標注不夠精確,這表明我們的 Seg-Zero 模型原則上應該能夠取得比表中數值更好的性能。補充材料提供了詳細的分析。 |


4.5. Qualitative Results
| We provide several examples in Figure 7. We can easily observe that the reasoning process is helpful in analyzing user instructions, especially when there are multiple objects within the same class categories. For instance, Seg-Zero demonstrates its ability to discern that a ‘recreational vehicle’ is more appropriate than a ‘truck’ in the context of a ‘road trip’, and correctly identifies that a ‘conductor’ is ‘positioned at the front of the stage’. | 我們在圖 7 中提供了幾個示例。我們可以很容易地觀察到,推理過程在分析用戶指令方面非常有效,尤其是在同一類別中有多個對象的情況下。例如,Seg-Zero 展示了其在“公路旅行”語境中辨別“休閑車”比“卡車”更合適的能力,并正確識別出“售票員”位于“舞臺前方”。 |

5. Conclusion
| In this paper, we propose Seg-Zero, a novel framework that integrates the CoT reasoning process into segmentation tasks. We design a sophisticated reward mechanism, incorporating both format and accuracy constraints, to guide the optimization directions. By training exclusively with RL, Seg-Zero emerges reasoning capabilities without relying on any supervised reasoning data. We present a detailed comparison between SFT and RL, as well as the introduction of reason chain. Additionally, we offer insightful perspectives on the design of RL and the reward functions. | 在本文中,我們提出了一個新穎的框架 Seg-Zero,它將 CoT 推理過程集成到分割任務中。我們設計了一個復雜的獎勵機制,結合了格式和準確度約束,以指導優化方向。通過專門使用強化學習進行訓練,Seg-Zero 無需依賴任何監督推理數據即可展現推理能力。我們對 SFT 和強化學習進行了詳細的比較,并引入了推理鏈。此外,我們還對強化學習和獎勵函數的設計提出了深刻的見解。 |



Yolo V8神經網絡的基礎應用)

)
-----目標檢測和圖像分類、語義分割的區別)

:k8s環境使用helm部署Seaweedfs集群)
)

如何實現)

的三種文件組織形式,工程文件,自由文件與存盤文件)

)



