Java集合框架
- 1、List、Set、Map的區別
- 2、ArrayList、LinkedList、Vector區別
- 3、為什么數組索引從0開始,而不是從1開始?
- 4、ArrayList底層的實現原理
- 5、紅黑樹、散列表
- 6、HashMap的底層原理
- 7、HashMap的put方法具體流程
- 8、HashMap的擴容機制
- 9、HashMap是怎么解決哈希沖突?
- 10、HashMap尋址算法
- 11、HashMap在1.7下的多線程死循環問題
- 12、HashMap、Hashtable、LinkedHashMap、TreeMap、ConcurrentSkipListMap選擇
- 13、CocurrentHashMap底層原理
- 14、CopyOnWriteArrayList
- 15、
1、List、Set、Map的區別

2、ArrayList、LinkedList、Vector區別
- ArrayList基于動態數組實現,LinkedList基于雙向鏈表實現
- ArrayList比LinkedList在隨機訪問時效率要更高,因為LinkedList是鏈表存儲,要移動指針從前往后尋找。
- 在非首尾的增刪操作時,LinkedList要比ArrayList效率高,因為ArrayList增刪數據要先將插入或刪除的后續元素后依次向后或向前移動。
- ArrayList和Vector的迭代器實現都是fail-fast的,兩者允許null值,也可以使用索引值對元素進行隨機訪問。兩者都是基于索引的,內部由一個數組支持,即都維護插入的順序,可以根據插入順序來獲取元素。
- ArrayList是非線程安全的,Vector是線程安全的,ArrayList比Vector快,但一般需要保證線程安全可使用CopyOnWriteArrayList.來代替Vector。

3、為什么數組索引從0開始,而不是從1開始?
- 在根據數組索引獲取元素的時候,會用索引和尋址公式來計算內存所對應的元素數據,尋址公式:數組的首地址 + 索引*存儲數據的類型大小。
- 如果數組的索引從1開始,尋址公式中,就需要增加一次減法操作,對于CPU來說就多了一次指令,性能不高。
4、ArrayList底層的實現原理
- ArrayList底層是用動態數組實現的
- ArrayList初始容量為0,當第一次添加數據的時候才會初始化容量為10
- ArrayList在進行擴容的時候是按原來的1.5倍,每次擴容都需要拷貝數組
- ArrayList在添加數據時
1)確保數組已使用長度加1之后足夠存下下一個數據
2)計算數組的容量,如果當前數組已使用長度+ 1后大于當前的數組長度,則會調用擴容方法,擴大為原來的1.5倍
3)確保新增的數據有地方存儲之后,則將新元素添加到位于size的位置上。
4)返回是否添加成功
ArrayList list = new ArrayList(10)中list擴容幾次:
- 該語句只是聲明和實例了一個ArrayList對象,指定了初始容量為10,未擴容
數組與ArrayList之間的轉換:
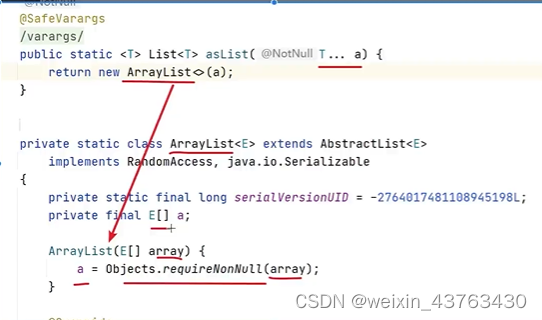
- 可以使用Arrays.asList()來將數組轉換成List,使用List中的toArray方法轉成數組
- 使用Arrays.asList()來將數組轉換成List后,如果改變原數組的數據,list的數組也會隨之改變,因為asList的底層使用的是Arrays類中的一個內部類ArrayList來構造的集合,在這個集合的構造器中,把我們傳入的這個集合進行了包裝,最終指向的都是同一個內存地址。
- list用toArray轉數組后,如果修改了list內容,數組不會影響,當調用了toArray以后,在底層是進行了數組的拷貝,跟原來的數組沒關系了。
5、紅黑樹、散列表
-
紅黑樹:
紅黑樹是一種自平衡的二叉搜索樹(BST);
所有的紅黑規則都是希望紅黑樹能夠保證平衡;
紅黑樹的時間復雜度:查找、添加、刪除都是O(logn) -
紅黑樹的性質:
1)節點要么是紅色、要么是黑色
2)根節點是黑色
3)葉子節點都是黑色的空節點
4)紅黑樹中紅色節點的子節點都是黑色
5)從任一節點到葉子節點的所有路徑都包含相同數目的黑色節點 -
散列表:
散列表又稱哈希表,是根據鍵直接訪問在內存存儲位置值的數據結構,是由數組演化而來的,利用了數組支持按照下標進行隨機訪問的特性。
在散列表中,數組的每個下標位置我們可以稱之為桶或槽,每個桶會對應一條鏈表,所有散列值相同的元素我們都放到相同槽位對應的鏈表中。
6、HashMap的底層原理
- HashMap底層使用hash表數據結構,即數組+鏈表+紅黑樹實現的。添加數據時,計算key的值確定元素在數組中的下標,key相同則替換,不同則存入鏈表或紅黑樹中。

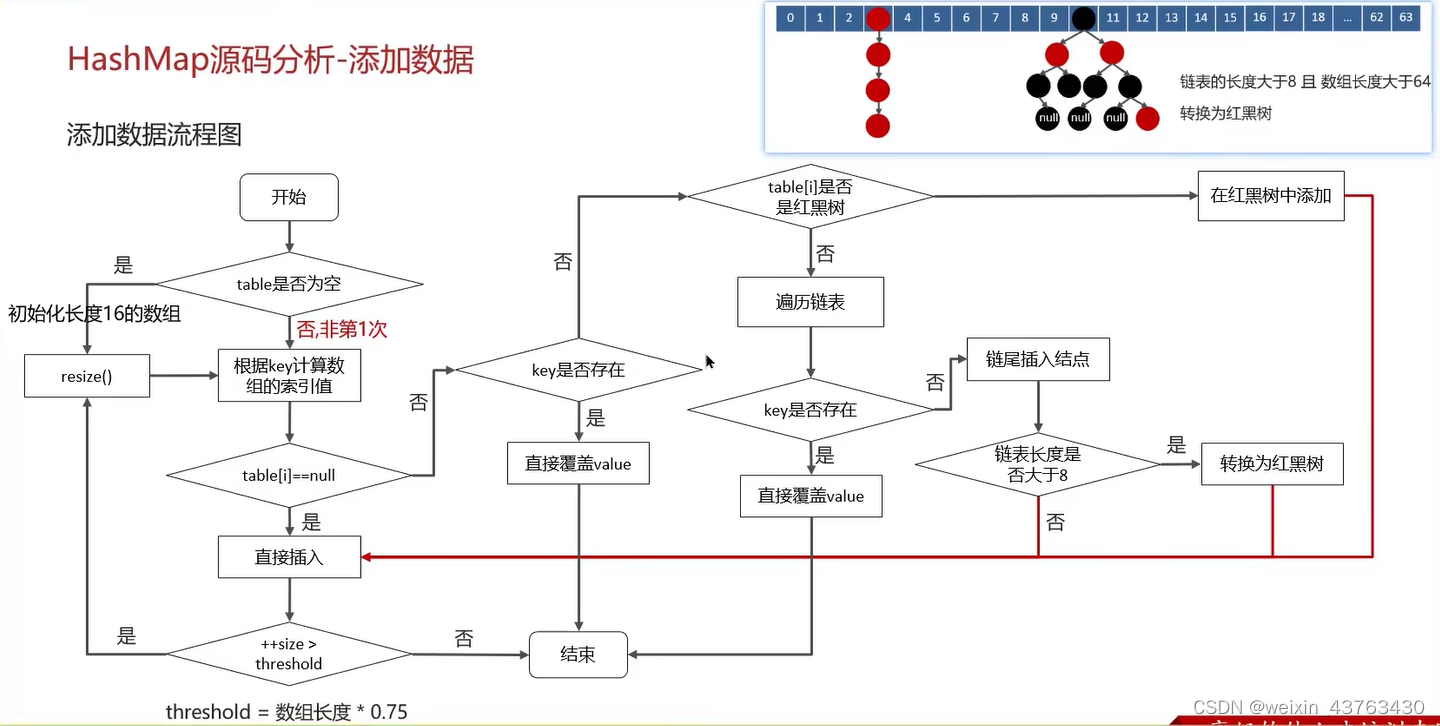
7、HashMap的put方法具體流程
- 判斷鍵值對數據table是否為空或null,否則執行resize()進行擴容(初始化)
- 根據鍵值key計算hash值得到數組索引
- 判斷table[i] 是否等于null,如果元素為空,則直接新建節點添加
- 如果table[i]元素不為空,則分情況討論:
1)判斷table[i]的首個元素是否和key一樣,如果相同直接覆蓋value
2)判斷table[i]是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對
3)遍歷table[i],鏈表的尾部插入數據,然后判斷鏈表長度是否大于8,大于8的話把鏈表轉換為紅黑樹,在紅黑樹中執行插入操作,遍歷過程中若發現key已經存在直接覆蓋value。 - 插入成功后,判斷實際存在的鍵值對數量size是否超過了最大容量threshold(數組長度*0.75),如果超過,進行擴容。

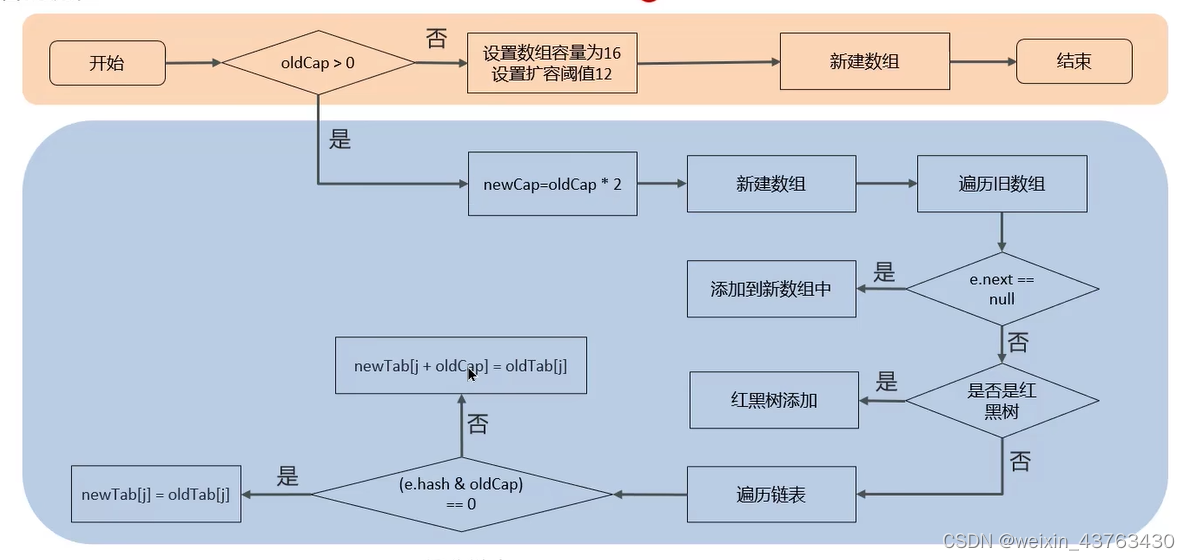
8、HashMap的擴容機制
- 在添加元素或初始化的時候需要調用resize方法進行擴容,第一次添加數據初始化數組長度為16,以后每次擴容都是達到了擴容閾值(數組長度*0.75)
- 每次擴容時,都是擴容之前容量的2倍;
- 擴容之后,會新創建一個數組,需要把老數組中的數據挪動到新的數組中
1)沒有hash - 沖突的節點,則直接計算新數組的索引位置(e.hash & (newCap - 1))
- 如果是紅黑樹,走紅黑樹的添加
- 如果是鏈表,則需要遍歷鏈表,可能需要拆分鏈表,判斷(e.hash & newCap)是否為0,該元素要么停留在原始位置,要么移動到原址位置+增加的數組大小這個位置上。

9、HashMap是怎么解決哈希沖突?

10、HashMap尋址算法
- 計算對象的hashCode值,再進行調用hash()方法進行二次哈希,hashcode值右移16位再異或運算,讓哈希分布更均勻,最后(capacity - 1) & hash 得到索引。
- HashMap的數組長度為什么一定是2的次冪?
1)計算索引時效率更高:如果是2的n次冪可以使用位與運算代替取模
2)擴容時重新計算索引效率更高:hash & oldCap == 0 的元素留在原來位置,否則新位置= 舊位置 + oldCap
11、HashMap在1.7下的多線程死循環問題
- 在jdk1.7的HashMap中在數組進行擴容的時候,因為鏈表是頭插法,在進行數據遷移的過程中,有可能導致死循環。
如:有兩個線程:
線程一:讀到當前的HashMap數據,數據中一個鏈表,在準備擴容時,線程二介入。
線程二:也讀取HashMap,直接進行擴容。因為是頭插法,鏈表的順序會進行顛倒過來,比如原來的順序是AB,擴容后的順序變成了BA,線程二執行結束。
線程一:繼續執行的時候就會出現死循環問題。
線程一先將A移入新的鏈表,再將B插入到鏈頭,由于另外一個線程的原因,B的next指向了A,所以B->A->B形成循環。當然,jdk8將擴容算法做了調整,不再將元素加入鏈表頭(而是保持與擴容前一樣的順序),尾插法,就避免了jdk7中的死循環問題。
12、HashMap、Hashtable、LinkedHashMap、TreeMap、ConcurrentSkipListMap選擇
- HashMap:沒有鎖機制,非線程安全,但效率比HashTable要高,允許key和value為null。不保證有序性,即遍歷的順序與put順序不一定一致。
- Hashtable:內部方法都是synchronized(同步鎖)修飾的,即線程安全;鍵值只要有一個是null,就出現空指針異常。
- HashMap提供對key的Set進行遍歷,因此它是fail-fast的,但HashTable提供對key的Enumeration進行遍歷,它不支持fail-fast。
- LinkedHashMap:LinkedHashMap保持有序性,遍歷的順序與put順序一致。在]ava1.4中引入了LinkedHashMap,是HashMap的一個子類,假如你想要遍歷順序,你很容易從HashMap轉向LinkedHashMap,但是Hashtable不是這樣的,它的順序是不可預知的。
- TreeMap:實現了SortedMap接口,保證了有序性,默認排序是根據key值進行排序,也可重寫comparator方法根據key進行排序。
- ConcurrentSkipListMap:對于并發環境下的有序 Map 操作,ConcurrentSkipListMap 的性能優于 TreeMap。TreeMap 不是線程安全的,而 ConcurrentSkipListMap 提供了一種線程安全且高并發的有序 Map 實現。
總結:不要求保證有序性,使用HashMap,要求不改變put順序使用LinkedHashMap,根據key排序使用TreeMap。需保證線程安全問題使用CocurrentHashMap。Hashtable是被認為一個遺留類,效率低,一般不使用。既要求線程安全,又要求有序可使用ConcurrentSkipListMap。
13、CocurrentHashMap底層原理
- jdk1.7底層采用分段的數組+鏈表實現。采用Segment分段鎖,底層使用的是ReentrantLock。
- jdk1.8采用的數據結構跟HashMap1.8的結構一樣,數組+鏈表+紅黑樹。采用CAS添加新節點,采用synchronized鎖定鏈表或紅黑二叉樹的首節點,相對Segment分段鎖粒度更細,性能更好。

14、CopyOnWriteArrayList
- 首先CopyOnWriteArrayList內部也是用數組來實現的,線程安全的并發集合,向CopyOnWriteArrayList添加元素時,會復制一個新的數組,寫操作在新數組上進行,讀操作在原數組上進行。并且,寫操作會加鎖,防止出現并發寫入丟失數據的問題,寫操作結束后會把原數組指向新數組,CopyOnWriteArrayList允許在寫操作時來讀取數據,大大提高了讀的性能,因此適合讀多寫少的應用場景,但是CopyOnWriteArrayList會比較占內存,同時可能讀到的數據不是實時更新的數據,所以不適合實時性要求很高的場景




)

![[Python學習篇] Python面向對象——類](http://pic.xiahunao.cn/[Python學習篇] Python面向對象——類)




-動態規劃入門)







