文章目錄
- 前言
- 一、UDP報頭
- 二、UDP校驗和
- 2.1 CRC
- 2.2 md5
前言
學習一個網絡協議,最主要就是學習的報文格式,對于UDP來說,應用層數據到達UDP之后,會給應用層數據報前面加上UDP報頭。
UDP數據報=UDP包頭+載荷
一、UDP報頭
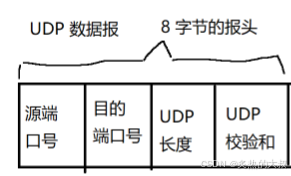
如上圖UDP的報頭主要就分為四個部分,分別占據兩字節的空間。
前兩個源端口號和目的端口號很好理解就是客戶端以及服務器的端口號,用來表示主機上的程序的。第三個UDP長度,因為只占了兩個字節的空間,所以UDP數據包的長度加上包頭最多只能達到64kb的長度,這是很局限的。不禁會想,為什么不把UDP的長度設置的高一點呢?實際上UDP出現的時代很早,那時64kb已經完全滿足通信需求了,只是隨著我們現在網絡的發展才越來越不夠用了。那為什么現在不能夠改一下UDP提高它的長度呢?對于這件事也沒想象中的簡單,單個主機的修改或升級是沒有意義的,需要對端也升級,也就是說要升級全世界得一起升級,這個成本難以想象。并且如果單獨你升級了,和別人通信不了,站在別人的角度就是你那邊除了bug。
二、UDP校驗和
數據在網絡傳輸的過程中是很容易出錯的,我們需要有辦法去對傳輸的數據進行校驗,校驗分為兩層,第一層就是發現是否出錯,第二層就是找到錯誤在哪并且糾錯,這兩層本質上都是要引入額外的冗余信息,但是第二層的代價比較大,在UDP數據報中實現到了第一層,發現是否有錯。
校驗和就是拿著數據進行一系列計算得到結果,如果數據部分發生改變此時得到的結果也就不一樣。在通信過程中就是接收方拿到UDP數據包后計算數據包的校驗和然后和UDP首部的校驗和比較,相同則代表未發生意外,相異則說明數據出了問題。
2.1 CRC
UDP中使用CRC算法(循環冗余校驗)計算校驗和,這種算法首先設定兩個字節的變量,然后把數據報中的每個字節取出來往這個變量上累加,如果結果超出兩個字節,溢出部分就舍棄。
這個方法主要是為了讓數據的每個字節都參與到運算中去都能夠影響結果,最終算的是啥不關鍵,關鍵在于接收方算出的校驗和和發送方算的是否相同。
假設使用一個很大的變量來保存最終總結果,能夠得到精確值,但是也是用來完成相同/不同的比較,具體多少也不關鍵,所以為了節省空間,高位就可以不要了,就留最低兩個字節即可。
2.2 md5
除了CRC之外,還有一個很常用的方法md5,可以作為字符串hash算法。
md5的三個特點:
(1)定長:無論你的輸入是什么,md5的輸出都是定長的字符串。
(2)不可逆:通過原輸入計算md5成本很低,將md5字符串還原成原輸入成本非常高,僅僅理論上可行。
(3)分散:輸入的內容哪怕改變一點點,差異都很大。
 kubectl 常用命令)

)


)
)












