目錄
一、Uniworld-V1
1、概述
2、架構
3、訓練過程
4、實驗
二、X-Omni
1、概述
2、方法
一、Uniworld-V1
1、概述
? ? ? ? 動機:當前統一模型雖然可以實現圖文理解和文本生成任務,但是難以實現圖像感知(檢測/分割)與圖像操控(編輯/遷移)等復合需求。另外傳統方法依賴VAE提取視覺特征,但同樣缺少高頻信息,限制了語義級任務的表現。
? ? ? ? 另外通過實驗發現GPT-4o-Image可能采用語義編碼器,而非VAE,從而導致在編輯實驗中局部修改后文本位置發生偏移,表明缺少底層信息。另外GPT-4o和Qwen2.5-VL,在去噪實驗中,低噪圖像上可以正確去噪,但是高噪圖像上識別出現錯誤。

2、架構
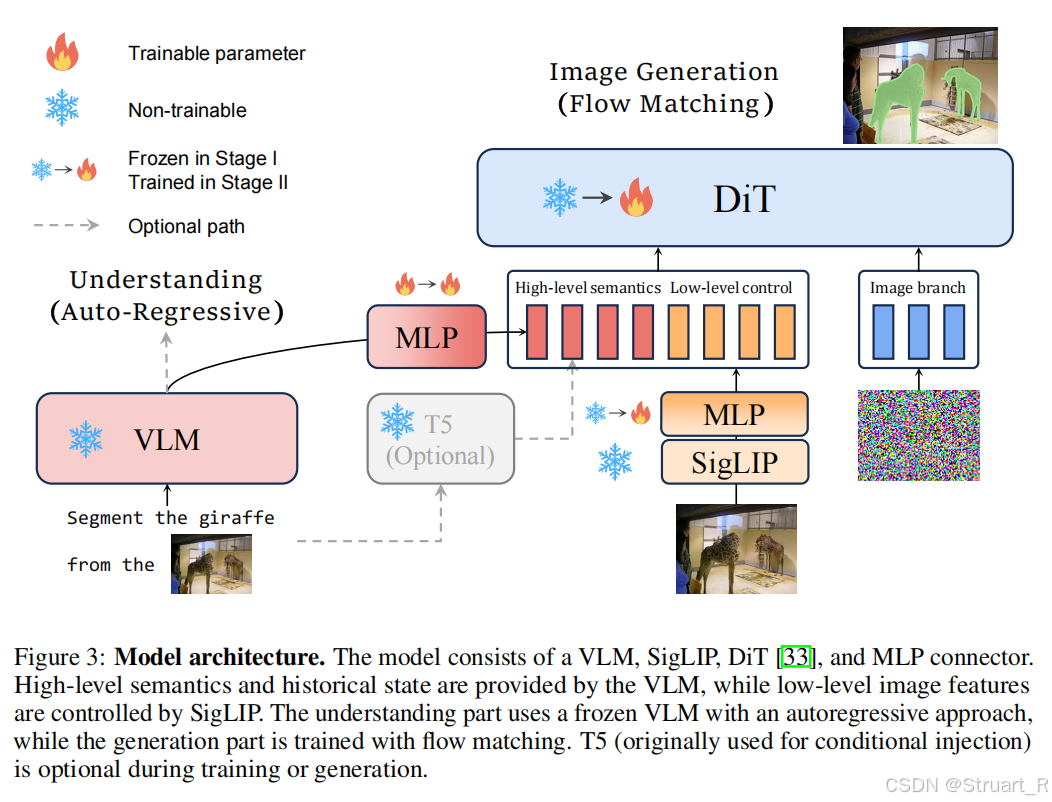
? ? ? ? UniWorld一改以往的理解統一模型均采用一個MLLM架構,通過特征提取,并完全輸入到這個大MLLM中,UniWorld不去訓練理解部分的網絡,并且用理解的輸出去引導圖像的生成。
Visual Encoder
? ? ? ? 采用SigLIP編碼器(SigLIP2-so400m/14,固定輸出512x512)替換以往的VAE編碼器。
VLM
? ? ? ? 使用預訓練的Qwen2.5-VL-7B,并且不再訓練這一部分,只用作視覺理解。
DiT
? ? ? ? 使用FLUX作為DiT的主干,把VLM的視覺tokens輸出經過一個MLP得到High-level semantics特征,Visual Encoder的輸出經過MLP得到Low-level control的特征,將高維語義特征,低維像素特征并且拼接在一起,作為FLUX的文本輸入,因為FLUX是一個文生圖的模型,通過FLUX可以生成特定任務的圖像(比如分割)。
3、訓練過程
? ? ? ? 三階段策略
? ? ? ? Stage1:對齊VLM輸出與DiT文本分支特征空間,不引入SigLIP分支。凍結VLM框架和DiT,只訓練VLM到DiT的MLP部分。
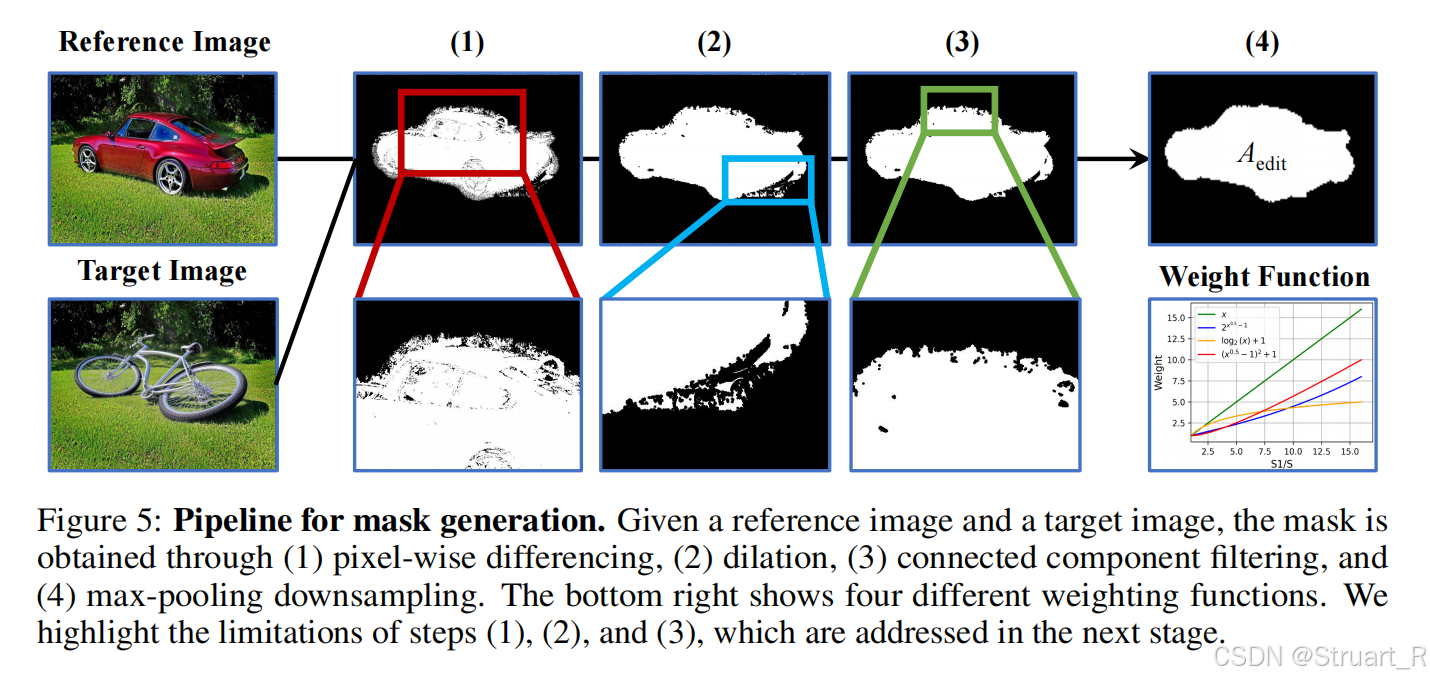
? ? ? ? Stage2:引入預訓練SigLIP特征,加載Stage1的權重,并解凍DiT圖像分支參數,繼續凍結VLM部分。只訓練兩個MLP,和DiT部分。另外引入自適應編輯區域加權策略,解決小編輯區域學習問題,就是區域內存在缺失的問題。
????????自適應編輯區域加權策略,主要是針對編輯區域占比小的情況,采用均勻損失,導致細節丟失,損失加權函數選用對數函數,。對于掩碼生成部分采用像素差分、膨脹、連通域過濾、最大池化下采樣四步來生成掩碼。
????????數據集(2.7M):
(1)圖像感知任務:COCO2017+Graph200K 處理各種圖像風格(Canny HED 深度圖)
(2)圖像操控任務:ImgEdit高質量樣本+SEED-X 處理自適應掩碼生成
(3)文本生成圖像:BLIP3o+Open-Sora Plan 美學分大于6.0過濾,并用Qwen2-VL標注
4、實驗
????????不同模型之間生成、理解、編輯。
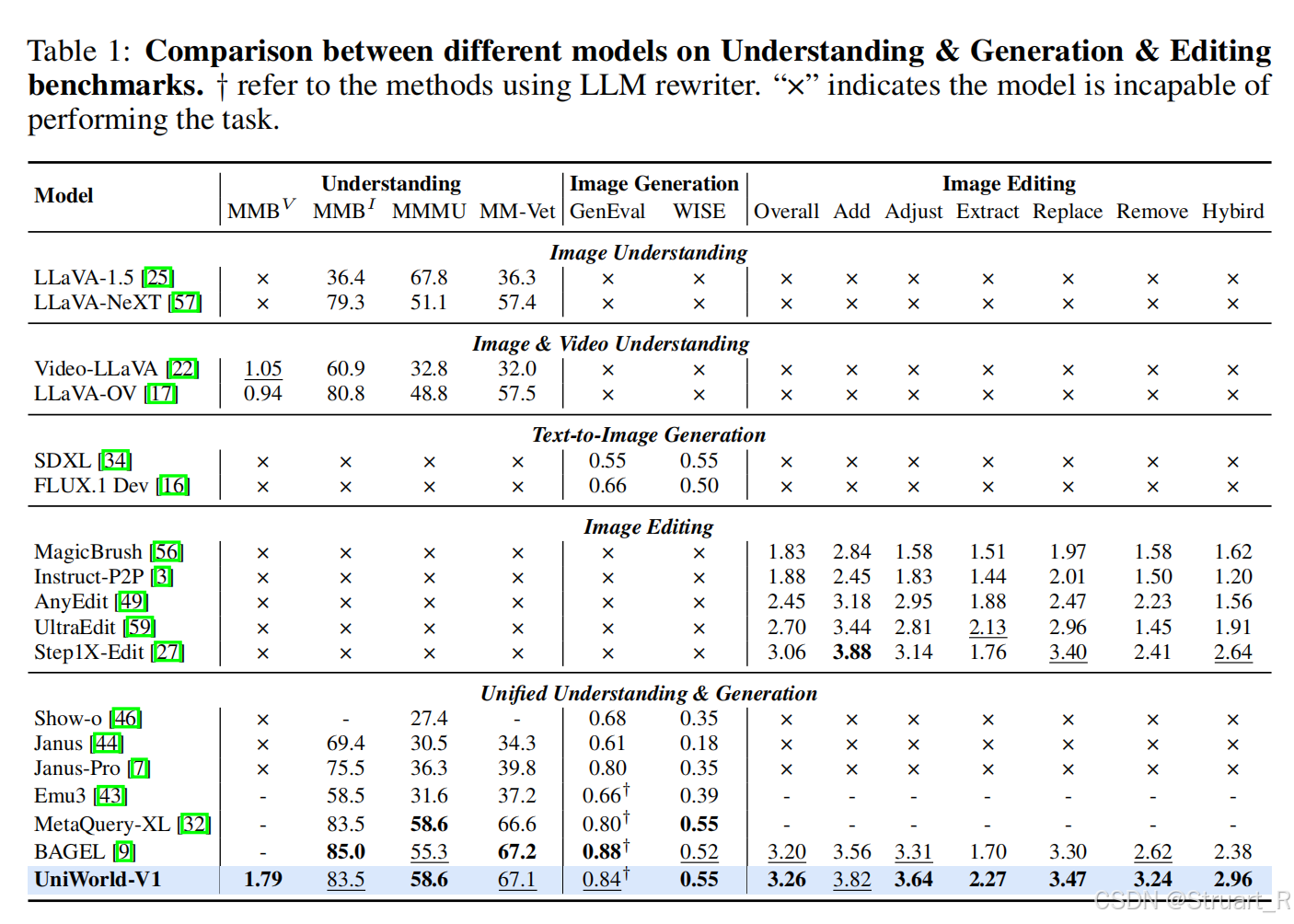
????????后續的對比實驗不在思考,大多數情況最多持平于BAGEL,但是主要原因是數據集的特定性的優勢。
提到了一些實驗中的觀察
????????DINOV2、RADIO v2.5替換SigLIP,但是不容易收斂
????????直接使用VLM視覺特征的視覺tokens作為引導,生成圖和參考圖之間一致性較差。他這里是輸出了所有tokens作為引導。
二、X-Omni
1、概述
????????傳統多模態模型的三大瓶頸問題:生成圖像模糊、失真,無法精確實現細節渲染,自回歸逐步預測導致的累積誤差。
????????另外統一模型轉向利用擴散模型解碼,但是擴散模型與自回歸模型異構,跨模態知識遷移受阻,所以考慮使用強化學習兼容優化。
2、方法
架構
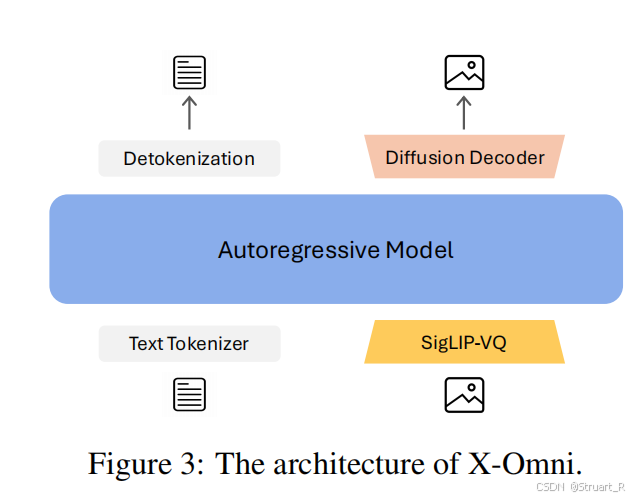
? ? ? ? 整體架構不再采用理解和生成解耦架構,而是只加一個視覺特征編碼器。X-Omni由SigLIP-VQ tokenizer,自回歸模型,擴散解碼器三部分組成。
? ? ? ? 自回歸模型選擇Qwen2-7B,并通過殘差塊實現視覺分詞器與自回歸模型的連接。另外在輸入部分插入4個隨機初始化的Transformer塊,用于僅處理圖像tokens,并且添加<SOM> height width <Image> 標記,用于支持任意分辨率輸入,位置編碼使用1D RoPE。
? ? ? ? 視覺特征編碼器采用SigLIP-VQ,也就是一個凍結的SigLIP2-g ViT編碼器連接一個向量量化器。
? ? ? ? 擴散解碼器將自回歸的Image tokens輸出采用線性層映射到FLUX.1dev特征空間。
強化學習應用
? ? ? ? 同樣應用于處理自回歸和擴散解碼之間的對齊工作,對于多模態獎勵機制可以參見MindOmni的做法,可以理解為只是替換了多模態獎勵的r值,其他不變,但是MindOmni只做了二值獎勵(用于檢查CoT邏輯規范),一致性獎勵(檢查圖文對齊)。X-Omni中處理了四個獎勵:美學質量獎勵,綜合質量獎勵,圖文對齊獎勵,文字渲染獎勵。
? ? ? ? 美學質量獎勵:利用HPSV2模型計算獎勵。224x224分辨率下預測人類偏好,用于評估多元審美標準。
? ? ? ? 綜合質量獎勵:1024x1024分辨率優化,評估銳利度,噪聲水平,動態范圍
? ? ? ? 圖文對齊獎勵:與Uniworld一致,余弦相似度計算
? ? ? ? 文字渲染獎勵:藝術字體識別GOT-OCR2.0,印刷體識別PaddleOCR。
? ? ? ? 另外實現任務自適應機制,當提示中含有文字關鍵詞,強化,高細節的風景則強化
訓練細節
? ? ? ? 類似Uniworld-V1的三階段學習。
? ? ? ? Stage1:預訓練,訓練視覺分詞器和嵌入的新圖像token,凍結其他層。數據包括圖像生成數據(COYO-700M,DataComp-1B,LAION-2B,并用Qwen2.5-VL-72B進行標注,美學分過濾,并進行圖像縮放,短邊最大384px,長邊最大1152px,共600B tokens),圖像理解數據(LLaVA-OneVision,BLIP3-KALE、Infinity-MM,同樣的分辨率處理,共100B tokens)
? ? ? ? Stage2:監督微調,解凍所有參數,高質量圖文對(BLIP3o-60K中的30K子集),合成文本生成(GPT-4合成的30K),預訓練數據中選擇美學質量HPSv2>=7.0的1.44B tokens,另外混合圖像理解任務LLaVA-NeXT,Cauldron VQA數據,SFT階段數據共1.5B tokens
? ? ? ? Stage3:強化學習,共180W提示,分為三類,真實用戶需求(比如去廣告,共80K,來自Midjourney),長文本(50K,按文本長度分桶采樣),自然場景強化(50K,景觀和人像提示,平衡美學與復雜度)

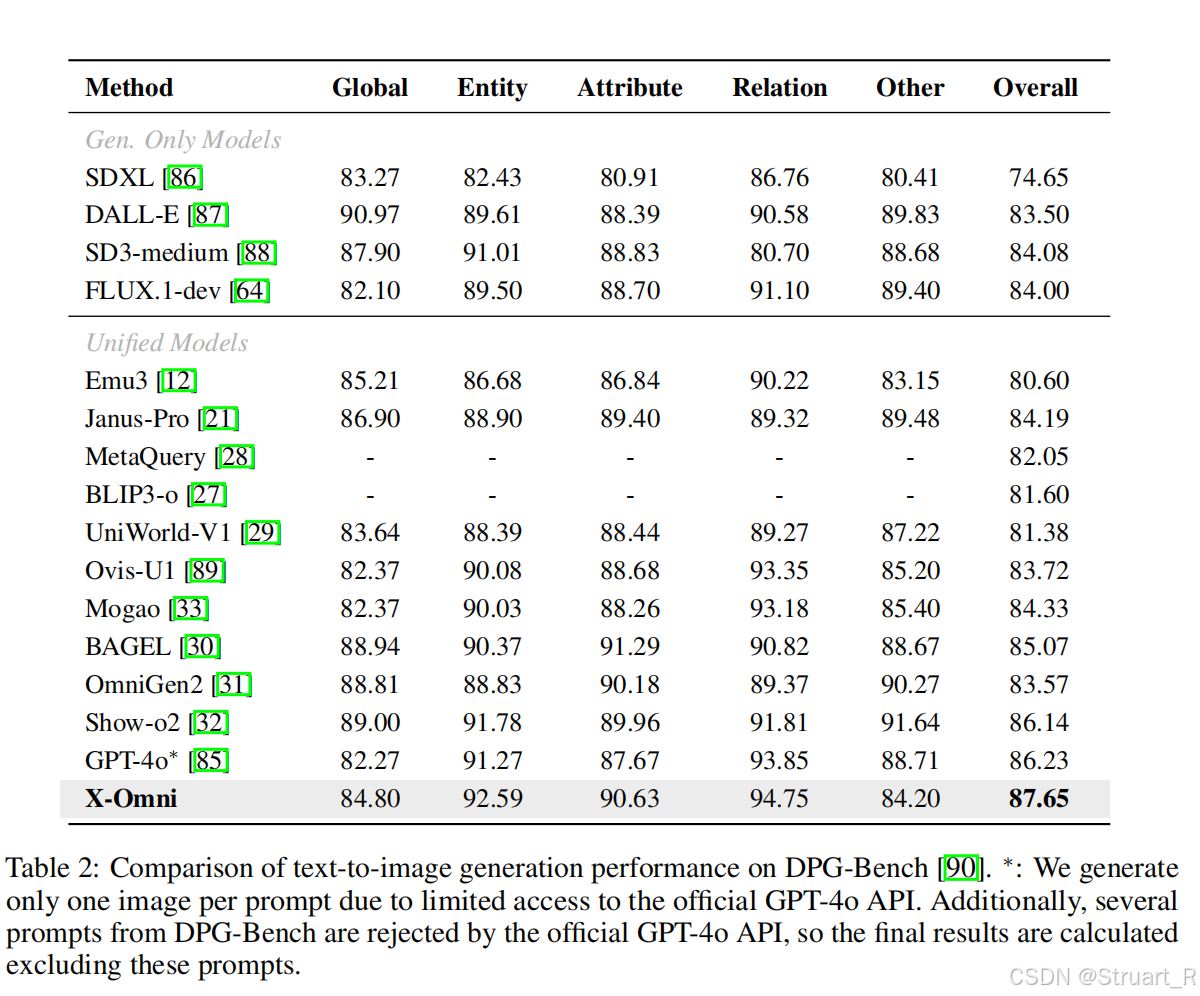
? ? ? ? 在圖像生成DPG eval中打敗了GPT-4o,超越一眾生成模型。測試復雜指令下圖像生成的推理能力
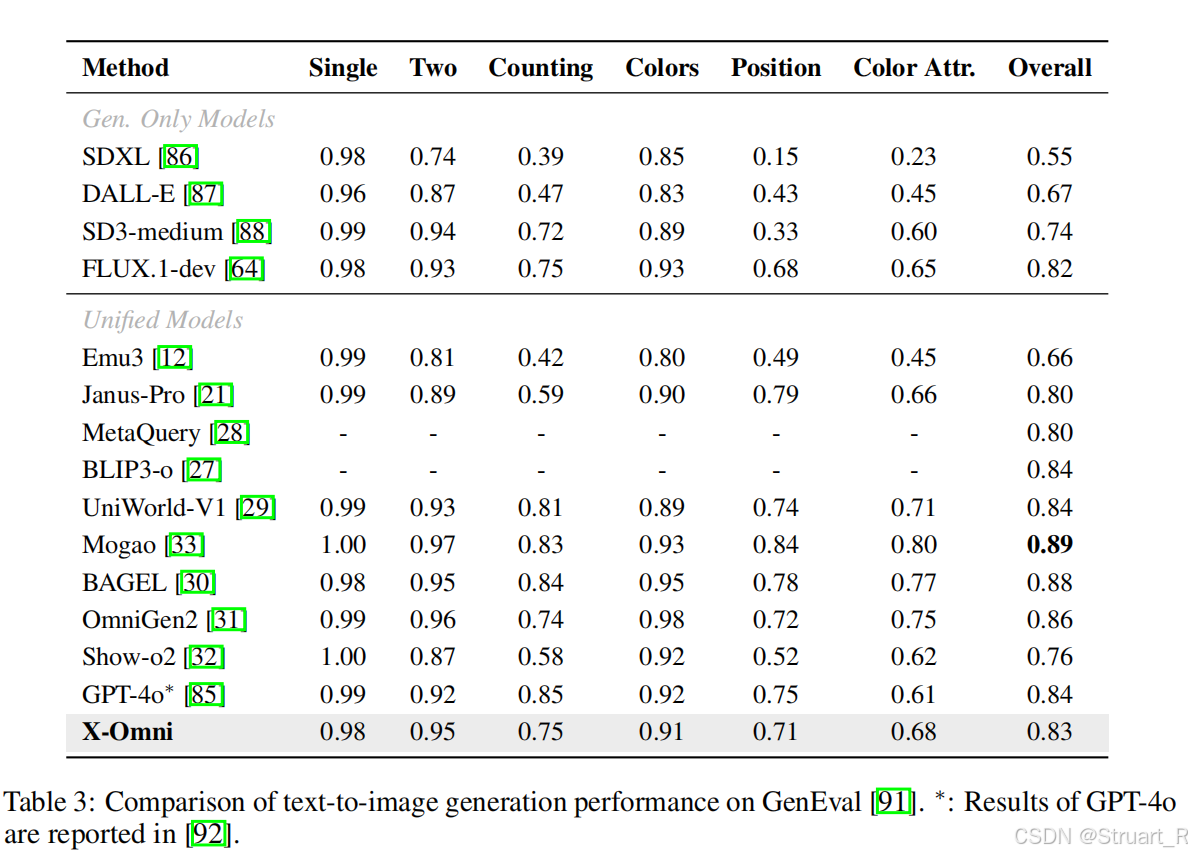
? ? ? ? GenEval,測試生成質量上,還是沒有打敗GPT-4o
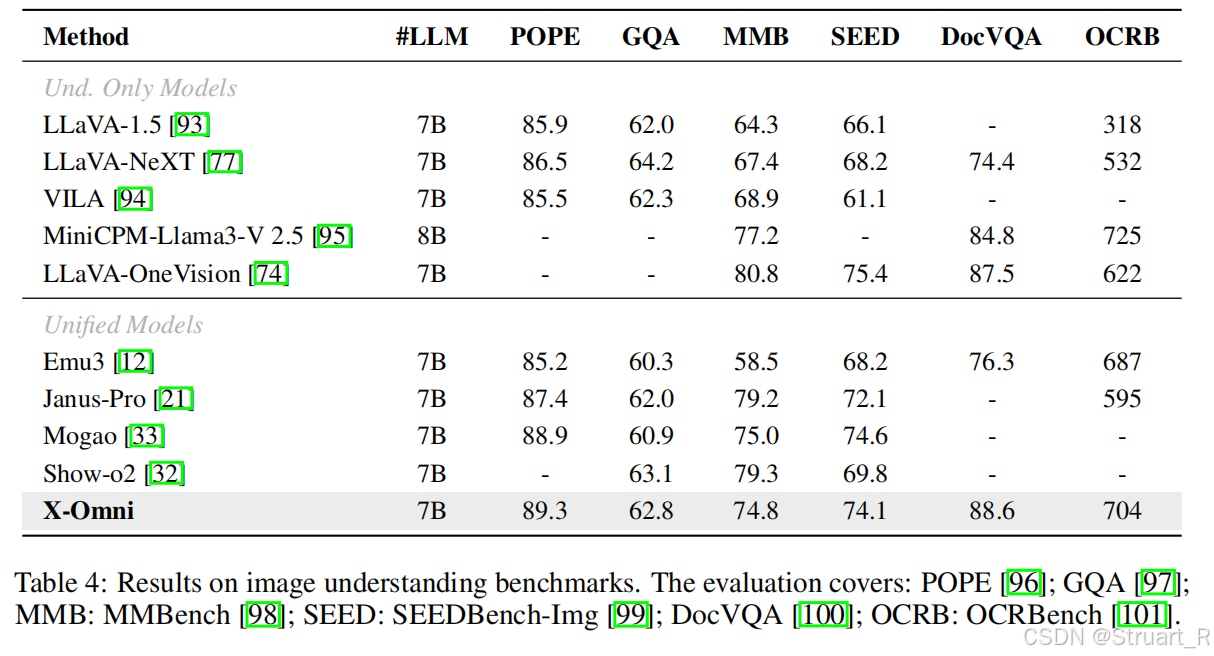
? ? ? ? 理解任務中,由于獎勵機制引入了OCR獎勵,所以在OCRBench分數上略高。
?參考:[2507.22058] X-Omni: Reinforcement Learning Makes Discrete Autoregressive Image Generative Models Great Again
[2506.03147] UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
????????





線性規劃+多項式回歸+邏輯回歸+決策樹)
)






(1天))


)


