概述
參考:What are Redis Cluster and How to setup Redis Cluster locally ? | by Rajat Pachauri | Medium
Redis Cluster 的工作原理是將數據分布在多個節點上,同時確保高可用性和容錯能力。以下是 Redis Cluster 運行方式的簡要概述:
- 節點發現:Redis 集群使用一種稱為“gossip 協議”的概念進行節點發現。每個節點都會維護集群中其他節點的列表,并定期與一些隨機選擇的節點共享有關集群狀態的信息。這有助于節點發現和加入集群。
- 數據分片:Redis Cluster 使用一致性哈希將數據劃分為多個哈希槽。集群支持 16384 個哈希槽,每個鍵使用哈希函數映射到特定槽。哈希槽分布在集群中的節點上。
- 主-副本復制:Redis 集群遵循主-副本復制模型。每個哈希槽都與特定的主節點相關聯,并且該槽中的數據被復制到一個或多個副本節點。副本提供冗余,并在主節點發生故障時充當故障轉移節點。
- 客戶端交互:客戶端可以連接到 Redis 集群中的任何節點。當客戶端發送與特定鍵相關的命令時,集群會使用該鍵的哈希槽來確定負責該槽的節點。然后使用 MOVED 或 ASK 重定向響應將客戶端透明地重定向到適當的節點。
- 故障轉移和高可用性:Redis 集群支持自動故障轉移。當主節點發生故障時,其副本之一將自動升級為主節點,從而確保數據的持續可用性。集群使用共識協議來選舉新的主節點。客戶端通過重定向響應更新新的主節點信息。
- 集群配置:Redis 集群維護一個集群配置,其中包含有關節點、哈希槽和副本的信息。當節點加入或離開集群時,此配置會動態更新。集群節點交換消息以就集群配置達成共識并確保其一致性。
通過在多個節點之間分配數據和負載,Redis Cluster 可實現水平擴展并提高性能。它提供容錯能力,因為副本可以接管發生故障的主節點的角色。集群還平衡哈希槽的分布,并確保每個節點負責一部分槽,從而使集群能夠高效擴展。
Redis cluster 簡介
Redis cluster 是一種去中心化的 Redis 分布式集群解決方案。通過數據自動分片分配到多個主節點之間(每個主節點 都是 主從搭配)、自動故障檢測,實現了高可用和高性能。
特點
Redis Cluster 具有以下幾個特點:
-
可擴展性(橫向擴展):通過向集群添加更多節點,可以增加 Redis 系統的整體容量和吞吐量。
擴展可以分為Las:垂直擴展(scale up)、水平擴展(scale out)
- 垂直拓展:升級單個 Redis 的硬件配置,比如增加內存容量、磁盤容量、使用更強大的 CPU。【部署簡單,但是當數據量大并且使用 RDB 實現持久化,會造成阻塞導致響應慢。另外受限于硬件和成本,拓展內存的成本太大,比如拓展到 1T 內存】
- 水平拓展:橫向增加 Redis 實例個數,每個節點負責一部分數據。【便于拓展,同時不需要擔心單個實例的硬件和成本的限制。但是,切片集群會涉及多個實例的分布式管理問題,需要解決如何將數據合理分布到不同實例,同時還要讓客戶端能正確訪問到實例上的數據】
-
高可用性:主從復制和故障轉移機制提高了集群的可靠性。
- 主從復制模式,從節點實時同步主節點的數據。這種結構不僅提高了數據的冗余性,還在主節點出現故障時提供了數據的可用性。
- 故障轉移機制:當主節點不可用時,從節點可以自動提升為主節點。這種自動化的故障處理機制減少了人為干預的需求,確保了系統的持續可用性。
使用場景
高并發應用:需要處理大量并發請求的場景,如電商、社交平臺。
數據分片需求:需要水平擴展存儲容量的場景。
高可用性需求:需要提供數據冗余和自動故障恢復的應用。
優缺點
優點:
- 水平擴展:通過添加節點輕松擴展集群容量。
- 高可用性:主從復制和故障轉移機制提高了集群的可靠性。
- 數據分布均衡:哈希槽機制確保數據在集群中均勻分布。
缺點:
- 復雜性增加:集群的配置和管理相較于單節點模式更加復雜。
- 數據一致性問題:可能出現部分數據不可用的情況,需要應用層處理。()
- 資源消耗:維護多個節點的狀態需要額外的資源和網絡通信。
Redis Cluster 實現原理
數據分片與哈希槽
Redis 的數據分片(sharding)是將 Redis數據集 分割為多個部分,分別存儲在不同的 Redis節點上的技術。通過數據分片技術可以將 一個單獨的 Redis數據庫擴展到多個物理機器上,從而提高 Redis集群的性能、擴展性。
當 16384 個槽都分配完全,Redis 集群才能正常工作。
在Redis的Cluster集群模式中,使用**哈希槽(hash slot)**的方式來進行數據分片,將整個數據集劃分為多個槽,每個槽分配給一個節點(這里的節點是由 主、從模式構成的)。
客戶端如何訪問/插入數據的?
客戶端訪問數據時,先計算出數據對應的槽,然后直接連接到該槽所在的節點進行操作。具體的:
如何分片的:Redis集群模式中,使用哈希槽(hash slot)的方式將數據分片。
- 首先,將數據集劃分為多個槽,每個槽分配給一個節點。(一個節點會對應多個槽)
- 客戶端訪問數據時,先計算出數據對應的槽,然后連接到該槽所屬的 Redis節點上,然后在該節點上訪問對應數據。
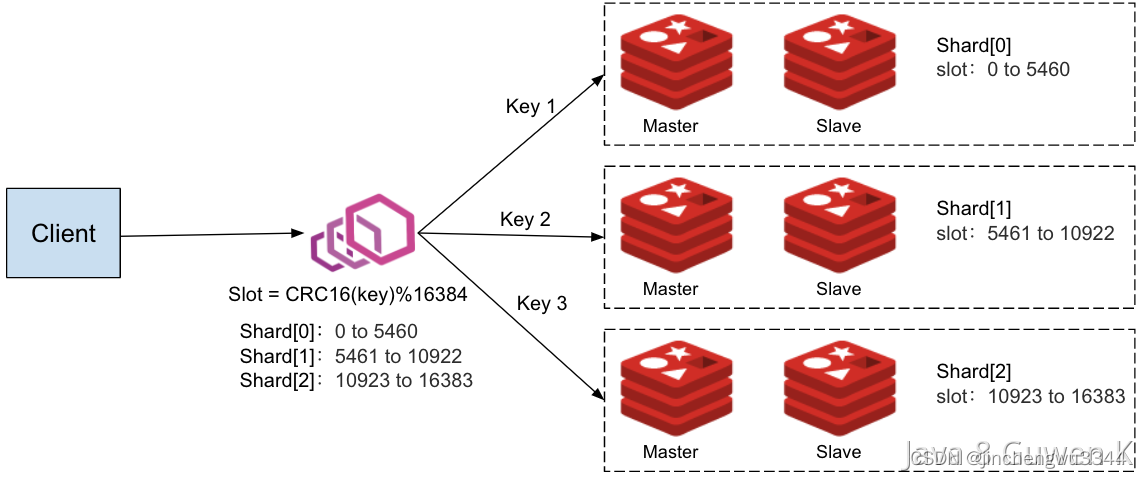
具體流程為:假設要查詢 鍵為key1的數據
- 對
key1進行哈希計算(使用CRC16算法計算的結果就是 key1的哈希值),假設得到哈希值為12345。 - 對哈希值取模16384,結果為12345。
key1映射到哈希槽12345,由節點B負責。
數據分片的作用
Redis Cluster中的數據分片具有以下特點:
- 提升性能和吞吐量:通過在多個節點上分散數據,可以并行處理更多的操作,從而提升整體的性能
和吞吐量。這在高流量場景下尤其重要,因為單個節點可能無法處理所有請求。 - 提高可擴展性:分片使得Redis可以水平擴展。可以通過添加更多節點擴展數據庫的容量和處理能
力。 - 降低單個節點的內存和計算需求:每個節點只處理數據的一部分,這降低了單個節點的內存和計算需求。
- 避免單點故障:在沒有分片的情況下,如果唯一的Redis服務器發生故障,整個服務可能會停止。
在分片的環境中,即使一個節點出現問題,其他節點仍然可以繼續運行。 - 數據冗余和高可用性:在某些分片策略中,如Redis集群,每個分片的數據都可以在集群內的其他
節點上進行復制。這意味著即使一個節點失敗,數據也不會丟失,從而提高了系統的可用性。
節點類型(主節點、從節點)
在 Redis Cluster 中,節點分為兩種類型:主節點(Master)和從節點(Slave)。
上面數據分片時所說的 會將數據分片到不同的節點上。這里的節點就是由 一個 master 和 1或多個slave 組成的。
- 主節點:是數據的主要存儲位置,負責處理與數據相關的所有操作,如讀、寫請求,數據分片等。
- 從節點:主要任務是復制主節點的數據。每個主節點可以有一個或多個從節點,從節點實時同步主節點的數據。這種設計保證了數據的冗余性和高可用性。
注意:關于Redis Cluster 中,從節點是否可以支持 讀服務?
-
默認情況下從節點不負責處理讀服務,所有的寫請求和讀請求都會被路由到主節點。
-
然而,Redis提供了
READONLY命令,允許客戶端將讀請求路由到從節點。但是,這種做法需要謹慎,因為它可能會引入一些問題,比如:
- 延遲讀取:從節點可能不會立即反映出主節點的最新數據變化,因為數據復制是異步進行的。
- 一致性風險:如果主從節點之間的網絡延遲較大,從節點可能會提供過時的數據
Redis Cluster 的通信協議:Gossip 協議
Redis 的集群節點之間的通信采取 gossip 協議進行通信,在 redis cluster 架構下,每個 redis 要放開兩個端口號,比如一個是 6379,另外一個就是 加10000 的端口號,比如 16379,16379 端口號是用來進行節點間通信的。
Gossip protocol 也叫 Epidemic Protocol (流行病協議),實際上它還有很多別名,比如:“流言算法”、“疫情傳播算法”等。
Gossip protocol (流言協議),是利用一種 隨機、帶有傳染性的方式,將信息傳播到整個網絡中,并在一定時間內,使得系統內所有節點數據一致。
Gossip協議的執行過程簡答描述為:Gossip 過程是由種子節點發起,當一個種子節點有狀態需要更新到網絡中的其他節點時,它會隨機的選擇周圍幾個節點散播消息,收到消息的節點也會重復該過程,直至最終網絡中所有的節點都收到了消息。這個過程可能需要一定的時間,由于不能保證某個時刻所有節點都收到消息,但是理論上最終所有節點都會收到消息,因此它是一個最終一致性協議。
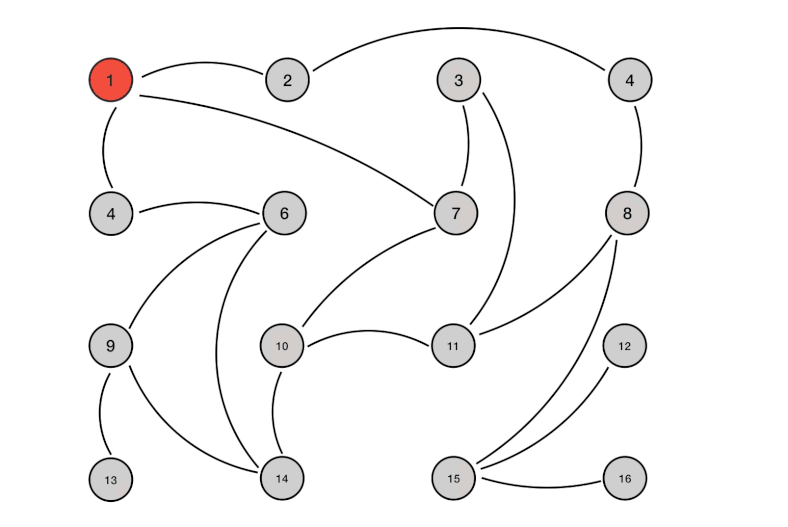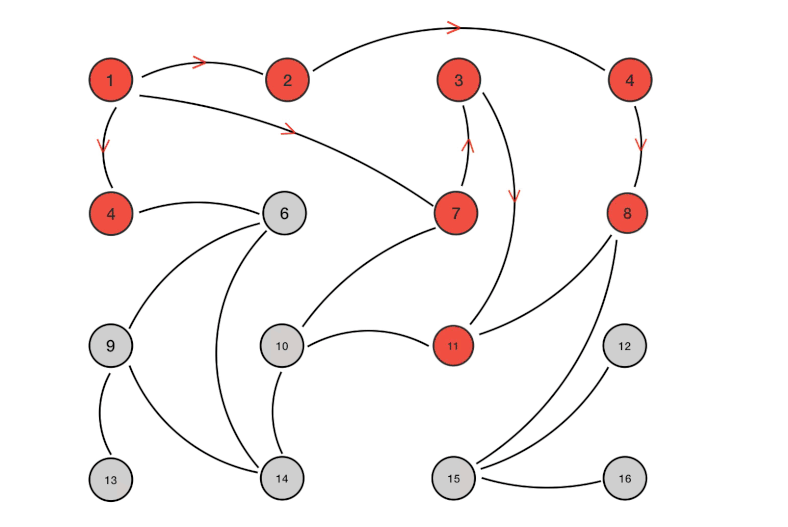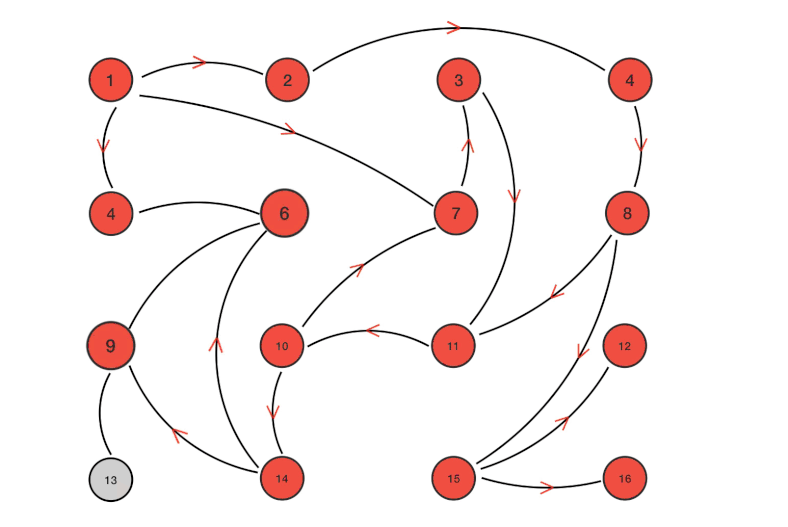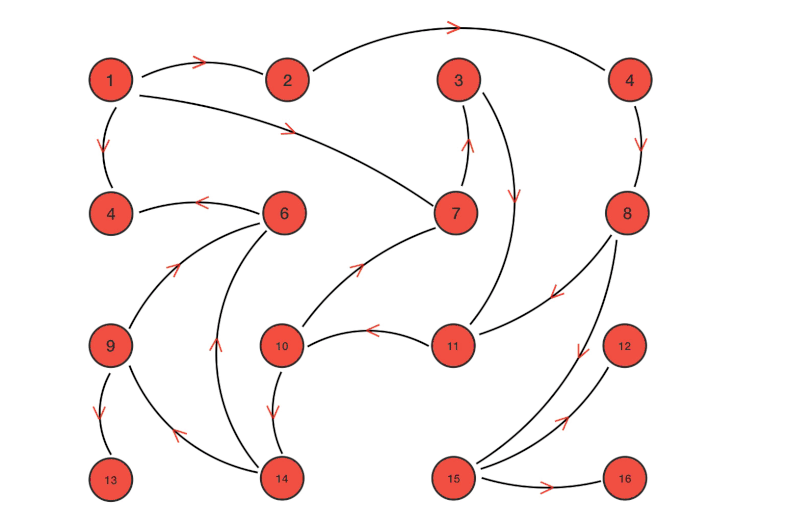
Gossip協議優缺點
優點:
- 擴展性 網絡可以允許節點的任意增加和減少,新增加的節點的狀態最終會與其他節點一致。
- 容錯 網絡中任何節點的宕機和重啟都不會影響 Gossip 消息的傳播,Gossip 協議具有天然的分布式系統容錯特性。
- 去中心化 Gossip 協議不要求任何中心節點,所有節點都可以是對等的,任何一個節點無需知道整個網絡狀況,只要網絡是連通的,任意一個節點就可以把消息散播到全網。
- 一致性收斂 Gossip 協議中的消息會以一傳十、十傳百一樣的指數級速度在網絡中快速傳播,因此系統狀態的不一致可以在很快的時間內收斂到一致。消息傳播速度達到了 logN。
- 簡單 Gossip 協議的過程極其簡單,實現起來幾乎沒有太多復雜性。
缺點:
- 消息的延遲 由于 Gossip 協議中,節點只會隨機向少數幾個節點發送消息,消息最終是通過多個輪次的散播而到達全網的,因此使用 Gossip 協議會造成不可避免的消息延遲。不適合用在對實時性要求較高的場景下。
- 消息冗余 Gossip 協議規定,節點會定期隨機選擇周圍節點發送消息,而收到消息的節點也會重復該步驟,因此就不可避免的存在消息重復發送給同一節點的情況,造成了消息的冗余,同時也增加了收到消息的節點的處理壓力。而且,由于是定期發送,因此,即使收到了消息的節點還會反復收到重復消息,加重了消息的冗余。
Redis Cluster的Gossip機制
Redis Cluster 是在 3.0 版本引入集群功能。為了讓讓集群中的每個實例都知道其他所有實例的狀態信息,Redis 集群規定各個實例之間按照 Gossip 協議來通信傳遞信息。

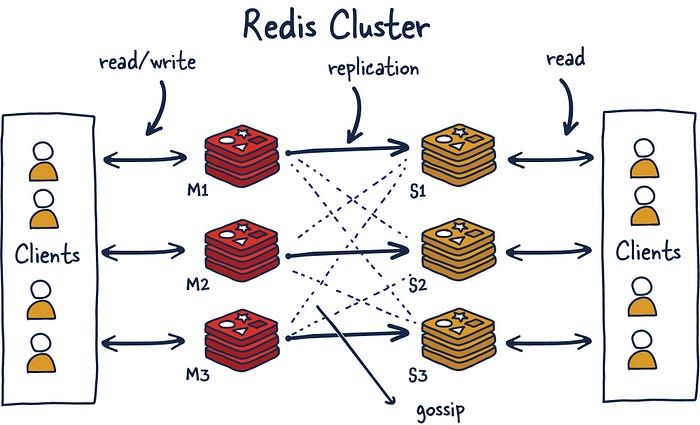
上圖展示了主從架構的 Redis Cluster 示意圖,其中:
- 實線表示節點間的主從復制關系,
- 虛線表示各個節點之間的 Gossip 通信。
Redis Cluster 中的每個節點都維護一份自己視角下的當前整個集群的狀態信息(元數據信息),主要包括:
- 當前集群狀態
- 集群中各節點所負責的 slots信息,及其migrate狀態
- 集群中各節點的master-slave狀態
- 集群中各節點的存活狀態及懷疑Fail狀態
Redis Cluster 的節點之間發送消息的類型
知道了 節點之間是通過 Gossip 協議進行消息的發送,現在來看看它們之間發送消息的類型。較為重要的如下所示:
| 消息 | 說明 |
|---|---|
meet | 通過「cluster meet ip port」命令,已有集群的節點會向新的節點發送邀請,加入現有集群,然后新節點就會開始與其他節點進行通信 |
ping | 節點按照配置的時間間隔向集群中其他節點發送 ping 消息,消息中帶有自己的狀態,還有自己維護的集群元數據,和部分其他節點的元數據 |
pong | 返回ping和meet,包含自己的狀態和其他信息,也可以用于信息廣播和更新 |
fail | 某個節點判斷另一個節點fail之后,就發送fail給其他節點,通知其他節點,指定的節點宕機了 |
定時ping/pong消息(心跳機制)
Redis Cluster 中的節點都會定時地向其他節點發送 PING 消息,來交換各個節點狀態信息,檢查各個節點狀態,包括在線狀態、疑似下線狀態 PFAIL 和已下線狀態 FAIL。
Redis 集群的定時 PING/PONG 的工作原理可以概括成兩點:
-
一是,每個實例之間會按照一定的頻率,從集群中隨機挑選一些實例,把 PING 消息發送給挑選出來的實例,用來檢測這些實例是否在線,并交換彼此的狀態信息。
例自身的狀態信息、部分其它實例的狀態信息,以及 Slot 映射表。
-
二是,一個實例在接收到 PING 消息后,會給發送 PING 消息的實例,發送一個 PONG 消息。PONG 消息包含的內容和 PING 消息一樣。

故障檢測與自動故障轉移
Redis Cluster保證高可用(High Availability)主要還是依靠:故障檢測與故障轉移。
自動故障檢測
故障檢測的機制如下(通過Gossip協議發送消息進行檢測):
關于節點參與情況說明:
- 主觀下線:每個節點(包括主節點和從節點)都會檢測其他節點的狀態。如果檢測到某個節點不可用,會將其標記為主觀下線(PFAIL)。
- 客觀下線:主節點之間會交換彼此的主觀下線狀態,如果超過半數的主節點都認為某個節點不可用,則該節點會被標記為客觀下線(FAIL)。
-
疑似下線:Redis Cluster 中的節點會定期檢查已經發送
PING消息(即上述的心跳機制)的接收方節點是否在規定時間 (cluster-node-timeout) 內返回了PONG消息,如果沒有則會將其標記為疑似下線狀態(possible fail,PFAIL)。

-
客觀下線:當一個節點將另一個節點標記為"疑似失敗"后,它會通過Gossip協議將這個信息傳播給其他節點。如果一個節點從大多數主節點那里都收到了某個節點的"疑似失敗"信息,那么這個節點將被標記為"客觀失敗"(FAIL)。并將該節點 客觀下線的信息,發送給所有節點。
這時,集群會觸發故障轉移流程,從失敗節點的從節點中選舉一個新的主節點。
自動故障轉移
節點參與情況說明:
從節點投票:當一個主節點被標記為客觀下線后,它的從節點會發起故障轉移過程。故障轉移請求會被發送到其他主節點,以請求授權進行故障轉移。
授權投票:其他主節點會對故障轉移請求進行投票,同意票數超過半數后,候選從節點會被提升為新的主節點。
當Redis Cluster中的主節點被標記為客觀下線(FAIL)時,會觸發故障轉移(failover)流程。故障轉移(failover)是指當主節點不可用時,從節點自動提升為新的主節點,以保證集群的高可用性。故障轉移的流程包括以下幾個步驟:
- 投票選舉:被標記為客觀下線的主節點的從節點會嘗試提升為主節點。
- 這些從節點會向集群中的其他主節點請求支持,開始選舉過程。
- 各個主節點會根據從節點的優先級(配置文件中的
slave-priority參數)、復制偏移量(replication offset)等因素進行投票。
- 選擇新的主節點:
- 得到多數票(超過半數)的從節點會被提升為新的主節點。
- 如果沒有從節點得到足夠的票數,則選舉失敗,并在短時間后重試。
- 配置更新:當選舉出新的主節點后,該主節點會通知所有的其他節點,告知他是新的主節點。
- 數據同步:原主節點的從節點現在會成為新主節點的從節點,并開始從新主節點同步數據。如果原主節點恢復后重新加入集群,它也會成為新主節點的從節點,并從新主節點同步數據。
重定向
為什么需要重定向
當客戶端第一次連接到 Redis Cluster 時,它會連接到集群中的一個節點(通常是配置好的一個或多個節點之一)。這個節點會提供當前集群的拓撲結構,包括每個節點負責的哈希槽范圍。
但是,后續如果節點進行擴容、縮容之后,每個節點的哈希槽范圍會改變。此時,客戶端是無法感知的。
之后通過重定向一次之后,客戶端會根據節點返回 MOVED 或 ASK 錯誤,客戶端更新其拓撲結構,并將請求重發到新的節點。
在此之后,客戶端維護的拓撲結構更新到最新的狀態。
一句話:在 Redis Cluster 中,每個鍵通過哈希槽分配到不同的節點。如果你向某個節點寫入數據,但該數據應該存儲在另一個節點上,Redis Cluster 會返回重定向指令,告訴你應該訪問哪個節點。這確保了數據的分布和存取的正確性。
重定向指令類型
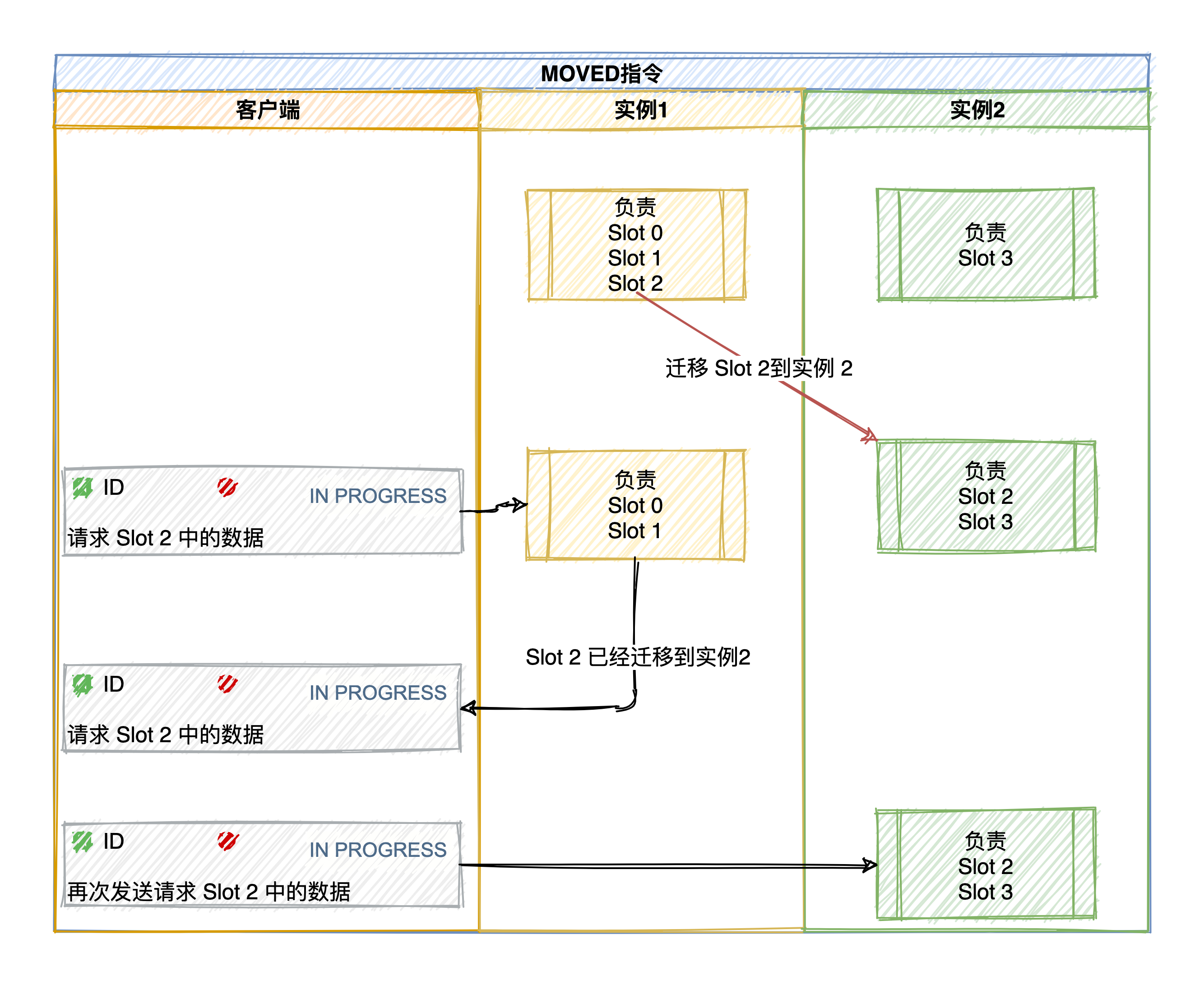
MOVED:當客戶端請求的鍵在另一個節點上時,節點會返回MOVED指令。該指令包含目標節點的地址。客戶端收到MOVED指令后,會重新請求目標節點。
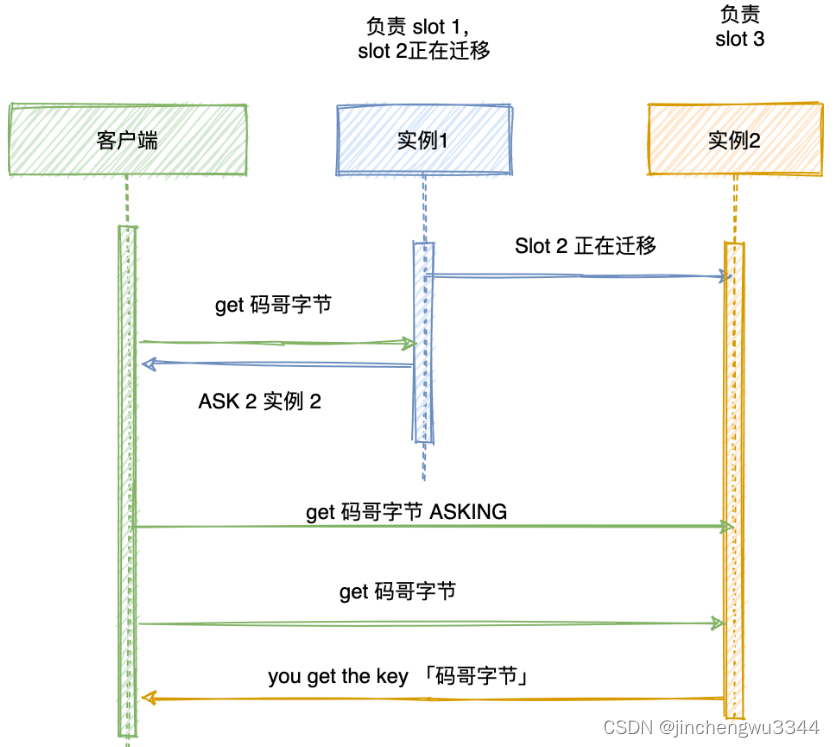
ASK:在數據遷移過程中,如果某個鍵正在從一個節點遷移到另一個節點,當客戶端請求這個鍵時,節點會返回ASK指令。ASK指令告訴客戶端臨時訪問新的目標節點,通常在數據遷移完成之前。
MOVED指令
重定向過程的詳細步驟:
- 初始請求:客戶端向節點A發送請求,如果鍵不在節點A的哈希槽范圍內。
- 返回
MOVED指令:節點A返回一個MOVED指令,包含目標節點B的地址。 - 客戶端重試:客戶端向節點B重新發送請求。
- 返回結果:節點B處理請求并返回結果。
注意:重定向MOVED類型,客戶端還會更新本地緩存,將該 slot 與 Redis 實例對應關系更新正確。
ASK指令
-
遷移過程中的請求:如果某個鍵正在從節點A遷移到節點B,客戶端請求這個鍵時,節點A會返回一個
ASK指令。 -
臨時訪問:客戶端向節點B發送請求,并在請求前發送
ASKING指令,表明這是一次臨時訪問。 -
數據遷移完成后:客戶端可以正常訪問節點B,不再需要發送
ASKING指令。
注意:ASK 指令并不會更新客戶端緩存的哈希槽分配信息。
擴容、縮容
縮容原理
縮容流程:
- 選擇要移除的節點
- 哈希槽重分配:在縮容過程中,首先需要將要移除節點上的哈希槽遷移到其他節點。這樣可以確保數據的完整性和一致性。
- 數據遷移:哈希槽的遷移意味著對應數據的遷移,Redis Cluster會自動將數據從一個節點復制到另一個節點。
- 將節點從集群中移除
- 更新集群狀態:集群狀態會隨時更新,以反映哈希槽和數據的遷移情況。
- 移除節點:一旦所有數據和哈希槽遷移完成,就可以安全地將節點從集群中移除。
擴容原理
擴容流程:
- 啟動新節點
- 將新節點加入集群
- 重新分配哈希槽:在擴容過程中,需要將部分哈希槽從現有節點遷移到新節點,以確保數據分布均勻。哈希槽的重新分配可以通過手動指定或者使用
reshard命令自動進行。 - 數據遷移:哈希槽遷移意味著對應數據的遷移,Redis Cluster會自動將數據從一個節點復制到另一個節點。數據遷移過程中,Redis Cluster會確保數據的一致性和完整性。
- 更新集群狀態:集群狀態會隨時更新,以反映哈希槽和數據的遷移情況。新節點加入集群后,集群中的其他節點會通過Gossip協議感知新節點的存在,并更新自己的拓撲信息。
- 驗證集群狀態
主、從節點如何建立的通信
步驟如下:
- 初始配置:每個節點啟動時都會加載其配置文件,其中包含節點的 ID、集群狀態和分配的哈希槽信息。如果是從節點,還會配置它所跟隨的主節點信息。
- 啟動節點、發現節點、加入集群:節點通過 Gossip 協議發現和加入集群。每個節點會周期性地向其他節點發送 PING 消息,接收 PONG 響應,了解對方的存在和狀態。
主從節點建立關系:- 從節點啟動時,根據配置文件中的信息,向其指定的主節點發送復制請求(PSYNC)。
- 主節點接收請求后,開始向從節點復制數據。
- 復制完成后,從節點進入同步狀態,定期向主節點發送 ACK 消息,確認接收到的數據。
復制請求(PSYNC)
這里的復制請求(PSYNC)主要使用的是 Redis 協議(REdis Serialization Protocol, RESP)。
RESP(Redis Serialization Protocol) 是 Redis 的內部協議,用于客戶端和服務器之間的通信,也用于 Redis 集群節點之間的通信。該協議簡單、高效且便于實現。
復制請求(PSYNC)的流程:
-
讀取
replicaof指令,獲取主節點信息:-
從節點的配置文件中會包含一條
replicaof指令,用于指定它要跟隨的主節點的 IP 地址和端口。例如:port 7001 cluster-enabled yes cluster-config-file nodes-7001.conf cluster-node-timeout 5000 appendonly yes replicaof 127.0.0.1 7000 -
啟動從節點,當從節點啟動時,它會讀取配置文件并解析
replicaof指令。
-
-
連接主節點:從節點根據
replicaof指令中指定的 IP 地址和端口,嘗試連接主節點。 -
發送
PSYNC命令:一旦連接成功,從節點會向主節點發送PSYNC命令以請求復制。PSYNC命令用于部分重同步或全量重同步。PSYNC <replicationid> <offset> -
主節點響: 主節點接收到
PSYNC命令后,就可以開始數據復制同步了。
參考
- Redis 高可用篇:Cluster 集群原理剖析,集群可以無限拓展么_redis cluster_碼哥字節_InfoQ寫作社區
- What are Redis Cluster and How to setup Redis Cluster locally ? | by Rajat Pachauri | Medium
- Redis Cluster集群節點間通信:Gossip協議 | 浮生無事Blog (fushengwushi.com)
- 認識Redis集群——Redis Cluster - JJian - 博客園 (cnblogs.com)
- Redis 高可用篇:Cluster 集群原理剖析,集群可以無限拓展么_redis cluster_碼哥字節_InfoQ寫作社區

![[終端安全]-1 總體介紹](http://pic.xiahunao.cn/[終端安全]-1 總體介紹)


非對稱加密)



:前端菜鳥的摸魚與成長)
)









