系列5中講到會講解3個方面RAG的提升,它們可能與RAG的準確率有關系,但是更多的它們是有其它用途。本期來講解第三部分:高級階段。之所以說是高級階段,可能是不好歸一,而且實現起來相對于前面來說可能更為復雜。
目錄
- 1 重排(Re-ranking)
- 1.1 RRF算法
- 1.2 Cohere Rerank模型
- 1.3 BGE-reranker模型
- 2 self-RAG
- 3 CRAG
- 4 總結
1 重排(Re-ranking)
在系列4中講到問題優化的方法RAG-Fusion,里面提到了它與Multi-Query最后不同就是使用RRF對結果進行重排。其實重排是一種提高RAG問題準確率很好的方法,但是之所以沒有放入RAG優化,而放入RAG提升,主要考慮2方面,其一是它其實算是一套流程中一個中間操作,在問題優化方法中也有提到過,不好在RAG優化單獨拎出來;其二是它也并非只是簡單使用RRF算法重排那么簡單。這里就是使用一個大篇幅來講一下重排。(注意:重排技術與問題優化等提高RAG準確度并不綁定,很多技術都是可以合著一起使用,效果會更好)
1.1 RRF算法
在系列4中講到問題優化的方法RAG-Fusion中已經給出這個算法的代碼,但是沒有細說這個算法原理。這里來個大家舉例說明一下。
RRF全稱是Reciprocal Rank Fusion,也稱為倒數排名融合。其實這個算法在日常生活中經常見到,比如足球、籃球等運動在評選MVP或者年度最佳球員時,經常會使用投票,這個投票一般會是一個排序,就是你排出你認為是MVP的三個人,注意:這里列出3個人是要排序,誰第一,誰第二,誰第三。然后再利用公式:1 / ( k + rank)。來計算每個人最終分數,然后通過最終分數排名。其中rank代表該球員在每張票的排名,k是一個常數。我們下面舉個例子:
假如有3個人對本年度金球獎進行投票
A教練的投票結果:1.卡卡 2.C羅 3.梅西
B教練的投票結果:1.卡卡 2.梅西 3.C羅
C教練的投票結果:1.C羅 2.卡卡 3.梅西
假如k=0,那么:
卡卡的得分就是:1/1+1/1+1/2=2.5
C羅的得分就是:1/2+1/3+1/1=1.83
梅西的得分就是:1/3+1/2+1/3=1.17
因此最終排名就是:卡卡第一名、C羅第二名、梅西第三名。
代碼實現如下:
# 定義RRF算法函數,代碼來自:https://github.com/langchain-ai/langchain/blob/master/cookbook/rag_fusion.ipynb
def reciprocal_rank_fusion(results: list[list], k=60):fused_scores = {}for docs in results:# Assumes the docs are returned in sorted order of relevancefor rank, doc in enumerate(docs):doc_str = dumps(doc)if doc_str not in fused_scores:fused_scores[doc_str] = 0# previous_score = fused_scores[doc_str]fused_scores[doc_str] += 1 / (rank + k)reranked_results = [(loads(doc), score)for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)]return reranked_results1.2 Cohere Rerank模型
Cohere Rerank是一個商業閉源的Rerank模型。它根據與指定查詢問題的語義相關性對多個文本輸入進行排序,專門用于幫助關鍵詞或向量搜索返回的結果做重新排序與提升質量。它是一個在線模型,也就是你無法在本地部署,使用步驟:
- 在其官方網站注冊一個API KEY
- 使用其客戶端或者使用langchain第三方組件進行訪問
下面就以langchain框架實現一個demo
前置條件:
- 申請一個Cohere的API KEY
- 下載m3e-base的embedding模型
- 準備一些文檔作為查詢使用
import os
import getpassfrom langchain_community.llms import Cohere
from langchain.chains import RetrievalQA
from langchain_cohere import CohereRerank
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever# 前置工作1:設置COHERE的APIKEY
os.environ["COHERE_API_KEY"] = getpass.getpass("Cohere API Key:")# 前置工作2:文檔存儲,如果已經存儲了文檔,則不需要該步驟
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 換成自己的embedding模型路徑model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)
if os.path.exists('VectorStore'):db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
loader = DirectoryLoader("/root/autodl-tmp/doc") # 換成自己的文檔路徑
documents = loader.load()
text_spliter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = text_spliter.split_documents(documents)
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()# 第一步:初始化Cohere模型
llm = Cohere(temperature=0)
compressor = CohereRerank()# 第二步:使用ContextualCompressionRetriever包裝檢索器
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=database.as_retriever(search_kwargs={"k": 20})
)# 第三步:使用RetrievalQA調用chain
chain = RetrievalQA.from_chain_type(llm=Cohere(temperature=0), retriever=compression_retriever
)
query = "ChatGLM是什么?"
chain({"query": query})1.3 BGE-reranker模型
cohere畢竟是閉源的,無法本地部署,因此國內推出了開源項目BGE-reranker模型。BGE-reranker模型是北京智源人工智能研究院(BAAI)推出的一種重排序模型,主要用于優化信息檢索系統的性能,底層是基于BAAI General Embedding模型擴展混合檢索能力。目前該已經開源,推出bge-reranker-base、bge-reranker-large等版本,在hugging face或者魔塔均可下載。
下面借助FlagEmbedding(一款用于微調/評估文本嵌入模型的工具)和FastAPI可以將BGE-reranker模型封裝為API格式,提供和Cohere模型一樣的效果。
前置條件:
- 下載BAAI/bge-reranker-base模型
- 安裝FlagEmbedding和FastAPI工具
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
from operator import itemgetter
from FlagEmbedding import FlagReranker# 定義FastAPI
app = FastAPI()
# 定義BGE-reranker模型
reranker = FlagReranker('你的BGE-reranker模型路徑') # 修改為你模型文件路徑# 定義入參
class Query(BaseModel):question: strdocs: list[str]top_k: int = 1# 提供訪問入口
@ app.post('/bge_rerank')
def bge_rerank(query: Query):scores = reranker.compute_score([[query.question, passage] for passage in query.docs])if isinstance(scores, list):similarity_dict = {passage: scores[i] for i, passage in enumerate(query.docs)}else:similarity_dict = {passage: scores for i, passage in enumerate(query.docs)}sorted_similarity_dict = sorted(similarity_dict.items(), key=itemgetter(1), reverse=True)result = {}for j in range(query.top_k):result[sorted_similarity_dict[j][0]] = sorted_similarity_dict[j][1]return resultif __name__ == '__main__':uvicorn.run(app, host='0.0.0.0', port=8000)通過以上你就可以使用API 方式訪問bge-reranker:
curl --location ‘http://localhost:50072/bge_base_rerank’
–header ‘Content-Type: application/json’
–data ‘{
“question”: “ChatGLM”,
“docs”: [“GLM3”, “Baichuan2”],
“top_k”: 2
}’
2 self-RAG
self-RAG是一種增強的RAG范式,其論文地址:https://arxiv.org/pdf/2310.11511。有興趣的同學可以拜讀,但是論文中更多的是底層和算法,如果研究應用的同學看起來會容易云里霧里。這里暫時摒棄數學公式,簡單易懂給大家講講self-RAG的原理。
首先之所以提出self-RAG當然是RAG存在某些缺陷。RAG本身是借助外部知識,利用大模型推理得出答案,但是會存在幾個問題
- 搜索知識過多,通過相似度檢索很容易過多搜索出知識,哪怕進行top k的處理也還是很多且有可能不是真正相關,并且很多模型并不能支持過長的token數
- 大模型生成的結果,本身無法確保與搜出來的知識保持一致,哪怕你通過增加prompt,也難保本身搜出來的知識就存在錯誤
那么self-RAG如何解決這些問題?我們可以從下圖看看self-RAG的工作流程
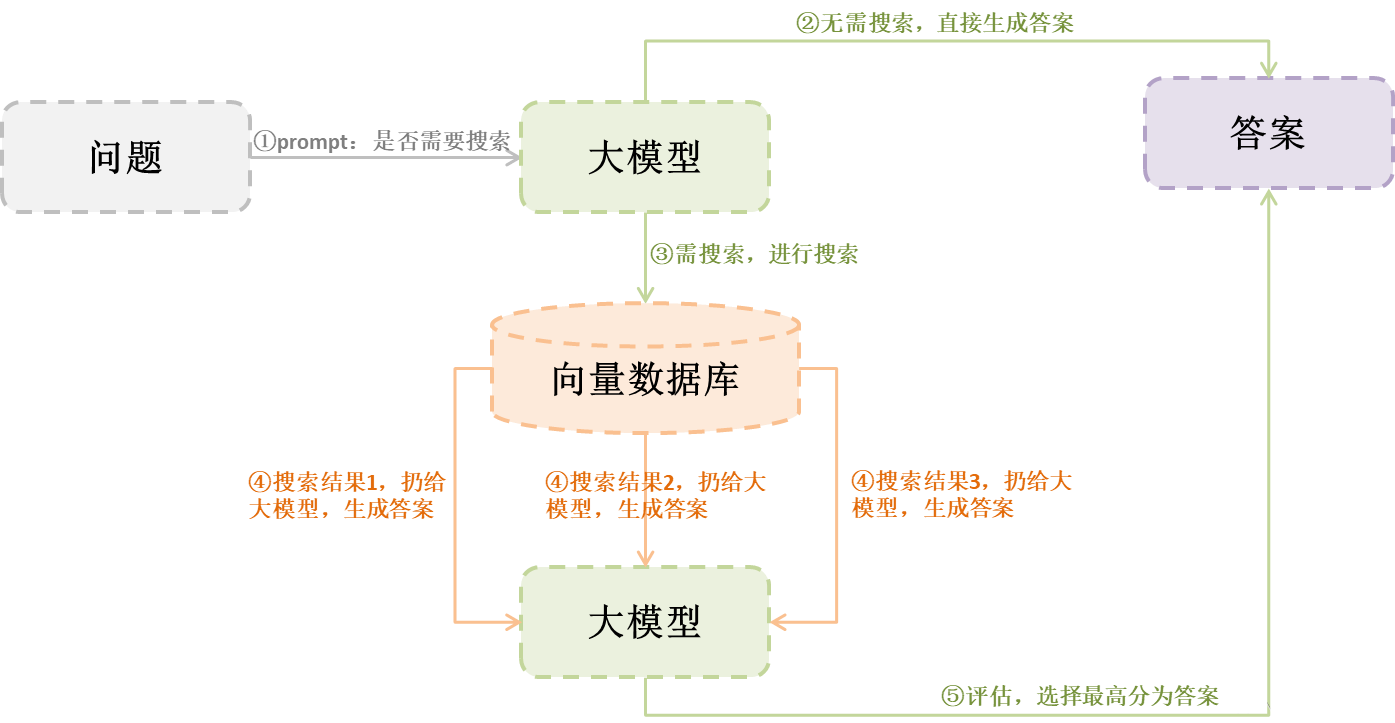
從上圖,我們可以看到,self-RAG增加或者改進3方面的內容:
- 判斷是否需要檢索:可以解決搜索知識過多問題,因為有些問題其實不需要進行檢索
- 搜索結果分別生成:這個可以解決大模型token不足的問題(相對于傳統RAG是一起扔給大模型進行生成)
- 評估生成結果:這個可以解決生成結果與知識內容的一致性
如何做到以上3個點,self-RAG通過微調訓練大模型,讓大模型在推理過程中實現自我反省。為了讓大模型具備自我反省,那么self-RAG在微調過程中,加入了有標志的“反省Token”,當大模型生成這些標志性的“反省Token”時,那么就要進行不同token的自我反省操作。如模型輸出如下例子:
[Relevant] ChatGLM3 是北京智譜華章科技有限公司和清華大學 KEG 實驗室聯合發布的對話預訓練模型。關于北京智譜華章科技有限公司[Retrieval]
我們能看到有2個特殊的token,分別是[Relevant]和[Retrieval]。當有這2個特別含義的token時,模型會根據這些token做出對應的反省操作,比如[Relevant]代表內容與問題相關,[Retrieval]代表這里需要進行搜索。至于如何評判是否需要檢索以及評判生成的分數,Self-RAG共設計了四種類型的評判指標:
| 特殊token | 作用 | 取值 |
|---|---|---|
| Retrieve | 是否需要知識檢索,表示LLM后續的內容生成是否需要做額外知識檢索。 | [No Retrieval]:無需檢索,LLM直接生成;[Retrieval]:需要檢索;[Continue to Use Evidence]:無需檢索,使用之前內容 |
| IsRel | 知識相關性,表示檢索出來的知識是否提供了解決問題所需的信息。 | [Relevant]:檢索出來的知識與需要解決的問題足夠相關;[Irrelevant]:檢索出來的知識與需要解決的問題無關 |
| IsSup | 響應支持度,表示生成的響應內容是否得到檢索知識的足夠支持。 | [Fully supported]:輸出內容陳述被檢索的知識完全支持;[Partially supported]:輸出內容陳述只有部分被檢索的知識所支持;[No support / Contradictory]:輸出內容不被檢索的知識所支持(即編造)。 |
| IsUse | 響應有效性。表示生成的響應內容對于回答/解決輸入問題是否有用 | [Utility : x]:按有效的程度x分成1-5分,即最高為[Utility:5] |
當然,這樣的模型是需要特殊的訓練,在Self-RAG的開源項目中提供了一個基于llama微調的模型selfrag_llama2_7b,希望將self-RAG應用于自身項目的同學,可以去看看這方面的內容。這就是self-RAG的流程原理,至于底層算法原理,有興趣朋友也可以進行論文深入研讀。
3 CRAG
在第二小節的self-RAG提出一種解決RAG痛點的流程框架,但是實際操作起來卻是有些難度,特別是微調帶有特殊token的模型,一說起微調就會是一個頭疼的問題,不僅僅數據準備費時費力,并且微調后的模型穩定性也不一定能達到預期效果。那么有沒有更為容易實現的簡便方式呢,答案就是CRAG。
相比于傳統的RAG,CRAG增加了一個用于矯正檢索到的文檔和用戶問題之間知識相關性的可插拔模塊。

從上圖我們可以看到,CRAG就是增加了一個評估大模型,對結果進行評估。評估結果如下:
- Correct:表示文檔與用戶問題有一定相關性的,但是doc其中仍會存在噪音或者過大問題,因此對文檔進行refine精簡。這里會對文檔進行叫做knowledge strips的操作,然后從中過濾出有用的 strip重新整合,最后得到矯正后的文檔。
- Incorrect:表示文檔對用戶問題并沒有相關性,需要引入新的知識源。這里引入 web searcher 從網上檢索相關信息,并從中選出有用的內容,最后得到矯正后的文檔。
- Ambiguous:表示評估大模型無法判斷文檔是否與用戶問題有關,就會同時做 Correct 和 Incorrect 時的動作。
相對于self-RAG來說,CRAG強調它是一種可插拔的設計模式,其中只是增加評估大模型,這個模型可以是微調模型,也可以是當今最好的大模型,比如ChatGPT。這使得在實際應用中,可能更為容易,當然,還有一點就是refine精簡,這也是CRAG論文的重要價值點之一。


和鎖定訪問(Locked Access))










模擬用戶登錄認證)

機制 | 超時重傳機制))



基本原理)