前言
- ?學習視頻:?Java項目《谷粒商城》架構師級Java項目實戰,對標阿里P6-P7,全網最強?
- 學習文檔:
- 谷粒商城-個人筆記(基礎篇一)
- 谷粒商城-個人筆記(基礎篇二)
- 谷粒商城-個人筆記(基礎篇三)
- 谷粒商城-個人筆記(高級篇一)
- 谷粒商城-個人筆記(高級篇二)
- 谷粒商城-個人筆記(高級篇三)
- 谷粒商城-個人筆記(高級篇四)
- 谷粒商城-個人筆記(高級篇五)
- 谷粒商城-個人筆記(集群部署篇一)
- 谷粒商城-個人筆記(集群部署篇二)
?3. 接口文檔:https://easydoc.net/s/78237135/ZUqEdvA4/hKJTcbfd
4. 本內容僅用于個人學習筆記,如有侵擾,聯系刪
五、MySQL 集群
0、集群簡介
-
集群的目標
- 高可用(High Availability),是當一臺服務器停止服務后,對于業務及用戶毫無影響。 停止服務的原因可能由于網卡、路由器、機房、CPU負載過高、內存溢出、自然災害等不可預期的原因導致,在很多時候也稱單點問題。
- 突破數據量限制,一臺服務器不能儲存大量數據,需要多臺分擔,每個存儲一部分,共同存儲完整個集群數據。最好能做到互相備份,即使單節點故障,也能在其他節點找到數據。
- 數據備份容災,單點故障后,存儲的數據仍然可以在別的地方拉起。
- 壓力分擔,由于多個服務器都能完成各自一部分工作,所以盡量的避免了單點壓力的存在
-
集群的基礎形式
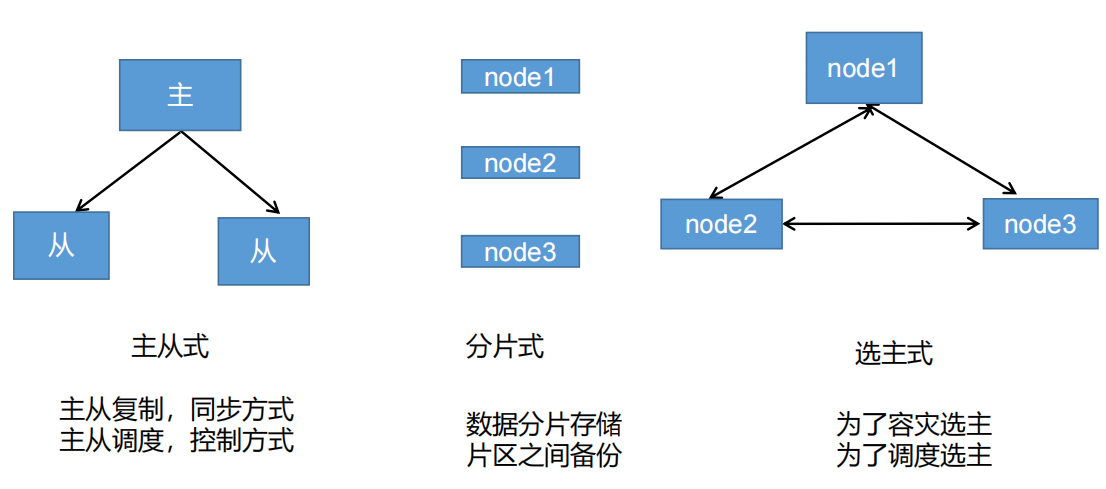
1、集群原理
以上可以作為企業中常用的數據庫解決方案;
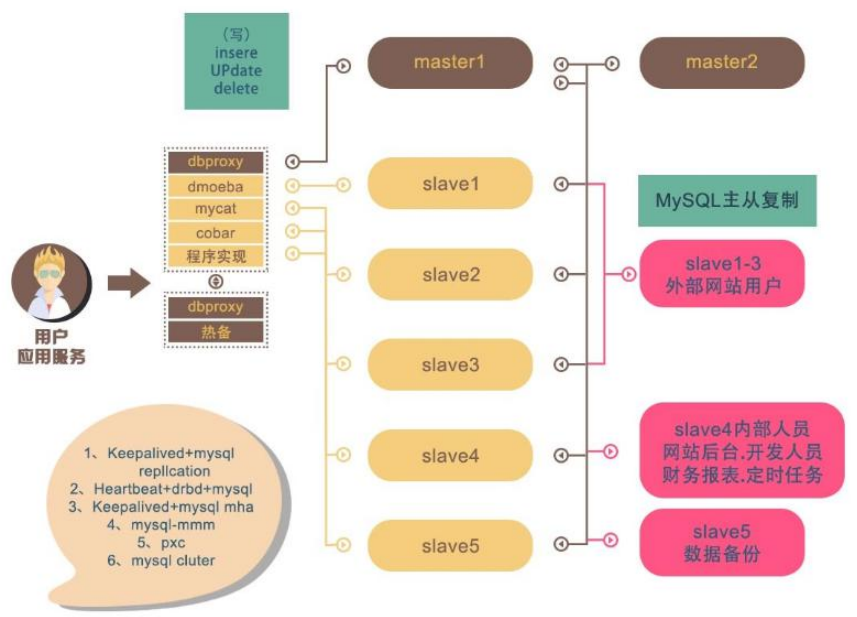
- MySQL-MMM 是 Master-Master Replication Manager for MySQL(mysql 主主復制管理器)的簡稱,是 Google 的開源項目(Perl 腳本)。MMM 基于 MySQL Replication 做的擴展架構,主要用來監控 mysql 主主復制并做失敗轉移。其原理是將真實數據庫節點的IP(RIP)映射為虛擬 IP(VIP)集。
mysql-mmm 的監管端會提供多個虛擬 IP(VIP),包括一個可寫 VIP,多個可讀 VIP,通過監管的管理,這些 IP 會綁定在可用 mysql 之上,當某一臺 mysql 宕機時,監管會將 VIP遷移至其他 mysql。在整個監管過程中,需要在 mysql 中添加相關授權用戶,以便讓 mysql 可以支持監理機的維護。授權的用戶包括一個mmm_monitor 用戶和一個 mmm_agent 用戶,如果想使用 mmm 的備份工具則還要添加一個 mmm_tools 用戶。
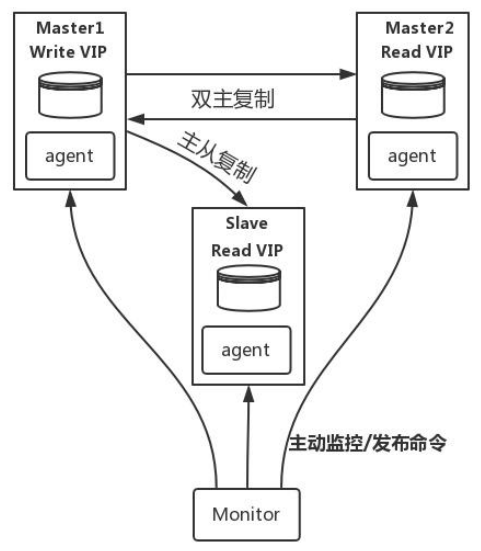
- MHA(Master High Availability)目前在 MySQL 高可用方面是一個相對成熟的解決方案, 由日本 DeNA 公司 youshimaton(現就職于 Facebook 公司)開發,是一套優秀的作為MySQL高可用性環境下故障切換和主從提升的高可用軟件。在MySQL故障切換過程中,MHA 能做到在 0~30 秒之內自動完成數據庫的故障切換操作(以 2019 年的眼光來說太慢了),并且在進行故障切換的過程中,MHA 能在最大程度上保證數據的一致性,以達到真正意義上的高可用。
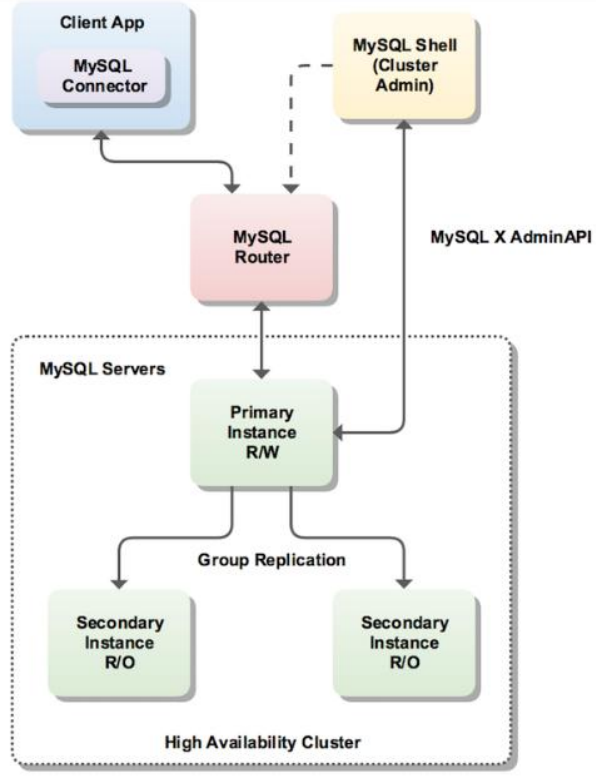
- InnoDB Cluster 支持自動 Failover、強一致性、讀寫分離、讀庫高可用、讀請求負載均衡,橫向擴展的特性,是比較完備的一套方案。但是部署起來復雜,想要解決 router單點問題好需要新增組件,如沒有其他更好的方案可考慮該方案。 InnoDB Cluster 主要由 MySQL Shell、MySQL Router 和 MySQL 服務器集群組成,三者協同工作,共同為MySQL 提供完整的高可用性解決方案。MySQL Shell 對管理人員提供管理接口,可以很方便的對集群進行配置和管理,MySQL Router 可以根據部署的集群狀況自動的初始化,是客戶端連接實例。如果有節點 down 機,集群會自動更新配置。集群包含單點寫入和多點寫入兩種模式。在單主模式下,如果主節點 down 掉,從節點自動替換上來,MySQL Router 會自動探測,并將客戶端連接到新節點。
2、Docker 安裝模擬 MySQL 主從復制集群
2.1、下載 mysql 鏡像
docker pull mysql:5.7
2.2、創建 Master 實例并啟動
docker run -p 3307:3306 --name mysql-master \
-v /mydata/mysql/master/log:/var/log/mysql \
-v /mydata/mysql/master/data:/var/lib/mysql \
-v /mydata/mysql/master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
參數說明:
- -p 3307:3306:將容器的 3306 端口映射到主機的 3307 端口
- -v /mydata/mysql/master/conf:/etc/mysql:將配置文件夾掛在到主機
- -v /mydata/mysql/master/log:/var/log/mysql:將日志文件夾掛載到主機
- -v /mydata/mysql/master/data:/var/lib/mysql/:將配置文件夾掛載到主機
- -e MYSQL_ROOT_PASSWORD=root:初始化 root 用戶的密碼
修改 master 基本配置
vim /mydata/mysql/master/conf/my.cnf
[client]
default-character-set=utf8[mysql]
default-character-set=utf8[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
skip-character-set-client-handshake
skip-name-resolve
# 注意:skip-name-resolve 一定要加,不然連接 mysql 會超級慢
添加 master 主從復制部分配置
vim /mydata/mysql/master/conf/my.cnf
server_id=1
log-bin=mysql-bin
read-only=0
binlog-do-db=gulimall_ums
binlog-do-db=gulimall_pms
binlog-do-db=gulimall_oms
binlog-do-db=gulimall_sms
binlog-do-db=gulimall_wms
binlog-do-db=gulimall_admin
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
重啟 master
docker restart mysql-master
2.3、創建 Slave 實例并啟動
docker run -p 3317:3306 --name mysql-slaver-01 \
-v /mydata/mysql/slaver/log:/var/log/mysql \
-v /mydata/mysql/slaver/data:/var/lib/mysql \
-v /mydata/mysql/slaver/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
修改 slave 基本配置
vim /mydata/mysql/slaver/conf/my.cnf
[client]
default-character-set=utf8[mysql]
default-character-set=utf8[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
skip-character-set-client-handshake
skip-name-resolve
添加 master 主從復制部分配置
vim /mydata/mysql/slaver/conf/my.cnf
server_id=2
log-bin=mysql-bin
read-only=1
binlog-do-db=gulimall_ums
binlog-do-db=gulimall_pms
binlog-do-db=gulimall_oms
binlog-do-db=gulimall_sms
binlog-do-db=gulimall_wms
binlog-do-db=gulimall_admin
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
重啟 slaver
docker restart mysql-slaver-01
2.4、為 master 授權用戶來他的同步數據
直接用navicat連接mysql-master數據庫執行步驟2.2、3就可以
#1、進入 master 容器
docker exec -it mysql /bin/bash
#2、進入 mysql 內部 (mysql –uroot -p)
#2.1、授權 root 可以遠程訪問( 主從無關,為了方便我們遠程連接 mysql)
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
#2.2、添加用來同步的用戶
GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';
#3、查看 master 狀態
show master status;

2.5、配置 slaver 同步 master 數據
#1、進入 slaver 容器
docker exec -it mysql-slaver-01 /bin/bash
#2、進入 mysql 內部(mysql –uroot -p)
#2.1、授權 root 可以遠程訪問( 主從無關,為了方便我們遠程連接 mysql)
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
#2.2、設置主庫連接
change master to master_host='192.168.119.127',master_user='backup',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=0,master_port=3307;
#3、啟動從庫同步
start slave;
#4、查看從庫狀態
show slave status;
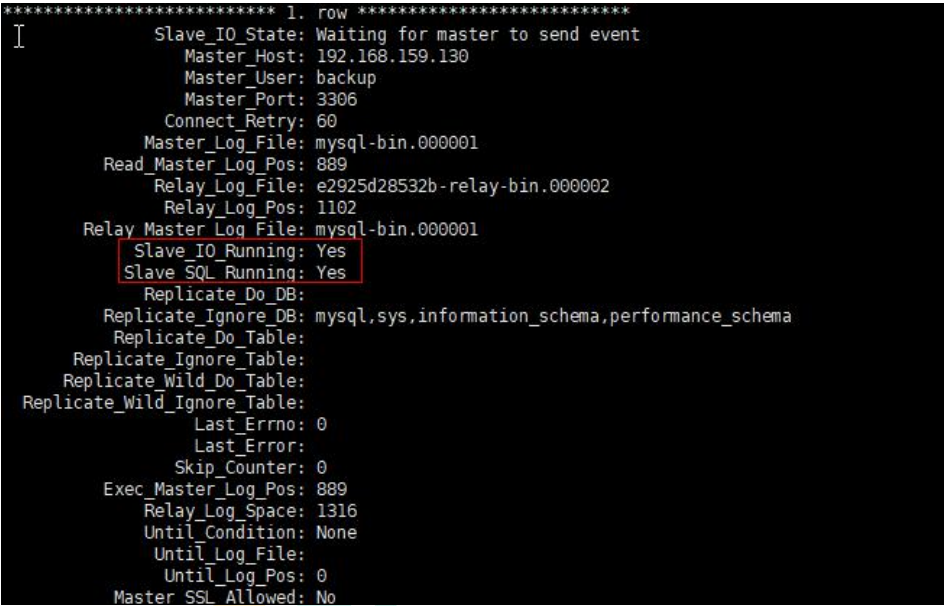
至此主從配置完成;
總結:
- 主從數據庫在自己配置文件中聲明需要同步哪個數據庫,忽略哪個數據庫等信息。并且 server-id 不能一樣
- 主庫授權某個賬號密碼來同步自己的數據
- 從庫使用這個賬號密碼連接主庫來同步數據
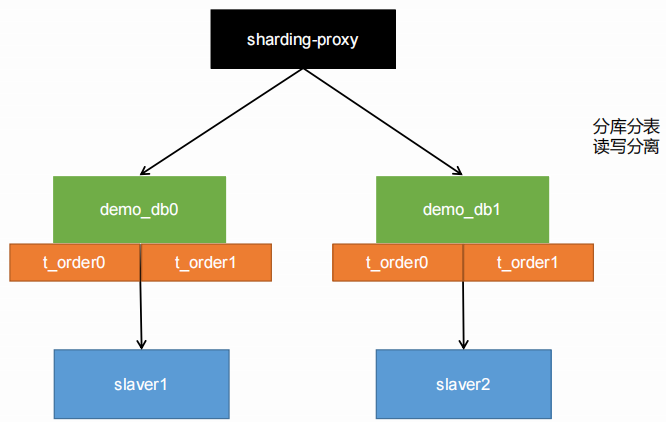
3、MyCat 或者 ShardingSphere
shardingSphere: https://shardingsphere.apache.org/index_zh.html
auto_increment_offset: 1 從幾開始增長
auto_increment_increment: 2 每次的步長
簡介
Apache ShardingSphere 是一款分布式的數據庫生態系統, 可以將任意數據庫轉換為分布式數據庫,并通過數據分片、彈性伸縮、加密等能力對原有數據庫進行增強。
Apache ShardingSphere 設計哲學為 Database Plus,旨在構建異構數據庫上層的標準和生態。 它關注如何充分合理地利用數據庫的計算和存儲能力,而并非實現一個全新的數據庫。 它站在數據庫的上層視角,關注它們之間的協作多于數據庫自身。
-
ShardingSphere-JDBC
ShardingSphere-JDBC 定位為輕量級 Java 框架,在 Java 的 JDBC 層提供的額外服務。 -
ShardingSphere-Proxy
ShardingSphere-Proxy 定位為透明化的數據庫代理端,通過實現數據庫二進制協議,對異構語言提供支持。
3.1、下載安裝 Sharding-Proxy
-
鏡像方式
docker pull apache/sharding-proxydocker run -d -v /mydata/sharding-proxy/conf:/opt/sharding-proxy/conf -v /mydata/sharding-proxy/lib:/opt/sharding-proxy/lib --env PORT=3308 -p13308:3308 apache/sharding-proxy:latest -
壓縮包下載
https://shardingsphere.apache.org/document/current/cn/downloads/
3.2、server.yaml 文件
authentication:users:root:password: rootsharding:password: sharding authorizedSchemas: sharding_db
#
props:
# max.connections.size.per.query: 1
# acceptor.size: 16 # The default value is available processors count * 2.executor.size: 16 # Infinite by default.
# proxy.frontend.flush.threshold: 128 # The default value is 128.
# # LOCAL: Proxy will run with LOCAL transaction.
# # XA: Proxy will run with XA transaction.
# # BASE: Proxy will run with B.A.S.E transaction.
# proxy.transaction.type: LOCAL
# proxy.opentracing.enabled: false
# query.with.cipher.column: truesql.show: false
3.3、配置數據分片+讀寫分離
-
數據分片 - config-sharding.yaml
###################################################################################################### # # If you want to connect to MySQL, you should manually copy MySQL driver to lib directory. # ######################################################################################################schemaName: sharding_db # dataSources:ds_0:url: jdbc:mysql://192.168.119.127:3307/demo_ds_0?serverTimezone=UTC&useSSL=falseusername: rootpassword: rootconnectionTimeoutMilliseconds: 30000idleTimeoutMilliseconds: 60000maxLifetimeMilliseconds: 1800000maxPoolSize: 50ds_1:url: jdbc:mysql://192.168.119.127:3307/demo_ds_1?serverTimezone=UTC&useSSL=falseusername: rootpassword: rootconnectionTimeoutMilliseconds: 30000idleTimeoutMilliseconds: 60000maxLifetimeMilliseconds: 1800000maxPoolSize: 50 # shardingRule:tables:t_order:actualDataNodes: ds_${0..1}.t_order_${0..1}tableStrategy:inline:shardingColumn: order_idalgorithmExpression: t_order_${order_id % 2}keyGenerator:type: SNOWFLAKEcolumn: order_idt_order_item:actualDataNodes: ds_${0..1}.t_order_item_${0..1}tableStrategy:inline:shardingColumn: order_idalgorithmExpression: t_order_item_${order_id % 2}keyGenerator:type: SNOWFLAKEcolumn: order_item_idbindingTables:- t_order,t_order_itemdefaultDatabaseStrategy:inline:shardingColumn: user_idalgorithmExpression: ds_${user_id % 2}defaultTableStrategy:none: -
讀寫分離
-
config-master_slave.yaml
###################################################################################################### # # If you want to connect to MySQL, you should manually copy MySQL driver to lib directory. # ######################################################################################################schemaName: sharding_db_1 # dataSources:master_0_ds:url: jdbc:mysql://192.168.119.127:3307/demo_ds_0?serverTimezone=UTC&useSSL=falseusername: rootpassword: rootconnectionTimeoutMilliseconds: 30000idleTimeoutMilliseconds: 60000maxLifetimeMilliseconds: 1800000maxPoolSize: 50slave_ds_0:url: jdbc:mysql://192.168.119.127:3317/demo_ds_0?serverTimezone=UTC&useSSL=falseusername: rootpassword: rootconnectionTimeoutMilliseconds: 30000idleTimeoutMilliseconds: 60000maxLifetimeMilliseconds: 1800000maxPoolSize: 50 masterSlaveRule:name: ms_dsmasterDataSourceName: master_0_dsslaveDataSourceNames:- slave_ds_0 # - slave_ds_1 # - slave_ds_1 -
config-master_slave_2.yaml
###################################################################################################### # # If you want to connect to MySQL, you should manually copy MySQL driver to lib directory. # ######################################################################################################schemaName: sharding_db_2 # dataSources:master_1_ds:url: jdbc:mysql://192.168.119.127:3307/demo_ds_1?serverTimezone=UTC&useSSL=falseusername: rootpassword: rootconnectionTimeoutMilliseconds: 30000idleTimeoutMilliseconds: 60000maxLifetimeMilliseconds: 1800000maxPoolSize: 50slave_ds_1:url: jdbc:mysql://192.168.119.127:3317/demo_ds_1?serverTimezone=UTC&useSSL=falseusername: rootpassword: rootconnectionTimeoutMilliseconds: 30000idleTimeoutMilliseconds: 60000maxLifetimeMilliseconds: 1800000maxPoolSize: 50 masterSlaveRule:name: ms_ds_1masterDataSourceName: master_1_dsslaveDataSourceNames:- slave_ds_1 # - slave_ds_1 # - slave_ds_1
-
3.4、修改
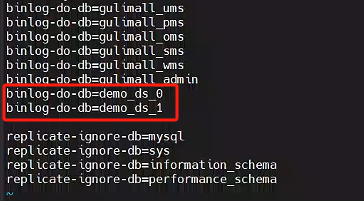
修改mysql-master和mysql-slaver-01服務的my.cnf,添加我們ShardingSphere配置的數據庫
binlog-do-db=demo_ds_0
binlog-do-db=demo_ds_1
重啟數據庫
docker restart mysql-master mysql-slaver-01
mysql-master和mysql-slaver-01連接創建兩個庫demo_ds_0、demo_ds_1
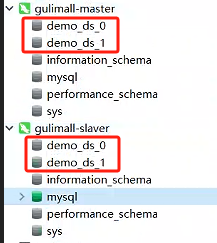
進入sharding-proxy的bin目錄下cmd 輸入start.bat 3388指定端口號
D:\ShardingSphere\apache-shardingsphere-incubating-4.0.0-sharding-proxy-bin\bin>start.bat 3388

在sharding_db創建測試表
CREATE TABLE `t_order` (
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`status` varchar(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE TABLE `t_order_item` (
`order_item_id` bigint(20) NOT NULL,
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`content` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`status` varchar(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`order_item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
4、k8s 有狀態服務部署
可以使用 kubesphere,快速搭建 MySQL 環境。
- 有狀態服務抽取配置為 ConfigMap
- 有狀態服務必須使用 pvc 持久化數據
- 服務集群內訪問使用 DNS 提供的穩定域名
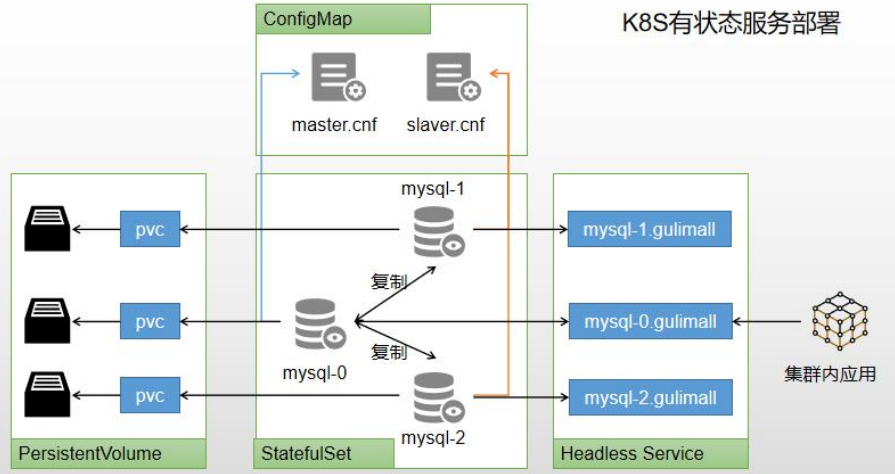
具體搭建流程:
4.1、 mysql-master(mysql主節點)
4.1.1、創建配置 - mysql-mster-cnf
我們把mysql配置的配置文件也單獨掛在出來,先關閉服務創建,點擊 配置中心 -》配置,創建mysql-mster-cnf文件
-
填寫基本信息
- 名稱:mysql-mster-cnf
- 別名:mysql配置
-
配置設置
- 鍵:
my.cnf - 值:
[client] default-character-set=utf8[mysql] default-character-set=utf8[mysqld] init_connect='SET collation_connection = utf8_unicode_ci' init_connect='SET NAMES utf8' character-set-server=utf8 skip-character-set-client-handshake skip-name-resolveserver_id=1 log-bin=mysql-bin read-only=0 binlog-do-db=gulimall_ums binlog-do-db=gulimall_pms binlog-do-db=gulimall_oms binlog-do-db=gulimall_sms binlog-do-db=gulimall_wms binlog-do-db=gulimall_admin replicate-ignore-db=mysql replicate-ignore-db=sys replicate-ignore-db=information_schema replicate-ignore-db=performance_schema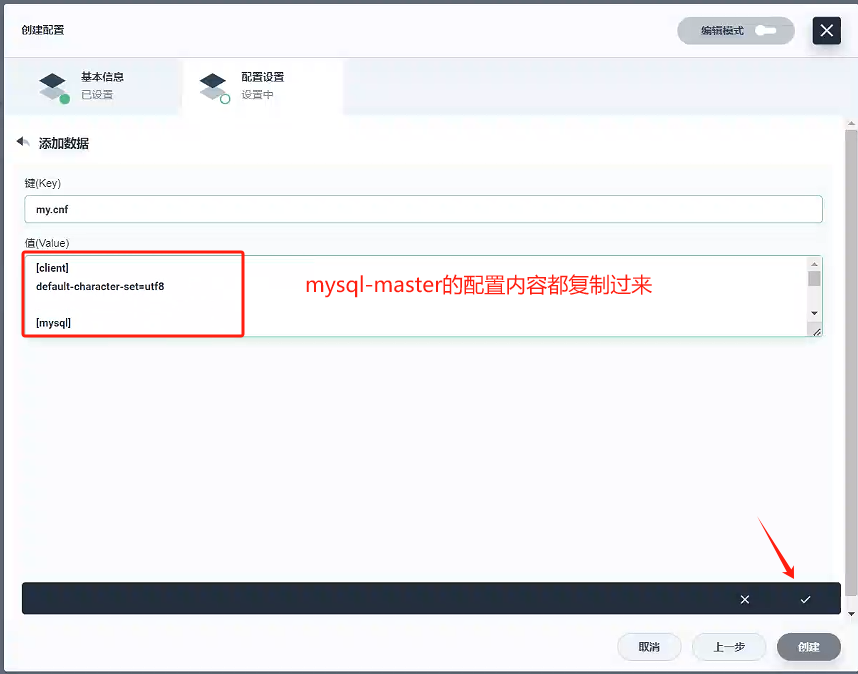
- 鍵:
-
創建
4.1.2、創建存儲卷 - gulimall-mysql-master-pvc
創建名稱為gulimall-mysql-master-pvc的存儲卷
4.1.3、創建服務-gulimall-mysql-master
-
選擇有狀態服務
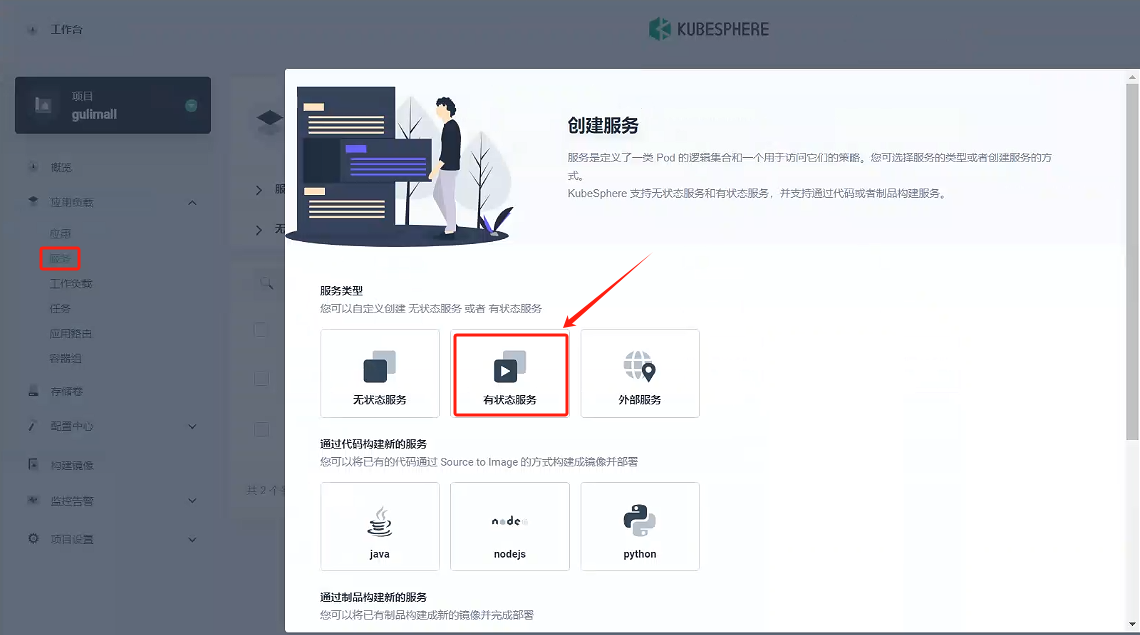
-
填寫基本信息
- 名稱:gulimall-mysql-master
- 別名:mysql主節點
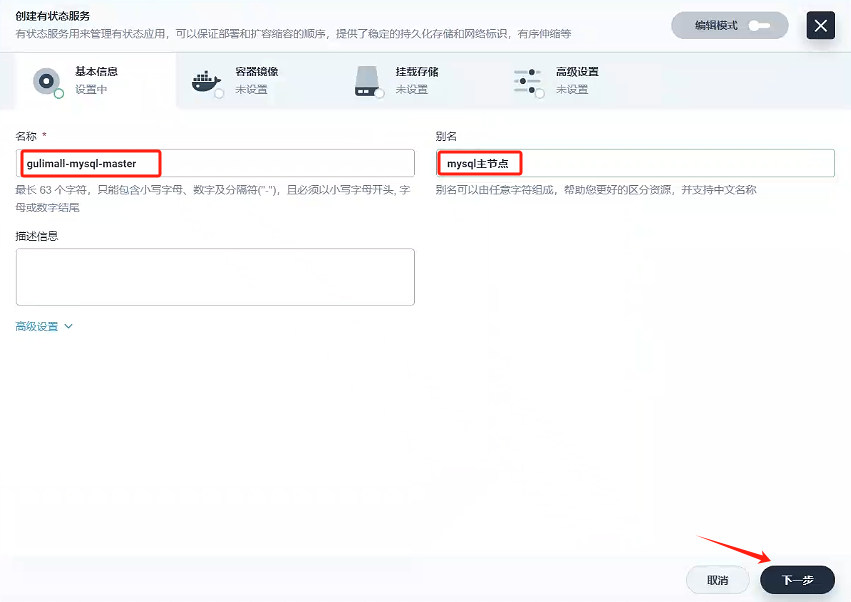
-
容器鏡像
- 容器組選擇分散部署
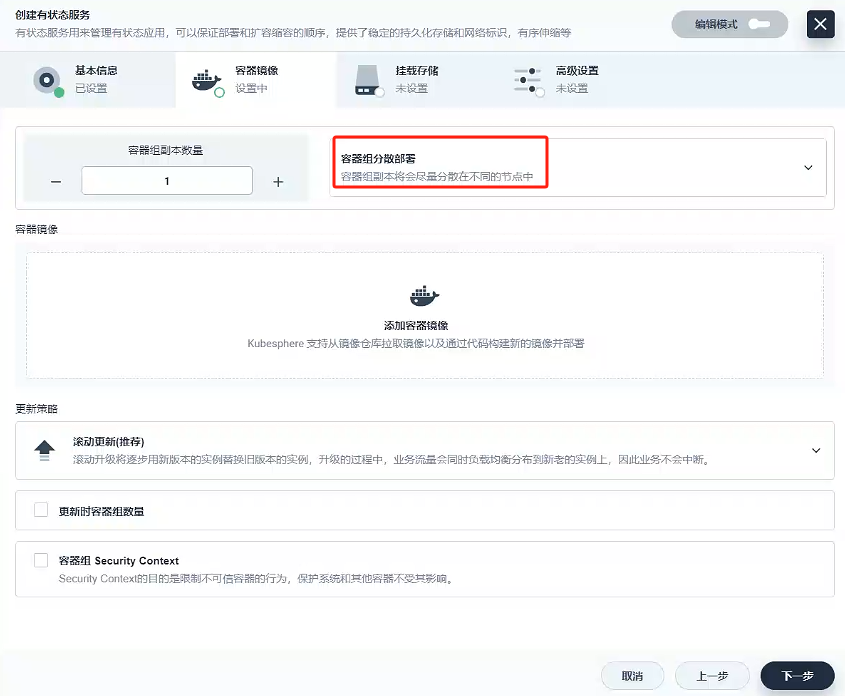
- 添加容器鏡像
這里我們使用的私有鏡像倉庫-Harbor創建容器,使用默認端口,內存要大于1000M,環境變量選擇原先配置好的MYSQL_ROOT_PASSWORD
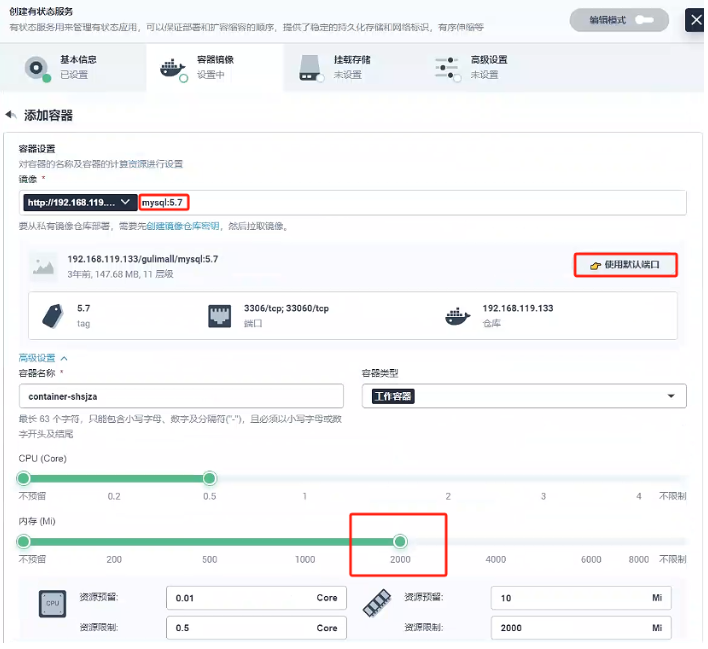
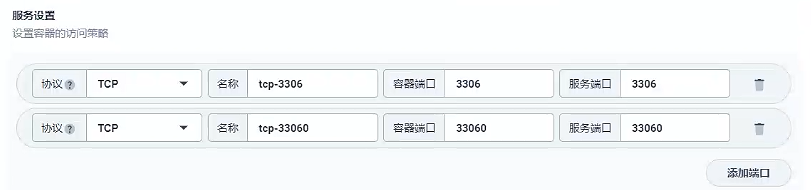
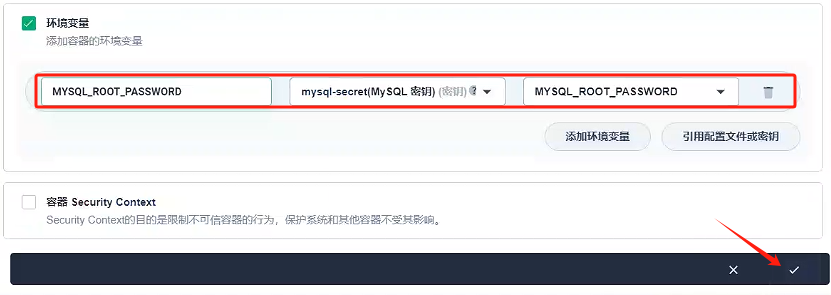
- 容器組選擇分散部署
-
掛載存儲
-
掛載配置文件
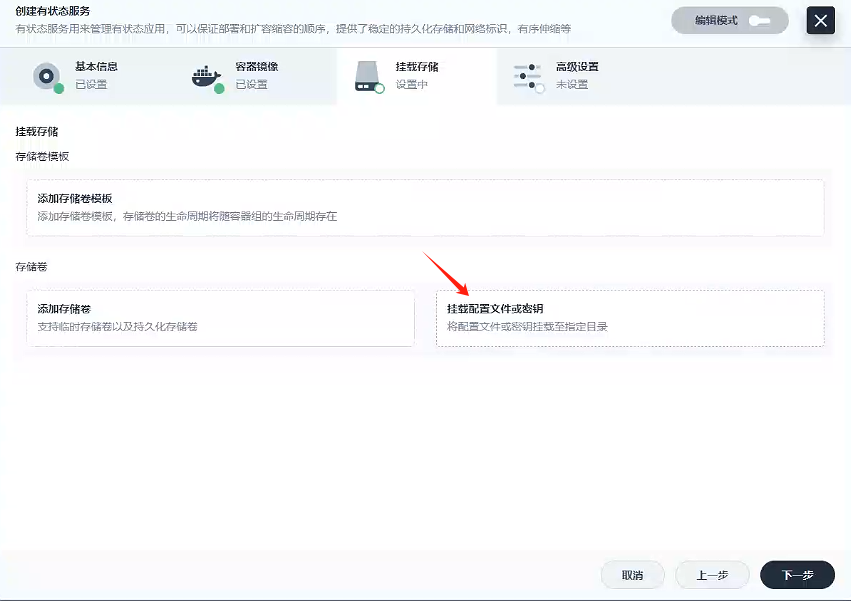
首先,選擇我們先前配置好的配置文件:mysql-master-cnf,然后選擇讀寫模式 ,我們查看原先docker創建mysql-master,發現我們以前掛載mysql的配置都是/etc/mysql下的,所以我們路徑填寫/etc/mysql,然后點擊√
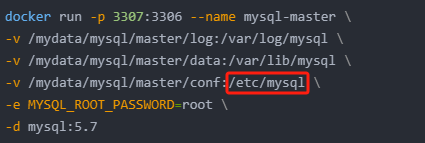
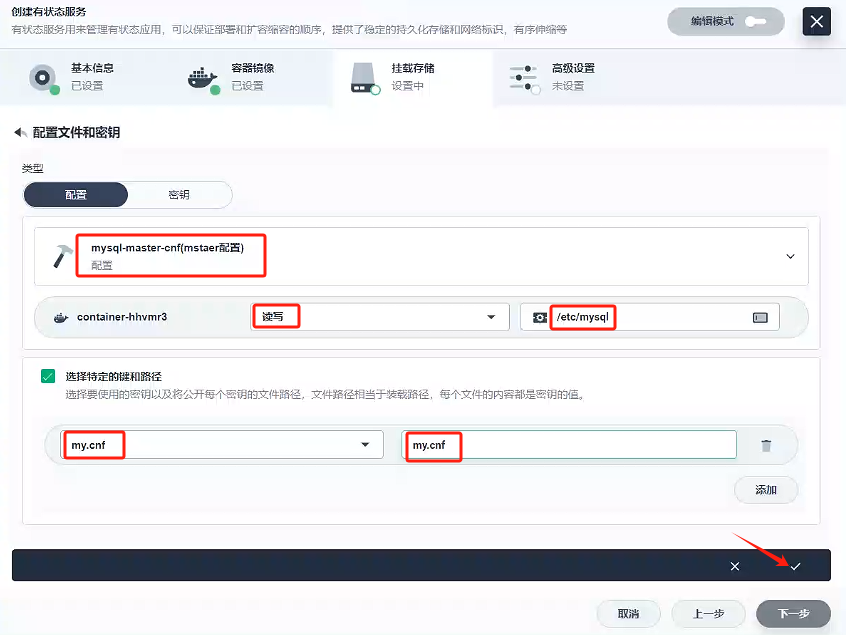
-
添加存儲卷
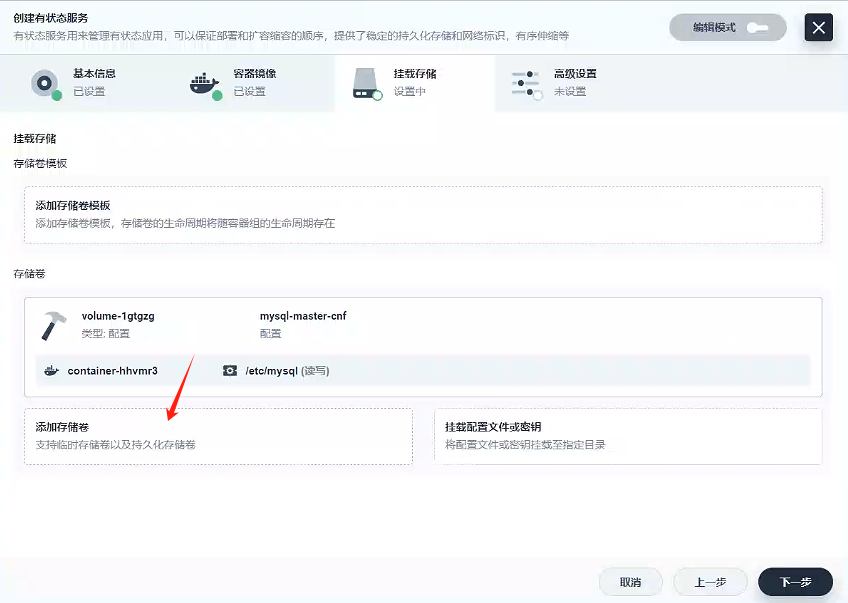
首先,選擇我們先前創建好的存儲卷:gulimall-mysql-master-pvc,然后選擇讀寫模式,我們查看原先docker創建mysql-master,發現我們以前掛載mysql的數據都是/var/lib/mysql下的,所以我們路徑填寫/var/lib/mysql,然后點擊√
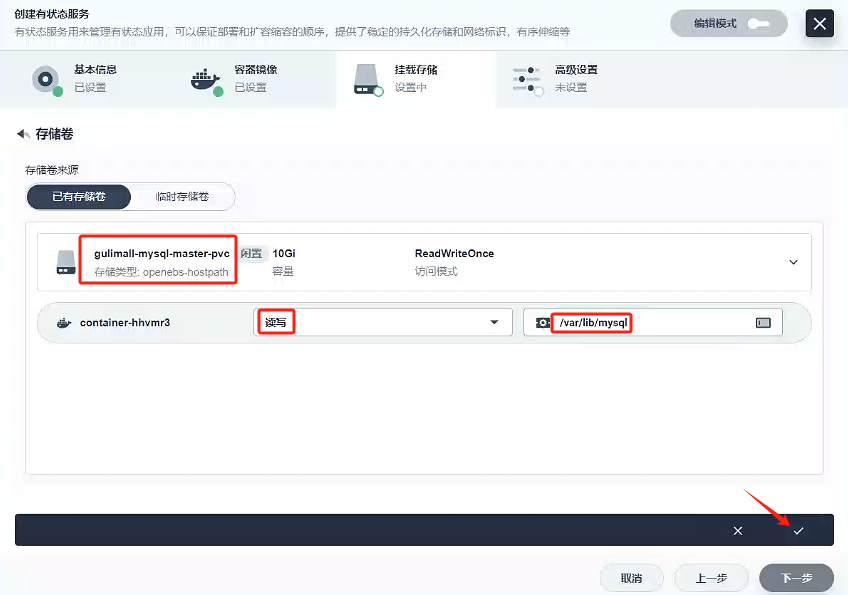
-
-
點擊下一步
-
點擊創建
-
至此,gulimall-mysql-master服務創建完成
4.1.4、測試
-
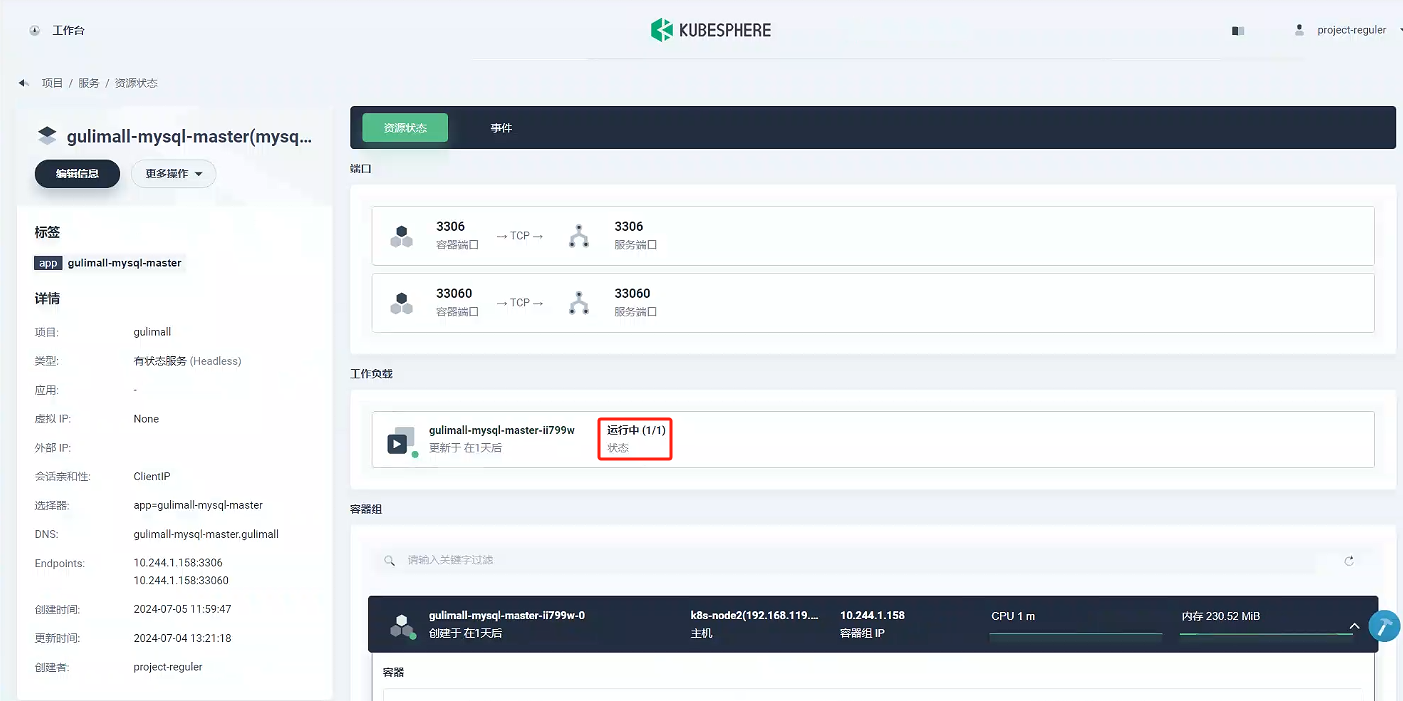
驗證容器是否創建成功
點擊gulimall-mysql-master,進去之后我們可以看到服務是運行中,代表服務創建成功。
-
驗證創建的mysql-master服務是否正確
進入容器組的
gulimall-mysql-master-ii799w-0
點擊終端,進入容器內部,查看配置是否是我們配置的內容,可以看到my.conf正是我們的配置
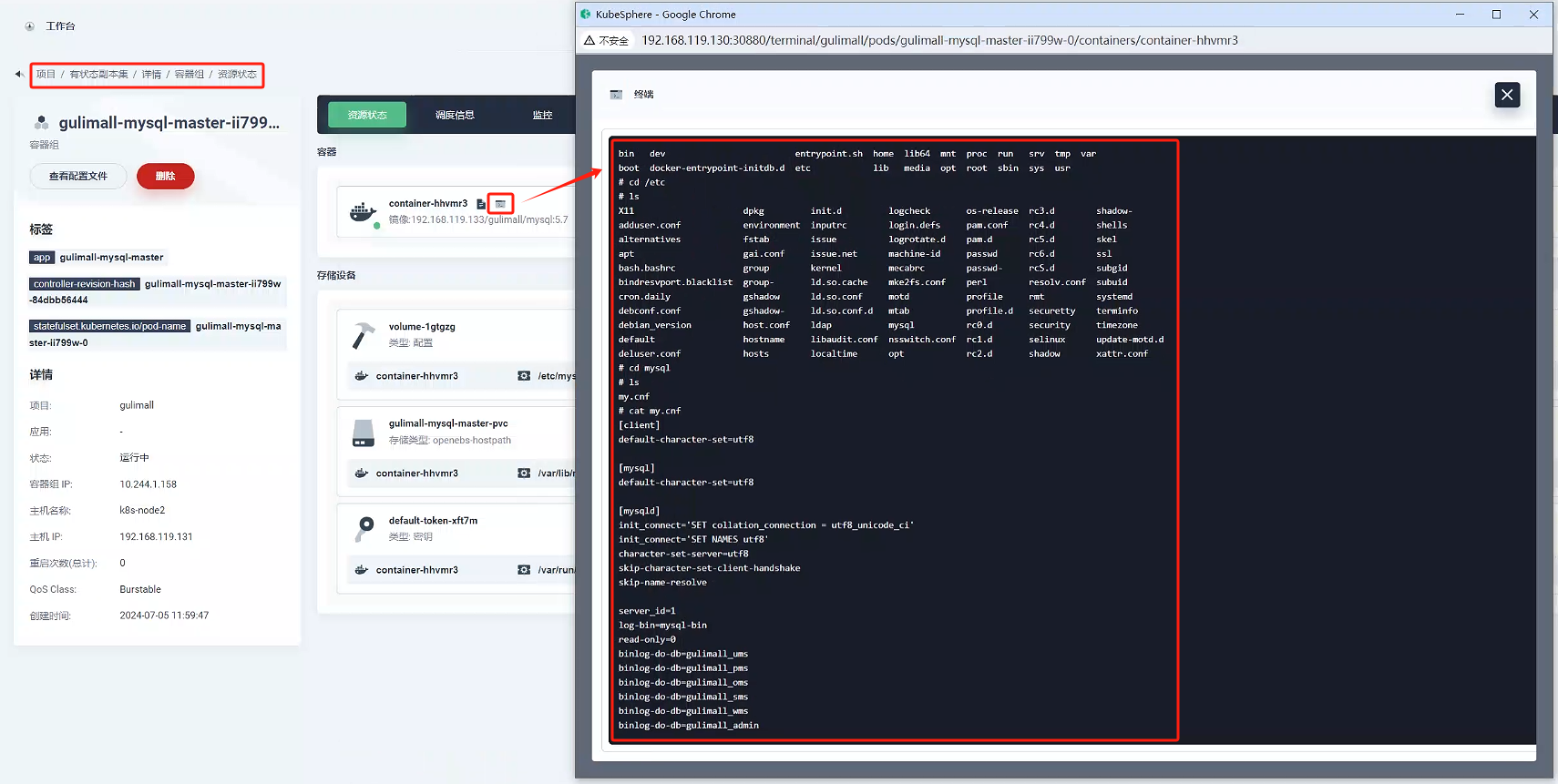
-
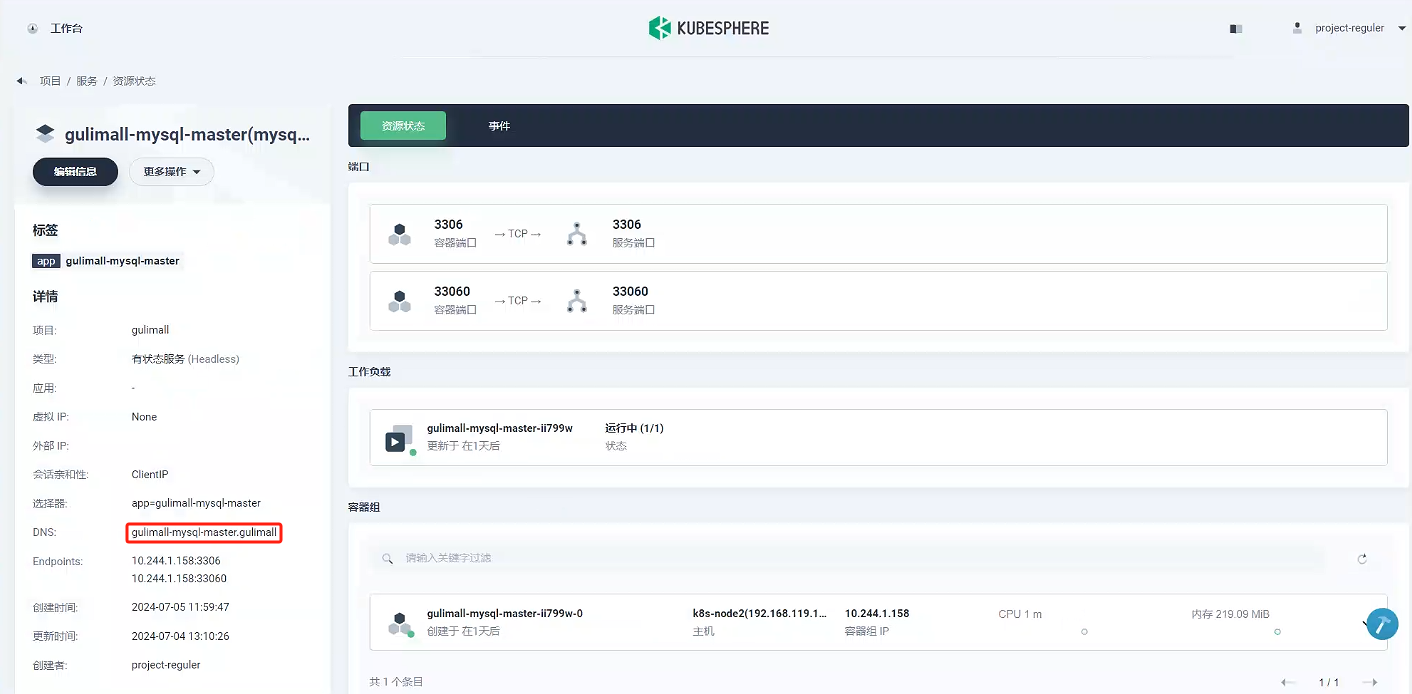
驗證其他服務是否能ping通
我們看到gulimall-mysql-master服務的DNS為gulimall-mysql-master.gulimall,我們在kubespere找一個其他服務進行測試,看看是否能ping通。
點擊 worpress服務 -》容器組 -》wordpress-v1-5d8b597899-xz5cn,進入頁面,然后點擊左上角的終端
ping gulimall-mysql-master.gulimall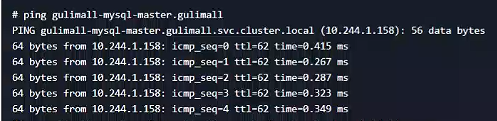
結果看到可以ping通。
4.2、 mysql-slaver(mysql從節點)
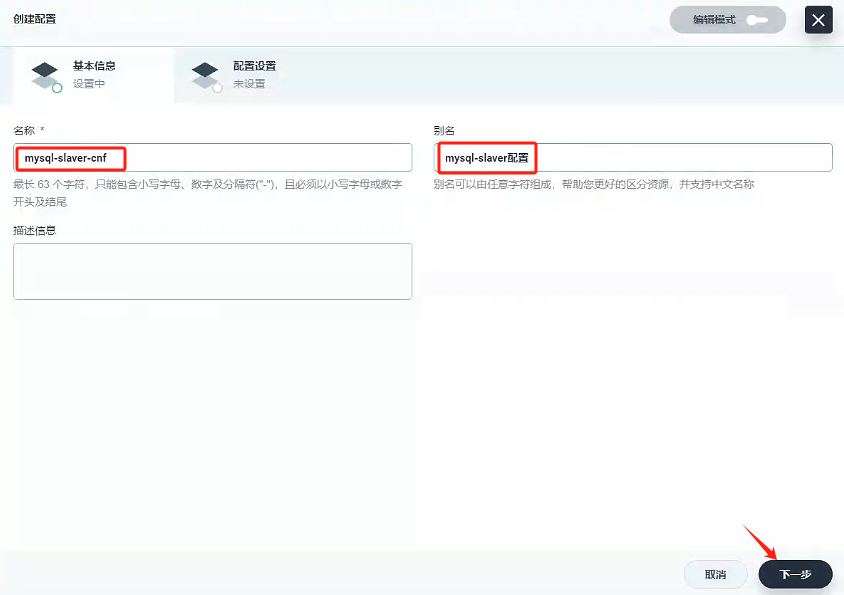
4.2.1、創建配置 - mysql-slaver-cnf
我們把mysql配置的配置文件也單獨掛在出來,先關閉服務創建,點擊 配置中心 -》配置,創建mysql-mster-cnf文件
- 填寫基本信息
- 名稱:mysql-slaver-cnf
- 別名:mysql-slaver配置
2. 配置設置
-
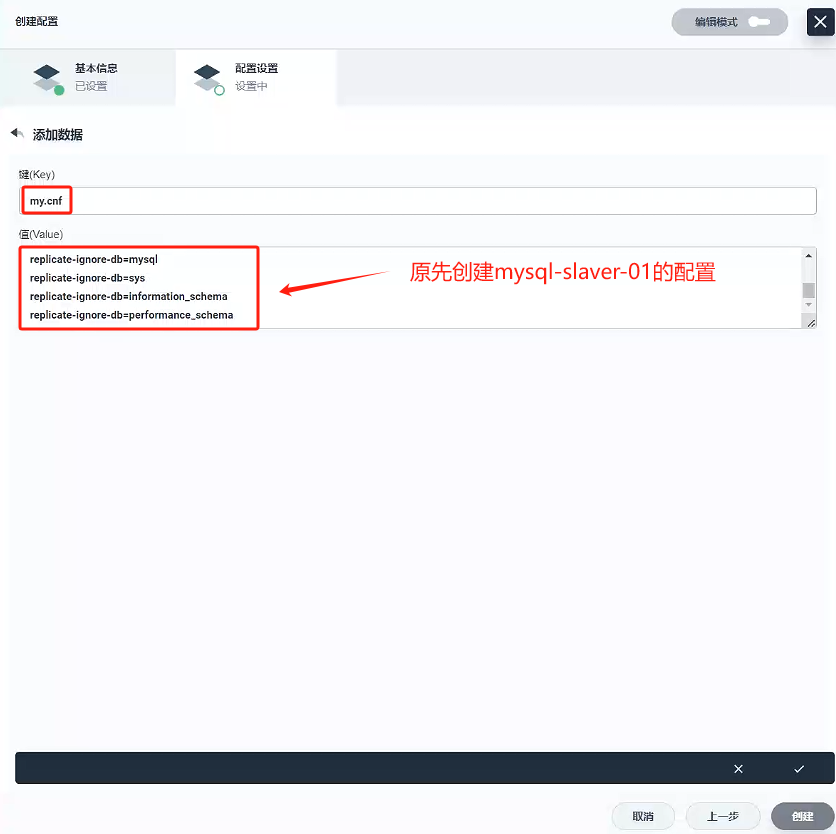
鍵:
my.cnf -
值:
[client] default-character-set=utf8[mysql] default-character-set=utf8[mysqld] init_connect='SET collation_connection = utf8_unicode_ci' init_connect='SET NAMES utf8' character-set-server=utf8 skip-character-set-client-handshake skip-name-resolveserver_id=2 log-bin=mysql-bin read-only=1 binlog-do-db=gulimall_ums binlog-do-db=gulimall_pms binlog-do-db=gulimall_oms binlog-do-db=gulimall_sms binlog-do-db=gulimall_wms binlog-do-db=gulimall_admin replicate-ignore-db=mysql replicate-ignore-db=sys replicate-ignore-db=information_schema replicate-ignore-db=performance_schema
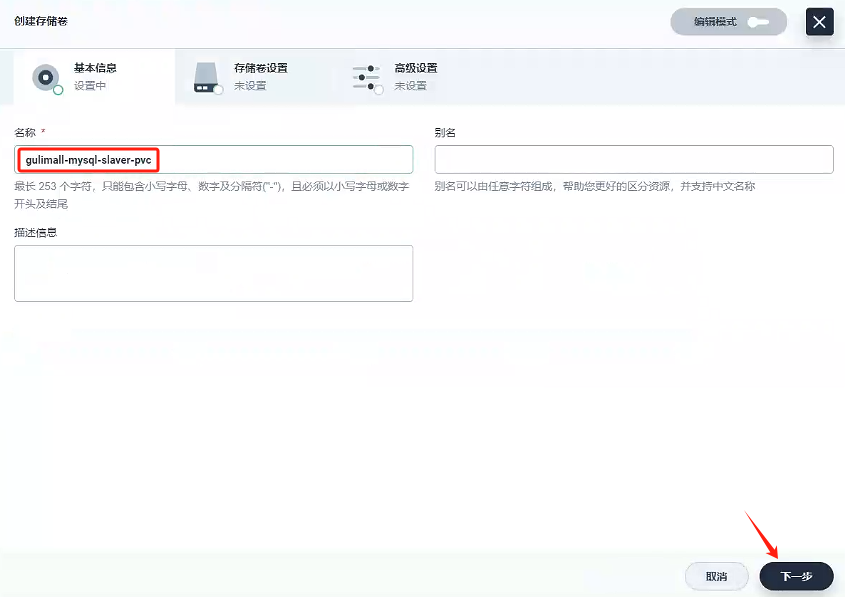
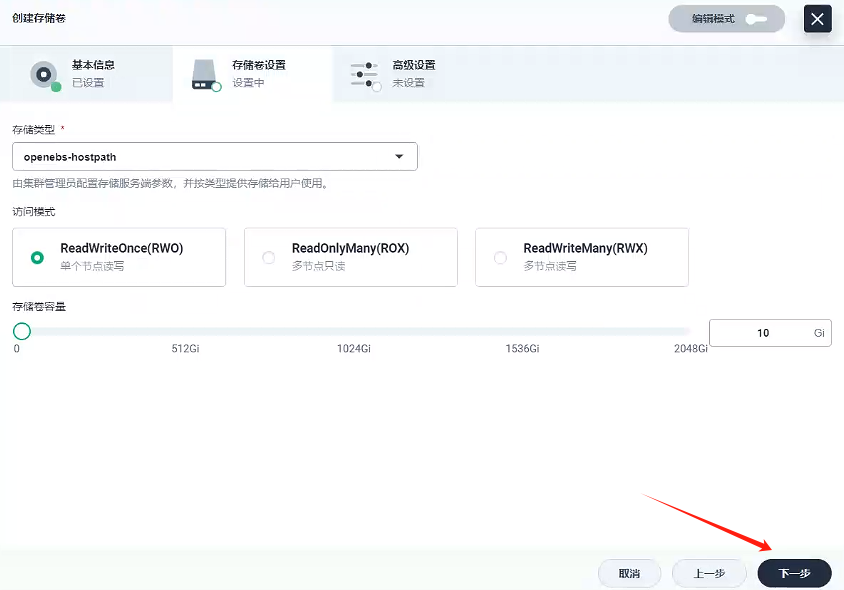
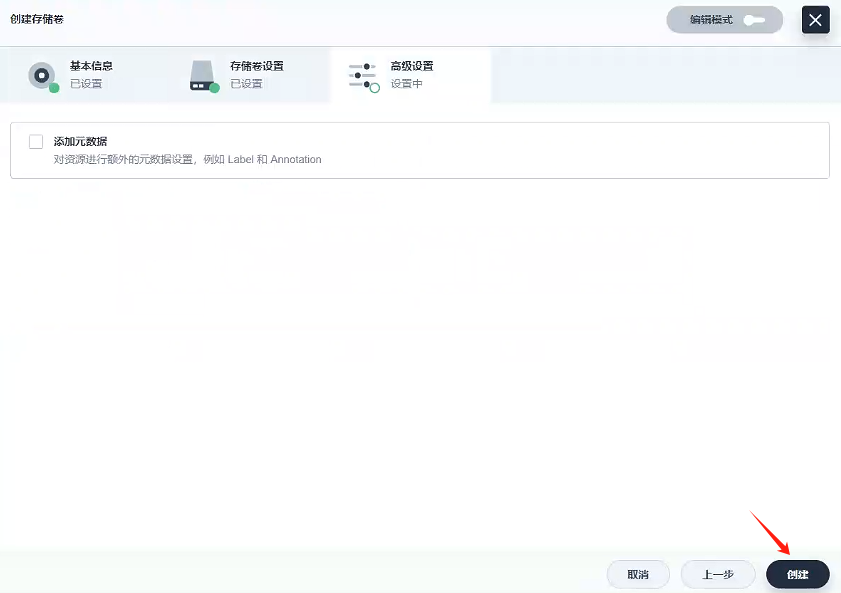
4.2.2、創建存儲卷 - gulimall-mysql-slaver-pvc
創建名稱為gulimall-mysql-slaver-pvc的存儲卷
4.2.3、創建服務-gulimall-mysql-master
-
選擇有狀態服務
-
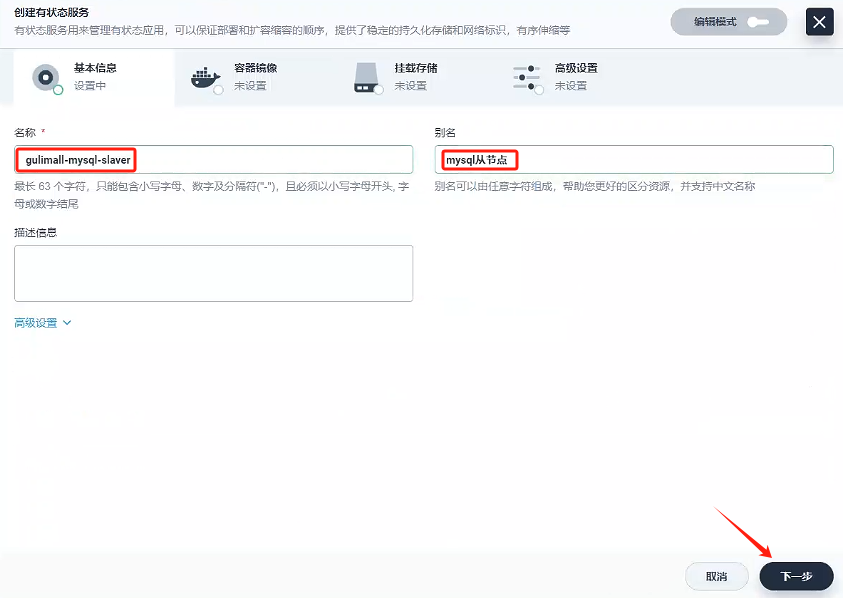
填寫基本信息
- 名稱:gulimall-mysql-slaver
- 別名:mysql從節點
-
容器鏡像
-
容器組選擇分散部署
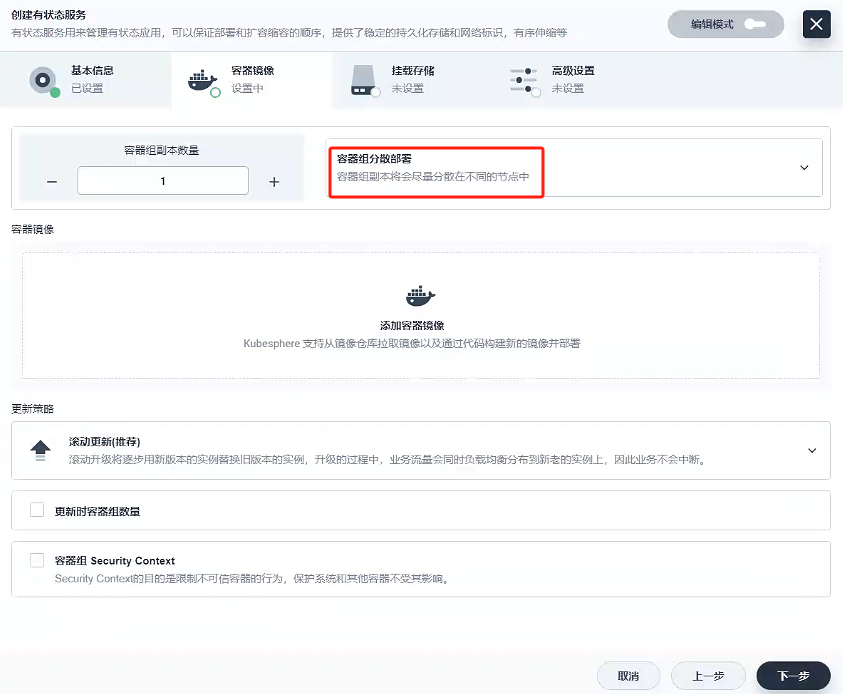
-
添加容器鏡像
這里我們使用的私有鏡像倉庫-Harbor創建容器,使用默認端口,內存要大于1000M,環境變量選擇原先配置好的MYSQL_ROOT_PASSWORD
-
-
掛載存儲
-
掛載配置文件
首先,選擇我們先前配置好的配置文件:mysql-slaver-cnf,然后選擇讀寫模式 ,我們查看原先docker創建mysql-slaver-01,發現我們以前掛載mysql的配置都是/etc/mysql下的,所以我們路徑填寫/etc/mysql,然后點擊√
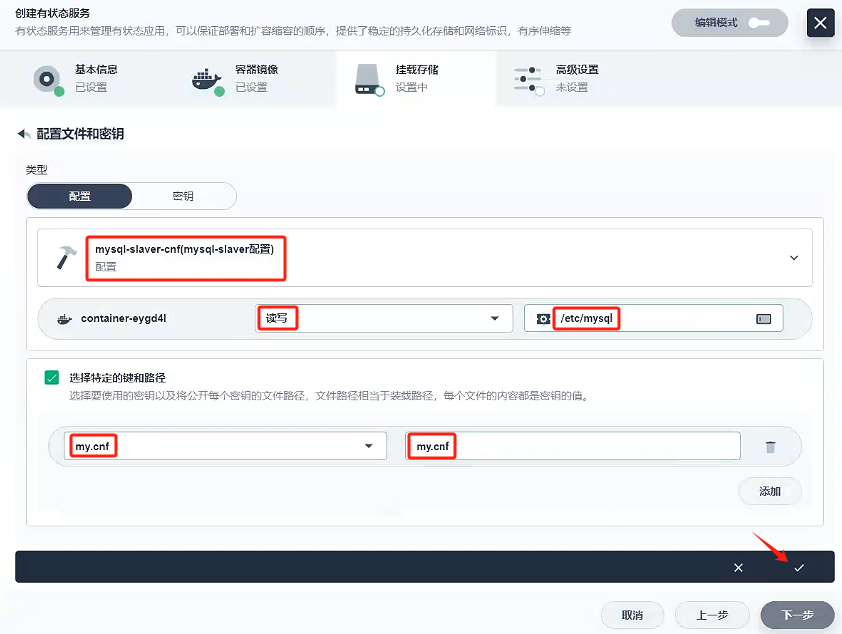
-
添加存儲卷
首先,選擇我們先前創建好的存儲卷:gulimall-mysql-slaver-pvc,然后選擇讀寫模式,我們查看原先docker創建mysql-slaver-01,發現我們以前掛載mysql的數據都是/var/lib/mysql下的,所以我們路徑填寫/var/lib/mysql,然后點擊√
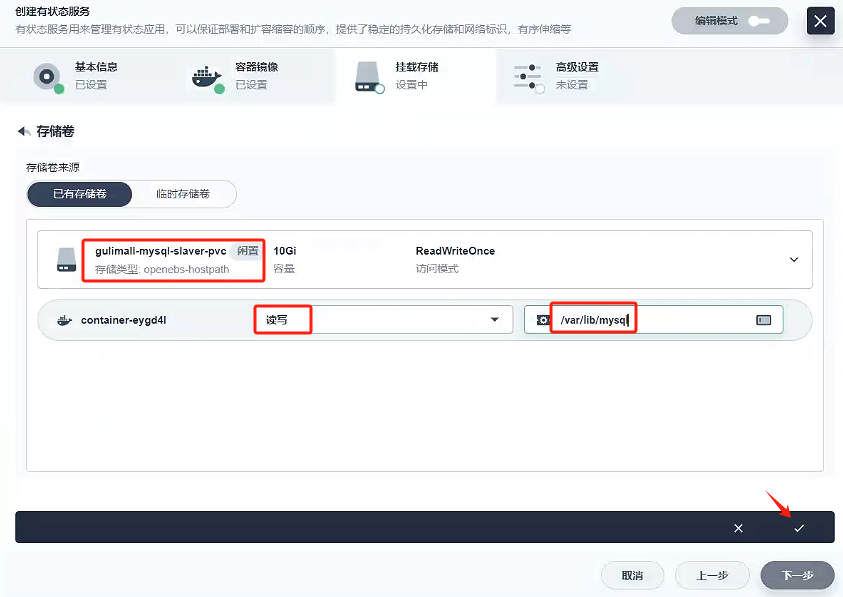
-
-
點擊下一步
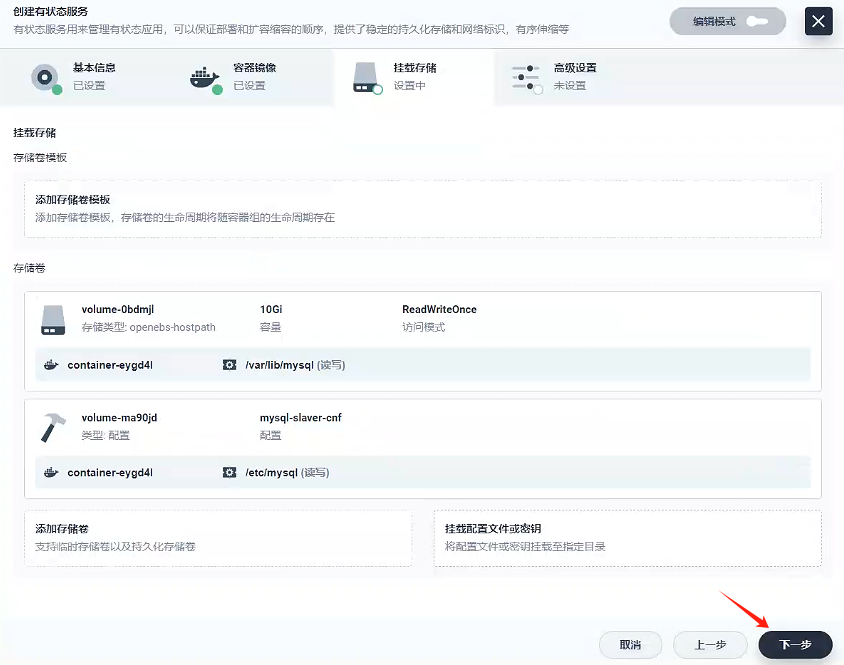
-
點擊創建
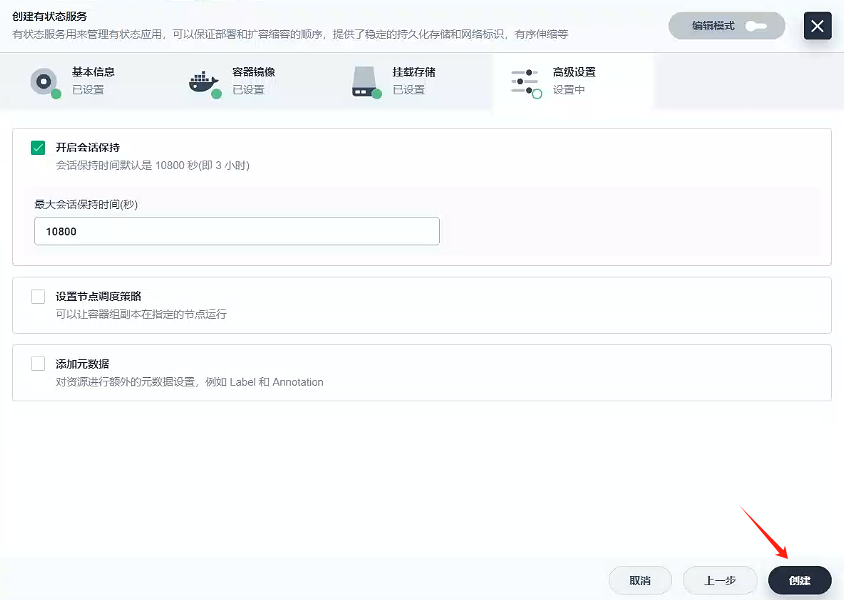
-
至此,gulimall-mysql-slaver服務創建完成
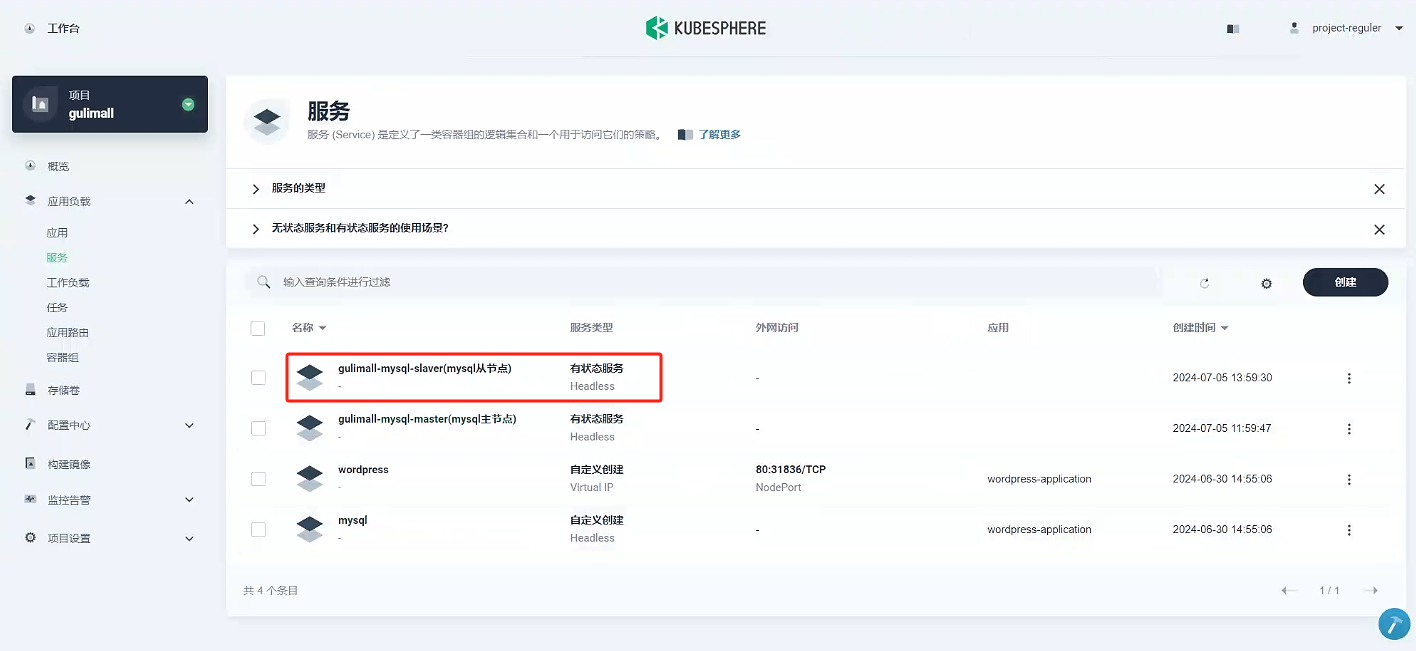
4.3、為 master 授權用戶來他的同步數據
-
點擊 gulimall-mysql-master 服務 -》容器組 -》gulimall-mysql-master-ii799w-0,進入頁面,然后點擊左上角的終端進入容器,輸入
mysql -uroot -p123456登錄mysql
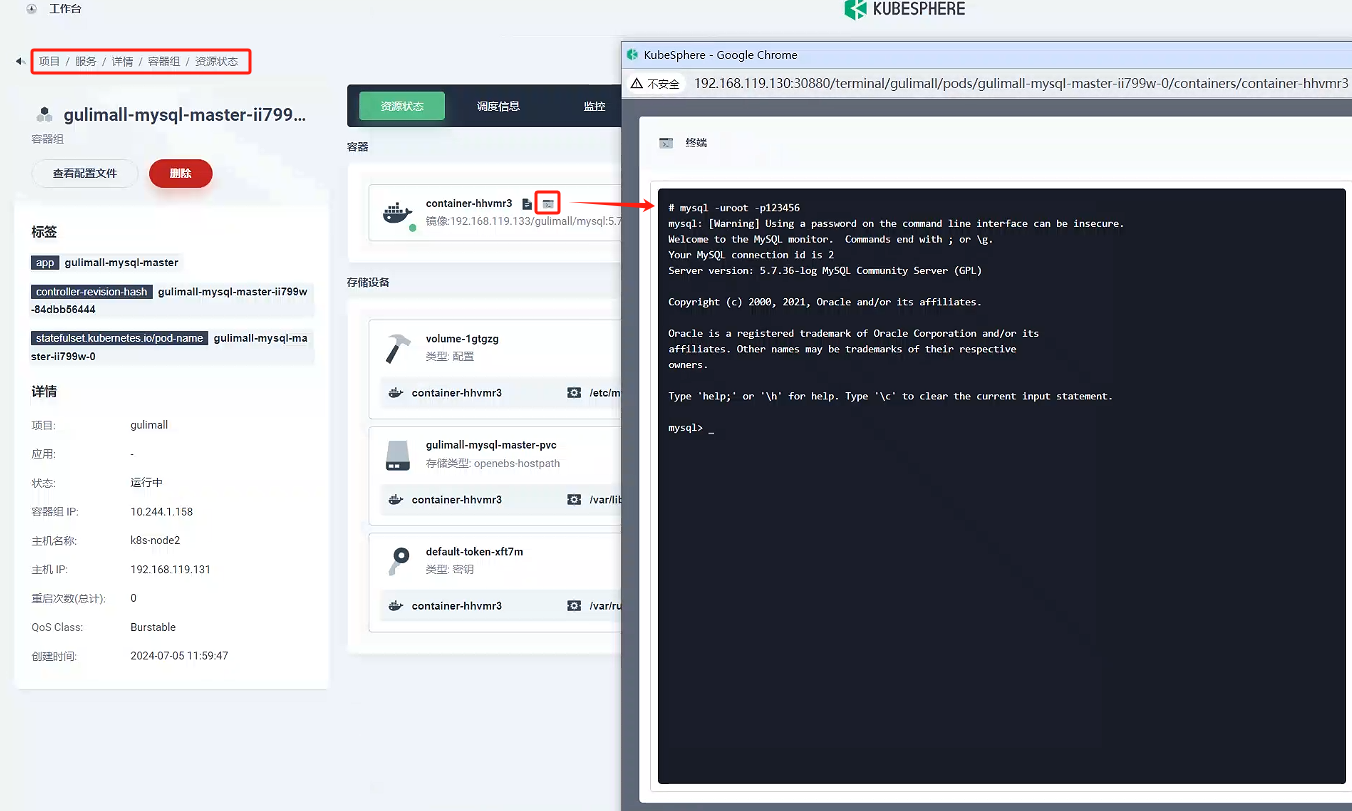
-
添加用來同步的用戶
GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';
-
查看 master 狀態
show master status;
-
退出容器
4.4、配置 slaver 同步 master 數據
-
點擊 gulimall-mysql-slaver 服務 -》容器組 -》gulimall-mysql-slaver-3urxgv-0,進入頁面,然后點擊左上角的終端進入容器,輸入
mysql -uroot -p123456登錄mysql
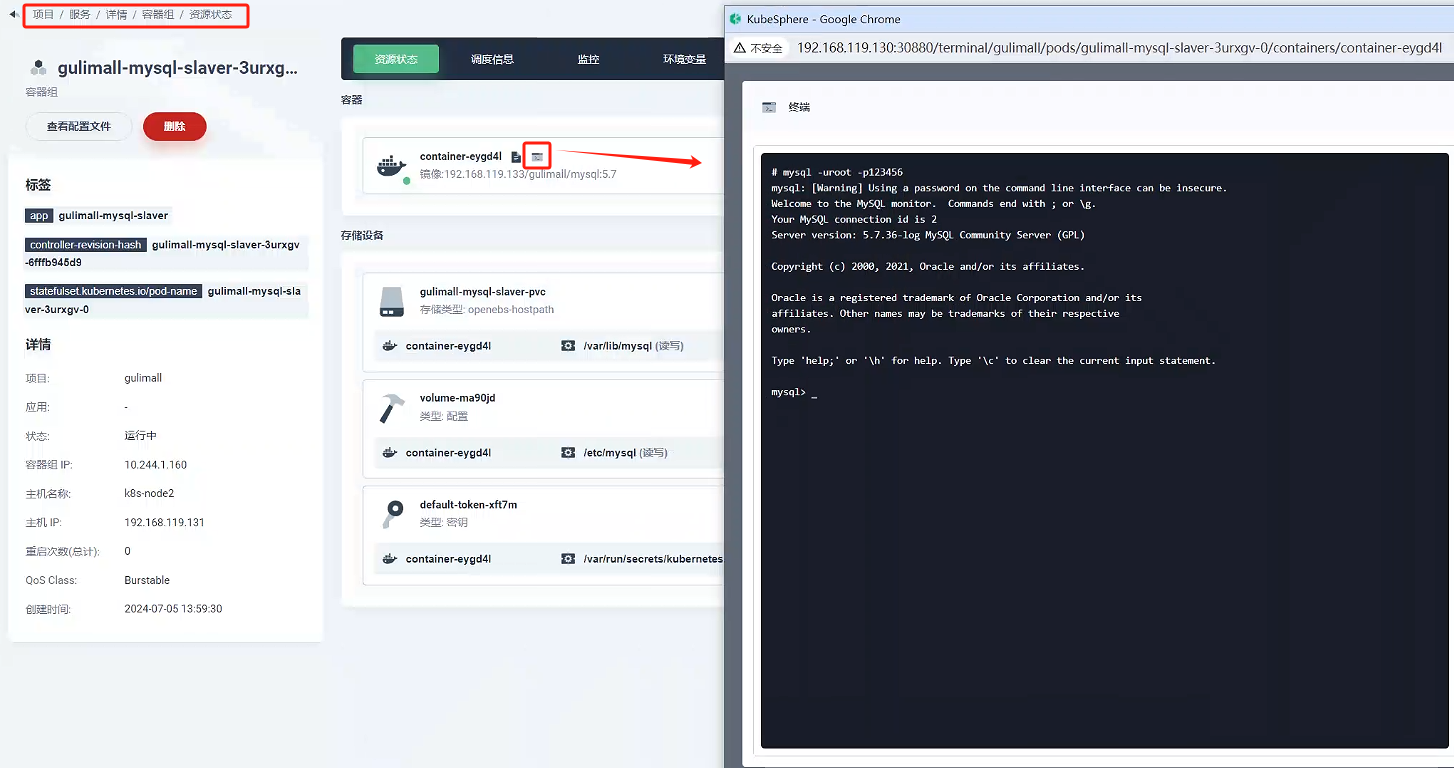
-
設置主庫連接
change master to master_host='gulimall-mysql-master.gulimall',master_user='backup',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=0,master_port=3306;
-
啟動從庫同步
start slave;
-
查看從庫狀態
show slave status\G;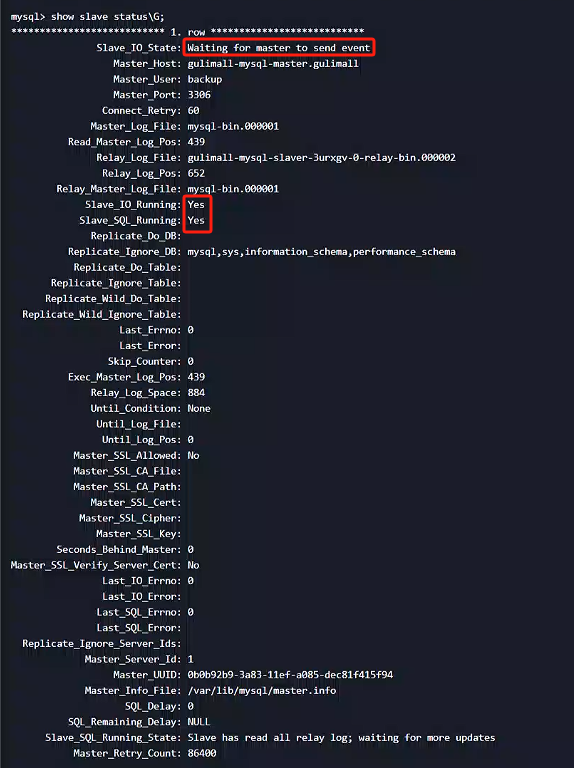
4.5、測試
在guilimall-mysql-master服務創建一個數據庫,看看是否可以同步到gulimall-mysql-slaver
- 進入gulimall-mysql-master容器,查看都有哪些數據庫
show databses;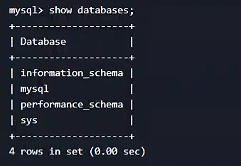
- 創建數據庫
CREATE DATABASE gulimall_oms DEFAULT CHARACTER SET utf8mb4;
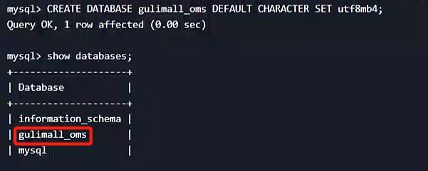
3. 去gulimall-mysql-slaver服務驗證是否同步過來
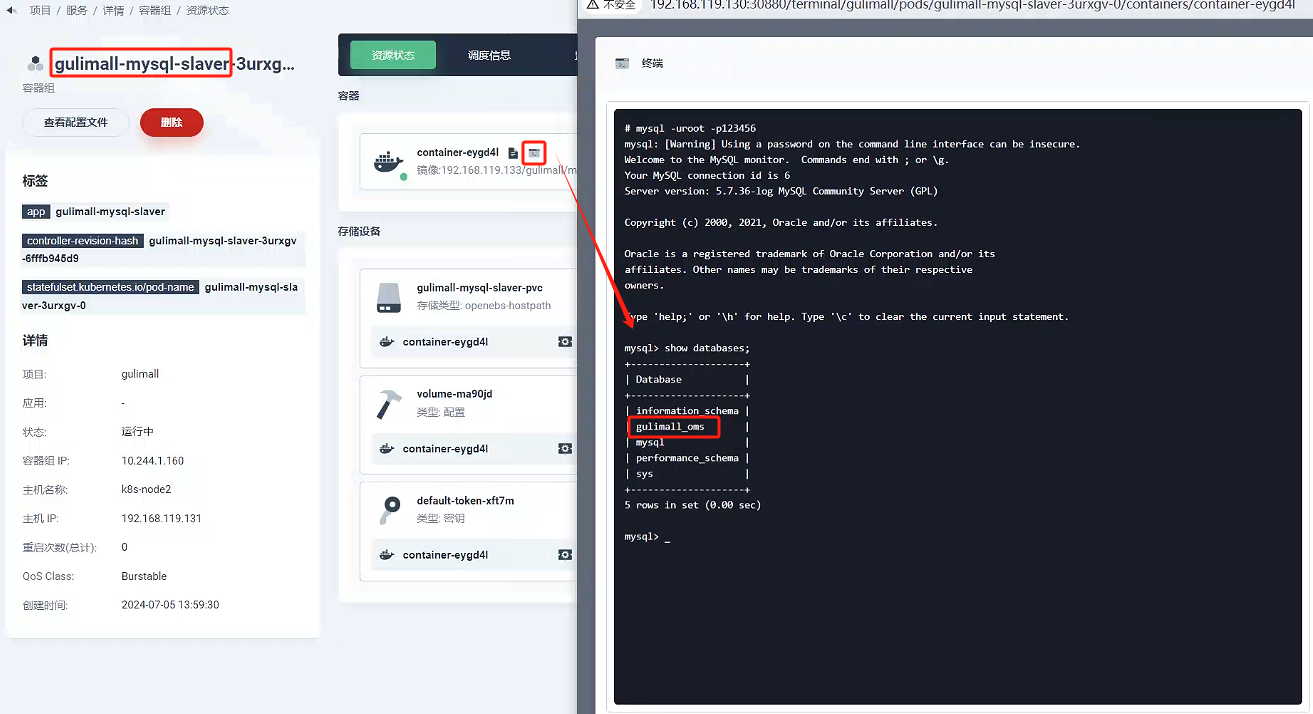
可以看到創建的數據庫已經同步過來
4.6、k8s搭建服務思路
- 每一個MySQL/Redis/elasticseash/rabbitmq必須都是-個有狀態服務
- 每一個MySQL/Redis/elasticseash/rabbitmq掛載自己配置文件(cm)和PVC
- 以后的IP都用域名即可搭建出集群
因為電腦配置原因,后面的服務集群我們不全部使用集群,方法都是想通的,后面都是搭建單機
六、Redis 集群
1、redis 集群形式
1.1、數據分區方案
1、客戶端分區
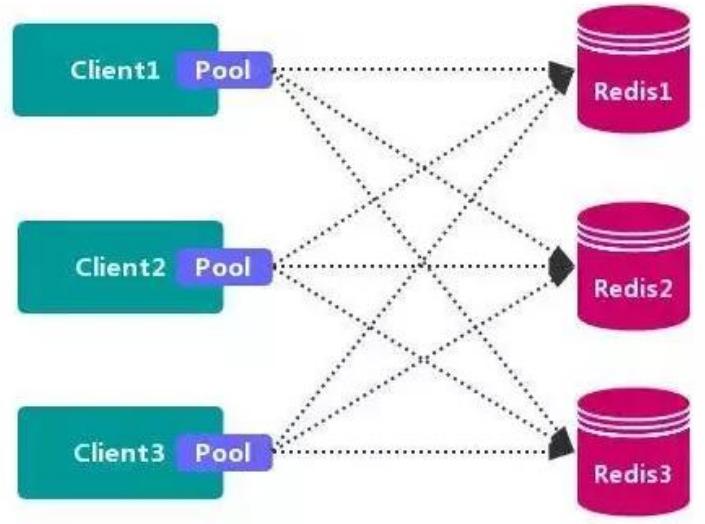
客戶端分區方案 的代表為 Redis Sharding,Redis Sharding 是 Redis Cluster 出來之前,業界普遍使用的 Redis 多實例集群 方法。Java 的 Redis 客戶端驅動庫 Jedis,支持 Redis Sharding 功能,即 ShardedJedis 以及 結合緩存池 的 ShardedJedisPool。
-
優點
不使用 第三方中間件,分區邏輯 可控,配置 簡單,節點之間無關聯,容易 線性擴展,靈
活性強。 -
缺點
客戶端 無法 動態增刪 服務節點,客戶端需要自行維護 分發邏輯,客戶端之間 無連接共享,
會造成 連接浪費。
2、代理分區
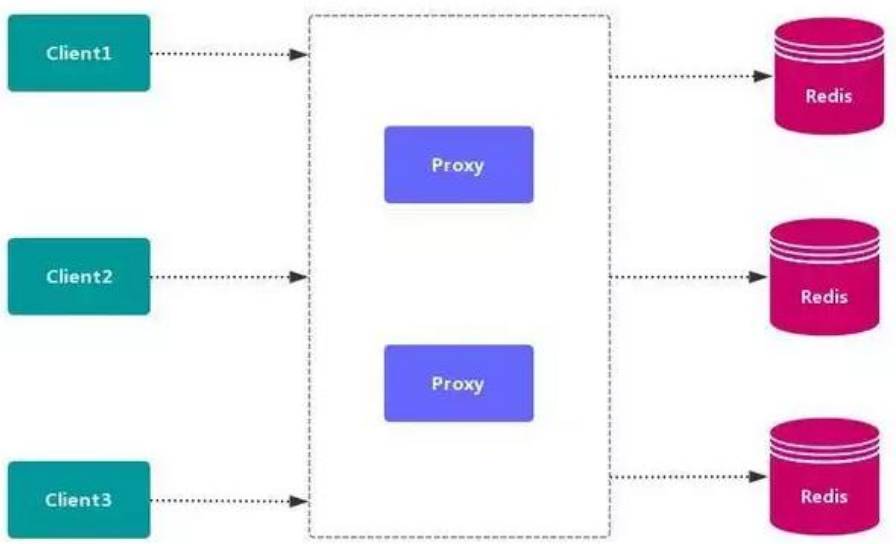
代理分區常用方案有 Twemproxy 和 Codis。
3、redis-cluster
1.2、高可用方式
1.2.1、Sentinel( 哨兵機制)支持高可用
前面介紹了主從機制,但是從運維角度來看,主節點出現了問題我們還需要通過人工干預的方式把從節點設為主節點,還要通知應用程序更新主節點地址,這種方式非常繁瑣笨重, 而且主節點的讀寫能力都十分有限,有沒有較好的辦法解決這兩個問題,哨兵機制就是針對第一個問題的有效解決方案,第二個問題則有賴于集群!哨兵的作用就是監控 Redis 系統的運行狀況,其功能主要是包括以下三個:
- 監控(Monitoring): 哨兵(sentinel) 會不斷地檢查你的 Master 和 Slave 是否運作正常。
- 提醒(Notification): 當被監控的某個 Redis 出現問題時, 哨兵(sentinel) 可以通過 API向管理員或者其他應用程序發送通知。
- 自動故障遷移(Automatic failover): 當主數據庫出現故障時自動將從數據庫轉換為主數據庫。
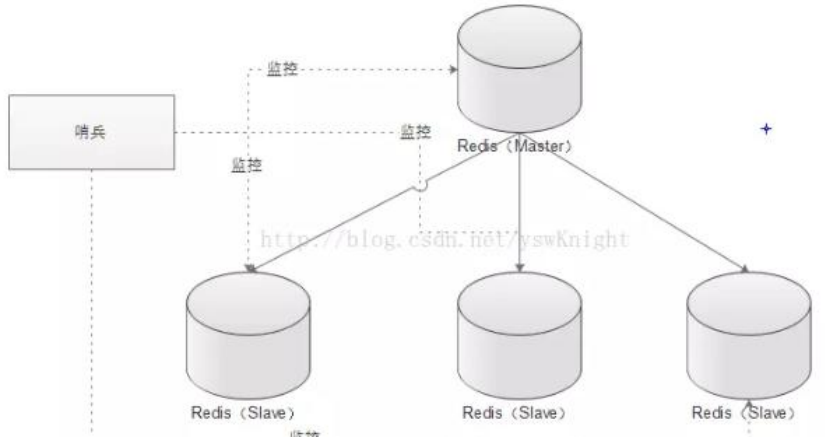
哨兵的原理
Redis 哨兵的三個定時任務,Redis 哨兵判定一個 Redis 節點故障不可達主要就是通過三個定時監控任務來完成的:
-
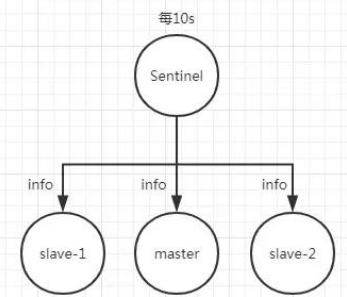
每隔 10 秒每個哨兵節點會向主節點和從節點發送"info replication" 命令來獲取最新的
拓撲結構
-
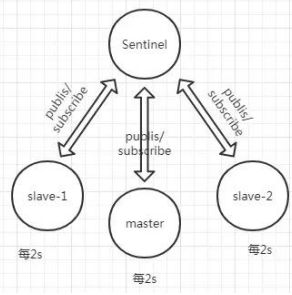
每隔 2 秒每個哨兵節點會向 Redis 節點的_sentinel_:hello 頻道發送自己對主節點是否故障的判斷以及自身的節點信息,并且其他的哨兵節點也會訂閱這個頻道來了解其他哨兵節點的信息以及對主節點的判斷
-
每隔 1 秒每個哨兵會向主節點、從節點、其他的哨兵節點發送一個 “ping” 命令來做心跳檢測
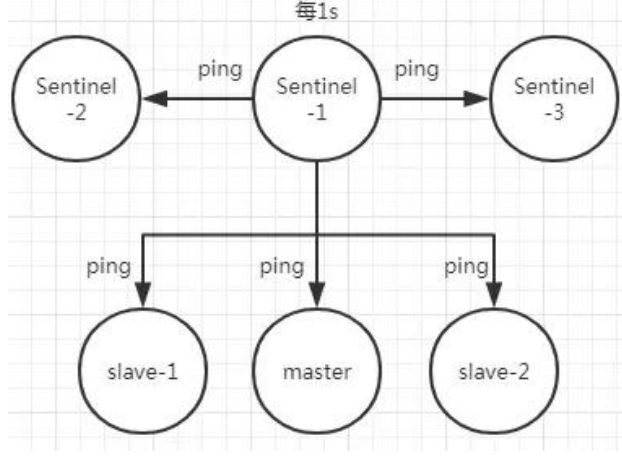
如果在定時 Job3 檢測不到節點的心跳,會判斷為“主觀下線”。如果該節點還是主節點那么還會通知到其他的哨兵對該主節點進行心跳檢測,這時主觀下線的票數超過了數時,那么這個主節點確實就可能是故障不可達了,這時就由原來的主觀下線變為了“客觀下線”。故障轉移和 Leader 選舉
如果主節點被判定為客觀下線之后,就要選取一個哨兵節點來完成后面的故障轉移工作,選舉出一個 leader,這里面采用的選舉算法為 Raft。選舉出來的哨兵 leader 就要來完成故障轉移工作,也就是在從節點中選出一個節點來當新的主節點,這部分的具體流程可參考引用. 《深入理解 Redis 哨兵搭建及原理》
1.2.2、redis-cluster
詳見下章
2、Redis-Cluster
https://redis.io/topics/cluster-tutorial/
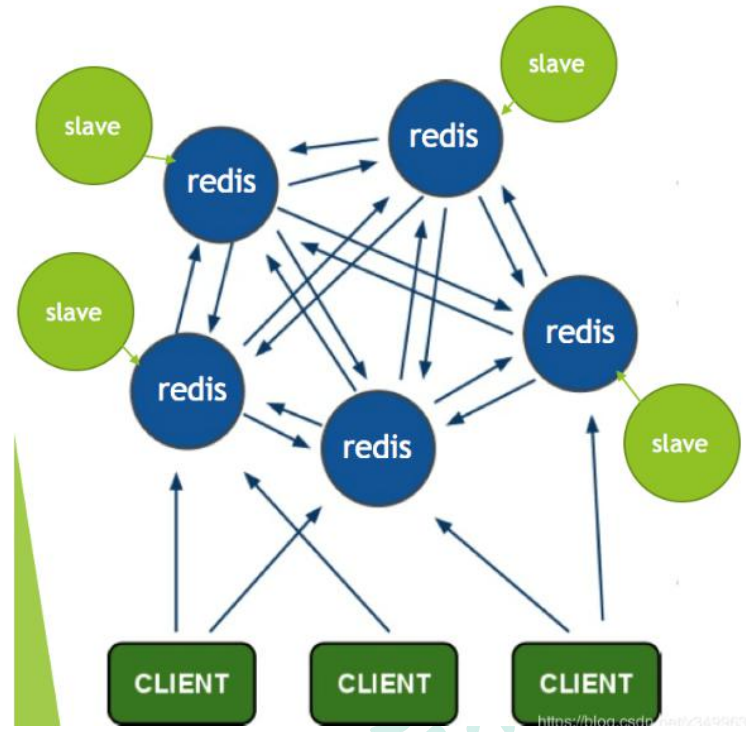
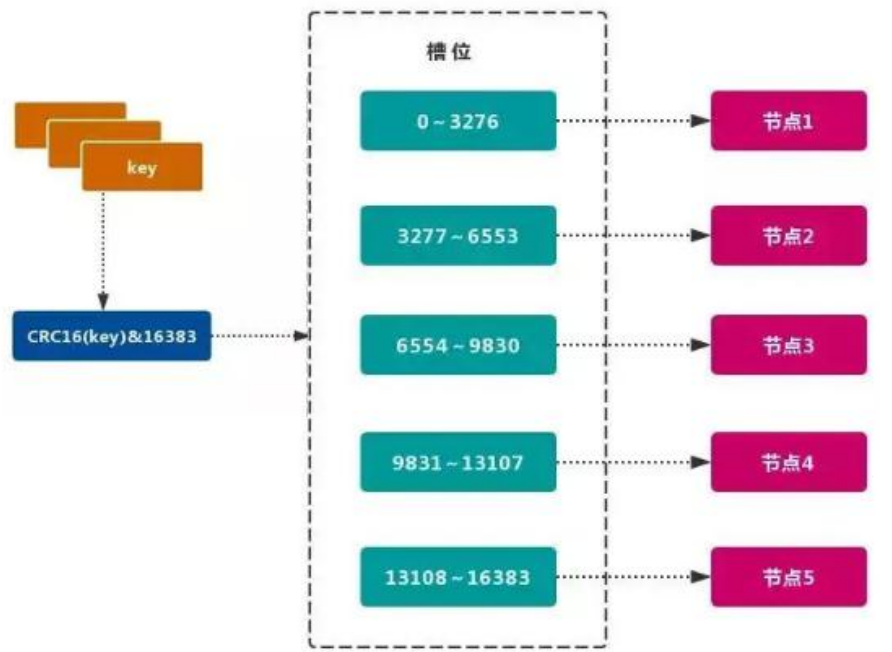
Redis 的官方多機部署方案,Redis Cluster。一組 Redis Cluster 是由多個 Redis 實例組成,官方推薦我們使用 6 實例,其中 3 個為主節點,3 個為從結點。一旦有主節點發生故障的時候,Redis Cluster 可以選舉出對應的從結點成為新的主節點,繼續對外服務,從而保證服務的高可用性。那么對于客戶端來說,知道知道對應的 key 是要路由到哪一個節點呢?Redis Cluster把所有的數據劃分為 16384 個不同的槽位,可以根據機器的性能把不同的槽位分配給不同的 Redis 實例,對于 Redis 實例來說,他們只會存儲部分的 Redis 數據,當然,槽的數據是可以遷移的,不同的實例之間,可以通過一定的協議,進行數據遷移。
2.1、槽
Redis 集群的功能限制;Redis 集群相對 單機 在功能上存在一些限制,需要 開發人員 提前
了解,在使用時做好規避。JAVA CRC16 校驗算法
- key 批量操作 支持有限。
- 類似 mset、mget 操作,目前只支持對具有相同 slot 值的 key 執行 批量操作。
對于 映射為不同 slot 值的 key 由于執行 mget、mget 等操作可能存在于多個節
點上,因此不被支持。
- 類似 mset、mget 操作,目前只支持對具有相同 slot 值的 key 執行 批量操作。
- key 事務操作 支持有限。
- 只支持 多 key 在 同一節點上 的 事務操作,當多個 key 分布在 不同 的節點上時 無法 使用事務功能。
- key 作為 數據分區 的最小粒度
- 不能將一個 大的鍵值 對象如 hash、list 等映射到 不同的節點。
- 不支持 多數據庫空間
- 單機 下的 Redis 可以支持 16 個數據庫(db0 ~ db15),集群模式 下只能使用 一個 數據庫空間,即 db0。
- 復制結構 只支持一層
- 從節點 只能復制 主節點,不支持 嵌套樹狀復制 結構。
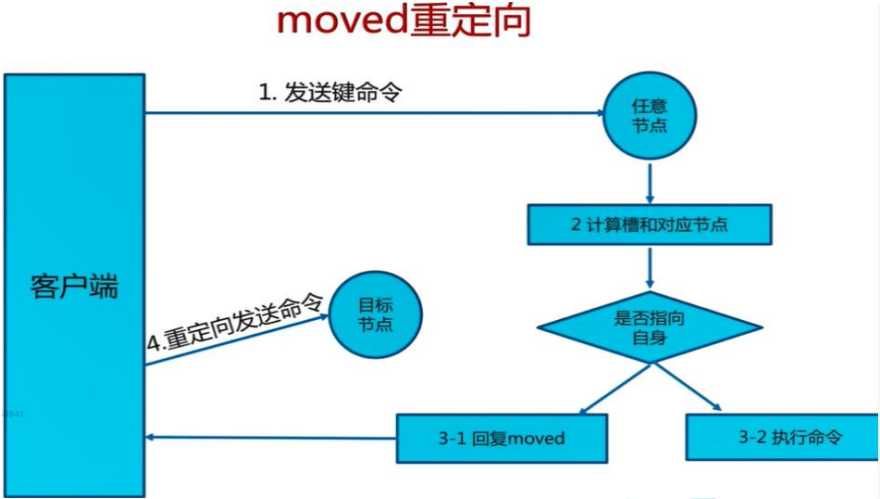
- 命令大多會重定向,耗時多
2.2、一致性 hash
一致性哈希 可以很好的解決 穩定性問題,可以將所有的 存儲節點 排列在 收尾相接 的Hash 環上,每個 key 在計算 Hash 后會 順時針 找到 臨接 的 存儲節點 存放。而當有節點 加入 或 退出 時,僅影響該節點在 Hash 環上 順時針相鄰 的 后續節點。
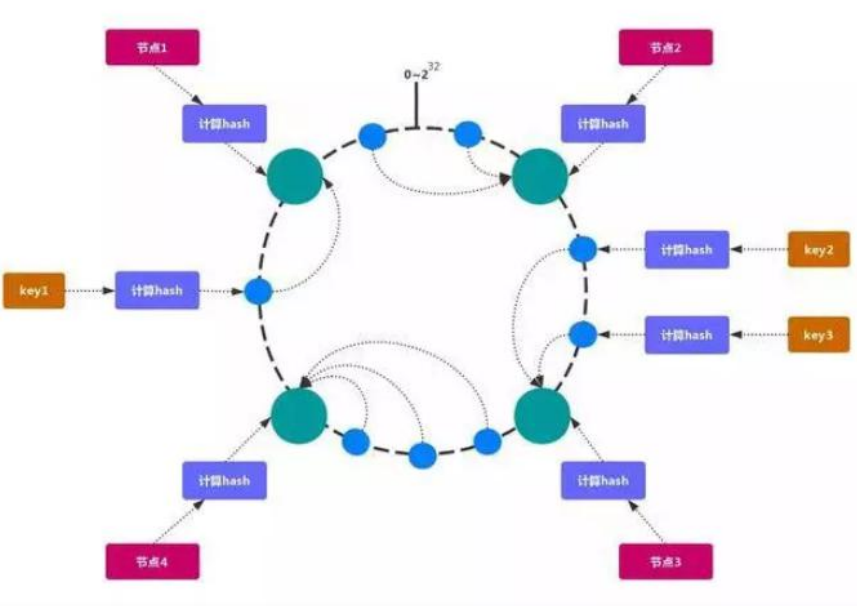
Hash 傾斜
如果節點很少,容易出現傾斜,負載不均衡問題。一致性哈希算法,引入了虛擬節點,在整個環上,均衡增加若干個節點。比如 a1,a2,b1,b2,c1,c2,a1 和 a2 都是屬于 A 節點的。解決 hash 傾斜問題
3、部署 Cluster
3.1、創建 6 個 redis 節點
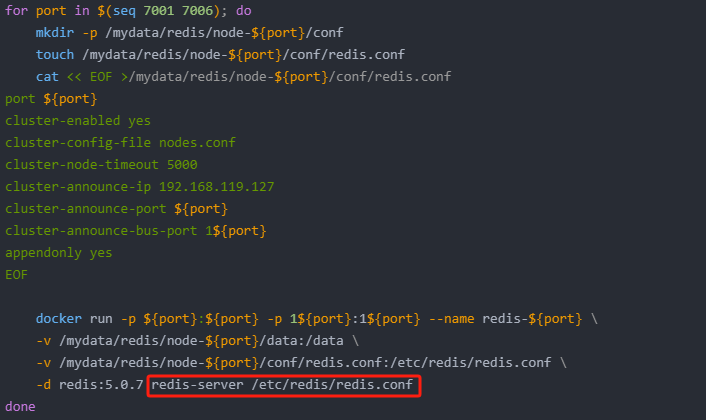
3 主 3 從方式,從為了同步備份,主進行 slot 數據分片
for port in $(seq 7001 7006); domkdir -p /mydata/redis/node-${port}/conftouch /mydata/redis/node-${port}/conf/redis.confcat << EOF >/mydata/redis/node-${port}/conf/redis.conf
port ${port}
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 192.168.119.127
cluster-announce-port ${port}
cluster-announce-bus-port 1${port}
appendonly yes
EOFdocker run -p ${port}:${port} -p 1${port}:1${port} --name redis-${port} \-v /mydata/redis/node-${port}/data:/data \-v /mydata/redis/node-${port}/conf/redis.conf:/etc/redis/redis.conf \-d redis:5.0.7 redis-server /etc/redis/redis.conf
done
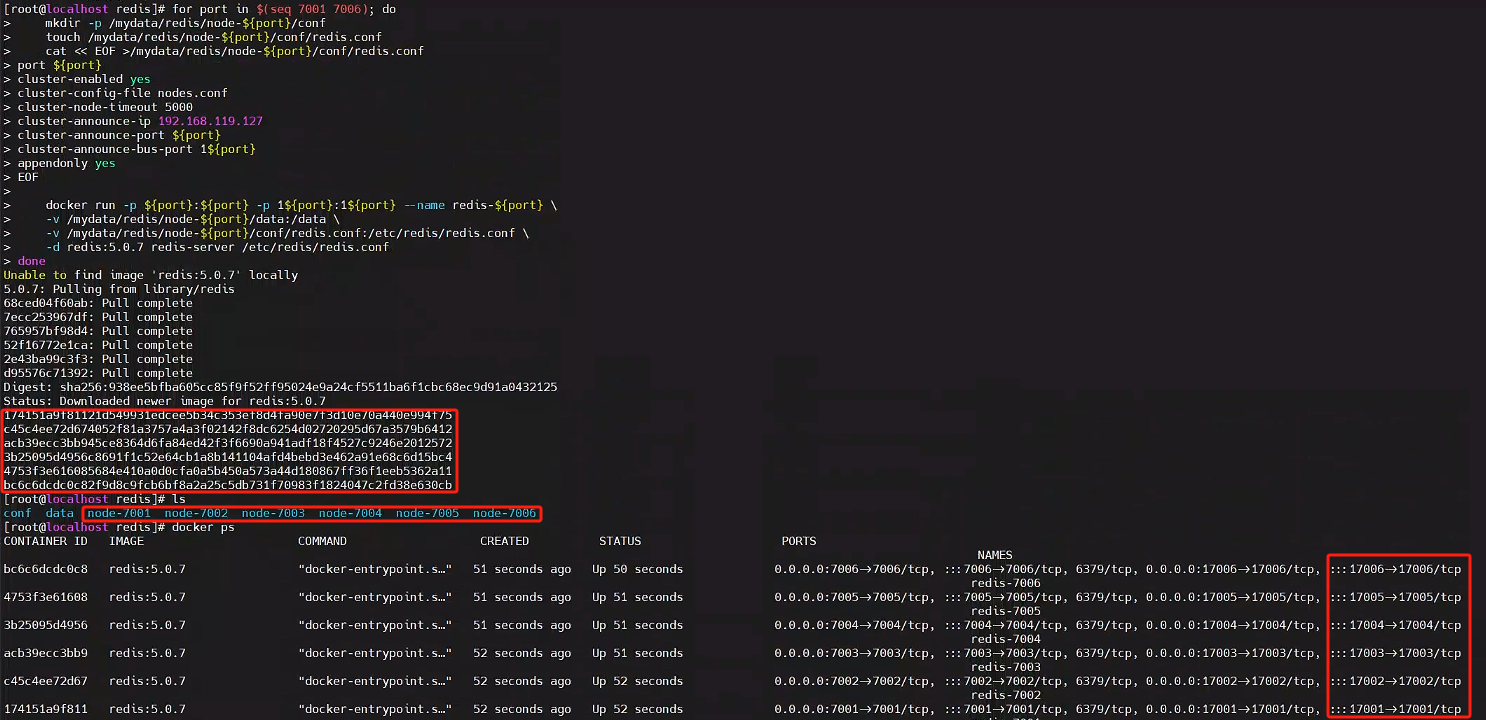
如果停止或者刪除可以操作以下命令
docker stop $(docker ps -a |grep redis-700 | awk '{ print $1}')
docker rm $(docker ps -a |grep redis-700 | awk '{ print $1}')
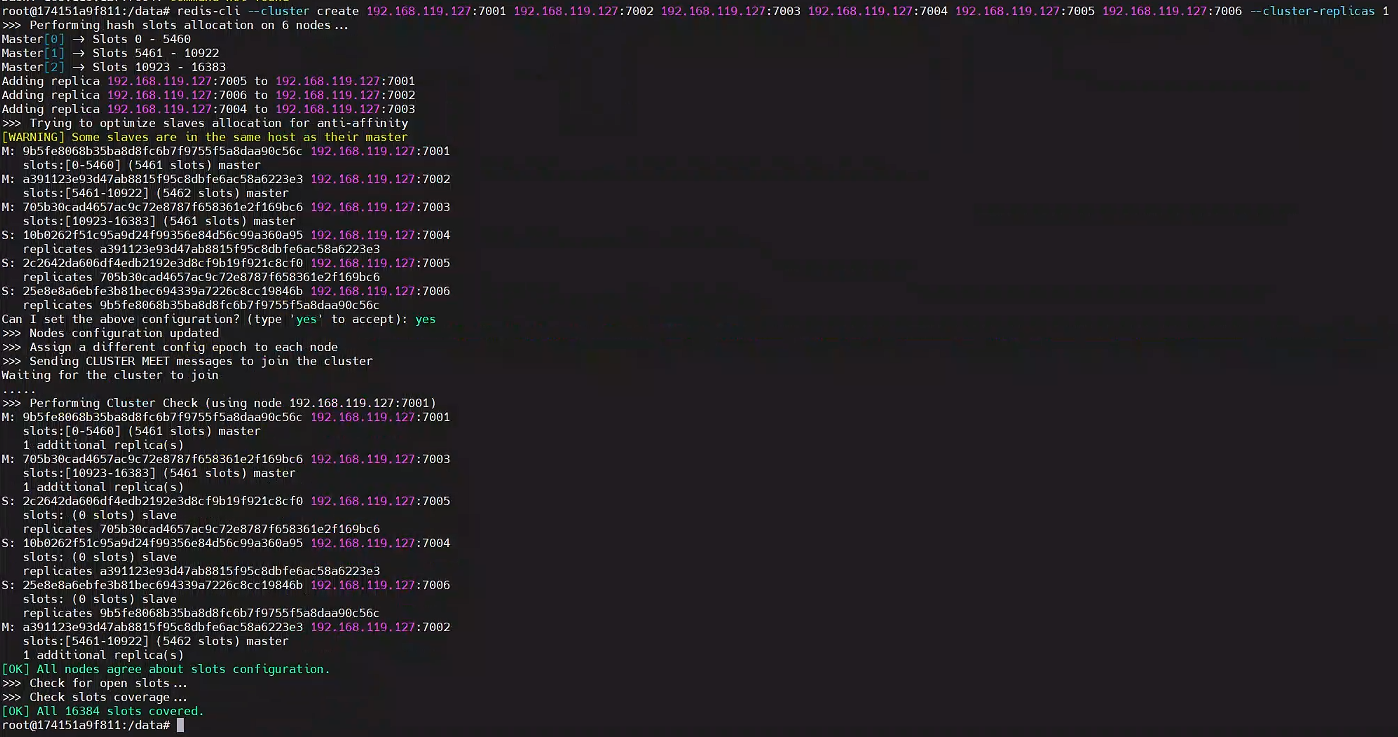
3.2、使用 redis 建立集群
# 隨便進入一個redis節點容器
docker exec -it redis-7001 bash
# 通過redis-cli創建redis集群
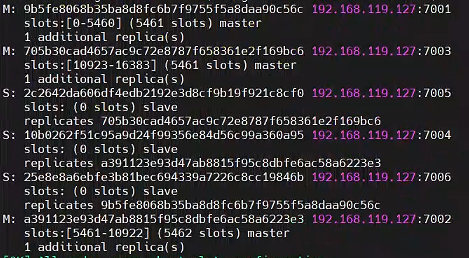
redis-cli --cluster create 192.168.119.127:7001 192.168.119.127:7002 192.168.119.127:7003 192.168.119.127:7004 192.168.119.127:7005 192.168.119.127:7006 --cluster-replicas 1
3.3、測試集群效果
隨便進入某個 redis 容器
docker exec -it redis-7002 /bin/bash
使用 redis-cli 的 cluster 方式進行連接
redis-cli -c -h 192.168.119.127 -p 7006
Get/Set 命令測試,將會重定向節點宕機,slave 會自動提升為 master,master 開啟后變為 slave
root@174151a9f811:/data# redis-cli -c -h 192.168.119.127 -p 7006
192.168.119.127:7006> set hello 1
-> Redirected to slot [866] located at 192.168.119.127:7001
OK
192.168.119.127:7001> set a aaaa
-> Redirected to slot [15495] located at 192.168.119.127:7003
OK
192.168.119.127:7003> get hello
-> Redirected to slot [866] located at 192.168.119.127:7001
"1"
192.168.119.127:7001> get a
-> Redirected to slot [15495] located at 192.168.119.127:7003
"aaaa"
192.168.119.127:7003>
獲取集群信息
cluster info;
獲取集群節點
cluster nodes;
4、k8s部署redis
參照有狀態部署即可
4.1、創建配置 - redis-conf
- 基本信息
- 名稱:redis-conf
- 名稱:redis-conf
- 配置設置
- 鍵(Key):redis-conf
- 值(Value):appendonly yes
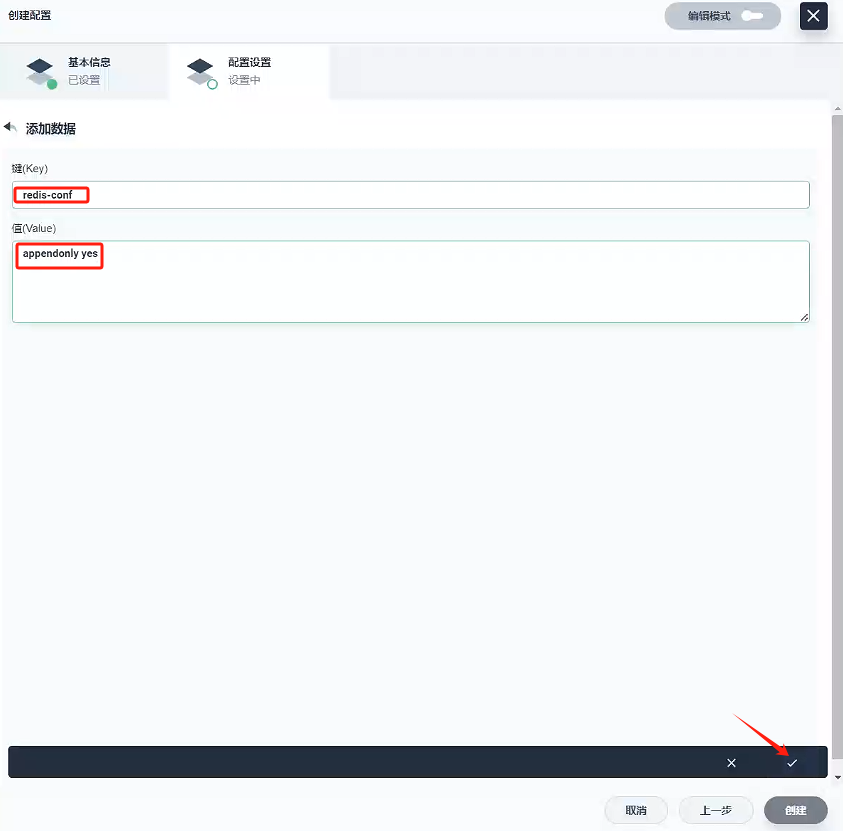
- 創建
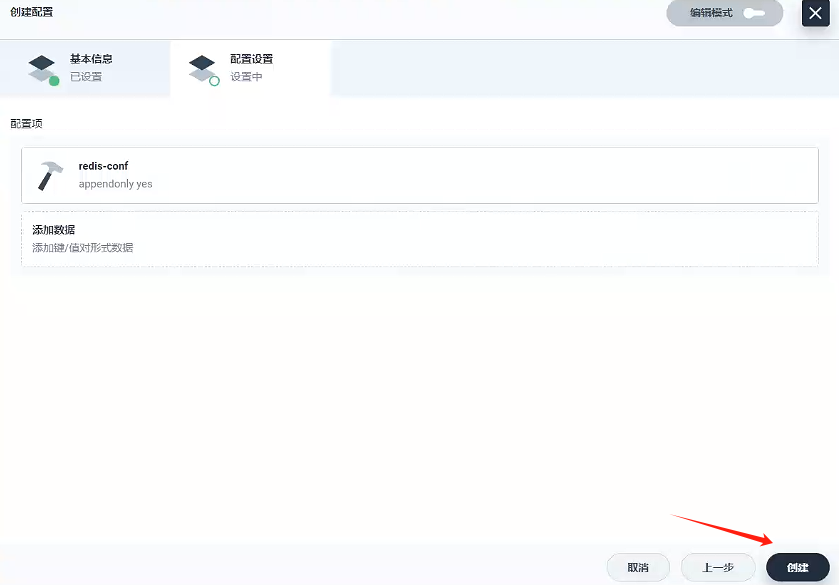
4.2、創建存儲卷 - gulimall-redis-pvc
- 基本信息
創建名稱為gulimall-redis-pvc的存儲卷
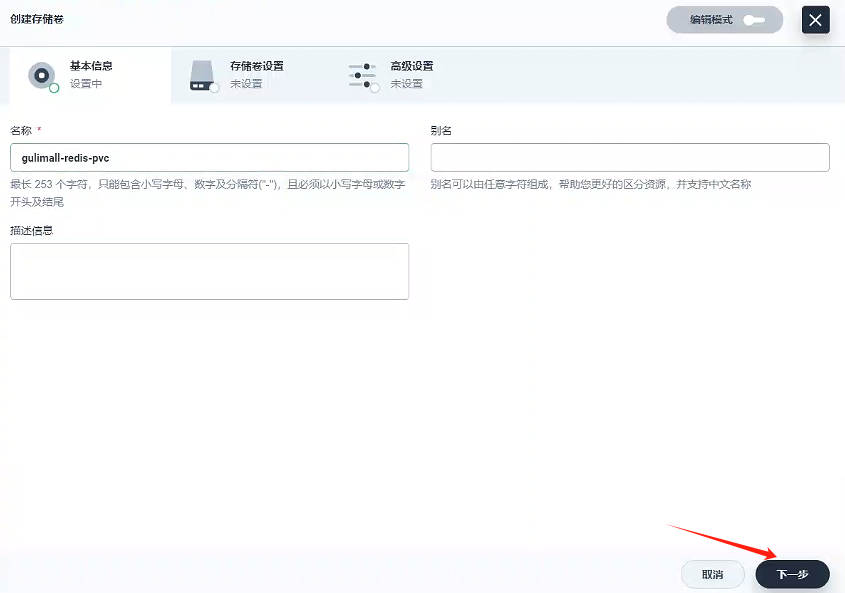
- 存儲卷設置
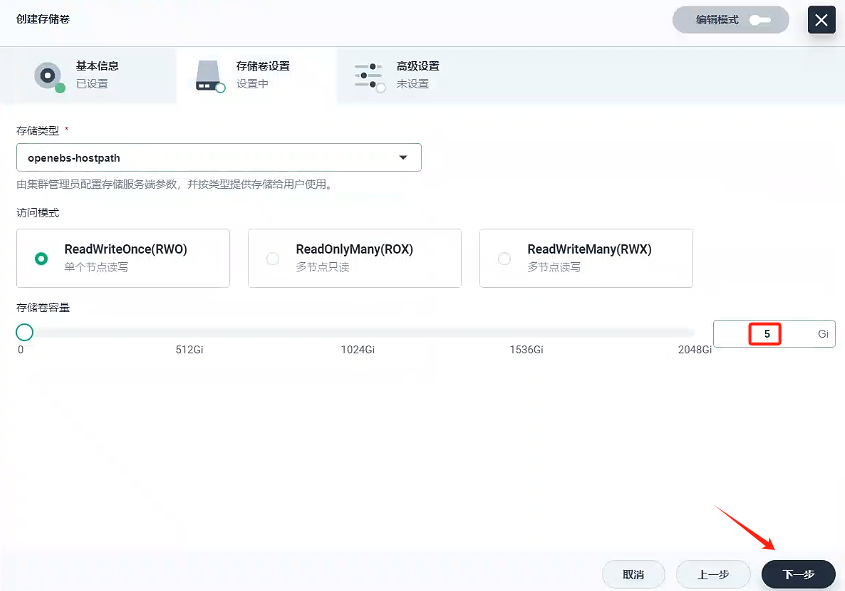
- 創建
4.3、創建服務- gulimall -redis
-
選擇有狀態服務
-
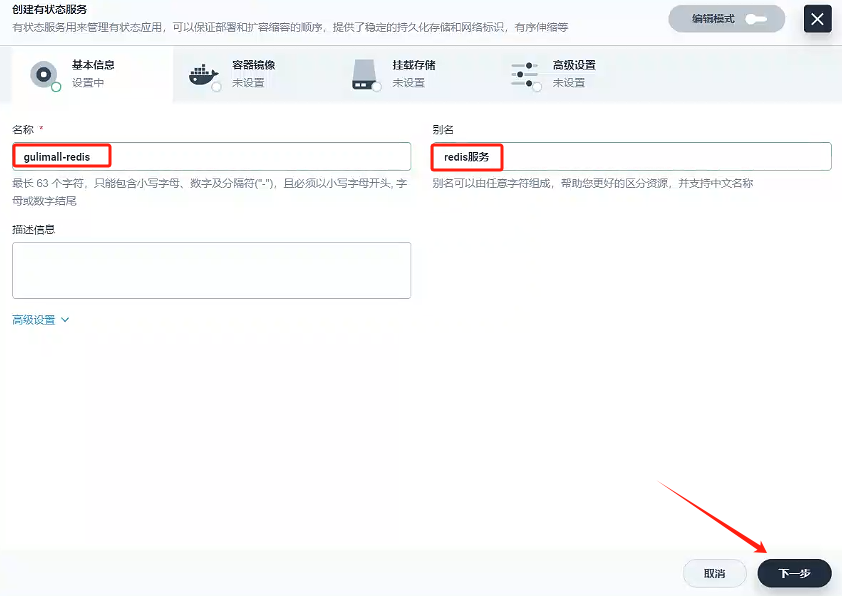
填寫基本信息
- 名稱:gulimall-redis
- 別名:redis服務
-
容器鏡像
-
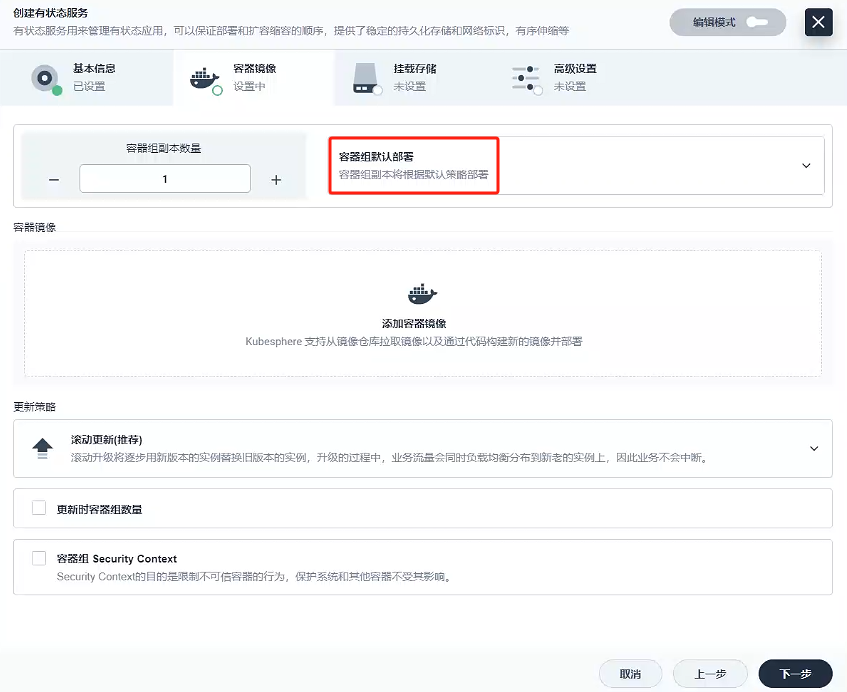
因為就一個容器,我們容器組選擇容器組默認部署就好
-
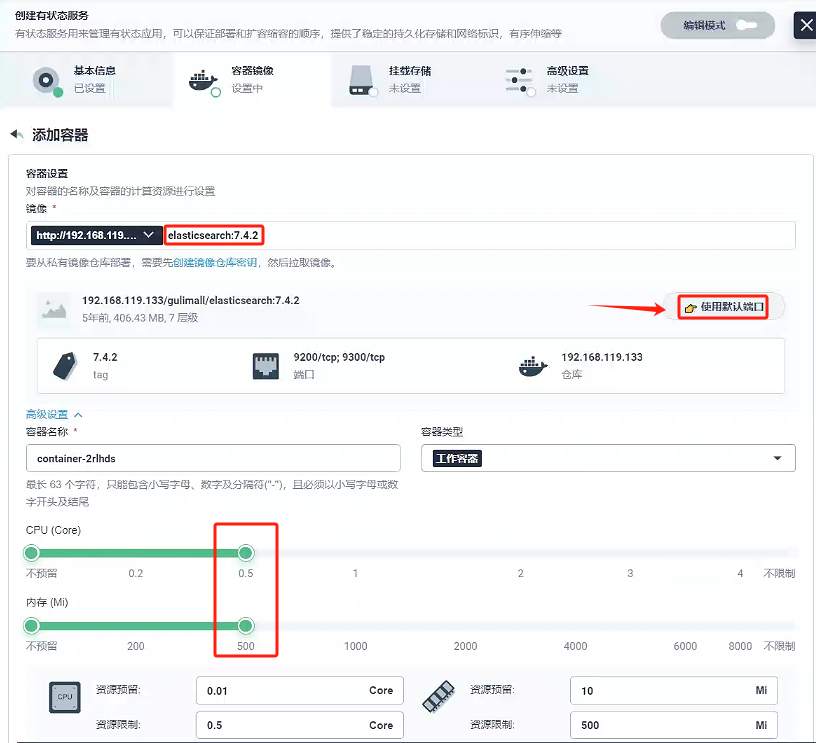
添加容器鏡像
這里我們使用的私有鏡像倉庫-Harbor創建容器,使用默認端口

-
設置一個啟動命令,這里配置參考docker創建 6 個 redis 節點的命令 redis-server /etc/redis/redis.conf
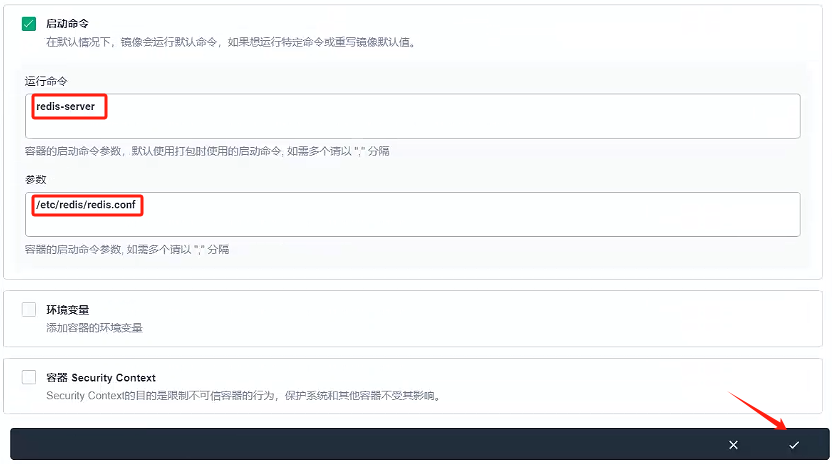
4. 下一步
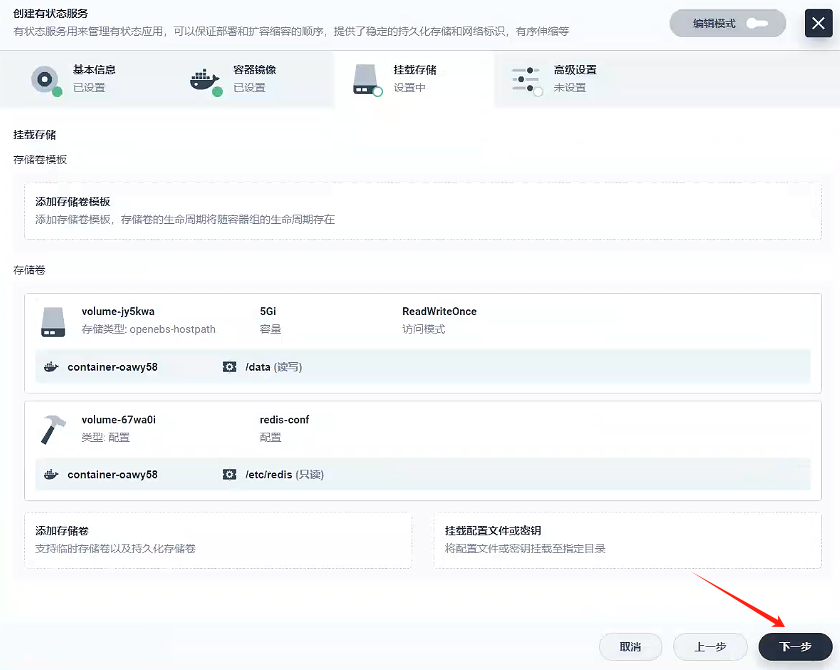
5. 掛載存儲
- 掛載存儲卷
這里的掛載路徑也參考docker創建 6 個 redis 節點的命令 /data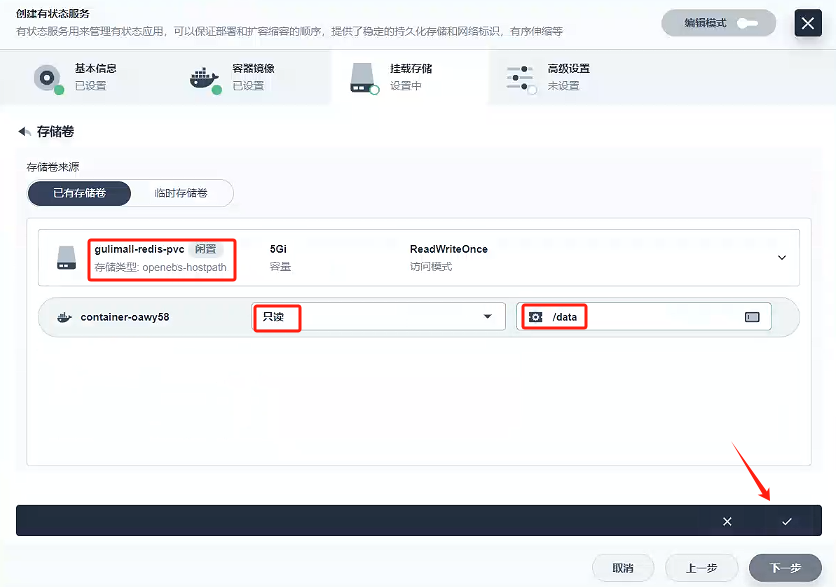
- 掛載配置文件
- 文件掛載路徑:/etc/redis
- 特定的鍵:redis-conf
- 路徑:redis.conf
這里的配置我們參考創建 6 個 redis 節點的命令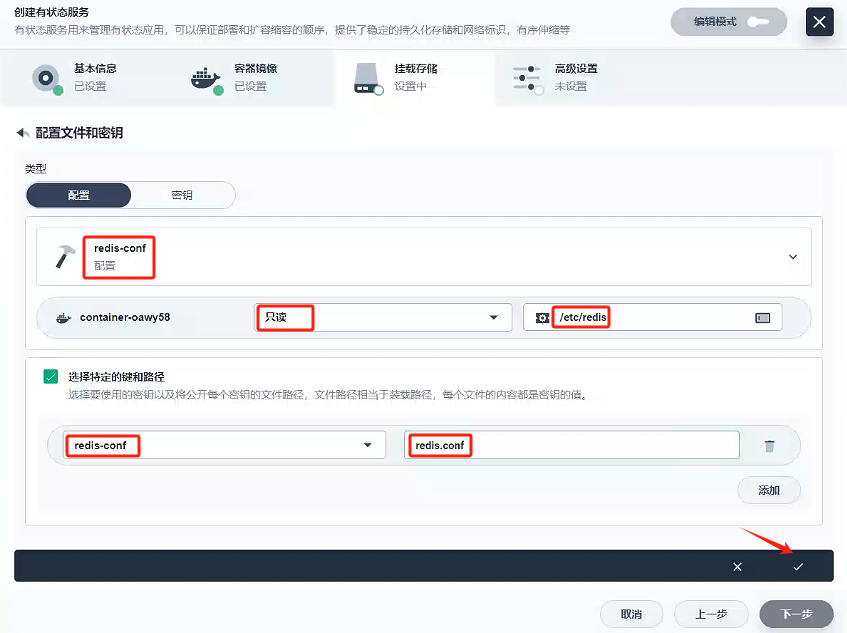
- 下一步
- 創建
4.4、測試
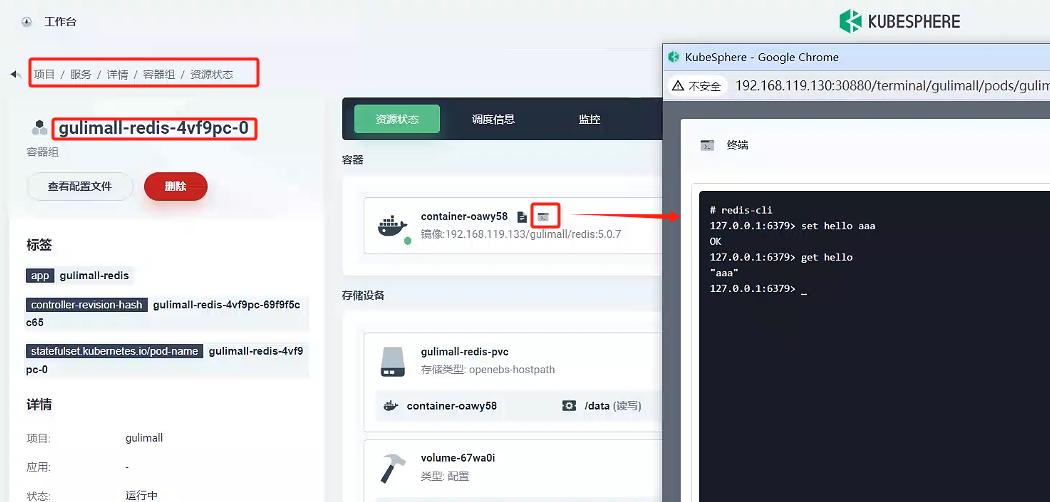
我們點擊 gulimall-redis 服務 -》 容器組 -》gulimall-redis-4vf9pc-0 -》端口
通過redis-cli客戶端命令進行get和set方法測試
# redis-cli
127.0.0.1:6379> set hello aaa
OK
127.0.0.1:6379> get hello
"aaa"
127.0.0.1:6379>
七、Elasticsearch 集群
1、集群原理
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/distributed-cluster.html
elasticsearch 是天生支持集群的,他不需要依賴其他的服務發現和注冊的組件,如 zookeeper這些,因為他內置了一個名字叫 ZenDiscovery 的模塊,是 elasticsearch 自己實現的一套用于節點發現和選主等功能的組件,所以 elasticsearch 做起集群來非常簡單,不需要太多額外的配置和安裝額外的第三方組件。
1.1、單節點

- 一個運行中的 Elasticsearch 實例稱為一個節點,而集群是由一個或者多個擁有相同cluster.name 配置的節點組成, 它們共同承擔數據和負載的壓力。當有節點加入集群中或者從集群中移除節點時,集群將會重新平均分布所有的數據。
- 當一個節點被選舉成為 主節點時, 它將負責管理集群范圍內的所有變更,例如增加、刪除索引,或者增加、刪除節點等。 而主節點并不需要涉及到文檔級別的變更和搜索等操作,所以當集群只擁有一個主節點的情況下,即使流量的增加它也不會成為瓶頸。任何節點都可以成為主節點。我們的示例集群就只有一個節點,所以它同時也成為了主節點。
- 作為用戶,我們可以將請求發送到 集群中的任何節點 ,包括主節點。 每個節點都知道任意文檔所處的位置,并且能夠將我們的請求直接轉發到存儲我們所需文檔的節點。無論我們將請求發送到哪個節點,它都能負責從各個包含我們所需文檔的節點收集回數據,并將最終結果返回給客戶端。 Elasticsearch 對這一切的管理都是透明的。
1.2、集群健康
Elasticsearch 的集群監控信息中包含了許多的統計數據,其中最為重要的一項就是 集群健康 , 它在 status 字段中展示為 green 、 yellow 或者 red 。

status 字段指示著當前集群在總體上是否工作正常。它的三種顏色含義如下:
green:所有的主分片和副本分片都正常運行。
yellow:所有的主分片都正常運行,但不是所有的副本分片都正常運行。
red:有主分片沒能正常運行。
1.3、分片
- 一個 分片 是一個底層的 工作單元 ,它僅保存了全部數據中的一部分。我們的文檔被存儲和索引到分片內,但是應用程序是直接與索引而不是與分片進行交互。分片就認為是一個數據區
- 一個分片可以是 主 分片或者 副本 分片。索引內任意一個文檔都歸屬于一個主分片,所以主分片的數目決定著索引能夠保存的最大數據量。
- 在索引建立的時候就已經確定了主分片數,但是副本分片數可以隨時修改。
- 讓我們在包含一個空節點的集群內創建名為 blogs 的索引。 索引在默認情況下會被分配 5 個主分片, 但是為了演示目的,我們將分配 3 個主分片和一份副本(每個主分片擁有一個副本分片):

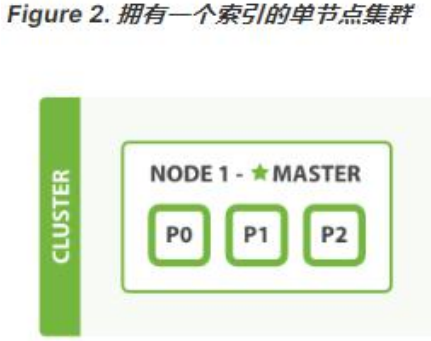
此時集群的健康狀況為 yellow 則表示全部 主分片都正常運行(集群可以正常服務所有請求),但是 副本 分片沒有全部處在正常狀態。 實際上,所有 3 個副本分片都是 unassigned —— 它們都沒有被分配到任何節點。在同一個節點上既保存原始數據又保存副本是沒有意義的,因為一旦失去了那個節點,我們也將丟失該節點上的所有副本數據。
當前我們的集群是正常運行的,但是在硬件故障時有丟失數據的風險。
1.4、新增節點
當你在同一臺機器上啟動了第二個節點時,只要它和第一個節點有同樣的 cluster.name 配置,它就會自動發現集群并加入到其中。 但是在不同機器上啟動節點的時候,為了加入到同一集群,你需要配置一個可連接到的單播主機列表。 詳細信息請查看最好使用單播代替組播

此時,cluster-health 現在展示的狀態為 green ,這表示所有 6 個分片(包括 3 個主分片和3 個副本分片)都在正常運行。我們的集群現在不僅僅是正常運行的,并且還處于 始終可用 的狀態。
1.5、水平擴容-啟動第三個節點

Node 1 和 Node 2 上各有一個分片被遷移到了新的 Node 3 節點,現在每個節點上都擁有 2 個分片,而不是之前的 3 個。 這表示每個節點的硬件資源(CPU, RAM, I/O)將被更少的分片所共享,每個分片的性能將會得到提升。
在運行中的集群上是可以動態調整副本分片數目的,我們可以按需伸縮集群。讓我們把副本數從默認的 1 增加到 2


blogs 索引現在擁有 9 個分片:3 個主分片和 6 個副本分片。 這意味著我們可以將集群擴容到 9 個節點,每個節點上一個分片。相比原來 3 個節點時,集群搜索性能可以提升 3 倍。

6、應對故障
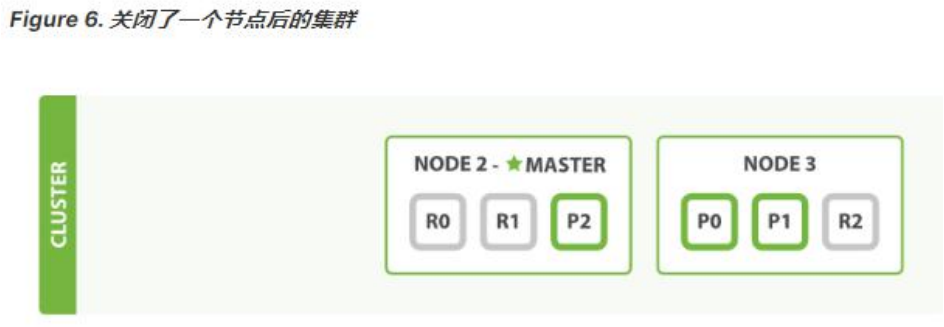
- 我們關閉的節點是一個主節點。而集群必須擁有一個主節點來保證正常工作,所以發生的第一件事情就是選舉一個新的主節點: Node 2 。
- 在我們關閉 Node 1 的同時也失去了主分片 1 和 2 ,并且在缺失主分片的時候索引也不能正常工作。 如果此時來檢查集群的狀況,我們看到的狀態將會為 red :不是所有主分片都在正常工作。
- 幸運的是,在其它節點上存在著這兩個主分片的完整副本, 所以新的主節點立即將這些分片在 Node 2 和 Node 3 上對應的副本分片提升為主分片, 此時集群的狀態將會為 yellow 。 這個提升主分片的過程是瞬間發生的,如同按下一個開關一般。
- 為什么我們集群狀態是 yellow 而不是 green 呢? 雖然我們擁有所有的三個主分片,但是同時設置了每個主分片需要對應 2 份副本分片,而此時只存在一份副本分片。 所以集群不能為 green 的狀態,不過我們不必過于擔心:如果我們同樣關閉了 Node 2 ,我們的程序 依然 可以保持在不丟任何數據的情況下運行,因為 Node 3 為每一個分片都保留著一份副本。
- 如果我們重新啟動 Node 1 ,集群可以將缺失的副本分片再次進行分配。如果 Node 1依然擁有著之前的分片,它將嘗試去重用它們,同時僅從主分片復制發生了修改的數據文件。
1.7、問題與解決
1、主節點
主節點負責創建索引、刪除索引、分配分片、追蹤集群中的節點狀態等工作。Elasticsearch中的主節點的工作量相對較輕,用戶的請求可以發往集群中任何一個節點,由該節點負責分發和返回結果,而不需要經過主節點轉發。而主節點是由候選主節點通過 ZenDiscovery 機制選舉出來的,所以要想成為主節點,首先要先成為候選主節點。
2、候選主節點
在 elasticsearch 集群初始化或者主節點宕機的情況下,由候選主節點中選舉其中一個作為主節點。指定候選主節點的配置為:node.master: true。
當主節點負載壓力過大,或者集中環境中的網絡問題,導致其他節點與主節點通訊的時候,主節點沒來的及響應,這樣的話,某些節點就認為主節點宕機,重新選擇新的主節點,這樣的話整個集群的工作就有問題了,比如我們集群中有 10 個節點,其中 7 個候選主節點,1個候選主節點成為了主節點,這種情況是正常的情況。但是如果現在出現了我們上面所說的主節點響應不及時,導致其他某些節點認為主節點宕機而重選主節點,那就有問題了,這剩下的 6 個候選主節點可能有 3 個候選主節點去重選主節點,最后集群中就出現了兩個主節點的情況,這種情況官方成為“腦裂現象”;
集群中不同的節點對于 master 的選擇出現了分歧,出現了多個 master 競爭,導致主分片和副本的識別也發生了分歧,對一些分歧中的分片標識為了壞片。
3、數據節點
數據節點負責數據的存儲和相關具體操作,比如 CRUD、搜索、聚合。所以,數據節點對機器配置要求比較高,首先需要有足夠的磁盤空間來存儲數據,其次數據操作對系統 CPU、Memory 和 IO 的性能消耗都很大。通常隨著集群的擴大,需要增加更多的數據節點來提高可用性。指定數據節點的配置:node.data: true。
elasticsearch 是允許一個節點既做候選主節點也做數據節點的,但是數據節點的負載較重,所以需要考慮將二者分離開,設置專用的候選主節點和數據節點,避免因數據節點負載重導致主節點不響應。
5、腦裂”問題可能的成因
1.網絡問題:集群間的網絡延遲導致一些節點訪問不到 master,認為 master 掛掉了從而選舉出新的 master,并對 master 上的分片和副本標紅,分配新的主分片
2.節點負載:主節點的角色既為 master 又為 data,訪問量較大時可能會導致 ES 停止響應造成大面積延遲,此時其他節點得不到主節點的響應認為主節點掛掉了,會重新選取主節點。
3.內存回收:data 節點上的 ES 進程占用的內存較大,引發 JVM 的大規模內存回收,造成 ES進程失去響應。
- 腦裂問題解決方案:
- 角色分離:即 master 節點與 data 節點分離,限制角色;數據節點是需要承擔存儲和搜索的工作的,壓力會很大。所以如果該節點同時作為候選主節點和數據節點,那么一旦選上它作為主節點了,這時主節點的工作壓力將會非常大,出現腦裂現象的概率就增加了。
- 減少誤判:配置主節點的響應時間,在默認情況下,主節點 3 秒沒有響應,其他節點就認為主節點宕機了,那我們可以把該時間設置的長一點,該配置是:
discovery.zen.ping_timeout: 5 - 選舉觸發:discovery.zen.minimum_master_nodes:1(默認是 1),該屬性定義的是為了形成一個集群,有主節點資格并互相連接的節點的最小數目。
- 一 個 有 10 節 點 的 集 群 , 且 每 個 節 點 都 有 成 為 主 節 點 的 資 格 , discovery.zen.minimum_master_nodes 參數設置為 6。
- 正常情況下,10 個節點,互相連接,大于 6,就可以形成一個集群。
- 若某個時刻,其中有 3 個節點斷開連接。剩下 7 個節點,大于 6,繼續運行之前的集群。而斷開的 3 個節點,小于 6,不能形成一個集群。
- 該參數就是為了防止”腦裂”的產生。
- 建議設置為(候選主節點數 / 2) + 1,
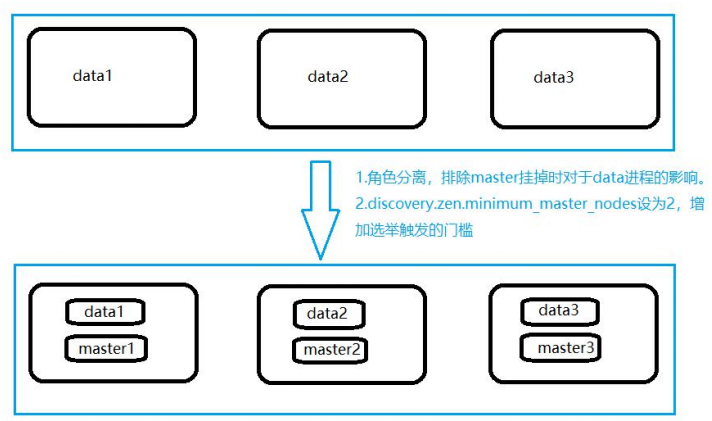
8、集群結構
以三臺物理機為例。在這三臺物理機上,搭建了 6 個 ES 的節點,三個 data 節點,三個 master節點(每臺物理機分別起了一個 data 和一個 master),3 個 master 節點,目的是達到(n/2)+1 等于 2 的要求,這樣掛掉一臺 master 后(不考慮 data),n 等于 2,滿足參數,其他兩個 master 節點都認為 master 掛掉之后開始重新選舉,
master 節點上
node.master = true
node.data = false
discovery.zen.minimum_master_nodes = 2
data 節點上
node.master = false
node.data = true
2、集群搭建

所有之前先運行:
sysctl -w vm.max_map_count=262144

我們只是測試,所以臨時修改。永久修改使用下面
#防止 JVM 報錯
echo vm.max_map_count=262144 >> /etc/sysctl.conf
sysctl -p
2.0、準備 docker 網絡
Docker 創建容器時默認采用 bridge 網絡,自行分配 ip,不允許自己指定。
在實際部署中,我們需要指定容器 ip,不允許其自行分配 ip,尤其是搭建集群時,固定 ip是必須的。
我們可以創建自己的 bridge 網絡 : mynet,創建容器的時候指定網絡為 mynet 并指定 ip即可。
查看網絡模式
docker network ls
創建一個新的 bridge 網絡
docker network create --driver bridge --subnet=192.168.0.0/16 --gateway=192.168.0.1 mynet

查看網絡信息
docker network inspect mynet
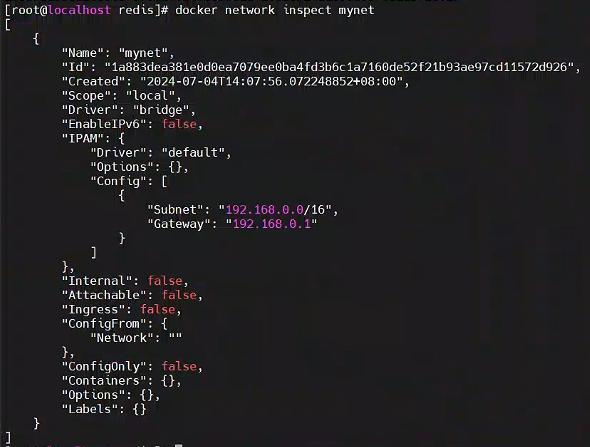
以后使用–network=mynet --ip 192.168.0.x 指定 ip
2.1、3-Master 節點創建
for port in $(seq 1 3); \
do \
mkdir -p /mydata/elasticsearch/master-${port}/config
mkdir -p /mydata/elasticsearch/master-${port}/data
chmod -R 777 /mydata/elasticsearch/master-${port}
cat << EOF >/mydata/elasticsearch/master-${port}/config/elasticsearch.yml
cluster.name: my-es #集群的名稱,同一個集群該值必須設置成相同的
node.name: es-master-${port} #該節點的名字
node.master: true #該節點有機會成為 master 節點
node.data: false #該節點可以存儲數據
network.host: 0.0.0.0
http.host: 0.0.0.0 #所有 http 均可訪問
http.port: 920${port}
transport.tcp.port: 930${port}
#discovery.zen.minimum_master_nodes: 2 #設置這個參數來保證集群中的節點可以知道其它 N 個有 master 資格的節點。官方推薦(N/2)+1
discovery.zen.ping_timeout: 10s #設置集群中自動發現其他節點時 ping 連接的超時時間
discovery.seed_hosts: ["192.168.0.21:9301", "192.168.0.22:9302", "192.168.0.23:9303"] #設置集群中的 Master 節點的初始列表,可以通過這些節點來自動發現其他新加入集群的節點,es7的新增配置
cluster.initial_master_nodes: ["192.168.0.21"] #新集群初始時的候選主節點,es7 的新增配置
EOF
docker run --name elasticsearch-node-${port} \
-p 920${port}:920${port} -p 930${port}:930${port} \
--network=mynet --ip 192.168.0.2${port} \
-e ES_JAVA_OPTS="-Xms300m -Xmx300m" \
-v /mydata/elasticsearch/master-${port}/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/master-${port}/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/master-${port}/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
done
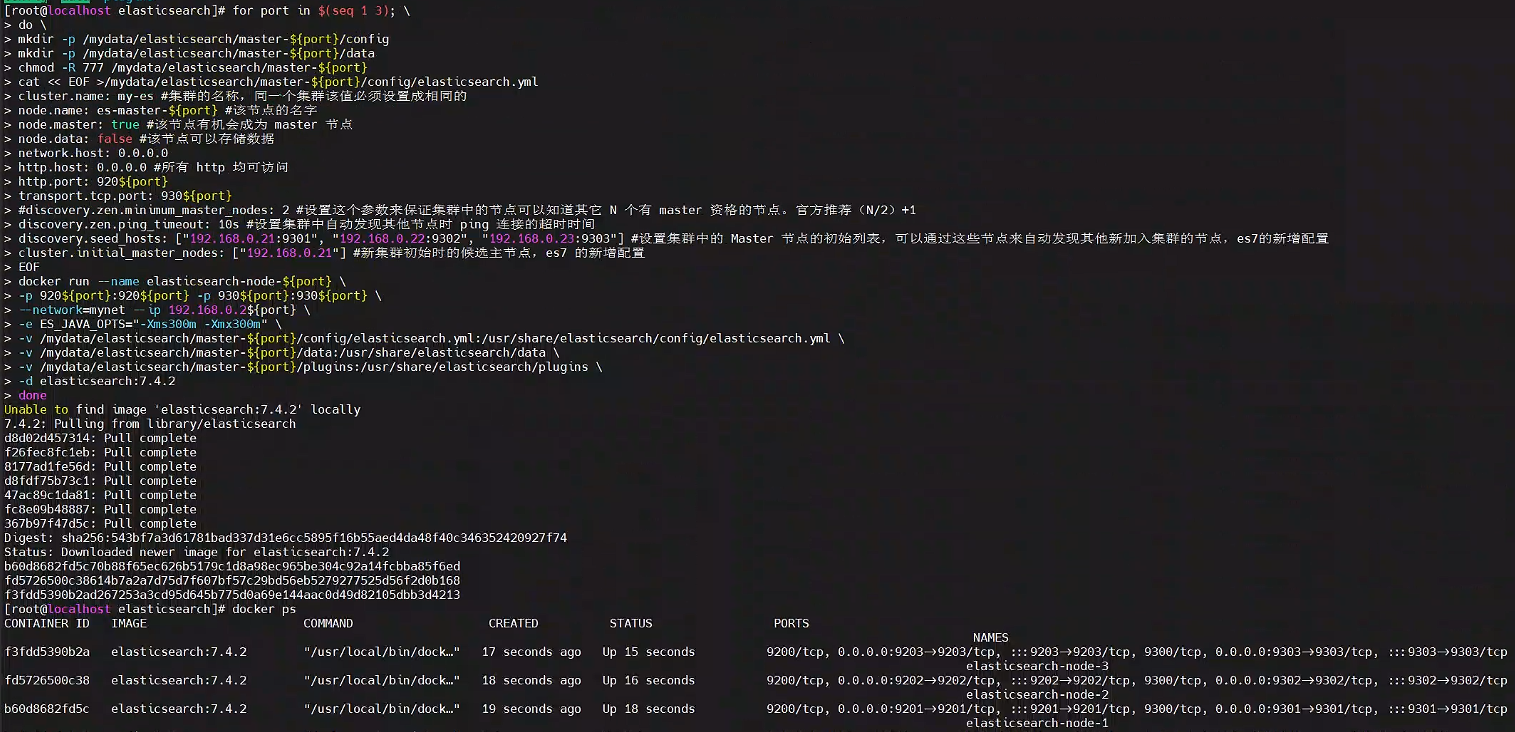
docker stop $(docker ps -a |grep elasticsearch-node-* | awk '{ print $1}')
docker rm $(docker ps -a |grep elasticsearch-node-* | awk '{ print $1}')
2.2、3-Data-Node 創建
for port in $(seq 4 6); \
do \
mkdir -p /mydata/elasticsearch/node-${port}/config
mkdir -p /mydata/elasticsearch/node-${port}/data
chmod -R 777 /mydata/elasticsearch/node-${port}
cat << EOF >/mydata/elasticsearch/node-${port}/config/elasticsearch.yml
cluster.name: my-es #集群的名稱,同一個集群該值必須設置成相同的
node.name: es-node-${port} #該節點的名字
node.master: false #該節點有機會成為 master 節點
node.data: true #該節點可以存儲數據
network.host: 0.0.0.0
#network.publish_host: 192.168.119.127 #互相通信 ip,要設置為本機可被外界訪問的 ip,否則無法通信
http.host: 0.0.0.0 #所有 http 均可訪問
http.port: 920${port}
transport.tcp.port: 930${port}
#discovery.zen.minimum_master_nodes: 2 #設置這個參數來保證集群中的節點可以知道其它 N 個有 master 資格的節點。官方推薦(N/2)+1
discovery.zen.ping_timeout: 10s #設置集群中自動發現其他節點時 ping 連接的超時時間
discovery.seed_hosts: ["192.168.0.21:9301", "192.168.0.22:9302", "192.168.0.23:9303"] #設置集群中的 Master 節點的初始列表,可以通過這些節點來自動發現其他新加入集群的節點,es7的新增配置
cluster.initial_master_nodes: ["192.168.0.21"] #新集群初始時的候選主節點,es7 的新增配置
EOF
docker run --name elasticsearch-node-${port} \
-p 920${port}:920${port} -p 930${port}:930${port} \
--network=mynet --ip 192.168.0.2${port} \
-e ES_JAVA_OPTS="-Xms300m -Xmx300m" \
-v /mydata/elasticsearch/node-${port}/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/node-${port}/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/node-${port}/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
done
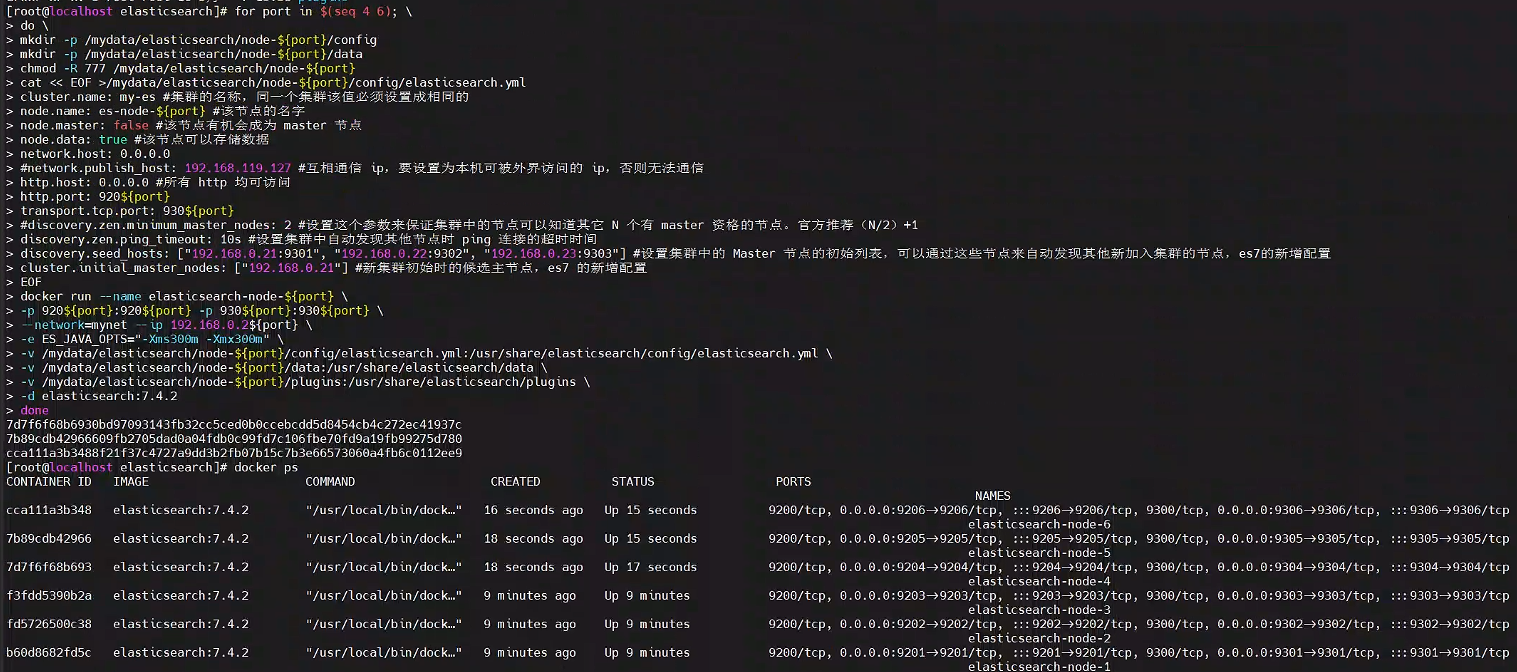
3、測試集群
http://192.168.0.21:9201/_nodes/process?pretty 查看節點狀況
http://192.168.0.21:9201/_cluster/stats?pretty 查看集群狀態
http://192.168.0.21.10:9201/_cluster/health?pretty 查看集群健康狀況
http://192.168.0.21:9202/_cat/nodes 查看各個節點信息
$ curl localhost:9200/_cat
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
3、k8s 上部署
有狀態服務
jvm.options -Xms100m
-Xmx512m
3.1、創建配置 - elastic-search-conf
-
創建配置
- 名稱:
elastic-search-conf
- 名稱:
-
配置設置
-
http.host:0.0.0.0
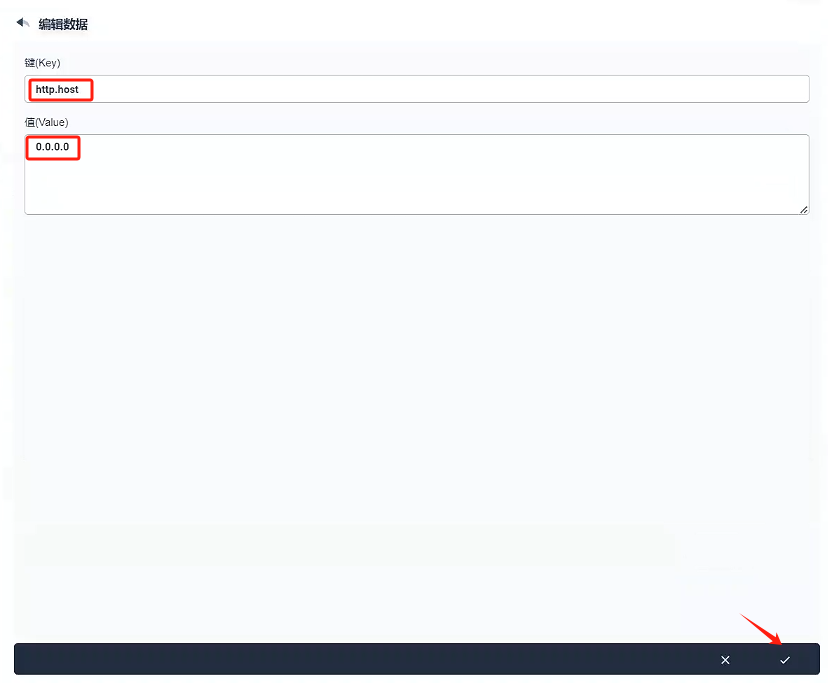
-
discovery.type:single-node

-
ES_JAVA_OPTS:-Xms64m -Xmx512m
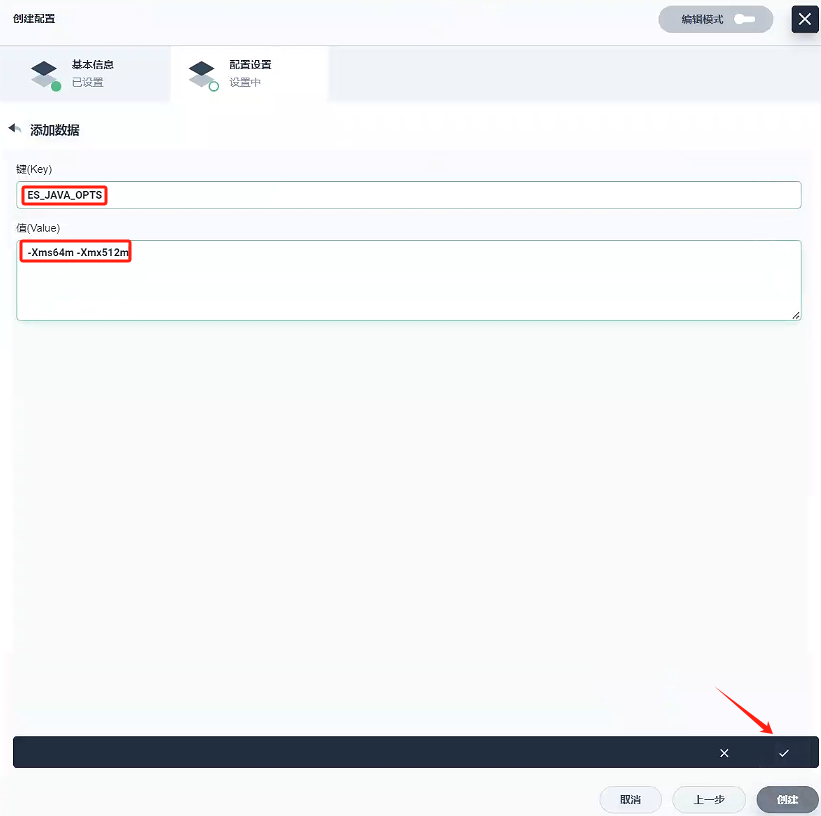
-
-
創建
3.2、創建存儲卷 - gulimall-elasticsearch-pvc
- 創建一個名稱為
gulimall-elasticsearch-pvc的存儲卷
- 下一步
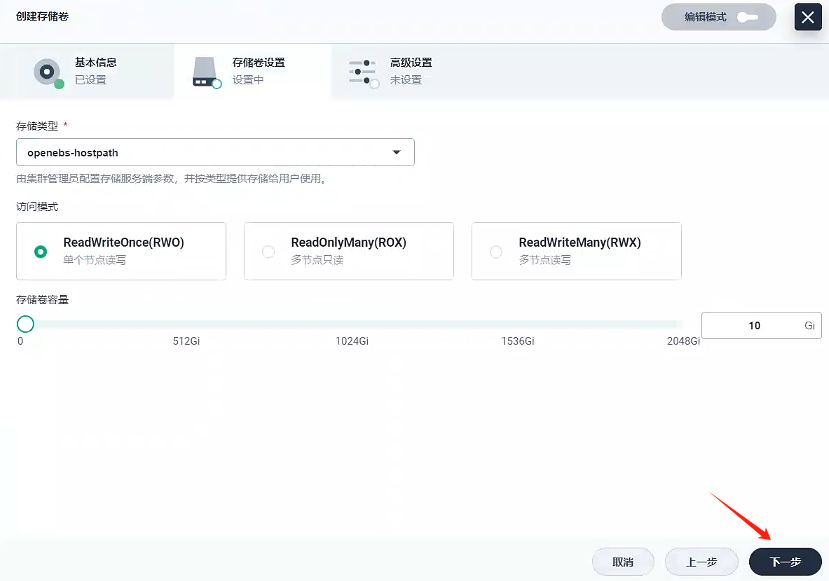
3、創建
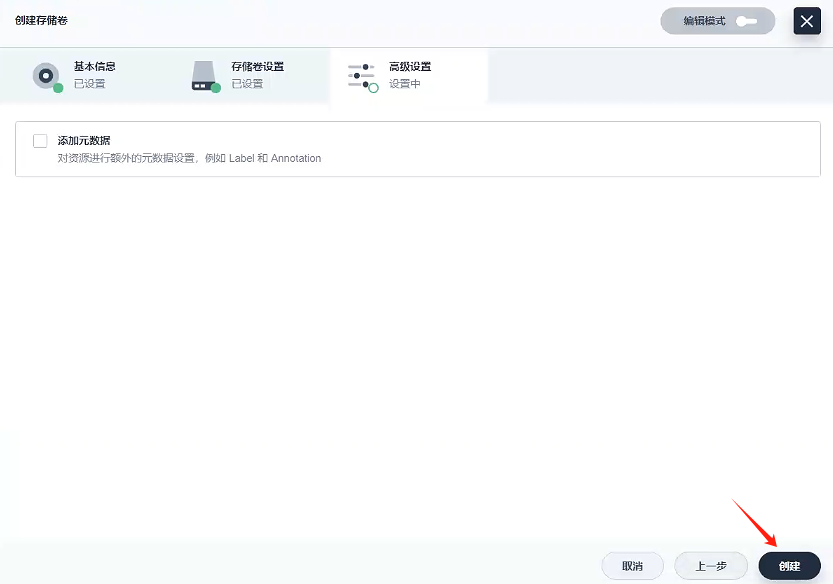
3.3、創建服務 - gulimall-elasticsearch
-
選擇有狀態服務
-
基本信息
- 名稱:gulimall-elasticsearch
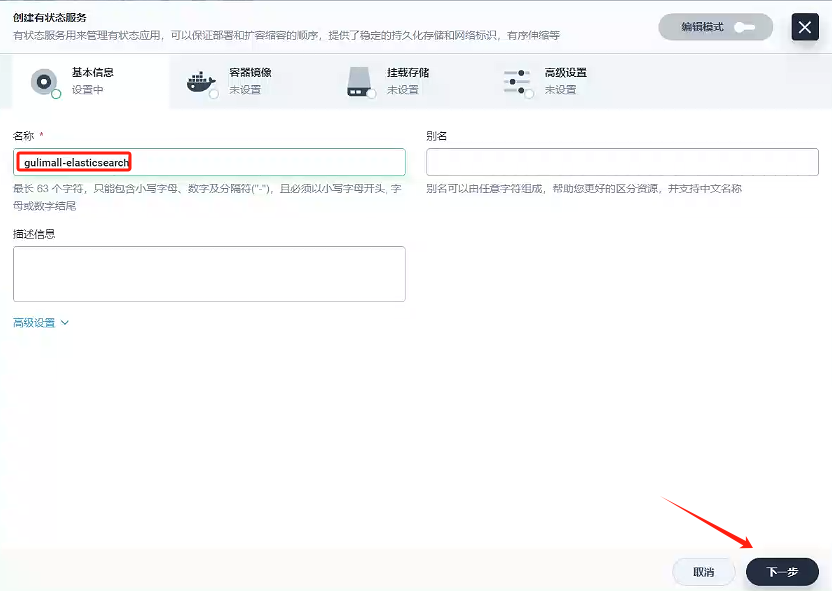
- 名稱:gulimall-elasticsearch
-
容器鏡像
- 因為就一個容器,我們容器組選擇容器組默認部署就好
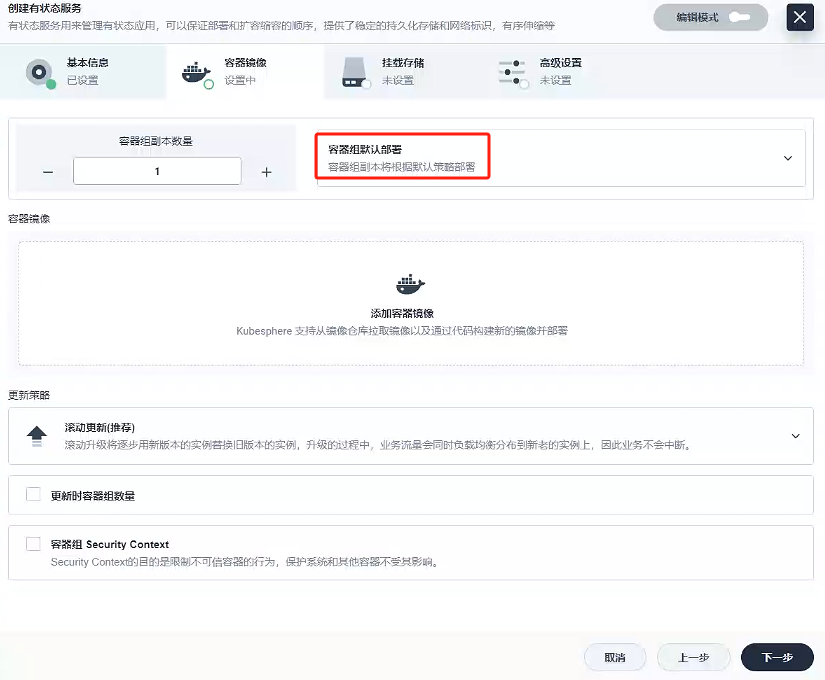
- 添加容器鏡像
這里我們使用的私有鏡像倉庫-Harbor創建容器,使用默認端口
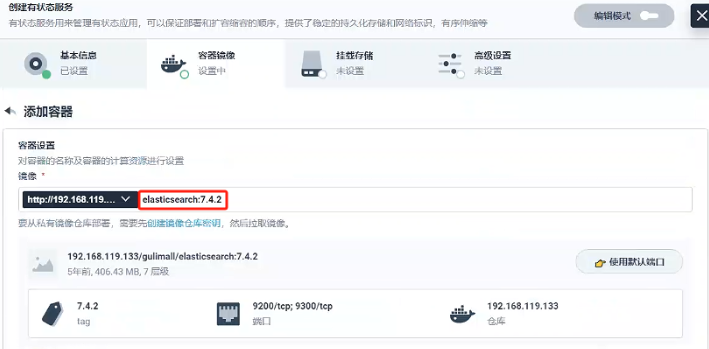
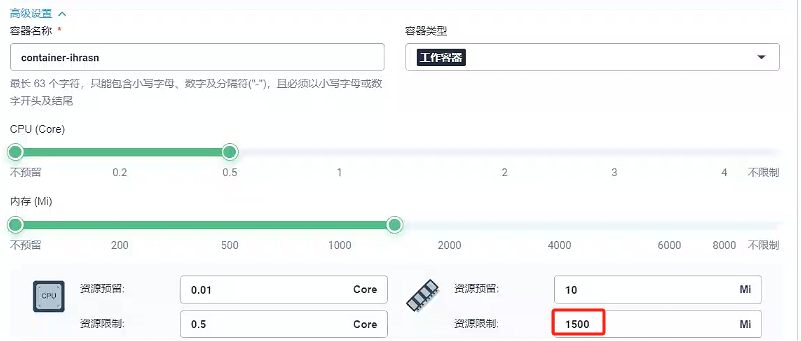
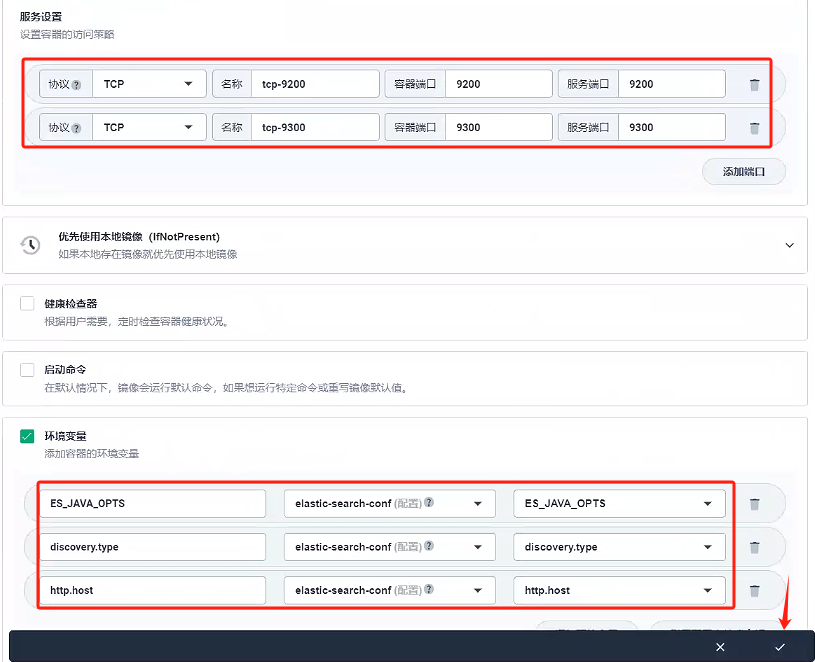
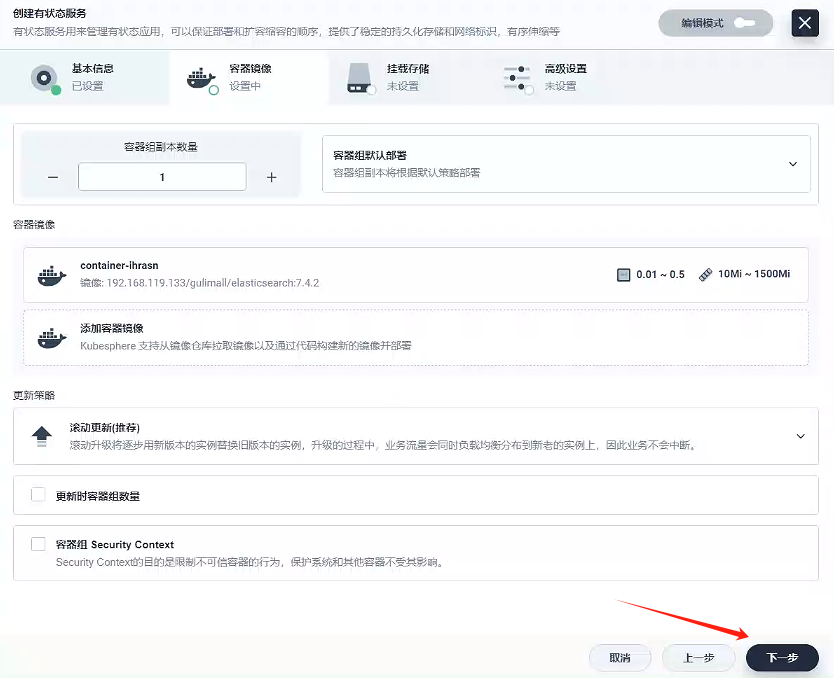
- 因為就一個容器,我們容器組選擇容器組默認部署就好
-
掛載存儲
這里掛載路徑參考docker創建elasticsearch的路徑/usr/share/elasticsearch/data
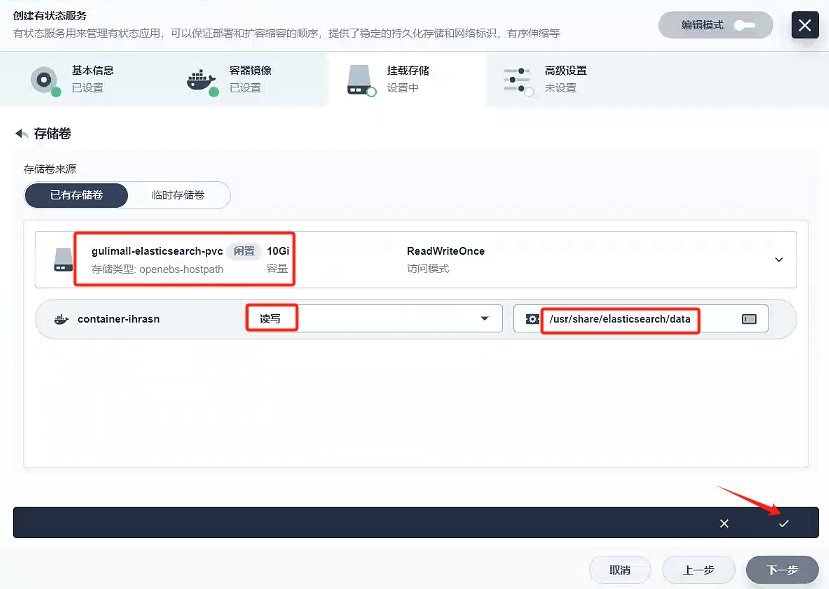
-
下一步
-
創建

3.4、測試
以admin登錄kubespere,進入控制臺
查看elasticsearch有json數據,則安裝成功。
/ # curl http://gulimall-elasticsearch.gulimall:9200
{"name" : "gulimall-elasticsearch-z8eh94-0","cluster_name" : "docker-cluster","cluster_uuid" : "fc3Pm8DLTzCXSHGYXR8oTA","version" : {"number" : "7.4.2","build_flavor" : "default","build_type" : "docker","build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96","build_date" : "2019-10-28T20:40:44.881551Z","build_snapshot" : false,"lucene_version" : "8.2.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"
}
3.5、創建服務 - gulimall-kibana
-
創建一個無狀態服務
-
填寫基礎信息
- 名稱:gulimall-kibana
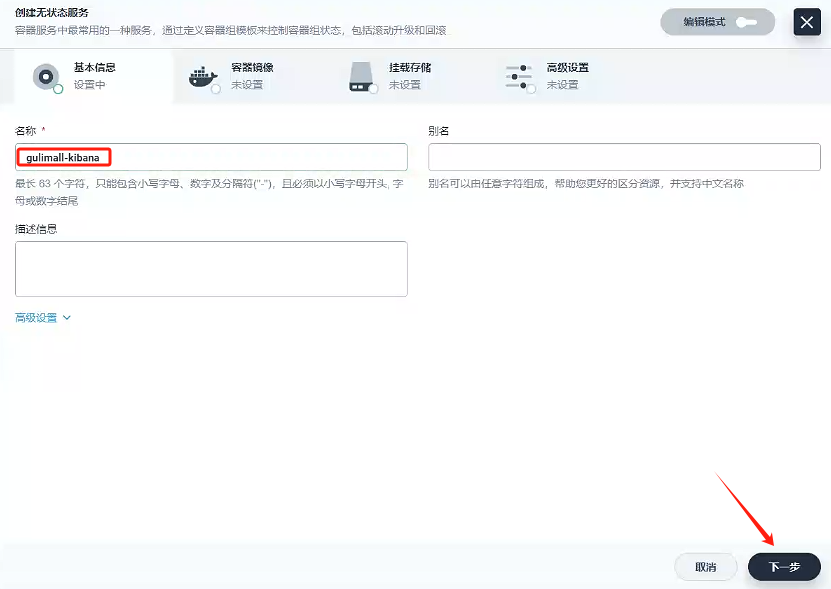
- 名稱:gulimall-kibana
-
容器鏡像
- 因為就一個容器,我們容器組選擇容器組默認部署就好
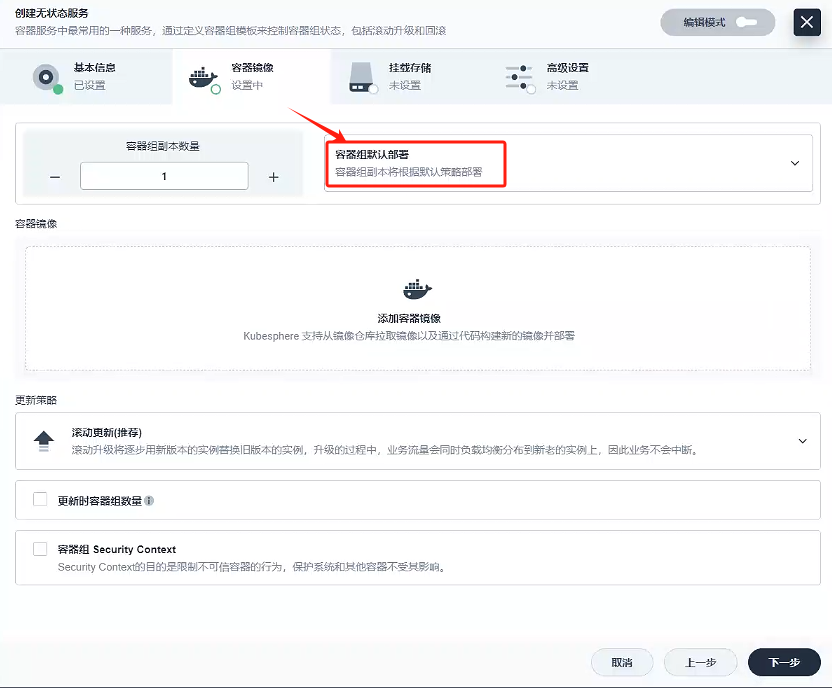
- 添加容器鏡像
這里我們使用的私有鏡像倉庫-Harbor創建容器,使用默認端口
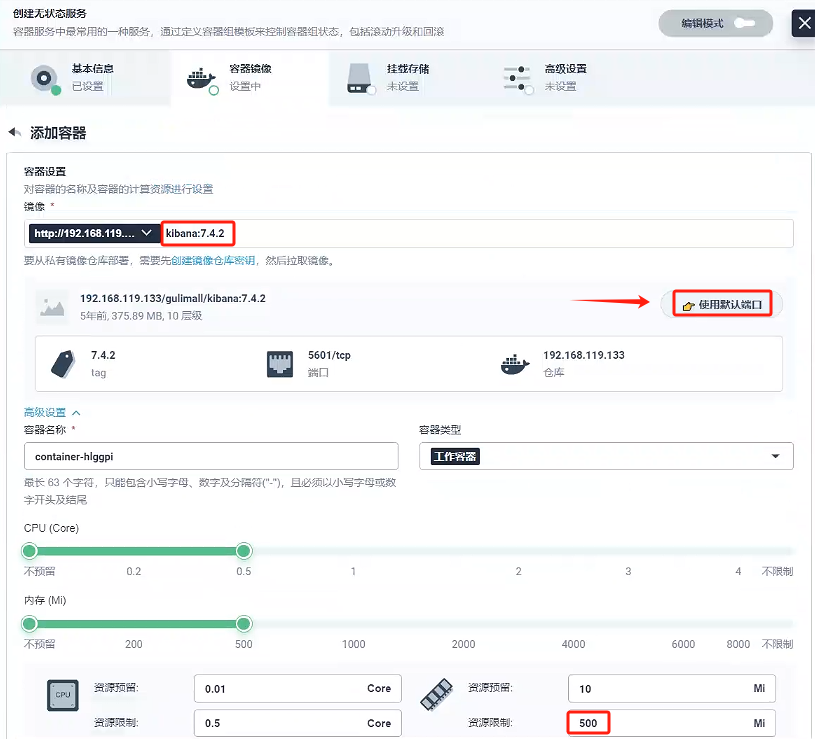
我們需要訪問elasticsearch路徑,這里環境變量配置
ELASTICSEARCH_HOSTS:http://gulimall-elasticsearch.gulimall:9200
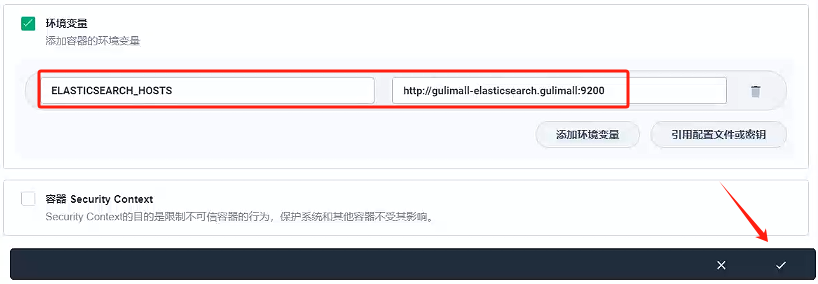
- 因為就一個容器,我們容器組選擇容器組默認部署就好
-
掛載存儲
不需要掛載,直接下一步

-
創建
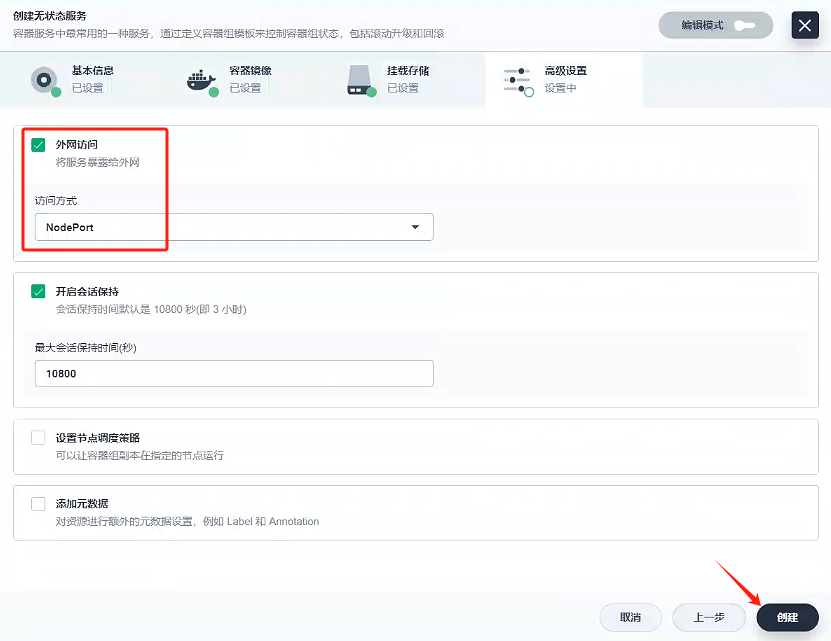
配置外網訪問,這樣我們可以在外網訪問kabana
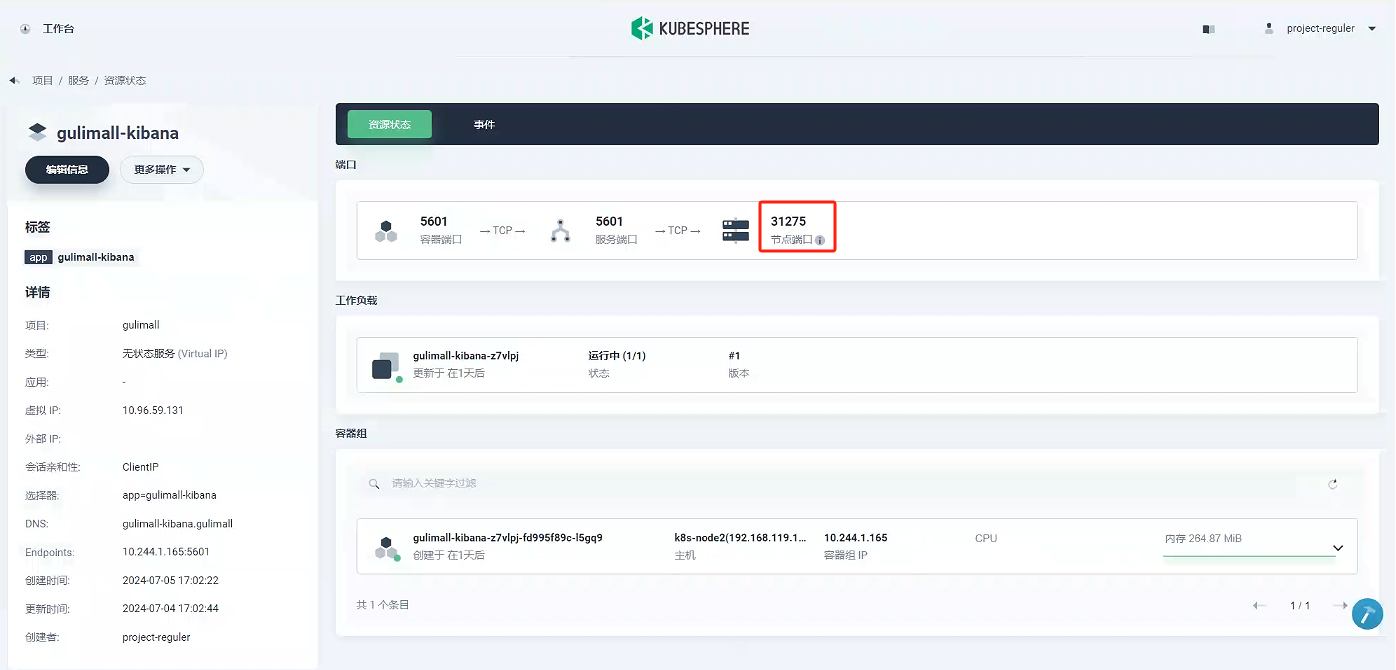
我們可以看到外網訪問的端口為31275
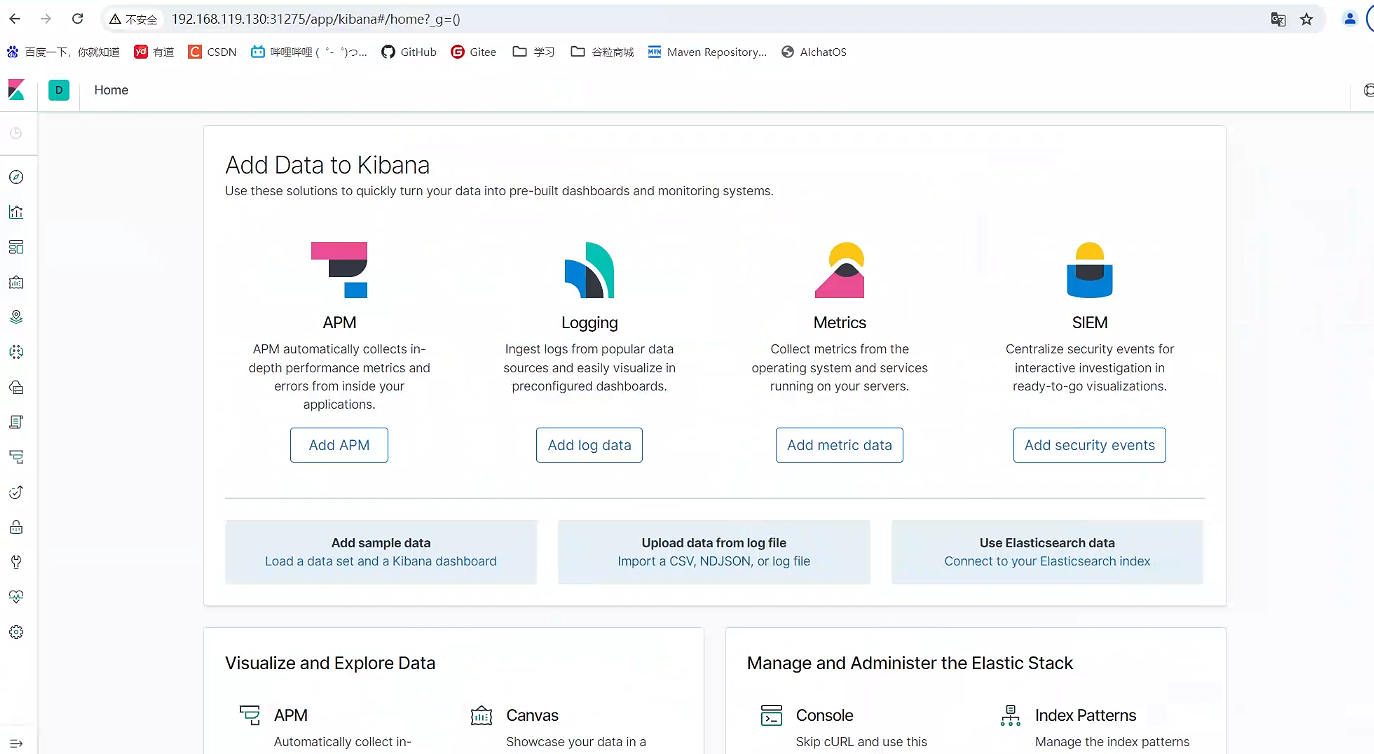
瀏覽器訪問:http://192.168.119.130:31275
八、RabbitMQ 集群
1、集群形式
RabbiMQ 是用 Erlang 開發的,集群非常方便,因為 Erlang 天生就是一門分布式語言,但其本身并不支持負載均衡。
RabbitMQ 集群中節點包括內存節點(RAM)、磁盤節點(Disk,消息持久化),集群中至少有一個 Disk 節點。
-
普通模式(默認)
對于普通模式,集群中各節點有相同的隊列結構,但消息只會存在于集群中的一個節點。對于消費者來說,若消息進入 A 節點的 Queue 中,當從 B 節點拉取時,RabbitMQ 會將消息從 A 中取出,并經過 B 發送給消費者。
應用場景:該模式各適合于消息無需持久化的場合,如日志隊列。當隊列非持久化,且創建該隊列的節點宕機,客戶端才可以重連集群其他節點,并重新創建隊列。若為持久化,只能等故障節點恢復。 -
鏡像模式
與普通模式不同之處是消息實體會主動在鏡像節點間同步,而不是在取數據時臨時拉取,高可用;該模式下,mirror queue 有一套選舉算法,即 1 個 master、n 個 slaver,生產者、消費者的請求都會轉至 master。應用場景:可靠性要求較高場合,如下單、庫存隊列。
缺點:若鏡像隊列過多,且消息體量大,集群內部網絡帶寬將會被此種同步通訊所消耗。
(1)鏡像集群也是基于普通集群,即只有先搭建普通集群,然后才能設置鏡像隊列。
(2)若消費過程中,master 掛掉,則選舉新 master,若未來得及確認,則可能會重復消費。
1.1、搭建集群
mkdir /mydata/rabbitmq
cd rabbitmq/
mkdir rabbitmq01 rabbitmq02 rabbitmq03
docker run -d --hostname rabbitmq01 --name rabbitmq01 \
-v /mydata/rabbitmq/rabbitmq01:/var/lib/rabbitmq \
-p 15673:15672 \
-p 5673:5672 \
-e RABBITMQ_ERLANG_COOKIE='atguigu' rabbitmq:management
docker run -d --hostname rabbitmq02 --name rabbitmq02 \
-v /mydata/rabbitmq/rabbitmq02:/var/lib/rabbitmq \
-p 15674:15672 \
-p 5674:5672 \
-e RABBITMQ_ERLANG_COOKIE='atguigu' \
--link rabbitmq01:rabbitmq01 rabbitmq:management
docker run -d --hostname rabbitmq03 --name rabbitmq03 \
-v /mydata/rabbitmq/rabbitmq03:/var/lib/rabbitmq \
-p 15675:15672 \
-p 5675:5672 \
-e RABBITMQ_ERLANG_COOKIE='atguigu' \
--link rabbitmq01:rabbitmq01 \
--link rabbitmq02:rabbitmq02 rabbitmq:management

--hostname 設置容器的主機名
RABBITMQ_ERLANG_COOKIE 節點認證作用,部署集成時 需要同步該值
1.2、節點加入集群
docker exec -it rabbitmq01 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
exit
進入第二個節點
docker exec -it rabbitmq02 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit

進入第三個節點
docker exec -it rabbitmq03 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit

訪問一個節點后臺:http://192.168.119.127:15675/ 可以看到集群搭建成功。
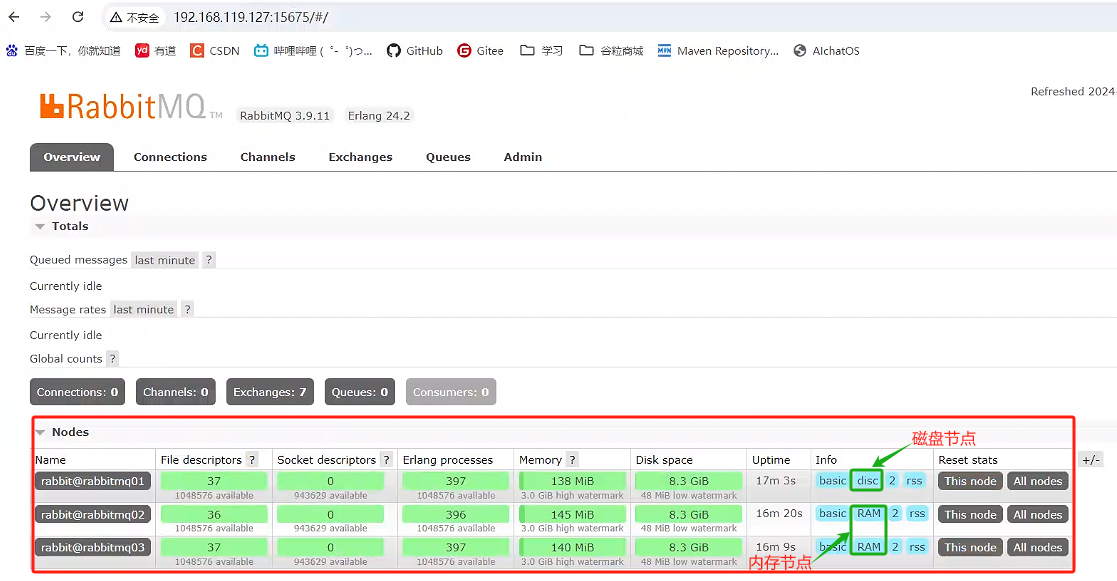
但是,目前只是一個普通集群,普通集群會出現單點故障的問題,下面我們繼續實現鏡像集群。
1.3、實現鏡像集群
docker exec -it rabbitmq01 bash
rabbitmqctl set_policy -p / ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
rabbitmqctl set_policy -p / ha-all “^” ’{“ha-mode”:“all”}’
策略模式 all 即復制到所有節點,包含新增節點,策略正則表達式為 “^” 表示所有匹配所有隊列名稱。“^hello”表示只匹配名為 hello 開始的隊列

可以使用 rabbitmqctl list_policies -p /;查看 vhost/下面的所有 policy在 cluster 中任意節點啟用策略,策略會自動同步到集群節點
[root@localhost rabbitmq]# docker exec -it rabbitmq01 bash
root@rabbitmq01:/# rabbitmqctl list_policies -p /

2、集群測試
隨便在 mq 上創建一個隊列,發送一個消息,保證整個集群其他節點都有這個消息。如果master 宕機,其他節點也能成為新的 master
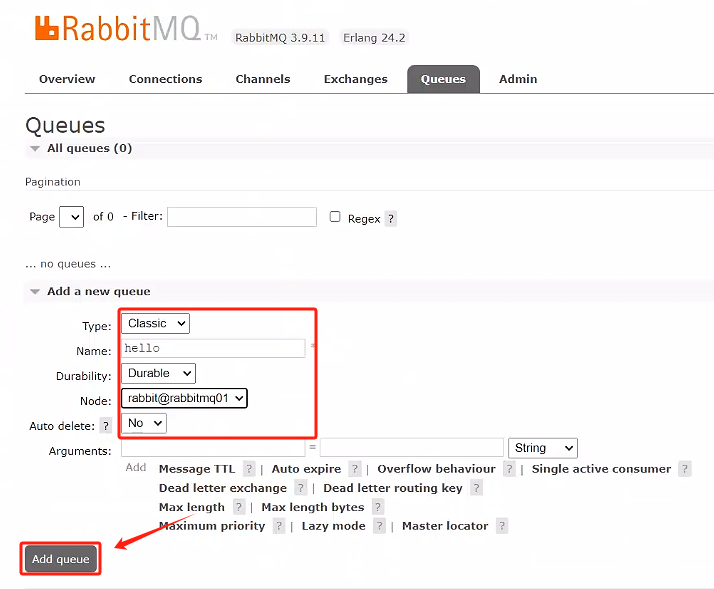
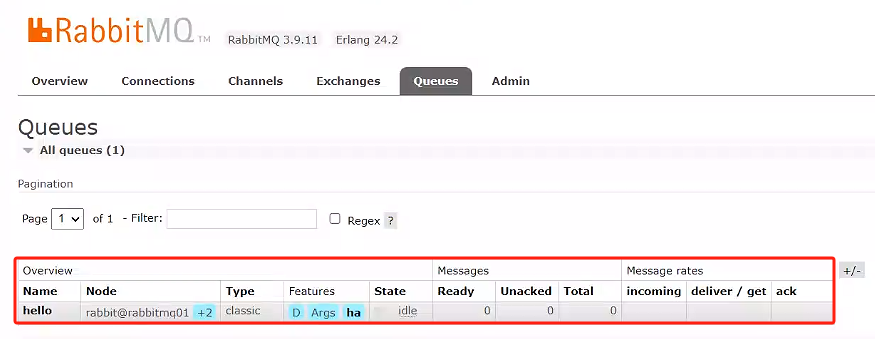
- 在rabbitmq01創建一個隊列,看看其他的rabbitmq有沒有隊列

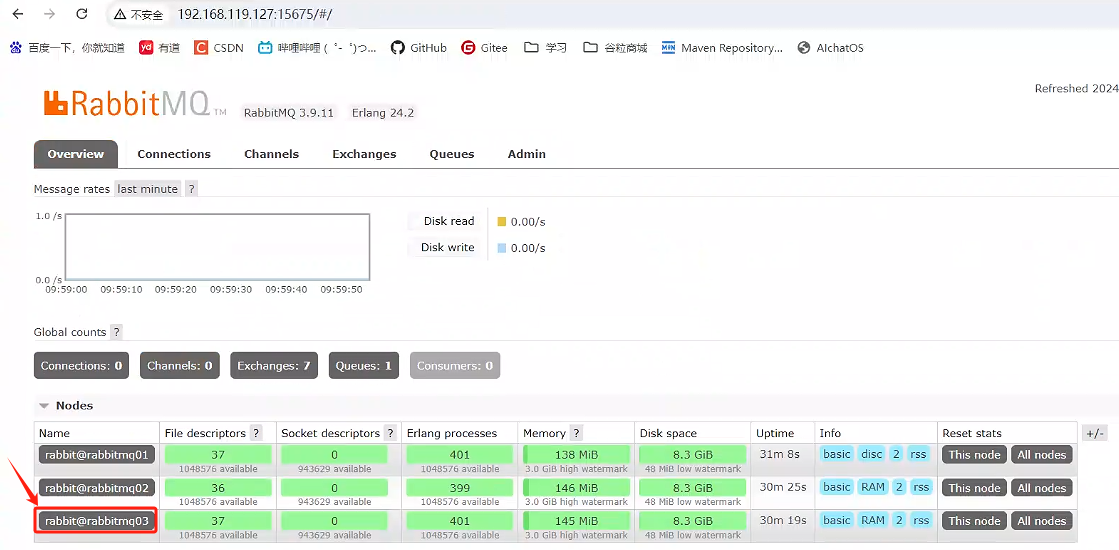
點擊rabbitmq03,查看是否有隊列
- 在rabbitmq01發送一個持久化消息,看看其他rabbitmq有沒有消息并手動確認消費,再查看是否都消費掉
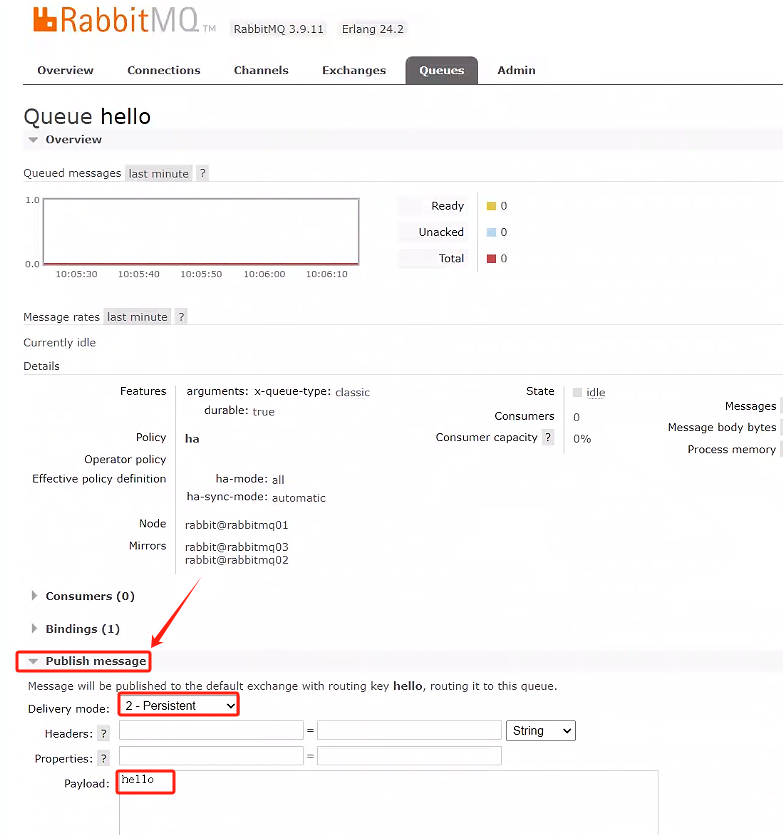
點擊rabbitmq02查看隊列是否有消息,并手動確認消費掉
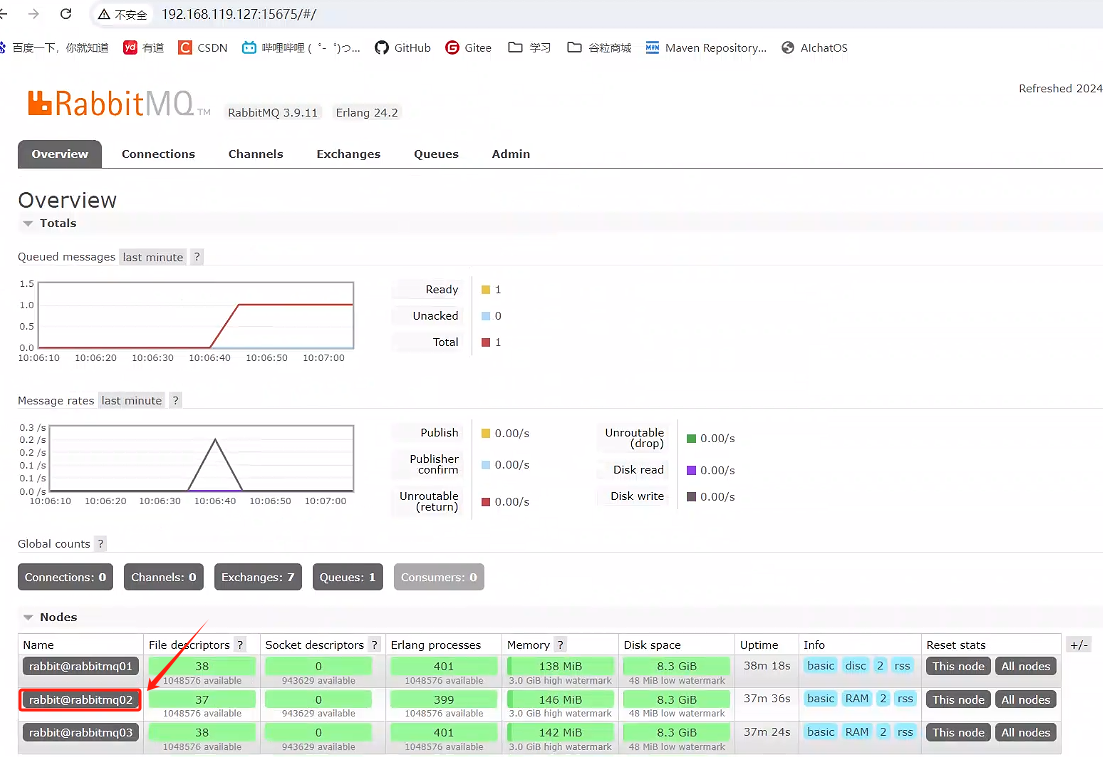
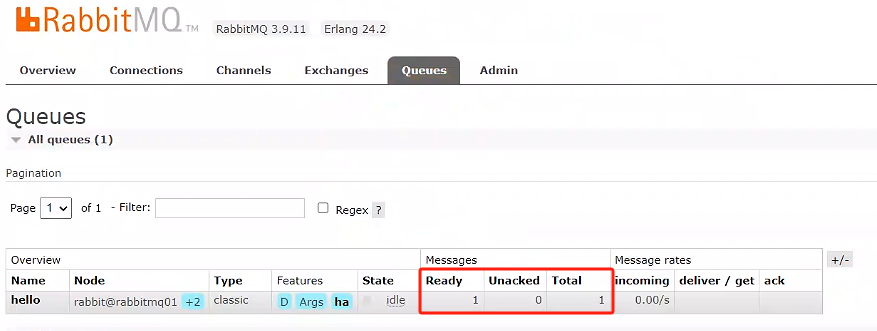
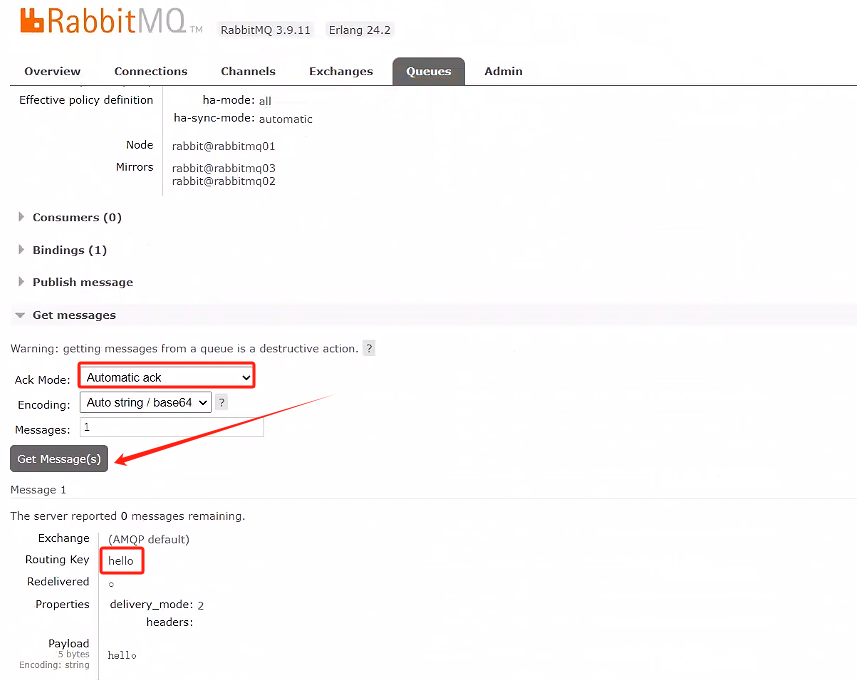
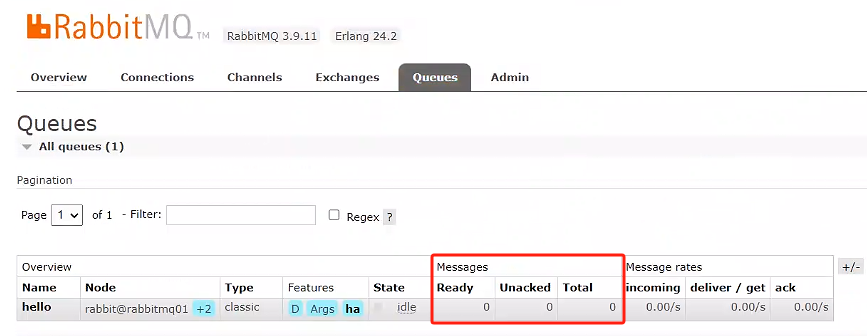
查看其他rabbitmq01、rabbitmq02、rabbitmq03是否都消費掉
3、k8s 上部署
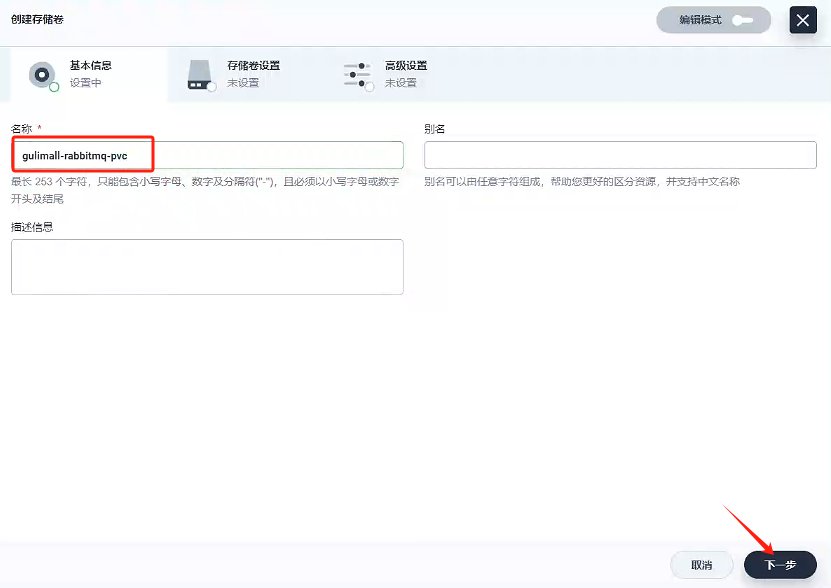
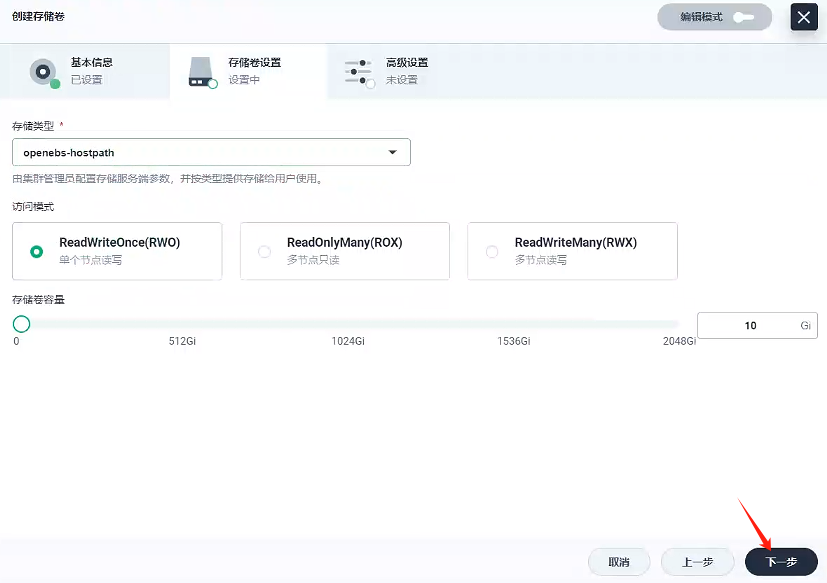
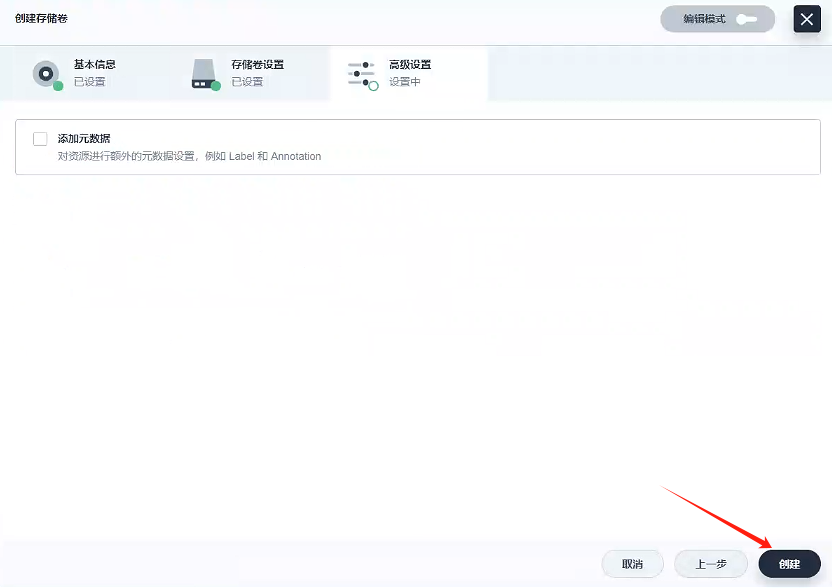
3.1、創建存儲卷 - gulimall-rabbitmq-pvc
創建一個名稱為gulimall-rabbitmq-pvc的存儲卷
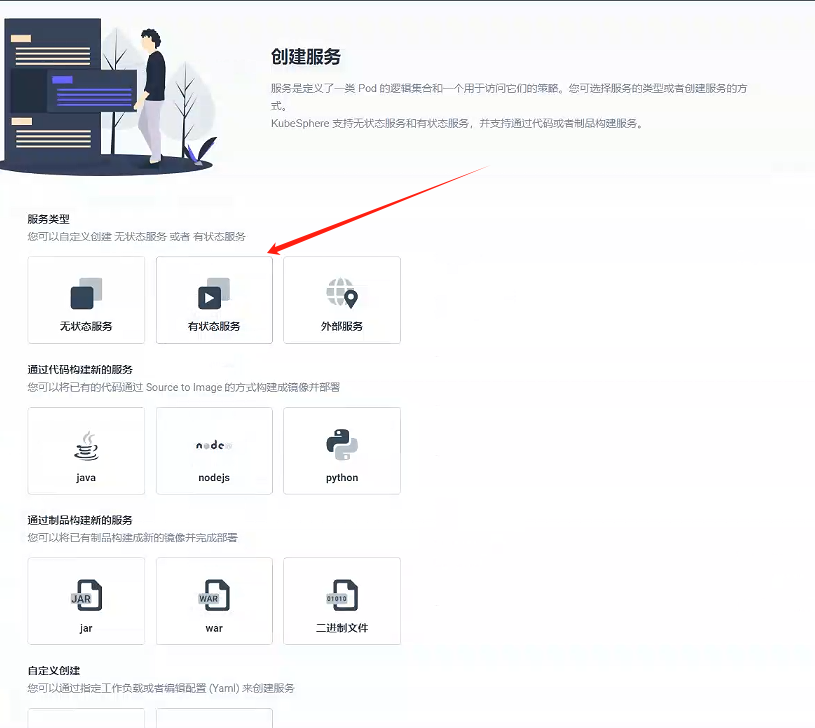
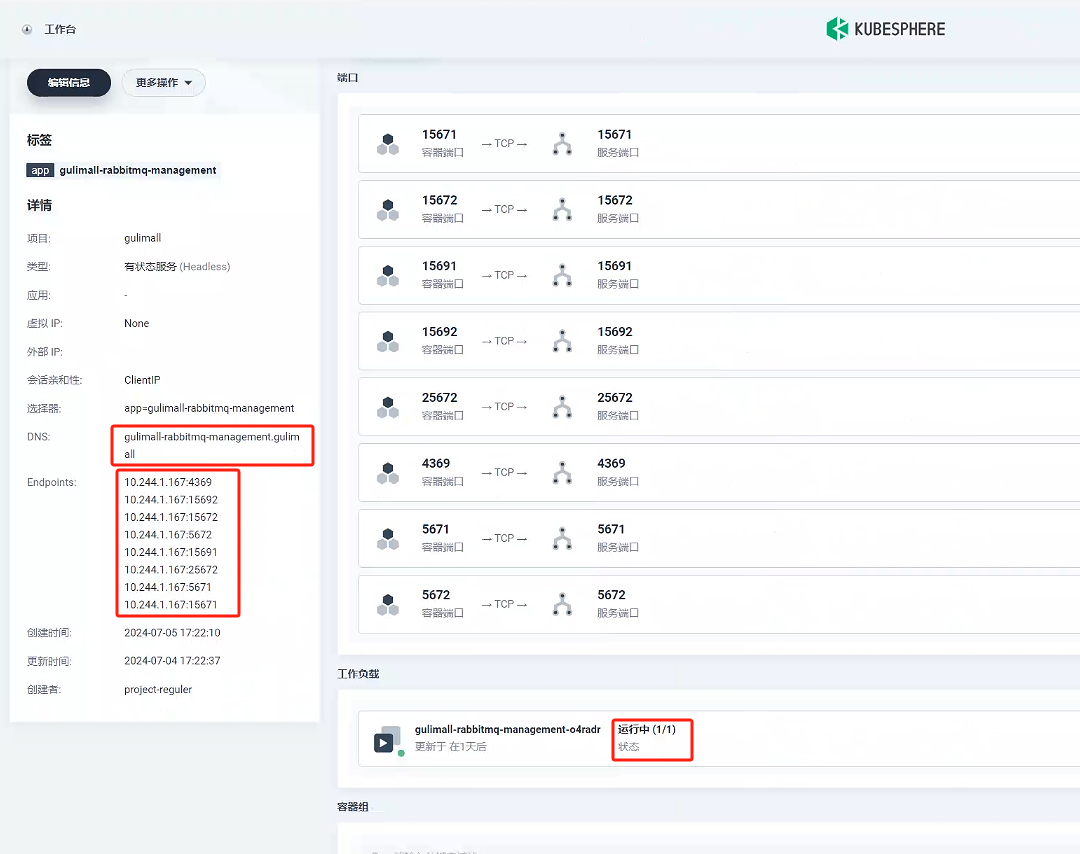
3.2、創建服務 - gulimall-rabbitmq-management
- 創建一個有狀態服務
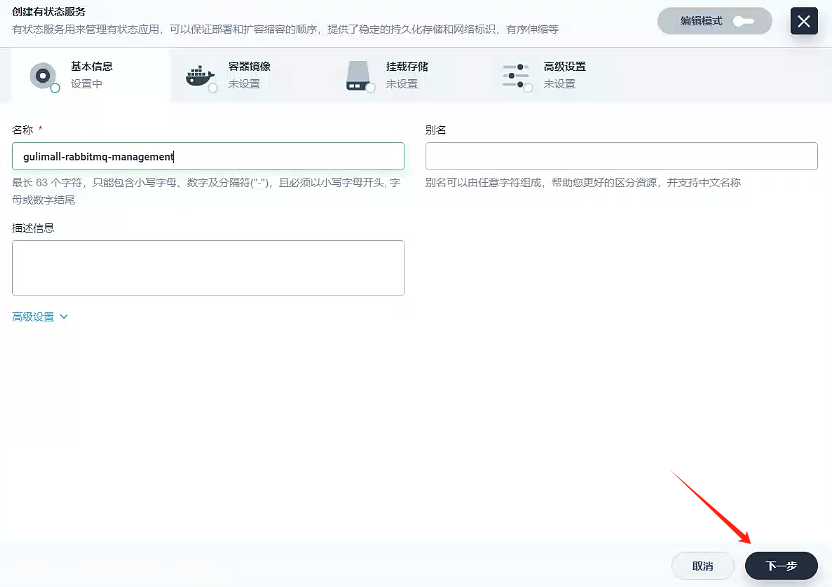
- 填寫基本信息
- 名稱 :
gulimall-rabbitmq-management
- 名稱 :
- 容器鏡像
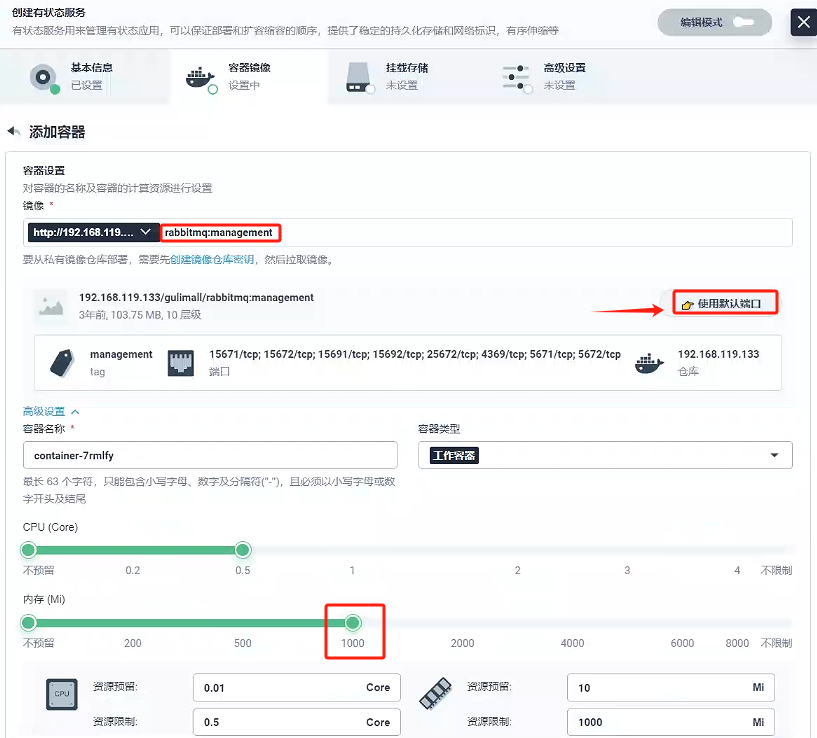
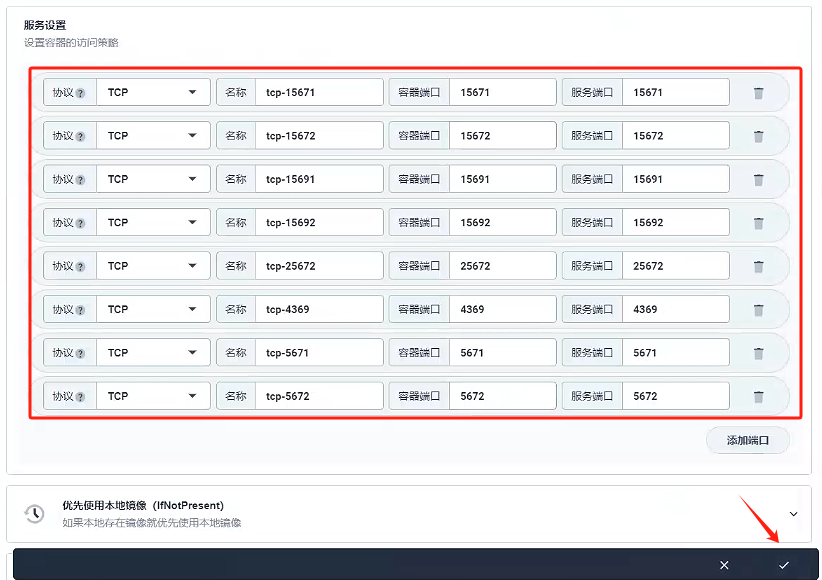
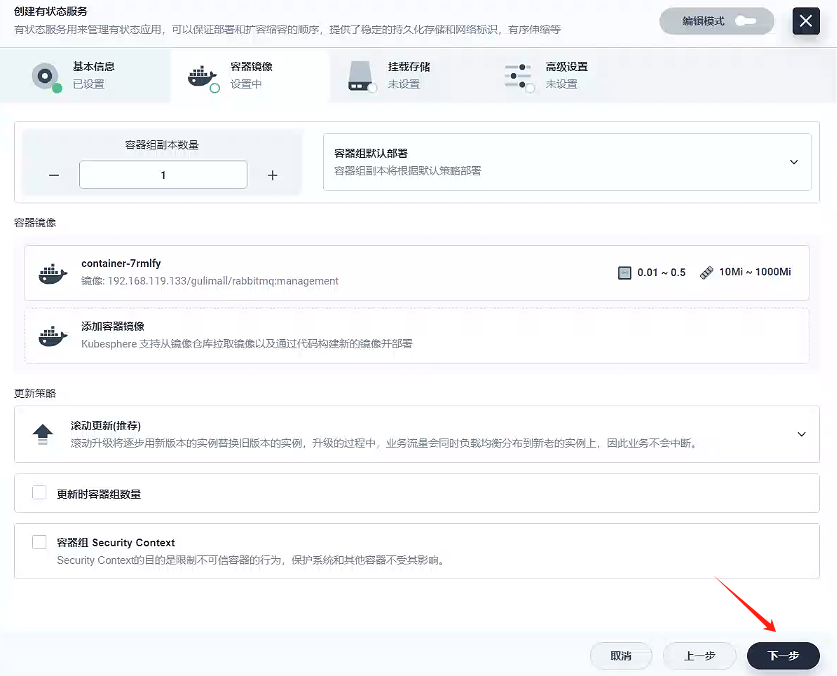
- 掛載存儲
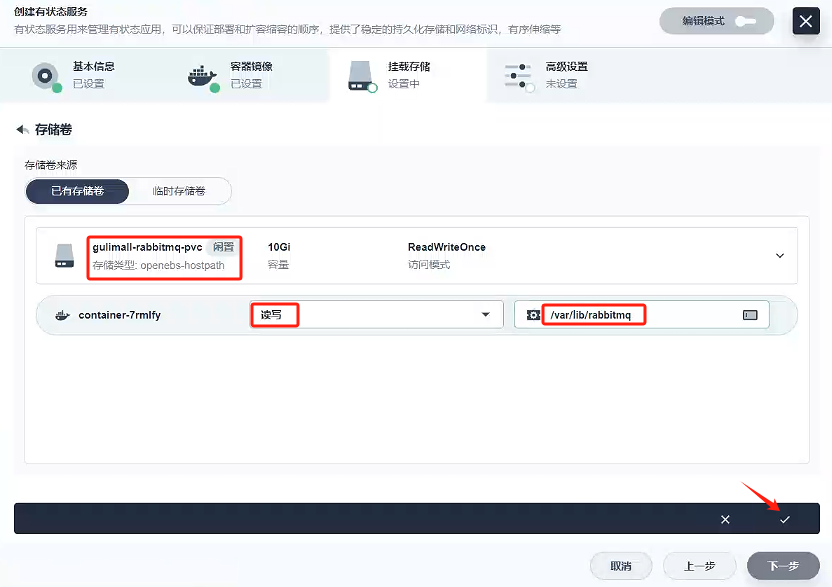
掛載路徑參考原先docker創建rabbitmq的路徑:/var/lib/rabbitmq

- 創建
九、其他集群搭建
1、k8s 部署 nacos
以前docker部署命令
docker run --env MODE=standalone --name nacos \
-v /mydata/nacos/conf:/home/nacos/conf -d -p 8848:8848 nacos/nacos-server:v2.1.1
1.1、創建存儲卷 - gulimall-nacos-pvc



1.2、創建服務 - gulimall-nacos
-
選擇一個有狀態服務

-
填寫基礎信息
- 名稱:gulimall-nacos

- 名稱:gulimall-nacos
-
容器鏡像
-
因為單機部署所以選擇容器組默認部署

-
添加容器鏡像
鏡像:nacos/nacos-server:v2.1.1注意:內存至少1000M,否則容易內存溢出,服務創建失敗
 添加環境變量
添加環境變量 MODE:standalone

-
-
掛載存儲
掛載路徑:/home/nacos/data


-
創建


1.3、如何把已部署的有狀態服務做成外網訪問?
1、通過nginx代理,外網可以訪問
2、刪除服務,重新創建無狀態服務
我們使用第二種方式,但是我們不是完全刪除,之刪除服務,像容器組不刪除。
- 刪除服務,有狀態負載集不刪除

服務里沒有了nacos

容器組還有nacos

- 創建指定工作負載的服務

- 填寫基本信息

- 指定工作負載

- 服務設置

- 創建
設置外網訪問

- 可以看到對外暴露端口號:30271

8、隨便選則一個節點ip訪問,訪問地址:http://192.168.119.130:30271/nacos

2、k8s 部署 zipkin
docker run -d -p 9411:9411 openzipkin/zipkin
或者
docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.10:9200 openzipkin/zipkin
2.1、創建服務 - gulimall-zipkin
-
選擇無狀態服務

-
填寫基礎信息
- 名稱:
gulimall-zipkin - 別名:鏈路追蹤

- 名稱:
-
容器鏡像
- 選擇容器組默認部署

- 添加容器鏡像
鏡像:openzipkin/zipkin

環境變量- STORAGE_TYPE:elasticsearch
- ES_HOSTS:http://gulimall-elasticsearch.gulimall:9200


- 選擇容器組默認部署
-
掛載存儲

-
創建

-
外網訪問端口號:31610

-
隨便找一個節點ip進行測試:http://192.168.119.130:31610/zipkin/

3、k8s 部署 sentinel
可以制作一個鏡像并啟動它,暴露訪問
docker run --name sentinel -d -p 8858:8858 -d bladex/sentinel-dashboard:1.6.3
3.1、創建服務 - gulimall-sentinel
- 選擇無狀態服務
- 填寫基礎信息
- 名稱:
gulimall-sentinel - 別名:熔斷/降級服務

- 名稱:
- 容器鏡像
- 選擇容器組默認部署
- 添加容器鏡像
鏡像:bladex/sentinel-dashboard:1.6.3



- 選擇容器組默認部署
- 掛載存儲

- 創建
設置外網訪問

6、外網可以訪問的端口號:30702
- 隨便選擇一個節點ip,進行測試:http://192.168.119.130:30702/





![[leetcode]minimum-absolute-difference-in-bst 二叉搜索樹的最小絕對差](http://pic.xiahunao.cn/[leetcode]minimum-absolute-difference-in-bst 二叉搜索樹的最小絕對差)









)




