前言
就在幾天前,Stability AI正式開源了Stable Diffusion 3 Medium(以下簡稱SD3M)模型和適配CLIP文件。這家身處風雨飄搖中的公司,在最近的一年里一直處于破產邊緣,就連創始人兼CEO也頂不住壓力提桶跑路。

即便這樣,它依然被譽為生成式AI的Top3之一,比肩OpenAI和Midjourney的存在……沒錯,Stability AI就是那個唯一的開源公司。真正的Open Source半死不活,閉源公司萬人追捧,這就是真實的世界,首先掙錢,再談尊嚴。
SDXL發布的時候,我就寫過深度測評,這次同樣拒絕信息差,沒有廢話,給一個SD3M最直觀的感受。
以下只討論官方發布的基礎版本模型,不包括開源社區發布的融合版。
Q:作為當前主流SD1.5,SDXL與SD3M有什么區別?
A:主要有三點區別
最顯著的是模型規模和參數:
SD1.5參數為8600萬;SDXL包含2.6億參數,是1.5的3倍;SD3的模型參數范圍從8億到80億,對應模型體積也不相同。
顯而易見,以SD3M模型本體4GB的大小,在它之上至少還有1-2個體積更大的版本(已知SD3 Ultra存在)沒有開源。
其次是語義理解能力:
SD1.5雖然采用了CLIP模型將自然語言與圖像對應,但實際效果只能說聊勝于無,稍微復雜一點的長句就歇菜;
SDXL有所改進,一個CLIP不夠兩個來湊,能理解長句,還能勉強畫出特定語種的文字,比如英文;
SD3M更進一步,直接在訓練時就引入Transformer,直接搭建Diffusion-Transformer俗稱DiT的結構(沒錯年初紅極一時的Sora也是這個路徑),帶來的好處顯而易見,就是真的能“聽懂人話”,這里暫且不表,下一段再展開來說。
最后是出圖質量:
正如真理只在大炮射程之內,畫質的高低同樣取決于像素。能堆出的像素越多,畫面看起來就越精致,簡單粗暴。
SD1.5默認像素512x512,如果過度提高像素(1024以上),很多時候會出現畸變導致畫面崩壞;
SDXL默認像素1024起步,畫面精細度肉眼可見的提高,但相比之下對GPU資源的消耗倍增,經常煉丹的朋友應該深有感受,動輒700m,大至1.3G的微調模型,真的難頂;
SD3M同樣是1024起步,畫質好于SDXL,主要是在對顏色和光影的把控上更為精準,8G顯存就能帶得動,直覺上感到這會是SDXL的平行替代品。
Q:相比起前幾個版本,SD3M最顯著的突破在哪里?
A:重點就在DiT這里,更具體一點,官方將其稱為Multimodal Diffusion Transformer (MMDiT)
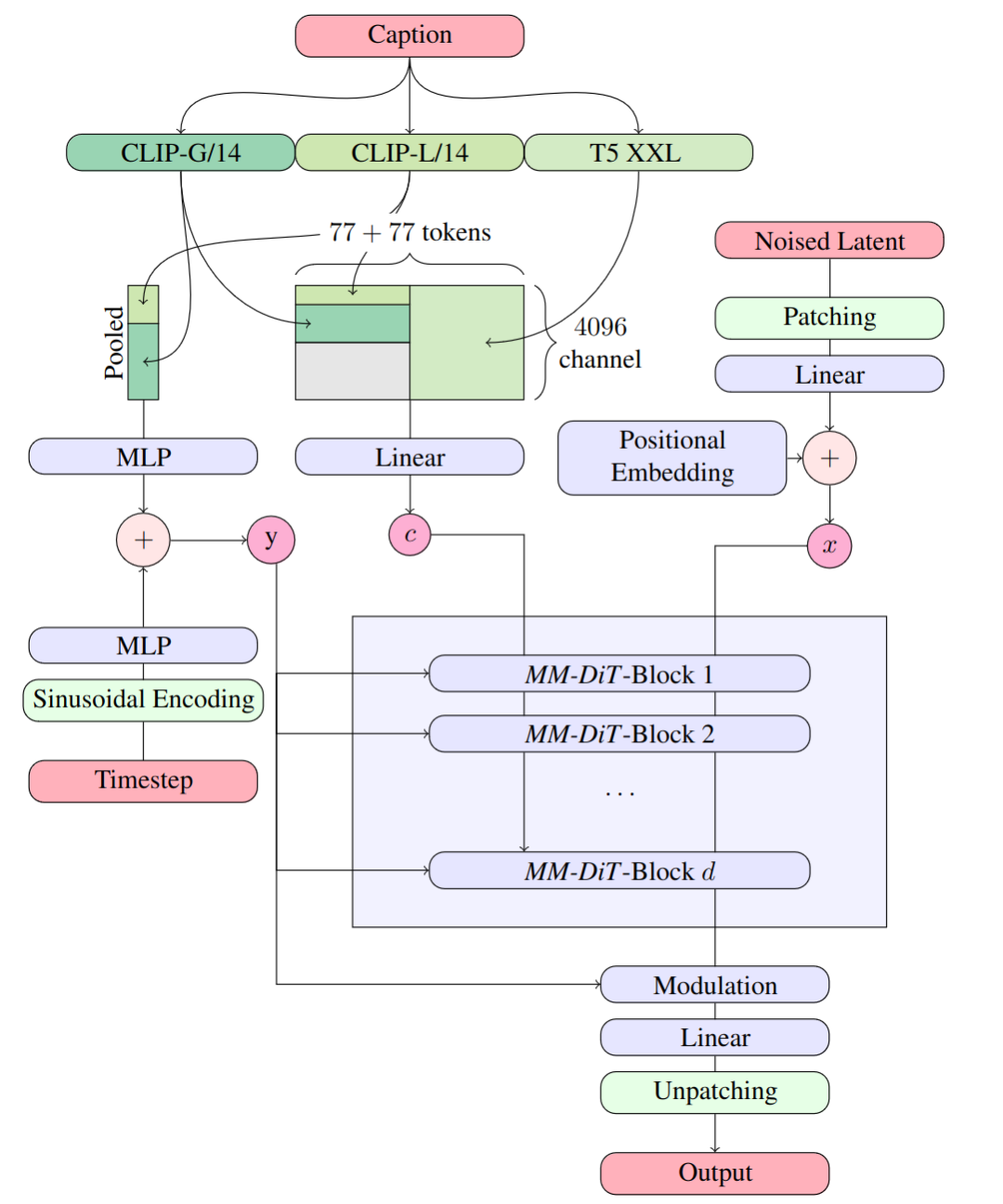
流程圖看上去很復雜,實際上翻譯成人話就是:模型現在更能看懂你想表達的意思。
經常抽卡的朋友應該深有體會,在文生圖時,如果不加入控制條件,你讓人物頭戴一束花環,那么大概率在圖的背景中同樣會出現鮮花;又比如描述人物穿著的上衣繡著小貓圖案,那么很大的可能這只小貓會出現在人的腳邊;更不必說同一場景中描述多人物,簡直就是一場難以形容的災難。
大語言模型的加入解決了一個重要的問題:語義理解。
經常研究U-Net潛空間的朋友都知道,從SD1.5開始潛空間深度學習是成對的,一邊是文字標簽caption,一邊是對應的圖像表達,經過多輪加噪聲和去像素,最終保存成經過預訓練的文件。
然而現實世界中很少有詞或詞組是唯一概念,比如我們說“這只貓真好看”,有可能這是一只真的貓,有可能是一只玩偶,還有可能只是鞋子上的Hello Kitty……離開了對上下文的語義理解,即便有插件輔助,抽卡依然是很痛苦的事。
舉個具體的例子,這樣一段提示詞:
三人走在城市街道上,華人,左邊的男人穿著淺紅色夾克和藍色牛仔褲,拿著相機,中間的女人穿著酒紅色毛衣,灰色裙子,戴著眼鏡,右邊的女人穿著海軍藍連衣裙,拿著手提包,天空晴朗,城市景觀,逼真風格
Three people walk in the city street,asian chinese,the man on the left is wearing a light red jacket and blue jeans,holding a camera,the woman in the middle is wearing a wine red sweater,gray skirt,wearing glasses,the woman on the right is wearing a navy blue dress,holding a handbag,the sky is clear,the city landscape,realistic style
這段提示詞里包括了多人場景,每個人物的服裝特征,甚至還定義了相對位置。經常出圖的朋友可以打開SD跑一張文生圖試試,這種場景對于SDXL也是一場災難。
而在SD3M這里,如下圖所示:

沒有抽卡,一步到位。不僅服裝穿搭嚴格遵照了提示詞的指引,連人物的左中右站位都是正確的。更進一步,如果你熟悉前幾個版本SD模型對顏色的復現,不難看出SD3M對色彩的控制力有大幅強化(比如酒紅)。
舉個更直觀的例子,下圖將上衣顏色改成淡藍、天藍和海軍藍,三者的差異肉眼可見。

這還只是4GB的官方底模,基礎能力恐怖如斯。
Q:在SD3M之外,難道還有其他版本?
A:已知至少存在Ultra版本,目前可以通過官方API調用,文生圖單價約0.5元/張。
Q:再來幾張圖看看檔次
A:以下提示詞相同,相比上面的例子減少了右邊的人。
漫畫風格

3D風格

像素風+英文

黏土風+英文

Q:SD3M缺點在哪里?
A:主要有三點
**非完全體。**如果官方發布的Ultra版效果圖保真的話,那效果至少是比肩Midjourney V5.2以上的存在。畢竟Stability也是要吃飯的,只能說理解。
**依然會肉眼可見的出錯。**手的問題,四肢協調的問題,臉的問題,亟待開源社區補充方案。

**生態環境問題。**從SD1.5到SDXL,沒人會用官方發布的底模,生態的豐富依賴模型創作者、插件作者,以及工作流設計師的共同努力。從現在算起,一個月之內應該能看到一些成果面世。
Q:硬件配置和軟件環境?
A:SD3M需求8G顯存,基于Comfy UI和Swarm UI可以運行,相信WebUI也不會遲到太久。
Q:最值得期待的是什么?
A:當然是微調模型!
底模代表了基座,微調模型就是建立在基座上的特定形式。底模能力越強大,就意味著能提供的精度越高,越能支撐微調模型的特征表達,最終展現出來的結果,很可能就是更好的復現物理世界的真實場景,或者更具有泛化能力的風格基調。
4GB的底模,體量僅僅相當于經典的Chilloumix,微調模型應該不至于像SDXL生態下的1.3GB這般臃腫吧。
更進一步來說,視頻本身就是多個靜態幀基于時間順序的連接,從這個角度來看,圖像模型能力的提升,最終能力會外延到視頻領域,提高整體畫面表現力的同時,部分打破或者削弱閉源視頻的壁壘。
**簡單總結,SD3M并不完美,但進步很大,值得上手。**至于NSFW什么的,那不重要,真的不重要。
關于AI繪畫技術儲備
學好 AI繪畫 不論是就業還是做副業賺錢都不錯,但要學會 AI繪畫 還是要有一個學習規劃。最后大家分享一份全套的 AI繪畫 學習資料,給那些想學習 AI繪畫 的小伙伴們一點幫助!

對于0基礎小白入門:
如果你是零基礎小白,想快速入門AI繪畫是可以考慮的。
一方面是學習時間相對較短,學習內容更全面更集中。
二方面是可以找到適合自己的學習方案
包括:stable diffusion安裝包、stable diffusion0基礎入門全套PDF,視頻學習教程。帶你從零基礎系統性的學好AI繪畫!
零基礎AI繪畫學習資源介紹
👉stable diffusion新手0基礎入門PDF👈
(全套教程文末領取哈)

👉AI繪畫必備工具👈

溫馨提示:篇幅有限,已打包文件夾,獲取方式在:文末
👉AI繪畫基礎+速成+進階使用教程👈
觀看零基礎學習視頻,看視頻學習是最快捷也是最有效果的方式,跟著視頻中老師的思路,從基礎到深入,還是很容易入門的。

溫馨提示:篇幅有限,已打包文件夾,獲取方式在:文末
👉12000+AI關鍵詞大合集👈

這份完整版的AI繪畫全套學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】

![[leetcode]minimum-absolute-difference-in-bst 二叉搜索樹的最小絕對差](http://pic.xiahunao.cn/[leetcode]minimum-absolute-difference-in-bst 二叉搜索樹的最小絕對差)









)








