最近有時間繼續研究一下各種有趣的開源項目,一個叫ChatTTS的項目吸引了我的注意,這個項目可以把文本轉換成語音,配合gpt生成文本,可以直接用于生產有聲書作品了,這可以說是直接的生產力項目了。
項目對顯存的要求不高,只需要4G顯存即可使用,可以說非常的經濟適用了。
項目支持中文和英文
項目地址:https://github.com/2noise/ChatTTS
社區維護的Awesome項目:https://github.com/libukai/Awesome-ChatTTS
簡單上手的webui項目:https://github.com/jianchang512/ChatTTS-ui
我們就以webui項目來進行測試
1.環境搭建
為了方便使用,我使用Windows環境進行搭建項目,首先根據項目要求,需要創建pytorch2.2.0 cuda118,python大于3.9,小于3.11的環境,還是使用Anaconda創建虛擬環境
conda create -n chattts python=3.10
conda activate chattts
激活環境后,最重要的是先安裝pytorch和pytorchaudio模塊,建議下載whl文件進行安裝,下載地址:https://download.pytorch.org/whl/cu118
選擇需要下載的pytorch文件:torch-2.2.0+cu118-cp310-cp310-win_amd64.whl和torchaudio-2.2.0+cu118-cp310-cp310-win_amd64.whl
安裝之前最好先手動卸載一下當前環境預裝的torch和torchaudio,如果沒有,可以先忽略
# pip uninstall torch
# pip uninstall torchaudio
# 在conda的終端中切換到下載文件所在目錄
pip install torch-2.2.0+cu118-cp310-cp310-win_amd64.whl
pip install torchaudio-2.2.0+cu118-cp310-cp310-win_amd64.whl
2.下載項目安裝依賴
切換到你的工作目錄
git clone https://github.com/jianchang512/ChatTTS-ui.git
conda終端切換到項目中,然后安裝項目依賴
pip install -r requirements.txt
3.運行項目
之前在運行項目之前我們通常會去下載模型文件,由于該項目默認從魔搭社區獲取模型文件,所以不需要去下載模型文件了。
python app.py
等待項目啟動,啟動后瀏覽器自動打開UI界面
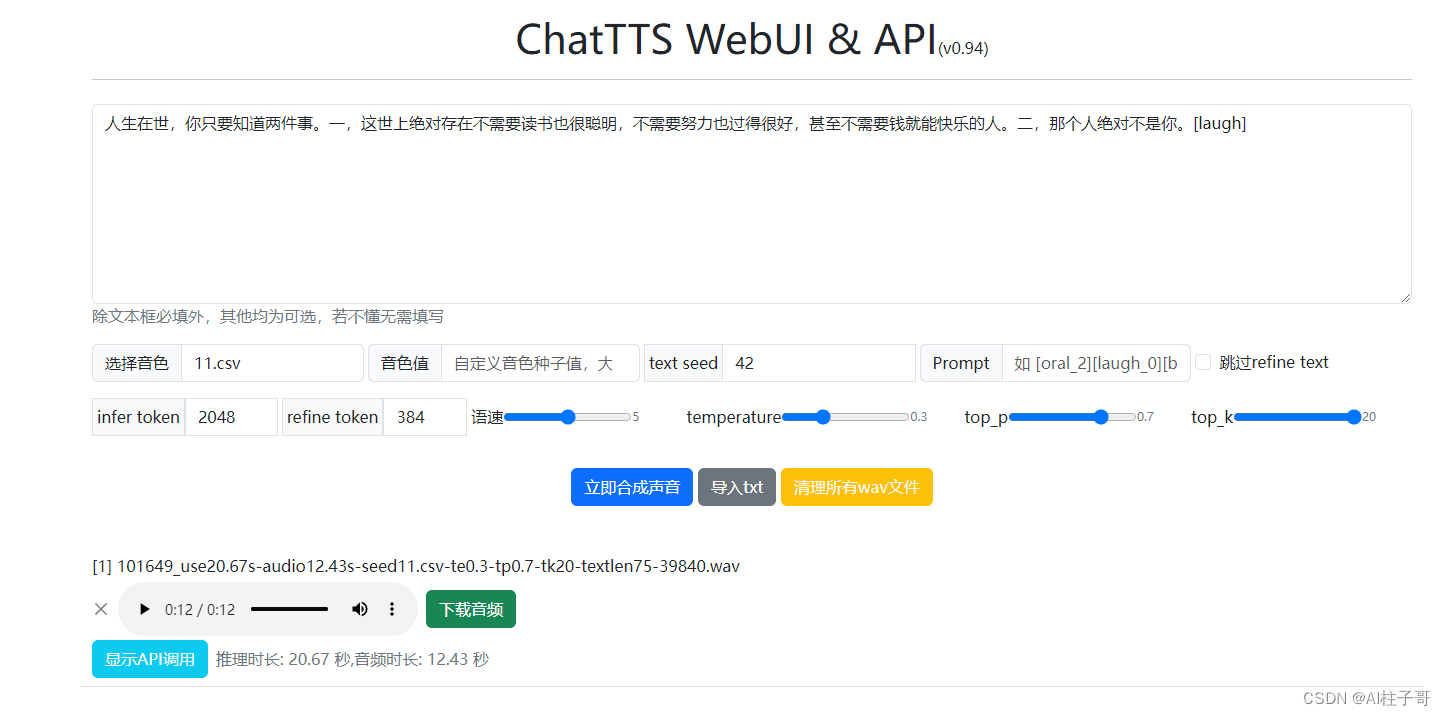
這里我在網上找了個段子,在使用默認設置的情況下直接生成語音,效果還算可以。






)

)










