目錄
1.數據預處理
2.數據增強
2.1 數據增強的作用
?2.2 數據增強方式與適用場景
2.2.1離線增強(Offline Augmentation)
2.2.2 在線增強(Online Augmentation)?
3. 數據增強的具體方法
4. YOLOv8的數據增強
4.1 YOLOv8默認使用的增強方式策略?
4.2 YOLOv8未使用的增強方式策略
?4.3?YOLOv8數據增強的源碼位置
?
1.數據預處理
當數據順利導入數據后,我們就可以依據圖像的具體情況對圖像進行預處理了。與機器學習中較為固定的預處理流程不同,圖像的預處理基本完全與數據本身有關。從數據采集的瞬間開始,我們就需要考慮預處理的事項。如果我們的數據是自行從網絡爬取或搜索引擎采集,我們可能需要對圖像進行去重、刪除無效樣本等操作,如果數據是自行拍攝、實驗提取,那可能也需要根據實驗要求進行一些刪除、增加的處理。當我們將所有有效數據導入后,至少需要確保:
1)全部樣本的尺寸是一致的(同時,全部樣本的通道數是一致的)
2)圖像最終以Tensor形式被輸入卷積網絡
3)圖像被恰當地歸一化
其中,前兩項是為了卷積神經網絡能夠順利地運行起來,第三項是為了讓訓練過程變得更加流暢快速。在PyTorch中,所有的數據預處理都可以在導入數據的時候,通過transform參數來完成,我們通常在transform參數中填寫torchvision.transforms這個模塊下的類。在預處理時,我們需要使用的常規類如下所示:
Compose ? ? transforms專用的,類似于nn.Sequential的打包功能,可以將數個transforms下的類 ? ? ? ? ? ? ? ? ? ? ? ?打包,形成類似于管道的結構來統一執行。
CenterCrop ?中心裁剪。需要輸入最終希望得到的圖像尺寸。
Resize ? ? ? ? ? 尺寸調整。需要輸入最終希望得到的圖像尺寸。注意區別于使用裁剪縮小尺寸或使 ? ? ? ? ? ? ? ? ? ? ? ? ? 用填充放大尺寸。
Normalize ? ? 歸一化(Tensor Only)。對每張圖像的每個通道進行歸一化,每個通道上的每個像素?
? ? ? ? ? ? ? ? ? ? ? 會減去該通道像素值的均值,并除以該通道像素值的方差。
ToTensor ? ? ? (PIL Only)將任意圖像轉變為Tensor
? ? ? ?無論使用怎樣的卷積網絡,我們都傾向于將圖像調整到接近28x28或224x224的尺寸。當原圖尺寸與目 標尺寸較為接近時,我們可以使用“裁剪”功能。裁剪是會按照我們輸入的目標尺寸,將大于目標尺寸的 像素點丟棄的功能,因此使用裁剪必然會導致信息損失,過多的信息損失會導致卷積網絡的結果變差。 當需要檢測或識別的對象位于圖像的中心時,可以使用中心裁剪。中心裁剪會以圖像中心點為參照,按照輸入的尺寸從外向內進行裁剪,被裁剪掉的像素會被直接丟棄。如果輸入的尺寸大于原始圖像尺寸, 則在原始圖像外側填充0,再進行中心裁剪。
? ? ? ?當圖像的尺寸與目標尺寸相差較大,我們不能接受如此多的信息被丟棄的時候,就需要使用尺寸調整的類Resize。Resize是使用像素聚類、像素插補等一定程度上對信息進行提取或選擇、并按要求的尺寸重排像素點的功能。一般來說,Resize過后的圖片會呈現出與原圖較為相似的信息,但圖片尺寸會得到縮放。如果原始圖像尺寸很大,目標尺寸很小,我們一般會優先使用Resize將圖像尺寸縮小到接近目標尺寸的程度,再用裁剪讓圖片尺寸完全等于目標尺寸。例如,對于600*800的圖像,先Resize將尺寸降到 256x256,再裁剪至224x224。
2.數據增強
2.1 數據增強的作用
在目標檢測模型的訓練過程中,進行數據增強是非常關鍵的一個步驟,其主要作用體現在以下幾個方面:
增加訓練數據的多樣性:
數據增強通過應用一系列隨機變換(如翻轉、裁剪、旋轉、縮放、顏色調整、平移等)到原始訓練圖像上,生成大量具有不同視點、尺寸、光照條件和背景的新樣本。這些變換模擬了現實世界中物體可能出現的各種形態和環境變化,使得模型在訓練階段就能接觸到更多樣化的場景,從而提高了模型對不同情況的適應性。
提高模型的泛化能力:
增加訓練數據的多樣性有助于防止模型過度擬合訓練集,即避免模型對訓練數據中的特定細節或噪聲過于敏感,而忽視了更普遍、更本質的特征。通過數據增強,模型被迫學習更為通用的特征表示,使其在面對未見過的測試數據時,仍能準確地檢測出目標物體,進而提高整體的泛化性能。
增強模型的魯棒性:
數據增強引入的噪聲和變化有助于模型在訓練中應對各種潛在干擾因素。例如,添加輕微的模糊、亮度變化或色彩失真,可以使模型在實際應用中對圖像質量的變化、光照條件的波動以及相機成像偏差等具有更強的抵抗能力。這樣,即使在復雜或非理想的環境下,模型也能穩定地進行目標檢測。
緩解樣本不均衡問題:
在許多目標檢測任務中,不同類別或不同大小的目標樣本可能存在數量上的顯著差異,導致訓練過程中的類別不平衡問題。數據增強可以通過復制、合成或優先增強少數類樣本的方法,幫助平衡各類別的數據分布,確保模型對所有目標類別都能給予適當的重視,提高整體檢測性能,特別是對稀有類別或小目標的檢測準確性。
優化模型對尺度變化的適應性:
特別是在目標檢測任務中,物體的實際大小和距離攝像頭的距離會導致目標在圖像中呈現出不同的尺度。數據增強通過應用多尺度訓練策略(如隨機縮放、多尺度輸入、多分辨率訓練等),使模型能夠更好地理解和處理不同尺度下的目標,提升對不同大小目標的檢測效果。
減少對大量標注數據的依賴:
在實際應用中,獲取大規模、高質量標注的目標檢測數據集成本高昂且耗時。數據增強通過有效利用現有數據生成新的訓練樣本,能夠在一定程度上彌補數據量不足的問題,使得有限的數據資源得以充分利用,降低對大規模標注數據集的硬性需求。
?2.2 數據增強方式與適用場景
常見的數據增強方式主要有兩種:在線增強(Online Augmentation)和離線增強(Offline Augmentation)。
以下是這兩種方式的定義、增強方式以及適用場景的詳細解釋:?
2.2.1離線增強(Offline Augmentation)
定義:
離線增強是指在模型訓練前在計算機上一次性完成所有數據增強操作,將原始數據集轉化為包含多種增強版本的擴充數據集,并將增強后的樣本保存到磁盤或內存中,然后使用這個固定的擴充數據集進行訓練。
適用場景:
離線增強適用于以下場景:
計算資源受限:離線增強只需在訓練前進行一次計算,后續訓練可以直接使用已增強好的數據,減少了實時計算需求,適合計算資源有限的環境。
模型對數據分布穩定有要求:對于需要保持訓練數據分布穩定的模型或算法(如某些基于統計特征的模型),離線增強提供了固定且一致的數據分布。
訓練時間緊張:當訓練時間有限,需要快速啟動訓練過程時,離線增強避免了每次迭代時的實時增強計算,可以顯著加快訓練初期的速度。
數據集較小:對于小型數據集,離線增強可以生成大量多樣化的樣本,有效擴充數據集規模,有助于提高模型泛化能力。
2.2.2 在線增強(Online Augmentation)?
定義:
在線增強是指在模型訓練過程中模型會實時進行數據增強操作。每次迭代時,從原始數據集中抽取一個樣本后,立即對其進行一系列隨機的變換處理,生成新的增強樣本,然后使用該增強樣本進行當前批次的訓練。
適用場景:
在線增強適用于以下場景:
計算資源充足:在線增強需要在訓練過程中實時生成增強樣本,可能會增加計算負擔,因此更適合在計算資源充足的環境中使用。
模型對數據變化敏感:對于需要精細調整超參數或對數據分布變化敏感的模型,實時數據增強可以即時反饋增強效果,便于調整和優化。
實時性要求不高:在線增強適用于訓練時間相對充裕、對預處理速度要求不高的場景。
總結來說,選擇在線增強還是離線增強主要取決于計算資源狀況、模型特性、訓練時間要求以及數據集規模等因素。在線增強具有更高的靈活性和即時反饋優勢,而離線增強則更適合資源有限、要求數據分布穩定的場景,并能節省訓練初期的時間。實際應用中,有時也會結合兩者的特點,采用混合策略進行數據增強。
3. 數據增強的具體方法
數據增強的具體方法包括但不限于:
幾何變換:如水平/垂直翻轉、隨機裁剪、旋轉、縮放、平移、透視變換等,改變目標物體的位置、方向和大小。
顏色空間變換:如亮度調整、對比度變化、飽和度調整、色調偏移、添加高斯噪聲、椒鹽噪聲等,模擬光照條件、相機白平衡和圖像質量的變化。
混合變換:如圖像混合(如CutMix、MixUp)、樣本拼接(如GridMask、RandomErasing)等,將多個樣本的部分內容組合在一起,或隨機擦除部分區域。
特定領域的增強:針對特定任務或數據類型設計的增強技術,如深度估計中的視點變換、醫學影像中的紋理合成等。
?
4. YOLOv8的數據增強
4.1 YOLOv8默認使用的增強方式策略?
1.1、 hsv_h
通過色輪的一小部分調整圖像的色調,引入顏色可變性。幫助模型在不同的照明條件下進行概括。
默認數值為0.015,范圍是0.0~1.0。
1.2、hsv_s
將圖像的飽和度更改一小部分,從而影響顏色的強度。適用于模擬不同的環境條件。
默認數值為0.7,范圍是0.0~1.0。
1.3、hsv_v
將圖像的值(亮度)修改一小部分,有助于模型在各種照明條件下表現良好。
默認數值為0.4,范圍是0.0~1.0。
1.4、translate
將圖像水平和垂直方向平移圖像的一小部分,有助于學習檢測部分可見對象。
默認數值為0.1,范圍是0.0~1.0。
1.5、translate
按增益因子縮放圖像,模擬與攝影機相距不同距離的對象。
默認數值為0.5,范圍是大于等于0.0都可以。
1.6、fliplr
以指定的概率將圖像從左向右翻轉(類似于左右鏡像),這對于學習對稱對象和增加數據集的多樣性非常有用。
默認數值為0.5,范圍是0.0~1.0。
1.7、mosaic
將四個訓練圖像組合為一個,模擬不同的場景組成和對象交互。YOLO最經典的數據增強方式。對復雜場景的理解非常有效。
默認數值為1.0,范圍是0.0~1.0。
1.8、auto_augment
面向分類任務,自動應用預定義的增強策略(randaugment、autoaugment和augmix),通過使視覺特征多樣化來優化分類任務。
默認數值為randaugment,范圍是(randaugment、autoaugment和augmix)。
1.9、erasing
在分類訓練過程中隨機擦除圖像的一部分,鼓勵模型專注于不太明顯的特征進行識別。
默認數值為0.4,范圍是0.0~0.9。
1.10、crop_fraction
將分類圖像裁剪到其大小的一小部分,以強調中心特征并適應對象比例,從而減少背景干擾。?
默認數值為1.0,范圍是0.1~1.0。
4.2 YOLOv8未使用的增強方式策略
2.1、degrees
在指定的度數范圍內隨機旋轉圖像,提高模型識別不同方向對象的能力。選擇旋轉角度后,在選擇的旋轉角度范圍內進行數據隨機旋轉。?
范圍是-180~+180。
2.2、shear
以指定的角度剪切圖像,模仿從不同角度觀看對象的效果。選擇角度后,在選擇的角度范圍內進行數據隨機剪切。?
范圍是-180~+180。
2.3、perspective
將隨機透視變換應用于圖像,增強模型理解三維空間中對象的能力。
范圍是0.0~0.001。
2.4、flipud
以指定的概率將圖像倒置,在不影響對象特性的情況下增加數據的可變性。
范圍是0.0~1.0。
2.5、bgr
以指定的概率將圖像通道從RGB翻轉到BGR,這有助于提高對不正確通道排序的魯棒性。
范圍是0.0~1.0。
2.6、mixup
混合兩個圖像及其標簽,創建合成圖像。通過引入標簽噪聲和視覺可變性來增強模型的泛化能力。
范圍是0.0~1.0。
2.7、copy_paste
將對象從一個圖像中復制并粘貼到另一個圖像上,這對于增加對象實例和學習對象遮擋非常有用。
范圍是0.0~1.0。
在進行訓練時,直接加相對應的參數即可!例如添加使用flipud 增強策略:
?
model = YOLO(r"yolov8m-pose.pt") # 用于遷移訓練的權重文件路徑results = model.train(data=r"E:\ultralytics-main\datasets\key-points.yaml",imgsz=640, epochs=100, batch=4, flipud = 0.5, device = 0)?
?4.3?YOLOv8數據增強的源碼位置
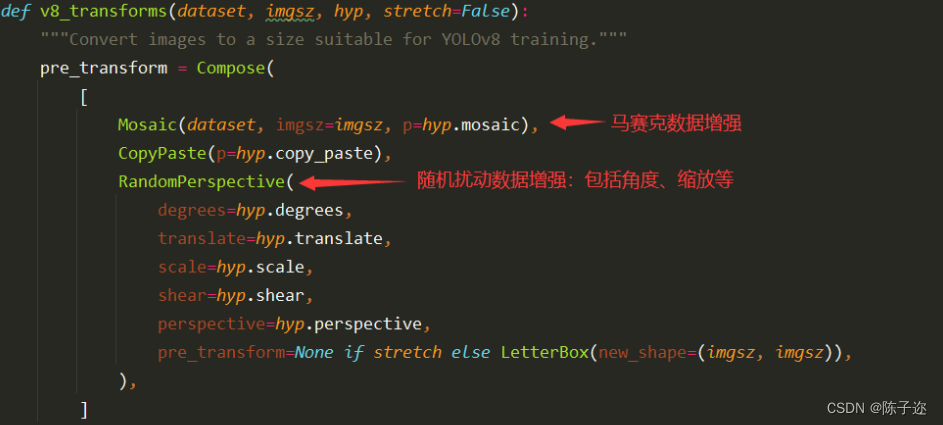
YOLOv8進行數據增強的源碼位置在ultralytics/data/augment.py中的v8_transforms函數中:?
?
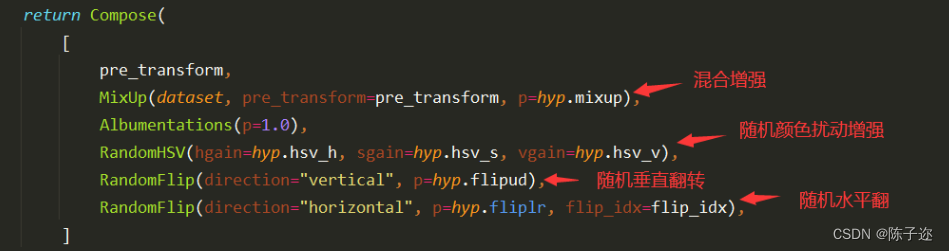 ?
?
因此,在YOLOv8模型訓練時:自己數據集數量不是特別少的情況下。一般為了節省訓練時間,我們無需額外對數據集進行離線數據增強。YOLOv8模型會自動幫我們在訓練時進行數據的在線數據增強主要包括:馬賽克增強(Mosaic)、混合增強(Mixup)、隨機擾動(random perspective )以及顏色擾動(HSV augment)等。以確保模型數據集的多樣性與泛化能力。
?
?以上數據增強策略均可用于目標檢測,分割,骨干提取和分類等。有可能加了之后會導致結果指標下降,需要實際實驗進行選取。












)

享元模式(Flyweight Pattern))



微調方法(總結)】)
