1.機器學習定義

2.機器學習工作流程
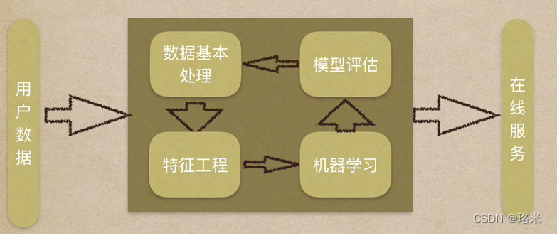
? ? ? ? (1)數據集
? ? ? ? ? ? ? ? ①一行數據:一個樣本
? ? ? ? ? ? ? ? ②一列數據:一個特征
? ? ? ? ? ? ? ? ③目標值(標簽值):有些數據集有目標值,有些數據集沒有。因此數據類型由特征值+目標值構成或僅由特征值構成。
? ? ? ? (2)數據分割:機器學習的數據集一般劃分為訓練數據(用于構建模型)和測試數據(用于模型評估)兩個部分,劃分比例一般為7:3、4:1、3:1。
? ? ? ? (3)數據基本處理:對數據的缺失值、異常值進行處理
? ? ? ? (4)特征工程(Feature Engineering):處理數據使特征在機器學習上更好發揮作用的過程
? ? ? ? ? ? ? ? 注:業界流傳,數據和特征決定機器學習的上限,而模型和算法只是逼近這個上限
? ? ? ? ? ? ? ? ①特征提取:將任意數據(如文本或圖像)轉為可用于機器學習的數字特征
? ? ? ? ? ? ? ? ②特征預處理:通過一些轉換函數將特征數據轉成更適合算法模型的特征數據
? ? ? ? ? ? ? ? ③特征降維:在某些限定條件下,降低隨機變量(特征)個數得到一組不相關的主變量
? ? ? ? (5)機器學習:選擇合適的算法對模型進行訓練
? ? ? ? (6)模型評估:對訓練好的模型進行評估
3.機器學習算法分類(根據數據集組成不同進行劃分)
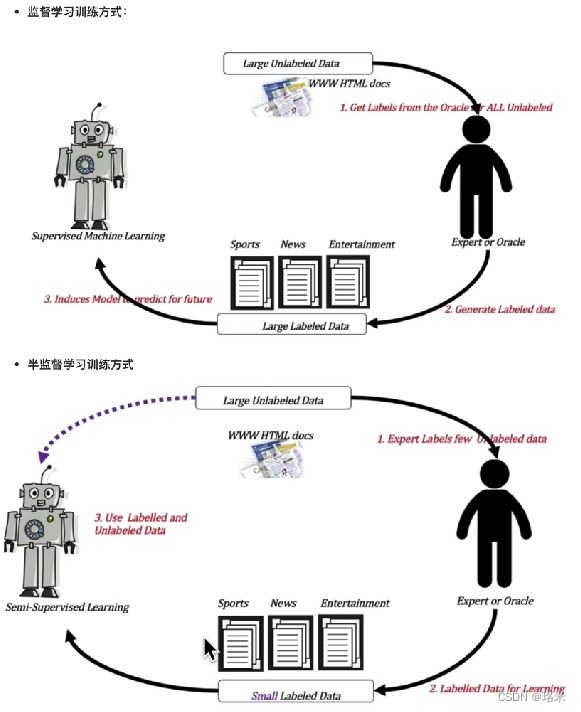
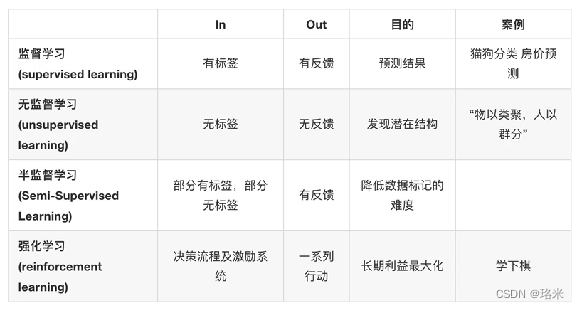
? ? ? ? (1)監督學習:輸入數據由特征值和目標值組成,函數的輸出(目標值)可以是一個連續的值(回歸)或是有限個離散值(分類)
? ? ? ? ? ? ? ? ①回歸問題:預測房價,根據樣本集擬合出一條連續曲線
? ? ? ? ? ? ? ? ②分類問題:根據腫瘤特征預測是良性還是惡性
? ? ? ? (2)無監督學習:輸入數據由特征值組成,輸入的數據沒有被標記也沒有確定結果,樣本數據類別未知,需根據樣本間的相似性對樣本集進行類別劃分
? ? ? ? (3)半監督學習:訓練集同時包含有標記(有目標值)數據和未標記(沒有目標值)數據
? ? ? ? (4)強化學習:實質是做決策問題,即自動進行決策,并且可以做連續決策,強化學習的目標就是獲得最多的累計獎勵

4.模型評估
? ? ? ? (1)分類模型評估:準確率(預測正確的數占樣本總數的比例)、精確率、召回率、F1-score、AUC指標
? ? ? ? (2)回歸模型評估:均方根誤差RMSE(p_i為預測值,a_i為實際值)、相對平方誤差RSE、平均絕對誤差MAE、相對絕對誤差RAE

? ? ? ? (3)模型表現效果:過擬合(所建的機器學習模型在訓練樣本中表現得過于優越,導致在測試數據集中表現不佳)、欠擬合(模型學習太粗糙,連訓練集中樣本數據的特征關系都沒有學出來)
5.深度學習:也稱深度結構學習、層次學習、深度機器學習,是一類算法集合,是機器學習的一個分支,在會話識別、圖像識別和對象偵測等領域表現出驚人的準確性。


Cookie與Session)

:使用 Embedded Coder 快速向導生成代碼)








——JDBC跟Mybatis、lombok)

)

:1.光學原理、變量選取與預處理)

