Redis篇
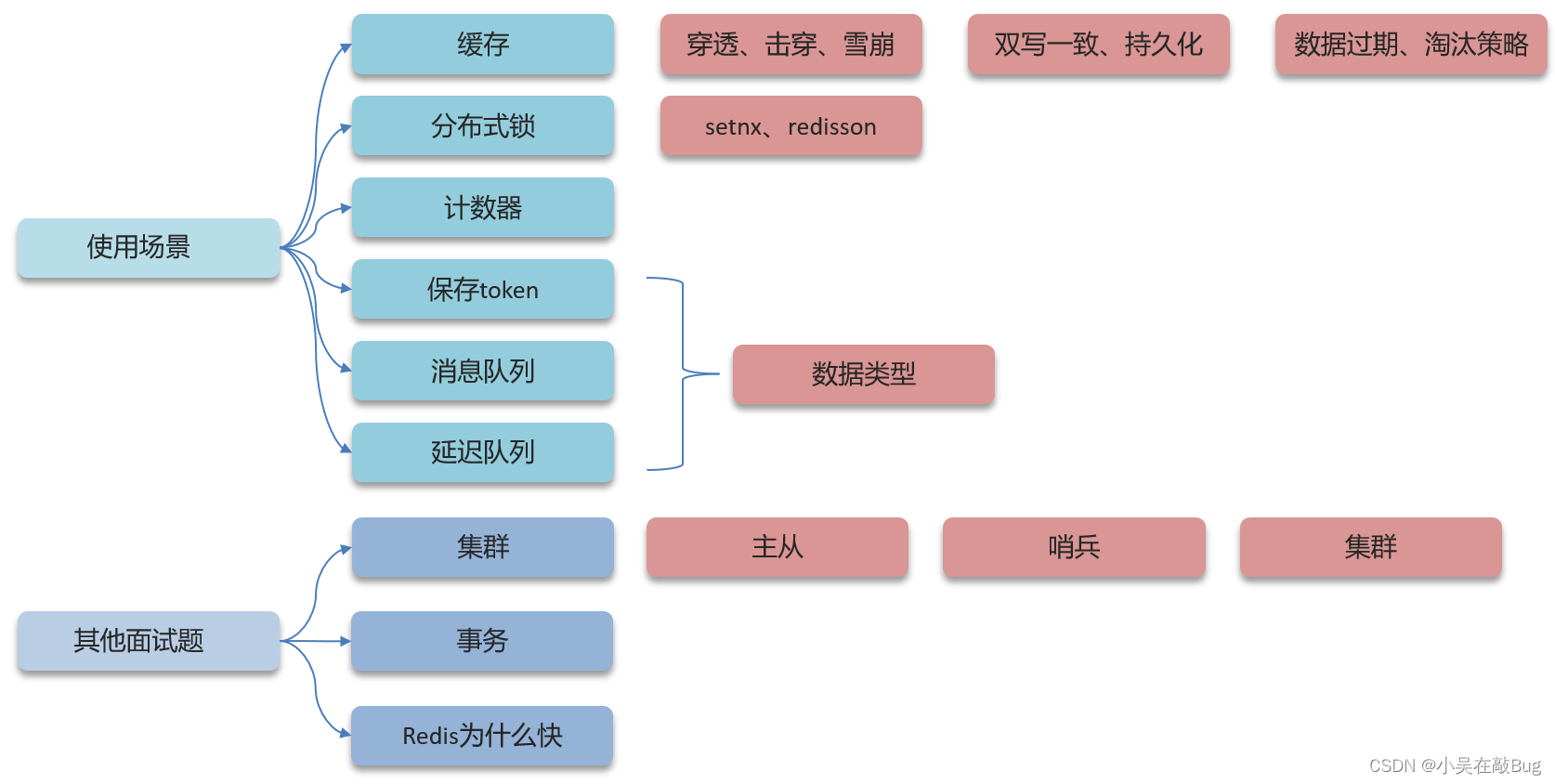
什么是緩存穿透 ? 怎么解決 ?
緩存穿透是指查詢一個不存在的數據,如果從存儲層查不到數據則不寫入緩存,這將導致這個不存在的數據每次請求都要到 DB 去查詢,可能導致 DB 掛掉。這種情況大概率是遭到了攻擊。
解決方案有兩種:
- 緩存空數據
- 布隆過濾器:我們通常都會用布隆過濾器來解決它。
你能介紹一下布隆過濾器嗎?
布隆過濾器主要是用于檢索一個元素是否在一個集合中。
它的底層主要是先去初始化一個比較大數組,里面存放的二進制0或1。在一開始都是0,當一個key來了之后經過3次hash計算,模于數組長度找到數據的下標然后把數組中原來的0改為1,這樣的話,三個數組的位置就能標明一個key的存在。查找的過程也是一樣的。
當然,布隆過濾器是有缺點的,其中之一就是可能會產生一定的誤判率。我們一般可以設置這個誤判率,通常不會超過5%。實際上,這個誤判率是難以避免的,除非我們增加布隆過濾器使用的位數組的長度。但即便如此,5%以內的誤判率對于一般的項目來說已經是可以接受的,不至于在高并發下導致數據庫被壓垮。
什么是緩存擊穿 ? 怎么解決 ?
緩存擊穿的意思是對于設置了過期時間的key,緩存在某個時間點過期的時候,恰好這時間點對這個Key有大量的并發請求過來,這些請求發現緩存過期一般都會從后端 DB 加載數據并回設到緩存,這個時候大并發的請求可能會瞬間把 DB 壓垮。
解決方案有兩種方式:
解決方案一: 互斥鎖,強一致,性能差
解決方案二: 邏輯過期,高可用,性能優,不能保證數據絕對一致
- 第一可以使用互斥鎖:當緩存失效時,不立即去load db,先使用如 Redis 的 setnx 去設置一個互斥鎖,當操作成功返回時再進行 load db的操作并回設緩存,否則重試get緩存的方法
- 第二種方案可以設置當前key邏輯過期,大概思路如下:
- 在設置key的時候,設置一個過期時間字段一塊存入緩存中,不給當前key設置過期時間
- 當查詢的時候,從redis取出數據后判斷時間是否過期
- 如果過期則開通另外一個線程進行數據同步,當前線程正常返回數據,這個數據不是最新的
當然兩種方案各有利弊:
- 如果選擇數據的強一致性,建議使用分布式鎖的方案,性能上可能沒那么高,鎖需要等,也有可能產生死鎖的問題
- 如果選擇key的邏輯刪除,則優先考慮的高可用性,性能比較高,但是數據同步這塊做不到強一致。
什么是緩存雪崩 ? 怎么解決 ?
緩存雪崩意思是設置緩存時采用了相同的過期時間,導致緩存在某一時刻同時失效,請求全部轉發到DB,DB 瞬時壓力過重雪崩。與緩存擊穿的區別:雪崩是很多key,擊穿是某一個key緩存。
解決方案:
- 給不同的Key的TTL添加隨機值
- 利用Redis集群提高服務的可用性:
哨兵模式、集群模式 - 給緩存業務添加降級限流策略:
Nginx、Spring Cloud Gateway - 給業務添加多級緩存:
Guava或Caffeine
解決方案主要是可以將緩存失效時間分散開,比如可以在原有的失效時間基礎上增加一個隨機值,比如1-5分鐘隨機,這樣每一個緩存的過期時間的重復率就會降低,就很難引發集體失效的事件。
緩存三兄弟總結
緩存無中生有Key,布隆過濾null隔離。
緩存擊穿過期Key,鎖與非期解難題。
雪崩大量過期Key,過期時間要隨機。
面試必考三兄弟,可用限流來保底。
redis做為緩存,mysql的數據如何與redis進行同步呢?(雙寫一致性)
雙寫一致性: 當修改了數據庫的數據也要同時更新緩存的數據,緩存和數據庫的數據要保持一致。
允許延時一致的業務(采用異步通知)
- 使用
MQ中間件,更新數據之后,通知緩存刪除 - 利用
Canal中間件,不需要修改業務代碼,偽裝為MySQL的一個從節點,Canal通過讀取binlong數據更新緩存
就說我最近做的這個項目,里面有xxxx(根據自己的簡歷上寫)的功能,數據同步可以有一定的延時(符合大部分業務)
我們當時采用的阿里的canal組件實現數據同步:不需要更改業務代碼,部署一個canal服務。canal服務把自己偽裝成mysql的一個從節點,當mysql數據更新以后,canal會讀取binlog數據,然后在通過canal的客戶端獲取到數據,更新緩存即可。
強一致性(采用Redisson提供的讀寫鎖)
- 共享鎖:讀鎖
readLock,加鎖之后其它線程可以共享讀操作 - 排他鎖:也叫獨占鎖
writeLock,加鎖之后,阻塞其它線程讀寫操作
就說我最近做的這個項目,里面有xxxx(根據自己的簡歷上寫)的功能,需要讓數據庫與redis高度保持一致,因為要求時效性比較高,我們當時采用的讀寫鎖保證的強一致性。
我們采用的是redisson實現的讀寫鎖,在讀的時候添加共享鎖,可以保證讀讀不互斥,讀寫互斥。當我們更新數據的時候,添加排他鎖,它是讀寫,讀讀都互斥,這樣就能保證在寫數據的同時是不會讓其他線程讀數據的,避免了臟數據。這里面需要注意的是讀方法和寫方法上需要使用同一把鎖才行。
你聽說過延時雙刪嗎?為什么不用它呢?
- 讀操作:緩存命中,直接返回;緩存未命中查詢數據庫,寫入緩存
- 寫操作:
延遲雙刪(刪除緩存—》修改數據庫—》延時刪除緩存)
延遲雙刪,如果是寫操作,我們先把緩存中的數據刪除,然后更新數據庫,最后再延時刪除緩存中的數據,其中這個延時多久不太好確定,在延時的過程中可能會出現臟數據,并不能保證強一致性,所以沒有采用它。
Redis持久化
RDB
RDB全稱 Redis DataBase Backup File(Redis數據備份文件),也被叫做Redis數據快照。簡單來說就是把內存中的所有數據都記錄到磁盤中。當Redis實例故障重啟后,從磁盤讀取快照文件,恢復數據
-
主動備份
save #由Redis主進程來執行RDB,會阻塞所有命令bgsave #開啟子進程執行RDB,避免主進程收到影響 -
Redis內部有觸發RDB的機制,可以在redis.conf文件中找到,格式如下:
# 900秒內,如果至少有一個key被修改,則執行bgsave save 900 1 # 300秒內,有10個key被修改,也會執行bgsave save 300 10 # 60秒內,有一萬個key被修改,也會執行bgsave save 60 10000
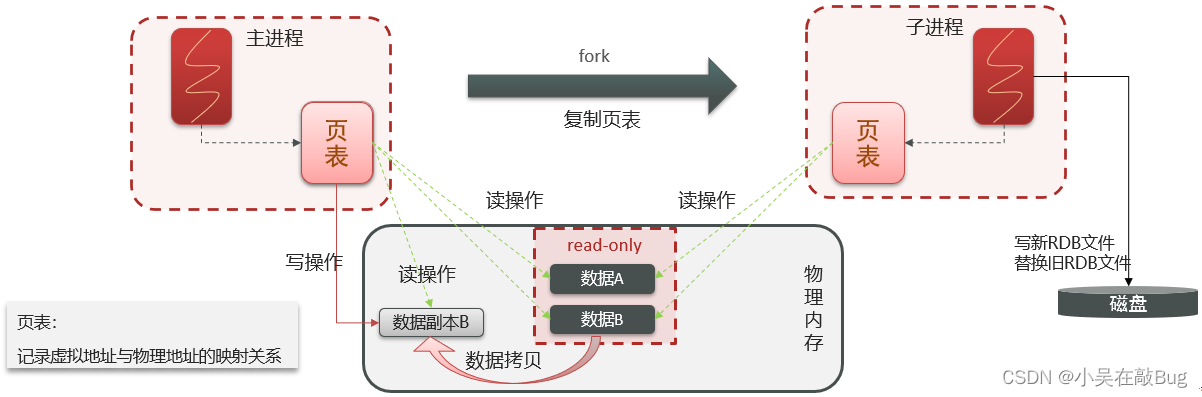
RDB的執行原理: bgsave開始時會fork主進程得到子進程 共享 主進程的內存數據。完成fork后讀取內存數據并寫入RDB文件。
fork采用的是copy-on-write技術:
- 當主進程執行讀操作時,訪問共享內存
- 當主進程執行寫操作時,則會拷貝一份數據,執行寫操作
AOF
AOF全稱為Append Only File(追加文件)。Redis處理的每一個寫命令都會記錄在AOF文件,可以看做是命令日志文件。
-
AOF默認是關閉的,需要修改redis.conf配置文件來開啟AOF:
# 是否開啟AOF功能,默認是no appendonly yes # AOf文件的名稱 appendfilename "appendonly.aof" -
AOF的命令記錄的頻率也可以通過redis.conf文件來配:
# 表示每執行一次寫命令,立即記錄到AOF文件 appendfsync always # 寫命令執行完先放入AOF緩沖區,然后表示每隔1秒將緩沖區寫到AOF文件,是默認方案 appendfsync everysec # 寫命令執行完先放入AOF緩沖區,由操作系統決定何時將緩沖區內容寫會磁盤 appendfsync no配置項 刷盤時機 優點 缺點 always 同步刷盤 可靠性高,幾乎不丟數據 性能差 everysec 每秒刷盤 性能適中 最多丟失1秒數據 no 操作系統控制 性能最好 可靠性差,可能丟失大量數據
因為是記錄命令,AOF文件會比RDB文件大的多。而且AOF會記錄對同一個key的多次寫操作,但只有最后一次寫操作才有意義。通過執行 bgrewriteaof 命令,可以讓AOF文件執行重寫功能,用最少的命令達到相同效果。
Redis也會在觸發閾值時自動去重寫AOF文件。閾值也可以在redis.conf中配置:
# AOF文件比上次文件 增長超過多少百分比則觸發重寫
auto-aof-rewrite-percentage 100
# AOF文件體積最小多大以上
auto-aof-rewrite-min-size 64mb
RDB與AOF對比
RDB和AOF各有自己的優缺點,如果對數據安全性要求較高,在實際開發中往往會 結合 兩者來使用
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定時對整個內存做快照 | 記錄每一次執行的命令 |
| 數據完整性 | 不完整,兩次備份之前會丟失 | 相對完整,取決于刷盤策略 |
| 文件大小 | 會有壓縮,文件體積小 | 記錄命令,文件體積很大 |
| 宕機恢復速度 | 快 | 慢 |
| 數據恢復優先級 | 低,因為完整性不如AOF | 高,因為數據完整更高 |
| 系統資源占用 | 高,大量CPU和內存消耗 | 低,主要是磁盤IO資源但AOF重寫時會占用大量CPU和內存資源 |
| 使用場景 | 可以容忍數分鐘的數據丟失,追求更快的啟動速度 | 對數據安全性要求較高 |
redis做為緩存,數據的持久化是怎么做的?
在Redis中提供了兩種數據持久化的方式:1、RDB 2、AOF
這兩種持久化方式有什么區別呢?
RDB是一個快照文件,它是把redis內存存儲的數據寫到磁盤上,當redis實例宕機恢復數據的時候,方便從RDB的快照文件中恢復數據。
AOF的含義是追加文件,當redis操作寫命令的時候,都會存儲這個文件中,當redis實例宕機恢復數據的時候,會從這個文件中再次執行一遍命令來恢復數據
這兩種方式,哪種恢復的比較快呢?
RDB因為是二進制文件,在保存的時候體積也是比較小的,它恢復的比較快,但是它有可能會丟數據,我們通常在項目中也會使用AOF來恢復數據,雖然AOF恢復的速度慢一些,但是它丟數據的風險要小很多,在AOF文件中可以設置刷盤策略
數據過期策略
Redis對數據設置數據的有效時間,數據過期以后,就需要將數據從內存中刪除掉。可以按照不同的規則進行刪除,這種刪除規則就叫做數據過期策略。
惰性刪除: 設置該key過期時間后,我們不去管它,當需要該key時,我們再檢查其是否過期,我們就刪掉它,反之返回該key。
-
優點: 對CPU友好,只會在使用該key時才會進行過期檢查,對于很多用不到的key不用浪費時間進行過期檢查
-
缺點: 對內存不友好,如果一個key已經過期,但是一直沒有使用,那么該key就會一直存在內存中,內存永遠不會釋放
set name zhangsan 10get name # 發現name過期了,直接刪除key
定期刪除: 每隔一段時間,我們就對一些key進行檢查,刪除里面過期的key(從一定數量的數據庫中取出一定數量的隨機key進行檢查,并刪除其中過期的key)
- 優點: 可以通過限制刪除操作執行的時長和頻率來減少刪除操作對CPU的影響。另外定期刪除,也能有效釋放過期占用的內存。
- 缺點: 難以確定刪除操作執行的時長和頻率
定時刪除兩種模式:
- SLOW模式是定時任務,執行頻率默認為10hz,每次不超過25ms,可以通過修改配置文件 redis.conf 的
hz選項來調整這個次數 - FAST模式執行頻率不固定,但兩次間隔不低于2ms,每次耗時不超過1ms
Redis的過期刪除策略: 惰性刪除 + 定期刪除 兩種策略進行配合使用。
數據淘汰策略
數據淘汰策略: 當Redis中的內存不夠用時,此時在向Redis中添加新的key,那么Redis就會按照某一種規則將內存中的數據刪除掉,這種數據的刪除規則叫做內存淘汰策略。
Redis支持8種不同策略來選擇要刪除的key:
- noeviction: 不淘汰任何key,但是內存滿時不允許寫入新數據,
默認是該策略 - volatile-ttl:對設置了TTL的可以,比較key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:對全體key,隨機進行淘汰
- volatile-random:對設置了TTL的key,隨機進行淘汰
- allkeys-lru: 對全體key,基于LRU算法(最近最少使用)進行淘汰
- volatile-lru: 對設置了TTL的key,基于LRU算法進行淘汰
- allkeys-lfu: 對全體key,基于LFU算法(最少頻率使用)進行淘汰
- volatile-lfu: 對設置了TTL的key,基于LFU算法進行淘汰
使用建議
- 優先使用 allkeys-lru 策略。充分利用 LRU 算法的優勢,把最近常訪問的數據保留在緩存中。 如果業務有明顯的冷熱數據區分,建議使用。
- 如果業務中數據訪問頻率差別不大,沒有明顯的冷熱數據區分,建議使用 allkeys-random,隨機選擇淘汰
- 如果業務中有置頂的需求,可以使用 volatile-lru 策略,同時置頂數據不設置過期時間,這些數據就一直不被刪除,會淘汰其它設置過期時間的數據
- 如果業務中有短時高頻訪問的數據,可以使用 allkeys-lfu 或 volatile-lfu 策略
數據庫有1000萬數據 ,Redis只能緩存20w數據, 如何保證Redis中的數據都是熱點數據 ?
可以使用 allkeys-lru (挑選最近最少使用的數據淘汰)淘汰策略,那留下來的都是經常訪問的熱點數據
Redis的內存用完了會發生什么?
這個要看redis的數據淘汰策略是什么,如果是默認的配置,redis內存用完以后則直接報錯
分布式鎖
分布式鎖使用的場景:集群情況下的定時任務、搶單、冪等性場景
Redis實現分布式鎖主要利用Redis的 setnx 命令。setnx是 SET is not exists (如果不存在,則SET)的簡寫
-
獲取鎖:
# 添加鎖,NX是互斥,EX是設置超時時間 SET lock value NX EX 10 -
釋放鎖:
# 釋放鎖,刪除即可 DEL key
為什么要使用分布式鎖?
在分布式系統里,因為多個服務或應用實例可能同時運行在不同的服務器上,它們都有可能去操作同一個共享資源,比如數據庫中的某條記錄或某個緩存項。如果不對這些操作加以控制,就可能會遇到數據沖突、數據不一致或者重復處理的問題。這就像是一群人在沒有協調的情況下同時去修改同一份文件,結果可想而知,文件內容會變得亂七八糟。
為了解決這個問題,我們就需要用到分布式鎖。分布式鎖就像是一個看門人,它確保在同一時間內,只有一個服務或應用實例能夠進入并操作這個共享資源。這樣,我們就可以避免數據沖突和不一致,確保操作的正確性和一致性。
Redis分布式鎖如何實現?
在redis中提供了一個命令setnx(SET if not exists)
由于redis的單線程的,用了命令之后,只能有一個客戶端對某一個key設置值,在沒有過期或刪除key的時候是其他客戶端是不能設置這個key的
如何控制Redis實現分布式鎖有效時長呢?
redis的setnx指令不好控制這個問題,我們可以采用的redis的一個框架redisson實現
在redisson中需要手動加鎖,并且可以控制鎖的失效時間和等待時間,當鎖住的一個業務還沒有執行完成的時候,在redisson中引入了一個看門狗機制,就是說每隔一段時間就檢查當前業務是否還持有鎖,如果持有就增加加鎖的持有時間,當業務執行完成之后需要使用釋放鎖就可以了
還有一個好處就是,在高并發下,一個業務有可能會執行很快,先客戶1持有鎖的時候,客戶2來了以后并不會馬上拒絕,它會自旋不斷嘗試獲取鎖,如果客戶1釋放之后,客戶2就可以馬上持有鎖,性能也得到了提升。
redisson實現的分布式鎖是可重入的嗎?
是可以重入的。這樣做是為了避免死鎖的產生。這個重入其實在內部就是判斷是否是當前線程持有的鎖,如果是當前線程持有的鎖就會計數,如果釋放鎖就會在計數上減一。在存儲數據的時候采用的hash結構,大key可以按照自己的業務進行定制,其中小key是當前線程的唯一標識,value是當前線程重入的次數
redisson實現的分布式鎖能解決主從一致性的問題嗎?
這個是不能的,比如,當線程1加鎖成功后,master節點數據會異步復制到slave節點,此時當前持有Redis鎖的master節點宕機,slave節點被提升為新的master節點,假如現在來了一個線程2,再次加鎖,會在新的master節點上加鎖成功,這個時候就會出現兩個節點同時持有一把鎖的問題。
我們可以利用redisson提供的紅鎖來解決這個問題,它的主要作用是,不能只在一個redis實例上創建鎖,應該是在多個redis實例上創建鎖,并且要求在大多數redis節點上都成功創建鎖,紅鎖中要求是redis的節點數量要過半。這樣就能避免線程1加鎖成功后master節點宕機導致線程2成功加鎖到新的master節點上的問題了。
但是,如果使用了紅鎖,因為需要同時在多個節點上都添加鎖,性能就變的很低了,并且運維維護成本也非常高,所以,我們一般在項目中也不會直接使用紅鎖,并且官方也暫時廢棄了這個紅鎖
如果業務非要保證數據的強一致性,這個該怎么解決呢?
redis本身就是支持高可用的,做到強一致性,就非常影響性能,所以,如果有強一致性要求高的業務,建議使用zookeeper實現的分布式鎖,它是可以保證強一致性的
Redis集群有哪些方案, 知道嘛?
在Redis中提供的集群方案總共有三種:主從復制、哨兵模式、Redis分片集群
- 主從和哨兵可以解決高可用、高并發讀的問題
- 分片集群可以解決海量數據存儲問題、高并發寫的問題
那你能介紹一下主從同步嗎?
單節點Redis的并發能力是有上限的,要進一步提高Redis的并發能力,可以搭建主從集群,實現讀寫分離。一般都是一主多從,主節點負責寫數據,從節點負責讀數據,主節點寫入數據之后,需要把數據同步到從節點中
能說一下,主從同步數據的流程?
主從同步分為了兩個階段,一個是全量同步,一個是增量同步
全量同步是指從節點第一次與主節點建立連接的時候使用全量同步,流程是這樣的:
- 從節點請求主節點同步數據,其中從節點會攜帶自己的拷貝(replication) id和偏移量(offset)
- 主節點判斷是否是第一次請求,主要判斷的依據就是,主節點與從節點是否是同一個replication id,如果不是,就說明是第一次同步,那主節點就會把自己的replication id和offset發送給從節點,讓從節點與主節點的信息保持一致
- 在同時主節點會執行bgsave,生成rdb文件后,發送給從節點去執行,從節點先把自己的數據清空,然后執行主節點發送過來的rdb文件,這樣就保持了一致
- 如果在rdb生成執行期間,依然有請求到了主節點,而主節點會以命令的方式記錄到緩沖區,緩沖區是一個日志文件,最后把這個日志文件發送給從節點,這樣就能保證主節點與從節點完全一致了,后期再同步數據的時候,都是依賴于這個日志文件,這個就是全量同步
增量同步指的是,當從節點服務重啟之后,數據就不一致了,所以這個時候,從節點會請求主節點同步數據,主節點還是判斷是不是第一次請求,不是第一次就獲取從節點的offset值,然后主節點從命令日志中獲取offset值之后的數據,發送給從節點進行數據同步
怎么保證Redis的高并發高可用?
首先可以搭建主從集群,再加上使用redis中的哨兵模式,哨兵模式可以實現主從集群的自動故障恢復,里面就包含了對主從服務的監控、自動故障恢復、通知;如果master故障,Sentinel會將一個slave提升為master。當故障實例恢復后也以新的master為主;同時Sentinel也充當Redis客戶端的服務發現來源,當集群發生故障轉移時,會將最新信息推送給Redis的客戶端,所以一般項目都會采用哨兵的模式來保證redis的高并發高可用
redis集群腦裂,該怎么解決呢?
有的時候由于網絡等原因可能會出現腦裂的情況,就是說,由于redis master節點和redis salve節點和sentinel處于不同的網絡分區,使得sentinel沒有能夠心跳感知到master,所以通過選舉的方式提升了一個salve為master,這樣就存在了兩個master,就像大腦分裂了一樣,這樣會導致客戶端還在old master那里寫入數據,新節點無法同步數據,當網絡恢復后,sentinel會將old master降為salve,這時再從新master同步數據,這會導致old master中的大量數據丟失。
關于解決的話,在redis的配置中可以設置:第一可以設置最少的salve節點個數,比如設置至少要有一個從節點才能同步數據,第二個可以設置主從數據復制和同步的延遲時間,達不到要求就拒絕請求,就可以避免大量的數據丟失
redis的分片集群有什么作用?
分片集群主要解決的是,海量數據存儲的問題,集群中有多個master,每個master保存不同數據,并且還可以給每個master設置多個slave節點,就可以繼續增大集群的高并發能力。同時每個master之間通過ping監測彼此健康狀態,就類似于哨兵模式了。當客戶端請求可以訪問集群任意節點,最終都會被轉發到正確節點
Redis分片集群中數據是怎么存儲和讀取的?
Redis 集群引入了哈希槽的概念,有 16384 個哈希槽,集群中每個主節點綁定了一定范圍的哈希槽范圍, key通過 CRC16 校驗后對 16384 取模來決定放置哪個槽,通過槽找到對應的節點進行存儲
取值的邏輯是一樣的
Redis是單線程的,但是為什么還那么快?
- 完全基于內存的,C語言編寫
- 采用單線程,避免不必要的上下文切換可競爭條件,多線程還要考慮線程安全問題
- 使用多路I/O復用模型,非阻塞IO
例如:bgsave 和 bgrewriteaof 都是在后臺執行操作,不影響主線程的正常使用,不會產生阻塞
能解釋一下I/O多路復用模型?
I/O多路復用是指利用單個線程來同時監聽多個Socket ,并在某個Socket可讀、可寫時得到通知,從而避免無效的等待,充分利用CPU資源。目前的I/O多路復用都是采用的epoll模式實現,它會在通知用戶進程Socket就緒的同時,把已就緒的Socket寫入用戶空間,不需要挨個遍歷Socket來判斷是否就緒,提升了性能
其中Redis的網絡模型就是使用I/O多路復用結合事件的處理器來應對多個Socket請求,比如,提供了連接應答處理器、命令回復處理器,命令請求處理器
在Redis6.0之后,為了提升更好的性能,在命令回復處理器使用了多線程來處理回復事件,在命令請求處理器中,將命令的轉換使用了多線程,增加命令轉換速度,在命令執行的時候,依然是單線程
MySQL篇
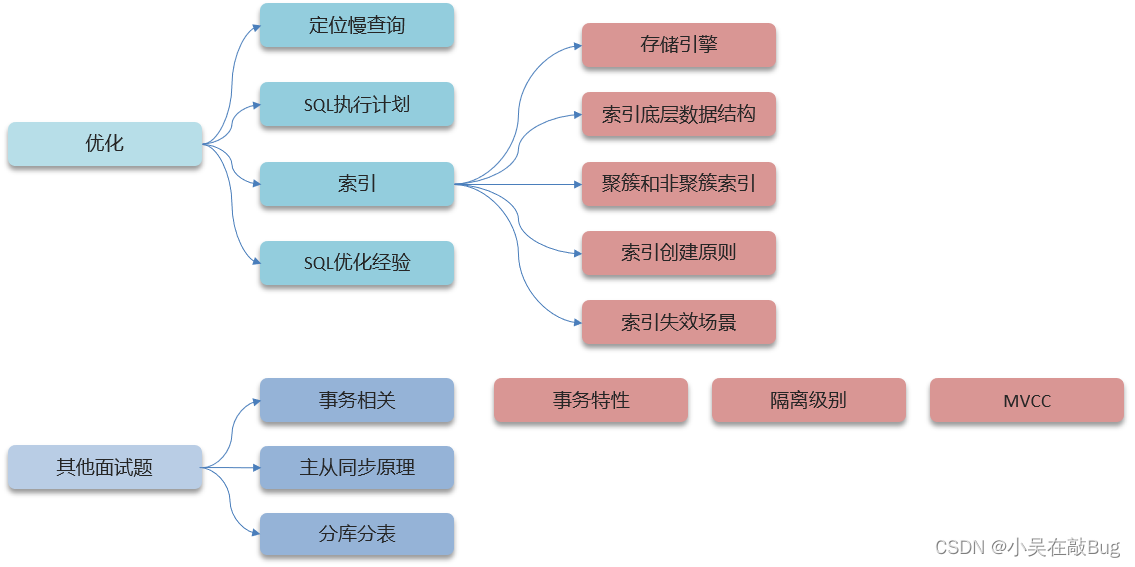
MySQL中,如何定位慢查詢?
在MySQL中提供了慢日志查詢的功能,可以在MySQL的系統配置文件中開啟這個慢日志的功能,并且也可以設置SQL執行超過多少時間來記錄到一個日志文件中
SQL語句執行很慢, 如何分析呢?
如果一條sql執行很慢的話,我們通常會使用mysql自帶的執行計劃explain來去查看這條sql的執行情況,比如在這里面可以通過key和key_len檢查是否命中了索引,如果本身已經添加了索引,也可以判斷索引是否有失效的情況,第二個,可以通過type字段查看sql是否有進一步的優化空間,是否存在全索引掃描或全盤掃描,第三個可以通過extra建議來判斷,是否出現了回表的情況,如果出現了,可以嘗試添加索引或修改返回字段來修復
什么是索引?
它是幫助MySQL高效獲取數據的數據結構,主要是用來提高數據檢索的效率,降低數據庫的IO成本,同時通過索引列對數據進行排序,降低數據排序的成本,也能降低了CPU的消耗
索引的底層數據結構了解過嘛 ?
MySQL的默認的存儲引擎InnoDB采用的B+樹的數據結構來存儲索引,選擇B+樹的主要的原因是:第一階數更多,路徑更短,第二磁盤讀寫代價B樹更低,非葉子節點只存儲指針,葉子階段存儲數據,第三B+樹便于掃庫和區間查詢,葉子節點是一個雙向鏈表
B樹和B+樹的區別是什么呢?
- 第一:在B樹中,非葉子節點和葉子節點都會存放數據,而B+樹的所有的數據都會出現在葉子節點,在查詢的時候,B+樹查找效率更加穩定
- 第二:在進行范圍查詢的時候,B+樹效率更高,因為B+樹都在葉子節點存儲,并且葉子節點是一個雙向鏈表
什么是聚簇索引什么是非聚簇索引 ?
-
聚簇索引主要是指數據與索引放到一塊,B+樹的葉子節點保存了整行數據,有且只有一個,一般情況下主鍵作為聚簇索引
-
非聚簇索引指的是數據與索引分開存儲,B+樹的葉子節點保存對應的主鍵,可以有多個,一般我們自己定義的索引都是非聚簇索引
什么是回表查詢?
回表的意思就是通過二級索引找到對應的主鍵值,然后再通過主鍵值找到聚集索引中所對應的整行數據,這個過程就是回表(如果面試官直接問回表,則需要先介紹聚簇索引和非聚簇索引)
什么叫覆蓋索引?
覆蓋索引是指select查詢語句使用了索引,在返回的列,必須在索引中全部能夠找到,如果我們使用id查詢,它會直接走聚集索引查詢,一次索引掃描,直接返回數據,性能高
如果按照二級索引查詢數據的時候,返回的列中沒有創建索引,有可能會觸發回表查詢,盡量避免使用select *,盡量在返回的列中都包含添加索引的字段
MYSQL超大分頁怎么處理?
超大分頁一般都是在數據量比較大時,我們使用了limit分頁查詢,并且需要對數據進行排序,這個時候效率就很低,我們可以采用覆蓋索引和子查詢來解決
先分頁查詢數據的id字段,確定了id之后,再用子查詢來過濾,只查詢這個id列表中的數據就可以了
因為查詢id的時候,走的覆蓋索引,所以效率可以提升很多
索引創建原則有哪些?
添加索引的字段是查詢比較頻繁的字段,一般也是作為查詢條件,排序字段或分組的字段
通常創建索引的時候都是使用復合索引來創建,一條sql的返回值,盡量使用覆蓋索引,如果字段的區分度不高的話,我們也會把它放在組合索引后面的字段
如果某一個字段的內容較長,我們會考慮使用前綴索引來使用,當然并不是所有的字段都要添加索引,這個索引的數量也要控制,因為添加索引也會導致增改刪的速度變慢
什么情況下索引會失效 ?
- 違反最左前綴法則
- 范圍查詢右邊的列,不能使用索引
- 不要再索引列上進行運算操作,索引將失效
- 字符串不加單引號,造成索引失效(類型轉換)
- 以%開頭的like模糊查詢,索引失效
sql的優化的經驗
sql優化的話,我們會從這幾方面考慮,比如:建表的時候、使用索引、sql語句的編寫、主從復制,讀寫分離,還有一個是如果數據量比較大的話,可以考慮分庫分表
創建表的時候,如何優化的呢?
在定義字段的時候需要結合字段的內容來選擇合適的類型,如果是數值的話,像tinyint、int 、bigint這些類型,要根據實際情況選擇。如果是字符串類型,也是結合存儲的內容來選擇char和varchar或者text類型
平時對sql語句做了哪些優化呢?
SELECT語句務必指明字段名稱,不要直接使用select * ,還有就是要注意SQL語句避免造成索引失效的寫法;如果是聚合查詢,盡量用union all代替union ,union會多一次過濾,效率比較低;如果是表關聯的話,盡量使用innerjoin ,不要使用用left join right join,如必須使用 一定要以小表為驅動
事務的特性是什么?可以詳細說一下嗎?
事務ACID,分別指的是:
- 原子性: 事務是不可分割的最小操作單元,要么全部成功,要么全部失敗
- 一致性:事務完成時,必須使所有的數據都保持一致狀態
- 隔離性:數據庫系統提供的隔離機制,保證事務在不受外部并發操作影響的獨立環境運行
- 持久性;事務一但提交或回滾,它對數據庫中數據的改變就是永久的
我舉個例子:
A向B轉賬500,轉賬成功,A扣除500元,B增加500元,原子操作體現在要么都成功,要么都失敗
在轉賬的過程中,數據要一致,A扣除了500,B必須增加500
在轉賬的過程中,隔離性體現在A像B轉賬,不能受其他事務干擾
在轉賬的過程中,持久性體現在事務提交后,要把數據持久化(可以說是落盤操作)
并發事務帶來哪些問題?
- 第一是臟讀, 當一個事務正在訪問數據并且對數據進行了修改,而這種修改還沒有提交到數據庫中,這時另外一個事務也訪問了這個數據,因為這個數據是還沒有提交的數據,那么另外一個事務讀到的這個數據是“臟數據”,依據“臟數據”所做的操作可能是不正確的
- 第二是不可重復讀:比如在一個事務內多次讀同一數據。在這個事務還沒有結束時,另一個事務也訪問該數據。那么,在第一個事務中的兩次讀數據之間,由于第二個事務的修改導致第一個事務兩次讀取的數據可能不太一樣。這就發生了在一個事務內兩次讀到的數據是不一樣的情況,因此稱為不可重復讀
- 第三是幻讀(Phantom read):幻讀與不可重復讀類似。它發生在一個事務(T1)讀取了幾行數據,接著另一個并發事務(T2)插入了一些數據時。在隨后的查詢中,第一個事務(T1)就會發現多了一些原本不存在的記錄,就好像發生了幻覺一樣,所以稱為幻讀
怎么解決這些問題呢?MySQL的默認隔離級別是?
解決方案是對事務進行隔離
- 第一個是,未提交讀(read uncommitted)它解決不了剛才提出的所有問題,一般項目中也不用這個
- 第二個是讀已提交(read committed)它能解決臟讀的問題的,但是解決不了不可重復讀和幻讀
- 第三個是可重復讀(repeatable read)它能解決臟讀和不可重復讀,但是解決不了幻讀,這個也是mysql默認的隔離級別
- 第四個是串行化(serializable)它可以解決剛才提出來的所有問題,但是由于讓是事務串行執行的,性能比較低。所以,我們一般使用的都是mysql默認的隔離級別:可重復讀
undo log和redo log的區別
其中redo log日志記錄的是數據頁的物理變化,服務宕機可用來同步數據,而undo log 不同,它主要記錄的是邏輯日志,當事務回滾時,通過逆操作恢復原來的數據,比如我們刪除一條數據的時候,那么undo log中會記錄一個與原始刪除操作相反的插入操作,如果發生回滾就執行逆操作
redo log保證了事務的持久性,undo log保證了事務的原子性和一致性
事務中的隔離性是如何保證的呢?(你解釋一下MVCC)
事務的隔離性是由鎖和MVCC實現的
其中MVCC的意思是多版本并發控制。指維護一個數據的多個版本,使得讀寫操作沒有沖突,它的底層實現主要是分為了三個部分,第一個是隱藏字段,第二個是undo log日志,第三個是readView讀視圖
隱藏字段是指:在mysql中給每個表都設置了隱藏字段,有一個是trx_id(事務id),記錄每一次操作的事務id,是自增的;另一個字段是roll_pointer(回滾指針),指向上一個版本的事務版本記錄地址
undo log主要的作用是記錄回滾日志,存儲老版本數據,在內部會形成一個版本鏈,在多個事務并行操作某一行記錄,記錄不同事務修改數據的版本,通過roll_pointer指針形成一個鏈表
readView解決的是一個事務查詢選擇版本的問題,在內部定義了一些匹配規則和當前的一些事務id判斷該訪問那個版本的數據,不同的隔離級別快照讀是不一樣的,最終的訪問的結果不一樣。如果是rc隔離級別,每一次執行快照讀時生成ReadView,如果是rr隔離級別僅在事務中第一次執行快照讀時生成ReadView,后續復用
MySQL主從同步原理
MySQL主從復制的核心就是二進制日志(DDL(數據定義語言)語句和 DML(數據操縱語言)語句),它的步驟是這樣的:
- 第一:主庫在事務提交時,會把數據變更記錄在二進制日志文件 Binlog 中
- 從庫讀取主庫的二進制日志文件 Binlog ,寫入到從庫的中繼日志 Relay Log
- 從庫重做中繼日志中的事件,將改變反映它自己的數據
框架篇
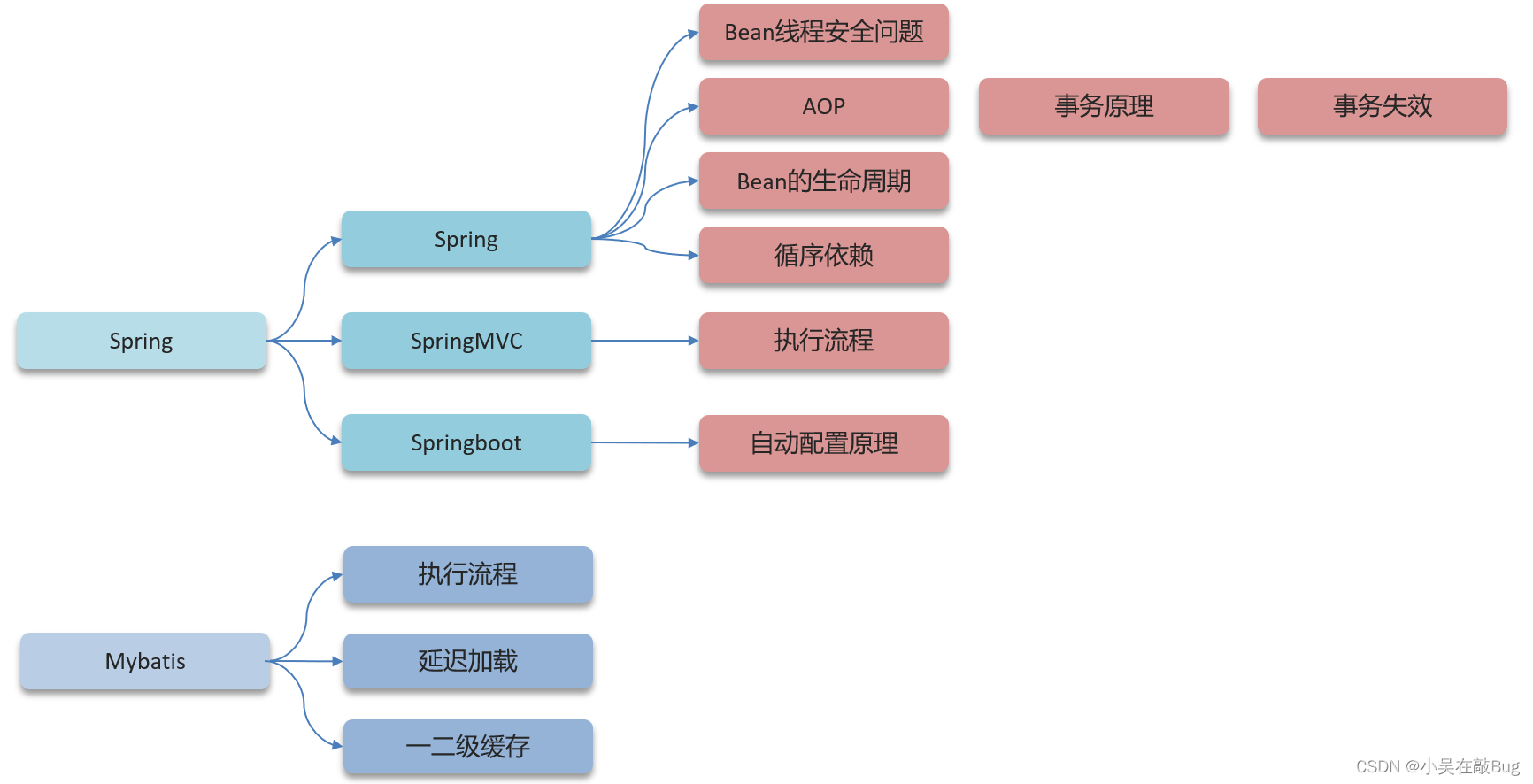
Spring框架中的單例bean是線程安全的嗎?
不是線程安全的
當多用戶同時請求一個服務時,容器會給每一個請求分配一個線程,這時多個線程會并發執行該請求對應的業務邏輯(成員方法),如果該處理邏輯中有對該單列狀態的修改(體現為該單例的成員屬性),則必須考慮線程同步問題。
Spring框架并沒有對單例bean進行任何多線程的封裝處理。關于單例bean的線程安全和并發問題需要開發者自行去搞定。
比如:我們通常在項目中使用的Spring bean都是不可變的狀態(比如Service類和DAO類),所以在某種程度上說Spring的單例bean是線程安全的。
如果你的bean有多種狀態的話(比如 View Model對象),就需要自行保證線程安全。最淺顯的解決辦法就是將多態bean的作用由“singleton”變更為“prototype”。
什么是AOP?
aop是面向切面編程,在spring中用于將那些與業務無關,但卻對多個對象產生影響的公共行為和邏輯,抽取公共模塊復用,降低耦合,比如可以做為公共日志保存,事務處理等
Spring中的事務是如何實現的?
spring實現的事務本質就是aop完成,對方法前后進行攔截,在執行方法之前開啟事務,在執行完目標方法之后根據執行情況提交或者回滾事務。
Spring中事務失效的場景有哪些?
- 數據庫不支持事務
- 如果方法上異常捕獲處理,自己處理了異常,沒有拋出,就會導致事務失效,所以一般處理了異常以后,別忘了拋出去
- 如果方法拋出檢查異常,如果報錯也會導致事務失效,最后在spring事務的注解上,就是@Transactional上配置rollbackFor屬性為Exception,這樣不管是什么異常,都會回滾事務
- 如果方法上不是public修飾的,也會導致事務失效
- 如果事務方法被final或static修飾,由于Spring的AOP代理機制無法對final或static方法進行代理,因此這些事務方法將不會生效
- 事務傳播性配置錯誤
spring事務的傳播性?
- REQUIRED(必需):如果當前有事務則加入,否則新建事務
- SUPPORTS(支持):如果當前有事務則加入,無事務則非事務執行
- MANDATORY(強制):必須有事務,無事務則拋出異常
- REQUIRES_NEW(新建):總是新建事務,若當前有事務則掛起
- NOT_SUPPORTED(不支持):總是非事務執行,若當前有事務則掛起
- NEVER(禁止):不能有事務,若當前有事務則拋出異常
- NESTED(嵌套):若當前有事務則為當前事務創建嵌套事務,否則同REQUIRED
Spring的bean的生命周期?
- 實例化階段:Spring容器根據配置創建Bean的實例
- 屬性注入階段:Spring將配置的屬性值或依賴的Bean注入到新創建的Bean實例中
- Aware接口注入階段:如果Bean實現了特定的Aware接口(如BeanNameAware),Spring會注入相關的上下文信息
- BeanPostProcessor的前置處理階段:BeanPostProcessor允許在Bean初始化之前進行自定義邏輯處理
- 初始化階段:Bean執行自定義的初始化邏輯,如通過@PostConstruct注解的方法或InitializingBean接口定義的方法
- 就緒使用階段:Bean已完成初始化,可供應用程序使用
- BeanPostProcessor的后置處理階段:BeanPostProcessor允許在Bean初始化之后進行額外的自定義邏輯處理
- 使用階段:Bean在應用程序中執行其業務邏輯
- 銷毀階段:當Spring容器關閉時,Bean執行自定義的銷毀邏輯,如通過@PreDestroy注解的方法或DisposableBean接口定義的方法
Spring中的循環引用?
循環依賴:循環依賴其實就是循環引用,也就是兩個或兩個以上的bean互相持有對方,最終形成閉環。比如A依賴于B,B依賴于A
循環依賴在Spring中是允許存在,Spring框架依據三級緩存已經解決了大部分的循環依賴
- 一級緩存:單例池,緩存已經經歷了完整的生命周期,已經初始化完成的Bean對象
- 二級緩存:緩存早期的Bean對象(生命周期還沒走完)
- 三級緩存:緩存的是ObjectFactory,表示對象工廠,用來創建某個對象
構造方法出現了循環依賴怎么解決?
由于bean的生命周期中構造函數是第一個執行的,spring框架并不能解決構造函數的的依賴注入,可以使用@Lazy懶加載,什么時候需要對象再進行Bean對象的創建
SpringMVC的執行流程知道嗎?
- 用戶發送請求到前端控制器DispatcherServlet,這是一個調度中心
- DispatcherServlet收到請求調用HandlerMapping(處理器映射器)
- HandlerMapping找到具體的處理器(可查找xml配置或注解配置),生成處理器對象及處理器攔截器(如果有),再一起返回給DispatcherServlet
- DispatcherServlet調用HandlerAdapter(處理器適配器)
- HandlerAdapter經過適配調用具體的處理器(Handler/Controller)
- Controller執行完成返回ModelAndView對象
- HandlerAdapter將Controller執行結果ModelAndView返回給DispatcherServlet
- DispatcherServlet將ModelAndView傳給ViewReslover(視圖解析器)
- ViewReslover解析后返回具體View(視圖)
- DispatcherServlet根據View進行渲染(即將模型數據填充至視圖中)
- DispatcherServlet響應用戶
Springboot自動配置原理?
在Spring Boot項目中的引導類上有一個注解@SpringBootApplication,這個注解是對三個注解進行了封裝,分別是:
- @SpringBootConfiguration(SpringBoot配置注解)
- @EnableAutoConfiguration(啟用自動配置注解)
- @ComponentScan(組件掃描注解)
其中@EnableAutoConfiguration是實現自動化配置的核心注解
該注解通過@Import注解導入對應的配置選擇器。關鍵的是內部就是讀取了該項目和該項目引用的Jar包的的classpath路徑下META-INF/spring.factories文件中的所配置的類的全類名
在這些配置類中所定義的Bean會根據條件注解所指定的條件來決定是否需要將其導入到Spring容器中
一般條件判斷會有像@ConditionalOnClass這樣的注解,判斷是否有對應的class文件,如果有則加載該類,把這個配置類的所有的Bean放入spring容器中使用
Spring 的常見注解有哪些?
- 第一類是:聲明bean,有@Component、@Service、@Repository、@Controller
- 第二類是:依賴注入相關的,有@Autowired、@Qualifier、@Resourse
- 第三類是:設置作用域 @Scope
- 第四類是:spring配置相關的,比如@Configuration,@ComponentScan 和 @Bean
- 第五類是:跟aop相關做增強的注解 @Aspect,@Before,@After,@Around,@Pointcut
SpringMVC常見的注解有哪些?
- @RequestMapping:用于映射請求路徑
- @RequestBody:注解實現接收http請求的json數據,將json轉換為java對象
- @RequestParam:指定請求參數的名稱
- @PathViriable:從請求路徑下中獲取請求參數(/user/{id}),傳遞給方法形參
- @ResponseBody:注解實現將controller方法返回對象轉化為json對象響應給客戶端
- @RequestHeader:獲取指定的請求頭數據,還有像@PostMapping、@GetMapping這些
Springboot常見注解有哪些?
Spring Boot的核心注解是@SpringBootApplication , 他由幾個注解組成 :
- @SpringBootConfiguration(SpringBoot配置注解): 組合了- @Configuration注解,實現配置文件的功能;
- @EnableAutoConfiguration(啟用自動配置注解):打開自動配置的功能,也可以關閉某個自動配置的選項
- @ComponentScan(組件掃描注解):Spring組件掃描
MyBatis執行流程
- 讀取MyBatis配置文件:mybatis-config.xml加載運行環境和映射文件
- 構造會話工廠SqlSessionFactory,一個項目只需要一個,單例的,一般由spring進行管理
- 會話工廠創建SqlSession對象,這里面就含了執行SQL語句的所有方法
- 操作數據庫的接口,Executor執行器,同時負責查詢緩存的維護
- Executor接口的執行方法中有一個MappedStatement類型的參數,封裝了映射信息
- 輸入參數映射
- 輸出結果映射
Mybatis是否支持延遲加載?
支持
延遲加載的意思是:就是在需要用到數據時才進行加載,不需要用到數據時就不加載數據
Mybatis支持一對一關聯對象和一對多關聯集合對象的延遲加載
在Mybatis配置文件中,可以配置是否啟用延遲加載lazyLoadingEnabled = true | false,默認是關閉的
延遲加載的底層原理
延遲加載在底層主要使用的CGLIB動態代理完成的
-
第一是使用CGLIB創建目標對象的代理對象,這里的目標對象就是開啟了延遲加載的mapper
-
第二個是當調用目標方法時,進入攔截器invoke方法,發現目標方法是null值,再執行sql查詢
-
第三個是獲取數據以后,調用set方法設置屬性值,再繼續查詢目標方法,就有值了
Mybatis的一級、二級緩存了解嗎?
mybatis的一級緩存: 基于 PerpetualCache 的 HashMap 本地緩存,其存儲作用域為 SQLSession,當Session進行flush或close之后,該SQLSession中的所有Cache就將清空,默認打開一級緩存
關于二級緩存需要單獨開啟
二級緩存是基于namespace和mapper的作用域起作用的,不是依賴于SQLSession,默認也是采用 PerpetualCache,HashMap 本地存儲
如果想要開啟二級緩存需要在全局配置文件和映射文件中開啟配置才行
Mybatis的二級緩存什么時候會清理緩存中的數據?
當某一個作用域(一級緩存 Session/二級緩存Namespaces)進行了新增、修改、刪除操作后,默認該作用域下所有 select 中的緩存將被 clear
微服務篇
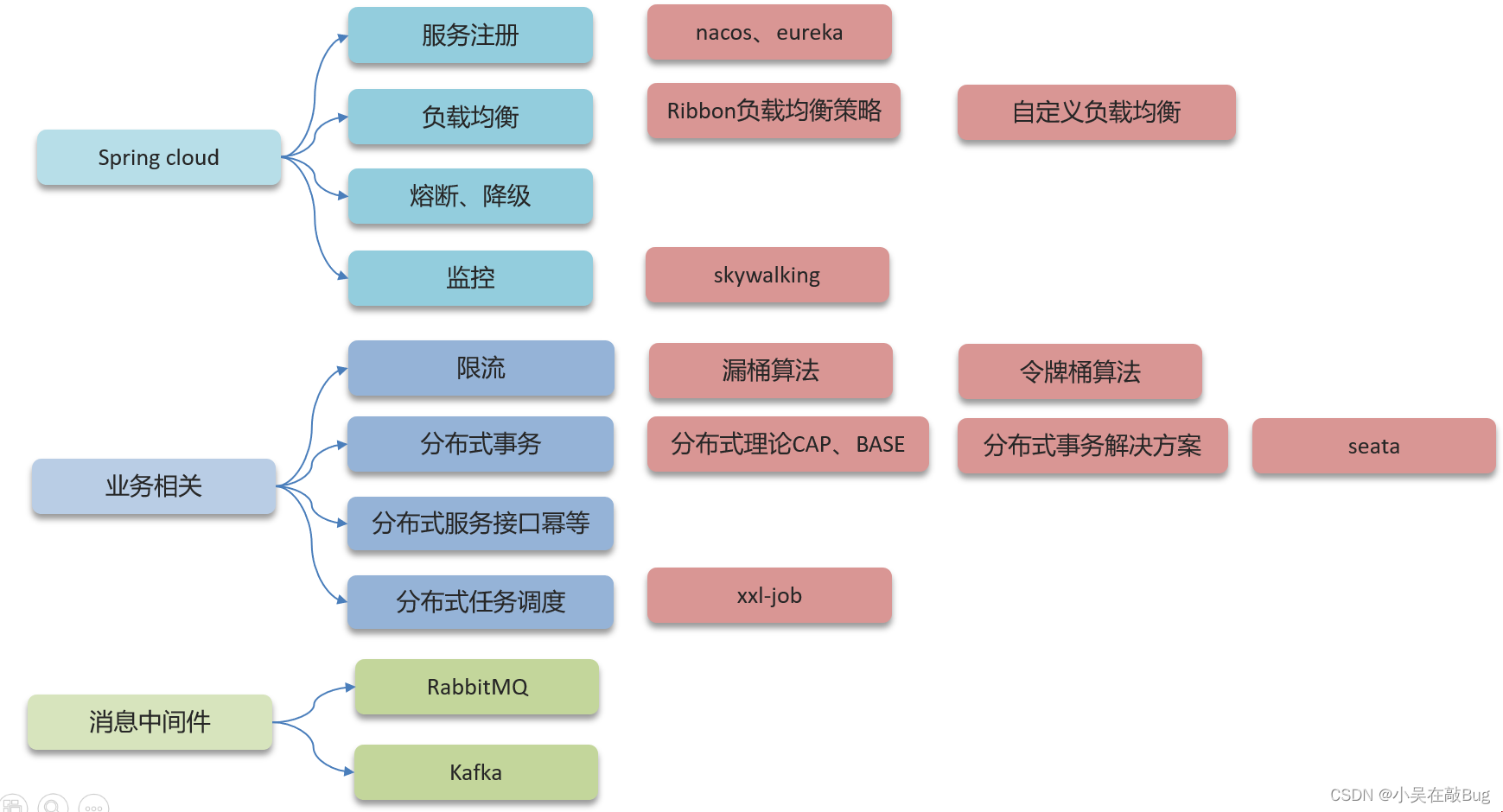
Spring Cloud 組件有哪些?
早期我們一般認為的Spring Cloud五大組件是
- Eureka : 注冊中心
- Ribbon : 負載均衡
- Feign : 遠程調用
- Hystrix : 服務熔斷
- Zuul/Gateway : 網關
隨著SpringCloudAlibba在國內興起 , 我們項目中使用了一些阿里巴巴的組件
-
注冊中心/配置中心 Nacos
-
負載均衡 Ribbon
-
服務調用 Feign
-
服務保護 sentinel
-
服務網關 Gateway
服務注冊和發現是什么意思?Spring Cloud 如何實現服務注冊發現?
我理解的是主要三塊大功能,分別是服務注冊 、服務發現、服務狀態監控
-
服務注冊:服務注冊是將服務實例的信息添加到Nacos注冊中心,使其他服務能夠發現并使用。
-
服務發現:服務發現是從Nacos注冊中心獲取可用的服務實例信息,以便服務消費者能夠調用它們
-
服務監控:監控監視是Nacos對注冊服務進行健康檢查和狀態監控,確保服務的高可用性和動態性
能說下nacos與eureka的區別嗎?
共同點:
- Nacos與eureka都支持服務注冊和服務拉取,都支持服務提供者心跳方式做健康檢測
Nacos與Eureka的區別:
- Nacos支持服務端主動檢測提供者狀態:臨時實例采用心跳模式,非臨時實例采用主動檢測模式
- 臨時實例心跳不正常會被剔除,非臨時實例則不會被剔除
- Nacos支持服務列表變更的消息推送模式,服務列表更新更及時
- Nacos集群默認采用AP方式,當集群中存在非臨時實例時,采用CP模式;Eureka采用AP方式
Nacos還支持配置中心,Eureka則只有注冊中心
負載均衡如何實現的 ?
在服務調用過程中的負載均衡一般使用SpringCloud的Ribbon 組件實現 , Feign的底層已經自動集成了Ribbon , 使用起來非常簡單
當發起遠程調用時,ribbon先從注冊中心拉取服務地址列表,然后按照一定的路由策略選擇一個發起遠程調用,一般的調用策略是輪詢
Ribbon負載均衡策略有哪些 ?
-
RoundRobinRule:簡單輪詢服務列表來選擇服務器
-
WeightedResponseTimeRule:按照權重來選擇服務器,響應時間越長,權重越小
-
RandomRule:隨機選擇一個可用的服務器
-
ZoneAvoidanceRule:區域敏感策略,以區域可用的服務器為基礎進行服務器的選擇。使用Zone對服務器進行分類,這個Zone可以理解為一個機房、一個機架等。而后再對Zone內的多個服務做輪詢(默認)
如果想自定義負載均衡策略如何實現 ?
提供了兩種方式:
- 創建類實現IRule接口,可以指定負載均衡策略,這個是全局的,對所有的遠程調用都起作用
- 在客戶端的配置文件中,可以配置某一個服務調用的負載均衡策略,只是對配置的這個服務生效遠程調用
什么是服務雪崩,怎么解決這個問題?
服務雪崩是指一個服務失敗,導致整條鏈路的服務都失敗的情形,一般我們在項目解決的話就是兩種方案,第一個是服務降級,第二個是服務熔斷,如果流量太大的話,可以考慮限流
服務降級: 服務自我保護的一種方式,或者保護下游服務的一種方式,用于確保服務不會受請求突增影響變得不可用,確保服務不會崩潰,一般在實際開發中與feign接口整合,編寫降級邏輯
服務熔斷: 默認關閉,需要手動打開,如果檢測到 10 秒內請求的失敗率超過 50%,就觸發熔斷機制。之后每隔 5 秒重新嘗試請求微服務,如果微服務不能響應,繼續走熔斷機制。如果微服務可達,則關閉熔斷機制,恢復正常請求
限流有哪些實現方式?
- nginx限流操作,nginx使用的漏桶算法來實現過濾,讓請求以固定的速率處理請求,可以應對突發流量,我們控制的速率是按照ip進行限流,限制的流量是每秒20
- spring cloud gateway中支持局部過濾器RequestRateLimiter來做限流,使用的是令牌桶算法,可以根據ip或路徑進行限流,可以設置每秒填充平均速率,和令牌桶總容量
限流常見的算法有哪些呢?
比較常見的限流算法有漏桶算法和令牌桶算法:
- 漏桶算法是把請求存入到桶中,以固定速率從桶中流出,可以讓我們的服務做到絕對的平均,起到很好的限流效果
- 令牌桶算法在桶中存儲的是令牌,按照一定的速率生成令牌,每個請求都要先申請令牌,申請到令牌以后才能正常請求,也可以起到很好的限流作用
- 它們的區別是,漏桶和令牌桶都可以處理突發流量,其中漏桶可以做到絕對的平滑,令牌桶有可能會產生突發大量請求的情況,一般nginx限流采用的漏桶,spring cloud gateway中可以支持令牌桶算法
什么是CAP理論?
CAP主要是在分布式項目下的一個理論。包含了三項,一致性、可用性、分區容錯性
-
一致性(Consistency)是指更新操作成功并返回客戶端完成后,所有節點在同一時間的數據完全一致(強一致性),不能存在中間狀態。
-
可用性(Availability) 是指系統提供的服務必須一直處于可用的狀態,對于用戶的每一個操作請求總是能夠在有限的時間內返回結果。
-
分區容錯性(Partition tolerance) 是指分布式系統在遇到任何網絡分區故障時,仍然需要能夠保證對外提供滿足一致性和可用性的服務,除非是整個網絡環境都發生了故障。
為什么分布式系統中無法同時保證一致性和可用性?
首先一個前提,對于分布式系統而言,分區容錯性是一個最基本的要求,因此基本上我們在設計分布式系統的時候只能從一致性(C)和可用性(A)之間進行取舍。
如果保證了一致性(C):對于節點N1和N2,當往N1里寫數據時,N2上的操作必須被暫停,只有當N1同步數據到N2時才能對N2進行讀寫請求,在N2被暫停操作期間客戶端提交的請求會收到失敗或超時。顯然,這與可用性是相悖的。
如果保證了可用性(A):那就不能暫停N2的讀寫操作,但同時N1在寫數據的話,這就違背了一致性的要求。
什么是BASE理論?
BASE是CAP理論中AP方案的延伸,核心思想是即使無法做到強一致性(StrongConsistency,CAP的一致性就是強一致性),但應用可以采用適合的方式達到最終一致性(Eventual Consitency)。它的思想包含三方面:
-
Basically Available(基本可用):基本可用是指分布式系統在出現不可預知的故障的時候,允許損失部分可用性,但不等于系統不可用。
-
Soft state(軟狀態):即是指允許系統中的數據存在中間狀態,并認為該中間狀態的存在不會影響系統的整體可用性,即允許系統在不同節點的數據副本之間進行數據同步的過程存在延時。
-
Eventually consistent(最終一致性):強調系統中所有的數據副本,在經過一段時間的同步后,最終能夠達到一個一致的狀態。其本質是需要系統保證最終數據能夠達到一致,而不需要實時保證系統數據的強一致性。
分布式事務有哪些解決方案?
- seata的XA模式,CP,需要互相等待各個分支事務提交,可以保證強一致性,性能差
- seata的AT模式,AP,底層使用undo log實現,性能好
- seata的TCC模式,AP,西能較好,不過需要人工編碼實現
- MQ模式實現分布式事務,在A服務寫數據的時候,需要在同一個事物內發送消息到另外一個事物,異步,能最好
分布式服務的接口冪等性如何設計?
- 冪等:多次調用方法或者不會改變業務狀態,可以
保證重復調用的結果和單詞調用的結果一致 - 如果是新增數據,可以使用數據庫的唯一索引
- 如果是新增或修改數據
- 分布式鎖,性能較低
- 使用 token + redis 來實現,性能較好
- 第一次請求,生成一個唯一token存儲redis,返回給前端
- 第二次請求,業務處理,攜帶之前的token,到redis進行驗證,如果存在,可以執行業務,刪除token;如果不存在,則直接返回,不處理業務
xxl-job篇
xxl-job路由策略有哪些?
xxl-job提供了很多的路由策略,比較常用的有:輪詢、故障轉移、分片廣播、隨機…
xxl-job任務執行失敗怎么解決?
- 第一:路由策略選擇故障轉移,優先使用健康的實例來執行任務
- 第二,如果還有失敗的,我們在創建任務時,可以設置重試次數
- 第三,如果還有失敗的,就可以查看日志或者配置郵件告警來通知相關負責人解決
如果有大數據量的任務同時都需要執行,怎么解決?
部署多個實例,共同去執行這些批量的任務,其中任務的路由策略是分片廣播
在任務執行的代碼中可以獲取分片總數和當前分片,按照取模的方式分攤到各個實例執行就可以了
消息中間件
RabbitMQ
RabbitMQ 如何保證消息不丟失?
我們要保證消息的不丟失,主要從三個層面考慮:
- 第一個是開啟生產者確認機制,確保生產者的消息能到達隊列,如果報錯可以先記錄到日志中,再去修復數據
- 第二個是開啟持久化功能,確保消息未消費前在隊列中不會丟失,其中的交換機、隊列、和消息都要做持久化
- 第三個是開啟消費者確認機制為auto,由spring確認消息處理成功后完成ack,當然也需要設置一定的重試次數,我們當時設置了3次,如果重試3次還沒有收到消息,就將失敗后的消息投遞到異常交換機,交由人工處理
RabbitMQ消息的重復消費問題如何解決的?
- 每條消息設置一個唯一的標識id
- 冪等性方案:分布式鎖、數據庫
RabbitMQ中死信交換機知道嗎?
當一個隊列中的消息滿足下列情況之一時,可以成為 死信(dead letter):
- 消費者使用
basic.reject或basic.nack聲明消費失敗,并且消息的requeue參數設置為false - 消息是一個過期消息,超時無人消費
- 要投遞的隊列消費堆積滿了,最早的消息可能成為死信
如果該隊列配置了 dead-letter-exchange 屬性,指定了一個交換機,那么隊列中的死信就會投遞到這個交換機中,而這個交換機為 死信交換機 (Dead Letter Exchange,簡稱DLX)
RabbitMQ延遲隊列有了解過嗎?
延遲隊列插件實現延遲隊列 DelayExchange
- 聲明一個交換機,添加
delayed屬性為true - 發送消息時,添加
x-delay頭,值為超時時間
如果有100萬消息堆積在MQ , 如何解決 ?
解決消息堆積有三種思路:
- 增加更多消費者,提高消費速度
- 再消費者內開啟線程池加快消息處理速度
- 擴大隊列容積,提高堆積上限,采用惰性隊列
- 在聲明隊列的時候可以設置屬性
x-queue-mode為lazy,即為惰性隊列 - 基于磁盤存儲,消息上限高
- 性能比較穩定,但基于磁盤存儲,受限于IO,時效性會降低
- 在聲明隊列的時候可以設置屬性
RabbitMQ的高可用機制有了解過嗎?
-
普通集群,或者叫標準集群(classic cluster),具備下列特征:
- 會在集群的各個節點間共享部分數據,包括:交換機、隊列元信息不包含隊列中的消息
- 當訪問集群某節點時,如果隊列不在該節點,會從數據所在節點傳遞到當前節點并返回
- 隊列所在節點宕機,隊列中的消息就會丟失
-
鏡像集群:本質是主從模式,具備下面的特征:
- 交換機、隊列、隊列中的消息會在各個mq的鏡像節點之間同步備份。
- 創建隊列的節點被稱為該隊列的主節點,備份到的其它節點叫做該隊列的鏡像節點。
- 一個隊列的主節點可能是另一個隊列的鏡像節點
- 所有操作都是主節點完成,然后同步給鏡像節點
- 主宕機后,鏡像節點會替代成新的主
-
仲裁隊列:仲裁隊列是3.8版本以后才有的新功能,用來替代鏡像隊列,具備下列特征:
- 與鏡像隊列一樣,都是主從模式,支持主從數據同步
- 使用非常簡單,沒有復雜的配置
- 主從同步基于Raft協議,強一致
Kafka
Kafka是如何保證消息不丟失?
需要從三個層面去解決這個問題:
- 生產者發送消息到
Brocker丟失- 設置異步發送,發送失敗使用回調進行記錄或重發
- 失敗重試,參數配置,可以設置重試次數
- 消息在
Brocker中存儲丟失- 發送確認
acks,選擇all,讓所有的副本都參與保存數據后確認
- 發送確認
- 消費者從
Brocker接收消息丟失- 關閉自動提交偏移量,開啟手動提交偏移量
- 提交方式,最好是同步 + 異步提交
Kafka中消息的重復消費問題如何解決的?
- 關閉自動提交偏移量,開啟手動提交偏移量
- 提交凡是,最好是同步 + 異步提交
- 冪等性方案:分布式鎖、數據庫
Kafka是如何保證消費的順序性?
問題原因: 一個 topic 的數據可能存儲在不同的分區中,每個分區都有一個按照順序的存儲的偏移量,如果消費者關聯了多個分區不能保證順序性
解決方案:
- 發送消息時指定分區號
- 發送消息時按照相同的業務設置相同的
key
Kafka的高可用機制有了解過嗎?
集群: 一個Kafka集群由多個 broker 實例組成,即使某一臺宕機,也不耽誤其它 broker 繼續對外提供服務
復制機制:
- 一個
topic有多個分區,每個分區有多個副本,有一個leader,其余的是follower,副本存儲在不同的borker中 - 所有的分區副本的內容都是相同的,如果
leader發生故障時,會自動將某一個follower提升為leader,保證了系統的容錯、高可用性
解釋一下復制機制中的ISR
ISR(in-sync replica)需要同步復制保存的 follower
分區副本分為兩類,一類是 ISR,與 leader 副本同步保存數據,另外一個普通的副本,是異步同步數據,當 leader 掛掉之后,會優先從 ISR 副本列表中選取一個作為 leader
Kafka數據清理機制了解過嗎?
Kafka存儲結構:
- Kafka 中 topic 的數據存儲在分區上,分區如果文件過大會分段存儲 segment
- 每個分段都在磁盤上以索引(xxx.index)和日志文件(xxx.log)的形式存儲
- 分段的好處是,第一能夠減少單個文件內容的大小,查找數據方便,第二方便 kafka 進行日志清理
日志的清理策略有兩個:
- 根據消息的保留時間,當消息保存的時間超過了指定的時間,就會觸發清理,默認是168小時(7天)
- 根據 topic 存儲的數據大小,當 topic 所占的日志文件大小大于一定的閾值,則開始刪除最久的消息(默認關閉)
Kafka中實現高性能的設計有了解過嗎?
Kafka 高性能,是多方面協同的結果,包括宏觀架構、分布式存儲、ISR 數據同步、以及高效的利用磁盤、操作系統特性等。主要體現有這么幾點:
- 消息分區:不受單臺服務器的限制,可以不受限的處理更多的數據
- 順序讀寫:磁盤順序讀寫,提升讀寫效率
- 頁緩存:把磁盤中的數據緩存到內存中,把對磁盤的訪問變為對內存的訪問
- 零拷貝:減少上下文切換及數據拷貝
- 消息壓縮:減少磁盤IO和網絡IO
- 分批發送:將消息打包批量發送,減少網絡開銷
常見集合篇

List相關面試題
為什么數組索引從0開始呢?假如從1開始不行嗎?
- 在根據數組索引獲取元素的時候,會用索引和尋址公式來計算內存所對應的元素數據,尋址公式是:數組的首地址 + 索引乘以存儲數據的類型大小
- 如果數組的索引從1開始,尋址公式中,就需要增加一次減法操作,對于CPU來說就多了一次指令,性能不高
ArrayList底層的實現原理是什么?
- ArrayList底層是用動態的數組實現的
- ArrayList初試容量為0,當第一次添加數據的時候才會初始化容量為10
- ArrayList在進行擴容的時候是原來的1.5倍,每次擴容都需要拷貝數組
- ArrayList在添加數據的時候
- 確保數組已使用長度(size)+ 1 之后足夠存下下一個數據
- 計算數組的容量,如果當前數組已使用長度 + 1 后大于當前的數組長度,則調用 grow 方法擴容(原來的1.5倍)
- 確保新增的數據有地方存儲之后,則將新元素添加到位于 size 的位置上
- 返回添加成功/失敗布爾值
ArrayList list = new ArrayList(10)中的list擴容幾次?
該語句只是聲明和實例了一個ArrayList,指定了容量為10,未擴容
如何實現數組和List之間的轉換?
- 數組轉List,使用 JDK 中
java.util.Arrays工具類的asLIst方法 - List轉數組,使用List的toArray方法。無參toArray方法返回Object數組,傳入初始化長度的數組對象,返回該對象數組
Arrays.asList轉List后,如果修改了數組內容,list受影響嗎?
Arrays.asList轉List后,如果修改了數組內容,list會受影響,因為它的底層使用的Arrays類中的一個內部類ArrayList來構造的集合,在這個集合的構造器中,把我們傳入的這個集合進行了包裝而已,最終指向的都是同一個內存地址
List用toArray轉數組后,如果修改了List內容,數組受影響嗎?
List用了toArray轉數組后,如果修改了list內容,數組不會受影響,當調用了toArray以后,在底層是它進行了數組的拷貝,跟原來的元素就沒有引用關系了,所以即使list修改了以后,數組也不受影響
ArrayList 和 LinkedList的區別是什么?
-
底層數據結構
-
ArrayList 是動態數組的數據結構實現
-
LinkedList 是雙向鏈表的數據結構實現
-
-
操作數據效率
- ArrayList按照下標查詢的時間復雜度O(1)(內存是連續的,根據尋址公式), LinkedList不支持下標查詢
- 查找(未知索引): ArrayList需要遍歷,鏈表也需要遍歷,時間復雜度都是O(n)
- 新增和刪除
- ArrayList尾部插入和刪除,時間復雜度是O(1);其他部分增刪需要挪動數組,時間復雜度是O(n)
- LinkedList頭尾節點增刪時間復雜度是O(1),其他都需要遍歷鏈表,時間復雜度是O(n)
-
內存空間占用
-
ArrayList底層是數組,內存連續,節省內存
-
LinkedList 是雙向鏈表需要存儲數據,和兩個指針,更占用內存
-
-
線程安全
- ArrayList和LinkedList都不是線程安全的
- 如果需要保證線程安全,有兩種方案:
- 在方法內使用,局部變量則是線程安全的
- 使用線程安全的ArrayList和LinkedList
HashMap相關面試題
說一下HashMap的實現原理?
HashMap的數據結構: 底層使用hash表數據結構,即數組和鏈表或紅黑樹
- 往 HashMap 中 put 元素時,利用 key 的 hashCode 重新 hash 計算出當前對象的元素在數組中的下標
- 存儲時,如果出現 hash 值相同的 key,此時有兩種情況
- 如果 key 相同,則覆蓋原始值
- 如果 key 不同(出現沖突),則將當前的 key-value 放入鏈表或紅黑樹種
- 獲取時,直接找到hash值對應的下標,在進一步判斷key是否相同,從而找到對應值
HashMap的jdk1.7和jdk1.8有什么區別?
- JDK1.8之前采用的是拉鏈法。拉鏈法:將鏈表和數組相結合。也就是說創建一個鏈表數組,數組中每一格就是一個鏈表。若遇到哈希沖突,則將沖突的值加到鏈表中即可
- JDK1.8在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(默認為8) 時并且數組長度達到64時,將鏈表轉化為紅黑樹,以減少搜索時間。擴容 resize( ) 時,紅黑樹拆分成的樹的結點數小于等于臨界值6個,則退化成鏈表
HashMap的put方法的具體流程
- 判斷鍵值對數組是否為空或為null,否則執行resize()進行擴容(初始化)
- 根據鍵值key計算hash值得到數組索引
- 判斷 table[i] == null,條件成立,直接新建節點添加
- 如果 table[i] == null,條件不成立:
- 判斷table[i]的首個元素是否和key一樣,如果相同直接覆蓋value
- 判斷table[i] 是否為treeNode,即table[i] 是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對
- 遍歷table[i],鏈表的尾部插入數據,然后判斷鏈表長度是否大于8,大于8的話,判斷數組長度是否大于64,如果數組長度也大于64的話把鏈表轉換為紅黑樹,在紅黑樹中執行插入操作,遍歷過程中若發現key已經存在直接覆蓋value
- 插入成功后,判斷實際存在的鍵值對數量size是否超過了最大容量 threshold (數組長度*0.75),如果超過了,進行擴容
講一講HashMap的擴容機制
-
在添加元素或初始化的時候需要調用resize方法進行擴容,第一次添加數據初始化數組長度為16,以后每次每次擴容都是達到了擴容閾值(數組長度 * 0.75)
-
每次擴容的時候,都是擴容之前容量的2倍;
-
擴容之后,會新創建一個數組,需要把老數組中的數據挪動到新的數組中
- 沒有hash沖突的節點,則直接使用 e.hash & (newCap - 1) 計算新數組的索引位置
- 如果是紅黑樹,走紅黑樹的添加
- 如果是鏈表,則需要遍歷鏈表,可能需要拆分鏈表,判斷(e.hash & oldCap)是否為0,該元素的位置要么停留在原始位置,要么移動到原始位置+增加的數組大小這個位置上
HashMap的尋址算法
- 計算對象的 hashCode()
- 再進行調用 hash() 方法進行二次哈希,hashCode值右移16為再異或運算,讓哈希分布更為均勻
- 最后(capacity - 1) & hash 得到索引
為何HashMap的數組長度一定是2的次冪?
- 計算索引時效率更高:如果是 2 的 n 次冪可以使用位與運算代替取模
- 擴容時重新計算索引效率更高: hash & oldCap == 0 的元素留在原來位置 ,否則新位置 = 舊位置 + oldCap
HashMap在1.7情況下的多線程死循環問題
在jdk1.7的hashmap中在數組進行擴容的時候,因為鏈表是頭插法,在進行數據遷移的過程中,有可能導致死循環
比如說,現在有兩個線程
線程一:讀取到當前的hashmap數據,數據中一個鏈表,在準備擴容時,線程二介入
線程二:也讀取hashmap,直接進行擴容。因為是頭插法,鏈表的順序會進行顛倒過來。比如原來的順序是AB,擴容后的順序是BA,線程二執行結束。
線程一:繼續執行的時候就會出現死循環的問題。
線程一先將A移入新的鏈表,再將B插入到鏈頭,由于另外一個線程的原因,B的next指向了A,
所以B->A->B,形成循環。
當然,JDK 8 將擴容算法做了調整,不再將元素加入鏈表頭(而是保持與擴容前一樣的順序),尾插法,就避免了jdk7中死循環的問題
HashSet與HashMap的區別
-
HashSet實現了Set接口, 僅存儲對象; HashMap實現了 Map接口, 存儲的是鍵值對
-
HashSet底層其實是用HashMap實現存儲的, HashSet封裝了一系列HashMap的方法. 依靠HashMap來存儲元素值,(利用hashMap的key鍵進行存儲), 而value值默認為Object對象. 所以HashSet也不允許出現重復值, 判斷標準和HashMap判斷標準相同, 兩個元素的hashCode相等并且通過equals()方法返回true
HashTable與HashMap的區別
主要區別:
| 區別 | HashTable | HashMap |
|---|---|---|
| 數據結構 | 數組+鏈表 | 數組+鏈表+紅黑樹 |
| 是否可以為null | Key和value都不能為null | 可以為null |
| hash算法 | key的hashCode() | 二次hash |
| 擴容方式 | 當前容量翻倍 +1 | 當前容量翻倍 |
| 線程安全 | 同步(synchronized)的,線程安全 | 非線程安全 |
在實際開中不建議使用HashTable,在多線程環境下可以使用ConcurrentHashMap類
并發編程篇
線程的基礎知識
線程和進程的區別?
Java 中,線程作為最小調度單位,進程作為資源分配的最小單位
二者對比
- 進程是正在運行程序的實例,進程中包含了線程,每個線程執行不同的任務
- 不同的進程使用不同的內存空間,在當前進程下的所有線程可以共享內存空間
- 線程更輕量,線程上下文切換成本一般上要比進程上下文切換低(上下文切換指的是從一個線程切換到另一個線程)
并行和并發有什么區別?
現在都是多核CPU,在多核CPU下
- 并發是同一時間應對多件事情的能力,多個線程輪流使用一個或多個CPU
- 并行是同一時間動手做多件事情的能力,4核CPU同時執行4個線程
創建線程的方式有哪些?
共有四種方式可以創建線程,分別是:
- 繼承Thread類
- 實現Runnable接口
- 實現Callable接口
- 線程池創建線程
runnable 和 callable 有什么區別?
- Runnable 接口run方法沒有返回值;Callable接口call方法有返回值,是個泛型,和Future、FutureTask配合可以用來獲取異步執行的結果
- Callalbe接口支持返回執行結果,需要調用FutureTask.get()得到,此方法會阻塞主進程的繼續往下執行,如果不調用不會阻塞。
- Callable接口的call()方法允許拋出異常;而Runnable接口的run()方法的異常只能在內部消化,不能繼續上拋
線程的 run()和 start()有什么區別?
-
start(): 用來啟動線程,通過該線程調用run方法執行run方法中所定義的邏輯代碼。start方法只能被調用一次
-
run(): 封裝了要被線程執行的代碼,可以被調用多次
線程包括哪些狀態,狀態之間是如何變化的?
新建(NEW)、可運行(RUNNABLE)、阻塞(BLOCKED)、等待(WAITING)、時間等待(TIMED_WALTING)、終止(TERMINATED)
- 創建線程對象是
新建狀態 - 調用了 start() 方法轉變為
可執行狀態 - 線程獲取到了CPU的執行權,執行結束是
終止狀態 - 在可執行的過程中,如果沒有獲取CPU的執行權,可能會切換其他狀態
- 如果沒有獲取鎖(synchronized 或 lock)進入
阻塞狀態,獲得鎖再切換為可執行狀態 - 如果線程調用了 wait() 方法進入
等待狀態,其它線程調用 notify() 喚醒后可切換為可執行狀態 - 如果線程調用了 sleep(50) 方法,進入
計時等待狀態,到時間后可切換為可執行狀態
- 如果沒有獲取鎖(synchronized 或 lock)進入
新建 T1、T2、T3 三個線程,如何保證它們按順序執行?
在多線程中有多種方法讓線程按特定順序執行,可以用線程類的 join()方法在一個線程中啟動另一個線程,另外一個線程完成該線程繼續執行
notify()和 notifyAll()有什么區別?
-
notifyAll:喚醒所有wait的線程
-
notify:只隨機喚醒一個 wait 線程
在 java 中 wait 和 sleep 方法的不同?
共同點
- wait() ,wait(long) 和 sleep(long) 的效果都是讓當前線程暫時放棄 CPU 的使用權,進入阻塞狀態
不同點
-
方法歸屬不同
- sleep(long) 是 Thread 的靜態方法
- 而 wait(),wait(long) 都是 Object 的成員方法,每個對象都有
-
醒來時機不同
- 執行 sleep(long) 和 wait(long) 的線程都會在等待相應毫秒后醒來
- wait(long) 和 wait() 還可以被 notify 喚醒,wait() 如果不喚醒就一直等下去
- 它們都可以被打斷喚醒
-
鎖特性不同(重點)
- wait 方法的調用必須先獲取 wait 對象的鎖,而 sleep 則無此限制
- wait 方法執行后會釋放對象鎖,允許其它線程獲得該對象鎖(我放棄 cpu,但你們還可以用)
- 而 sleep 如果在 synchronized 代碼塊中執行,并不會釋放對象鎖(我放棄 cpu,你們也用不了)
如何停止一個正在運行的線程?
有三種方式可以停止線程
- 使用退出標志,使線程正常退出,也就是當run方法完成后線程終止
- 使用stop方法強行終止(不推薦,方法已作廢)
- 使用interrupt方法中斷線程
- 打斷阻塞的線程(sleep,wait,join)的線程,線程會拋出InterruptedExcepting異常
- 打斷正常的線程,可以根據打斷狀態來標記是否退出線程
線程中并發鎖
synchronized關鍵字的底層原理
Java中的synchronized有偏向鎖、輕量級鎖、重量級鎖三種形式,分別對應了鎖只被一個線程持有、不同線程交替持有鎖、多線程競爭鎖三種情況。
| 描述 | |
|---|---|
| 重量級鎖 | 底層使用的Monitor實現,里面涉及到了用戶態和內核態的切換、進程的上下文切換,成本較高,性能比較低。 |
| 輕量級鎖 | 線程加鎖的時間是錯開的(也就是沒有競爭),可以使用輕量級鎖來優化。輕量級修改了對象頭的鎖標志,相對重量級鎖性能提升很多。每次修改都是CAS操作,保證原子性 |
| 偏向鎖 | 一段很長的時間內都只被一個線程使用鎖,可以使用了偏向鎖,在第一次獲得鎖時,會有一個CAS操作,之后該線程再獲取鎖,只需要判斷mark word中是否是自己的線程id即可,而不是開銷相對較大的CAS命令 |
什么是JMM(Java內存模型)?
- JMM(Java Memory Model)Java內存模型,定義了
共享內存中多線程程序讀寫操作的行為規范,通過這些規則來規范對內存的讀寫操作從而保證了指令的正確性 - JMM 把內存分為兩塊,一塊是私有線程的工作區域(工作內存),一塊是所有線程的共享區域(主內存)
- 線程跟線程之間相互隔離,線程跟線程交互需要通過主內存
CAS 了解嗎?
- CAS 的全稱是:Compare And Swap(比較并交換),它體現的一種樂觀鎖的思想,在無鎖狀態下保證線程操作數據的原子性
- CAS 使用到的地方很多:AQS框架、AtomicXXX原子類
- 在操作共享變量的時候使用的自旋鎖,效率上更高一些
- CAS 的底層是調用的 Unsafe 類中的方法,都是操作系統提供的,其它語言實現
樂觀鎖和悲觀鎖的區別?
- CAS 是基于樂觀鎖的思想:最樂觀的設計,不怕別的線程來修改共享變量,就算改了也沒關系,再重試下
- synchronized 是基于悲觀鎖的思想:最悲觀的估計,得防著其它線程來修改共享變量,當前線程上了鎖別的線程都別想改,等當前線程改完了釋放鎖,其它線程才有機會
volatile 有什么用?
- 保證線程間的可見性: 用 volatile 修飾共享變量,能夠防止編譯器的優化發生,讓一個線程對共享變量的修改對另一個線程可見
- 禁止進行指令重排序: 用 volatile 修飾共享變量會在讀、寫共享變量時加入不同的屏障,阻止其它讀寫操作越過屏障,從而達到阻止重排序的效果
什么是AQS?
- AQS(抽象同步隊列):是多線程中的隊列同步器。是一種鎖機制,它是做為一個
基礎框架使用的,像 ReentrantLock、Semaphore都是基于AQS實現的 - AQS內部維護了一個先進先出的雙向隊列,隊列中存儲排隊的線程
- 在AQS內部還有一個屬性state,這個state就相當于是一個資源,默認是0(無鎖狀態),如果隊列中有一個線程修改成功了state為1,則當前線程就相當于獲取了資源
- 在對state修改的時候使用了CAS操作,保證了多個線程修改情況下的原子性
ReentrantLock的實現原理
- ReentrantLock 表示支持重入鎖,調用lock方法獲取了鎖之后,再次調用 lock,是不會再阻塞
- ReentrantLock 主要利用
CAS + AQS隊列來實現 - 支持公平鎖和非公平鎖,在提供的構造器的無參默認是非公平鎖,也可以傳參設置為公平鎖
synchronized和Lock有什么區別?
- 語法層面
- synchronized 是關鍵字,源碼在 jvm 中,用 c++ 語言實現
- Lock 是接口,源碼由 jdk 提供,用 java 語言實現
- 使用 synchronized 時,退出同步代碼塊鎖會自動釋放,而使用 Lock 時,需要手動調用 unlock 方法釋放鎖
- 功能層面
- 二者均屬于悲觀鎖、都具備基本的互斥、同步、鎖重入功能
- Lock 提供了許多 synchronized 不具備的功能,例如獲取等待狀態、公平鎖、可打斷、可超時、多條件變量
- Lock 有適合不同場景的實現,如 ReentrantLock, ReentrantReadWriteLock
- 性能層面
- 在沒有競爭時,synchronized 做了很多優化,如偏向鎖、輕量級鎖,性能不賴
- 在競爭激烈時,Lock 的實現通常會提供更好的性能
死鎖產生的條件是什么?
- 互斥條件(Mutual Exclusion):資源不能被多個進程同時訪問
- 保持和等待條件(Hold and Wait):一個進程至少持有一個資源,并等待獲取一個當前被其他進程持有的資源
- 不可剝奪條件(No Preemption):資源只能由持有它的進程釋放,不能被其他進程剝奪。
- 循環等待條件(Circular Wait):存在一個等待資源的循環,即進程集合中的一組進程 {P1, P2, …, Pn},P1 等待 P2 釋放的資源,P2 等待 P3 釋放的資源,…,Pn 等待 P1 釋放的資源
如何進行死鎖診斷?
- 當程序出現了死鎖現象,我們可以使用JDK自帶的工具:jps 和 jstack
- jps:輸出JVM中運行的進程狀態信息
- jstack:查看java進程內線程的堆棧信息,查看日志,檢查是否有死鎖,如若有死鎖現象,需要查看具體代碼分析后,可修復
- 可視化工具jconsole、VisualVM也可以檢查死鎖問題
說一下ConcurrentHashMap
- 底層數據結構:
- JDK1.7底層采用 分段的數組 + 鏈表 實現
- JDK1.8采用 數組 + 鏈表/紅黑樹 實現
- 加鎖的方式:
- JDK1.7采用Segment分段鎖,底層使用的是ReentrantLockLock
- JDK1.8采用CAS添加新節點,采用synchronized鎖定鏈表/紅黑樹的首節點,相對Segment分段鎖粒度更細,性能更好
Java程序中怎么保證多線程的執行安全?
- 原子性:一個線程在CPU中操作不可暫停,也不可中斷,要不執行完成,要不不執行
- 內存可見性:讓一個線程對共享變量的修改對另一個線程可見
- 有序性:處理器為了提高程序運行效率,可能會對輸入代碼進行優化,它不保證程序中各個語句的執行先后順序同代碼中的順序一致,但是它會保證程序最終執行結果和代碼順序執行的結果是一致
線程池
說一下線程池的核心參數
- corePoolSize:核心線程數
- maximumPoolSize:最大線程數,最大線程數目 = (核心線程 + 救急線程的最大數目)
- keepAliveTime:生存時間,救急線程的生存時間,生存時間內沒有新任務,此線程資源會釋放
- unit:時間單位,救急線程的生存時間單位,如秒、毫秒等
- workQueue:阻塞隊列,當沒有空閑核心時,新來任務會加入到此隊列排隊,隊列滿了會創建救急線程執行任務
- threadFactory:線程工廠,可以指定線程對象的創建,例如設置線程名字、是否是守護線程等
- handler:拒絕策略,當所有線程都在繁忙,workQueue 也放滿時,會觸發拒絕策略
- AbortPolicy:直接拋出異常,默認策略
- CallerRunsPolicy:用調用者所在的線程來執行任務
- DiscardOldestPolicy:丟棄阻塞隊列中靠最前的任務,并執行當前任務
- DiscardPolicy:直接丟棄任務
線程池中有哪些常見的阻塞隊列?
workQueue:當沒有空閑核心線程時,新來任務會加入到此隊列排隊,隊列滿會創建救急線程執行任務
ArrayBLockingQueue:基于數組結構的有界阻塞隊列,FIFOLinkedBlockingQueue:基于鏈表結構的有界阻塞隊列,FIFO- DelayedWorkQueue:是一個優先級隊列,它可以保證每次出隊的任務都是當前隊列中執行時間最靠前的
ArrayBlockingQueue的LinkedBlockingQueue區別
| LinkedBlockingQueue | ArrayBlockingQueue |
|---|---|
| 默認無界,支持有界 | 強制有界 |
| 底層是鏈表 | 底層是數組 |
| 是懶惰的,創建節點的時候添加數據 | 提前初始化 Node 數組 |
| 入隊會生成新 Node | Node需要是提前創建好的 |
| 兩把鎖(頭尾) | 一把鎖 |
- LinkedBlockingQueue讀和寫各有一把鎖,性能相對較好
- ArrayBlockingQueue只有一把鎖,讀和寫公用,性能相對于LinkedBlockingQueue差一些
如何確定核心線程數?
- IO密集型任務:文件讀寫、DB讀寫、網絡請求等,
核心線程數大小設置為 2N+1 - CPU密集型任務:計算型代碼、BitMap轉換、Gson轉換等,
核心線程數大小設置為 N+1
線程池的種類有哪些?
在java.util.concurrent.Executors類中提供了大量創建連接池的靜態方法,常見就有四種
- 創建使用固定線程數的線程池
- 核心線程數與最大線程數一樣,沒有救急線程
- 阻塞隊列是LinkedBlockingQueue,最大容量為Integer.MAX_VALUE
- 單線程化的線程池,它只會用唯一的工作線程來執行任 務,保證所有任務按照指定順序(FIFO)執行
- 核心線程數和最大線程數都是1
- 阻塞隊列是LinkedBlockingQueue,最大容量為Integer.MAX_VALUE
- 可緩存線程池
- 核心線程數為0
- 最大線程數是Integer.MAX_VALUE
- 阻塞隊列為SynchronousQueue:不存儲元素的阻塞隊列,每個插入操作都必須等待一個移出操作
- 提供了 “延遲” 和 “周期執行” 功能的線程池
為什么不建議用Executors創建線程池?
線程池不允許使用 Executors 去創建,而是通過 ThreadPoolExecutor 的方式,這樣的處理方式讓寫的同學更加明確線程池的運行規則,規避資源耗盡的風險
Executors 返回的線程池對象的弊端如下:
- FixedThreadPoo l和 SingleThreadPool :允許的請求隊列長度為 Integer.MAX VALUE,可能會堆積大量的請求,從而導致 OOM
- CachedThreadPool:允許的創建線程數量為Integer.MAX VALUE,可能會創建大量的線程,從而導致 OOM
CountDownLatch(倒計時鎖)
CountDownLatch(倒計時鎖)用來進行線程同步協作,等待所有線程完成倒計時(一個或者多個線程,等待其他多個線程完成某件事情之后才能執行)
- 其中構造參數用來初始化等待計數值
- await() 用來等待計數歸零
- countDown() 用來讓計數減一
如何控制某個方法允許并發訪問線程的數量?
在多線程中提供了一個工具類Semaphore,信號量。在并發的情況下,可以控制方法的訪問量
- 創建Semaphore對象,可以給一個容量
- acquire() 可以請求一個信號量,這時候的信號量個數 -1
- release()釋放一個信號量,此時信號量個數 +1
談談你對ThreadLocal的理解
- ThreadLocal 可以實現 資源對象 的線程隔離,讓每個線程各用各的 資源對象,避免爭用引發的線程安全問題
- ThreadLocal 同時實現了線程內的資源共享
- 每個線程內有一個 ThreadLocalMap 類型的成員變量,用來存儲資源對象
- 調用 set 方法,就是以 ThreadLocal 自己作為 key,資源對象作為 value,放入當前線程的 ThreadLocalMap 集合中
- 調用 get 方法,就是以 ThreadLocal 自己作為 key,當前線程中查找關聯的資源值
- 調用 remove 方法,就是以 ThreadLocal 自己作為 key,移除當前線程關聯的資源值
ThreadLocal內存泄漏問題
- ThreadLocalMap 中的 key 是弱引用,值為強引用
- key 會被GC釋放內存,關聯 value 的內存并不會釋放
- 建議主動 remove 釋放 key,value
JVM虛擬機篇
JVM由那些部分組成?
- 類加載器
- Java堆
- 方法區
- 虛擬機棧
- 本地方法棧
- 程序計數器
- 執行引擎
什么是程序計數器?
線程私有的,每個線程一份,內部保存字節碼的行號。用于記錄正在執行的字節碼指令地址
什么是Java堆?
線程共享的區域:主要用來保存對象實例,數組等,內存不夠則拋出OutOfMemoryError異常- 組成:
新生代+ 老年代新生代被劃分為三部分,伊甸區和兩個大小嚴格相同的幸存者區老年代主要保存生命周期長的對象,一般是一些老的對象
- JDK 1.7 和 1.8 的區別:
- 1.7 中有一個永久代,存儲的是類信息、靜態變量、常量、編譯后的代碼
- 1.8 移除了永久代,把數據存儲到了本地內存的元空間中,防止內存溢出
什么是虛擬機棧?
- 每個線程運行時所需要的內存,稱為虛擬機棧
- 每個棧由多個棧幀(frame)組成,對應著每次方法調用時所占用的內存
- 每個線程只能有一個活動棧幀,對應著當前執行的那個方法
垃圾回收是否涉及棧內存?
垃圾回收主要是回收堆內存,當棧幀彈棧以后,內存就會釋放
棧內存分配越大越好嗎?
未必,默認的棧內存統稱為 1024K,棧內存過大會導致線程數變少
方法內的局部變量是否線程安全?
- 如果方法內局部變量沒有逃離方法的作用范圍,它是線程安全的
- 如果是局部變量引用了對象,并逃離方法的作用范圍,需要考慮線程安全
什么情況下會導致棧內存溢出?
- 棧幀過多導致棧內存溢出,典型問題:遞歸調用
- 棧幀過大導致棧內存溢出
堆棧的區別是什么?
- 棧內存一般會用來存儲局部變量和方法調用,但堆內存是用來存儲Java對象和數組的。堆會被GC垃圾回收,而棧不會
- 棧內存是線程私有的,而堆內存是線程共有的
- 兩者異常錯誤不同,但如果棧內存或者堆內存不足都會拋出異常
- 棧空間不足:java.lang.StackOverFlowError
- 堆空間不足:java.lang.OutOfMemoryError
什么是方法區?
- 方法區(Method Area)是各個線程
共享的內存區域 - 主要存儲類的信息,運行時常量池
- 虛擬機啟動的時候創建,關閉虛擬機時釋放
- 如果方法區域中的內存無法滿足分配請求,則會拋出OutOfMemoryError:Metaspace
什么是運行時常量池?
- 常量池:可以看作是一張表,虛擬機指令根據這張常量表找到要執行的類名、方法名、參數類型、字面量等信息
- 當類被加載,它的常量池信息就會
放入運行時常量池,并把里面的符號地址變為真實地址
什么是直接內存?
- 并不屬于JVM中的內存結構,不由JVM進行管理。是虛擬機的系統內存
- 常見于 NIO 操作時,用于數據緩沖區,分配回收成本較高,但讀寫性能高,不受 JVM 內存回收管理
什么是類加載器?
JVM只會運行二進制文件,類加載器的作用就是將 字節碼文件加載到JVM中 ,從而讓Java程序能夠啟動起來
類加載器有哪些?
- 啟動類加載器(BootStrap ClassLoader):加載 JAVA_HOME/jre/lib 目錄下的庫
- 擴展類加載器(ExtClassLoader):主要加載 JAVA_HOME/jre/lib/ext 目錄下的類
- 應用類加載器(APPClassLoader):用于加載 classPath 下的類
- 自定義類加載器(CustomizeClassLoader):自定義類繼承ClassLoader,實現自定義類加載規則
什么是雙親委派模型?
加載某一個類,先委托上一級的加載器進行加載,如果上級加載器也有上級,則會繼續向上委托,如果該類委托上級沒有被加載,子加載器嘗試加載該類
JVM為什么采用雙親委派機制?
- 通過雙親委派機制可以避免某一個類被重復加載,當父類已經加載后則無需重復加載,保證唯一性
- 為了安全,保證類庫API不會被修改
類裝載的執行過程?
- 加載:查找和導入class文件
- 驗證:保證加載類的準確性
- 準備:為類變量分配內存并設置類變量初始值
- 解析:把類中的符號引用轉換為直接引用
- 初始化:對類的靜態變量,靜態代碼塊執行初始化
- 使用:JVM 開始從入口方法開始執行用戶的程序代碼
- 卸載:當用戶程序代碼執行完畢后,JVM 便開始銷毀創建的Class對象
對象什么時候可以被垃圾器回收?
如果一個或多個對象沒有任何的引用指向它了,那么這個對象現在就是垃圾,如果定位了垃圾,則有可能會被垃圾回收器回收
定位垃圾的方式有兩種:
- 引用計數法
- 可達性分析算法
JVM 垃圾回收算法有哪些?
標記清除算法:垃圾回收分為2個階段,分別是標記和清除,效率高,有磁盤碎片,內存不連續標記整理算法:將存活對象都向內存一端移動,然后清理邊界以為的垃圾,無碎片,對象需要移動,效率低復制算法:將原有的內存空間一分為二,每次只用其中的一塊,正在使用的對象復制到另一個內存空間中,然后將該內存空間清空,交換兩個內存的角色,完成垃圾的回收,無碎片,內存使用率低
什么是JVM中的分代回收?
- 堆的區域劃分
- 堆被分為了兩份:新生代和老年代 [ 1 : 2 ]
- 對于新生代,內部又被分為了三個區域。伊甸區,幸存者區(分為 from 和 to)
- 對象分代回收策略
- 新創建的對象,都會先分配到伊甸區
- 當伊甸區內存不足,標記伊甸區與 from(現階段沒有)的存活對象
- 將存活對象采用復制算法復制到 to 中,復制完畢后,伊甸區 和 from 內存得到釋放
- 經過一段時間后伊甸區的內存又出現不足,標記伊甸區 to 區存活的對象,將其復制到 from 區
- 當幸存區對象熬過幾次回收(最多15次),晉升到老年代(幸存區內存不足或大對象會提前晉升)
MinorGC、MixedGC、FullGC的區別是什么?
- MinorGC(young GC):發生在新生代的垃圾回收,暫停時間短(STW)
- MixedGC:新生代 + 老年代 部分區域的垃圾回收,G1收集器持有
- FullGC: 新生代 + 老年代 完整垃圾回收,暫停時間長(STW),應盡力避免
說一下JVM有哪些垃圾回收器?
- 串行垃圾回收器:Serial GC、Serial Old GC
- 并行垃圾回收器:Parallel Old GC、ParNew GC
- CMS(并發)垃圾回收器:CMS GC,作用在老年代
- G1垃圾回收器:作用在新生代和老年代
G1垃圾回收器知道嗎?
- 應用于新生代和老年代
- 劃分成多個區域,每個區域都可以充當 eden,survivor,humongous,其中 humongous 專為大對象準備
- 采用復制算法
- 響應時間與吞吐量兼顧
- 分成三個階段:新生代回收(STW),并發標記(重新標記STW),混合回收
- 如果并發失敗(即回收速度趕不上創建新對象的速度),會觸發 Full GC
強引用、軟引用、弱引用、虛引用的區別?
- 強引用:只有所有 GC Roots 對象都不通過強引用引用該對象,該對象才能被垃圾回收
- 軟引用:僅有軟引用引用該對象時,在垃圾回收后,內存仍不足時會再次出發垃圾回收
- 弱引用:僅有弱引用引用該對象時,在垃圾回收時,無論內存是否充足,都會回收弱引用對象
- 虛引用:必須配合引用隊列使用,被引用對象回收時,會將虛引用入隊,由 Reference Handler 線程調用虛引用相關方法釋放直接內存
JVM 調優的參數可以在哪里設置參數值?
- war 包部署在 tomcat 中設置: 修改
TOMCAT_HOME/bin/catalina.sh文件 - jar 包部署在啟動參數設置: java
-Xms512m -Xmx1024m-jar xxx.jar
JVM 調優的參數都有哪些?
- 設置堆空間大小
- 虛擬機棧的設置
- 設置垃圾回收器
- 年輕代中伊甸區和兩個幸存者區的大小比例
- 年輕代晉升老年代的閾值
JVM 調優工具有哪些?
命令工具:
- jps:進程狀態信息
- jstack:查看 java 進程內線程的堆棧信息
- jmap:查看堆信息
- jhat:堆轉儲快照分析工具
- jstat:JVM 統計監測工具
可視化工具:
- jconsole:用于對 jvm 的內存、線程、類 的監控
- VisualVM:能夠監控線程,內存情況
Java 內存泄漏怎么排查?
內存泄漏通常是指堆內存,通常是指一些大對象不被回收的情況
- 通過 jmap 或設置 jvm 參數獲取堆內存快照 dump
- 通過工具,VisualVM 去分析 dump 文件,VisualVM 可以加載離線的 dump 文件
- 通過查看堆信息的情況,可以大概定位內存溢出是哪行代碼儲了問題
- 找到對應的代碼,通過閱讀上下文的情況,進行修復即可
CPU飆高怎么排查?
- 使用 top 命令查看 CPU 占用情況
- 通過 top 命令查看后,可以查看是哪一個進程 CPU 占用較高
- 使用 ps 命令查看進程中的線程信息
- 使用 jstack 命令查看進程中哪些線程出現了問題,最終定位問題
- OOM問題排查)








: 依賴管理與版本控制)








)
