經典的卷積神經網絡模型 - ResNet
flyfish
2015年,何愷明(Kaiming He)等人在論文《Deep Residual Learning for Image Recognition》中提出了ResNet(Residual Network,殘差網絡)。在當時,隨著深度神經網絡層數的增加,訓練變得越來越困難,主要問題是梯度消失和梯度爆炸現象。即使使用各種優化技術和正則化方法,深層網絡的表現仍然不如淺層網絡。ResNet通過引入殘差塊(Residual Block)有效解決了這個問題,使得網絡層數可以大幅度增加,同時還能顯著提升模型的表現。
經典的卷積神經網絡模型 - AlexNet
經典的卷積神經網絡模型 - VGGNet
卷積層的輸出
1x1卷積的作用
2. 殘差(Residual)
在ResNet中,殘差指的是輸入值與輸出值之間的差值。具體來說,假設輸入為 x x x,經過一系列變換后的輸出為 F ( x ) F(x) F(x),ResNet引入了一條“快捷連接”(shortcut connection),直接將輸入 x x x加入到輸出 F ( x ) F(x) F(x),最終的輸出為 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x。這種結構稱為殘差塊(Residual Block)。
3. ResNet的不同版本
ResNet有多個不同版本,后面的數字表示網絡層的數量。具體來說:
- ResNet18: 18層
- ResNet34: 34層
- ResNet50: 50層
- ResNet101: 101層
- ResNet152: 152層
4. 常規殘差模塊
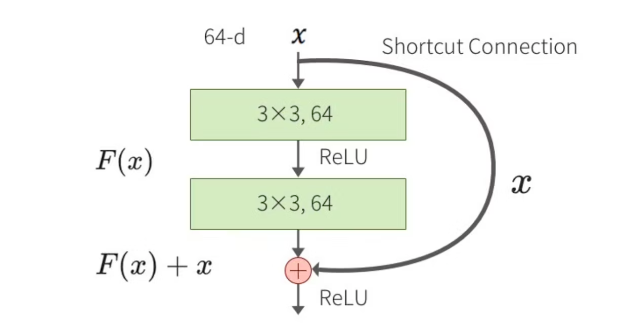
常規殘差模塊(Residual Block)包含兩個3x3卷積層,每個卷積層后面跟著批歸一化(Batch Normalization)和ReLU激活函數。假設輸入為 x x x,經過第一層卷積、批歸一化和ReLU后的輸出為 F 1 ( x ) F_1(x) F1?(x),再經過第二層卷積、批歸一化后的輸出為 F 2 ( F 1 ( x ) ) F_2(F_1(x)) F2?(F1?(x))。最終的輸出是輸入 x x x和 F 2 ( F 1 ( x ) ) F_2(F_1(x)) F2?(F1?(x))的和,即 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x。
ResNet-18和ResNet-34使用的是BasicBlock。
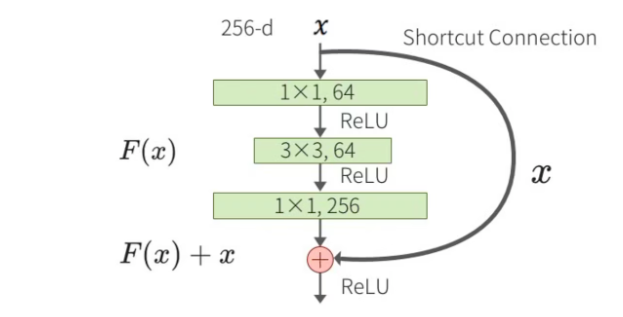
5. 瓶頸殘差模塊(Bottleneck Residual Block)
瓶頸殘差模塊用于更深的ResNet版本(如ResNet50及以上),目的是減少計算量和參數量。瓶頸殘差模塊包含三個卷積層:一個1x1卷積層用于降維,一個3x3卷積層用于特征提取,最后一個1x1卷積層用于升維。假設輸入為 x x x,經過1x1卷積降維后的輸出為 F 1 ( x ) F_1(x) F1?(x),再經過3x3卷積后的輸出為 F 2 ( F 1 ( x ) ) F_2(F_1(x)) F2?(F1?(x)),最后經過1x1卷積升維后的輸出為 F 3 ( F 2 ( F 1 ( x ) ) ) F_3(F_2(F_1(x))) F3?(F2?(F1?(x)))。最終的輸出是輸入 x x x和 F 3 ( F 2 ( F 1 ( x ) ) ) F_3(F_2(F_1(x))) F3?(F2?(F1?(x)))的和,即 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x。ResNet-50、ResNet-101和ResNet-152使用的是Bottleneck。
6. 快捷連接(shortcut connection )
快捷連接(shortcut connection),即直接將輸入 x x x加到輸出 F ( x ) F(x) F(x)上,從而避免了梯度消失和梯度爆炸問題。
import torchvision.models as models
resnet18 = models.resnet18()
print(resnet18)
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer2): Sequential((0): BasicBlock((conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer3): Sequential((0): BasicBlock((conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer4): Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(fc): Linear(in_features=512, out_features=1000, bias=True)
)
自定義實現ResNet-18
import torch
import torch.nn as nn
import torch.nn.functional as Fclass BasicBlock(nn.Module):expansion = 1def __init__(self, in_channels, out_channels, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential()if stride != 1 or in_channels != self.expansion * out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion * out_channels))def forward(self, x):out = self.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)out = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=1000):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, out_channels, num_blocks, stride):layers = []layers.append(block(self.in_channels, out_channels, stride))self.in_channels = out_channels * block.expansionfor _ in range(1, num_blocks):layers.append(block(self.in_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.relu(self.bn1(self.conv1(x)))x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef resnet18(num_classes=1000):return ResNet(BasicBlock, [2, 2, 2, 2], num_classes)# Example usage
model = resnet18()
print(model)
自定義實現ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152
ResNet-18和ResNet-34使用的是BasicBlock,而ResNet-50、ResNet-101和ResNet-152使用的是Bottleneck。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass BasicBlock(nn.Module):expansion = 1def __init__(self, in_channels, out_channels, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential()if stride != 1 or in_channels != self.expansion * out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion * out_channels))def forward(self, x):out = self.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)out = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, in_channels, out_channels, stride=1):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)self.relu = nn.ReLU(inplace=True)self.shortcut = nn.Sequential()if stride != 1 or in_channels != out_channels * self.expansion:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels * self.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels * self.expansion))def forward(self, x):out = self.relu(self.bn1(self.conv1(x)))out = self.relu(self.bn2(self.conv2(out)))out = self.bn3(self.conv3(out))out += self.shortcut(x)out = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=1000):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, out_channels, num_blocks, stride):layers = []layers.append(block(self.in_channels, out_channels, stride))self.in_channels = out_channels * block.expansionfor _ in range(1, num_blocks):layers.append(block(self.in_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.relu(self.bn1(self.conv1(x)))x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef resnet18(num_classes=1000):return ResNet(BasicBlock, [2, 2, 2, 2], num_classes)def resnet34(num_classes=1000):return ResNet(BasicBlock, [3, 4, 6, 3], num_classes)def resnet50(num_classes=1000):return ResNet(Bottleneck, [3, 4, 6, 3], num_classes)def resnet101(num_classes=1000):return ResNet(Bottleneck, [3, 4, 23, 3], num_classes)def resnet152(num_classes=1000):return ResNet(Bottleneck, [3, 8, 36, 3], num_classes)# Example usage
model_18 = resnet18()
model_34 = resnet34()
model_50 = resnet50()
model_101 = resnet101()
model_152 = resnet152()print(model_18)
print(model_34)
print(model_50)
print(model_101)
print(model_152)
網絡結構
以ResNet18和ResNet50的結構舉例
因為ResNet-18和ResNet-34使用的是BasicBlock,ResNet-50、ResNet-101和ResNet-152使用的是Bottleneck,可以區分看。
ResNet18
-
輸入:224x224圖像
-
卷積層:7x7卷積,64個過濾器,步長2
-
最大池化層:3x3,步長2
-
殘差模塊:
-
2個Basic Block,每個包含2個3x3卷積層(64個過濾器)
-
2個Basic Block,每個包含2個3x3卷積層(128個過濾器)
-
2個Basic Block,每個包含2個3x3卷積層(256個過濾器)
-
2個Basic Block,每個包含2個3x3卷積層(512個過濾器)
-
-
全局平均池化層
-
全連接層:1000個單元(對應ImageNet的1000個類別)
用參數表示就是 [2, 2, 2, 2]
ResNet50
-
輸入:224x224圖像
-
卷積層:7x7卷積,64個過濾器,步長2
-
最大池化層:3x3,步長2
-
殘差模塊:
-
3個Bottleneck Block,每個包含1x1降維、3x3卷積、1x1升維(256個過濾器)
-
4個Bottleneck Block,每個包含1x1降維、3x3卷積、1x1升維(512個過濾器)
-
6個Bottleneck Block,每個包含1x1降維、3x3卷積、1x1升維(1024個過濾器)
-
3個Bottleneck Block,每個包含1x1降維、3x3卷積、1x1升維(2048個過濾器)
-
-
全局平均池化層
-
全連接層:1000個單元(對應ImageNet的1000個類別)
用參數表示就是 [3, 4, 6, 3]
列表參數表示每個階段(layer)中包含的殘差塊(residual block)的數量。ResNet的網絡結構通常分為多個階段,每個階段包含多個殘差塊。這些殘差塊可以是常規的(BasicBlock)或瓶頸的(Bottleneck)。具體來說:
[2, 2, 2, 2] 表示第1個階段有2個殘差塊,第2個階段有2個殘差塊,第3個階段有2個殘差塊,第4個階段有2個殘差塊。
[3, 4, 6, 3] 表示第1個階段有3個殘差塊,第2個階段有4個殘差塊,第3個階段有6個殘差塊,第4個階段有3個殘差塊。
BasicBlock: 實現了常規殘差模塊,包含兩個3x3的卷積層。用于ResNet-18和ResNet-34。
Bottleneck: 實現了瓶頸殘差模塊,包含一個1x1卷積層、一個3x3卷積層和另一個1x1卷積層。用于ResNet-50、ResNet-101和ResNet-152。
identity shortcut和projection shortcut
import torchvision.models as models
model = models.resnet50()
print(model)
完整內容自行打印看,這里主要說明 identity shortcut和projection shortcut
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))......
在 ResNet 中,identity shortcut 和 projection shortcut 主要出現在 Bottleneck 模塊中。
- Identity Shortcut : 這是直接跳過層的快捷方式,輸入直接添加到輸出。通常在輸入和輸出維度相同時使用。在模型輸出中可以看到,如
layer1的第1和第2個Bottleneck:
(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)
)
可以看到這里沒有 downsample 層,所以輸入和輸出直接相加。
- Projection Shortcut : 這是使用卷積層調整維度的快捷方式,用于當輸入和輸出維度不同時。在模型輸出中可以看到,如
layer1的第0個Bottleneck:
(0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))
)
這里有一個 downsample 層,通過卷積和批量歸一化調整輸入的維度以匹配輸出。
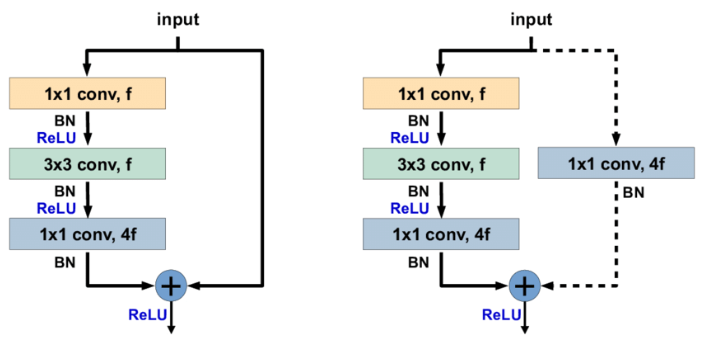
-
Identity Shortcut : 左側圖,沒有
downsample層。如果要寫上downsample也是(downsample): Sequential()括號里是空的 -
Projection Shortcut :右側圖 有
downsample層,用于調整維度。 比如
(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))
Bottleneck 結構中,f 通常表示瓶頸層的過濾器(或通道)數。
在 Bottleneck 模塊中,通常有三層卷積:
第一個 1x1 卷積,用于降低維度,通道數是 f。
第二個 3x3 卷積,用于在降低維度的情況下進行卷積操作,通道數也是 f。
第三個 1x1 卷積,用于恢復維度,通道數是 4f。
如果要保證輸出的特征圖大小是固定的(如 1x1),自適應平均池化或者全局平均池化是最常用的選擇;如果要調整通道數并保持空間結構,則可以用 1x1 卷積和池化的組合。
無論輸入的特征圖大小是多少,自適應平均池化都可以將其調整到一個指定的輸出大小。在 ResNet 中使用的 AdaptiveAvgPool2d(output_size=(1, 1)) 會將輸入的特征圖調整到大小為 1x1。通過將特征圖大小固定,可以更容易地設計網絡結構,尤其是全連接層的輸入部分。例如,將特征圖調整到 1x1 后,后面的全連接層只需要處理固定數量的特征,不用考慮輸入圖像的大小變化。在特征圖被調整到較小的大小(例如 1x1)后,隨后的全連接層所需的參數和計算量會顯著減少。


)







職業技能競賽樣題)


Linux下yum源配置實戰)




)
