非極大值抑制(Non-Maximum Suppression,簡稱NMS)是一種在計算機視覺中廣泛應用的算法,主要用于消除冗余和重疊的邊界框。在目標檢測任務中,尤其是在使用諸如R-CNN系列的算法時,會產生大量的候選區域,而這些區域可能存在大量的重疊。為了解決這個問題,使用NMS算法來保留最有可能的區域,同時抑制其他冗余或重疊的區域。
1. NMS在目標檢測領域的應用
非極大值抑制在目標檢測領域的基本原理和步驟如下:
- 對于每個類別,按照預測框的置信度進行排序,將置信度最高的預測框作為基準。
- 從剩余的預測框中選擇一個與基準框的重疊面積最大的框,如果其重疊面積大于一定的閾值,則將其刪除。
- 對于剩余的預測框,重復步驟2,直到所有的重疊面積都小于閾值,或者沒有被刪除的框剩余為止。
通過這樣的方式,NMS可以過濾掉所有與基準框重疊面積大于閾值的冗余框,從而實現檢測結果的優化。值得注意的是,NMS的閾值通常需要根據具體的數據集和應用場景進行調整,以兼顧準確性和召回率。
# NMS Python 簡單實現
import numpy as npdef nms(dets, thresh):x1 = dets[:, 0]y1 = dets[:, 1]x2 = dets[:, 2]y2 = dets[:, 3]scores = dets[:, 4]areas = (x2 - x1 + 1) * (y2 - y1 + 1)order = scores.argsort()[::-1]keep = []while order.size > 0:i = order[0]keep.append(i)xx1 = np.maximum(x1[i], x1[order[1:]])yy1 = np.maximum(y1[i], y1[order[1:]])xx2 = np.minimum(x2[i], x2[order[1:]])yy2 = np.minimum(y2[i], y2[order[1:]])w = np.maximum(0.0, xx2 - xx1 + 1)h = np.maximum(0.0, yy2 - yy1 + 1)inter = w * hovr = inter / (areas[i] + areas[order[1:]] - inter)inds = np.where(ovr <= thresh)[0]order = order[inds + 1]return keep
這段代碼首先計算所有候選框的面積和分數,然后按照分數對候選框進行排序。然后,它進入一個循環,每次循環中,它都會選擇當前分數最高的框,并將其添加到保留列表中。然后,它會計算這個框與其他所有框的重疊區域,并計算這些重疊區域與各自框的面積之比(即IoU)。如果這個比值大于給定的閾值,那么就會將對應的框從候選列表中刪除。這個過程會一直重復,直到所有的框都被處理完畢。
2. NMS在軌跡預測領域的應用
NMS在軌跡預測中的應用,主要是用來處理預測結果中的冗余和重疊的軌跡,對于一些方法,模型預測出大量的候選軌跡,這些軌跡可能存在大量的重疊。為了解決這個問題,可以使用上述NMS算法來保留最有可能的軌跡,同時抑制其他冗余或重疊的軌跡。
假設對某個場景中的某輛車使用模型預測了64條或更多的軌跡,以很好地捕獲多模態性,同時每條軌跡對應一個置信度,所有軌跡置信度總和為1。但最終輸出時,我們一般僅輸出6條軌跡(下游 or 打榜需求),如果直接選擇置信度最高的6條軌跡會存在問題,比如說這六條軌跡靠的很近,無法體現多模態性。因此,我們需要使用NMS來選擇最終的軌跡:
- 將軌跡按照置信度從高到低排序。
- 計算每兩條軌跡之間最后一個點的距離,會產生一個距離矩陣。
- 依次按照置信度高低選取軌跡,比如第一次選擇排名第一的軌跡,后面再選擇軌跡時需要跟已經選擇的所有判斷距離是否大于某個閾值,如果小于該閾值,說明存在已選的軌跡與當前要被選擇的軌跡很類似,則放棄選擇該軌跡。
這樣,通過NMS,我們可以從大量的預測軌跡中選擇出最具代表性的軌跡,從而提高軌跡預測的效果。
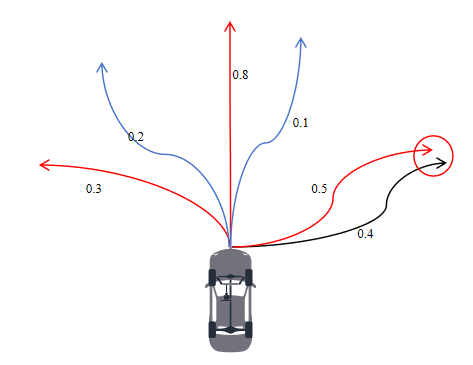
從圖中6條軌跡中選擇出3條,如果按照置信度來選,應該選擇0.8,0.5,0.4的軌跡,但由于0.5和0.4兩條軌跡靠的太近(小于某個閾值)因此最終選擇的軌跡為0.8,0.5,0.3三條軌跡。
def batch_nms(pred_trajs, pred_scores, dist_thresh, num_ret_modes=6):"""Args:pred_trajs (batch_size, num_modes, num_timestamps, 7)pred_scores (batch_size, num_modes):dist_thresh (float):num_ret_modes (int, optional): Defaults to 6.Returns:ret_trajs (batch_size, num_ret_modes, num_timestamps, 5)ret_scores (batch_size, num_ret_modes)ret_idxs (batch_size, num_ret_modes)"""batch_size, num_modes, num_timestamps, num_feat_dim = pred_trajs.shapesorted_idxs = pred_scores.argsort(dim=-1, descending=True)bs_idxs_full = torch.arange(batch_size).type_as(sorted_idxs)[:, None].repeat(1, num_modes)sorted_pred_scores = pred_scores[bs_idxs_full, sorted_idxs] # 對score從大到小排序sorted_pred_trajs = pred_trajs[bs_idxs_full, sorted_idxs] # (batch_size, num_modes, num_timestamps, 7)sorted_pred_goals = sorted_pred_trajs[:, :, -1, :] # (batch_size, num_modes, 7) 最后一個點dist = (sorted_pred_goals[:, :, None, 0:2] - sorted_pred_goals[:, None, :, 0:2]).norm(dim=-1) # 64*64 的距離矩陣point_cover_mask = (dist < dist_thresh)point_val = sorted_pred_scores.clone() # (batch_size, N)point_val_selected = torch.zeros_like(point_val) # (batch_size, N)ret_idxs = sorted_idxs.new_zeros(batch_size, num_ret_modes).long()ret_trajs = sorted_pred_trajs.new_zeros(batch_size, num_ret_modes, num_timestamps, num_feat_dim)ret_scores = sorted_pred_trajs.new_zeros(batch_size, num_ret_modes)bs_idxs = torch.arange(batch_size).type_as(ret_idxs)for k in range(num_ret_modes):cur_idx = point_val.argmax(dim=-1) # (batch_size)ret_idxs[:, k] = cur_idxnew_cover_mask = point_cover_mask[bs_idxs, cur_idx] # (batch_size, N)point_val = point_val * (~new_cover_mask).float() # (batch_size, N)point_val_selected[bs_idxs, cur_idx] = -1point_val += point_val_selectedret_trajs[:, k] = sorted_pred_trajs[bs_idxs, cur_idx]ret_scores[:, k] = sorted_pred_scores[bs_idxs, cur_idx]bs_idxs = torch.arange(batch_size).type_as(sorted_idxs)[:, None].repeat(1, num_ret_modes)ret_idxs = sorted_idxs[bs_idxs, ret_idxs]return ret_trajs, ret_scores, ret_idxs

)








GPS/指南針(一))

![[Labview] 改寫表格內容并儲存覆蓋Excel](http://pic.xiahunao.cn/[Labview] 改寫表格內容并儲存覆蓋Excel)
![[21] Opencv_CUDA應用之使用Haar級聯的對象檢測](http://pic.xiahunao.cn/[21] Opencv_CUDA應用之使用Haar級聯的對象檢測)





