《昇思25天學習打卡營第8天|CarpeDiem》
- 模型訓練
- 構建數據集
- 定義神經網絡模型
- 定義超參、損失函數和優化器
- 超參
- 損失函數
- 優化器
- 訓練與評估
打卡
今天是昇思25天學習打卡營的第8天,終于迎來 模型訓練 的部分了!!!
興奮 發癲
模型訓練
模型訓練一般分為四個步驟:
- 構建數據集。
- 定義神經網絡模型。
- 定義超參、損失函數及優化器。
- 輸入數據集進行訓練與評估。
現在我們有了數據集和模型后,可以進行模型的訓練與評估。
評估的時候也可以采用第二天的方式 創建一個 loss_history 的數組 將每次的loss值計算出來存進去,然后借助 matplotlab 模塊將loss數據可視化展示,這樣可以更加直觀的感受到模型訓練的過程和結果的好壞
構建數據集
首先從數據集 Dataset加載代碼,構建數據集。
老生常談,沒什么好說的了
不會就***給我去前面的篇章看
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset# Download data from open datasets
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)def datapipe(path, batch_size):image_transforms = [vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]label_transform = transforms.TypeCast(mindspore.int32)dataset = MnistDataset(path)dataset = dataset.map(image_transforms, 'image')dataset = dataset.map(label_transform, 'label')dataset = dataset.batch(batch_size)return datasettrain_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)

定義神經網絡模型
從網絡構建中加載代碼,構建一個神經網絡模型。
不會就***給我去前面的篇章看
不好意思這個沒單獨講過
class Network(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.dense_relu_sequential = nn.SequentialCell(nn.Dense(28*28, 512),nn.ReLU(),nn.Dense(512, 512),nn.ReLU(),nn.Dense(512, 10))def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logitsclass Network_new(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.dense_relu_sequential = nn.SequentialCell(nn.Dense(28*28, 512),nn.ReLU(),nn.Dense(512, 1024),nn.ReLU(),nn.Dense(1024, 512),nn.ReLU(),nn.Dense(512, 128),nn.ReLU(),nn.Dense(128, 10),)def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logitsmodel = Network()
model_new = Network_new()
這里的神經網絡模型和第二天的神經網絡模型是一模一樣的
都是將 28*28 的圖片先線性變換為 512 再線性變化成 512 再線性變化成 10 得到 10 個類別的特征值
Network_new 是創建的一個新的模型 測試一下多添加一些新的網絡層后 其訓練結果是怎么樣變換的
采用 28*28 -> 512 -> 1024 -> 512 -> 128 -> 10 的形式
可以發現多添加了兩層分別為 1024 和 128 個神經元
定義超參、損失函數和優化器
超參
超參(Hyperparameters)是可以調整的參數,可以控制模型訓練優化的過程,不同的超參數值可能會影響模型訓練和收斂速度。目前深度學習模型多采用批量隨機梯度下降算法進行優化,隨機梯度下降算法的原理如下:
w t + 1 = w t ? η 1 n ∑ x ∈ B ? l ( x , w t ) w_{t+1}=w_{t}-\eta \frac{1}{n} \sum_{x \in \mathcal{B}} \nabla l\left(x, w_{t}\right) wt+1?=wt??ηn1?x∈B∑??l(x,wt?)
公式中, n n n是批量大小(batch size), η η η是學習率(learning rate)。另外, w t w_{t} wt?為訓練輪次 t t t中的權重參數, ? l \nabla l ?l為損失函數的導數。除了梯度本身,這兩個因子直接決定了模型的權重更新,從優化本身來看,它們是影響模型性能收斂最重要的參數。一般會定義以下超參用于訓練:
-
訓練輪次(epoch):訓練時遍歷數據集的次數。
-
批次大小(batch size):數據集進行分批讀取訓練,設定每個批次數據的大小。batch size過小,花費時間多,同時梯度震蕩嚴重,不利于收斂;batch size過大,不同batch的梯度方向沒有任何變化,容易陷入局部極小值,因此需要選擇合適的batch size,可以有效提高模型精度、全局收斂。
-
學習率(learning rate):如果學習率偏小,會導致收斂的速度變慢,如果學習率偏大,則可能會導致訓練不收斂等不可預測的結果。梯度下降法被廣泛應用在最小化模型誤差的參數優化算法上。梯度下降法通過多次迭代,并在每一步中最小化損失函數來預估模型的參數。學習率就是在迭代過程中,會控制模型的學習進度。
epochs = 3
batch_size = 64
learning_rate = 1e-2
損失函數
損失函數(loss function)用于評估模型的預測值(logits)和目標值(targets)之間的誤差。訓練模型時,隨機初始化的神經網絡模型開始時會預測出錯誤的結果。損失函數會評估預測結果與目標值的相異程度,模型訓練的目標即為降低損失函數求得的誤差。
常見的損失函數包括用于回歸任務的nn.MSELoss(均方誤差)和用于分類的nn.NLLLoss(負對數似然)等。 nn.CrossEntropyLoss 結合了nn.LogSoftmax和nn.NLLLoss,可以對logits 進行歸一化并計算預測誤差。
loss_fn = nn.CrossEntropyLoss()
loss_fn_new = nn.CrossEntropyLoss()
優化器
模型優化(Optimization)是在每個訓練步驟中調整模型參數以減少模型誤差的過程。MindSpore提供多種優化算法的實現,稱之為優化器(Optimizer)。優化器內部定義了模型的參數優化過程(即梯度如何更新至模型參數),所有優化邏輯都封裝在優化器對象中。在這里,我們使用SGD(Stochastic Gradient Descent)優化器。
我們通過model.trainable_params()方法獲得模型的可訓練參數,并傳入學習率超參來初始化優化器。
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
optimizer_new = nn.SGD(model_new.trainable_params(), learning_rate=learning_rate)
在訓練過程中,通過微分函數可計算獲得參數對應的梯度,將其傳入優化器中即可實現參數優化,具體形態如下:
grads = grad_fn(inputs)
optimizer(grads)
訓練與評估
設置了超參、損失函數和優化器后,我們就可以循環輸入數據來訓練模型。一次數據集的完整迭代循環稱為一輪(epoch)。每輪執行訓練時包括兩個步驟:
- 訓練:迭代訓練數據集,并嘗試收斂到最佳參數。
- 驗證/測試:迭代測試數據集,以檢查模型性能是否提升。
接下來我們定義用于訓練的train_loop函數和用于測試的test_loop函數。
使用函數式自動微分,需先定義正向函數forward_fn,使用value_and_grad獲得微分函數grad_fn。然后,我們將微分函數和優化器的執行封裝為train_step函數,接下來循環迭代數據集進行訓練即可。
# Define forward function
def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return loss, logitsdef forward_fn_new(data, label):logits = model(data)loss = loss_fn_new(logits, label)return loss, logits# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
grad_fn_new = mindspore.value_and_grad(forward_fn_new, None, optimizer_new.parameters, has_aux=True)# Define function of one-step training
def train_step(data, label):(loss, _), grads = grad_fn(data, label)optimizer(grads)return lossdef train_step_new(data, label):(loss, _), grads = grad_fn_new(data, label)optimizer_new(grads)return loss# 相較第二天的新加入了一個參數 loss_history 使得可以記錄歷史 loss 值
def train_loop(model, dataset,loss_history):size = dataset.get_dataset_size()model.set_train()for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):loss = train_step(data, label)# 添加損失到 loss_historyloss_history.append(loss)if batch % 100 == 0:loss, current = loss.asnumpy(), batch# # 添加損失到 loss_history# loss_history.append(loss)print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")test_loop函數同樣需循環遍歷數據集,調用模型計算loss和Accuray并返回最終結果。
def test_loop(model, dataset, loss_fn):num_batches = dataset.get_dataset_size()model.set_train(False)total, test_loss, correct = 0, 0, 0for data, label in dataset.create_tuple_iterator():pred = model(data)total += len(data)test_loss += loss_fn(pred, label).asnumpy()correct += (pred.argmax(1) == label).asnumpy().sum()test_loss /= num_batchescorrect /= totalprint(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")我們將實例化的損失函數和優化器傳入train_loop和test_loop中。訓練3輪并輸出loss和Accuracy,查看性能變化。
# use a loss_history array to save losses for visual display
# 用一個 loss_history 數組去存儲所有的損失值 loss 以便進行可視化展示
loss_history = []
loss_history_new = []loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)loss_fn_new = nn.CrossEntropyLoss()
optimizer_new = nn.SGD(model_new.trainable_params(), learning_rate=learning_rate)for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(model, train_dataset, loss_history)test_loop(model, test_dataset, loss_fn)
print("Done!")for t in range(epochs):print(f"Epoch_new {t+1}\n-------------------------------")train_loop(model_new, train_dataset, loss_history_new)test_loop(model_new, test_dataset, loss_fn_new)
print("Done_new!")

下面導入 matplotlib 模塊來進行可視化展示
import matplotlib.pyplot as plt
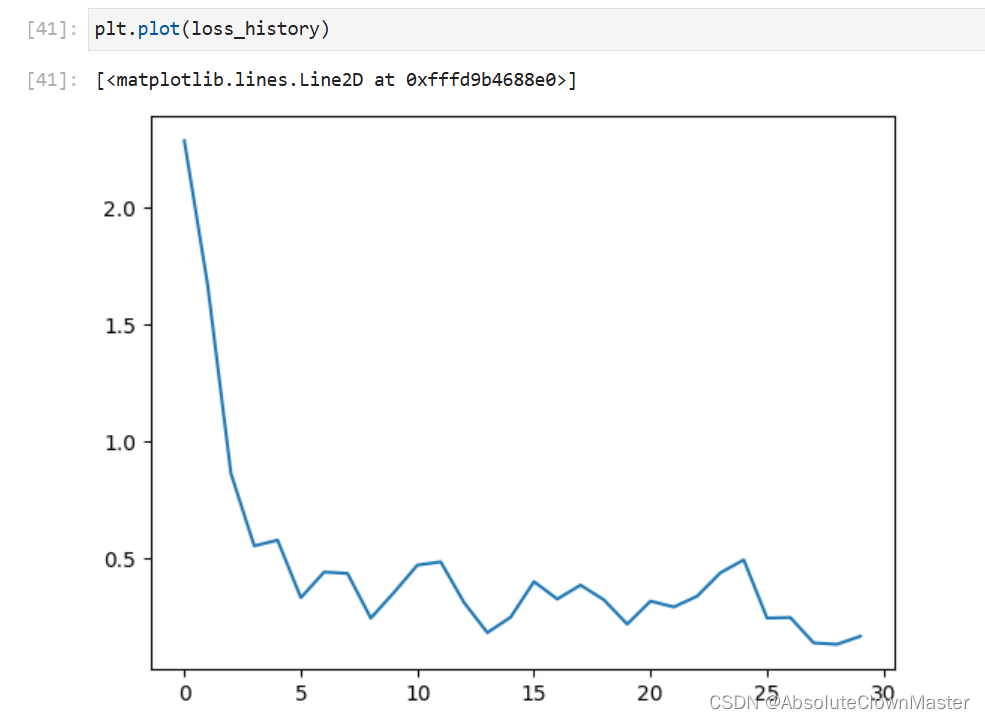
plt.plot(loss_history)
plt.plot(loss_history_new)
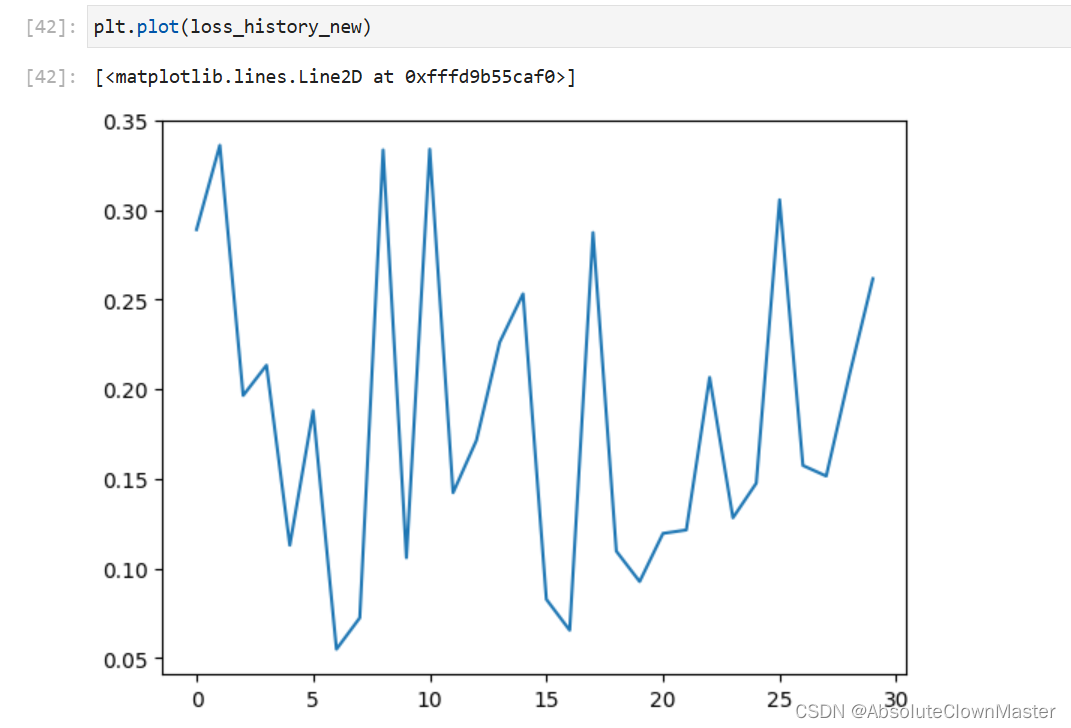
就上面兩個圖來看,第一個訓練的結果還是蠻不錯的,第二個的loss抖動太多,雖然幅度不大(0.05–0.35)但是還是不如第一個,畢竟加了兩層,白瞎了
所以,在訓練模型的時候一定要記得化繁為簡,多大規模的模型干多大規模的事情,要不然很容易出現譬如:欠擬合、過擬合等各種各樣的問題 還得好好調教
這就是今天的全部內容了,別忘了點贊收藏加關注 別逼我求你!!!
驗證)







)

)


![[C++11] 退出清理函數(quick_exit at_quick_exit)](http://pic.xiahunao.cn/[C++11] 退出清理函數(quick_exit at_quick_exit))
![[今日一水]論壇該如何選擇](http://pic.xiahunao.cn/[今日一水]論壇該如何選擇)
)



)