💐大家好!我是碼銀~,歡迎關注💐:
CSDN:碼銀
公眾號:碼銀學編程
實驗目的和要求
- 會用Python創建Kmeans聚類分析模型
- 使用KMeans模型對航空公司客戶價值進行聚類分析
- 會對聚類結果進行分析評價
實驗環境
- pycharm2020
- Win11
- Python3.7
- Anaconda2019
KMeans聚類算法簡介
KMeans聚類算法是一種基于中心點的聚類方法,其目標是將數據點劃分為K個簇,使得每個簇內的數據點與簇中心的距離之和最小。算法的基本步驟包括:
- 初始化:隨機選擇K個數據點作為初始簇中心。
- 分配:將每個數據點分配到最近的簇中心,形成K個簇。
- 更新:重新計算每個簇的中心點。
- 迭代:重復步驟2和3,直到簇中心不再變化或達到最大迭代次數。
數據的加載和分析
數據集的獲取:搜索微信公眾號“碼銀學編程”。回復:航空數據集
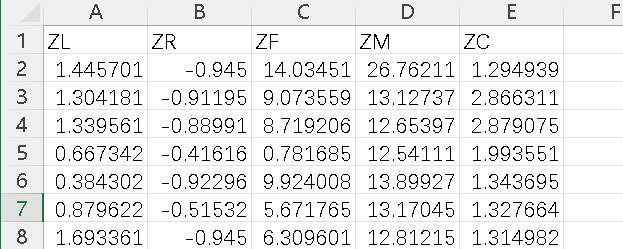
ZL:入會至當前時長,反映客戶的活躍時間。
ZR:最近消費時間間隔,反映客戶的最近活躍程度。
ZF:消費頻次,反映客戶的忠誠度。
ZM:消費里程總額,反映客戶對航空公司服務的依賴程度。
ZC:艙位等級對應折扣系數,通常艙位等級越高,折扣系數越大。
首先,使用Pandas庫加載CSV格式的環境監測數據文件。
def load_data(filepath):"""加載CSV數據文件"""return pd.read_csv(filepath, header=0)
聚類分析
接著,使用Scikit-learn庫中的KMeans模型對數據進行聚類分析。通過設置不同的參數,如最大迭代次數、簇的數量等,可以對模型進行調整以適應不同的數據集。
def perform_kmeans(data, n_clusters):"""執行KMeans聚類分析"""model = KMeans(max_iter=300, n_clusters=n_clusters, random_state=None, tol=0.0001)model.fit(data)return model
結果可視化
為了直觀展示聚類結果,使用Matplotlib庫繪制聚類圖。通過將數據點和簇中心在二維平面上表示,可以清晰地觀察到數據的分布和簇的劃分情況。
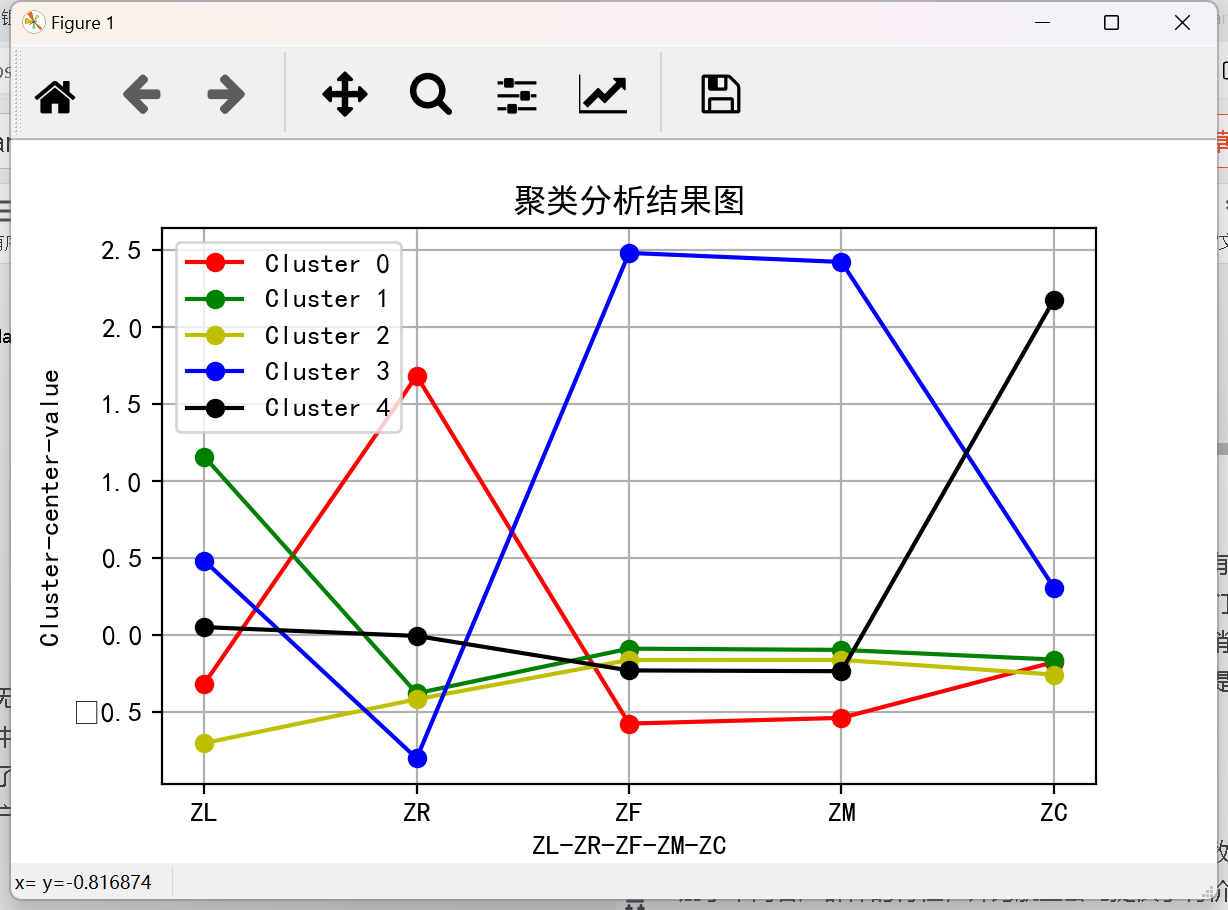
def plot_clusters(model, data):"""繪制聚類結果"""plt.figure(figsize=(10, 6)) # 設置圖表大小plt.xlabel("ZL-ZR-ZF-ZM-ZC") # 假設環境指標plt.ylabel("Cluster-center-value")plt.title("聚類分析結果圖")colors = ['r', 'g', 'y', 'b', 'k']for i in range(model.n_clusters):plt.plot(data.columns, model.cluster_centers_[i], label=f'Cluster {i}', color=colors[i], marker='o')plt.legend()plt.grid(True)plt.show()
主函數
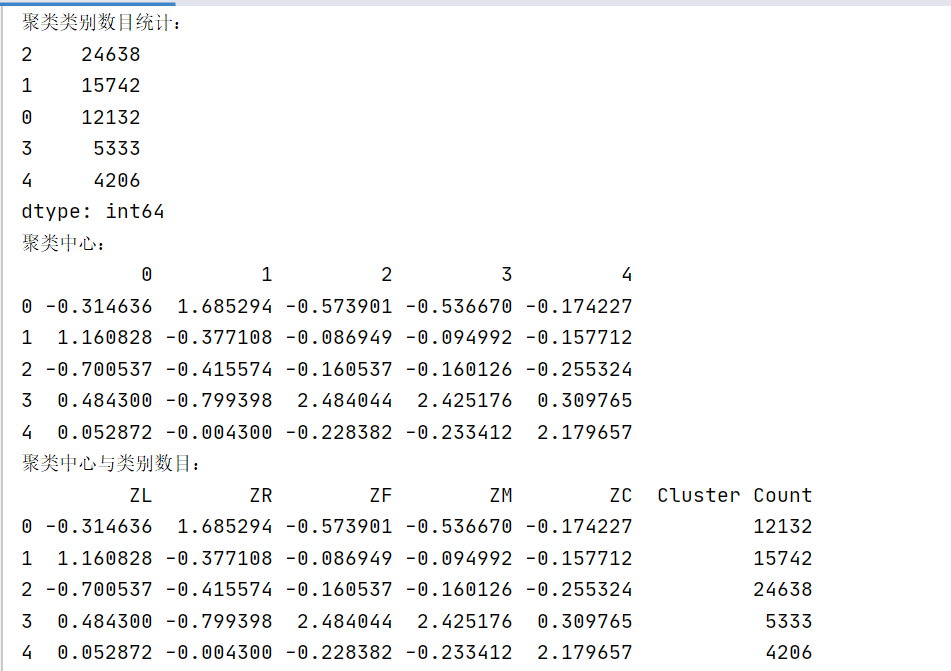
def main():# 加載數據data = load_data("air_data.csv")print("數據形狀:", data.shape)print("數據前五行:")print(data.head())# 聚類分析kmodel = perform_kmeans(data, 5)print("聚類類別數目統計:")print(pd.Series(kmodel.labels_).value_counts())# 聚類中心cluster_centers = pd.DataFrame(kmodel.cluster_centers_)print("聚類中心:")print(cluster_centers)# 聚類中心與類別數目cluster_info = pd.concat([cluster_centers, pd.Series(kmodel.labels_).value_counts()], axis=1)cluster_info.columns = list(data.columns) + ['Cluster Count']print("聚類中心與類別數目:")print(cluster_info)# 繪制聚類結果圖plot_clusters(kmodel, data)if __name__ == "__main__":main()
分析與討論
這個結果展示了使用K-Means聚類算法對航空公司客戶數據進行分析后得到的聚類中心和每個聚類的樣本數量。每一列(ZL、ZR、ZF、ZM、ZC)代表數據集中的一個特征,這些特征分別表示:
- ZL:入會至當前時長,反映客戶的活躍時間。
- ZR:最近消費時間間隔,反映客戶的最近活躍程度。
- ZF:消費頻次,反映客戶的忠誠度。
- ZM:消費里程總額,反映客戶對航空公司服務的依賴程度。
- ZC:艙位等級對應折扣系數,通常艙位等級越高,折扣系數越大。
聚類中心(Cluster Centers)是每個聚類中所有點的均值,可以看作是該聚類的“代表”或“典型”客戶。在這個例子中,我們有5個聚類中心和它們的統計數據:
-
第一個聚類中心(Cluster 0)的ZL值較低,ZR值較高,ZF和ZM值較低,ZC值也較低。這可能代表一群活躍時間較短、最近消費間隔較長、消費頻次和里程較低的客戶,他們可能對航空公司的忠誠度和依賴程度不高。
-
第二個聚類中心(Cluster 1)的ZL值較高,ZR值較低,ZF值較低,ZM值較低,ZC值較低。這可能代表一群活躍時間較長但最近不太活躍的客戶,他們的消費頻次和里程也較低。
-
第三個聚類中心(Cluster 2)的ZL和ZR值都較低,ZF值較低,ZM值較低,ZC值較高。這可能代表一群活躍時間較短且最近消費間隔較長的客戶,他們的消費頻次和里程較低,但可能購買了較高艙位等級的機票。
-
第四個聚類中心(Cluster 3)的ZL和ZR值都較高,ZF和ZM值較高,ZC值也較高。這可能代表一群活躍時間較長、最近消費頻繁、消費里程高且購買了較高艙位等級機票的客戶,他們對航空公司的忠誠度和依賴程度很高。
-
第五個聚類中心(Cluster 4)的ZL值較低,ZR值較低,ZF值較低,ZM值較低,ZC值較高。這可能代表一群最近活躍且購買了較高艙位等級機票的客戶,但他們的總體消費頻次和里程較低。
完整代碼
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.cluster import KMeansdef load_data(filepath):"""加載CSV數據文件"""return pd.read_csv(filepath, header=0)def perform_kmeans(data, n_clusters):"""執行KMeans聚類分析"""model = KMeans(max_iter=300, n_clusters=n_clusters, random_state=None, tol=0.0001)model.fit(data)return modeldef plot_clusters(model, data):"""繪制聚類結果"""plt.figure(figsize=(10, 6)) # 設置圖表大小plt.xlabel("ZL-ZR-ZF-ZM-ZC")plt.ylabel("Cluster-center-value")plt.rcParams['font.sans-serif'] = ['SimHei'] # 確保中文標簽正常顯示plt.title("聚類分析結果圖")cluster_centers = model.cluster_centers_colors = ['r', 'g', 'y', 'b', 'k']for i in range(len(cluster_centers)):plt.plot(data.columns, cluster_centers[i], label=f'Cluster {i}', color=colors[i], marker='o')plt.legend()plt.grid(True) # 添加網格線plt.show()def main():# 加載數據data = load_data("air_data.csv")print("數據形狀:", data.shape)print("數據前五行:")print(data.head())# 聚類分析kmodel = perform_kmeans(data, 5)print("聚類類別數目統計:")print(pd.Series(kmodel.labels_).value_counts())# 聚類中心cluster_centers = pd.DataFrame(kmodel.cluster_centers_)print("聚類中心:")print(cluster_centers)# 聚類中心與類別數目cluster_info = pd.concat([cluster_centers, pd.Series(kmodel.labels_).value_counts()], axis=1)cluster_info.columns = list(data.columns) + ['Cluster Count']print("聚類中心與類別數目:")print(cluster_info)# 繪制聚類結果圖plot_clusters(kmodel, data)if __name__ == "__main__":main()



)

)


![[C++11] 退出清理函數(quick_exit at_quick_exit)](http://pic.xiahunao.cn/[C++11] 退出清理函數(quick_exit at_quick_exit))
![[今日一水]論壇該如何選擇](http://pic.xiahunao.cn/[今日一水]論壇該如何選擇)
)



)

)

