目錄
信息檢索概述
IR vs數據庫: 結構化vs 非結構化數據
結構化數據
非結構化數據
半結構化數據
傳統信息檢索VS現代信息檢索
布爾檢索
倒排索引
一個例子
建立詞項(可以是字、詞、短語、一句話)-文檔的關聯矩陣。
關聯向量
檢索效果的評價
建立倒排索引表
索引構建過程:
布爾查詢的處理
查詢優化
信息檢索概述
Information Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).
信息檢索是從大規模非結構化數據(通常是文本) 的集合(通常保存在計算機上)中找出滿足用戶 信息需求的資料(通常是文檔)的過程。
Document –文檔
Unstructured – 非結構化
Information need –信息需求
Collection—文檔集、語料庫
IR vs數據庫: 結構化vs 非結構化數據
結構化數據
通常指表格中的數據。
數據庫常常支持范圍或者精確匹配查詢。
非結構化數據
通常指自由文本
允許
- 關鍵詞加上操作符號的查詢
- 更復雜的概念性查詢,
找出所有的有關藥物濫用(drug abuse)的網頁
經典的檢索模型一般都針對自由文本進行處理
考慮文本之間的相似性 搜兵乓球,出現劉國梁
半結構化數據
沒有數據是沒有結構的。
不同位置的關鍵詞權重是不一樣的,如標題比正文權重更高。
傳統信息檢索VS現代信息檢索
傳統信息檢索主要關注非結構化、半結構化數據
現代信息檢索中也處理結構化數據
第一個檢索只能使用結構化數據,而結構化數據僅占全部數據的20%,日志文件+機器數據又占非結構化數據的90%。如何利用日志文件等非結構化數據是現在信息檢索發展的關鍵。
布爾檢索
針對布爾查詢的檢索,布爾查詢是指利用AND, OR 或 者NOT操作符將詞項連接起來的查詢
布爾模型是最簡單的模型 第一個模型 但在現在最先進的模型中依然使用
輸入信息,被切割為關鍵詞
人工and 檢索and not 教材
百度的高級檢索中有。
1\And 2\or not 3排序
倒排索引
一個例子
莎士比亞的哪部劇本包含Brutus及Caesar但是不包含 Calpurnia? 布爾表達式為Brutus AND Caesar AND NOT Calpurnia。
笨方法:從頭到尾掃描所有劇本,對每部劇本判斷它是否 包含Brutus AND Caesar ,同時又不包含Calpurnia
笨方法為什么不好?
?§ 速度超慢(特別是大型文檔集) § 處理NOT Calpurnia 并不容易(一旦包含即可停止判斷) § 不太容易支持其他操作(e.g., find the word Romans near countrymen) § 不支持檢索結果的排序(即只返回較好的結果)
因為現在語料庫太長,從頭到尾不現實。
建立詞項(可以是字、詞、短語、一句話)-文檔的關聯矩陣。
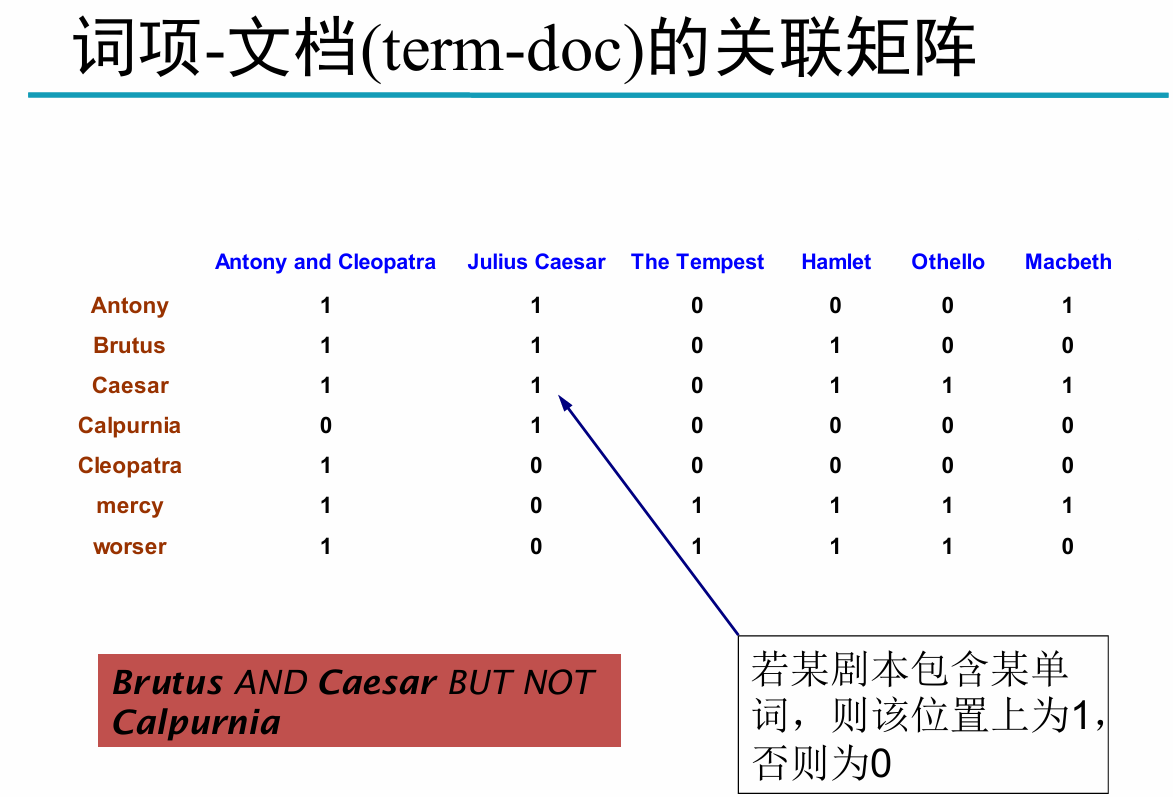
關聯向量
關聯矩陣的每一列都是0/1向量,每個0/1都對應 一個詞項
給定查詢Brutus AND Caesar AND NOT Calpurnia
取出三個行向量,并對Calpurnia 的行向量求補, 最后按位進行與操作
110100 AND 110111 AND 101111 = 100100.
檢索效果的評價
正確率(Precision) : 返回結果文檔中正確的比例。 如返回80篇文檔,其中20篇相關,正確率1/4
召回率(Recall) : 全部相關文檔中被返回的比例, 如返回80篇文檔,其中20篇相關,但是總的應該 相關的文檔是100篇,召回率1/5
正確率和召回率反映檢索效果的兩個方面,缺一 不可。
全部返回,正確率低,召回率100%
只返回一個非常可靠的結果,正確率100%
召回率低F是P R的調和平均
詞項-文檔的關聯矩陣應該是高度稀疏的矩陣(就是1的占比很少)
為了降低占用空間,我們只把1的位置保留下來。
建立倒排索引表
把1保留下來,把0去掉。從稀疏矩陣到存儲docID的向量。
對每個詞項t, 記錄所有包含t的文檔列表.
每篇文檔用一個唯一的docID來表示,通常是正整數, 如1,2,3…
通常采用變長表方式
磁盤上,順序存儲方式較好,便于快速讀取
內存中,采用鏈表或者可變長數組方式
索引構建過程:
詞條序列、排序、詞典&倒排記錄表
布爾查詢的處理
And查詢的處理 合并(Merge)兩個倒排記錄表,即求交集
每個倒排記錄表都有一個定位指針,兩個指針同 時從前往后掃描, 每次比較當前指針對應倒排記錄, 然后移動某個或兩個指針。合并時間為兩個表長 之和的線性時間
OR表達式:Brutus OR Caesar 兩個倒排記錄表的并集
NOT表達式:Brutus AND NOT Caesar 兩個倒排記錄表的減
查詢優化
合并索引表!實現and操作。
一、先最短的兩個合并,DF小的先合并。//保留DF的原因之一
二、或者將布爾表達式轉化為合取范式,
獲得每個詞項的df,(保守)估算每個子合取范式的df,最后將子合取范式的df從小到大排序。
布爾檢索可以限定很多條件。
布爾檢索構造復雜,對用戶極其不友好。
布爾檢索沒有排序。
沒有利用詞頻信息。



 的作用)



-C卷D卷-200分)











