文章目錄
- 網頁地址
- 爬蟲目標
- 技術棧
- 爬蟲代碼
- 注意事項
Python爬蟲學習:我們可以選擇一個相對簡單的網站進行數據抓取。這里以抓取“豆瓣電影Top250”的信息為例,這個網站提供了豐富的電影數據,包括電影名稱、評分、導演、演員等信息。
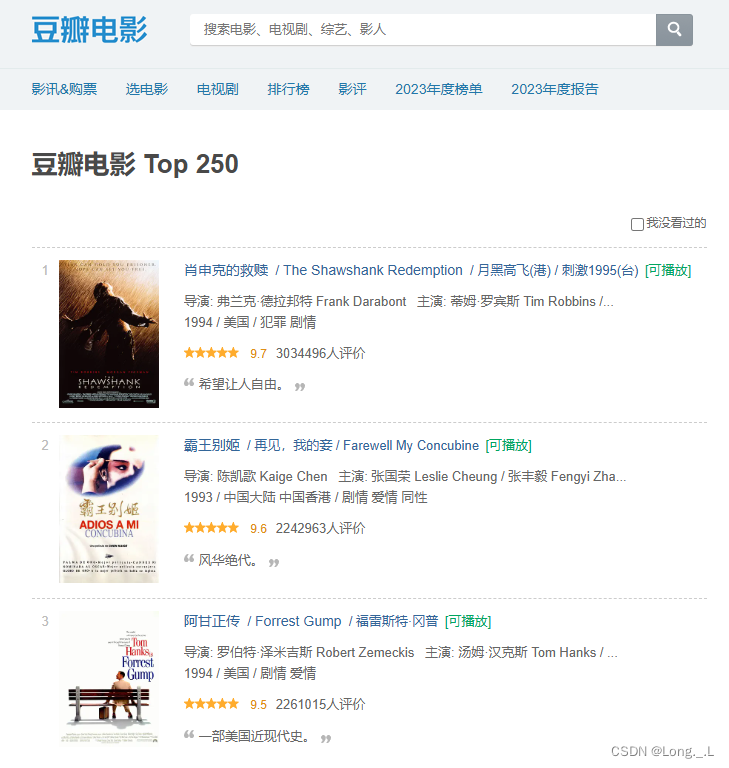
網頁地址
- https://movie.douban.com/top250
爬蟲目標
- 抓取每部電影的名稱、評分、簡介和前幾位主演的名字。
技術棧
- Python 3.x
requests:用于發送HTTP請求。BeautifulSoup4:用于解析HTML文檔。
爬蟲代碼
首先,確保你已經安裝了requests和beautifulsoup4庫,如果沒有安裝,可以通過以下命令安裝:
pip install requests beautifulsoup4
以下是完整的爬蟲代碼:
# 導入requests庫用于發送HTTP請求
import requests
# 導入BeautifulSoup庫用于解析HTML文檔
from bs4 import BeautifulSoup# 定義一個函數用于獲取電影數據
def fetch_movie_data():# 設置請求的URL,這里是豆瓣電影Top 250的頁面url = "https://movie.douban.com/top250"# 設置請求頭,偽裝成瀏覽器訪問headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}# 發送GET請求,獲取頁面內容response = requests.get(url, headers=headers)# 使用BeautifulSoup解析獲取到的頁面內容soup = BeautifulSoup(response.text, 'html.parser')# 查找頁面中所有的電影條目movies = soup.find_all('div', class_='item')# 遍歷每部電影條目for movie in movies:# 提取電影標題title = movie.find('span', class_='title').text# 提取電影評分rating = movie.find('span', class_='rating_num').text# 提取電影的詳細信息,這里只取第一行info = movie.find('div', class_='bd').find('p').text.strip().split('\n')[0]# 提取主演信息,可能有多個主演,通過分割和篩選獲取actors = [actor.strip() for actor in info.split('/') if actor.strip().startswith('主演')]# 如果有主演信息,去除'主演:'并用逗號連接,否則顯示'N/A'actors = ', '.join(actors).replace('主演:', '') if actors else 'N/A'# 打印電影的標題、評分和主演信息print(f"Title: {title}")print(f"Rating: {rating}")print(f"Actors: {actors}\n")# 判斷是否是直接運行此腳本,如果是,則調用fetch_movie_data函數
if __name__ == "__main__":fetch_movie_data()
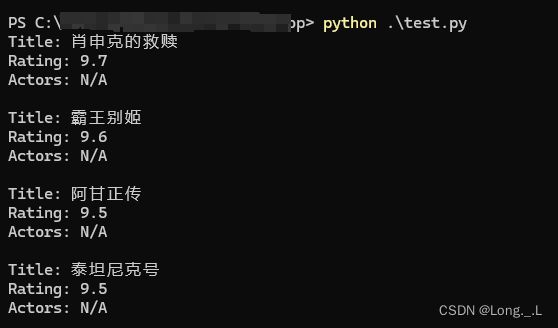
代碼解釋:
這段Python代碼定義了一個函數fetch_movie_data()用于從豆瓣電影Top250頁面抓取電影數據,包括電影標題、評分以及主演信息,并打印這些信息。
下面是代碼的詳細解釋:
-
導入必要的庫:
requests:用于發送HTTP請求。BeautifulSoup:用于解析HTML文檔。
-
定義
fetch_movie_data函數:- 設置目標URL為豆瓣電影Top250頁面。
- 設置請求頭
headers,其中包含一個模擬瀏覽器的User-Agent字符串,這是為了繞過網站可能的反爬蟲機制。
-
發送GET請求并解析HTML:
- 使用
requests.get方法發送GET請求到指定URL,獲取響應文本。 - 使用
BeautifulSoup解析響應文本,創建一個soup對象,這個對象可以用來解析和提取HTML元素。
- 使用
-
提取電影信息:
- 使用
soup.find_all找到所有的電影條目,每個電影條目是一個div標簽,類名為item。 - 對于每部電影,使用
find方法來查找特定的信息:- 電影名稱:查找類名
title的span標簽。 - 評分:查找類名
rating_num的span標簽。 - 信息:查找
div標簽下的p標簽,此標簽通常包含電影的年份、國家、類型及演員等信息。
- 電影名稱:查找類名
- 從
info中提取主演信息,通過查找以“主演”開始的字符串,然后去除“主演:”,并將所有主演名字用逗號連接起來。
- 使用
-
打印電影信息:
- 打印電影標題、評分和主演信息。
-
執行函數:
- 在
__main__模塊下調用fetch_movie_data函數,執行抓取和打印操作。
- 在
注意事項
- 遵守網站規則:在實際操作中,請確保你的行為符合目標網站的
robots.txt文件規定,不要對服務器造成過大負擔。 - 動態加載內容:有些網站使用JavaScript動態加載內容,這可能需要使用如Selenium這樣的工具來模擬瀏覽器行為。
- 錯誤處理:在實際應用中,應加入更完善的錯誤處理機制,比如重試策略、超時設置等。
漠漠水田飛白鷺,陰陰夏木囀黃鸝。







)



--學習記錄之迭代器與生成器(上))





)

