? ?Python中的requests庫主要用于發送HTTP請求并獲取響應結果。在現代網絡編程中,HTTP請求是構建客戶端與服務器之間通信的基礎。Python作為一種高級編程語言,其豐富的庫支持使得它在網絡數據處理領域尤為突出。其中,requests庫以其簡潔、易用的特點,被廣泛應用于Web開發、數據抓取、API交互等場景。
以下是對requests庫功能及其在實際使用中的一些典型應用的詳細分析:
1. 簡化HTTP請求
? - 易于上手:requests庫提供了簡潔明了的API,讓用戶能夠輕松地發送HTTP請求。
? - 多種請求方法支持:支持GET、POST、PUT、DELETE等所有常用的HTTP方法。
2. 獲取和解析響應
? - 響應對象:每次請求都會返回一個包含狀態碼、響應頭、內容等信息的response對象。
? - 內容處理:可以方便地獲取響應內容,并對內容進行進一步的處理,如JSON解析、文本編碼轉換等。
3. 靈活的參數配置
? - 請求頭設置:允許自定義請求頭,模擬不同的瀏覽器或設備。
? - Cookies處理:支持通過cookies保持會話狀態。
? - 代理和認證:支持通過代理訪問以及基本/摘要式認證。
4. 異常處理和重試機制
? - 異常處理:提供多種異常類型,便于錯誤捕獲和處理。
? -會話管理:利用session對象可以更好地管理持久連接和cookies,適合需要發送多個請求的場景。
5. 高級功能
? - 文件上傳下載:支持直接上傳文件作為請求體,或從響應中下載文件。
? - SSL證書驗證:支持設置是否驗證SSL證書,確保數據傳輸的安全性。
? - 超時設置:允許設置請求超時時間,防止因網絡延遲導致的程序假死。
除了上述功能外,還有一些值得注意的應用場景:
- Web爬蟲開發:requests常用于編寫網絡爬蟲,可以方便地獲取網頁數據并進行解析。
- API接口測試:對于開發人員來說,requests是測試RESTful API接口的好工具,可以模擬前端發送請求,檢查后端響應。
- 自動化測試:在自動化測試腳本中,可以利用requests發送請求并驗證返回數據是否符合預期。
以下是一段關于requests的代碼:
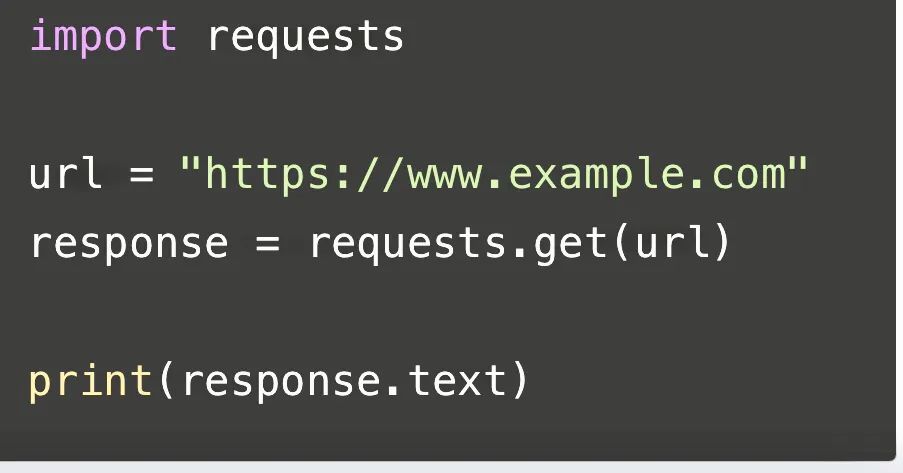
? ? ? 這段代碼使用了Python的requests庫來發送一個HTTP GET請求到指定的URL(這里是"https://www.example.com"),并將返回的響應內容打印出來。首先,我們導入了requests庫,然后定義了一個變量url,存儲了要請求的網址。接著,我們使用requests.get()函數發送GET請求,并將返回的響應對象存儲在response變量中。最后,我們通過response.text屬性獲取響應的內容,并使用print()函數將其打印出來。
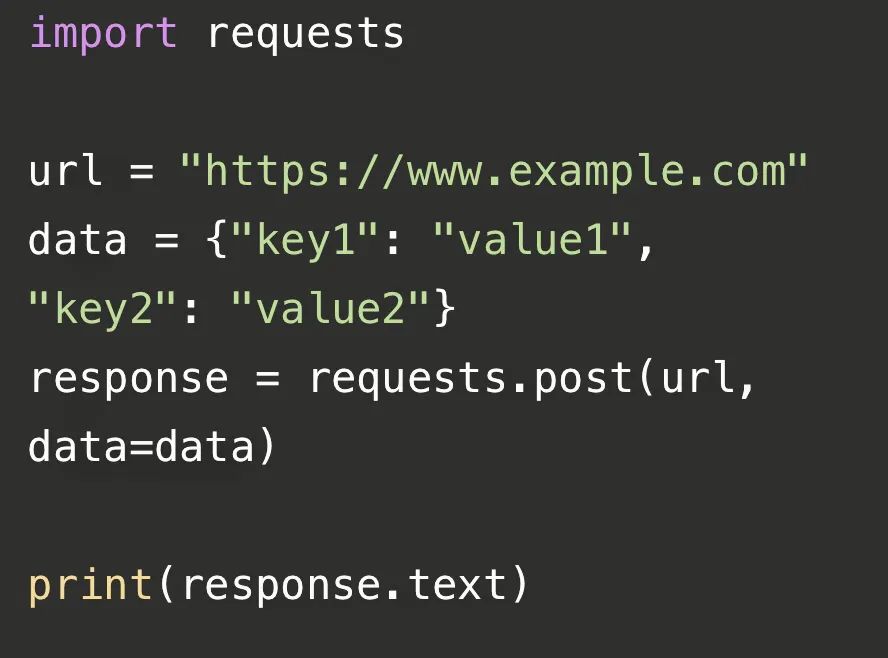
? ? ? 這段代碼使用了Python的requests庫來發送一個HTTP POST請求到指定的URL(這里是"https://www.example.com"),并將返回的響應內容打印出來。首先,我們導入了requests庫,然后定義了一個變量url,存儲了要請求的網址。接著,我們創建了一個字典data,其中包含了要發送的數據。然后,我們使用requests.post()函數發送POST請求,并將返回的響應對象存儲在response變量中。最后,我們通過response.text屬性獲取響應的內容,并使用print()函數將其打印出來。
? 接下來介紹一下requests庫在爬蟲方面的應用:
Requests庫在網絡爬蟲中的主要應用場景包括數據抓取、模擬登錄、文件下載和上傳以及會話管理等。具體如下:
1. 數據抓取:Requests庫使得發送HTTP請求變得簡單,能夠方便地從網站上抓取數據。通過GET和POST請求,可以輕松獲取網頁內容,是數據挖掘和數據分析不可或缺的工具。
2. 模擬登錄:在進行需要登錄的網站爬取時,Requests庫可以處理cookies和session,保持用戶的登錄狀態,自動處理cookies,適用于需要持久連接和多次請求的場景。
3. 文件下載:Requests庫支持文件的上傳和下載,通過`files`參數上傳文件,通過`save_response_content`方法下載文件,這使得從網絡資源中獲取數據變得十分便捷。
4. 會話管理:使用`requests.Session()`可以創建一個會話,保持某些參數(如cookies、headers)在多個請求之間,這對于需要維持登錄狀態或連續進行多個請求的爬蟲場景非常有用。
5. 異常處理:在進行網絡請求時,可能會遇到各種異常如`requests.exceptions.Timeout`等,合理處理這些異常是使用Requests庫的難點之一。
6. 超時設置:通過設置timeout參數,可以控制請求的超時時間,防止請求過久無響應,這對爬蟲效率和穩定性有重要影響。
7. 代理設置:在爬取網頁時,可以通過proxies參數設置代理服務器,增加匿名性,有助于避免被目標網站封鎖。
8. JSON數據處理:Requests庫支持直接發送和接收JSON數據,使用`json`參數傳遞JSON數據,或使用`response.json()`解析響應的JSON數據,這在處理API響應時非常有用。
9. 安全性問題:通過`verify`參數可以控制是否驗證SSL證書,確保請求的安全性,在處理敏感數據或進行重要操作時,這一點至關重要。
10. 性能優化:Requests庫內部使用urllib3庫,后者提供了連接池的管理,合理配置可以提升性能。
此外,在使用Requests庫進行網絡爬蟲開發時,還需要注意以下幾點:
1. 當請求需要登錄或保持登錄狀態的網站時,需要特別處理cookies和session。
2. 對于頻繁的請求,需要考慮設置合理的超時時間和重試策略,以避免因網絡波動導致的請求失敗。
3. 在處理敏感數據或進行重要操作時,務必注意安全性問題,如SSL證書的驗證和HTTP基本認證。
綜上所述,Requests庫以其簡潔易用、功能強大的特點,成為了Python中進行網絡數據交互的首選工具。無論是基本的GET和POST請求,還是復雜的異常處理、超時設置、代理使用、Cookies處理、Session會話、JSON數據處理、文件上傳下載、安全性問題以及性能優化,Requests庫都能提供強大的支持。
以下是一段爬蟲代碼僅供參考:
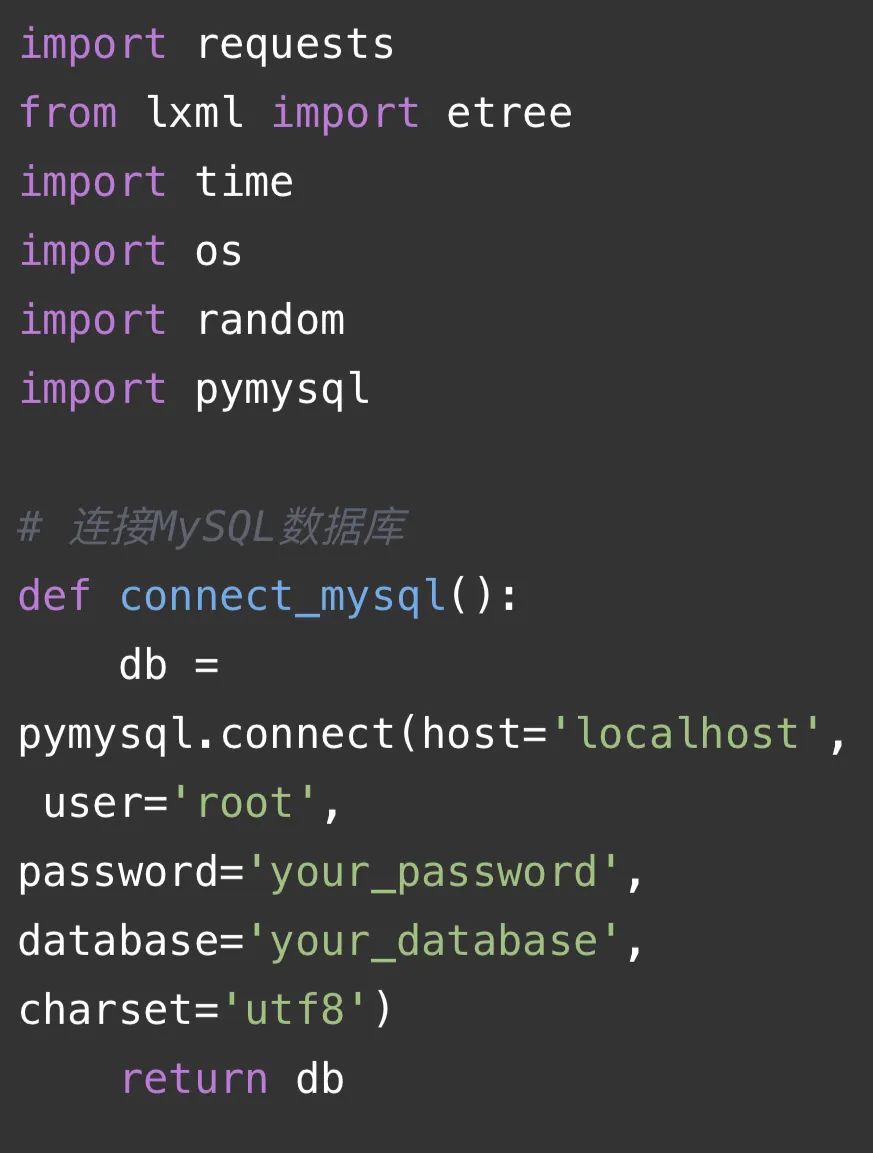
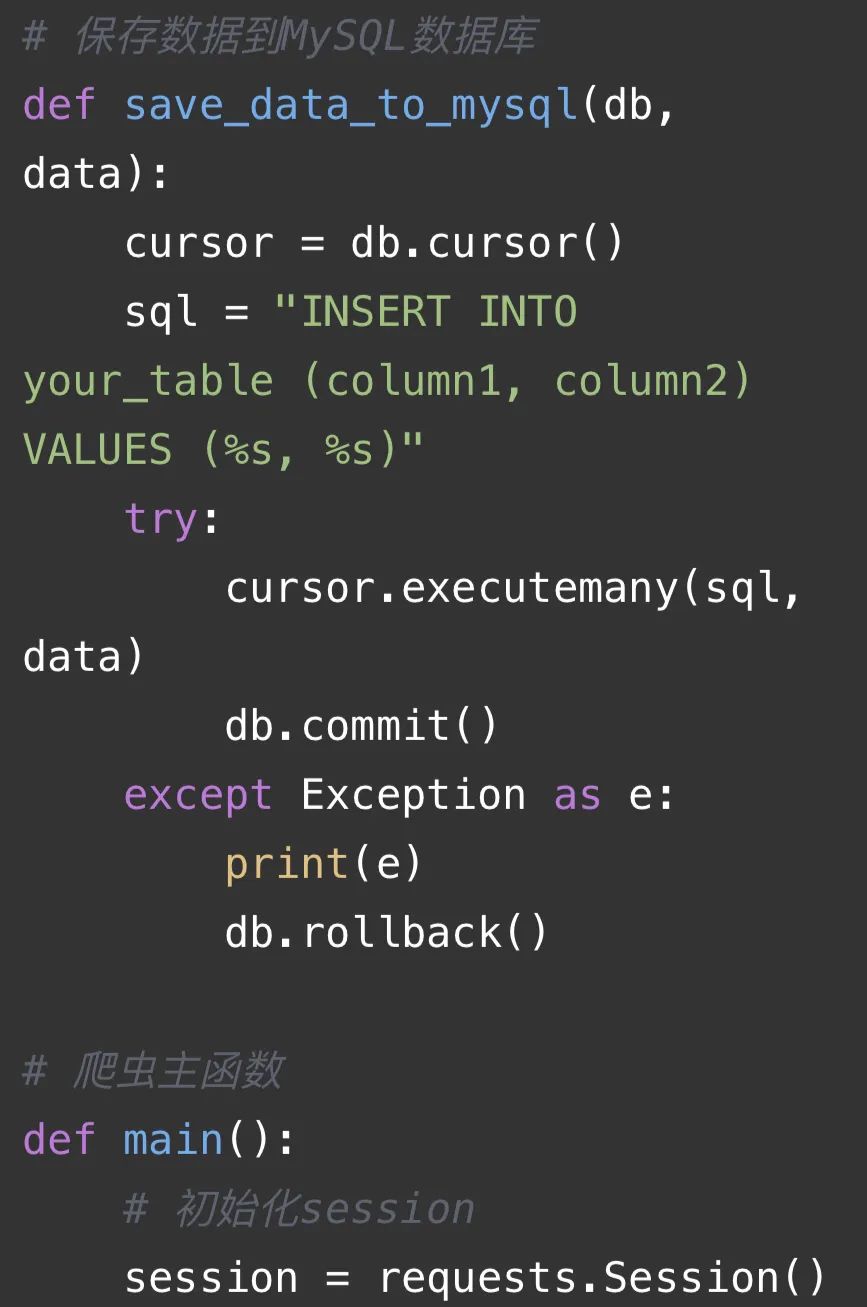
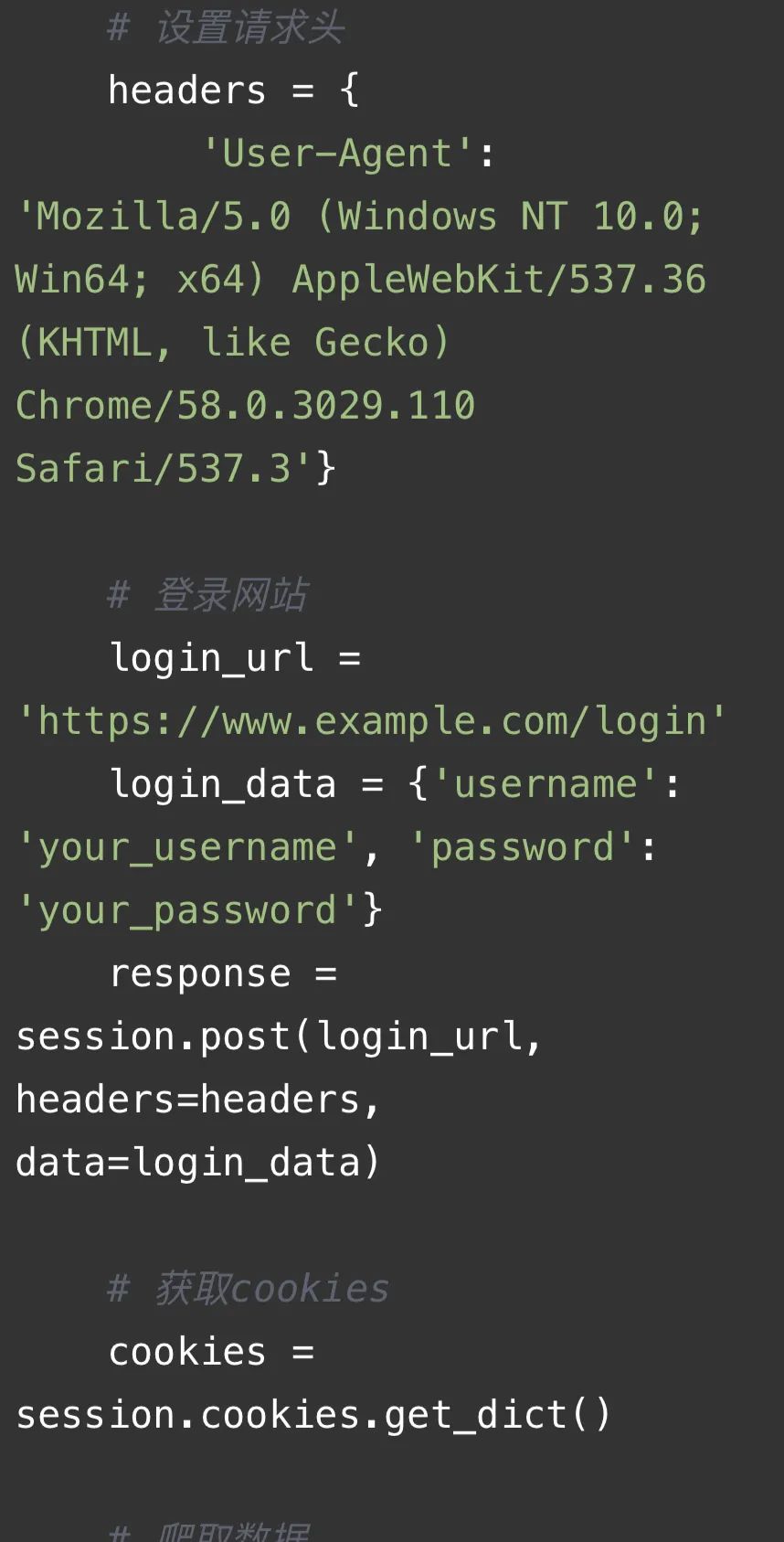

代碼解釋:
這段代碼是一個使用requests庫、lxml庫、time庫、os庫和random庫的爬蟲代碼。主要功能如下:
1. 連接MySQL數據庫:通過`connect_mysql()`函數連接到MySQL數據庫,返回一個數據庫連接對象。
2. 保存數據到MySQL數據庫:通過`save_data_to_mysql(db, data)`函數將數據保存到MySQL數據庫中。其中,`db`是數據庫連接對象,`data`是要保存的數據。
3. 爬蟲主函數:通過`main()`函數實現爬蟲的主要邏輯。
4. 初始化session:使用`requests.Session()`創建一個session對象,用于管理HTTP請求。
5. 設置請求頭:定義一個headers字典,包含User-Agent等信息,用于模擬瀏覽器發送請求。
6. 登錄網站:通過POST請求登錄網站,獲取cookies。
7. 爬取數據:使用GET請求爬取網頁數據,并將HTML內容解析為lxml對象。
8. 解析數據:通過XPath表達式提取網頁中的相關信息,并將數據存儲到一個列表中。
9. 保存數據到MySQL數據庫:調用`save_data_to_mysql()`函數將解析得到的數據保存到MySQL數據庫中。
10. 關閉數據庫連接:在數據保存完成后,關閉數據庫連接。
以上的相關應用可以通過小蜜蜂AI的GPT問答獲取更多的示例。網址:https://zglg.work。
(文章對你有用的話。記得點贊?在看哦😯😯😯😯分享知識也是一種美德)
? 如有學習上的困惑或問題歡迎評論區留言告訴我們,讓我們一起解決共同進步:



—— 節日母親節介紹網頁(5個頁面))
-游戲實例GameEntity)


)







)



