本篇文章我將介紹使用智譜 AI 最新開源的 GLM-4-9B 模型和 GenAI 云服務 SiliconCloud 快速構建一個 RAG 應用,首先我會詳細介紹下 GLM-4-9B 模型的能力情況和開源限制,以及 SiliconCloud 的使用介紹,最后構建一個編碼類智能體應用作為測試。
本文首發自博客 使用智譜 GLM-4-9B 和 SiliconCloud 云服務快速構建一個編碼類智能體應用
我的新書《LangChain編程從入門到實踐》 已經開售!推薦正在學習AI應用開發的朋友購買閱讀,此書圍繞LangChain梳理了AI應用開發的范式轉變,除了LangChain,還涉及其他諸如 LIamaIndex、AutoGen、AutoGPT、Semantic Kernel等熱門開發框架。

GLM-4-9B 有多強
智譜家 GLM-4-9B 模型的發布,可以稱得上大模型開源領域的又一個里程碑事件,除了開源行為本身值得肯定,我覺得開源出來的模型可以接入線上應用直接使用,可能對我們做應用層的開發者意義更大。話不多說,看 GLM-4-9B 的介紹:
首先 GLM-4-9B 模型結構與 GLM-3-9B 變化不大,主要是模型層數由 28 增加到 40,詞表大小由 65024 擴充到 151552、支持的上下文長度支持從 32K、128K 擴展到 128K、1M(GLM-4-9B-Chat-1M),做應用最關注的就是長上下文(多輪對話記憶保持、各種閱讀助手、長文本理解等常見場景)能力和 Function Call 能力(工具調用,構建智能體應用的基礎)。
1M 的上下文長度(約 200 萬中文字符)方面,GLM-4-9B 在大海撈針測試中全綠。

不過根據英偉達研究團隊最近新提出的名為RULER的新基準,這里選用的測試方法(測試的 LWM 聲稱上下文長度 1M,實際不到 4K)測出來的結果有水分,這個我還會自己測試下。
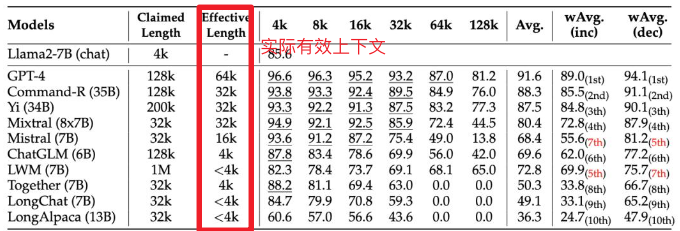
Function Call 能力也屬于 gpt-4-turbo 級別,使用 Berkeley Function-Calling Leaderboard 測試集,這個對我來說比較有說服力,有興趣的可以看看測試集設計,不過畢竟測試集公開,混在訓練集里也不好說,這個我也按照相同思路設計了對應的私有中文測試集,引入之前也會再跑一次作為交叉驗證。
| Model | Overall Acc. | AST Summary | Exec Summary | Relevance |
|---|---|---|---|---|
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
雖然開源,但也存在限制,就是學術研究免費,商業用途需要登記且必須遵守相關條款和條件,詳見 Github 項目介紹:https://github.com/THUDM/GLM-4
SiliconCloud 有多好用
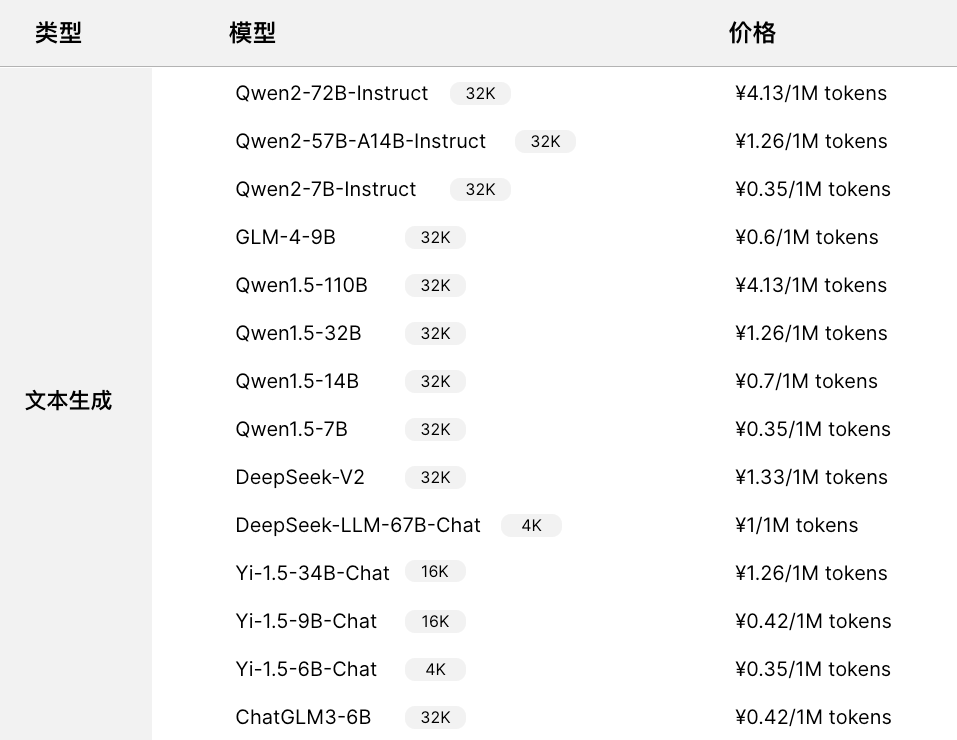
SiliconCloud 是硅基流動推出的 GenAI 云服務,這是國內同類產品中我體驗最好的一家,便宜且推理速度還快,國外已經有很多類似服務了,比如 Banana, Replicate, Beam, Modal 、OctoAI、ModelZ、BentoML等,這類服務主要用于私有模型或常見開源模型托管,通過它們自研的推理加速引擎、大模型基礎設施優化能力,大幅降低大模型的部署及推理成本,降低 AI 應用的成本,加速 AI 產品的落地 。
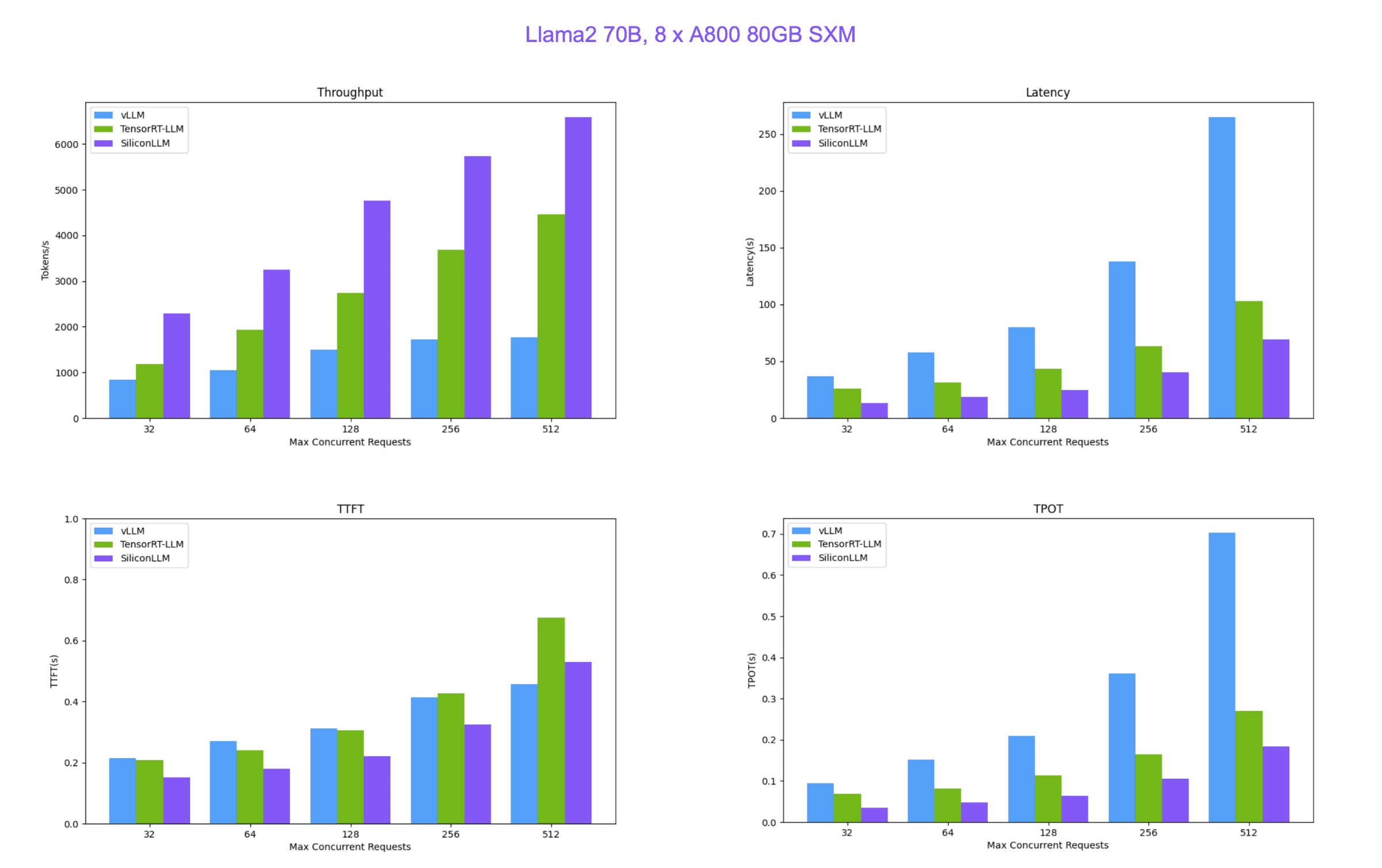
SiliconCloud 便宜又快的原因就在于硅基流動自研的 LLM 推理加速引擎 SiliconLLM ,支持 Llama3、Mixtral、DeepSeek、Baichuan、ChatGLM、Falcon、01-ai(零一萬物開源的模型)、GPT-NeoX 等模型加速,下面是 SiliconLLM 與推理框架vLLM(伯克利大學 LMSYS 組織開源)、Tensorrt-LLM(英偉達開源)的性能比較。
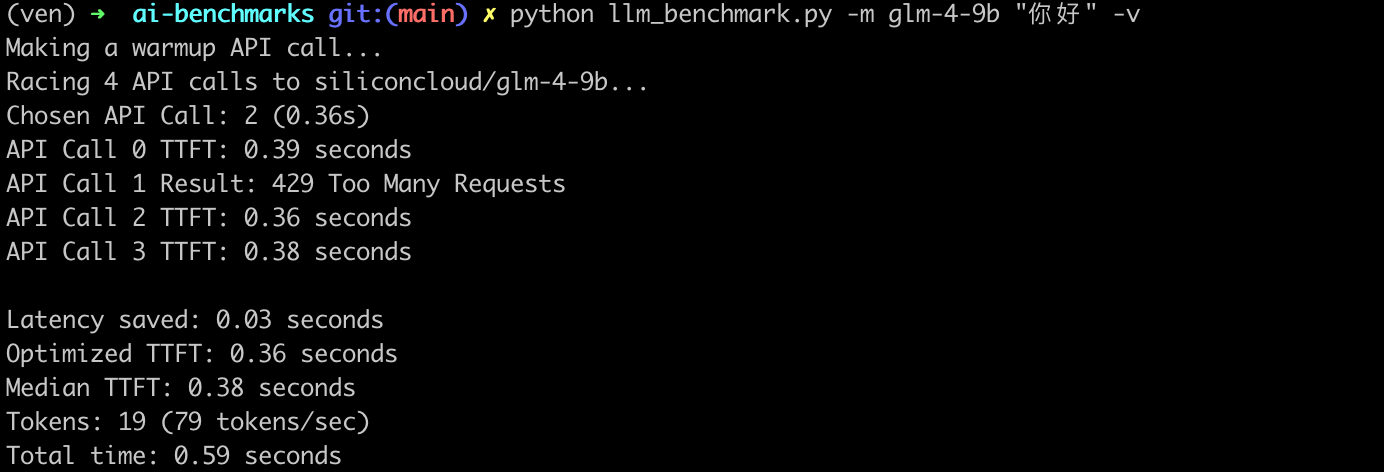
最后補充一組我自己本地隨手測試的 API 調用服務吞吐:
- 首次響應時間與最快響應時間差(
Latency saved 0.03s): 表示首次響應時間與最快響應時間之間的差異,這個指標可以反映出大模型 API 服務在處理請求時的波動。 - 優化后的首 token 響應時間(
Optimized TTFT 0.36s):是指在多次請求中,最快的一次首 token 響應時間。 - 首 token 響應時間中位數(
Median TTFT 0.03s):是指在所有請求中,首 token 響應時間的中位數,即一半的請求首 token 響應時間比這個值快,另一半比這個值慢。中位數可以提供一個更穩健的性能指標,因為它不受極端值的影響。 - 生成的 token 數量(
Tokens: 19):表示在請求過程中生成的 token 總數。 - token 生成速率(
79 tokens/sec): 表示每秒生成的 Token 數量,這是衡量大模型 API 服務處理能力的一個指標。 - 總時間(
Total time: 0.59s): 表示從開始發送 HTTP 請求到接收到最后一個 token 的時間,這是整個請求處理過程的總耗時
構建編碼類智能體應用
首先前往官網 👉 https://cloud.siliconflow.cn/auth/login 注冊 SiliconCloud 賬號,無需手機號,郵箱注冊即可(值得一提,新用戶注冊可以得到 42 元免費額度用于體驗,相當于 3 億 tokens),按流程注冊,保存好生成的 API-KEY。
開始之前先設置好 SiliconCloud 的 GLM-4-9B-Chat 模型, API 調用方式也與 OpenAI 兼容 ,所以可以直接使用 OpenAI SDK (langchain_openai)來訪問 SiliconCloud 上的任意模型。
import os
from langchain_openai import ChatOpenAI
sc_api_key = os.getenv("SC_API_KEY")
llm = ChatOpenAI(base_url="https://api.siliconflow.cn/v1",api_key=sc_api_key,model="zhipuai/glm4-9B-chat")
后續代碼和這篇文章 DeepSeek-V2 到底有多強?寫一個 AI 編碼 Agent 測測看(附詳細代碼)基本一致,也有著詳細解釋過程,這里不再贅述,后臺回復 DeepSeek可獲取完整代碼。


(二)均勻分布簡介)






)







【應用啟動框架AppStartup】)

