? ? ? 人工智能正在迅速變得無處不在,在科學和學術研究中,自回歸的大型語言模型(LLM)走在了前列。自從LLM的概念被整合到自然語言處理(NLP)的討論中以來,LLM中的幻覺現象一直被廣泛視為一個顯著的社會危害和一個關鍵的瓶頸,阻礙了LLM在現實世界中的應用。無論是在流行且全面的學術調查中,還是在面向公眾的技術報告中,都將幻覺問題定位為LLM的主要倫理和安全陷阱之一,應該與其他問題(如偏見和毒性)一起得到嚴重緩解。因此,將幻覺減少到可以忽略不計的水平的承諾,不僅被視為一個技術挑戰,也是更廣泛使命的關鍵組成部分,以減輕與LLM的廣泛部署和廣泛采用相關的社會污名和系統風險。
? ? ?然而,一小部分工作提出了一種觀點,即幻覺并非本質上有害。這種探索性的觀點強調了幻覺的潛在價值和合理必要性。最近的研究表明,幻覺是統計上的必然,并且由于創造性、生成性和信息準確性之間的權衡,從LLM中消除幻覺是不可能的。此外,在許多特定領域的應用中,實現創造性和事實性之間的優化平衡,比僅僅試圖消除幻覺更能有效地最大化LLM的效用。幻覺可能特別有價值的LLM用例包括發現新型蛋白質、為創意寫作提供靈感以及制定創新的法律類比。
? ? 在本文中,我們試圖擴大幻覺的概念,并認為幻覺更接近于“虛構”這一概念,這一術語已經在關于AI的公共話語中獲得了流行,但尚未在學術文獻中廣泛傳播。
1 “虛構”(confabulation)VS“幻覺”(hallucination)
"Confabulation" 和 "hallucination" 都是從精神病學借用過來的人化類比,但"confabulation"因避免了暗示LLMs具有感官體驗或意識的棘手含義,且更中性,因此在AI公共話語中被視為"hallucination"的首選替代詞。
1.1 現有定義的局限性
現有的定義主要關注偽造與事實不符的特征,忽略了其在人類交流中的社會和認知效益。
這些定義沒有充分考慮人類在填補知識空白時,傾向于使用敘事作為認知資源的傾向。
1.2 新的定義
偽造是一種敘事沖動,即生成更具實質性、更連貫的輸出的傾向。這種沖動體現了人類利用敘事進行理解和交流的傾向。
偽造可以產生虛構但可信的信息,幫助人們填補知識空白,并構建連貫的語義意義。
2 數據、方法和結果
2.1 基準數據集
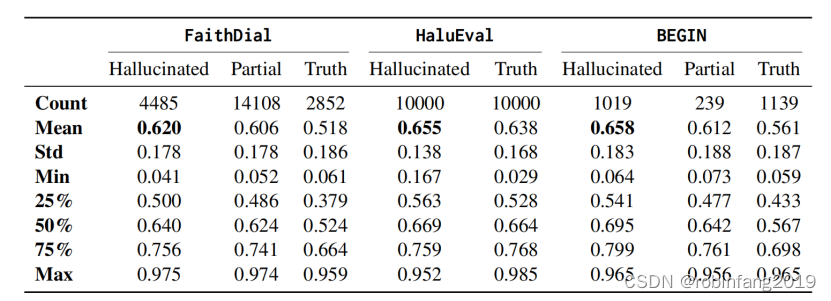
FaithDial:一個無幻覺的對話基準,介于尋求信息的用戶和聊天機器人之間,改編自“維基百科巫師”。Mechanical Turk注釋器將WoW的人類生成響應標記為“幻覺”或真實響應。真實響應被細分為三個類別:“蘊含”(Entailment)、“不合作”(Uncooperative)和“通用”(Generic),并對21445個原始響應進行了忠實且基于知識的編輯。
BEGIN:是對FaithDial進行的初步研究,旨在選擇一個現有的基準進行后續的大規模注釋和編輯。作為一個較小的專家策劃集,它包括信息尋求查詢以及人類編寫和模型生成(GPT-2、DoHA和CRTL)的響應,每種響應都使用與FaithDial略有不同的幻覺分類法進行標記(增加了“部分幻覺”作為標簽),由專家注釋器完成。我們采用BEGIN作為對我們在HaluEval上發現的敘事模式的模型和數據集的一致性和魯棒性的驗證,以確認不同數據集和模型之間敘事模式的一致性和魯棒性。
HaluEval:是一個全面的數據集,展示了合理但幻覺的ChatGPT生成與其真相對應物。與FaithDial和BEGIN更細粒度的幻覺標簽不同,HaluEval只區分幻覺和真相響應。我們只使用HaluEval的對話部分,包含10000個樣本,以保持與其他基準的領域一致性。
對于FaithDial和BEGIN數據集,我們將所有不包含“幻覺”標簽的輸出視為“真相”,并將所有包含“幻覺”標簽以及一個額外真實標簽的輸出視為“部分”幻覺/真相。這種聚合允許跨數據集進行更直接的比較。如下表所示:虛構文本表現出更高水平的敘事性,因此可以被視為一種敘事豐富的行為。
2.2 方法
- 敘事性評估: 使用微調后的 ELECTRA-large 模型,對幻覺文本和真實文本進行敘事性評估,并比較兩組文本的敘事性得分。
- 敘事性與幻覺標簽的相關性分析: 使用二元邏輯回歸模型,分析敘事性得分與幻覺標簽之間的預測關系,以確定敘事性是否可以預測幻覺標簽。
- 敘事性與連貫性的相關性分析: 使用貝塔回歸模型,分析敘事性得分與對話連貫性得分之間的相關性,以確定敘事性是否與連貫性相關。
2.3 結果
- 敘事性: 在所有三個基準數據集中,幻覺文本的敘事性得分都顯著高于部分幻覺文本和非幻覺文本,以及它們的真實回復。
- 敘事性與幻覺標簽: 敘事性得分可以顯著預測幻覺標簽,即敘事性越高的文本,更有可能被標注為幻覺。
- 敘事性與連貫性: 敘事性得分與對話連貫性得分之間存在顯著正相關關系,即敘事性越高的文本,對話的連貫性也越高。
3 虛構價值有待挖掘
我們認為,虛構的敘事豐富特性不應被視為缺陷,而是LLM與人類使用敘事作為說服、身份構建和社會協商多功能工具的既定傾向相一致的標志。反過來,規范觀點對虛構的不加思索的否定將冒著從LLM的能力中消除對溝通和意義構建至關重要的行為和認知能力的風險。虛構價值有待進一步挖掘:
- 敘事性增強: 偽造的輸出往往具有更高的敘事性,即內容更加連貫和有故事性。這與人類傾向于使用敘事來理解和溝通的方式相似,因此可能更易于理解和接受。
- 啟發式工具: 偽造的輸出可以作為啟發式工具,幫助人們探索特定領域的場景,并利用偽造的特性進行創造性思維。
- 對抗樣本: 偽造的輸出可以用于構建對抗樣本,幫助提高模型的魯棒性和可靠性。
- 合成訓練數據: 偽造的輸出可以作為合成訓練數據,用于增強模型的泛化能力。
4 未來研究方向
我們提出對LLM虛構現象作為潛在資源的系統性辯護,而不是一個絕對的負面陷阱。我們認為,認為LLM產生幻覺是因為它們不可靠、不忠實,最終不像人類的觀點過于簡化。相反,它們虛構并表現出與人類講故事沖動非常相似的敘事豐富行為模式——也許幻覺使它們比我們愿意承認的更像我們。
- 因果關系未明確:盡管研究發現敘述性與連貫性之間存在關聯,但研究并未斷言敘述性直接驅動連貫性,這需要更全面的方法來闡明。
- 跨學科視角的支持:當前結論得到了跨學科視角的支持,但需要更健壯的敘事建模方法和更全面的人類評估來進一步探討這一關聯。
- 人類-AI交互的驗證:研究中觀察到的敘述性和連貫性特征在人類-人類交流中被認為是有益的,但這些特性在人類-AI交互中的適用性需要通過基于人類的評估來驗證。
- 后續實驗計劃:計劃通過包含人類參與者的實驗來驗證敘事參與的益處,并探索虛構在不同領域的應用潛力。
- 跨領域應用探索:如果敘事豐富的虛構得到有效驗證,將為未來研究開辟新途徑,包括在新聞、廣告等領域的應用,并可能激發更多跨學科的探索。




)
第3章)





)







