day01
1、報錯獲取不到瀏覽器二進制文件:需要指定瀏覽器路徑及驅動路徑。
第一次使用谷歌瀏覽器驅動,找不到二進制文件報錯:
selenium.common.exceptions.WebDriverException: Message: unknown error: cannot find Chrome binary
Stacktrace:原因:沒有把谷歌瀏覽器安裝在默認的地方這個錯誤信息表明在嘗試初始化webdriver.Chrome()時,Selenium無法找到Chrome瀏覽器的二進制文件。錯誤信息為:“unknown error: cannot find Chrome binary”。這通常發生在以下幾種情況:Chrome未安裝:確保Google Chrome瀏覽器已經安裝在你的系統上,并且安裝在默認路徑。對于Windows系統,Chrome通常安裝在C:\Program Files (x86)\Google\Chrome\Application\chrome.exe或者C:\Program Files\Google\Chrome\Application\chrome.exe。安裝路徑非標準:如果Chrome安裝在非標準路徑,Selenium可能無法自動找到它。在這種情況下,你需要在Selenium的ChromeOptions中手動指定Chrome的位置。環境變量問題:確保系統的環境變量中包含了Chrome的路徑,這樣Selenium就能找到Chrome的二進制文件。針對這個問題,如果Chrome已經安裝但Selenium仍然報錯,你可以通過以下方式手動指定Chrome的路徑:?指定路徑的代碼:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Optionschrome_driver_path = "D:/path/to/chromedriver.exe" # Chrome Driver的路徑
chrome_binary_path = "C:/Program Files/Google/Chrome/Application/chrome.exe" # Chrome瀏覽器的路徑,根據實際安裝位置調整options = Options()
options.binary_location = chrome_binary_path
service = Service(executable_path=chrome_driver_path)driver = webdriver.Chrome(service=service, options=options)
請確保將chrome_driver_path和chrome_binary_path替換為你系統上實際的路徑。這樣,Selenium就能正確地找到并使用Chrome瀏覽器了。
2、selenium的原理
地址:了解組件 | Selenium
3、更新pip的指令
python -m pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple/day02
1、會手寫Xpath--只用相對路徑
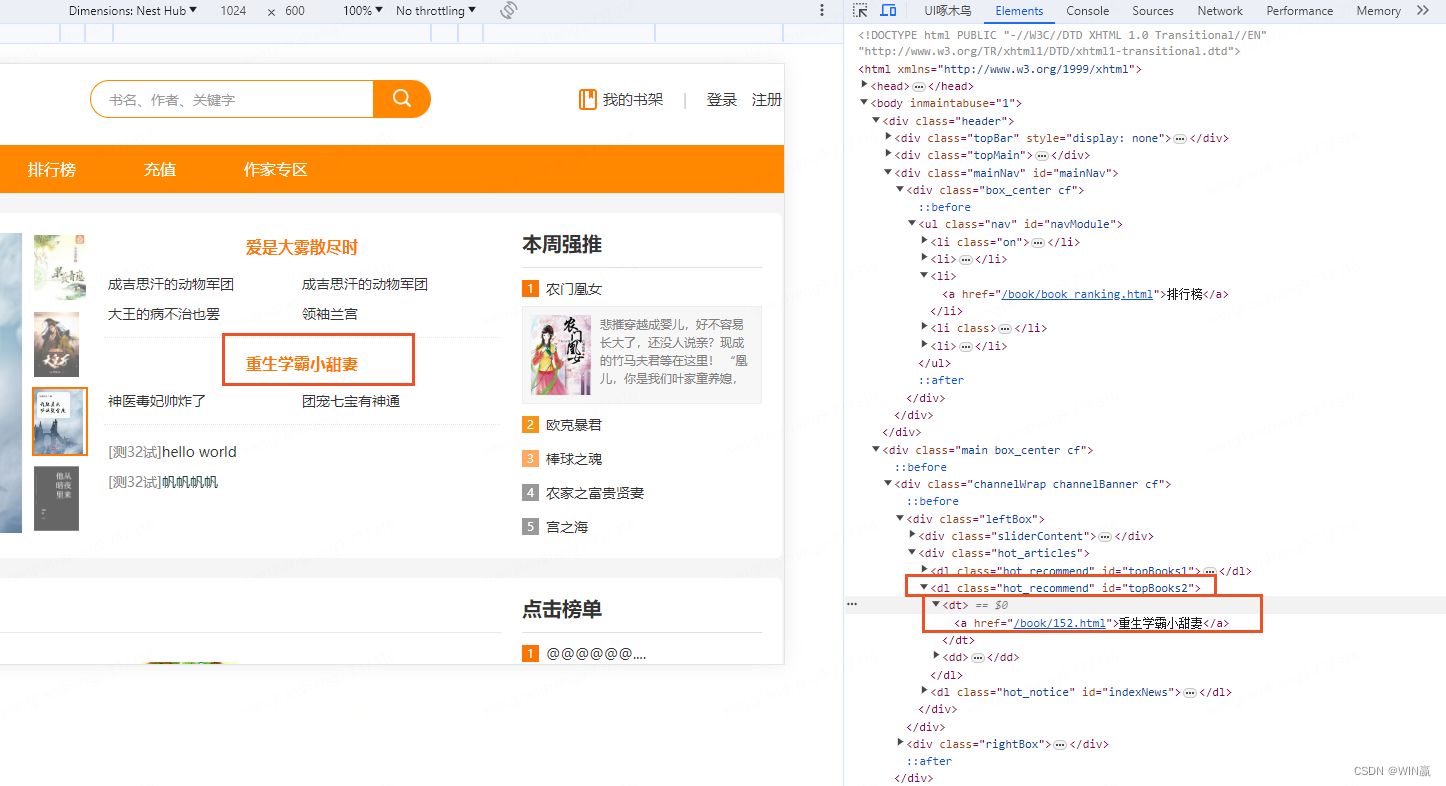
?1)通過唯一標識的方式
不管是什么元素類型,使用通配符*
el = driver.find_element(By.XPATH,"//*[@ID='topBooks2']")?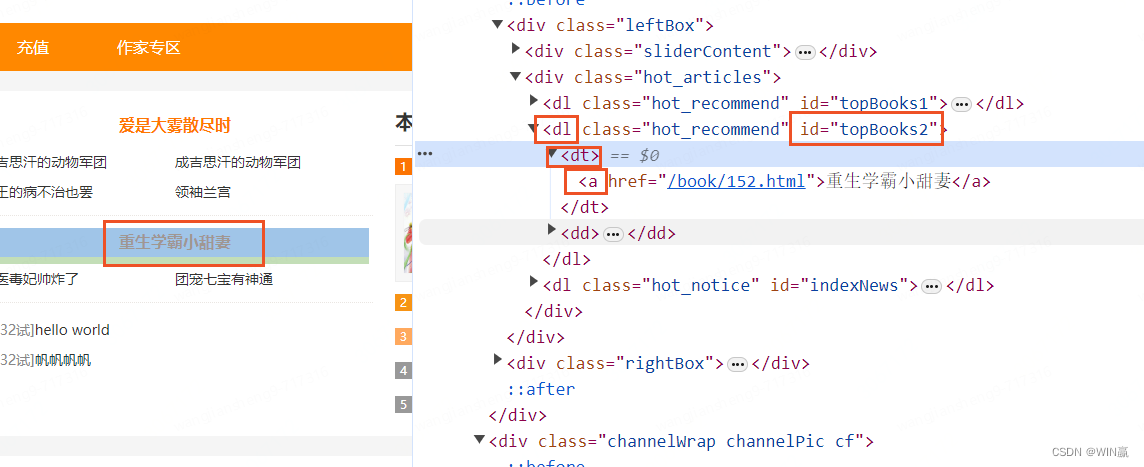
?在確定元素類型的情況下,使用元素類型 dl 去匹配元素
el = driver.find_element(By.XPATH,"//dl[@ID='topBooks2']")2)以。。開頭--模糊查詢
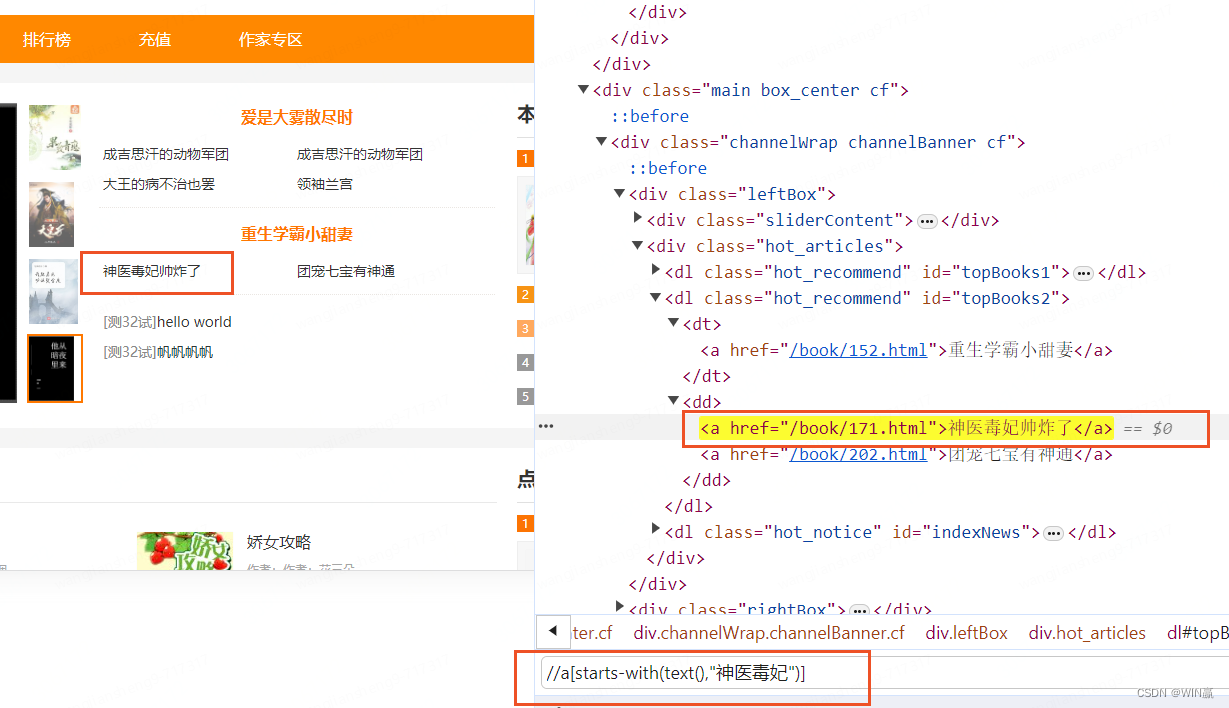
el = driver.find_element(By.XPATH,'//a[starts-with(text(),"神醫毒妃")]')3)包含
el = driver.find_element(By.XPATH,'//a[contains(text(),"神醫毒妃")]')4)蘇雪梅
要編寫XPath來定位包含“蘇雪梅”的元素1. **直接定位包含文本的`<a>`標簽**://td[@class='name']/a[contains(text(),'蘇雪梅')]這個XPath查找類名為`name`的`<td>`標簽下的`<a>`標簽,其中包含文本“蘇雪梅”。2. **使用文本定位整個`<td>`標簽**://td[contains(.,'蘇雪梅')]這個XPath查找任何包含“蘇雪梅”文本的`<td>`標簽。點(`.`)表示當前節點,所以`contains(.,'蘇雪梅')`是查找當前節點及其子節點中包含指定文本的情況。3. **基于特定父標簽的ID定位**://tbody[@id='newRankBooks2']//a[contains(text(),'蘇雪梅')]```如果頁面上有多個元素包含“蘇雪梅”且你只對特定區域(例如ID為`newRankBooks2`的`<tbody>`內的元素)感興趣,這個XPath會更加精確。4. **考慮使用兄弟節點定位**:如果你想基于與目標元素相鄰的其他元素(例如作者名“張瑩”)來定位“蘇雪梅”,可以使用如下XPath://td[a[contains(text(),'張瑩')]]/preceding-sibling::td[@class='name']/a[contains(text(),'蘇雪梅')]這個XPath首先定位包含文本“張瑩”的`<a>`標簽的`<td>`標簽,然后向前查找前一個兄弟`<td>`標簽,該標簽的類為`name`,并且其子`<a>`標簽包含文本“蘇雪梅”。
day03
1、等待
1)強制等待--調試代碼
import time time.sleep(3)程序執行到此處會強制等待3s2)隱式等待
driver.implicitly_wait(2)表示對程序執行整個生命周期內的元素都會等待2s.不需要導包哦3)顯式等待
4)包含下拉框的項目地址
包含下拉框的項目地址:https://sahitest.com/demo/selectTest.ht

)





—— 主題建模)



)







