論文:https://arxiv.org/abs/2404.16022
代碼:https://github.com/ToTheBeginning/PuLID
文章目錄
- Abstract
- Introduction
- Related Work
- Methods
Abstract
我們提出了一種新穎的、無需調整的文本生成圖像ID定制方法——Pure and Lightning ID customization(PuLID)。通過將Lightning T2I分支與標準擴散分支結合,PuLID引入了對比對齊損失和準確ID損失,最大程度地減少了對原始模型的干擾,確保了高ID保真度。實驗表明,PuLID在ID保真度和可編輯性方面都表現出色。PuLID的另一個吸引人的特性是,在插入ID前后,圖像的元素(例如背景、光照、構圖和風格)盡可能保持一致。代碼和模型將會發布在https://github.com/ToTheBeginning/PuLID。
Introduction
作為一種特定類別的定制化文本生成圖像(T2I)方法【5, 30, 12, 17, 40, 42】,身份(ID)定制允許用戶適配預訓練的T2I擴散模型,以符合他們的個性化ID。一類方法【5, 30, 12, 17】通過在用戶提供的同一ID的若干圖像上微調某些參數,從而將ID嵌入到生成模型中。這些方法催生了許多流行的AI肖像應用程序,如PhotoAI和EPIK。
盡管基于微調的解決方案取得了可觀的成果,但每個ID的定制需要耗費數十分鐘的微調時間,因此使個性化過程經濟成本較高。另一類方法【41, 42, 2, 36, 20, 19, 38】則放棄了每個ID微調的必要性,轉而在一個龐大的肖像數據集上預訓練一個ID適配器【11, 24】。這些方法通常利用編碼器(例如CLIP圖像編碼器【27】)提取ID特征。然后,將提取的特征以特定方式(例如嵌入到交叉注意力層中)整合到基礎擴散模型中。盡管這些無需微調的方法效率極高,但面臨兩個顯著挑戰。
- ID插入會破壞原始模型的行為。一個純粹的ID信息嵌入應具有兩個特征。首先,理想的ID插入應僅改變與ID相關的方面,如面部、發型和膚色,而與特定身份不直接相關的圖像元素,如背景、光照、構圖和風格,應該與原始模型的行為保持一致。據我們所知,以前的工作并未關注這一點。盡管一些研究【42, 38, 20】展示了生成風格化ID的能力,但與ID插入前的圖像相比,風格明顯退化(如圖1所示)。具有較高ID保真度的方法往往會導致更嚴重的風格退化。
其次,在ID插入后,仍應保持原始T2I模型遵循提示的能力。在ID定制的背景下,這通常意味著能夠通過提示改變ID屬性(例如年齡、性別、表情和發型)、方向和配件(例如眼鏡)。為了實現這些特性,目前的解決方案通常分為兩類。第一類涉及增強編碼器。IPAdapter【42, 1】從早期版本的CLIP提取網格特征轉向利用面部識別骨干【4】提取更抽象和相關的ID信息。盡管編輯性有所改善,但ID保真度還不夠高。InstantID【38】通過包括一個額外的ID和標志控制網【43】來進行更有效的調節。盡管ID相似性顯著提高,但卻犧牲了一定程度的編輯性和靈活性。第二類方法【20】通過構建按ID分組的數據集支持非重建訓練以增強編輯性;每個ID包含若干圖像。然而,創建這樣的數據集需要付出巨大的努力。而且,大多數ID對應于有限數量的名人,這可能會限制其對非名人的效果。
- 缺乏ID保真度。考慮到我們對面部的高度敏感性,在ID定制任務中保持高度的ID保真度至關重要。受GAN時代【7】面部生成任務【29, 39】成功經驗的啟發,提高ID保真度的一個直接想法是在擴散訓練中引入ID損失。然而,由于擴散模型的迭代去噪特性【10】,實現準確的x0需要多個步驟。以這種方式訓練所消耗的資源可能高得令人望而卻步。因此,一些方法【2】直接從當前時間步預測x0,然后計算ID損失。然而,當當前時間步較大時,預測的x0往往嘈雜且有缺陷。在這種條件下計算ID損失顯然不準確,因為面部識別骨干【4】是在照片級真實感圖像上訓練的。盡管提出了一些變通方法,如僅在噪聲較小的時間步計算ID損失【25】或通過額外的推理步驟預測x0【45】,但仍有改進空間。
在這項工作中,為了在減少對原始模型行為影響的同時保持高ID保真度,我們提出了PuLID,一種通過對比對齊實現的純粹和快速的ID定制方法。具體而言,我們引入了一個Lightning T2I分支以及標準擴散去噪訓練分支。利用最近的快速采樣方法【23, 32, 21】,Lightning T2I分支可以在有限且可控的步驟內從純噪聲生成高質量圖像。通過這個額外的分支,我們可以同時解決上述兩個挑戰。首先,為了最小化對原始模型行為的影響,我們構建了一個對比對,其中包括相同提示和初始潛在變量,有和沒有ID插入。在Lightning T2I過程中,我們在語義上對齊對比對的UNet特征,指導ID適配器如何插入ID信息而不影響原始模型的行為。其次,由于我們現在在ID插入后有了精確和高質量的生成x0,我們可以自然地提取其面部嵌入并與真實面部嵌入計算準確的ID損失。值得一提的是,這種x0生成過程與實際測試環境一致。我們的實驗表明,在這種情況下優化ID損失可以顯著提高ID相似性。
貢獻總結如下:(1) 我們提出了一種無需調整的方法,即PuLID,在減輕對原始模型行為影響的同時保持高ID相似性。(2) 我們引入了一個Lightning T2I分支和常規擴散分支。在這個分支中,我們結合了對比對齊損失和ID損失,以最小化ID信息對原始模型的污染,同時確保保真度。與當前主流方法提高ID編碼器或數據集相比,我們提供了新的視角和訓練范式。(3) 實驗表明,我們的方法在ID保真度和可編輯性方面實現了SOTA性能。此外,與現有方法相比,我們的方法對模型的ID信息侵擾較少,使得我們的方法在實際應用中更加靈活。
Related Work
基于微調的文本生成圖像ID定制。文本生成圖像模型的ID定制旨在使預訓練模型能夠生成特定身份的圖像,同時遵循文本描述。兩個開創性的基于微調的工作【5, 30】努力實現這一目標。Textual Inversion【5】為用戶提供的ID優化了一個新的詞嵌入,而Dreambooth【30】則通過微調整個生成器進一步增強了保真度。隨后,各種方法【12, 17, 8, 35】在生成器和嵌入空間探索了不同的微調范式,以實現更高的ID保真度和文本對齊。盡管這些進展顯著,但每個ID的耗時優化過程(至少需要幾分鐘)限制了其更廣泛的應用。
無需微調的文本生成圖像ID定制。為了減少在線微調所需的資源,一系列無需微調的方法【36, 38, 25, 42, 20, 41, 3】應運而生,這些方法直接將ID信息編碼到生成過程中。這些方法面臨的主要挑戰是,在保持高ID保真度的同時,盡量減少對T2I模型原始行為的干擾。為了最小化干擾,一個可行的方法是使用面部識別模型【4】提取更抽象和相關的面部領域特定表示,就像IP-Adapter-FaceID【1】和InstantID【38】所做的那樣。包含同一ID的多張圖像的數據集可以促進共同表示的學習【20】。盡管這些方法取得了一定的進展,但它們還沒有從根本上解決干擾問題。值得注意的是,ID保真度較高的模型往往會對原始模型的行為造成更大的干擾。在本研究中,我們提出了一種新的視角和訓練方法來解決這一問題。有趣的是,該方法不需要按ID分組的數據集,也不局限于特定的ID編碼器。
為了提高ID保真度,以前的工作【16, 2】使用了ID損失,這一做法受到了先前基于GAN的工作【29, 39】的啟發。然而,在這些方法中,通常在當前時間步使用單一步驟直接預測x0,這往往會導致嘈雜和有缺陷的圖像。這些圖像對于面部識別模型【4】來說并不理想,因為它們是在真實世界的圖像上訓練的。PortraitBooth【25】通過僅在噪聲較小的階段應用ID損失來緩解這一問題,但這忽略了早期步驟中的損失,從而限制了其整體有效性。Diffswap【45】通過使用兩步而不是一步來獲得更好的預測x0,盡管這種估計仍然包含嘈雜的偽影。在我們的工作中,通過引入Lightning T2I訓練分支,我們可以在更準確的設置中計算ID損失。
我們注意到一個同時進行的工作LCM-Lookahead【6】,它也使用了快速采樣技術(即LCM【23】)來實現更精確的x0預測。然而,該工作與我們的工作有幾個不同之處。首先,LCM-Lookahead在傳統的擴散去噪過程中對x0進行精確預測,而我們從純噪聲開始,迭代去噪到x0。我們的方法與實際測試設置更一致,使得ID損失的優化更加直接。其次,為了增強提示編輯能力,LCM-Lookahead利用了SDXL-Turbo【32】的模式崩潰現象來合成一致的ID數據集。然而,合成的數據集可能面臨多樣性和一致性挑戰,作者發現,使用該數據集訓練可能比其他方法更頻繁地產生風格化結果。相比之下,我們的方法不需要按ID分組的數據集。相反,我們通過一種更基礎和直觀的方法,即對比對齊,來增強提示跟隨能力。
擴散模型的快速采樣。在實踐中,擴散模型通常在1000步內進行訓練。在推理過程中,這種冗長的過程可以借助高級采樣方法【33, 22, 15】縮短到幾十步。最近基于蒸餾的工作【21, 23, 32】進一步將這一生成過程加速到10步以內。其核心動機是指導學生網絡對齊與基礎教師模型更遠的點。在本研究中,我們引入的Lightning T2I訓練分支利用了SDXL-Lightning【21】加速技術,從而使我們能夠在僅4步內從純噪聲生成高質量圖像。
Methods
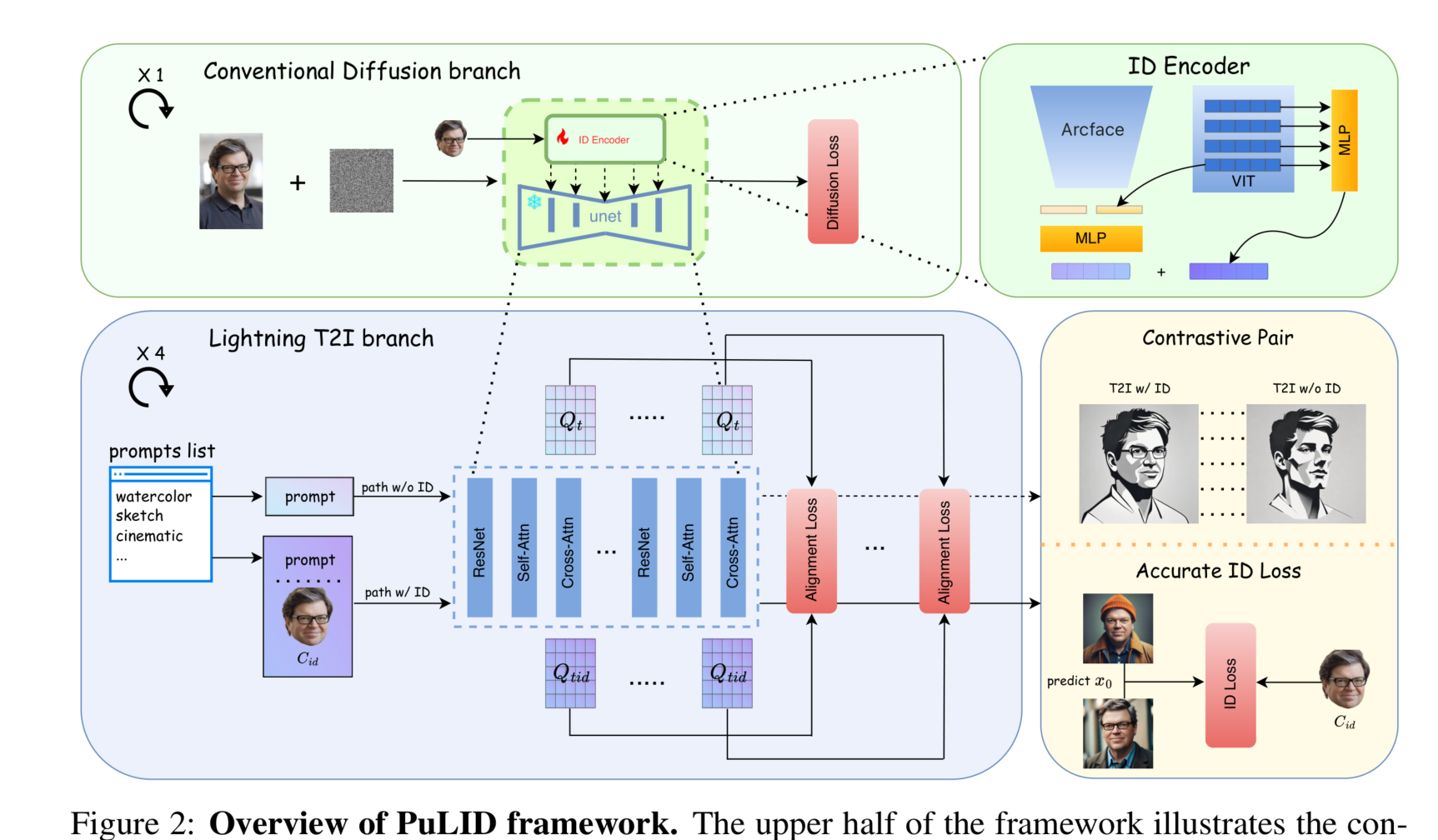
圖2:PuLID框架概述。框架的上半部分展示了傳統的擴散訓練過程。從同一圖像中提取的面部用作ID條件 ( C_{\text{id}} )。框架的下半部分展示了本研究中引入的Lightning T2I訓練分支。該分支利用了最新的快速采樣方法,通過幾步迭代去噪從純噪聲生成高質量圖像(本文中為4步)。在這個分支中,我們構建了有ID注入和無ID注入的對比路徑,并引入了對齊損失,以指導模型如何在不破壞原始模型行為的情況下插入ID條件。由于該分支可以生成照片級真實感圖像,這意味著我們可以實現更準確的ID損失優化。

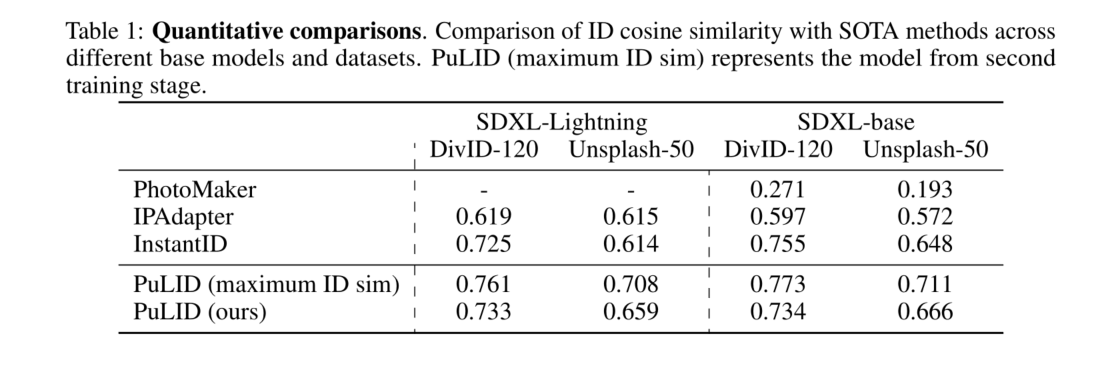













查詢)





