整數集合是 Set 對象的底層實現之一。當一個 Set 對象只包含整數值元素,并且元素數量不大時,就會使用整數集合這個數據結構作為底層實現。
1. 整數集合結構設計
整數集合本質上是一塊連續內存空間,它的結構定義如下:
typedef struct intset {// 編碼方式uint32_t encoding;// 集合包含的元素數量uint32_t length;// 保存元素的數組int8_t contents[];
} intset;可以看到,保存元素的容器是一個 contents 數組,雖然 contents 被生命為 int8_t 類型的數組,但是實際上 contents 數組并不保存任何 int8_t 類型的元素,contents 數組的真正類型取決于 intset 結構體里的 encoding 屬性的值。比如:
-
如果 encoding 屬性值為 INTSET_ENC_INT16,那么 contents 就是一個 int16_t 類型的數組,數組中每一個元素的類型都是 int16_t;
-
如果 encoding 屬性值為 INTSET_ENC_INT32,那么 contents 就是一個 int32_t 類型的數組,數組中每一個元素的類型都是 int32_t;
-
如果 encoding 屬性值為 INTSET_ENC_INT64,那么 contents 就是一個 int64_t 類型的數組,數組中每一個元素的類型都是 int64_t;
不同類型的 contents 數組,意味著數組的大小也會不同。
2. 整數集合的升級操作
整數集合會有一個升級規則,就是當我們將一個新元素加入到整數集合里面,如果新元素的類型(int32_t)比整數集合現有所有元素的類型(int16_t)都要長時,整數集合需要先進行升級,也就是按新元素的類型(int32_t)擴展 contents 數組的空間大小,然后才能將新元素加入到整數集合里,當然升級的過程中,也要維持整數集合的有序性。
為什么管理混合類型會增加復雜度:
從計算機的基本原理來看,
int16_t和int32_t在內存中的占用大小、表達范圍以及在某些情況下的處理方式上存在區別,這些區別導致了在處理它們時的一些差異。在數據結構內部同時管理int16_t和int32_t類型的數據,意味著每次操作數據(如添加、刪除、查找)時,都需要判斷并根據不同的類型作相應處理。這不僅在編碼時增加了分支判斷的復雜度,還可能導致在執行時增加額外的判斷開銷。此外,混合類型的數據存儲可能導致內存布局的非連續性和對齊問題,進而影響訪問效率。因此,雖然
int16_t和int32_t在概念上是相似的(都是用來存儲整數的類型),但它們在內存占用、表達范圍和處理細節上的這些區別,決定了在統一的數據結構中同時管理這些不同類型會使得結構管理變得更加復雜。Redis 的整數集合通過類型升級來避免這種復雜性,從而使得數據存儲、訪問和維護更加高效和一致。
整數集合升級的過程不會重新分配一個新類型的數組,而是在原本的數組上擴展空間,然后再將每個元素按間隔類型大小分割,如果 encoding 屬性值為 INTSET_ENC_INT16,則每個元素的間隔就是 16 位。
舉個例子,假設有一個整數集合里有 3 個類型為 int16_t 的元素。
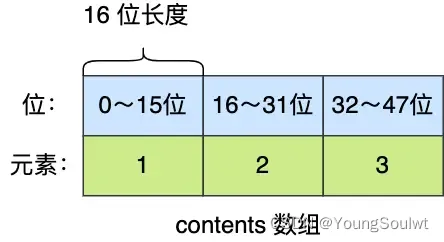
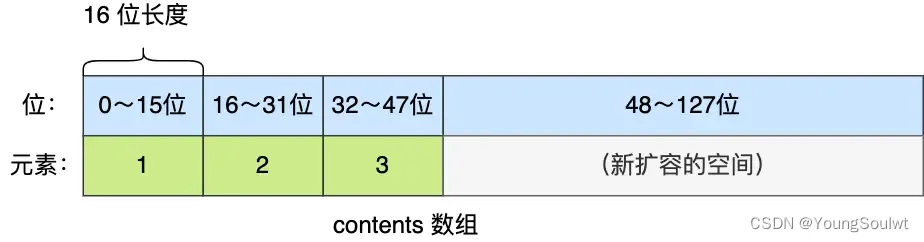
現在,往這個整數集合中加入一個新元素 65535,這個新元素需要用 int32_t 類型來保存,所以整數集合要進行升級操作,首先需要為 contents 數組擴容,在原本空間的大小上再擴容多 80 位(4 × 32 - 3 × 16 = 80),這樣就能保存下四個類型為 int32_t 的元素。
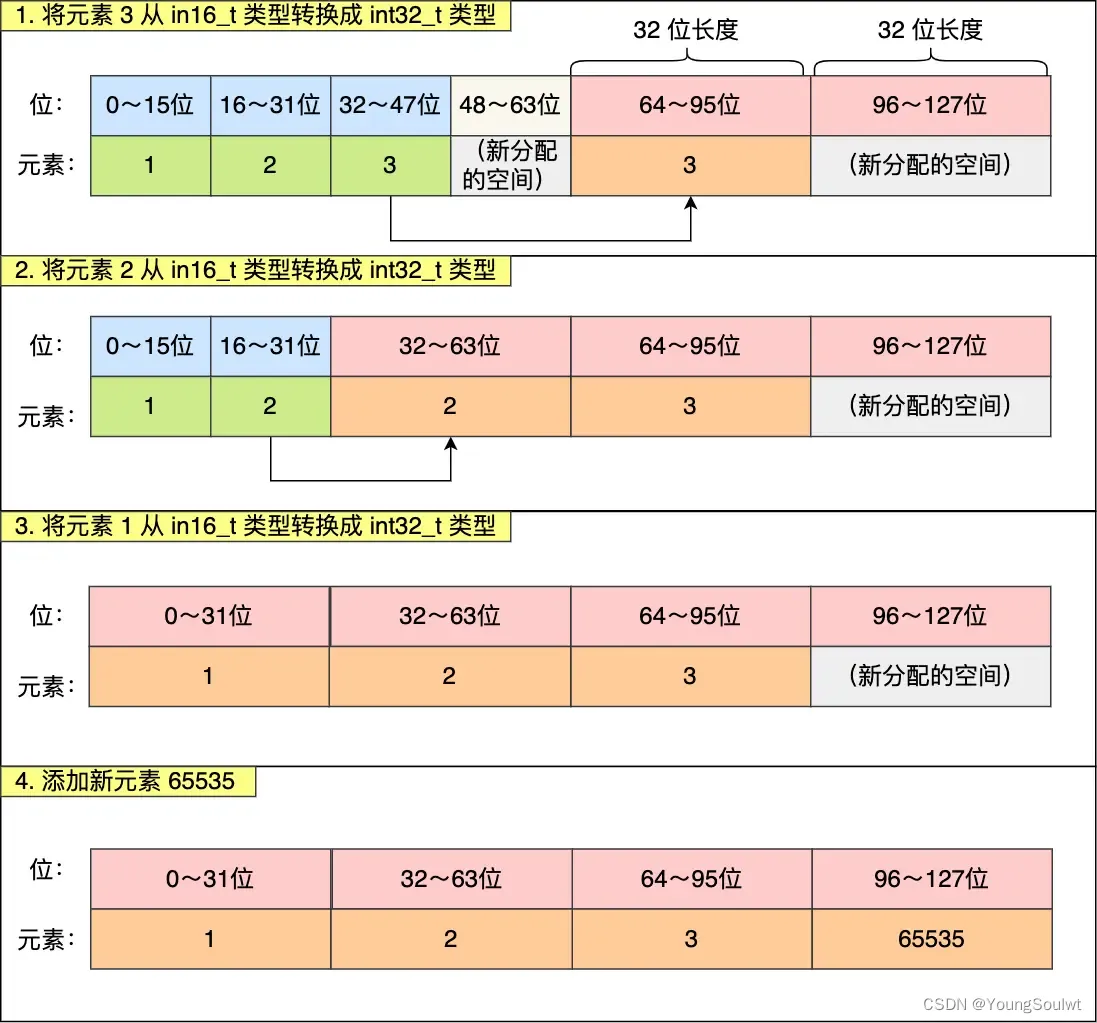
擴容完 contents 數組空間大小后,需要將之前的三個元素轉換為 int32_t 類型,并將轉換后的元素放置到正確的位上面,并且需要維持底層數組的有序性不變,整個轉換過程如下:
整數集合升級有什么好處呢?
如果要讓一個數組同時保存 int16_t、int32_t、int64_t 類型的元素,最簡單的做法就是直接使用 int64_t 類型的數組。不過這樣的話,當如果元素都是 int16_t 類型的,就會造成內存浪費的情況。
整數集合升級就能避免這種情況,如果一直向整數集合添加 int16_t 類型的元素,那么整數集合的底層實現就一直是用 int16_t 類型的數組,只有在我們要將 int32_t 類型或 int64_t 類型的元素添加到集合時,才會對數組進行升級操作。
因此,整數集合升級的好處是節省內存資源。
整數集合支持降級操作嗎?
不支持降級操作,一旦對數組進行了升級,就會一直保持升級后的狀態。比如前面的升級操作的例子,如果刪除了 65535 元素,整數集合的數組還是 int32_t 類型的,并不會因此降級為 int16_t 類型。


)




介紹)
)



 A~D)






